Russ J.C. Image Analysis of Food Microstructure
Подождите немного. Документ загружается.


As shown in Chapter 4, the skeleton of each feature has end points with a single
neighbor, and nodes points with three or four neighbors, which can easily be counted
to determine the basic topology. Euler’s relationship ties these together:
Number of loops =
Number of Segments – Number of Ends – Number of Nodes + 1 (5.4)
People extract these basic properties — especially the number of end points and
the number of loops or holes in the feature — automatically and quickly by visual
inspection. Computer measurement using the skeleton is nearly as fast.
In addition to the purely topological shape properties, the skeleton is used by
itself and with the Euclidean distance map to determine other properties such as the
mean length and width of segments, both the terminal and interior branches. Figures
4.41 and 4.42 in Chapter 4 showed examples of classification of features based on
their topological parameters as measured by the skeleton.
Many natural objects have boundaries that are best described by fractal rather
than Euclidean geometry. A formal definition of such a boundary is that the observed
length of the perimeter increases with magnification so that a plot of the length of
the total measured perimeter vs. the image resolution is linear on log-log axes. More
practically, features are considered fractal if the apparent roughness stays the same as
magnification is increased, at least over some finite range of scales (usually several
orders of magnitude). This self-similar geometry arises from many physical processes
FIGURE 5.45 A selection of shapes with the same numerical value of formfactor.
2241_C05.fm Page 347 Thursday, April 28, 2005 10:30 AM
Copyright © 2005 CRC Press LLC

such as fracture and agglomeration, but is certainly not universal. Features for which
a single force such as surface tension or a bounding membrane dominates the shape
will have a Euclidean boundary that is smooth and does not exhibit an increase in
perimeter with magnification.
Examples of fractal surfaces and clusters were shown, along with procedures
for measuring their dimension, in Chapter 3 (Figure 3.33) and Chapter 4 (Figure
4.42). Measurement of the boundary fractal dimension of features can be performed
in several ways, which do not necessarily produce exact numerical agreement. The
most robust method uses the Euclidean distance map to determine the number of
pixels (both inside and outside the feature) as a function of their distance from the
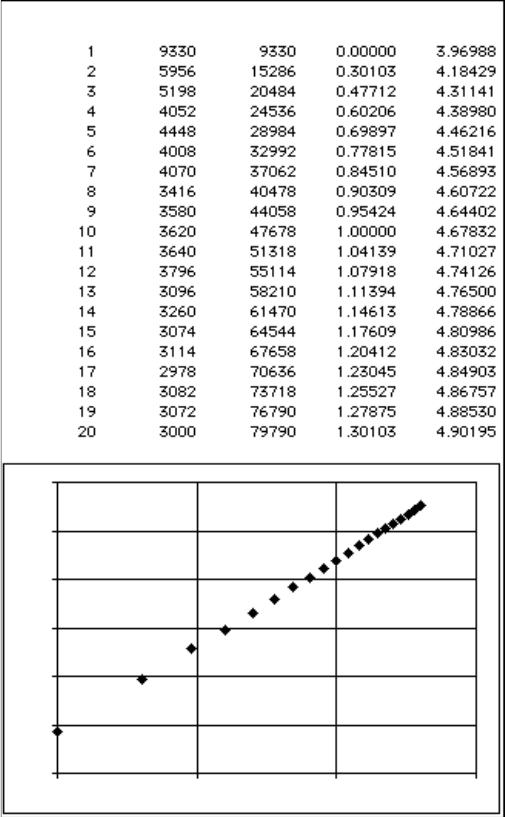
boundary. As shown in Figure 5.46(b), the slope of a log-log plot of the number of
pixels vs. distance from the boundary gives the dimension, which varies from 1.0
(for a perfectly Euclidean feature) upwards. Typically rough boundaries often have
dimensions in the range from 1.05 to 1.4; a few representative examples are shown
in Figure 5.47.
There are other approaches to shape measurement as well. One that is rarely
used but extremely powerful is harmonic analysis. The boundary of each feature is
(a)
FIGURE 5.46 Fractal dimension measurement using the EDM: (a) the EDM of pixels inside
and outside the classic Koch snowflake; (b) a table of the number of pixels as a function of
their EDM value, and the constructed cumulative plot whose slope gives the fractal dimension.
2241_C05.fm Page 348 Thursday, April 28, 2005 10:30 AM
Copyright © 2005 CRC Press LLC
unrolled into a plot of direction vs. position, and Fourier analysis is performed on
the plot (which of course repeats every time a circuit of the boundary is completed).
