Li S.Z., Jain A.K. (eds.) Encyclopedia of Biometrics
Подождите немного. Документ загружается.


France, and China. Other participants have been from
Canada, various European countries, Singapore,
Australia, Israel, and South Africa.
Most of the sites participating in the NIST evalua-
tions have been from academic institutions. Some
government funded research institutions or companies
involved in government research have also partici-
pated. Not frequently represented, however, have
been smalle r commercially oriented companies. This
may be due in part to the text-independent and re-
search oriented type of evaluation being conducted,
but also bespeaks a reticence to participate in evalua-
tions where competitors may show superior perfor-
mance results.
Evaluation requires a performance measure. For
detection tasks there are inherently two types of error.
There are trials where the target is present (target
trials) but a ‘‘false’’ decision is made by a system.
Such errors are misses. And there are trials where the
target is not present (non-target or impostor trials) but
a ‘‘true’’ decision is made. These are referred to as false
alarms. Thus it is possible to speak of a miss rate for
target trials and a false alarm rate for non-target trials.
The NIST evaluations have used a linear combi-
nation of these two error rates as its primary evaluation
metric. A decision cost function (DCF) is defined as
DCF ¼ C
Miss
P
Miss Targetj
P
Target
þ C
FalseAlarm
P
FalseAlarm NonTarget
j
ð1 P
Target
Þ
where C
Miss
represents the cost of a miss, C
FA
the cost
of a false alarm, and P
Target
the prior probability of a
target trial. These are three somewhat arbitrary and
certainly application dependent parameters. The NIST
evaluations have used parameter values as hereunder.
These have been viewed as reasonable parameters
for applications involving an unaware user, where
most spe ech segments examined are likely to be of
someone other than the target of interest, but where
detecting instances of the target have considerable
value. Note that P
Target
need not represent the actual
target richness of the evaluation trials, but may be
chosen based on possible applications of interest. The
NIST evaluations have generally had an approximately
ten to one ratio of non-target to target trials, to mini-
mize the variance of the metric in the light of the
parameter values chosen.
A detection task inherently involves two types of
error, and a system may be expected to be able to tune
its performance to vary the relative frequency of the
two error types. In the NIST evaluations, systems have
been required to produce not only a decision, but also
a score for each trial, where higher scores indicate
greater likelihood that the correct decision is ‘‘true’’.
A decision threshold may then be varied based on this
score to show different possible operating points or
tradeoffs between the two types of error. Note that the
evaluations have required that this threshold be the
same for all target speakers.
The most informative way of presenting system
performance in the NIST SRE’s has been to draw a
curve showing the operating points and the tradeoff in
the error rates. This is easily done by varying the
decision threshold based on the scores provided. A
simple linear plot is know as an ROC (Receiver Opera-
tor Characteristic) curve, but a clearer presentation is
obtained by putti ng both error rates on a normal
