Zelditch M.L. (и др.) Geometric Morphometrics for Biologists: a primer
Подождите немного. Документ загружается.


chap-09 4/6/2004 17: 25 page 228
228 GEOMETRIC MORPHOMETRICS FOR BIOLOGISTS
categorical variable. Add the interactions between the explanatory variables if they are not
automatically included in the model. As discussed earlier in this chapter (see discussion of
simple and complex ANOVAs, Tables 9.2–9.4), exclusion of the interaction terms from
the analysis is not advised because it alters all of the sums of squares, which may influence
conclusions if any of the explanatory variables has a marginal effect.
Now punch the “go” button, sit back, and wait for the output to stop scrolling (if you
have a lot of landmarks and more than a couple of explanatory variables, it may take
a while for the program to work through all of the tests). If your program generates a
series of univariate tests for each landmark coordinate or spline component, ignore them.
As discussed in Chapters 4 and 6, these variables are not independent in the sense that is
relevant to these tests. If your results include a test for the MANOVA constant, this result
can also usually be ignored. However, this component of the test cannot be excluded; it
is analogous to evaluating whether a regression has a non-zero intercept. Excluding the
constant is equivalent to forcing a regression through the origin. In the case of regression,
this can affect the estimation of the slope, conclusions regarding the deviation of the slope
from zero, and inferences about the proportion of variation explained by the regression.
For similar reasons, excluding the constant from the MANOVA is not recommended under
most circumstances. (Effects of constants are also computed in ANOVA, but are often not
included in the output.) Eventually, scrolling through the results will reach the multivariate
results for each categorical variable and any interactions. As mentioned earlier, there are
several possible test statistics that could be reported. The differences among them only
matter when the effects are marginal. Each test statistic should have a corresponding F
or χ
2
, degrees of freedom, and p-value. These are the numbers on which you will base
conclusions regarding the significance of effects.
References
Chatfield, C. and Collins, A. J. (1980). Introduction to Multivariate Analysis. Chapman and Hall.
Morrison, D. F. (1990). Multivariate Statistical Methods, 3rd edn. McGraw Hill.
Snedecor, G. W. and Cochran, W. G. (1967). Statistical Methods, 6th edn. Iowa State University
Press.

chap-10 4/6/2004 17: 26 page 229
10
Regression
Chapter 9 covered methods for testing hypotheses about samples that differ categorically.
This chapter covers methods for testing hypotheses about samples that vary along a con-
tinuously valued factor–afactor measured on an infinitely divisible scale. Size is an
example of such a continuously valued factor because there is always a size between any
two others; similarly, latitude is continuously valued because there is a latitude between
any two others. When we hypothesize that a continuously valued factor affects shape, we
use regression to test the hypothesis. Additionally, when we want to control for the effects
of such a factor so that we can distinguish between groups defined by a categorical vari-
able, we use regression to control for those effects. Finally, we would use regression when
our hypotheses concern the particular nature of an effect, i.e. the direction of the shape
variable covarying with the factor of interest. For example, if our hypothesis is that two
species follow a common ontogeny of shape, we use regression to describe each ontogeny,
then we compare the two vectors, asking if they point in the same direction.
The chief aim of regression is to explain the variation in one variable (shape, in our case)
by another. For example, we might suspect that several factors account for the variation in
our data, including: age or size; geographic variables such as latitude, longitude or temper-
ature; ecological variables such as the size of predators and the density of the canopy; or
even clinically important characteristics such as health status. So long as the candidate fac-
tor is measured, and measured along a continuously valued scale, we can test the hypothesis
that it affects shape. The strategy for testing the hypothesis is simple and straightforward:
(1) formulate a mathematical model that predicts shape as a function of the presumed
explanatory variable; (2) fit the model to the data; (3) evaluate the fit. However, the anal-
ysis is somewhat more delicate than it seems, for two reasons. First, and perhaps most
obvious, the mathematical model might not be simple (either to devise or to fit). Second,
what we actually are doing is predicting shape, not explaining it – and prediction is not
quite the same thing as explanation, just as a mathematical model is not quite the same as
a biological model. The distinction is important to keep in mind because, when we test our
model statistically, the hypothesis we are actually testing is that the mathematical model
predicts shape, which is not the same as testing the hypothesis that the independent vari-
able actually causes the variation in shape. It is common to make the distinction between
Geometric Morphometrics for Biologists Copyright © 2004 Elsevier Ltd
ISBN 0–12–77846–08 All rights of reproduction in any form reserved

chap-10 4/6/2004 17: 26 page 230
230 GEOMETRIC MORPHOMETRICS FOR BIOLOGISTS
causation and correlation, which is often done by pointing to trends that are accidentally
related; but sometimes the trends are biologically related and yet there still is not a direct,
causal relationship.
