Li S.Z., Jain A.K. (eds.) Encyclopedia of Biometrics
Подождите немного. Документ загружается.

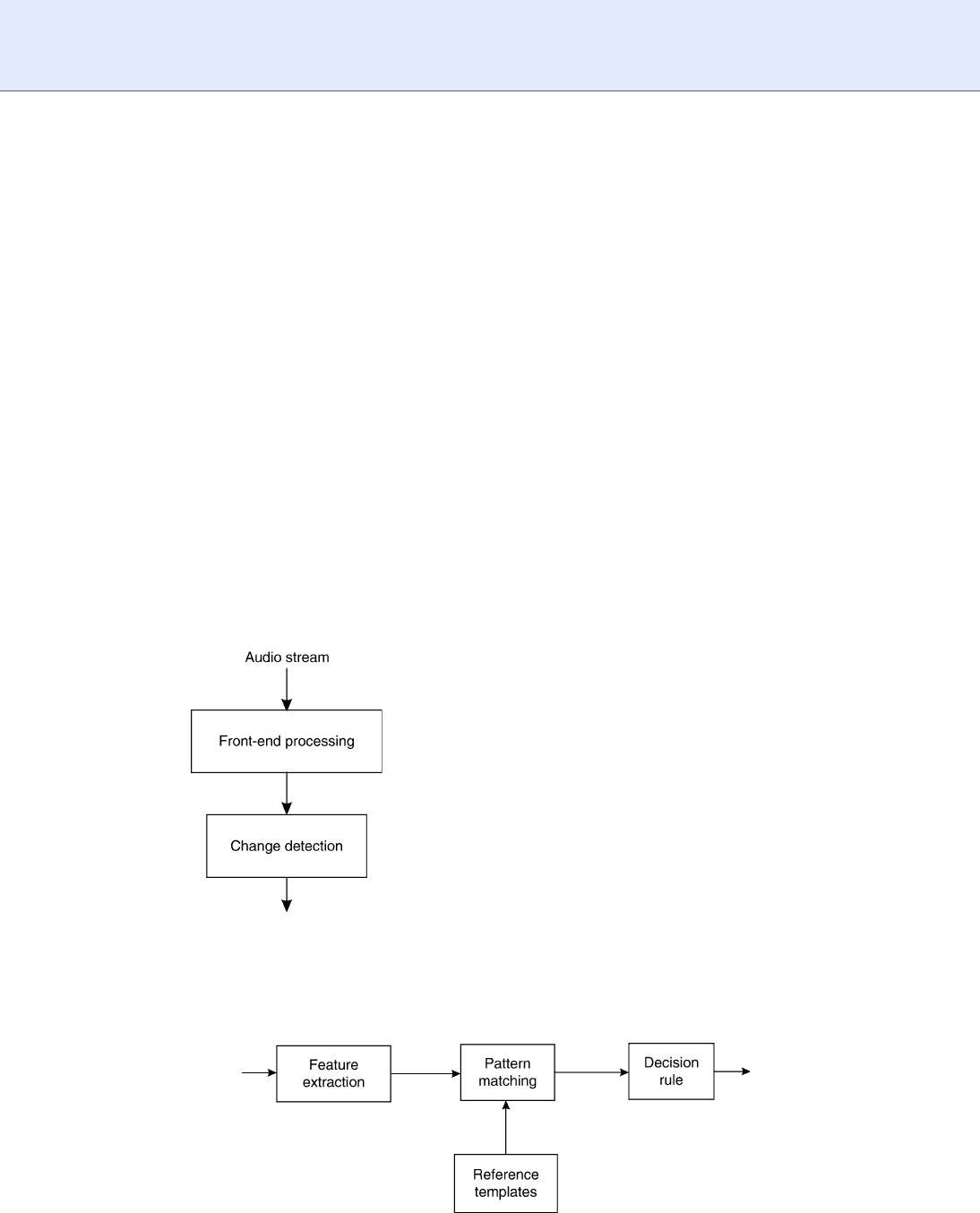
points in each speech region and consequently divides
the speech regions into segments containing speech
from a single speaker (Fig. 1).
The state-of-art systems for speaker segmentation
can be divided into three categories: metric-based,
model-based, and hybrid (i.e., combined metric-
and model-based) ones. The segmentation process
may be carried out by a single pass or by multiple
passes through the acoustic data. In the multiple passes
case the decision of change-point detection is refined
on successive iterations.
Metric-based segmentation is probably the most
used approach. It relies on the definition of some metric
or distance measure to compare the spectral character-
istics on both sides of successive points of the audio
signal, and it hypothesizes as speaker change points
those boundaries whose distance values exceed a given
threshold. The performance of this approach depends
highly on the metric and the threshold. Various metrics
have been proposed and analyzed in the literature.
The most cited are the Bayesian Information Criterion
(BIC) which presents the advantages of robustness and
threshold independence [2]; the Generalized Likelihood
ratio (GLR) and the Kullback–Leibler distance [3];
Divergence Shape Distance [4], etc. The threshold is
normally defined empirically given a development set,
according to a desired performance. Thus, the thresh-
old will be dependent on the data being processed and
needs to be redefined every time data of a different
nature need to be processed. This problem has been
studied within the speaker identification community
in order to classify speakers in an open set speaker
identification task [ 5].
Model-based techniques are an applied evolution
of a common pattern recognition task ( Fig. 2). In
model-based segmentation, a set of models is esti-
mated for different speaker classes by using training
data. Then, the input audio stream is classified, using
these models, by finding the most likely sequence of
models [6, 7]. The boundaries between models become
the segmentation change points. Several models, in-
cluding Gaussian Mixture Models (GMMs) [8],
▶ Hidden Markov Models (HMMs) [9] and Support
Vector Machines (SVMs) [10] have been employed to
describe specific speakers.
Hybrid techniques combine metric- and model-
based techniques [11]. Usually, metric-based segmen-
tation is used initially to presegment the input audio
signal. The obtained segments are used then to create
a set of speakers models. Finally, model-based re-
segmentation gives a refined segmentation.
