Yangsheng Xu, Yongsheng Ou. Control of Single Wheel Robots
Подождите немного. Документ загружается.

4.3
Le
arningC
on
trol
with
Limited
Tr
aining
Data
113
x
1
x
2
Y
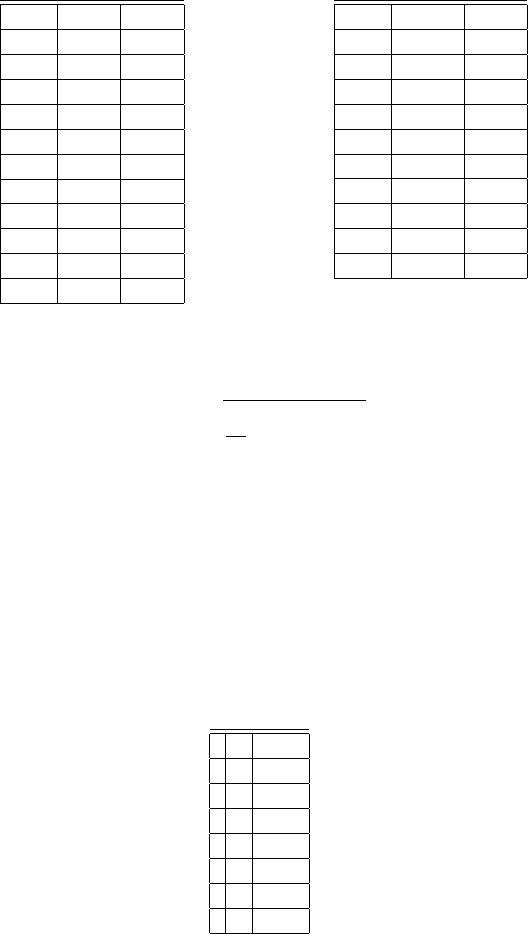
0.5104 -0.3080 0.4318
0.7315 -0.3574 0.1323
0.8938 -0.5146 -0.3163
0.8905 -0.7076 -0.6519
0.7373 -0.8340 -0.6232
0.4970 -0.9027 -0.3515
0.2674 -0.8584 -0.0114
0.1177 -0.6967 0.2528
0.1188 -0.5087 0.4345
0.2719 -0.3806 0.4863
0.4920 -0.3136 0.4233
Table 4.3. Thetraining data sample.
x
1
x
2
Y
0.6054 -0.3213 0.3026
0.8347 -0.4217 -0.0964
0.8986 -0.6179 -0.5057
0.8347 -0.7902 -0.7121
0.6292 -0.8833 -0.5097
0.3812 -0.87067 -0.1597
0.1696 -0.7727 0.1501
0.1028 -0.6044 0.3709
0.1631 -0.4242 0.5190
0.3692 -0.3139 0.5111
Table 4.4. Thetesting data sample
testingt
he network performance.Let
Y
i
be
an actualtest data outputand
ˆ
Y
i
be the correspondingneural network’soutput,
err =
1
n
1
n
1
i =1
( Y
i
−
ˆ
Y
i
)
2
. (4.101)
When the origin
n
o
=11training data forlearning, the result of err
o
is 0 . 1607.
Then,w
ep
roducedthe unlabelled trainingd
ata with MA
TLABfunction
“ spline ”using the origin n
o
=11trainingdatawith thescales k =2, 3 , 4 , 5 , 6 , 7
andsampling rate ∆
k
= ∆/k.Byremovingthe endtailmuchnoisy data,we
producedsix groups of unlabelled data, ( n
k
= k ( n
o
− 1)).Then, using the
unlabelled trainingdata to train theneural networks individually, theresults
of err
k
areshown in Table 4.5.
k n
k
err
k
2 20 0.0486
3 30 0.0461
4 40 0.0408
5 50 0.0316
6 60 0.0262
7 70 0.0267
9 90 0.1059
Table 4.5. Theresults of learning error with unlabelled training data.