deviate scale to produce what NIST has denoted a
DET (Detection Error Tradeoff) curve [4]. This has
the nice property that if the underlying error distri bu-
tions for the miss and false alarm rates are normal, the
resulting curve is linear.
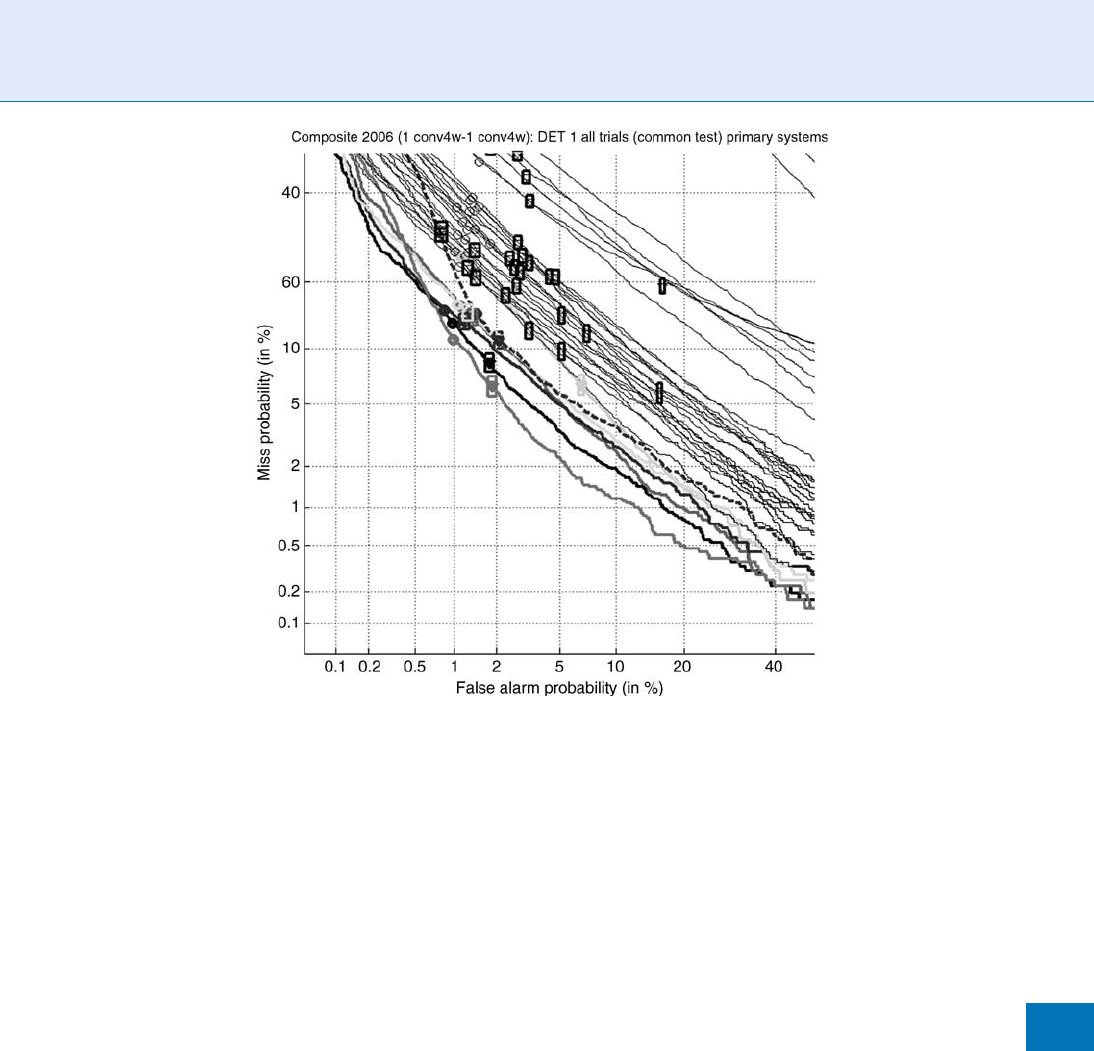
Figure 1 shows
▶ DET curves for the systems in the
core test done in the 2006 NIST SRE. These a re curves
representing the performance of the primary systems
submitted by over 30 sites participating in the evalua-
tion. Better systems have performance curves closer
to the lower left corner of the plot. The actual decision
point of each performance curve is denoted by a
triangle, and a 95% confidence box is drawn around
these, while circles are used to denote the points
corresponding to the minimum DCF operating points.
The closer these two specially denoted points on each
curve, the better the system did at calibrating its deci-
sion threshold for hard decisions. For example, for the
best performing system shown, the actual decision
point has a false alarm rate of about 2% and a miss
rate of about 7%, while the minimum DCF point has a
false alarm rate of about 1% and a miss rate of about
11%. This gives a sense of the level of current state-of-
the-art performance for speaker detection on this type
of telephone data.
C
Miss
C
FalseAlarm
P
Target
10 1 0.01
1250
S
Speaker Databases and Evaluation
A possible alternative non-parametric information
theoretic type of metric has been proposed to be appli-
cable to a range of applications, and has been included
as an alternative measure in the most recent NIST
evaluations, provided the system specifies that its like-
lihood scores may be viewed as log likelihood ratios.
This metric is discussed in [5].
While the basic detection task has remained fixed,
there have been multiple test conditions in most
of the evaluations, and these conditions have varied
over the years. In particular there has been variation
in the durations of the training and test segments.
While the earlier evaluations focused on landline
phones and the varying types of telephone handsets
(carbon-button vs. electrets microphone), in the new
millennium there is was greater focus on the effect of
cellular transmission and newer types of handsets as
these became common in the U.S. Certain additional
data sources, such as a small FBI forensic database and
a Castilian Spanish corpus know n as AHUMADA
(both apparently not currently easily available) were
used in one or two evaluations.
The earlier evaluations used fixed durations of
speech, as determined by an automatic speech detector.
Later evaluations allowed more variation in duration
within each test condition. Starting in 2001 there was
greater interest in longer durations for training and
test. This was largely as a result of some research
suggesting that with effective word recognition, higher
level lexical information about a speaker could be
effectively combined with more traditional lower level
acoustic information [6]. As a result of the apparent
success of such an approach in the 2001 evaluation,
a major summer research program was carried out at
Johns Hopkins University in the summer of 2001 (see
http://www.clsp.jhu.edu/ws2002/groups/supersid/).
Since then, ‘‘extended’’ training conditions, where the
training consists of multiple (often eight) conversation
sets have been a major part of the evaluations. The
earlier NISTevaluations are described further in [7–9].