There are some speaker segmentation techniques
proposed in the literature that are not a clear fit to any
of the two previous categories. For example, in [12]
dynamic programing is proposed to find the speaker
change poin ts. In [13] a genetic algorithm is proposed
where the number of segments is estimated via the
Walsh basis functions and the location of change points
Speaker Segmentation. Figure 1 A brief flow diagram
for a speaker segmentation module.
Speaker Segmentation. Figure 2 Block diagram of a traditional pattern recognition system.
1280
S
Speaker Segmentation
is found using a multipopulation genetic procedure.
In [14] segmentation is based on the location estimation
of the speakers by using a multiple-microphone setting.
The difference between two locations is used as a feature
and tracking techniques are employed to estimate the
change points of possibly moving speakers.
Assessing Performance
A speaker segmentation system should provide the cor-
rect speaker turns and therefore the segments should
contain a single speaker. The performance of speaker
segmentation can be assessed in terms of the accuracy
of speaker turn point detection. In this case, two pairs of
figures of merit are commonly used to assess the perfor-
mance of a speaker segmentation system. On the one
hand, one may define two fundamental types of errors,
namely false alarm (FA) and missed detection (MD).
A FA of turning point detection occurs when a detected
turning point is not a true one. A missed MD occurs
when a true turning point cannot be detected. Thus, it is
possible to use the false alarm rate (FAR) and the miss
detection rate (MDR) defined as:
FAR ¼
N
FA
N
FA
þ N
ref
;
MDR ¼
N
MD
N
ref
;
where N
FA
and N
MD
are the total number of FA and MD
respectively , and N
ref
is the total number of true turning
points given by the reference manual segmentation. A
high value of FAR signifies that the speech signal has
been oversegmented. A high value of MDR means
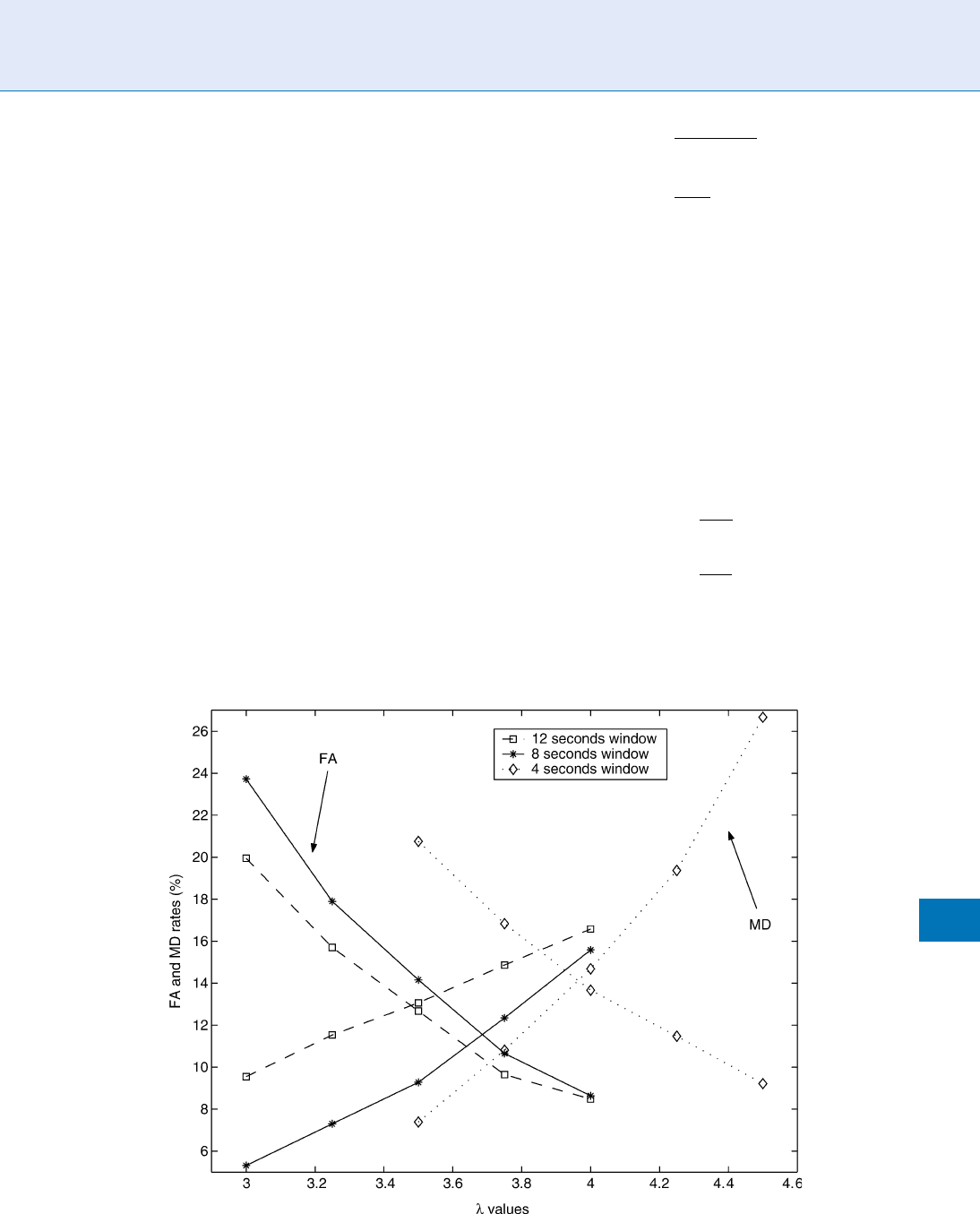
undersegmentation. Figure 3 shows an example of
FAR–MDR curve [15]. This figure shows the tradeoff
between missed detection and false alarm, and pro-
vides a reference to select different operation points.