To clarify the distinction between prediction and explanation, and also between math-
ematical and biological models, we can consider one common predictor of shape: size.
Often, much (or most) of the variation in shape is predicted by size. Based on the good fit
of our model to the data, we might conclude that size predicts shape, and so it might seem
that size explains shape. However, size is not a process. In the context of developmental
biology, we can explain size in terms of the proliferation of cells that add tissue to a struc-
ture. Because growth rates vary over the organism, cell proliferation (in conjunction with
cell death, cell differentiation, deposition of an extracellular matrix, etc.) produces changes
in shape. In this context, saying that size “explains” shape does not mean that size itself
causes shape; rather, it means that we are using “size” as shorthand for all those develop-
mental processes that jointly alter size and shape. Also, we are modeling this process by
a simple mathematical function, which is the model that is actually tested. In the context
of functional morphology, “size” is also shorthand, but it is shorthand for a more com-
plex argument. The underlying causal hypothesis is biomechanical; the idea is that shape
covaries with size because the mechanically optimal shape for one size differs from that for
another size. However, in correlating shape to size we are not demonstrating that selection
molds shape, nor even that shape affects performance; instead, we are demonstrating that
the relationship between size and shape is predicted by a particular mathematical model.
Most often, that mathematical model is the equation of a straight line, hence the term
“linear regression.” We are fitting the equation of a straight line to the data to find the
coefficients that best predict shape from values of the independent variable (e.g. size).
More specifically, we are trying to find the best estimates of the coefficients m and b of
the equation:
Y =mX +b +ε (10.1)
where Y is the dependent variable (shape in our case), m is the slope of the line, b is the
Y-intercept of the line, and ε is “error” (the variation in Y not explained by X). To predict
Y from X we need to find the values for m and b. Having obtained the best estimates for
them (using the approach described below), we can then ask whether they are statistically
different from zero.
The approach we use to find the values for those coefficients assumes a linear relationship
between X and Y. The reason for emphasizing this assumption is that a strong but non-
linear relationship might look like a weak linear one. Consequently, we end up rejecting
our biological model because the statistical analysis suggests a weak relationship between
variables, but the relation is actually strong but not linear. When the assumption of linearity
holds, our statistical analysis can tell us if Y is only weakly dependent on X – meaning that
knowledge about X does not enable us to predict Y. It is also possible that the relationship
of the two variables is statistically significant, but that m is such a small number that the
effect of X on Y is biologically trivial. It may be a statistically significant relationship, in
that it is stronger than expected by chance, but it might not be biologically significant.
Recognizing this distinction is important, because statistical significance is a matter of
sample size and the power of a test. With very large samples, or very powerful tests, we

chap-10 4/6/2004 17: 26 page 231
REGRESSION 231
might have little difficulty rejecting the null hypothesis. However, if X accounts for very
little of the variation in Y, X provides little biological insight into Y. We therefore need to
pay as much attention to the explanatory power of X and to the magnitude of its impact
on Y as to the statistical results. The fraction of the variance in Y explained by X provides
the needed information about explanatory power; the magnitude of the effect is evident
primarily in the depiction of the regression as a deformation, although we can also estimate
it from the Procrustes distance between the shapes at the lowest and highest values of the
independent variable. If that distance is small, the impact of X on Y is slight.
