Спивак Д.Л. (отв. ред.) Фундаментальные проблемы культурологии : В 4 т. Том IV: Культурная политика
Подождите немного. Документ загружается.


Л. Н. Беляева 100
технологий, для которых глобальный английский язык является основным носителем ин-
формации;
выявление тех аспектов английского языка, которые вызывают особые сложности при ге-•
нерировании текста (в частности, научного) и модификация и/или уточнение учебных
программ, которые должны обеспечить знание языка, позволяющее сделать мобильность
студентов, преподавателей и ученых реальностью.
Таким образом, при исследовании особенностей глобального английского языка необ-
ходим аппарат, позволяющий разделить универсальные и специфические характеристики
изучаемого лингвистического объекта. Проведение исследования требует предварительного
сбора и организации материала таким образом, чтобы сопоставление было объективно и до-
стоверно, поскольку результат любого исследования зависит от того, как организована вы-
борка, насколько она однородна и представительна по отношению к исследуемым явлениям,
насколько и по каким параметрам сопоставим материал.
Одним из современных методов анализа, применение которых к подобному объекту мо-
жет быть и оправданным, и целесообразным, является создание и исследование корпуса па-
раллельных текстов, жестко ограниченных тематикой, структурой и объемом, но различа-
ющихся родными языками их авторов и, как следствие, ракурсами описания одного и того
же жестко заданного явления. При этом отличия на лексическом и синтаксическом уровне
должны определяться не различиями в теме текста, а различиями когнитивными и ситуа-
ционными.
Условию сопоставимости темы, объема, цели, синхронного среза и жанра текста соответс-
твуют материалы международных конференций и семинаров по конкретным научным про-
блемам. Такие материалы, как правило, посвящены достаточно узким проблемам, что задает
общность отражаемой языком предметной области, тезауруса, той экстралингвистической
реальности, знание которой составляет профессиональную компетенцию участников и ав-
торов текстов. Кроме того, удобству их использования служит то, что материалы выпуска-
ются в электронном виде.
Поскольку такие материалы как правило не редактируются, то подобные корпусы текстов
отражают реальное владение их авторами английским языком и терминологией конкретной
предметной области. Следует, к сожалению, отметить, что в материалах конференций толь-
ко у российских участников нет (как правило) достаточной компетенции в области англий-
ского языка, поэтому они прибегают к услугам переводчиков, в результате чего возникают
ошибки на лексическом уровне (ср., например вариант own frequency для термина собствен-
ная частота). Другие специалисты свои тексты создают сами, и поэтому они являются ис-
точником информации об интерференции родного языка.
На основе корпуса псевдопараллельных текстов может быть, в частности, проведен анализ
номинации экстралингвистических объектов и особенностей терминообразования (струк-
туры именных терминологических сочетаний) в условиях разных родных языков. Особенно-
сти номинации одних и тех же референтов в текстах носителей разных языков отражаются
в вариантах структур именных терминологических сочетаний в этих языках. При этом сле-
дует иметь в виду, что построение лексического спектра глобального английского языка дает
возможность проанализировать не только особенности использования лексических единиц

Глобальный английский язык как отражение лингвистического и когнитивного своеобразия 101
(ЛЕ) — слов и словосочетаний в текстах, написанных носителями разных языков, но и вы-
явить особенности когниции, свойственные «усредненному» носителю конкретного языка и,
как следствие, конкретной культуры.
Для определения методики построения подобного корпуса и установления возмож-
ностей его использования для лингвистического, культурологического и когнитивного
анализа проведен специальный эксперимент. В рамках эксперимента для создания кор-
пуса параллельных текстов были использованы материалы симпозиума «International
Symposium on Seismic Evaluation of Existing Nuclear Facilities» (Vienna, Austria 25–29 August
2003 IAEA-CN-106), и отчет МАГАТЭ «Seismic Evaluation of Existing Nuclear Power Plants»
(Vienna, Austria, 2003), подготовленный международной группой экспертов специально к
этому симпозиуму. Весь корпус текстов посвящен проблеме выбора методов и параметров
оценки сейсмостойкости объектов повышенного риска (атомных электростанций), все тек-
сты (кроме отчета) написаны по заданной организаторами жесткой схеме и имеют сопос-
тавимый объем.