On the other hand, one may employ the precision
(PRC) and recall (RCL) rates given by
PRC ¼
CFC
DET
;
RCL ¼
CFC
GT
;
where CFC denotes the number of correctly found
changes, DET is the number of the detected
speaker changes, and GT stands for the actual number
Speaker Segmentation. Figure 3 The MDR–FAR curve for speaker segmentation.
Speaker Segmentation
S
1281
S

of speaker turns, i.e., the ground truth. For the latter pair,
another objective figure of merit is the F
1
measure
F
1
¼
2PRCRCL
PRC þ RCL
that admits a value between 0 and 1. The higher its
value is, the better performance obtained is. Between
the pairs (FAR, MDR) and (PRC, RCL) the following
relationships hold:
MDR ¼ 1 RCL;
FAR ¼
RCLFA
DETPRC þ RCLFA
:
The perf ormance of speaker segmentation can also
be assessed in terms of the speaker coverage. For the
measurement of speaker coverage, the false alarm cov-
erage (FACov) and the missed detection coverage
(MDCov) are defined as,
MDCov ¼
P
i
duration of missed portion for
reference segment i
P
i
duration of reference segment i
;
FACov ¼
P
j
duration of false portion for
detected segment j
P
i
duration of detected segment j
:
In the NIST evaluations the performance of a
speaker segmentation system is measured using the
segmentation cost function, defined as a weighted
sum of decision errors, weighted by error type and
integrated over error duration. Thus, five kinds of
errors are considered, all as a function of time:
Missing a segment of speech when speech is present
(PMissSeg)
Falsely declaring a segment of speech when there is
no-speech (PFASeg)
Assigning a false alarm speaker to a segment of
speech (PMissSpkr)
Assigning a speaker to a segment of speech of a
missed speaker (PFASpkr)
Assigning an incorrect speaker to a segment of
speech (PErrSpkr)
Therefore, the speaker segmentation cost is defined
as:
C
Seg
¼ðC
MissSeg
P
MissSeg
þ C
FASeg
P
FASeg
Þ
þðC
MissSpkr
P
MissSpk
þ C
FASpk
P
FASpk
Þ
þ C
ErrSpk
P
ErrSpk
:
Typically, the cost parameters are all set equal to 1.
Applications
First, one of the applications is in multimedia infor-
mation management (information indexing, informa-
tion access and content protection) in order to
automatically extract meta-data information. Multi-
media technologies, which play a crucial role in a
wide range of recent application domains, are highly
demanded to further facilitate multimedia services
and to more efficiently utilize multimedia information
generated from diverse domains. A multimedia con-
tent based indexing and retrieval system requires anal-
ysis of both textual and speaker content. Speaker
changes are often considered natural points around
which to structure the spoken document for naviga-
tion by users. Creating an index into an audio–visual
stream, either in real time or in postprocessing, may
enable a user to locate particular segments of the audio
data. For example, this may enable a user to browse a
recording to select audio segments corresponding to
a specific speaker, or ‘‘fast-forward’’ through a record-
ing to the next speaker. In addition, knowing the
ordering of speakers can also provide content clues
about the conversation, or about the context of the
conversation. In broadcast news, for example, speaker
changes typically coincide with story changes or tran-
sitions. Furthermore, audio recordings of meetings,
presentations, and panel discussions are also examples
where organizing audio segments by speaker identity
can provide useful browsing cues to listeners. Also, the
audio recording of a meeting or a conversation can be
speaker-indexed automatically to facilitate the search
and retrieval of the content spoken by a specific per-
son. In this way, meeting information can be obtained
conveniently, such as who is saying what and when,
remotely through on-line or off-line systems.
Second, biometric applications such as access
control. Surveillance is becoming increasingly impor-
tant for public places. However, most surveillance sys-
tems simply store video data, then storing video
information selectively through identifying key events
or human activities is very important for facilitating
access to huge amount of the stored surveillance video
archivals with improved browsing and retrieval func-
tionality. Tracking speaker-specific segments in con-
versations, to aid in surveillance applications, is
another place to use a speaker segmentation system.
Third, ASR related applications such as the tran-
scription of conversations. Speaker segmentation relates
to automatic labeling and transcription of audio archives
1282
S
Speaker Segmentation

that involve multiple speakers. In this application, the
audio signal typically contains speech from different
speakers under different acoustic conditions. It is well
known that the performance of automatic speech recog-
nition can benefit greatly from speaker adaptation,
whether supervised or unsupervised. With the knowl-
edge of ‘‘who is speaking,’’ acoustic models for speech
recognition can be adapted to better match the environ-
mental conditions and the speakers. Furthermore, in the
speech-to-text conversion process, information about
speaker turns can also be used to avoid linguistic
discontinuity.
Also, capturing the speaker change in a given audio
stream could be very useful in military and forensic as
well as commercial applications. In forensic applica-
tions it is often required to process speech recorded by
means of microphones installed in a room where a
group of speakers conduct a conversation. Questions
such as how many speakers are present, at what time a
new person has joined (left) the conversation and
others are often asked. It is also often required to
determine the true identity of the speakers, or some
of them, using available templates of known suspects.
For this, one needs to segment the recorded signal into
the various speakers and then use conventional speaker
identification or verification methods.
Summary
There are a number of relevant applications that may
benefit from a speaker segmentation module. Among
them, ASR (rich transcription), video tracking, movie
analysis, etc. Defining and extracting meaningful char-
acteristics from an audio stream aim at obtaining a
more or less structured representation of the audio
document, thus facilitating content-based access or
search by similarity.
In par ticular, speaker detection, tracking, clustering
as well as speaker change detection are key issues in
order to provide metadata for multimedia documents
and are an essential preprocess stage of multimedia
document retrieval. Speaker characteristics, such as
the gender, the approximate age, the accent or the
identity, are also key indices for the indexing of
spoken documents. It is also important information
concerning, the presence or not of a given speaker in a
document, the speaker changes, the presence of speech
from multiple speakers, etc.