To this point, we have talked about the relationship between Y and X as if it is the
primary focus of a study. Often it is, but sometimes their relationship is a complicating
factor. For example, we might want to know whether males and females differ in shape,
and to make that determination we might need to take into account that they also differ
in size. We then have two questions to address: (1) do males and females differ in shape?
and (2) do males and females differ in shape solely because they differ in size? Even if we
find that they differ in shape, we might suspect that they would be the same shape were
we able to compare them at the same size. Making such comparisons is another purpose
of regression. Using the regression model, we can control for differences in X when com-
paring groups. That is done by (multivariate) analysis of covariance ({M}ANCOVA). The
independent variable, X, is treated as a covariate whose effects are controlled statistically
when comparing two or more means. So long as the relationship between X and Y is
linear, and the groups have the same value for m, we can statistically control for the effect
of X on Y when comparing the groups. This analysis depends on two assumptions: (1)
linearity, and (2) equality of m. If either is false the results can be seriously misleading; we
might manufacture differences between groups, or fail to detect the ones that exist.
Prediction and control are the two main uses of regression, but there is a third: testing
the equality of the regression equations. This third use is important when we wish to
know whether populations evince the same response to a particular factor. For example,
we might want to know if species follow the same ontogeny of shape. Each ontogeny is
described by the linear model relating shape to size or age, so to compare the ontogenies we
compare the vectors of regression coefficients. Similarly, we might be interested in whether
two or more populations respond to variation in temperature in the same way – which we
can determine by testing the hypothesis that they undergo the same changes in shape as a
function of temperature.
In this chapter we begin with a general overview of regression, starting with simple
bivariate regression then generalizing to multivariate regression. We first discuss estimating
the parameters m and b, evaluating the strength of the relationship between X and Y, and
testing the statistical significance of the regression model. We then discuss the use of
regression to control for variation in X when we want to compare values of Y between
groups. Finally, we discuss comparative analyses.
An overview of regression
We presume that most readers are familiar with simple bivariate regression, but we discuss
it in some detail, both as a review of the general idea of regression and as preparation for
moving from the bivariate to the multivariate case.

chap-10 4/6/2004 17: 26 page 232
232 GEOMETRIC MORPHOMETRICS FOR BIOLOGISTS
Bivariate regression
The simplest possible use of regression is to analyze the relationship between two vari-
ables, Y and X, both of which are single numbers (meaning that neither is a vector).
Many mathematical models could be used to analyze the dependence of Y on X, but the
simplest and most popular is a straight line, hence the model uses the formula for a line
(Y =mX +b). We must add another term to the model, ε, representing “error,” not only
because measurements are made with error, but also because individuals within popula-
tions vary. “Error” in this context refers not only to measurement error, but also to any
source of random variation in Y that is independent of X.
For the simple bivariate case, we have one dependent variable (Y) and one independent
variable (X), each of which is measured on N individuals. The relationship between the
two variables was given in Equation 10.1, but we repeat it here so you do not have to turn
back to that page:
Y =mX +b +ε (10.1)
Our objective is to estimate m and b.
In a moment we will present the equations that provide the best estimates of m and b, but
to explain why they are considered “best” we first need to consider how that decision could
be made, in general. The standard approach for deriving the best estimator is to choose an
error function. By minimizing that error, we find the optimal values for the parameters.
A least squares analysis, as the term suggests, uses the sum of squared residuals as the error
function, so that is the function minimized. We then express the relationship between that
error term and the regression model:
N
i=1
ε
2
i
=
N
i=1
(y
i
−mx
i
−b)
2
(10.2)
where x
i
=X
i
−<X> (the difference between an observed value of X
i
and its expected
value <X>, which is the sample mean) and y
i
=Y
i
−<Y> (the difference between an
observed value of Y
i
and its expected value <Y>). Thus, we are summing residuals, or
deviations from expected values, over all N individuals in a population. By minimizing
this function, we will obtain the best estimates for m and b.