The introduction of Mixer data in 2004 inaugu-
rated a new era in the NIST evaluations. The inclusion
of calls in multiple languages and cross language
trials introduced a new wrinkle that affected overall
Speaker Databases and Evaluation. Figure 1 DET (Detection Error Tradeoff) Curves for the primary systems of
participating sites on the core test of the 2006 NIST SRE.
Speaker Databases and Evaluation
S
1251
S
performance. The latest evaluations have also intro-
duced test conditions involving multiple microphones
and cross channel trials, that will be a major focus
in 2008 and beyond. The recent SRE’s are discussed
in [10–12].
Have the evaluations shown progress in perfor-
mance capabilities over the years? They have, but
changes in the test conditions from year to year and
in the types of data used have complicated perfor-
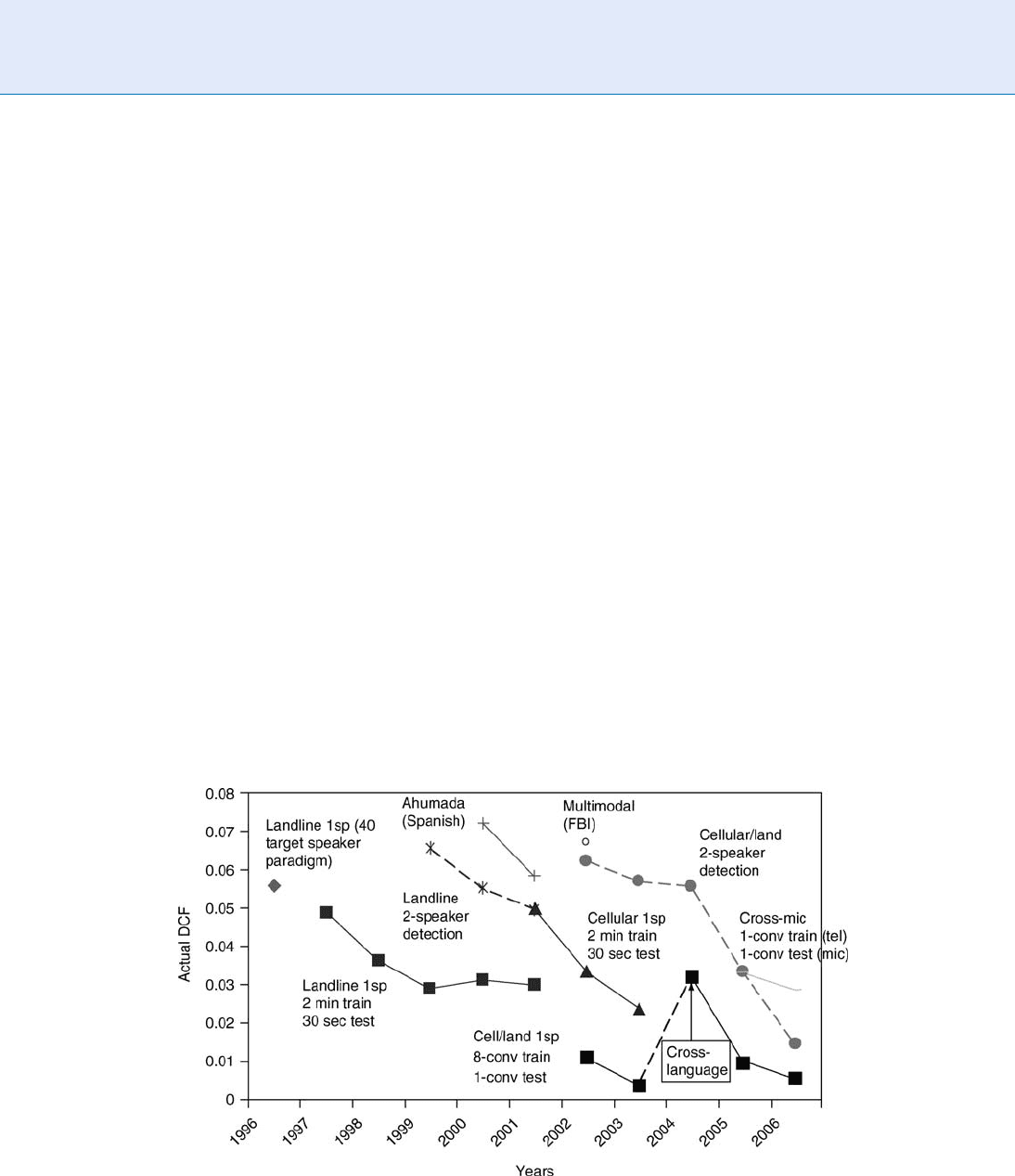
mance comparisons. Figure 2 from [13] attempts to
sort these matters out, and summarizes the DCF scores
of the best evaluation systems across ranges of years
involving more or less consistent test conditions.