As analysis in Section 4.3.1, with regardtoEquation(4.91),when n
k
increases, the mean-square error of learningdecreases. However, afterthe n
k
reached aspecific lever, here n
k
=70, thesecond term in Equation(4.91) did
114 4 Learning-based Control
dominate the total error, but not the first and third terms. Thus, the error
increased.
Experimental Study
The aim of this experiment is to illustrate how to use the proposed local
polynomial fitting interpolation re-sampling approach and verify it.
The control problem involves tracking Gyrover in a circular path with a
defined radius. A human expert controls Gyrover to track a fixed 1.5-meter
radius circular path and collect around 1,000 training samples with a sampling
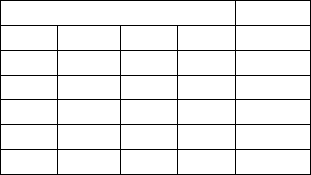
rate of 0 . 062s (62ms). Table 4.6 displays some raw sensor data from the human
expert control process.
Input Output
β
˙
β
β
a
˙α U
1
5.5034 0.9790 2.4023 0.8765 179.0000
5.7185 1.2744 2.3657 1.4478 176.0000
5.6012 -0.8374 2.1313 1.0767 170.0000
5.1271 0.6641 2.1460 0.6030 170.0000
5.9433 -0.4907 1.0425 1.3574 143.0000
Table 4.6. Sample human control data.
We
buildupanANN learningcontroller based on learningimparted from
expert human demonstrations. Here, the ANN is acascadeneural network
architecturewith node-decoupled extended Kalmanfilteringlearner (CNN),
whichc
ombines(
1) flexiblec
ascadeneural networks,whichd
ynamically ad-
just the size of thehidden neurons as part of thelearningprocess,and (2)
node-decoupledextended KalmanF
iltering(
NDEKF), afaster converging
alternative to quickpropalgorithms. This methodologyhas been proven to
efficiently modelhuman control skills [76].
Achievingthis goal requirestwo majorcontrol inputs: U
0
controlling the
rolling speed of thesingle wheel ˙γ ,and U
1
controlling the angular position
of thefl
ywheel
β
a
.For themanual-mode (i.e., controlled by ahuman), U
0
and U
1
areinput by joysticks, and in auto-mode they are derivedfromthe
software controller. During all experiments,wefixthe value of
U
0
.
Based on these original trainingsample data, the CNN learner exhibited
poor learning performance,and Gyroveralwaysfell down soon after an initial
running.Using this original learningcontroller,Gyroverisunable to track
acircular path. Subsequently,the human expert controlled Gyrovertotrack
the circular path two times andproducedaround 17,000 and18,000 training
samples respectively.Bycombining these two sets of data, the performance of
the CNN learner wasmoreeffectiveand the experiment wassuccessful.Thus,
4.3
Le
arningC
on
trol
with
Limited
Tr
aining
Data
115
thereasonfor thefailure initiallywas due to the limitednumberoftraining
samples.
In this work, we used the approach outlined abovetosolvethe small sam-
ple
pro
blemr
elying
on
th
efi
rst
seto
fo
riginalt
raining
s
ample
da
ta.
First,
we
carried
out
the
in
terp
olation
fo
rl
ean
angle
β with
regard
to
time
t using
a
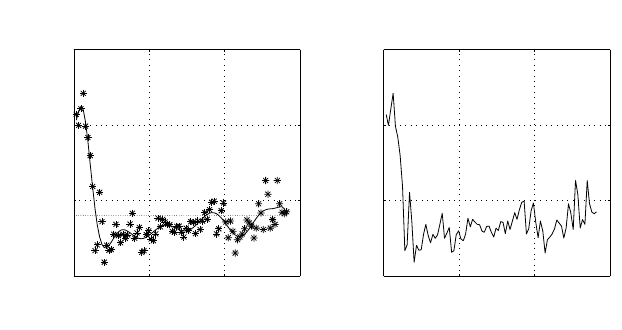
local polynomial fitting algorithm. In MATLAB,weused “ lpolyreg”tocollect
thepolynomial coefficients andthe bandwidth andthenused “ lpolyregh ”to
calculate the unlabelled trainingdata,
´
β .Figure 4.18 shows the localpolyno-
mialfitting for lean angle β .