To find the values of m and b that minimize the sum of squared residuals, we set the
derivative to zero (for both m and b). As you recall from calculus, the derivative of a
function is zero at the maximum and minimum. We then solve for m and b. Using this
optimization method, the equation for the slope, m, can be written as:
m =
xy
x
2
(10.3)
which is the sum of the products of the deviations divided by the sum of the squared
deviations of the X values (each sum is taken over all individuals). In other words, the
slope is the ratio of the deviations of Y to the corresponding deviations of X. When the
corresponding deviations are identical, the slope is one; when the deviations of Y are a
consistent multiple of the deviations of X, the slope will be that multiple.

chap-10 4/6/2004 17: 26 page 233
REGRESSION 233
Substituting the X
i
−<X> for x
i
and Y
i
−<Y> for y
i
allows us to compute m directly
from the observed values. The sum of the products can be written as:
xy =
(
X
i
−<X>
)(
Y
i
−<Y>
)
(10.4)
which can be simplified to:
N
X
i
Y
i
−
X
i
Y
i
(10.5)
After applying a similar substitution and simplification to the sum of the squared
deviations, we can write:
M =
N
N
i=1
X
i
Y
i
−
N
i=1
X
i
N
i=1
Y
i
N
N
i=1
X
2
i
−
N
i=1
X
i
2
(10.6)
Now that we have an expression for the slope, we can solve for the intercept, b, and
complete the equation for the regression. When b =0, <Y> =m<X>, so we can calculate
b from the observed values, X
i
and Y
i
, and the sample size, N:
b = <Y> −m<X> =
N
i=1
Y
i
−m
N
i=1
X
i
N
(10.7)
In addition to an estimate of the value of m, we will also need measures of the uncertainty
of that estimate. These measures will be used to test whether m is significantly different
from zero (because if we cannot say that, we cannot claim that Y depends on X), and
to test whether the value of m differs between samples (whether the relationship between
X and Y is different).
Before we derive the measures of uncertainty, it will be useful to introduce some
shorthand notation. The sums of squares of the deviations x
i
and y
i
will be:
s
xx
=
N
i=1
x
2
i
(10.8)
and
s
yy
=
N
i=1
y
2
i
(10.9)
Similarly, the sum of the products of the deviations will be:
s
xy
=
N
i=1
x
i
y
i
(10.10)
In testing whether the regression is significant, it is important to keep in mind that we
are asking whether the relationship between X and Y explains a significant proportion

chap-10 4/6/2004 17: 26 page 234
234 GEOMETRIC MORPHOMETRICS FOR BIOLOGISTS
of the variance in Y. If we knew the values of the error terms, ε
i
, we could compute
their variance and use that to determine the proportion of the variance in Y explained by
the regression of Y on X. More often than not, ε
i
are unknown, so we need a different
approach. Following the logic of ANOVA (Chapter 9), we can compute an F-ratio from
the information we do have. F is a ratio of variances or mean squared deviations, which
are sums of squared deviations divided by the appropriate degrees of freedom. The sum of
squared deviations explained by the regression is s
2
XY
/s
XX
. This has one degree of freedom,
so the variance explained is also s
2
XY
/s
XX
. Recall that the slope is s
XY
/s
XX
, so the explained
variance can also be written as m ·s
XY
. The unexplained or residual sum of squared devi-
ations is s
YY
−m ·s
XY
, which has N −2 degrees of freedom, so the unexplained variance
is (s
YY
−m ·s
XY
)/(N −2). F is the explained variance divided by the unexplained, so
(N −2)m ·s
XY
/(s
YY
−m ·s
XY
) with 1 and N −2 degrees of freedom; the corresponding
p-value indicates the likelihood that such a high F (such a large proportion of the variance
in Y explained by regression on X) is due to chance.