The NIST SRE’s have been the most notable eva-
luations in speaker recognition in recent years. They
have concentrated on a basic speaker detec tion task
not tied to any specific current commercial applica-
tion. This has made it possible for a large range of
research sites around the world to participate in these
evaluations.
One other notable evaluation in the field was con-
ducted by TNO in the Netherlands in 2003. It featured
a protocol ver y similar to that of the NIST evaluations,
but utilized actual forensic data provided by the Dutch
police. Its very interesting results are discussed in [14],
but the data used was only provided to the evaluation
participants for a limited time and purpose and is not
otherwise available.
Other efforts have been less successful. Research in
speaker recognition technology has been advanced by
the series of Odyssey workshops. These were held
in Martigny, Switzerland in 1996, Avignon, France in
1998, Crete, Greece in 2001 (where the name ‘‘Odys-
sey’’ was adopted), Toledo, Spain in 2004, San Juan,
Puerto Rico in 2006, and Stellenbosch, South Africa
in 2008. For the 2001 workshop an evaluation track
was include d. This included both a text-independent
track based on the preceding NIST evaluation, and
a text-dependent track. Participation, particularly in
the text-dependent track, was very limited, perhaps
demonstrating the difficulty of persuading companies
or organizations to participate in this inherently appli-
cation specific and more immediately commercially
oriented field.
The European Union has sponsored a multi-year
program to develop biometric technologies deno-
ted as ‘‘BioSecure’’ (http://www.biosecure.info/), with
speaker as one of the included technologies. Evaluation
is intended to be part of this program, in particular
including evaluation of the fusion of multiple bio-
metrics. As of 2007, however, speaker recognition
evaluation appears not to have begun.
Speaker Databases and Evaluation. Figure 2 DCF (Decision Cost Function) values for the best (lowest DCF) systems
on different roughly comparable evaluation conditions over multiple years during the course of the NIST SRE’s from
1996 to 2006.
1252
S
Speaker Databases and Evaluation

The NIST evaluations will resume in 2008, and
may be held in alternate years in the future. They will
feature an increased emphasis on cross channel recog-
nition. Whereas in 2005 and 2006 the core test involved
only telephone speech, with cross channel (tr ain on
telephone, test on microphone) as an optional addi-
tional test, the core test condition is expected to
require processing of a mix of training or test segments
including both telephone and microphone speech,
with some of the trials including different channels in
training and test. This will utilize at least both types of
data as in Mixer 3 and Mixer 5. Evaluation perfor-
mance, however, will be subsequently analyzed to dis-
tinguish performance on telephone, microphone, and
cross-channel trials. A number of different micro-
phone types from the Mixer 5 data will be included.
Related Entries
▶ Performance Evaluation, Overview
▶ Speaker Recognition, Overview
References
1. Cieri, C., Campbell, J.P., Nakasone, H., Miller, D., Walker, K.:
The Mixer Corpus of Multilingual, Multichannel Speaker
Recognition Data, LREC 2004: Fourth International Con-
ference on Language Resources and Evaluation, Lisbon (2004)
2. Cieri, C., Andrews, W., Campbell, J.P., Doddington, G., Godfrey,
J., Huang, S., Liberman, M., Martin, A., Nakasone, H.,
Przybocki, M., Walker, K.: The Mixer and Transcript Reading
Corpora: Resources for Multilingual, Crosschannel Speaker Rec-
ognition Research, LREC 2006: Fifth International Conference
on Language Resources and Evaluation (2006)
3. Cieri, C., Corson, L., Graff, D., Walker, K.: Resources for New
Research Directions in Speaker Recognition: The Mixer 3, 4 and
5 Corpora, Interspeech 2007, Antwerp (August 2007)
4. Martin, A.F., et al.: The DET cur ve in assessment of detection
task performance. In: Proceedings of Eurospeech ’97, vol. 4,
pp. 1899–1903. Rhodes, Greece (September 1997)
5. Brummer, N., du Preez, J.: Application-independent evaluation
of speaker detection. Comput. Speech Lang. 20(2–3), 230–275
(April–July 2006)
6. Doddington, G.: Speaker recognition based on idiolectal differ-
ences between speakers. In: Proceedings of Eurospeech ’01,
vol. 4, pp. 2521–2524. Aalborg, Denmark (September 2001)
7. Martin, A.F., Przybocki, M.A.: The NIST speaker recognition
evaluations: 1996–2001. In: Proceedings of 2001: A Speaker
Odyssey, pp. 39–43. pp. 39–43. Chainia, Crete, Greece ( June
2001)
8. Martin, A.F., Przybocki, M.A., Campbell, J.P.: The NIST speaker
recognition evaluation program. In: Wayman, J. (eds.) et al.:
Biometric Systems: Technology, Design and Performance Evalu-
ation, Chapter 8, pp. 241–262. ?pp. 241–262. Springer, Berlin
(2005)
9. Przybocki, M.A., Martin, A.F.: NIST speaker recognition evalua-
tion chronicles. In: Proceedings of Odyssey 2004: The Speaker
and Language Recognition Workshop. Toledo, Spain (2004)
10. Przybocki, M.A., Martin, A.F., Le, A.N.: NIST speaker recogni-
tion evaluation chronicles – Part 2. In: Proceedings of Odyssey
2006: The Speaker and Language Recognition Workshop.