Related Entries
▶ Gaussian Mixture Models
▶ Hidden Markov Models
▶ Pattern Recognition
▶ Speech Analysis
▶ Speaker Features
▶ Session Effects on Speaker Modeling
▶ Speaker Recognition, Overview
References
1. Docio-Fernandez, L., Garcia-Mateo, C.: Speaker segmentation,
detection and tracking in multi-speaker long audio recordings.
In: Third COST 275 Workshop: Biometrics on the Internet,
pp. 97–100. Hatfield, UK (2005)
2. Chen, S.S., Gopalakrishnan, P.: Clustering via the bayesian in-
formation criterion with applications in speech recognition. In:
Proceedings of IEEE International Conference on Acoustics,
Speech and Signal Processing, vol. 2, pp. 645–648. Seattle, WA
(1998)
3. Delacourt, P., Wellekens, C.J.: DISTBIC: a speaker-based seg-
mentation for audio data indexing. Speech Commun. 32(1–2),
111–126 (2000)
4. Lu, L., Zhang, H.J.: Speaker change detection and tracking in
real-time news broadcasting analysis. In: ACM International
Conference on Multimedia, pp. 602–610. Quebec, QC, Canada
(2002)
5. Campbell, J.P.: Speaker recognition: a tutorial. Proc. IEEE 85(9),
1437–1462 (1997)
6. Gauvain, J.L., Lamel, L., Adda, G.: Partitioning and transcription
of broadcast news data. In: Proceedings of International Confer-
ence on Speech and Language Processing, vol. 4, pp. 1335–1338.
Sidney, Australia (1998)
7. Kemp, T., Schmidt, M., Westphal, M., Waibel, A.: Strategies for
automatic segmentation of audio data. In: Proceedings of the
IEEE International Conference on Acoustics, Speech and Signal
Processing, pp. 1423–1426. Istanbul, Turkey (2000)
8. Gauvain, J.L., Lamel, L., Adda, G.: The LIMSI broadcast news
transcription system. Speech Commun. 37(1–2), 89–108 (2002)
9. Moraru, D., Meignier, S., Fredouille, C., Besacier, L., Bonastre, J.F.:
The ELISA consortium approaches in broadcast news speaker
segmentation during the NIST 2003 rich transcription evaluation.
In: Proceedings of IEEE ICASSP’04, pp. 223–228. Montreal,
Canada (2004)
10. Lu, L., Li, S.Z., Zhang, H.J.: Content-based audio segmentation
using support vector machines. ACM Multimedia Syst. J. 8(6),
482–492 (2001)
11. Kim, H.G., Ertelt, D., Sikora, T.: Hybrid speaker-based segmen-
tation system using model-level clustering. In: Proceedings of the
IEEE International Conference on Acoustics, Speech and Signal
Processing, vol. 1, pp. 745–748. Philadelphia, PA (2005)
12. Vescovi, M., Cettolo, M., Rizzi, R.: A DP algoritm for speaker
change detection. In: Proceedings of Eurospeech03. (2003)
Speaker Segmentation
S
1283
S
13. Pwint, M., Sattar, F.: A segmentation method for noisy speech
using genetic algorithm. In: Proceedings of the IEEE Interna-
tional Conference on Acoustics, Speech and Signal Processing.
Philadelphia, PA (2005)
14. Lathoud, G., McCowan, I., Odobez, J.: Unsupervised location-
based segmentation of multi-party speech. In: Proceedings of the
IEEE International Conference on Acoustics, Speech and Signal
Processing: NIST Meeting Recognition Workshop. Montreal,
Canada (2004)
15. Perez-Freire, L., Garcia-Mateo, C.: A multimedia approach for
audio segmentation in TV broadcast news. In: Proceedings of the
IEEE International Conference on Acoustics, Speech and Signal
Processing, pp. 369–372. Montreal, QC, Canada (2004)
Speaker Separation
Speaker separation is a technology used in multi-
speaker environments to separate the vocal features of
each speaker from those of the other speakers, even
when speakers interrupt and talk over each other.
▶ Speaker Recognition, Standardization
Speaker Tracking
Speaker tracking consists of determining not only
whether a particular speaker appears in a multispeaker
audio stream, but identifying the specific intervals
within the audio stream corresponding to the speaker.
It requires that this speaker is known a priori by the
system. In that sense, speaker tracking can be seen as a
speaker verification task applied locally along a docu-
ment containing multiple interventions of various
speakers. The objective of this task is to cluster the
speech by speaker.
▶ Speaker Segmentation
Speaker Verification
▶ Liveness Assurance in Voice Authentication
Spectral Analysis of Skin
▶ Skin Spectroscopy
Specular Reflection
Specular reflection is the mirror-like reflection of light
or waves on a surface. The incoming light is reflected at
the same angle as it hits on the surface.
▶ Iris Standards Progression
▶ Skin Spectroscopy
Specularity
▶ Specular Reflection
Speech Analysis
DOR O TEO T. T OLEDANO,DANIEL RAMOS,JAV I ER GONZALEZ-
D
OMINGUEZ,JOAQUI
´
N GONZA
´
LEZ-RODRI
´
GUEZ
ATVS – Biometric Recognition Group. Escuela
Politecnica Superior, Universidad Autonoma de
Madrid, Spain
Synonyms
Speech parametrization
Definition
The analysis of speech signals can be defined as the
process of extracting relevant information from the
speech signal (i.e., from a recording). This process is
mainly based on the speech production mechanism,
whose study involves multiple disciplines from linguis-
tics and articulatory phonetics to signal processing and
1284
S
Speaker Separation
source coding. In this article, a short overview is given
about how the speech signal is produced and typical
models of the speech production system, focusing on
the different sources of individuality that will be pres-
ent in the final uttered speech. In this way, the speaker
who produced the speech with those individual features
is then recognizable both for humans and for machines.
