Ипатов В.П. Широкополосные сигналы
Подождите немного. Документ загружается.


238
зуя понятие расширенного двузначного характера
,1,0,1,;1,,2,1),(
,,
ipkda
ikik
. (7.58)
Сформированное подобным образом бинарное множество обладает следующими пара-
метрами
2
2
2
max
)3(
,1),1(
L
p
pKppL
. (7.59)
Длина L может быть сделана достаточно большой только за счет выбора
p
)1( p
, при
котором
1)/()3(/)3(
222
pppLp
и
L/1
2
max
, доказывая после сравнения с
(7.45), по крайней мере, асимптотическую оптимальность ансамбля по уровню пика кор-
реляции.
Пример 7.5.3. Пусть
7p
. Прямая проверка подтверждает, что
3
является
примитивным элементом поля
)7(GF
. Тогда последовательности
}{
i
и
}{
i
обладают
периодом
61p
и имеют вид:
},3,1,5,4,6,2,3,1,{
и
},5,1,3,2,6,4,5,1,{
соответст-
венно. Комбинирование их по модулю 7 с последовательностью
},1,0,6,5,4,3,2,1,0,{}{ i
периода 7, как это предписано (7.57), дает
81 pK
7–
значных последовательностей периода
42)1( ppL
. Например, первой из них являет-
ся
}404433513322550355446225006614662211361100{}{
,1
i
d
. Замена 7–значных элемен-
тов расширенными характерами согласно правилу
1)4()2()1()0(
и
1)6()5()3(
превращает последовательности в их 8 бинарных аналогов, напри-
мер,
}{}{
,1
i
a
. Дос-
таточно утомительно вычислять их АКФ и ВКФ «в ручную», поэтому задача 7.42 оказы-
вает программную поддержку в решении данной проблемы.
Вторая конструкция Камалетдинова использует p–ичную
)4mod334( hp
ли-
нейную последовательность
}{
i
c
, полученную децимацией с индексом
1 pd
1p
сдвига
1,,2,1},{
pKkd
ki
p–ичной m–последовательности
}{
i
d
памяти
2n
, т.е.
длины
1
2
p
. Поскольку d делит
1
2
p
, то последовательность
}{}{
kdii
dc
обладает
периодом
1)1/()1(
2
ppp
. Теперь построим
1p
последовательность над
)(pGF
,1,0,1,;1,,2,1,
,
ipkdid
kdiik
, (7.60)
и отобразим их на бинарный алфавит
}1{
согласно (7.58). В результате имеем ансамбль с
параметрами
22
2
2
max
1)1(
,1),1(
pL
p
pKppL
. (7.61)
Снова для больших длин
)1( p
отношение
1)/()1(/)1(
222
pppLp
и
L/1
2
max
, демонстрируя, по крайней мере, асимптотическую оптимальность ансамбля.
Пример 7.5.4. В данном случае отсутствует исключение для
3p
и
p
–ичная m–
последовательность
}{
i
d
памяти
2n
и длины
81
2
p
может быть сформирована с
помощью примитивного полинома над
)3(GF
второй степени
2)(
2
xxxf
, или, что
эквивалентно, с помощью рекурсии
21
2
iii
ddd
. При начальном состоянии регистра
0,1
10
dd
получаем последовательность
},0,1,1,2,0,2,2,1,0,1,{}{
i
d
. Ее сдвиги,
децимированные с индексом
21 pd
, трансформируются в две последовательности с

239
периодом 4:
},2,2,1,1,2,2,1,1,{
и
},1,0,2,0,1,0,2,0,{
. После посимвольного сложе-
ния с последовательностью
},2,1,0,2,1,0,{}{ i
они дают
21 pK
последователь-
ностей периода
12)1( ppL
:
}1,0,1,0,0,2,0,2,2,1,2,1{
и
}0,1,2,2,2,0,1,1,1,2,0,0{
. По-
следний шаг, состоящий в замене их элементов расширенными характерами
1)1()0(
,
1)2(
, приводит к образованию множества Камалетдинова из двух
бинарных последовательностей длины
12L
:
}{}{
,1
i
a
и
}{}{
,2
i
a
. Вычисление значений их АКФ и ВКФ не составляет труда
выполнить вручную (или с помощью программы из задачи 7.43), которое приводит к
9/1
2
max
в полном соответствии с (7.61).