0 2 4 6
50
100
150
200
β [deg]
time(sec)
Curve fitting of β [deg]
0 2 4 6
50
100
150
200
β [deg]
time(sec)
Original β [deg]
Fig. 4.18. Local po
lynomial fittingfor lean angle
β .
Second, we
pe
rformedt
he functionestimationfor (
˙
β, β
a
, ˙α, U
1
)asfor
lean angle β .Weproducedthe new unlabelled trainingsample by interpolation
with the newsampling rate of 0 . 0062s (6. 2 ms)and producedabout 10,000
piecesofunlabelled trainingsample data.
Third, by putting these 10,000 piecesofunlabelled sample data into anew
CNN learning model, we developed anew CNN-new neural network model.
We can, therefore, compare it with the old CNN model, CNN-old, whichis
producedbythe original single-set trainingdata. We use β and β
a
of another
set of human demonstrationtraining data as inputs to comparethe outputs
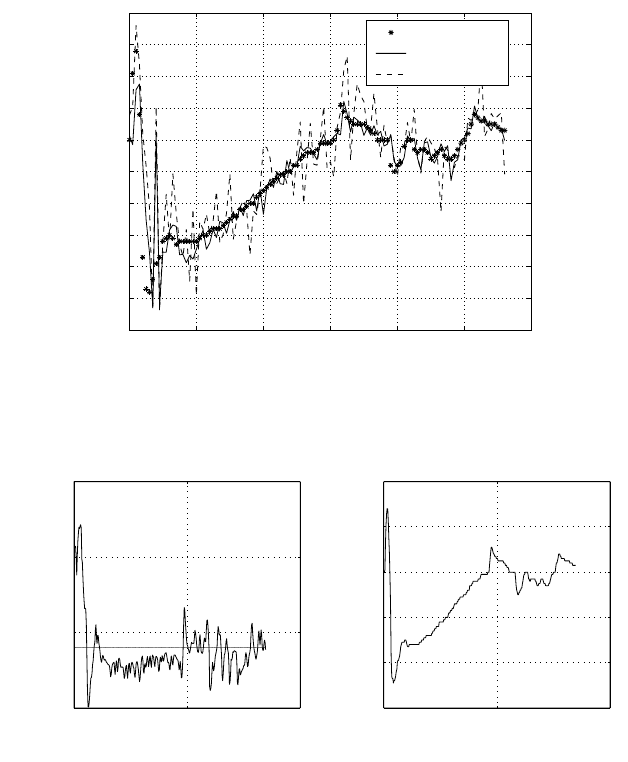
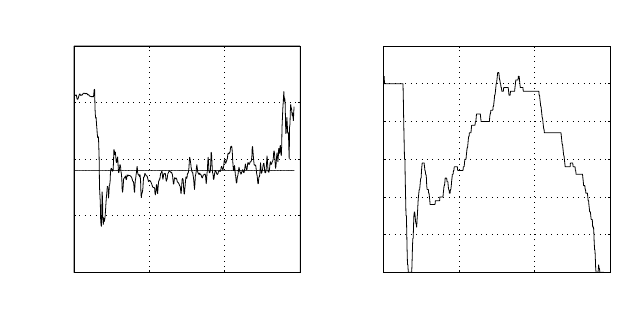
of thesetwo neuralnetwork models. Figure4.19 shows the comparison among
the human control, the CNN-new modellearningcontrol andthe CNN-old
model learningcontrol. As Figure4.19 demonstrates, the CNN-new model
hassmaller error variance than that of theCNN-old, i.e., it mayhavebetter
learning control performance.Practical experiments confirm this.