Although speech production is felt by humans as a
very natural and simple mechanism, it is a very com-
plex process that involves the coordinated participa-
tion of several physiological structures that evolution
has developed over the years. For a deeper description
of this process the interested reader may consult some
of these excellent books [1–3]. Here the human speech
production mechanism is described ver y briefly as
the basis for the automated speech analysis systems.
Once these mechanisms have been understood, the most
common methods to analyze speech are addressed.
These methods are based on the speech production
mechanisms to some extent. The last part of this article
analyzes how the relevant information in this context
(the speaker individualization information) is encoded
into the speech signal.
Speech Production and Its Relation to
Speech Analysis
The process of speech production is described in
many books [1–3]. Here the main conclusions about
how the speech production system relates to the main
parameters estimated in speech analysis are briefly
reviewed. Next section addresses the problem of esti-
mating these parameters.
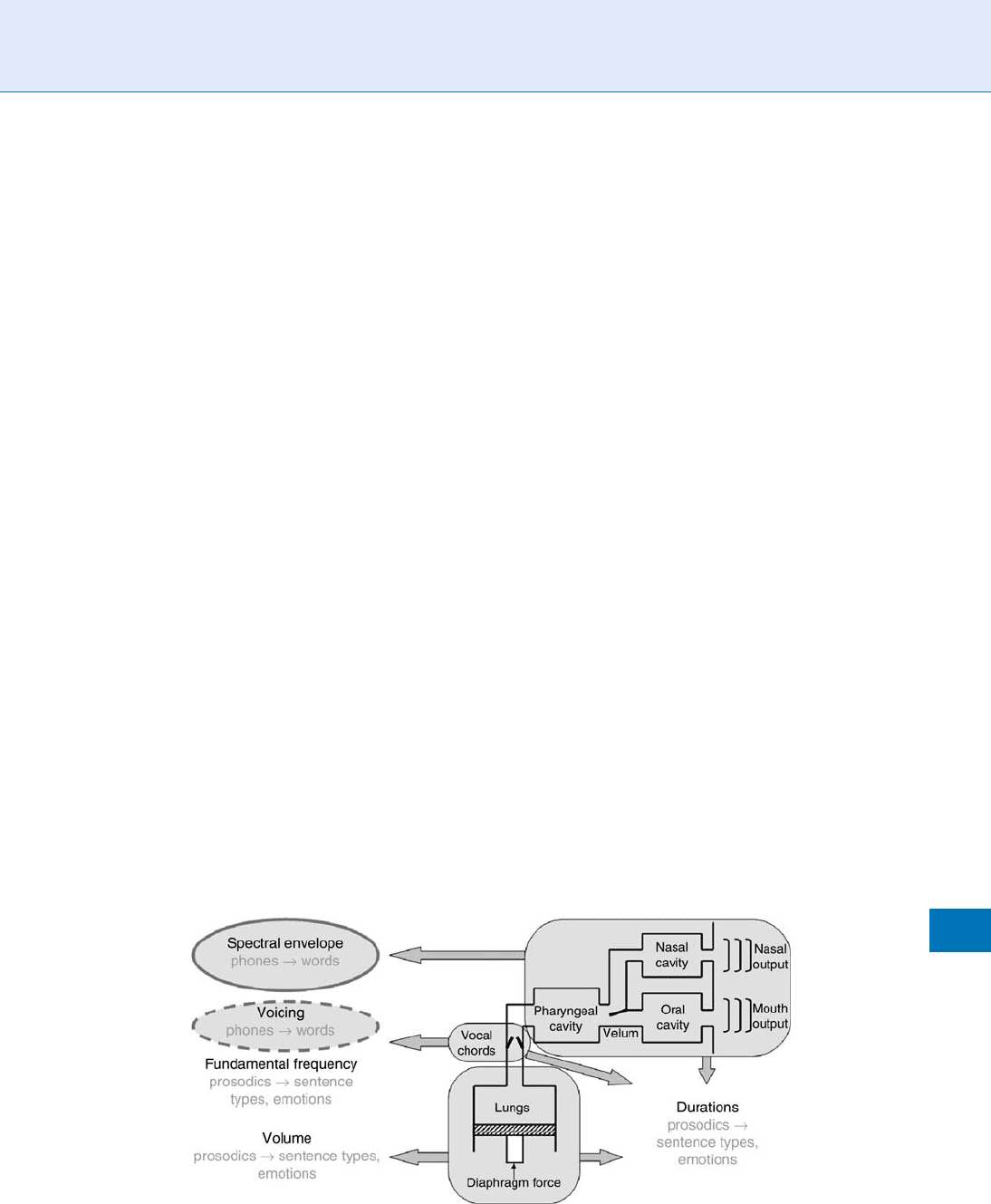
Figure 1 summarizes the different parts of the
human speech productionsystem (represented very
schematically), and how they are related to the main
parameters that describe the characteristics of the
speech signal:
Volume or intensity of the sound. The volume or
intensity of a speech sound depends mainly on
the amount of air exhaled by the lungs and the
muscular tension on the articulators producing
the sound. The volume or intensity is a prosodic
parameter that is related to emotions (i.e., speech in
anger has usually more volume than normal or
relaxed speech) and sentence type (for instance
interrogative sentences tend to end with a higher
intensity).
Voicing and, in case of a voiced sound, ▶ funda-
mental frequency. Human sounds can be voiced or
unvoiced depending on whether the vocal chords
vibrate or not when producing the sound. Voicing
is a binary feature that is essential in discriminating
different phonemes. In voiced sounds the vocal
chords vibrate at a frequency that is called funda-
mental frequency (also called F0, tone, or pitch). The
fundamental frequency depends on the tension ap-
plied to the vocal chords and on the air flow pro-
duced by the lungs, and can be modulated to provide
the sentence with a certain intonation, constituting
one of the most important prosodic parameters. The
fundamental frequency plays an important role in
determining emotions and sentence types.
Speech Analysis. Figure 1 Simplified functional scheme of the human speech production system with indication of the
speech parameters affected by each organ.