Для доказательства утверждений о величине пика корреляции в вышеприведенных
ансамблях необходимо привлечение теории квадратичных уравнений в конечных полях.
Оставляя эту сложную задачу вне нашего внимания, рекомендуем обратиться заинтересо-
ванному читателю к оригинальной статье [76].
В таблице 7.1 представлены итоговые результаты рассмотрения бинарных мини-
максных ансамблей, в которой приведены значения длины (перечень всех длин сущест-
вующих ансамблей в диапазоне
10237 L
), числа сигнатур и квадрата максимума кор-
реляции. Таблица достаточно выразительно подчеркивает вклад множеств Камалетдино-
ва: в рассматриваемом интервале число их длин составляет 11 против 6 для Голда и 4 для
Касами.
Таблица 7.1. Примеры ансамблей бинарных минимаксных сигнатур.
Ансамбль
Длина
L
Объем
K
Квадрат максимума
корреляции
2
max
Голд
1023,511,127,63,31,7
4mod0,12 n
n
122
n
L
четное,
4
)1)1(2(
,нечетное,
2
)1)1(2(
2
2
2
2
n
L
L
L
n
L
L
L
Касами
1023255,63,15,
четное,12 n
n
1L
L
L
L 1)11(
2
2
Объединение Каса-
ми и бент последо-
вательностей
255,15
4mod0,12 n
n
112 L
L
L
L 1)11(
2
2
Камалетдинов 1
930,506,342110,42,
простое),1( ppp
L
L
p
2
314
1
L
L
p 1)3(
2
2
Камалетдинов 2
992,552,380,13256,12,
простое),1( ppp
L
L
p
2
314
1
L
L
p 1)1(
2
2
240
Задачи.
7.1. В CDMA системе с прямым расширением спектра, основанной на периодиче-
ских бинарных сигнатурах и передаче данных с бинарной ФМ, пользователь передает
сигнал вида
}{
, занимающий интервал более двух бит
данных. Какой код сигнатуры использует этот абонент (общий знак всех символов являет-
ся несущественным), если длительность бита данных равна периоду сигнатуры?
7.2. В CDMA системе с прямым расширением спектра, основанной на периодиче-
ских бинарных сигнатурах и передаче данных с бинарной ФМ, некоторый абонент ис-
пользует сигнатурный код вида
}{
с длительностью бита данных, равной пе-
риоду сигнатуры
7
. Вследствие неудачи в синхронизации по времени сужающий опор-
ный сигнал приемника отстает от принятого расширенного сигнала на один чип. Каким
будет результат демодуляции данных в случае передачи нулевого потока бит?
7.3. В какой степени наличие амплитудной модуляции в АФМ сигнатуре затронет
структуру приемника с прямым расширением спектра? Возвратит ли в этом случае проце-
дура снятия расширения символ данных к виду, отвечающему передаче без расширения
спектра?
7.4. CDMA система с прямым расширением спектра использует квадратурную ФМ
для передачи данных со скоростью 64 кбит/сек и расширяющий код с чиповой скоростью
6
1028.1
чип/сек. Определить коэффициент расширения и полосу, занимаемую системой.
7.5. CDMA–система с прыгающей частотой использует 4-х частотный расширяю-
щий сигнал длины
}3,2,4,1{:4N
и передачу данных с ЧМ-4 (каждая пара бит передается
на одной из 4-х частот). Передается битовый поток вида 00101101. Изобразить возможную
частотно–временную решетку переданного сигнала, если один бит данных охватывает две
длительности чипа. Какой тип прыгающей частоты используется: быстрый или медлен-
ный?
7.6. CDMA система с прыгающей частотой использует 4-х частотный расширяю-
щий сигнал длины
}3,2,4,1{:4N
и передачу данных с ЧМ-4 (каждая пара бит передается
на одной из четырех частот). Передается битовый поток вида 10110100. Изобразить воз-
можную частотно–временную решетку переданного сигнала, если один сигнатурный чип
охватывает два бита данных. Какой тип прыгающей частоты используется: быстрый или
медленный?
7.7. CDMA–система с быстрой перестройкой частоты использует 16–ти частотный
расширяющий сигнал и модуляцию данных с ЧМ-4. Длительность чипа составляет 10
мксек. Оценить минимальные полосы расширяющего и переданного сигнала, если чипы
различных частот будут ортогональны.