Subsequently,weuse the CNN-new modelasalearningcontroller to let
Gyrovertrack acircle automatically in real-time. This experimentwas also
116 4 Learning-based Control
0 0.02 0.04 0.06 0.08 0.1 0.12
120
130
140
150
160
170
180
190
200
210
220
Time (s)
U
1
Human
CNN−new
CNN−old
Fig. 4.19. Comparison of U
1
in as
et of testing data.
successful. Figures 4.20 and4
.21 show
thecontrol state va
riablesl
ean angle
β andcontrol command U
1
fora
set of
human and learning controls.
0 5 10
50
100
150
200
β [deg]
time(sec)
lean angle of Gyrover
0 5 10
120
140
160
180
200
220
Tilt Command
time(sec)
Control of flywheel
Fig. 4.20. Human control.
4.3
Le
arningC
on
trol
with
Limited
Tr
aining
Data
117
0 5 10 15
0
50
100
150
200
β [deg]
time(sec)
lean angle of Gyrover
0 5 10 15
130
140
150
160
170
180
190
Tilt Command
time(sec)
Control of flywheel
Fig. 4.21. The CNN-new model learning control.

5
Further Topics on Learning-based Control
5.1 Input Selection for Learning Human Control
Strategy
Modeling human control strategy (HCS) refers to a model of a human ex-
pert’s control action in response to system real-time feedback. That is, we aim
to develop a relationship between human control action (control commands)
and the system response (state variables).
The HCS model can be simply interpreted as a mapping function Φ such
that:
Φ : I −→ O , (5.1)
where I is the model input and O is the model output. Modeling HCS means
that the function Φ is derived by empirical input-output data. The major input
data are state variables and the output data are control variables. In order
to generate reliable models, we should not neglect some important factors,
such as previous control inputs. However, if we consider all of these as model
inputs, the dimension of the input space is too large and there is an excess
of highly redundant information. In fact, it is important that not all features
presented are taken into account. The following three types of undesirable
features should be discarded or neglected:
1. irrelevant features that do not affect the output in any way;
2. redundant features that are linearly related to or dependent on other
features;
3. weakly relevant features with only trivial influences on the model output.
Here, the input selection for this class of regression problems involves the
removal of irrelevant features, marginally relevant features and redundant
features, and selecting a group of the smallest self-contained subset of features
from the full set of features with respect to the learning output. This feature
selection is a process independent of any special neural network architecture
and the training process. Moreover, we assume that the full features already
Y. Xu and Y. Ou: Control of Single Wheel Robots, STAR 20, pp. 119–149, 2005.
© Springer-Verlag Berlin Heidelberg 2005
120 5 Further Topics on Learning-based Control
include all the necessary information to determine the learning output. It
means that the input selection process will not produce any new feature.
When using random sampling, or experimental designs, several factors can
be varied independently. Factors can be varied one-at-a-time (OAT) and all
the other factors can be held constant, at the same time. Modeling human
control strategy is not an OAT process. All the effective factors (system states
or parameters) are nonlinearly relevant to each other, i.e. if one of these factors
changes, then all the other key parameters will also change.
Different feature selection methods have been analyzed in the past. Based
on information theory, Battiti [9] proposed the application of mutual informa-
tion critera to evaluate a set of candidate features and to select an informative
subset to be used as input features for a neural network classifier. In [54], inter-
class and intraclass distances are used as the criterion for feature selection. A
method proposed by Thawonmas [105] performs an analysis of fuzzy regions.
All these approaches are suitable for classification problems. Here, modeling
human control strategy is a problem of regression. A large set of methods for
input selection are based on the analysis of a trained multilayer feedforward
neural net work or other specific network architectures in [17], [25], [69] and
[101]. Even though, in these methods, the subset features are optimal for their
special network architectures, it is possible they are not suitable or optimal
for some other network architectures. Our method, while producing similar
results in test cases, is applied before learning starts and therefore does not de-
pend on the learning process. In [85] different feature evaluation methods are
compared. In particular, the method based on principal component analysis
(PCA) evaluates features according to the projection of the largest eigenvector
of the correlation matrix on the initial dimensions. A major weakness of these
methods is that they are not invariant under a transformation of the variables.