Speech Analysis
S
1285
S

Spectral envelope. The rest of the speech production
system from the vocal chords to the lips and nostrils
is called the vocal tract. The effect of the vocal tract
is to modulate the sound produced to obtain the
different phonemes. This is accomplished with the
help of several mobile parts called articulators such
as the tongue, the lips, and the teeth, which can
substantially modify the shape of the vocal tract
and therefore the modulation produced. It can be
seen that the modulation produced by the vocal
tract affects mainly the spectral envelope of the
signal produced. This spectral envelope typically
presents a few maxima at the frequencies of reso-
nance of the vocal tract, called formants, which are
characteristics of the different phonemes. In fact, it
is possible to distinguish the diffe rent vowels based
on their formants. The spectral envelope alone is
capable of, with the help of voicing (and fundamen-
tal frequency for tonal languages such as Chinese),
discriminating among the different phonemes of a
language and also among different speakers.
Duration of the phonemes. The speech production
system moves over time in a coordinated way and
this movement defines the durations of the pho-
nemes. This is considered a prosodic feature that
contains valuable information for recognizing pho-
nemes and speakers.
This complex system is coordinated and directed
by the brain, which in a much more complex and
largely unexplained process is capable of generating
the adequate sequence of words to utter at a precise
instant in a dialog, transforming these sente nces into a
sequence of phonemes, sending the necessary orders to
the muscles to coordinately produce the speech and
even superimposing other information such as emo-
tions. This process of language generation is mainly
learned, and different individuals learn to generate
language and coordinate the articulatory organs in
different ways, thus constituting anot her source of
speaker discriminating information.
Speech Analysis
Speech analysis is the process of ana lyzing the speech
signal to obtain relevant information of the signal in
a more compact form than the speech signal itself.
Given the previous review of the speech production
mechanism and its relation to the most important
characteristics of speech, the goal of speech analysis is
to obtain some or all of these parameters (and possibly
more) from a speech recording. This section presents a
review of how these parameters are estimated from
a speech recording and how important they are for
voice biometrics.
Volume or intensity of the sound. This parameter is
typically measured as the logarithm of the short-term
average energy of the signal (i.e., the average of the
energy of the signal over a few milliseconds). In-
tensity can be a clue to identify a speaker and to
discriminate between sounds, but this feature is
affected very much by external parameters such as
the gain of the recording equipment and micro-
phone and even the distance and position between
the mouth and the microphone. For this reason
absolute intensity is rarely used in speech analysis
and only relative intensity variations are used.
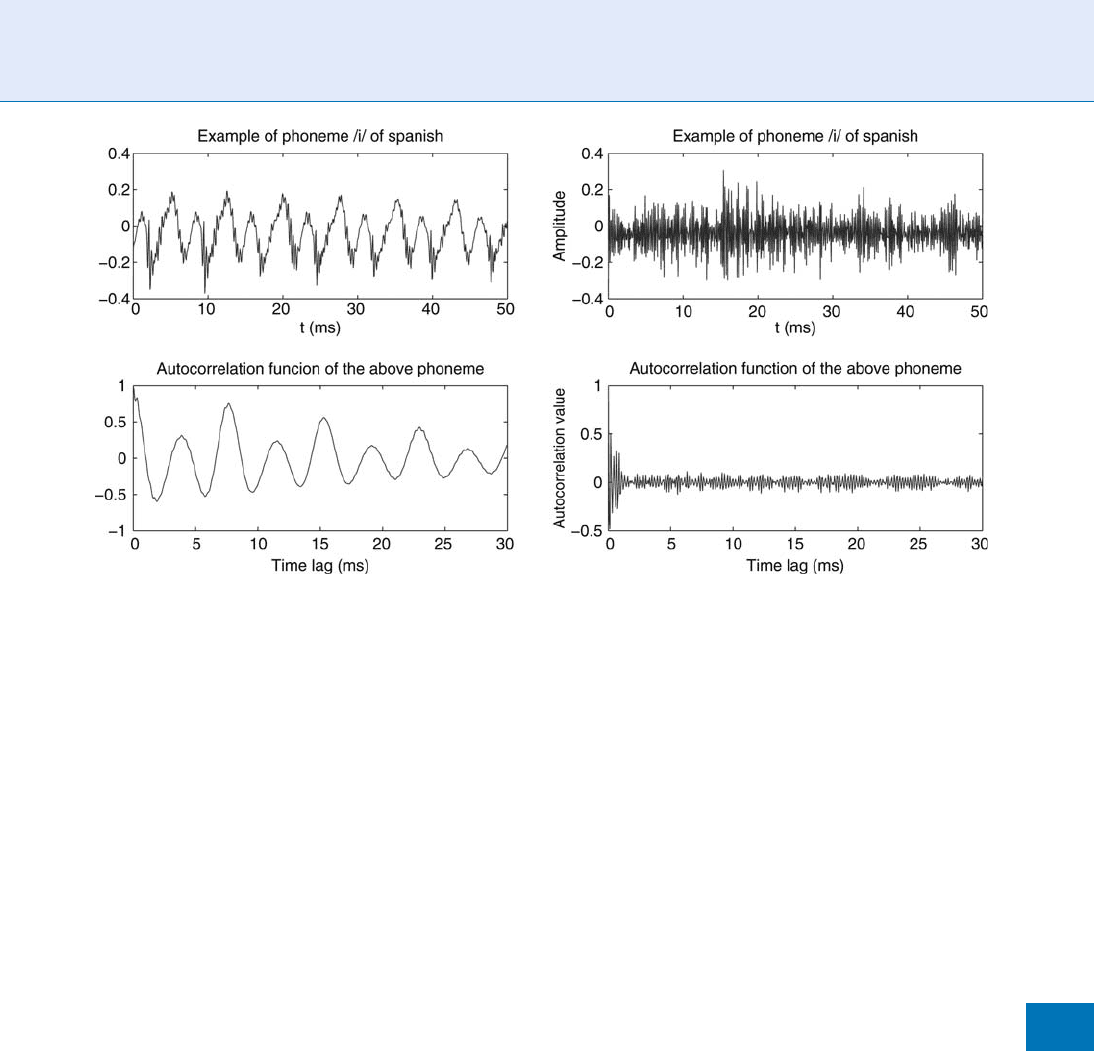
Voicing and, in case of a voiced sound, fundamental
frequency. Voicing and the fundamental frequency
can be estimated from the autocorrelation function
of the speech signal. Figure 2 shows a voiced and
and unvoiced phoneme and their autocorrelation
functions. The quasi-periodicity of the voiced sig-
nals becomes apparent in the autocorrelation func-
tion as a local maximum at a lag corresponding to
the pitch period (the inverse of the fundamental
frequency). In Fig. 2 this maximum is placed at a
lag of 7.5ms, corresponding to a fundamental fre-
quency of 133 Hz. For unvoiced phonemes this
maximum does not appear. To estimate the funda-
mental frequency it is necessar y to locate the correct
local maximum in the autocorrelation function,
which is sometimes (as in the example shown
here) difficult due to the presence of local maxima
at rational multiples of the fundamental frequency.