San Juan, PR (2006)
11. Przybocki, M.A., Martin, A.F., Le, A.N.: NIST speaker recogni-
tion evaluations utililizing the mixer corpora – 2004, 2005, 2006.
IEEE Trans. Audio Speech Lang. Process. 15(7), (2007)
12. Martin, A.F.: Evaluations of automatic speaker classification
systems. In: Muller, C. (ed.) Speaker Classification I, pp. 313–
329. pp. 313–329. Springer, Berlin (2007)
13. Reynolds, D.A.: Keynote talk. In: Proceedings of Odyssey
2008: The Speaker and Language Recognition Workshop.
Stellenbosch, South Africa (January 2008)
14. van Leeuwen, D.A., et al.: NIST and NFI-TNO evaluations
of automatic speaker recognition. Comput. Speech Lang.
20(2), 128–158 (2006)
Speaker Detection
Speaker detection means determining whether or not a
particular speaker is present in an audio stream. The
term multispeaker detection refers to the task of deter-
mining whether a particular known speaker is speaking
in an audio stream containing speech from multiple
speakers.
▶ Speaker Segmentation
Speaker Diarization
This task consists of segmenting a conversation involv-
ing multiple speakers into homogeneous parts, which
contain the voice of only one speaker, and grouping
together all the segments that correspond to the same
speaker.
▶ Speaker Segmentation
Speaker Diarization
S
1253
S
Speaker Features
DANIEL RAMOS,JAV I E R GONZALEZ-DOMINGUEZ,
D
OROTEO T. TOLEDANO,
J
OAQU I N GONZALEZ-RODRI
´
GUEZ
ATVS – Biometric Recognition Group. Escuela
Politecnica Superior, Universidad Autonoma de
Madrid, Spain
Synonyms
Observations from speech; Speaker parameters
Definition
Speaker features are measurements extracted from the
speech signal with the objective of determi ning the
identity of a given speaker. In voice biometrics, speaker
features whose source is known are typically used to
build
▶ speaker models. Then, speaker features of un-
known source are compared with the enrolled models
in order to obtain measures of similarity. The identity
of the speaker influences the speech production pro-
cess in many different ways, due to vocal tract configu-
ration, language spoken, social context, education, etc.
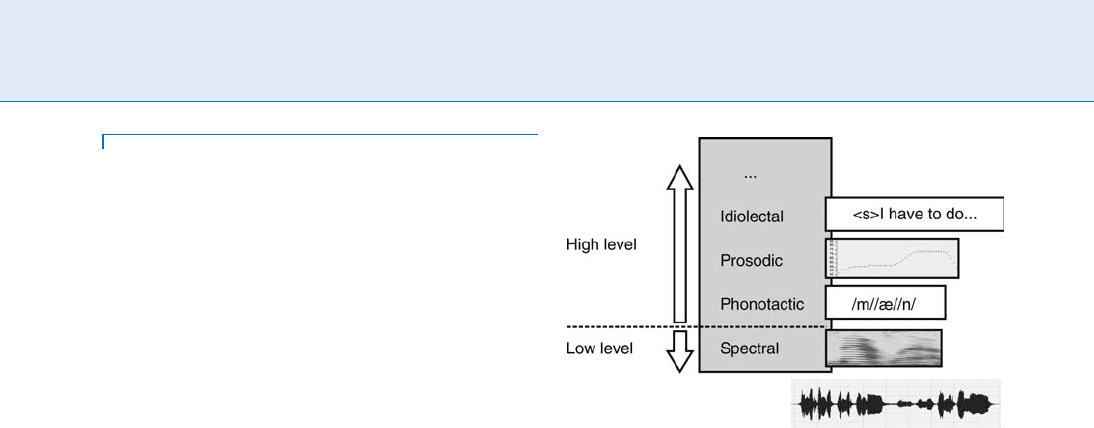
Thus, several levels of identity can be identified in the
speech signal, e.g., spectral, phonetic, prosodic, etc.
Speaker features can be extracted at any of this identity
levels, and therefore the speaker recognition process
follows in essence a multilevel approach.
Identity Information in the Speech
Signal
The ▶ identity levels in the speech signal are config-
ured by the speech production process, which is the
subject of study of phoneticians and other areas such as
engineering, physics or signal processing [1, 2, 3, 4].