7.8. В выделенной полосе
8.76
t
W
КГц следует организовать синхронную CDMA
систему, передающую данные с помощью бинарной ФМ со скоростью
6.9R
кбит/сек.
Сколько пользователей она может обслуживать при сохранении оптимальности однополь-
зовательского приемника? Построить соответствующее множество бинарных сигнатур. На
сколько изменится число пользователей, если передачу данных с бинарной ФМ заменить
на квадратурную ФМ, ФМ-8 или КАМ-16? Если любой из перечисленных методов моду-
ляции увеличивает число пользователей, то какой ценой это достигается?

241
7.9. Синхронная CDMA система обслуживает 36 пользователей, используя ортого-
нальные сигнатуры с одинаковой энергией на бит. Сколько новых сигнатур с такой же
энергией на бит можно добавить к существующим, не ухудшая минимального расстояния
между различными групповыми сигналами?
7.10. Какова минимальная длина синхронных сигнатур, допускающая увеличение
не менее чем на 33% числа пользователей в схеме перенасыщения (7.23)?
7.11. Добавить дополнительную сигнатуру к четырем функциям Уолша длины
4N
. Является ли дополнительная сигнатура бинарной? Если нет, то можно ли модифи-
цировать исходные сигнатуры так, чтобы дополнительная сигнатура была бы бинарной?
7.12. Построено
3/)14( NK
синхронных сигнатур согласно схеме перенасыще-
ния (7.23). Рационально ли их использовать в CDMA системе с K пользователями, если
допустим только обычный однопользовательский приемник?
7.13. Определить минимальную длину, потенциально допускающую мощность по-
мех MAI на сигнатуру в однопользовательском приемнике при синхронном перенасы-
щенном CDMA не выше –30 дБ относительно мощности полезного сигнала, если число
пользователей равно 101.
7.14. Доказать, что три и более бинарных последовательностей длины
N
не могут
быть ортогональными друг другу, если их длина не кратна четырем.
7.15. Существует ли перенасыщенное множество из
21K
бинарной сигнатуры,
удовлетворяющее границе Велча? Что можно сказать для случая
32или23,22K
?
7.16. Обрисовать процедуру построения множества из
256K
бинарных последо-
вательностей длины
100N
, лежащих на границе Велча.
7.17. (Каристинос–Падос [64]). Доказать, что для перенасыщенного множества не-
четного числа
K
бинарных сигнатур граница Велча (7.30) возрастает до
N
N
N
K
TSC
1
2
.
7.18. Построить ансамбль из
15K
бинарных сигнатур длины
12N
, достигаю-
щих границы, приведенной в предыдущей задаче. Обобщить процедуру на случай
12
m
K
сигнатур
)( NK
.
7.19. Каков минимальный период
11K
асинхронных сигнатур, которые не отри-
цают получение среднего квадрата корреляции между всеми их циклическими копиями в
пределах –20 дБ?
7.20. Рассмотрим случайные сигнатуры, удовлетворяющие (7.37). Доказать, что
умножение сигнатур на символы данных (модуляция данных) не нарушает соотношения
(7.37), обеспеченного независимостью символов данных от символов сигнатур.
7.21. Доказать, что если две последовательности одного и того же наименьшего пе-
риода L обладают идеальной периодической АКФ, то их периодическая ВКФ не может
равняться нулю при всех взаимных сдвигах.
242
7.22. Определить максимальное число асинхронных сигнатур периода
100L
, ко-
торые позволяют удержать максимум корреляции ниже –23 дБ.
7.23. В пределах зоны с радиусом
15
c
D
км свободно могут передвигаться
50K
пользователей. Максимальная задержка распространения в канале между пользователем и
центральной станцией составляет
20
ds
мксек. Полоса, занимаемая системой, составля-
ет 2 МГц. Определить минимальные длины m– последовательности и последовательности
Лежандра, позволяющие использовать сдвинутые по времени сигнатуры для канала
«пользователь – центральная станция». Определить минимальную длину троичной после-
довательности с идеальной ПАКФ памяти 3, удовлетворяющую данной задаче.