В результате было сформировано 6 корпусов текстов, которые можно считать псевдопа-
раллельными: это корпуса текстов на «подлинном» английском языке (авторы из Великобри-
тании, США, Канады и Новой Зеландии), на «японском», «французском» (авторы из Франции
и Алжира), «славянском» (авторы из Словении, Чехии, Македонии, Болгарии), «индийском»
(авторы из Индии, Бангладеш и Пакистана), а также «русском» английском языке. Кроме то-
го, отдельный объект (седьмой корпус) был представлен сводным отчетом МАГАТЭ (авторы
из Болгарии, Венгрии, Франции, России, США и Индии). Естественно, проведение полномас-
штабного исследования глобального английского языка в дальнейшем потребует более жес-
ткой «привязки» к различным «родным» языкам авторов и планируется.
Все 7 корпусов текстов были предварительно размечены (в них вручную выделялись про-
стые именные группы) и обработаны с использование средств компьютерного анализа текс-
та. В результате для 7 корпусов были получены алфавитные словари слов и именных слово-
сочетаний по каждому из вариантов глобального английского языка, которые объединены
в сводный распределительный алфавитный словарь с отражением частоты ЛЕ в каждом из
корпусов. Кроме того, получены сводный словарь именных словосочетаний с указанием дли-
ны словосочетания (количество компонентов — отдельно оформленных лексических еди-
ниц), сводной частоты и степени распространенности и словарь моделей именных словосо-
четаний с теми же характеристиками.
Анализ материалов распределительного словаря может вестись по ряду параметров, как
собственно лингвистических, так и культурологических. В качестве культурологических
параметров рассмотрим использование в текстах таких реалий как календарные единицы
(Таблица 1) и географические названия (Таблица 2).
Из приведенной Табл. 1 следует, что в текстах российских авторов нет привязки к времени
проведения исследований с точностью до месяца, столь же незначительна эта привязка для
авторов из различных западно- и южно-славянских государств (Чехии, Словении, Болгарии
и т. д.) и Индии. Большие частоты этих лексических единиц в сводном тексте связаны с тем,
что этот текст представляет собой заключительный отчет по договору с МАГАТЭ, в котором
привязка данных по времени является обязательной.

Л. Н. Беляева 102
Таблица 1. Календарные единицы в текстах разных носителей языков
Лексичес-
кие
единицы
Частота в корпусе
Суммарная Славянские Русский Японский Французский США Индия Сводный
January 9 1 2 2 4
February 6 2 4
March 10 2 2 2 4
April 16 1 5 1 9
May-August 1 1
June 52 3 2 3 44
July 7 1 2 4
August 20 16 1 3
Sept 1 1
September 16 1 3 4 8
Oct 2 1 1
October 38 1 4 2 31
Nov 1 1
November 15 1 1 4 2 7
Dec 5 5
December 26 1 1 3 21
Итого 5 0 7 17 44 4 126
Рассмотрим далее в качестве культурологических параметров использование таких реа-
лий как географические названия (Табл.2).
Таблица 2. Страны и регионы в текстах носителей разных языков
Лексичес-
кие
единицы
Частота в корпусе
Суммарная Славян-
ские
Русский Японский Француз-
ский
Англий-
ский
Индий-
ский
Сводный
America 9 1 1 4 1 2
Argentina 1 1
Armenia 41 3 1 28 9
Australia 13 15
Austria 6 1 5
Bangladesh 16 16
Belgium 4 1 3
Bulgaria 41 11 2 1 27
Canada 8 1 4 2 1
China 1 1
Czech
republic
17 9 8

Глобальный английский язык как отражение лингвистического и когнитивного своеобразия 103
Europe 53 12 1 15 2 8 15
France 59 1 1 57
Germany 1 1
Hungary 10 1 9
India 20 1 19
Iran 1 1
Italy 12 2 3 3 4
Japan 52 1 23 12 4 12
Korea 3 1 1 1
Luxemburg 2 1
Macedonia 5 1 4
New
Zealand
5 5
North
America
3 2 1
Pacic 6 3 2 1
Pakistan 1 1
Portugal 1 1
Romania 18 2 1 1 14
Russia 74 59 1 1 23
Slovakia 8 1 1 6
Slovenia 7 7
Spain 2 1 1
Switzerland 2 2
Taiwan 11 1 10
Turke y 35 3 22
UK (United
Kingdom)
20 1 15 1 3
Ukraine 2 1 1
United
States (US,
USA)
72 3 4 14 18 15 18
USSR
(Soviet
Union)
4 1 1 2
Анализ таблицы показывает, что в японских материалах упоминаются только две страны:
сама Япония и Корея, а также территория Тихого Океана, остальные страны и регионы не
упоминаются вообще. Если не учитывать материалы сводного отчета, в котором наблюдает-
ся особое перечисление и анализ регионов мира, в которых расположены атомные электро-
станции или есть реальная опасность землетрясений, то чаще всего в материалах упомина-
ются США, Россия, Франция, Япония, Армения, Болгария, Румыния и в целом Европа.