We can also use the explained variance to calculate an estimate of the variance of the
slope:
s
2
m
=
s
YY
−ms
XY
N −2
s
XX
(10.11)
The square root of this quantity is the standard error of the slope, which can be used
in conjunction with the t distribution to test whether the slope deviates from a specific
value and to construct confidence intervals around the slope. To test whether the slope
differs from zero, compute t =(m −0)/s
m
and look up the p-value associated with that
t and N −2 degrees of freedom. To construct a confidence interval around m, select an
appropriate value of α, which is the critical value for the test statistic. This value is chosen
according to the rate at which we are willing to make a Type I error (which is the error
of rejecting a true null hypothesis). Usually α is chosen to be 0.05, which means that we
are willing to risk an error rate of 5%. To have a total error rate of 0.05, we usually
want the value of t that allows on 2.5% error on either side of the estimate (t
α/2, N −2,
i.e.
the critical value of the t distribution for the confidence level of α, with N −2 degrees of
freedom). The width of the confidence interval is 2t ·s
m
; its upper and lower bounds are
given by m ±t ·s
m
. To show that Y depends on X, m must be significantly different from
zero. When N is large (>60 or so) the t-distribution approximates the normal one, so that
t
0.05/2, N −2
is 1.96 (the 2.5% upper and lower bounds for the normal distribution).
In some circumstances it is desirable to estimate the variance in the intercept. This can
be computed as:
σ
2
b
=
s
XX
+N<X>
2
σ
2
Ns
XX
(10.12)
in which σ
2
is the unexplained variance (above). Again, there are N −2 degrees of free-
dom. Then the confidence interval for b can be determined using either the t or normal
distribution, depending on N.

chap-10 4/6/2004 17: 26 page 235
REGRESSION 235
The correlation coefficient
The correlation coefficient (R), which ranges from minus one to one, expresses the strength
of the linear relationship between X and Y. Its squared value (R
2
), which ranges from zero
to one, indicates the fraction of the variance in Y explained by X. The expression for R
2
is:
R
2
=
s
2
XY
s
XX
s
YY
(10.13)
It is very common to regard high R
2
values as if they indicate high explanatory power of
the model. However, even high values of R
2
need not be statistically significantly greater
than zero. For that reason we need to test the statistical significance of R
2
, which we can
do (assuming normality of the residuals) by the expression:
1
2
ln
(1 +R)
(1 −R)
(10.14)
which is a normally distributed variable, with variance equal to 1/(N −3), where N is the
sample size.
Multivariate regression
To apply this theory to shape we need to extend it to the multivariate case, because shape
is multidimensional. Our dependent variable is a vector with 2K −4 components (where
K is the number of landmarks and each landmark has two coordinates). The statistics are
much easier to handle if we use partial warp scores instead of the coordinates obtained by
a Procrustes (GLS) superimposition, because partial warp scores have the correct degrees
of freedom. Thus, throughout the remainder of this chapter, the dependent variable is a
vector of partial warp scores (including the scores on the uniform component – rather than
saying this repeatedly, assume that the uniform component is included whenever we refer
to the vector of partial warp scores).
To regress shape on an independent (scalar) variable, we regress the full set of partial
warp scores on the independent variable. For example, suppose we have P partial warp
and uniform components, which we can write as a row vector {Y
1
, Y
2
, Y
3
, ... Y
P
}. Then
the (linear) model for the regression of that vector on a scalar (X) is:
{Y
1
, Y
2
, Y
3
, ...Y
P
}={m
1
, m
2
, m
3
, ...m
P
}X +{b
1
, b
2
, b
3
, ...b
P
}+{ε
1
, ε
2
, ε
3
, ...ε
P
}
(10.15)
where {m
1
, m
2
, m
3
,…m
P
}, {b
1
, b
2
, b
3
,…b
P
} and {ε
1
, ε
2
, ε
3
,…ε
P
} are vectors of slope
and intercept coefficients and residuals, respectively. Although this expression looks far
more complicated than that for a bivariate regression, it actually is not. In fact, we can
determine the ith component of the slope and intercept terms using the same m
i
and b
i
values that minimize the residuals in the corresponding bivariate model.