7.24. В параграфе 7.5.1 для формирования множества частотно–сдвинутых сигна-
тур используется m– последовательность. Может ли любая другая бинарная минимаксная
последовательность (например, последовательность Лежандра) позволить использование
этого же метода получения множества сигнатур с квадратом корреляции около
L/1
? Если
нет, то почему?
7.25. Система с CDMA использует несущее колебание с длиной волны 4 см и дли-
тельностью чипа сигнатуры 1 мксек. Длина сигнатур должна быть
102312
10
L
. Ка-
ково максимальное число частотно–сдвинутых сигнатур может быть образовано, если
диапазон скоростей пользователей простирается до 144 км/час?
7.26. Найти все индексы децимации, подходящие алгоритму Голда для длин 63,
127, 511 и 1023.
7.27. Необходим ансамбль сигнатур для обслуживания
100K
пользователей с
максимумом корреляции не более 0.064. Какова минимальная длина ансамбля Голда,
удовлетворяющего этим требованиям?
7.28. Доказать минимаксные свойства (7.56) множеств Касами.
7.29. Необходим ансамбль сигнатур мощности не менее 31 с максимумом корреля-
ции ниже –23 дБ. Среди известных бинарных множеств найти ансамбль минимальной
длины, удовлетворяющий данным требованиям.
7.30. Необходим ансамбль сигнатур мощности не менее 24 с максимумом корреля-
ции ниже –25 дБ. Среди известных бинарных множеств найти ансамбль минимальной
длины, удовлетворяющий данным требованиям.
243
8. Поиск и слежение за сигналом с прямым расширением
спектра.
8.1. Процедуры поиска и слежения.
Одной из наиболее характерных задач в технологии распределенного спектра явля-
ется измерение времени прихода и частоты принятого сигнала. В системах, где широко-
полосные сигналы служат инструментом местоопределения и измерения параметров дви-
жущегося объекта (радиолокация, радионавигация, гидролокация), частотно–временная
оценка является основной операцией. В широкополосной связи указанное действие со-
ставляет основу процедуры установления временной шкалы. Действительно, для коррект-
ной демодуляции передаваемых данных приемник любой цифровой системы связи дол-
жен с достаточной точностью определить границы символов, кадров и т. п. в принятом
потоке данных. Другими словами, генератор локального приемника должен быть соответ-
ствующим образом синхронизирован с принятым потоком данных. В широкополосных
системах достаточно точная синхронизация является необходимым условием, поскольку
временное рассогласование между принятым расширяющим сигналом и его местной су-
жающей копией – опорой, превосходящее или равное длительности чипа, полностью на-
рушит процедуру снятия расширения и последующую демодуляцию данных (см. параграф
7.1). Таким образом, связанные с синхронизацией действия приемника включают предва-
рительное (до начала этапа восстановления данных) согласование собственного сужающе-
го образца с расширяющим кодом принятого сигнала и поддержание достаточно точной
синхронизации между ними в течение всего последующего времени приема данных. Оче-
видно, что с теоретической точки зрения в процедуре синхронизации нет ничего нового:
для согласования локальной опоры с принятым сигналом следует только измерить частот-
но–временной сдвиг принятого сигнала относительно местного генератора. Затем, если
это необходимо, генератор приемника может быть скорректирован по времени и частоте
и, значит, синхронизирован с принятым сигналом.
Оптимальные (максимально правдоподобные) стратегии измерения временного за-
паздывания и частоты основательно были рассмотрены в параграфах 2.12–2.14. Однако на
практике их «чистая» реализация очень часто сталкивается с серьезными препятствиями.
Начальное (например, при первичной инициализации приемника) смещение локального
генератора по времени и частоте относительно принятого сигнала может оказаться доста-
точно большим. К числу факторов, обуславливающих подобное рассогласование, отно-
сятся автономное функционирование передающего и приемного генераторов, широкий
диапазон изменения длины пути распространения между передатчиком и приемником,
доплеровский сдвиг частоты, вызванный их относительным движением, и т. п. В этих об-
стоятельствах непосредственное применение МП правила иногда может оказаться чрез-
мерно затруднительным или даже нереализуемым с точки зрения необходимых ресурсов,
что демонстрирует следующий пример.