В культурологическом отношении подобные данные позволяют ранжировать регионы ми-
ра по степени сейсмической опасности для имеющихся на их территории атомных электро-
станций.

Л. Н. Беляева 104
Анализ полученных словарей показал очень большую вариативность лексики даже
при жестко ограниченной оценкой сейсмостойкости существующих атомных электро-
станций тематике: без учета строевой лексики в распределительном словаре зафиксиро-
вано 15667 разных слов и словосочетаний, из которых только 23 слова, 4 словосочетания
(nite(-) element(s), ground motion(s), reactor building, time(-)history(ies)), различающиеся
написанием слитно или через дефис, и 1 аббревиатура (NPP(s)), встречаются во всех 7
корпусах.
Эти лексические единицы характеризуют принятые всеми базовые объекты и методы ана-
лиза, все остальные номинации объектов, методов и параметров либо вариативны, либо за-
висят от оценки важности ситуации, принятой в конкретной стране. Вариативность номи-
нации определяется структурой термина, принятого в родном языке автора, и особенностью
фокуса номинации. Так, например, слово asperity используется в сочетании со словами area,
location и model в «японском» английском и в сочетании со словом region в подлинно англий-
ских текстах, в других вариантах английского языка это слово не встретилось. Следует от-
метить разницу в частоте этого слова: при сопоставимости объемов текстов частота asperity
в текстах на «японском» английском почти в 6 раз выше. В том же значении в текстах «фран-
цузского» английского языка встречается слово irregularity, в других текстах эта тема не об-
суждается.
Таблица 3. Частоты слов asperity и irregularity в текстах материалов
Лексические единицы Частота
Славян-
ские
Русский Японский Француз-
ский
Англий-
ский
Индия Сводный
ASPERITY(IES) 23 4
asperities 6 2
asperity 8
asperity area 1
asperity locations 1
asperity region 1
closest asperity 2
dynamic asperity model 1
non-asperity 3
non-asperity area 1
o-asperity 1
IRREGULARITY((IES) 8
irregular 1
irregularities 3
stated irregularities 1
substantial vertical
irregularity
1
torsional irregularity 1
typical structure-in-
structure irregularity
1

Глобальный английский язык как отражение лингвистического и когнитивного своеобразия 105
Именные словосочетания (именные группы) представляют собой особый случай номина-
ции. Такие группы функционально равны слову, но в то же время они представляют сверт-
ку предложения, т. е. являются скорее элементами синтаксиса, а не словаря. Таким образом,
можно предположить, что внутренняя структура именной группы коррелирует с внутрен-
ней структурой зависимостей соответствующего предложения, сверткой которого она яв-
ляется. В научном тексте простые именные группы являются многокомпонентными струк-
турами с большим количеством атрибутивных элементов в препозиции к ядру именной
группы (ИГ). Являясь зависимыми членами предложения, эти группы формируют одну син-
таксическую группу с ядром, синтаксическая функция которого совпадает с синтаксической
функцией группы в целом.
Именная группа выступает, таким образом, в функции расчлененной номинации и поэто-
му выполняет две функции: номинативную (или функцию называния), а также дефинитив-
ную (или функцию выражения специального понятия. В терминоведении предполагается,
что формой существования понятия является дефиниция, которая «свертывается» до тер-
мина. Тем самым терминологическое сочетание замещает дефиницию, состоящую в экспли-
цитном или имплицитном виде из целого ряда высказываний.
Поскольку ИГ всегда представляет собой именно свертку, некое стяжение структуры вы-
сказывания, то это внешнее упрощение конструкции и формы вызывает ее семантическое
усложнение: показатели наличия связи между конкретными компонентами и типов свя-
зи между компонентами, которые в предложение вводятся с помощью коннекторов и реля-
торов разного уровня, в английской именной группе сняты. Следовательно, основной про-
блемой при переводе именного терминологического словосочетания является установление
структуры и типа связей между его компонентами.