There are two main stages in voice production: (1) lan-
guage generati on and (2) speech production; and
speaker specifi cities are introduced in both compo-
nents. In the field of speaker recognition these two
components correspond to so-called high-level (lin-
guistic) and low-level (spectral) characteristics. Auto-
matic speaker recognition systems will intend to take
advantage of the different sources of information avail-
able in the speech signal, combining them in the best
possible way for every speaker [5, 6]. Figure 1 illus-
trates these different identity levels in the speech signal.
The information extracted in each of these groups of
levels can be summarized as follows:
Spectral level. The information about the speaker
identity is extracted from the spectrum of the
speech signal, analyzed in short-time windows.
The spectrum of the speech signal is directly related
to the dynamic configuration of the vocal tract,
which presents speaker-dependent specificities.
Higher levels. Several sublevels can be found
here. For instance, at the phonotactic level, the infor-
mation about the identity of the speaker is embedded
in the particular use of the phones and syllables and
their realizations. At the prosodic level, parameters
like instantaneous energy, intonation, speech rate,
and unit durations are analyzed, which are known
to be speaker-dependent. At the idiolectal level, the
information about speaker identity relies on the par-
ticular use of the words and language in general,
which depends not only on the speaker, but also on
many other sociolinguistic conditions.
Short-Term Spectral Feature
Extraction
The analysis at spectral level of the speech signal is
based on classic Fourier analysis. However, an exact
definition of Fourier transform cannot be directly ap-
plied becaus e speech signal cannot be considered
Speaker Features. Figure 1 Identity levels in the speech
signal.
1254
S
Speaker Features
stationary due to constant changes in the articulatory
system within each speech utterance.
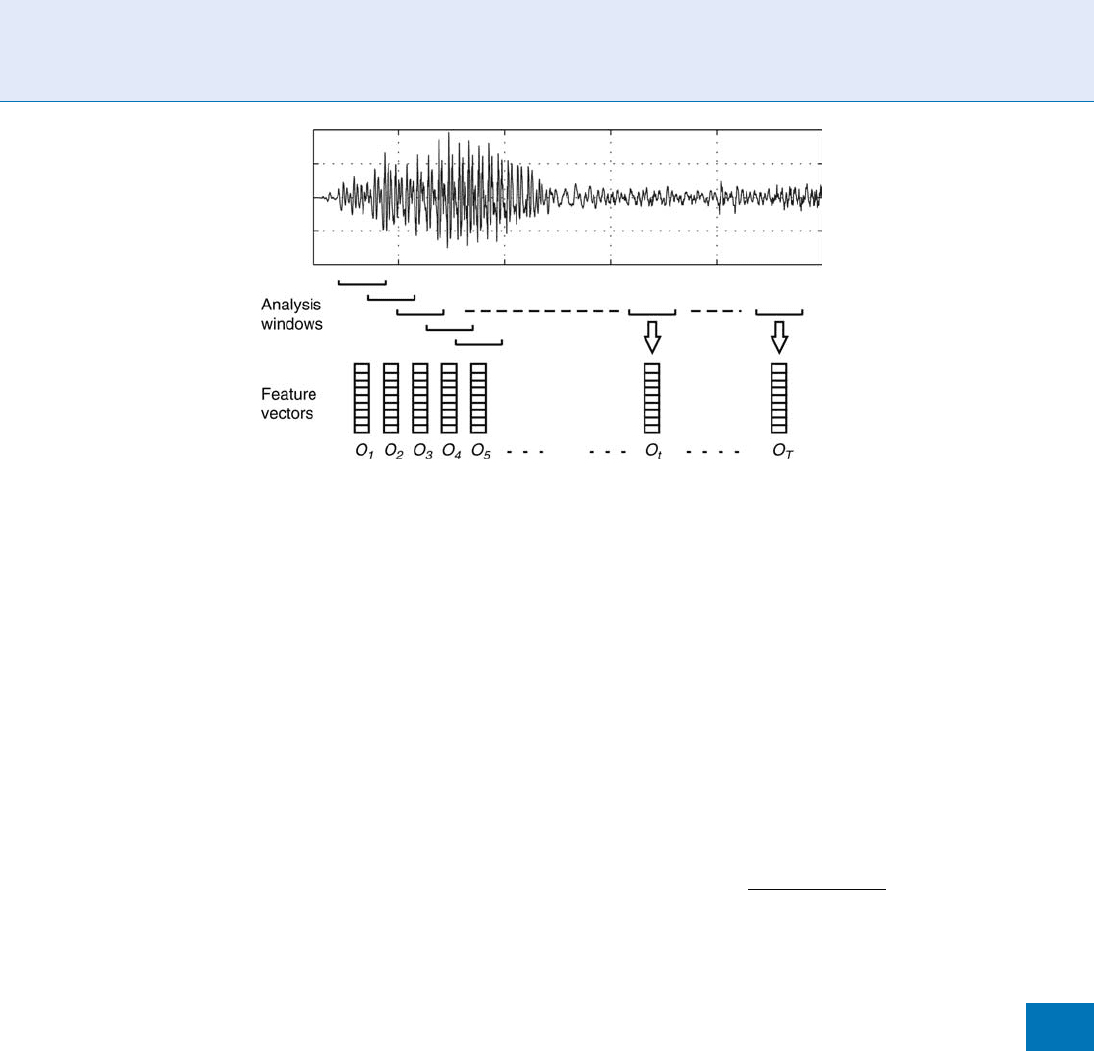
To solve these problems, speech signal is split into a
sequence of short segme nts in such a way that each one
is short enough to be considered pseudo-stationary.