Пример 8.1.1. Дальномерный C/A–сигнал системы GPS Navstar (см. параграф 11.1)
обладает периодом
1023L
чипов или, в реальном времени, равным
1L
мсек. Для
решения навигационной задачи необходимо измерять временное положение сигнала с
точностью не хуже долей микросекунды, например, 0.1 длительности чипа
. Если при-
емник инициализируется без предварительных сведений о расстройке локального генера-
тора относительно сигнала, то неопределенность о временной задержке сигнала составля-
ет один период, т.е.
L
. Обращаясь к структуре приемника, содержащей набор корреля-
торов (см. рис. 2.18), можно увидеть, что ее реализация требует применения 10230 парал-
лельных корреляторов. Переход к структуре с использованием согласованного фильтра
(рис. 2.19) не делает проблему проще: цифровой вариант подобного фильтра с памятью
L
должен оперировать, по крайней мере, с десятью отсчетами на чип, выполняя 1023
244
суммирования в течение одного интервала между выборками (менее 100 нсек). Привлече-
ние таких обширных аппаратных или программных ресурсов для решения только одной
из многих задач приема не выглядит экономически оправданным, по крайней мере, учи-
тывая существующие технологические тенденции.
Для избежания трудностей реализационного плана на практике процедуры частот-
но–временного оценивания в широкой области неопределенности часто реализуются в
виде двух последовательных этапов. Первый из них, называемый поиском (acquisition)
(поиском кода), производит грубое измерение необходимых параметров и обеспечивает
предварительными оценками, используемыми на втором этапе, называемом слежением
(tracking). Этот второй этап, обычно выполняемый специальными схемами слежения за
кодом и частотой, обеспечивает точными частотно–временными оценками, которые в
дальнейшем непосредственно используются местным опорным генератором для согласо-
вания сжимающего сигнала с принятым расширяющим кодом. Однако для вхождения в
синхронизм и этап слежения схемы слежения нуждаются в первоначальных целеуказани-
ях, например, в знании временного положения принятого сигнала с точностью до дли-
тельности одного чипа или около. Достижение данного условия, как уже указывалось ра-
нее, является задачей этапа поиска, решение которой уменьшает начальную неопределен-
ность сигнальных параметров до диапазона, требуемого схемой слежения. Сравнительно
мягкие требования относительно точности оценивания на этапе поиска позволяют сокра-
тить количество вычисляемых статистик и упростить структуру их реализующую. Если
возвратиться к условиям примера 8.1.1, то ослабление требований к необходимой точно-
сти временного измерения до длительности одного чипа означает в десять раз меньшее
число корреляторов в схеме на рис. 2.18 или в десять раз меньшую скорость обработки в
структуре с согласованным фильтром. В итоге, основной ресурсо–сберегающий техноло-
гией, используемой при поиске, является частичная или полная замена параллельных вы-
числений решающих статистик их последовательным выполнением.
Для объяснения данного утверждения будем трактовать неизвестные задержку
и
частотный сдвиг
F
сигнала как сигнальные координаты на частотно–временной плоско-
сти. Предположим, что диапазоны начальной неопределенности по параметрам
и
F
со-
ставляют
u
и
u
F
соответственно, и что в результате поиска они сокращаются до
и
F
. Тогда, как показывает рис. 8.1, позиция сигнала находится в пределах одной из
M
прямоугольных ячеек (cells) размера
F
, где
)/()( FFM
uu
. Процедура поиска
должна определить в какой из
M
ячеек содержится сигнал, т.е. осуществить проверку ис-
тинности
M
конкурирующих гипотез (см. параграф 2.8). Если бы использовалась опти-
мальная процедура указанной проверки, то параллельно были бы вычислены
M
корреля-
F
u
F
u
F
Рис. 8.1. Зона поиска и позиция сигнала на частотно–временной плоскости.
245
ций типа (2.74) для значений
и
F
, которые отвечают центрам ячеек, и решение было бы
принято в пользу тех
и
F
, которым отвечало бы максимальное значение корреляции.
На практике, однако, процедуры поиска используют факт длительного нахождения сигна-
ла на входе приемника, что позволяет одновременно вычислять только некоторые (а не
все
M
) корреляции. Если ни одна из них не является достаточно большой, то принимает-
ся решение, что среди тестируемых ячеек отсутствует истинная (т.е. содержащая сигнал),
и поиск продолжается путем проверки другой группы ячеек. Данная процедура продолжа-
ется до тех пор, пока некоторая корреляция не будет признана достаточно большой для
принятия решения об истинности соответствующей ей ячейки. Принятие решения завер-
шает процедуру поиска, после чего начинают работать схемы слежения, используя в каче-
стве начальных условий полученные оценки. Были осуществлены значительные исследо-
вания, касающиеся алгоритмов и стратегий поиска (см., например, библиографию в [77]).