При анализе ИГ в научном или научно-техническом тексте важен ее денотативный или ре-
ференциальный статус, то есть заданная ситуацией определенность объекта в речевом акте
и для автора, и для реципиента. Эта определенность внеязыкового объекта является основой
понимания научного текста специалистами в конкретной области, необходимым условием
такого понимания. При коммуникации на одном языке и, более того, при коммуникации в
рамках одной предметной области, одного профессионального жаргона, возможность адек-
ватного распознавания номинируемых объектов поддерживается совпадением тезаурусов
участников, общим культурным и профессиональным фоном и установкой. Иная ситуация
возникает при коммуникации на английском языке специалистов с различными родными
языками. Именно здесь возникает особая ситуация, интересная с точки зрения отражения
особенностей номинации в различных языках.
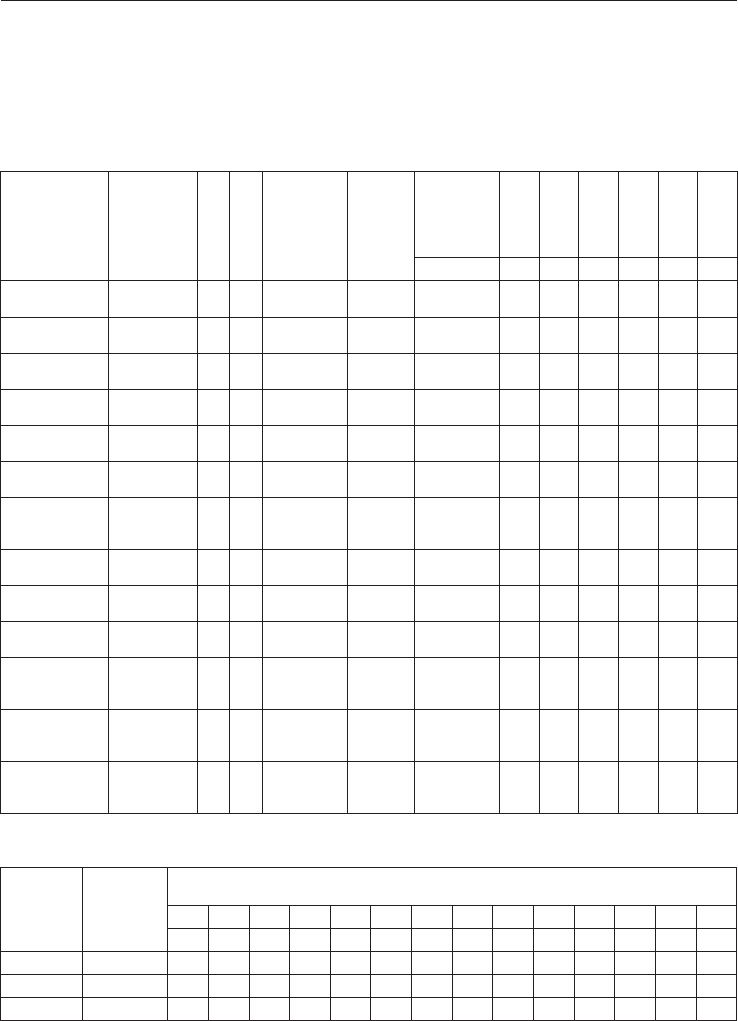
В массивах текстов на глобальном английском языке выявлено 404 разных модели имен-
ных групп, из них 26 моделей встречаются во всех корпусах текстов (см. фрагмент частотно-
го списка моделей в Таблице 4), а 240 моделей встречаются только в одном из корпусов каж-
дая (Таблица 5) и являются уникальными.
Базовыми ИГ в английском языке являются двухкомпонентные сочетания с существи-
тельным в функции ядра, частота которых в научном тексте превышает частоту трехкомпо-
нентных сочетаний в три раза (по нашим наблюдениям максимальная длина простой ИГ в
научном тексте составляет 8 элементов). Однако внешняя структурная простота частотных
Л. Н. Беляева 106
ИГ в английском языке обманчива, поскольку является следствием стяжения структуры вы-
сказывания и, следовательно, исходной конструкции — предложения или исходной ИГ. Та-
кое стяжение, формальное упрощение структуры словосочетания ведет к ее семантическо-
му усложнению.