Besides the autocorrelation method there are other
methods to estimate the fundamental frequency,
either with lower computational cost (such as
using the Magnitude Difference Function instead of
the autocorrelation function) or with more preci-
sion [4]. The fundamental frequency is very char-
acteristic of the speaker and is very different for
male and female speakers. The evolution of the
fundamental frequency over time determines the
1286
S
Speech Analysis
intonation of the utterance and intonation is also
very characteristic of the speaker.
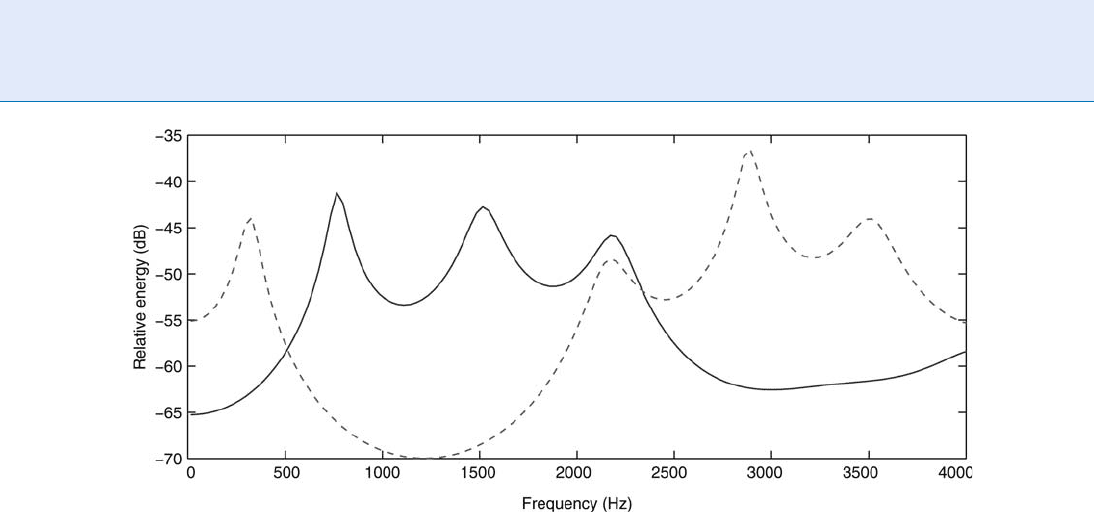
Spectral envelope. The spectral envelope of the
speech signal contains the richest information
about the speech sounds and also about the speak-
er. Not surprisingly, speech and speaker recogni-
tion systems typically focus primarily (many times
exclusively) on extracting and processing this dyna-
mically changing information from the speech sig-
nal. For this reason many times the speech analysis
phase is reduced to the spectral envelope estima-
tion. Several modeling strategies have been pro-
posed in the literature, but with no doubt the
most successful one in terms of number of applica-
tions based on one kind of modeling is Linear
Predictive Coding (LPC) of speech. In this ap-
proach, the vocal tract is modeled as an all-pole
(or autoregressive, AR) model [5] representing the
vocal tract resonances with a digital filter com-
pletely determined by the poles positions. In this
way, with a very small number of LPC coefficients
(typically between 10 and 20), the spectral envelope
is fully determined for every analysis frequency. An
example of this analysis is shown in Fig. 3 for two
different vowels in Spanish. Here the spectral enve-
lope is represented with 17 LPC coefficients and
shows very clearly the different formants of the two
vowels. Theoretically, only nasal sounds are not
properly modeled with an AR system, as the nasal
cavity in parallel, as shown in the acoustic theory of
tubes, introduces zeros (minima, as opposed to the
poles or resonances) in the overall vocal tract re-
sponse. Then those nasal sounds could be better
modeled by ARMA (AR and MA, moving aver-
age) – or pole-zero models – doubling the number
of coefficients. However, good enough approxima-
tions of nasal spectral envelopes can be obtained
with the typical numbe r of poles (now in positions
not so well correlated with physical configuration
of the acoustic vocal tract), simplifying the model
with a single all-pole mode l for all kinds of sounds.
Each possible sound is then modeled as a set of LPC
coefficients (see ‘‘Speaker Features’’ entry for
details on LPC coefficients computation). In this
LPC context, the speech production system, as a
generator of a continuum of different sounds
which constitute syllables, words, and phrases, is
modeled as a discrete sequence of different config-
urations of the LPC model, switching every new
analysis fram e (typically, each 5–25ms) to a new
vector of parameters defining the model character-
istics. This kind of modeling has been successful in
Speech Analysis. Figure 2 Example of a voiced sound /a/ and an unvoiced sound /s/ of Spanish and their corresponding
autocorrelation functions showing a possible way of determining voicing and estimating the pitch period.