Mathematically, the regression of P components on a scalar X is identical to doing
P separate simple bivariate regressions of each Y on X. The parameters m
i
and b
i
are
determined by the equations for the bivariate case, given above. However, the test for
the significance of the regression is different from that for the bivariate case because we

chap-10 4/6/2004 17: 26 page 236
236 GEOMETRIC MORPHOMETRICS FOR BIOLOGISTS
are dealing with a multivariate system. One approach is to use the Wilks’ Lambda, ,
which is:
=
det(
R
)
det()
(10.16)
where
R
is the variance–covariance matrix of the predicted values of Y at a value of X in
the data set, det is the determinant of the matrix, and is the variance–covariance matrix
for the original set of variables (i.e. partial warp scores in our case); this is the same statistic
discussed in Chapter 9 (MANOVA). Several other conventional multivariate test criteria
can be used that all give the same results when there is only one independent variable. Addi-
tionally, we can use a generalized form of Goodall’s F-statistic to test the significance of the
regression of geometric shape data on size (this statistic was also introduced in Chapter 9).
To determine the proportion of the shape variance that is a function of the independent
variable we should not use the standard multivariate version of R
2
because that is a function
of two determinants, one of which is the determinant of the sample variance–covariance
matrix (the other is the determinant of the matrix of predicted values). Because R
2
is
partly a function of the correlations among the dependent variables, it does not measure
the correlation between dependent and independent variables. As an alternative measure
of the explanatory power of the regression, we can use one that depends on the Procrustes
distance between each specimen and its expected shape (given its value of X). Squaring
and summing those distances gives a measure of the variance in shape not explained by
X (because the distances are the deviations from the regression, so the model does not
explain them). This metric corresponds to what we would normally regard as the variance
not explained by the regression, i.e. 1 −R
2
, and has the advantage of being in the familiar
(and meaningful) units of Procrustes distance.
The assumption of linearity
When we fit a straight line to the data we are assuming that the relationship between shape
and the independent variable is linear. Sometimes it is not. Fortunately, in some of those
cases, it is easy to transform the independent variable to make the relationship linear. For
example, a number of studies of ontogenetic allometry use the logarithm of centroid size,
rather than centroid size itself, as the independent variable. That transformation is useful
when most of the shape change occurs over small values of X, such as when most shape