Таблица 4. Частотный список моделей именных групп (список языков см. в Табл. 1 и 2)
Модель
Пример
именной
группы
Длина
Номер модели
Распро-
странен-
ность
Сум-
марная
частота
Число сло-
восочета-
ний в кор-
пусе
1 2 3 4 5 6 7
A+N
technical
advisor
2 1 7 4281 381 536 306 667 852 397 1142
N1+N2
acceleration
capacity
2 3 7 3695 450 373 308 601 635 483 845
A+N1+N2
acceptable
damage levels
3 10 7 1311 94 104 108 219 392 159 235
N1+N2+N3
design basis
earthquake
3 4 7 925 71 66 103 96 216 123 250
A/N1+N2
alternate
approach
2 5 7 740 73 61 76 133 173 106 118
G/N1+N2
adjoining
structures
2 20 7 611 46 73 57 110 93 80 152
A1+A2+N
acceptable
structural
response
3 9 7 575 44 65 32 100 102 51 181
PII+N
accepted
acceleration
2 12 7 526 54 62 37 72 92 76 123
A+N1+N2+N3
active fault
research center
4 18 7 230 10 8 15 31 97 25 44
A/N1+N2+N3
air leakage
characteristics
3 39 7 192 21 14 11 29 50 32 35
N1+N2+N3+N4
battery bank
support
structure
4 25 7 133 3 3 7 20 43 20 37
PII+N1+N2
applied
displacement
spectra
3 16 7 130 7 7 8 9 47 18 34
A1+A2+N1+N2
Atomic Energy
Research
Establishment
4 43 7 125 12 6 4 21 41 16 25
Таблица 5. Характеристика уникальных моделей словосочетаний
Длина
словосоче-
тания
Количест-
во моде-
лей
Количество моделей и словосочетаний в различных корпусах текстов
(m — число моделей, f — частота)
1 2 3 4 5 6 7
m f m f m f m f m f m f m f
2 2 1 1 1 1
3 13 3 5 2 2 2 3 3 4 3 3
4 59 3 4 7 11 6 6 12 15 10 11 17 24 4 6

Глобальный английский язык как отражение лингвистического и когнитивного своеобразия 107
5 81 7 7 9 10 2 2 10 13 25 35 13 14 15 21
6 61 5 5 5 5 2 3 10 11 13 14 8 11 18 24
7 12 1 1 3 3 2 2 3 4 3 3
8 12 1 2 3 3 3 4 1 1 4 5
Σ 240 20 24 21 26 10 11 40 47 55 69 46 55 48 63
Особенности организации двух- и трехкомпонентных ИГ в глобальном английском языке
определяется последовательностью их свертывания из более длинных конструкций и степе-
нью этого свертывания.
К многокомпонентным именным сочетаниям отнесем ИГ с количеством компонентов 5 и
выше (см. таблицу 6). Анализ этой таблицы демонстрирует значительно большее количество
многокомпонентных именных групп в текстах на подлинно английском языке.
Собственно формирование многокомпонентных ИГ реализуется двояко в зависимости от
того, как происходит номинация: либо как процесс последовательного усложнения и уточне-
ния номинации объекта (постепенное усложнение именной конструкции с добавлением ха-
рактеристик ядра), либо как процесс последовательного сворачивания.
Основными именными группами в английском языке являются двухэлементные комби-
нации с именем в позиции ядра, частота которых в научном тексте превышает частоту ком-
бинаций с тремя элементами в три раза.
Таблица 6. Характеристика моделей многоэлементных словосочетаний
Длина
словосоче-
тания
Число сло-
восочета-
ний
Число
разных
словосо-
четаний
Число разных
моделей
модели
Число словосочетаний в корпусе*
1 2 3 4 5 6 7
5 315 275 114 18 25 21 49 98 40 64
6 93 88 68 7 5 6 14 23 15 23
7 19 16 16 3 1 0 3 5 4 3
8 12 11 9 0 0 0 3 4 1 4
439 390 217 28 31 27 69 130 60 94
* Языки авторов перечислены в таблицах 1 и 2
Сопоставительный анализ ИГ позволяет сделать вывод о различиях в принципах номиниро-
вания сложных объектов и степени отражения особенностей этих внеязыковых объектов при
расчлененной (многокомпонентной) номинации. Вопрос о том, являются ли эти различия куль-
турологическими, когнитивными или определяются типом языка, остается дискуссионным.
Таким образом, материал корпуса параллельных текстов позволяет оценить весь спектр
явлений, выделить рекомендуемые и некорректные термины, возникающие в результате
буквального перевода, исследовать особенности описания ситуаций.