The length of each segment, also called window or
frame, ranges between 10 and 40ms (in such a short-
time period our articulator y system is not able to
significantly change). Finally, a feature vector will be
extracted from the shor t-time spectrum in each win-
dow. The whole process, known as short-term analysis,
is depicted in Fig. 2.
Signal representation or coding from short-term
spectrum into a feature vector is one of the most
important steps in automatic speaker recognition and
continues being subject of research. Many different
techniques have be en proposed in the literature and
generally they are based on speech production models
or speech perception models. Most widely used tech-
niques in the state of the art are described as follows.
Linear Predictive Coding (LPC) method, introduced
in [7], is based on the assumption that a speech
sample can be approximated by a linearly weig hted
summation of a determined number of preceding
samples. In time domain, this can be represented as
s
½n¼
X
p
k¼0
ak½sn k½: ð1Þ
Here, s
∗
[n] is the approximation, or prediction,
of the speech signal, and a [k] are the LPC coeffi-
cients calculated to minimize the total square error
E ¼
X
n
e½n
2
; ð2Þ
where e[n] is the error between the real signal
value s [n] and predicted value s
∗
[n], defined as
e½n¼s½ns
½n¼s½n
X
p
k¼1
ak½sn k½: ð3Þ
In the domain of the z-transform, a [k] para-
meters define an all-pole filter H(z), as defined
in [1, 7].
HzðÞ¼
1
1
P
p
k¼1
ak½z
k
: ð4Þ
LPC has proved to be a valid way to compress
the spectral envelope in an all-pole model with just
10–16 coefficients [1, 3]. Figure 3 shows the rep-
resentation of the envelope of the short-time spec-
trum at a given window as modeled by LPC.
However, LPC coefficients are strongly correlated
among them, which is an undesirable characteris-
tic. Therefore,
▶ cepstrum transform [3, 8] has
been proposed in order to obtain pseudo-orthogo-
nal cepstral coefficients, yielding Linear Prediction
Cepstral Coefficients (LPCC).
Mel-Frequency Cepstral Coefficients (MFCC) pro-
posed in [9] are the most extensively used para-
meters at the spectral level in automatic speaker
recognition systems. The MFCC method first uses a
mel-scale filterbank in order to obtain some coeffi-
cients from the power spectrum of the speech win-
dow. The main aim of mel filtering is to mimic
Speaker Features. Figure 2 Short-term feature extraction.
Speaker Features
S
1255
S
the human hearing behavior by emphasizing lower
frequencies and penalizing higher frequencies. Thus,
a mel filterbank analyzes the power spectrum using a
logarithmic scale. First, a transformation is applied
according to the following formula:
f
m
¼ 1; 125 log 1 þ f =700ðÞ; ð5Þ
where f is the linear frequency . Second, a filterbank is
applied to the amplitude of the mel-scaled spectrum f
m
in
order to obtain a vector of outputs from each filter .
Figure 4 shows a typical mel filterbank in the fre-
quency domain. The centers f [m] of the filters H
m
[k]
are uniformly spaced in the mel scale. Using a DFT
of the input signal withN points each filter H
m
[k]is
given by
H
m
k½¼
0 k < fm1½
kfm1½ðÞ
fm½fm1½ðÞ
fm1½k fm½
fmþ1½kðÞ
fmþ1½fm½ðÞ
fm½k fm½
0 k > fmþ1½;
8
>
>
>
>
>
>
>
>
<
>
>
>
>
>
>
>
>
:
ð6Þ
where 0<k<N.
Once filtering is carried out, cepstrum transform is
applied to the filter outputs in order to obtain mel
frequency cesptrum coefficients.
Speaker Features. Figure 3 LPC modeling of short-term spectrum. The envelope is determined by the LPC filter
coefficients defined in Eq. 4 .
Speaker Features. Figure 4 Triangular mel-filter bank for typical MFCC feature extraction.