The amplitude of the Fourier components provides a series of numbers that com-
pletely define the shape. In most cases only the first few dozen coefficients are
significant (although for a truly fractal shape that would not be the case), and these
numbers can be used in statistical analysis routines that search for discrimination
between groups or underlying identities in complex mixtures.
(b)
FIGURE 5.46 (continued)
EDM Value Pixel Count Cumulative Log(R) Log(A)
Minowski Sausage Method
Fractal Dimension = 2 – slope = 1.28257
3.80
4.00
4.20
4.40
4.60
4.80
5.00
0.00 0.50 1.00 1.50
2241_C05.fm Page 349 Thursday, April 28, 2005 10:30 AM
Copyright © 2005 CRC Press LLC

The harmonic analysis method is used primarily in sedimentology, to classify
particle shapes, but has been used occasionally on food products, for instance to
identify different species of wheat kernels. The two principal reasons that it is not
used more are: a) a significant amount of computation is required for each feature;
and b) the list of numbers for each feature represent the shape in a mathematical
sense, but are very difficult for a human to understand or decipher. To the author’s
knowledge, none of the image analysis programs that run on small computers include
this function at the present time.
IDENTIFICATION
One goal of feature measurement is to make possible the automatic recognition
or classification of objects. The cross-correlation method shown in Chapter 3 (Fig-
ures 3.41 and 3.42) can locate features in an image that match a specific target, but
requires an image of the target that must be closely matched in shape, size, color
and orientation. Consequently, while it can be a very powerful method for seeing
through clutter and camouflage, it is not a generally preferred method for classifi-
cation. Most techniques for feature identification start with the list of measurement
parameter values rather than the image pixels.
FIGURE 5.47 Several representative natural shapes (and one smooth ellipsoid) with the
measured fractal dimensions for each.
2241_C05.fm Page 350 Thursday, April 28, 2005 10:30 AM
Copyright © 2005 CRC Press LLC
There are many different techniques used. Most require prior training with data
from representative examples of each class of objects, although there are methods
that can find clusters of parameter values that indicate the presence of multiple
classes, as well as methods that start with a few examples and continue to learn as
more objects are encountered. There are many texts just on the various recognition
and classification techniques, which are heavily statistical. Good introductions that
cover a variety of methods include S.-T. Bow, Pattern Recognition and Image
Preprocessing (Marcel Dekker, New York, 1992) and K. Fukunaga, Introduction to
Statistical Pattern Recognition (Academic Press, Boston, 1990).
It is not the intent of this text to delve deeply into the relative merits of expert
systems, fuzzy logic and neural nets, syntactical description, or kNN (nearest neigh-
bor) methods. The following illustrations are basically implementations of a classic
expert system but have some of the characteristics of fuzzy logic due to the use of
histograms of feature parameters. Figure 5.48 shows a simple example, a collection
of the letters A through E in different fonts, sizes and orientations. A set of four
rules are shown connected in an expert system that identifies all of the letters.
This is a very sparse example of an expert system; most have hundreds or
thousands of rules, and the task of the software is to find a logical connection path
and efficient order of application that will result in paths from input values to output
identification. But even this simple example indicates one of the limitations of the
method: the difficulty of adding additional classes. If the letter “F” is added to the
image, new rules are needed, some of the existing ones may be discarded, and the
order of application may change completely.
Also, it is important to remember that the expert in an expert system is the
human who generates the rules. These are typically based on experience with or
measurement of many prototypical examples of each class (a training set). For
instance, the rule shown for distinguishing the letters A and D is based on roundness.
Figure 5.49 shows a histogram of the roundness values for the various A and D
letters in the original image, showing that they are completely separated and indi-
cating where a decision threshold can be placed between the two groups.
It is unusual to find a single parameter that completely separates the classes.
One approach to dealing with this is to use statistical techniques such as stepwise
regression or principal components analysis to find a combination of parameters that
provide the separation. Instead of roundness, the horizontal axis for the histogram
might be a combination of several measurement values, each multiplied by appro-
priate coefficients. Neural networks operate in a similar way, finding the weights
(coefficients) that describe the importance of each input variable.
Another way to improve the separation of classes is to work with multiple
parameters in a two-, three- or higher dimension space. For example, consider the
task of separating cherries, lemons, apples, and grapefruit. Size clearly has a role,
but by itself size is not sufficient for complete discrimination. Some lemons are
larger than some apples, and some apples are larger than some grapefruit. Color is
also a useful parameter. Cherries and apples are red, while lemons and grapefruit
are yellow. But again there is overlap. Some grapefruit are pink colored and some
apples (e.g., Golden Delicious) are yellow. Figure 5.50 shows a schematic approach
to using both the redness of the color and the size of the fruit to separate the classes.