Ниже ограничимся только очень кратким обсуждением, начав с простейшей версии этой
процедуры.
8.2. Процедура последовательного поиска.
8.2.1. Модель алгоритма.
При последовательном поиске в каждый момент времени анализируется только од-
на ячейка, т.е. вычисляется единственная корреляция наблюдения и локальной сигнальной
копии, характеризующейся некоторыми конкретными значениями сдвига по времени и
частоте. Затем величина корреляции анализируется с целью принятия решения об истин-
ности или ложности данной ячейки. При принятии решения могут использоваться различ-
ные критерии. Например, поиск может продолжаться до тех пор, пока все ячейки внутри
области неопределенности (см. рис. 8.1) не будут проанализированы, причем в течение
анализа запоминаются максимальное значение корреляции на текущий момент времени и
соответствующие ей значения
и
F
. Затем, после анализа последней ячейки, автомати-
чески становится известной ячейка, признанная истинной, поскольку ее координаты хра-
нятся в памяти, а процедура поиска завершается простым их считыванием. Данная страте-
гия, хотя и реализующая правило МП оценивания, производит необходимые вычисления
корреляций не одновременно, а последовательно во времени для следующих друг за дру-
гом сегментов принятого сигнала.
Более типичной для реальных приемников является другая версия последователь-
ного поиска, когда найденное в текущий момент значение корреляции только сравнивает-
ся с порогом [6, 9, 77]. Если значение корреляции превышает порог, то принимается ре-
шение, что текущая ячейка является истинной и поиск заканчивается. В противном случае
поисковая система анализирует следующую ячейку и так далее.
С точки зрения анализа выполнения неважно сколько параметров неизвестно и
должно быть оценено в ходе поиска: одновременно время и частота (или еще что-нибудь),
либо что-то одно из них. Существенным является только общее число анализируемых
ячеек. Для большей прозрачности дальнейших обсуждений будем полагать, что процедура
поиска заключается только в измерении временного запаздывания принятого сигнала, то-
гда как значение частоты а приори известно с достаточной точностью. На рис 8.2 пред-
ставлена структура устройства, осуществляющего последовательный поиск в рассматри-
ваемых условиях. В случае периодичности расширяющего кода максимальная область не-
определенности по времени может простираться только на один период, а все большие за-
держки приводятся к одному периоду. В свете этого совершенно оправдано использова-
ние термина «фазы» как синонима задержки периодического кода [2, 6, 9], а переход от
одной ячейки к следующей в области неопределенности означает просто изменение фазы
местной копии кода. Если текущее значение корреляции ниже порога, то управляющая
поиском логика предписывает местному генератору увеличить фазу кодовой копии
246
)( ts
на его выходе на один чип или часть чипа, а устройство переходит к анализу сле-
дующей ячейки. Если же текущая корреляция превышает порог, то логика управления
сигнализирует об окончании поиска, а генератор сохраняет фазу кода, отвечающую ячей-
ке, которая признана истинной. В следующих параграфах обсудим характеристики выше-
упомянутого алгоритма, базирующиеся на анализе, приведенном в [78], а читателя, заин-
тересованного в изучении подробностей, отсылаем к [6, 9, 77, 79-81].
8.2.2. Вероятность правильного завершения поиска и среднее число шагов.