Speech Analysis
S
1287
S
many applications, such as coding or recognition of
speech signals. In speech coding, basic vocoders
were based mainly in the model description men-
tioned earlier, focused on efficient extraction from
real speech of the best set of model parameters (also
including voicing, fundamental frequency, and in-
tensity) that better fit the actual speech in each
analysis frame. Newest codecs have based their
improvements in better modeling of the excitation
signal, as having catalogs (VQ, Vector Quantized
codebooks) of possible excitation patterns, but the
underlying model is basically the same as men-
tioned earlier. In speech recognition, the objective
is to properly estimate the phone which better
corresponds to the observed spectral features at
the input at every time frame. In order to have an
efficient (both in accuracy and complexity) pattern
recognizer, the coefficients in the feature vector to
be modeled should not be correlated, which eases
the obtention of pseudo-diagonal covariance ma-
trices modeling the underlying data classes. This is
the main reason why cepstral derived features (see
‘‘Speaker Features’’ entry for details) are preferred
from highly correlated LPC coefficients, but the
model is still valid as the objective is to better
decode the phoneme at the origin of the observed
(LPC or cepstral) feature vector. Finally, in voice
biometrics even t his simple LPC model can provide
speaker specific information as frame based spec-
tral, but also phonotactic data can be derived from
the basic previous features. Details on state-of-the-
art features and models for voice biometrics are
detailed in corresponding entries ‘‘Speaker Fea-
tures’’ and ‘‘Speaker Modeling.’’
Duration of the phonemes. Estimating the durations
of the phonemes requires recognizing the pho-
nemes and determining the boundaries between
them. This process is usually made within the
context of phonetic recognition and is generally
considered too complex and not enough reliable
to be used in the context of speaker recognition,
even though durations contain important informa-
tion for speaker individualization purposes.
Speaker Information in the
Speech Signal
Speech production is an extremely complex process
that encodes multiple types of information into a
speech signal. This section describes the information
about the speaker that is encoded in the speech signal.
This information is what it is necessary to extract from
the speech signal for performing speaker recognition.
There is no single way of looking for speaker informa-
tion in a speech signal. Rather, there are multiple ways
Speech Analysis. Figure 3 Spectral envelope of /a/ (solid blue line) and /i/ (dashed red line) Spanish vowels estimated
with LPC analysis of order 17 on 8 kHz bandwidth speech (only 0–4 kHz range is shown). The spectral envelope
shows clearly the different position of the formants in both vowels.
1288
S
Speech Analysis

of extracting valuable speaker information from differ-
ent levels of the speech signal. Recently these levels
have been named hig h-level and low-level speaker fea-
tures, however, there is more of a continuous rather
than a hard division. Some of the levels from which it is
possible to extract information about the speaker from
a speech signal are the following:
Idiolectal characteristics of a speaker’s speech are on
the highest levels to take into account, and describe
how a speaker uses a specific linguistic system. This
‘‘use’’ of the language is basically learned and is
determined by how the speaker learned to generate
the adequate words for each speaking act. It can be
seen that there are individualities in this use that
can be exploited for voice biometrics.
Phonotactics describes the use by the speaker of
the phone sequences, highly influenced by the
language being spoken but including highly
individualized features. A bit lower than the idiolec-
tal characteristics, the phonotactics is also learned by
the speaker and determine the phones produced for
a sequence of words. As with idiolectal characteris-
tics, it has also been shown that this information has
important individualization power.
Prosody is the combination of instantaneous energy,
fundamental frequency, and phoneme durations to
provide speech with naturalness and full sense.
Prosody helps clarifying the message, the type
of sentence, and even t he stat e of mind of the
speaker. Some prosodic features are learned by
the spea ker (suc h as the different prosodic struc-
tures for the different messages and possibly even
state of mind), but some other prosodic features
have a physiological basis (such as the average fun-
damental frequency). In both cases the prosodic
features provide useful speaker information for
voice biometrics.
Short-term spectral characteristics are the lowest
level features containing speaker individ ualization
information. These are directly related to the artic-
ulatory actions related to each phone being pro-
duced. Spectral information intends to extract the
peculiarities of speaker’s vocal tracts and their re-
spective articulation dynamics. Again these features
are a mixture of learnt uses (such as dynamics) and
physiological features (such as the length of the
vocal tract, that have a strong impact on the char-
acteristics of the produced speech).
Summary
An overview of the speech production system has been
given, centered on the basic mechanisms involved in
speech production and the origin of sounds or pho-
nemes individuality, which makes them recognizable.
But in this homogenizing environment (the use of a
common linguistic system, usually a language, intended
for communication based in common elements),
speakers introduce individual characteristics making
each speaker’s speech to sound according to his indi-
vidual physical, emotional, and idiolectal characteris-
tics. Simple analysis models as Linear Predictive Coding
of speech allow us to easily understand the potential of
digital signal processing and pattern recognition tech-
niques, which will lately allow us to build efficient
speech codecs or recognizers and even finally good
detectors of individual speaker’s voice.
Related Entries
▶ Session Effects on Speaker Modeling
▶ Speaker Features
▶ Speech Production
▶ Voice, Forensic Evidence of
▶ Voice Device
References
1. Huang, X., Acero, A., Hon, H.W.: Spoken Language Processing.
Prentice Hall PTR, Upper Saddle River, NJ (2001)
2. Rabiner, L., Schafer, R.: Digital Processing of Speech Signals.
Prentice Hall, Upper Saddle River, NJ (1978)
3. Deller, J., Hansen, J., Proakis, J.: Discrete-Time Processing of
Speech Signals, 2nd edn. Wiley, New York (1999)
4. Chu, W.C.: Speech Coding Algorithms. Foundation and Evolu-
tion of Standardized Coders. Wiley, New York (2003)
5. Oppenheim, A., Schafer, R., Buck, J.: Discrete-Time Signal Pro-
cessing. 2nd ed. Prentice Hall, Upper Saddle River, NJ (1999)
Speech Input Device
▶ Voice Device
Speech Input Device
S
1289
S