2241_C05.fm Page 351 Thursday, April 28, 2005 10:30 AM
Copyright © 2005 CRC Press LLC

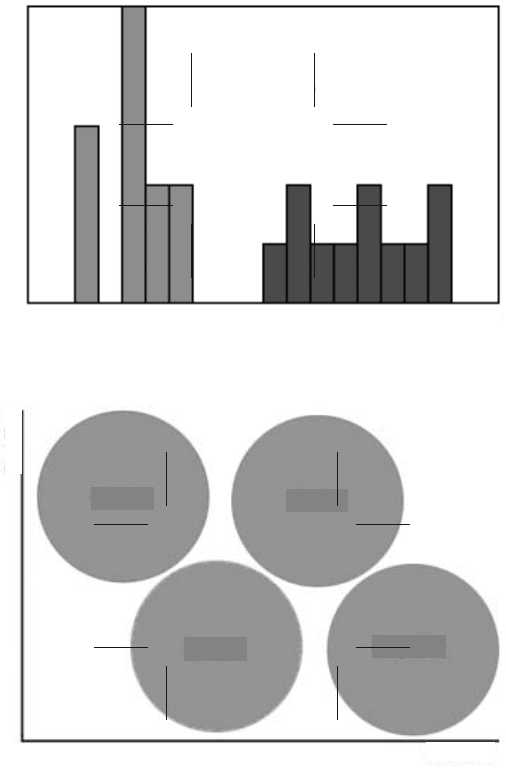
Obviously, this method can be extended to more than two dimensions, although
it becomes more difficult to represent the relationships graphically. Figure 5.51
shows a schematic example of a three-dimensional case in which classes are repre-
sented by boxes that correspond to ranges of size, shape and density parameters.
Several parameters for each of these may be needed, especially for shape since as
noted previously the various shape descriptors emphasize somewhat different aspects
of feature shape.
(a)
(b)
FIGURE 5.48 Expert system identification of features: (a) collection of letters A through E
in various fonts, sizes and orientations; (b) rules that will successfully identify each feature.
Holes = 2?
Holes = 1?
Roundness>0.4?
YN
Aspect
Ratio>1.32?
D
AEC
B
YN
Y
NY
N
2241_C05.fm Page 352 Thursday, April 28, 2005 10:30 AM
Copyright © 2005 CRC Press LLC
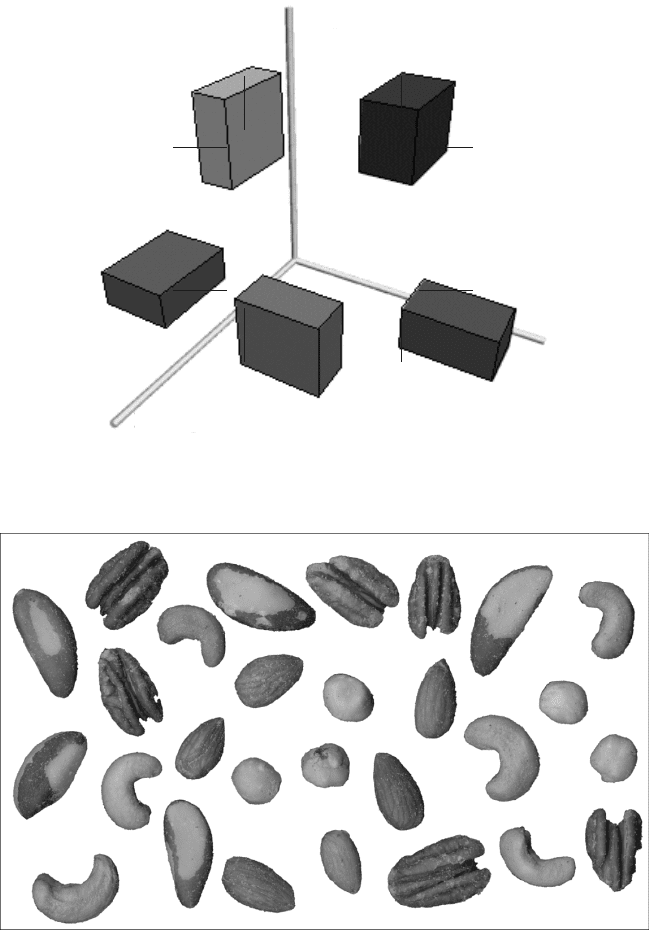
As an example of this type of classification, Figure 5.52 shows an image of
mixed nuts from a can. There are known to be five types of nuts present. Many size
and shape parameters can be measured, but which ones are useful? That question
can be difficult for a human to answer. The plots in Figure 5.53 show that no single
parameter can separate all of the classes, but also that each of the parameters shown
has the ability to separate some of them. Determining which combination to use
generally requires the use of statistical analysis programs that use regression to
isolate the most important parameters.