change occurs early in ontogeny (as it often does). In other cases, other transformations of
X (such as other trigonometric functions, for example) might do a better job of linearizing
the relationship between variables. We should note that it does not matter whether the
logarithm is taken to base 10 (log) or base e (ln) because these differ only by a constant,
i.e. log(X) =log(e) ln(X) =0.4329 ln(X).
The assumption of linearity should always be checked before using a linear model (and
before taking any statistical test at face-value). There are at least two ways to check this
assumption, although neither is ideal. One is to look at the relationship between each
individual component of shape and the independent variable, such as by regressing each
partial warp on size. If one or more evinces a highly non-linear relationship, such as shown
in Figure 10.1A, then it is unlikely that shape and size are linearly related. This method is
not ideal, because it falls back on bivariate regression when it is multivariate linearity that
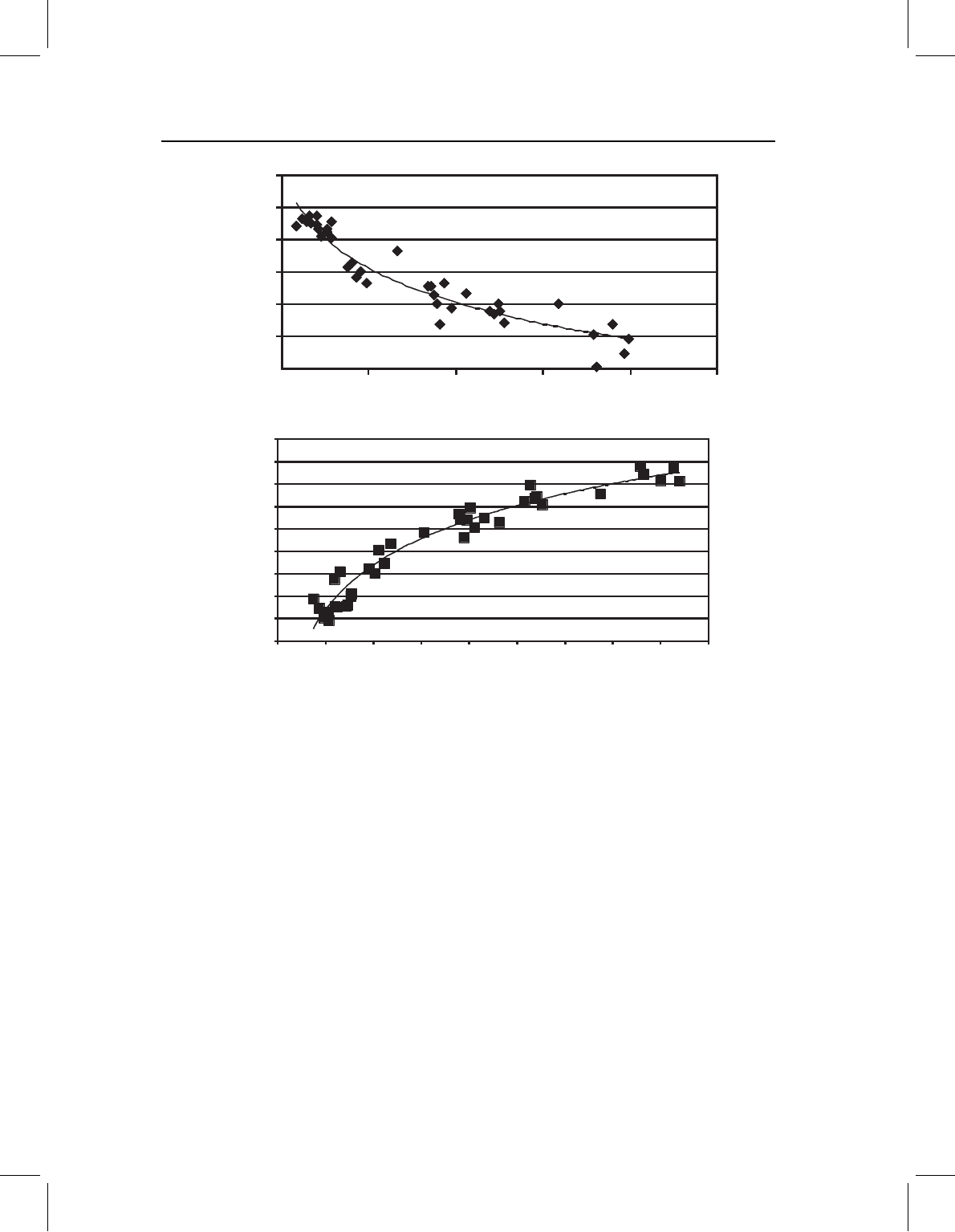
chap-10 4/6/2004 17: 26 page 237
REGRESSION 237
20 120 220 320 420 520
CS
PW3X
⫺0.04
⫺0.02
0
0.02
0.04
0.06
0.08
(A)
0
0.02
0.04
0.06
0.08
0.10
0.12
0.14
0.16
0.18
0 50 100 150 200 250 300 350 400 450
CS
PD
(B)
Figure 10.1 Checking the assumption of a linear relationship between shape and the independent
variable: (A) using a single variable plotted on centroid size; (B) using the Procrustes distance of each
specimen from the shape having the smallest size, plotted on centroid size.
matters. Another approach is to estimate the Procrustes distance between each specimen
and the shape at the lowest value on the independent variable. Regressing that distance on
the independent variable may show if that relationship is non-linear (as in Figure 10.1B).
If not, it is unlikely that shape and size are linearly related. This method is again not ideal,
because the Procrustes distance measures only the magnitude of the difference between
each specimen and the reference, not its direction. Two specimens that differ a great deal
from each other in shape may be equally distant from the reference.
Nevertheless, we can use the results from these two less than ideal methods to determine
if it is unlikely that shape is linearly related to size. The results shown in Figure 10.1 both
indicate a non-linear relationship, and both also suggest that shape might be linearly related
to the log of centroid size (that suggestion is in the shape of the curves, which indicate a
very rapid change in shape relative to size over the smaller values of size). So we can
try a log transform of centroid size, then repeat the analyses to check for linearity again
(Figure 10.2). Both plots now suggest a nearly linear relationship between shape and log
centroid size. Thus, we would use log centroid size as our independent variable.