Не нарушая общности, для упрощения анализа будем полагать, что местная копия
кода сдвинута относительно принятого сигнала на целое число длительностей чипа. Тогда
при периоде кода L всего возможно L значений фазы кода, одно из которых является ис-
тинным. В предположении различия всех фаз может существовать не более L ячеек поис-
ка, а каждый переход от одной ячейки к следующей означает увеличение фазы кода на
длительность одного чипа. В ходе поиска очень часто оказывается излишним анализ всех
этих L ячеек, поскольку благодаря достоверной априорной информации возможно сокра-
щение области поиска до M из общего числа L ячеек. Первоначально будем считать, что
поиск стартует с наименее благоприятной ячейки области неопределенности, т.е. с наибо-
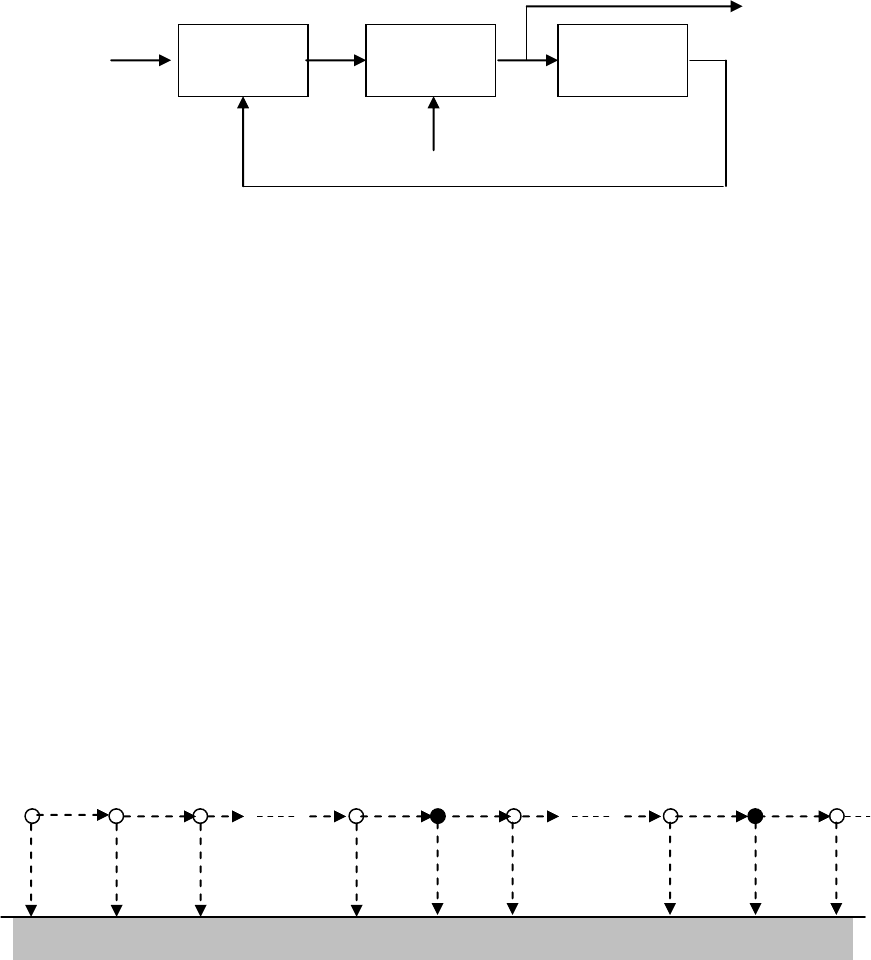
лее удаленной от истинной ячейки. Иллюстрацией данного предположения служит
рис. 8.3: первое достижение истинной ячейки (обозначенной закрашенным кружком) име-
ет место только после благополучного прохождения через
1M
пустых ячеек (отмечен-
ных не закрашенным кружком).
Для достижения надежного отличия между уровнями корреляции в пустой и ис-
тинной ячейках система поиска в каждой ячейке должна вычислять корреляцию на доста-
точном временном интервале: времени анализа (dwell time). При любом времени анализа и
пороге решения об истинности или пустоте ячейки не могут быть вынесены абсолютно
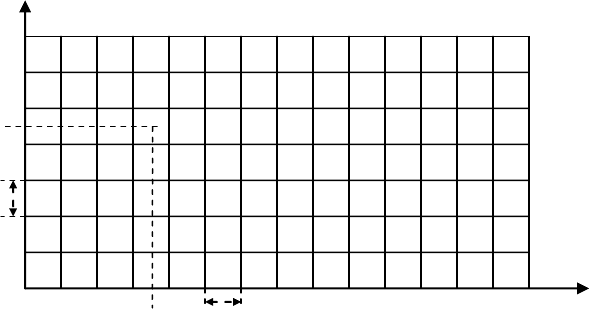
Коррелятор
Управляю-
щая логика
Порог
Генератор
кода
Рис. 8.2. Последовательный поиск фазы расширяющего кода.