Л. Н. Беляева 108
Исследование глобального английского языка особенно важно сегодня, в условиях, ког-
да необходимо необходимость сделать информацию активной, то есть обеспечить макси-
мальное использование информации на всех видах носителей, на электронных носителях
в частности, и содействовать распространению и получению знаний. Это значит, в частно-
сти, что из информации, получаемой из различных «бумажных» источников (книг, статей,
документов и т. п.), а также по сети Интернет, мы должны уметь оперативно извлекать не-
обходимые сведения. Процесс получения знаний из различных источников, которые мо-
гут быть как материальными, так и экспертными, в современном направлении инженерии
знаний определяется термином «извлечение знаний». Исследование глобального англий-
ского языка методами корпусной лингвистики создает базу для создания и ведения спе-
циализированных словарей и онтологий, являющихся ядром современных средств пере-
работки информации.
Кроме того, актуальные проблемы развития современного полиэтнического и поликуль-
турного общества определяют необходимость в создании специальных средств поддержки
совместной деятельности в условиях многоязычной коммуникации и умении их использо-
вать. Эти же условия требуют обеспечения полной многоязычности информации на всех эта-
пах ее существования, что может быть обеспечено на базе применения информационных
технологий за счет создания систем генерации и поддержки многоязычной информации, ло-
кализации данных и программного обеспечения, за счет создания практических систем ав-
томатического (машинного) перевода, компьютерных словарных и обучающих систем.
В современном мире в условиях открытой и многоязычной коммуникации и развития
средств непрерывного и открытого обучения возникает целый ряд задач, решение которых
связано с качеством и практической применимостью различных информационных техноло-
гий, связанных с анализом текстов на естественном языке и звучащей речи. К таким задачам
в самом общем виде относятся:
автоматический поиск, извлечение и обогащение информации и знаний, получаемых из •
различных мультимедийных, многоязычных источников и источников, связанных с ком-
муникацией различных участников;
межъязыковое или многоязычное извлечение, презентация и распространение информа-•
ции;
автоматическое обнаружение и «отслеживание» возникающих тем и проблем из неструк-•
турированных мультимедийных данных;
использование источников знаний для того, чтобы облегчить разметку знаний и доступ •
к ним (в качестве таких структурированных источников знаний могут выступать одно- и
многоязычные лексиконы, толковые и энциклопедические словари, тезаурусы, энцикло-
педии и т. д.);
поддержание вопросно-ответного взаимодействия человека и компьютера или людей с по-•
мощью компьютера как посредника для извлечения знаний из источников различной при-
роды, структуры и состава;
поддержание дистантного обучения в системах открытого образования, включая автома-•
тизированное тестирование уровня знаний, разработку электронных учебников и диало-
говых обучающих систем;

Глобальный английский язык как отражение лингвистического и когнитивного своеобразия 109
создание интеллектуальных средств поддержки автоматизированного ведения библиогра-•
фической работы, анализа и понимания документов для того, чтобы обеспечить возмож-
ности доступа к информации различных экспертов или групп экспертов;
моделирование знаний, надежд, планов, потребностей и намерений пользователей на ос-•
нове анализа их запросов к различным системам, созданных ими продуктов и взаимодей-
ствия с компьютером;
обеспечение возможности устного диалога с компьютером и поддержки анализа и порож-•
дения звучащей речи.
Решение задачи оперативного извлечения и обработки знаний сегодня возможно только
при наличии базовых навыков и умений в области работы со специализированными систе-
мами машинного перевода, электронными словарями и, в целом, компьютерными система-
ми обработки информации. Подобные умения и навыки могут вырабатываться не только в
условиях аудиторного обучения, но и в рамках обучения дистанционного.
L. N. Belyaeva
English as Lingua Franca as Linguiic and Cognitive Reeion of Its User Mentality
Phenomenon of global English is to be considered both as the reection of language peculiarities
of non-English speakers who use global English for professional communication and-or training,
and as cognitive characteristics, patterns of world, reected in global English texts by these native
languages. us it is necessary to investigate texts, which are restricted to one and the same topic,
structure and volume, but written in English by dierent language speakers and, as a consequence.
On this basis, among the other things, we can analyze nomination of extralinguistic objects and
peculiarities of special terminological collocations in conditions of dierent native languages, and
peculiarities of cognition of “averaged” native language speakers.