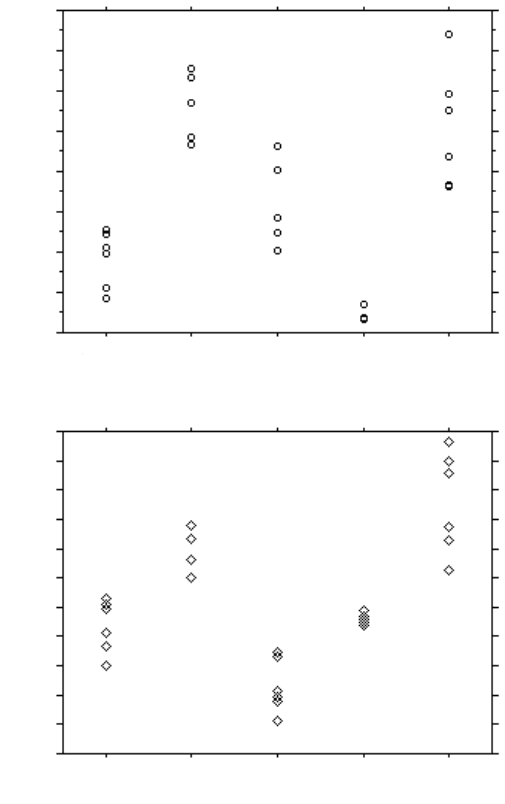
Figure 5.54 shows a scatterplot of the measurements of two parameters, the
inscribed radius (a measure of size) and the radius ratio (the ratio of the inscribed radius
to the circumscribed radius, a measure of shape). In this plot the five types of nuts are
FIGURE 5.49 Histogram of roundness values for letters A and D.
FIGURE 5.50 Schematic diagram for parameters that separate fruit into classes.
0.30 0.60Roundness
0
5
Count
To tal=23
"A"
"D"
Diameter
Red Hue
Cherries
Apples
Lemons
Grapefruit
2241_C05.fm Page 353 Thursday, April 28, 2005 10:30 AM
Copyright © 2005 CRC Press LLC
completely separated. Figure 5.55 shows a very simple example of how numerical limits
could be established for these two parameters that would identify each of the nuts.
There is always a concern about how representative the measurements on a small
sample of objects used for training are of the larger population that will be classified.
FIGURE 5.51 Separating classes in multiple dimensions.
FIGURE 5.52 (See color insert following page 150.) Image of nuts used for recognition.
Density
Shape
Size
2241_C05.fm Page 354 Thursday, April 28, 2005 10:30 AM
Copyright © 2005 CRC Press LLC
Given a larger training population, better values for the discrimination thresholds
would be determined, and it is possible that other parameters might be used as well
to provide a more robust classification, but the principles shown do not change.
Some systems are programmed to continue to learn, by adjusting the decision
boundaries as more objects are encountered and the populations of each class become
better defined.
The example in Figure 5.51 assumes that all objects examined will belong to
one of the five classes of nuts for which the system is trained. A somewhat different
(a)
(b)
FIGURE 5.53 Plots of measured values sorted by type of nut: (a) area; (b) inscribed radius;
(c) roundness; (d) formfactor.
almond brazil cashew filbert walnut
Class
1.5
2
2.5
3
3.5
4
4.5
5
5.5
Area(cm
^2)
almond brazil cashew filbert walnut
Class
.45
.5
.55
.6
.65
.7
.75
.8
.85
Inscrib.Rad.(cm)
.9
.95
1
2241_C05.fm Page 355 Thursday, April 28, 2005 10:30 AM
Copyright © 2005 CRC Press LLC

approach using fuzzy logic with the same data is shown in Figure 5.56. The mean
and standard deviation of the measured values from the training set define the ellipses
that represent 95% probability limits for each class. A measured object that falls
inside one of the ellipses would be identified as belonging to it. An object whose
measured values fall outside the ellipses would be labeled as unclassified, but could
be identified as most probably belonging to the nearest class, and the probability of
that identification reported.
(c)
(d)
FIGURE 5.53 (continued)
almond brazil cashew filbert walnut
Class
.3
.4
.5
.6
.7
.8
.9
Roundness
almond brazil cashew filbert walnut
Class
.5
.55
.6
.65
.7
.75
.8
.85
.9
FormFactor
2241_C05.fm Page 356 Thursday, April 28, 2005 10:30 AM
Copyright © 2005 CRC Press LLC