)(ty
)( ts
Значение фазы
1
2
3
1M
M
1
1M
M
1
f
p1
f
p1
f
p1
f
p1
d
p1
d
p1
f
p
f
p
f
p
f
p
f
p
f
p
f
p
d
p
d
p
Конец
Рис. 8.3. Иллюстрация последовательного поиска кода в облас-
ти неопределенности из M ячеек.

247
безупречно. Одной из возможных ошибок является ложная тревога (см. параграф 3.2), т.е.
принятие пустой ячейки за истинную. В этом случае процедура поиска завершится в лож-
ном месте и совершенно естественно стремление удержать вероятность подобного собы-
тия на достаточно низком уровне. С другой стороны, с ненулевой вероятностью анализ в
истинной ячейке также может завершиться неправильным решением: пропуском сигнала
и переходом в следующую (пустую) ячейку, которая уже была проанализирована ранее.
Указанное событие делает процедуру поиска циклической: если поиск не заканчивается
при первом прохождении области неопределенности, то производится второе прохожде-
ние и т.д., причем каждый из последовательных повторов инициирует новый цикл. Далее
полагаем, что разыскиваемый сигнал постоянно присутствует на входе приемника, так что
число возможных циклов не ограничено сверху. Из рис. 8.3 следует, что если система по-
иска безошибочно доходит до истинной ячейки, то возможны два варианта выхода: при-
нятие правильного решения (и окончание поиска) с вероятностью обнаружения
d
p
или
пропуск сигнала с вероятностью
d
p1
. Последнее событие влечет за собой только про-
должение поиска на следующем цикле проверки и не имеет отрицательных последствий
кроме увеличения времени до момента завершения поиска. Анализ пустой ячейки также
может иметь два возможных исхода: правильное решение об отсутствии сигнала, сопро-
вождаемое переходом в следующую ячейку с вероятностью
f
p1
, или признание ее ис-
тинной с вероятностью ложной тревоги
f
p
. В отличие от пропуска сигнала последствия
от второй ошибки оказываются значительно катастрофичнее, поскольку неправильная фа-
за кода, найденная в результате поиска, означает, что все последующие операции, осуще-
ствляемые приемником, будут бесполезны. Для обеспечения низкой вероятности данного
события каждое решение о нахождении фазы кода, как правило, подвергается дополни-
тельной проверке за счет увеличения времени анализа в подозрительной ячейке (см. сле-
дующий параграф), но, тем не менее, вероятность окончания поиска неправильным реше-
нием остается ненулевой.
Назовем шагом поиска любой анализ в некоторой ячейке, завершающийся ре-
шением либо о продолжении, либо об окончании поиска. Из рис. 8.3 непосредственно
видно, что когда поиск начинается с ячейки номер один (наиболее удаленной от истин-
ной), он может окончиться в t–й ложной ячейке
)1,,2,1( Mt
после
tmM
шагов и в
истинной ячейке после
MmMmM )1(
шагов, где
,1,0m
– число полных «лиш-
них» поисковых циклов, т.е. проходов по всей области неопределенности, предшествую-
щих конечному
)му1( m
циклу, на котором поиск завершается либо в ложной, либо ис-
тинной ячейках. Тогда рассмотрение рис. 8.3, как диаграммы переходов, позволяет запи-
сать следующее выражение для вероятности
)(sp
окончания поиска после s шагов:
,,)1)(1()1(
,1,,2,1,,)1)(1()1(
)(
11
11
MmMspppp
MttmMspppp
sp
M
fd
M
fd
m
M
fd
t
ff
(8.1)
где
,1,0m
. Все события (и только они), вероятность которых определяется второй
строкой (8.1), подразумевают завершение поиска правильной оценкой фазы кода. Следо-
вательно, полная вероятность
1c
P
(индекс «1» указывает, что поиск стартует с первой
ячейки) правильного завершения поиска (правильного захвата) есть просто сумма всех
этих вероятностей по всем возможным значениям m, т.е. сумма геометрической прогрес-
сии с показателем
1
)1)(1(
M
fd
pp
:
.
)1)(1(1
)1(
)1)(1()1(
0
1
1
11
1
m
M
fd
M
fd
m
M
fd
M
fdc
pp
pp
ppppP
(8.2)