Some nonlinear PCA approaches are examined in the literature [50]-[51]. In
fact, the process of building up a nonlinear PCA is similar to the training
process for a feedforward neural network. Another large class of methods are
called filter wrapper and a combination of them [19], [56] and [68]. These,
methods are focused on a searching strategy for the best subset features. The
selection criteria are similar to the above approaches. The searching strat-
egy is very import for classification problems with hundreds or thousands of
features. However, for regression problems there are usually fewer features.
Feature selection is one of the initial steps in the learning process. There-
fore, we propose to analyze through some relatively simple and efficient pro-
cesses, the search for the smallest subset of full features. This process of input
selection ensures that learned models are not over-parameterized and are able
to be generalized beyond the narrow training data. Our approach can be di-
vided into three subtasks:
1. significance analysis for the full features;
2. dependence analysis among a select set of features;
3. self-contained analysis between the select set of features and the learning
output.

5.1
Inpu
tS
election
for
Learning
Human
Con
trol
Strategy
121
5.1.1Sample Data Selection and Regrouping
Ourlearningcontrol problemcan be considered as buildingamap Φ be-
tween the system states X andthe controlinputs Y .Weassume both
X =[x
1
,x
2
,..., x
m
]and Y maybetime-variantvectors with continuous sec-
ondorder derivatives. Furthermore, without theloss of generality,werestrict
Y to be scalarfor thepurposes of simplifying the discussion.
Φ : Y = f ( X )=f ( x
1
,x
2
,.
..,
x
m
) . (5.2)
Here, we focusour attentiononthe estimation of regression function f .
Forafairlybroad class of sampling schemes t
i
,theyhavefixed andidentical
sampling
time
in
terv
al
s
δt
>
0(δt = t
i +1
− t
i
). We have asample data table,
whichincludes theobservation forbothinputs andoutputstotrain aneural
net
work as alearningcontroller.The data table is derivedfromadiscrete time
sampling fromhumanexpert control demonstrations. Atraining data point
T
j
=[X
o
j
,Y
o
j
](
j =1
,
2
,..., N )consistsofasystem state vector X
o
j
andt
he
control input Y
o
j
.Let
(
X
o
,Y
o
)b
ea
data pointfromthe sampled
ata table
and Y
o
be the observations fortrue Y and
Y
o
= Y + , (5.3)
where hast
he Gaussiandistribution with
E ( )=0an
dv
ar
ia
nc
e
σ
2
> 0. If
X
o
is the observation of
X ,
X
o
= X + ε, (5.4)
where ε ∈ R
m
.H
ere, we
assume each
system state
x
i
hasa
similar observation
erroras Y .The distribution of ε hasthe form N (0,σ
2
I
m
). X form the full
feature set. We will select thekey features from them with respect to the
learningoutput (orcontrol input) Y .For theinput selection, we needto
carefully select and collect the sample data into anumberofnew localgroups.
The sampled
ata table mayb
ep
roducedb
yone or
acombination of
sev
eral
human controlprocesses.Inthe ( m )dimension data space, according to the
distance D ,wecluster the data into asmall ball with radius r ( D<r ), as
showninFigure 5.1
D = ||X
i
− X
c
|| =
( x
1
i
− x
1
c
)
2
+(x
2
i
− x
2
c
)
2
+ ... +(x
m
i
− x
m
c
)
2
, (5.5)
where X
c
is the center data pointofthe ball (or data group).
In anygiven ball, even though the values of thedata arevery similar,
the first-order time derivatives of them maydiffer sufficiently.This is because
the near data points maycome fromdifferentcontrol processes or different
paragraphs in the same control process.The selectioncriteriafor adata point
T
j
areasfollows.

1225
Fu
rther
To
pics
on
Learning-based
Con
trol
r
Fig. 5.1. Clustering the dataintoasmall ball with radius r .
1. If we define η as thesignal to noise ratio andfor anyselect data point
X
j
=[x
1
j
,x
2
j
,...x
m
j
],
δx
i
j
= x
i
( j +1) − x
i
( j ) , (5.6)
|
δx
i
j
δt
| >ησ/δt, ∀ i =1, 2 ,..., m, (5.7)
where η =1forsignificance analysis and η =10for dependentanalysis
and σ is the variance of noise defined in Equation (5.3).
2. Fo
re
achd
ata group(or ball), let
¯
N
k
be th
en
um
bero
ft
he
k
th
data group,
¯
N
k
oughttobelarger than
¯
N ,where
¯
N = max{ 20, 2 m } . (5.8)
3. Ther
adius
r of
th
ebal
ls
ma
ybedefi
ne
das
r =
√
m
√
ηξ
, (5.9)
where
ξ = max{|
∂
2
f
∂x
i
,∂x
j
/
∂f
∂x
i
|} ∀ i, j =1, 2 ,..., m.
Next, the regrouping strategy is as follows.
1. Remove the data points that do notsatisfycondition1andreorder the
data points.
2. Select the firstdata point
T
1
as thecenter of thefirst data group.
3. Calculatethe distance
D
1
between the next data pointwith the center
of thefirst data group. If D
1
≤ r ,the data pointisset to the firstdata
group.
4. If D
1
>r,calculate the distance
D
2
between this data pointwith the
center of thesecond data group. If
D
2
≤ r ,the data pointisset to the
second data group. If D
2
>r,this data pointwill be tested with the third
5.1
Inpu
tS
election
for
Learning
Human
Con
trol
Strategy
123
group.Ifthis data pointcan notbeset into anygroup, it will be set as
the center of anew data group.
5. Repeat thelast step, until alldata points have been set into agroup.
6.
Remo
ve
the
da
ta
gr
oups
where
th
en
um
be
r
of
data
po
in
ts
is
less
than
¯
N
andr
eorder
the
gr
oupn
um
be
r.
Here, we assume the data is large enough in the sense of this regrouping
process.Finally,weobtain k balls(or k groups) of sample data, whichsatisfy
the aboveconditions.
5.1.2 Significance Analysis
We define I ( x
i
)asthe significance value of x
i
in respect to Y ,given that
i =1, 2 ,..., m andif I ( x
i
) >I( x
j
), x
i
is
more
imp
or
tan
tt
han
x
j
.
Here, forthe significance analysis, we mainly focus on significance prob-
lems: i.e., what is the importantorder of themodel parameters x
i
, i =1, 2 ,...m
in respect to
Y .
LocalSensitivityAnalysis
Localsensitivityanalysis(Local SA)concentratesonthe local impact of the
factorso
nt
he model.Local SA
is
usually carried out by
computing partial
derivatives numerically.Local SA is especially suitable for human learning
control
strategy,
because the
time interval of data sampling is
the
same for
all thevariables. Our global significantorder is derivedfromthe cumulation
effectofthe local sensitivityanalysisprocess.The sensitivity coefficient
∂Y
∂x
i
is an evaluationofhow parameter x
i
affectsthe variable Y .Inthe followings
steps, we
will address ho
wtoestimate this.
First, with regardtodealing with the local SA,since in each groupthe data
arevery near to eachother,wetransform ournonlinearmapping Equation
(5.2) in
to
an
almost linearo
ne througha
first-order Ta
ylor series expansion:
dY =
∂f
∂x
1
dx
1
+
∂f
∂x
2
dx
2
+ ... +
∂f
∂x
m
dx
m
+ o ( ||dX||) . (5.10)
X is not the same in eachdata group, but the difference is very small.
Let’s consider the effect of this on the almost linear relation. Let
¯
X be the
center data pointofthis data group. The first-order Taylor series expansion
of thecoefficientof dx
i
is
∂f
∂x
i
=
∂f
∂x
i
X =
¯
X
+
∂
2
f
∂x
1
∂x
i
X =
¯
X
( x
1
− ¯x
1
)+...
+
∂f
∂x
m
∂x
i
X =
¯
X
( x
m
− ¯x
m
)+o ( ||( X −
¯
X ||) .
(5.11)
Set