1256
S
Speaker Features

Perceptual Linear Prediction (PLP) was proposed
in [10]. Here, speaker features are calculated in a
similar way as LPC coefficients, but previous trans-
formations are carried out in the spectrum of each
window aiming at introducing knowledge about
human hearing behavior. Details can be found in
[10].
As we mentioned earlier, the main aim of the
described methods is to extract a feature vector for
each frame or window. However, in this independent
analysis possible useful information such as coarticula-
tion can be lost. In order to take this kind of information
into account, velocity (D) and acceleration (DD) coeffi-
cients are usually obtained from the static window-
based informati on. This D and DD coefficients model
the speed and acceleration of the variation of cepstral
feature vectors across adjacent windows.
High-Level Tokenization
At phonotactic and idiolectal levels, tokenization is the
translation from sampled speech into a time-aligned
sequence of linguistic units, or tokens. Hidden Markov
Models (HMM) [11] are widely used for phone, sylla-
ble, and word tokenization. HMM as used in speech
processing are finite stat e machines which model the
temporal dependency of spectral feature vectors in a
probabilistic way [1, 11 ]. The performance of the toke-
nization may be improved by the use of language
models, which impose some linguistic or grammatical
constraints on the high number of combinations of all
possible units (phones, sy llables or words) [1].
Basic prosodic features as pitch and energy are also
obtained at a frame level. The instantaneous pitch
can be determined by, e.g., autocorrelation or cepstral-
decomposition based methods, usually smoothed with
some time filtering [2]. Other important prosodic fea-
tures are those related to linguistic units duration,
speech rate, and all those related to accent. In all
those cases, precise segmentation is required [1, 12],
i.e., determination of the points in the speech signal
where each unit occurs.
Recently, Nonuniform Extraction Region Features
(NERF) have been proposed for obtaining high level
features [13]. This technique is based on including
high-level information in the spectral information at
each short-time frame.
Summary
The information about the identity of the speaker
extracted from a speech utterance is represented by
the speaker features, which can be obtained at different
levels. The essay presented the main approaches for
speaker feature extraction at the short-time spectral
level and at higher levels. The widely used MFCC,
LPCC, and PLP features have been described, and
several approaches of phonetic and prosodic tokeniza-
tion have been sketched. Such features will be used to
build the models and to compare them with test speech
segments in a given voice biometric system.
Related Entries
▶ Feature Extraction
▶ Speaker Matching
▶ Session Effects on Speaker Modeling
▶ Speaker Recognition, Overview
▶ Speech Analysis
References
1. Huang, X., Acero, A., Hon, H.W.: Spoken Language Processing:
A Guide to Theory, Algorithm and System Development. Pren-
tice Hall PTR, Upper Saddle River, NJ (2001)
2. Rabiner, L.R., Schafer, R.W.: Digital Processing of Speech Sig-
nals. Prentice Hall, Englewood Cliffs, NJ (1978)
3. Deller, J.R., Hansen, J.H.L., Proakis, J.L., Discrete-Time Proces-
sing of Speech Signals, 2nd Ed. Wiley, New York (1999)
4. Gonzalez-Rodriguez, J., Toledano, D.T., Ortega-Garcia, J.: Voice
biometrics. In: Anil K. Jain, Patrick Flynn and Arun A. Ross
(eds.) Handbook of Biometrics. Springer, Berlin (2007)
5. Reynolds, D.A.: The SuperSID project: Exploiting high-level
information for high-accuracy speaker recognition. In: Proceed-
ings of ICASSP (2003)
6. Doddington, G.: Speaker recognition based on idiolectal differ-
ences between speakers. In: Proceedings of Eurospeech,
pp. 2517–2520. Aalborg, Denmark (2001)
7. Makhoul, J.: Spectral analysis of speech by linear prediction.
IEEE Trans. Audio Electroacoust. 21, 140–148 (1973)
8. Furui, S.: Cepstral analysis technique for automatic speaker
verification. IEEE Trans. Acoust. Speech, Signal Processing 29,
254–272 (1981)
9. Bridle, J.S., Brown, M.D.: An experimental automatic word
recognition system. Technical Report 1003, Joint Speech Re-
search Unit, Ruislip, Eng land (1974)
10. Hermansky, H., Hanson, B., Wakita, H.: Perceptually based
linear predictive analysis of speech. In: Proceedings of ICASSP,
Vol.10, pp. 509–512. (1985)
Speaker Features
S
1257
S
11. Rabiner, L.R.: A tutorial on hidden markov models and selected
applications in speech recogniton. Proc. IEEE 77, 257–286 (1989)
12. Toledano, D.T., Hernandez-Gomez, L., Villarrubia-Grande, L.:
Automatic phonetic segmentation. IEEE Trans. Speech Audio
Process 11, 617–625 (2003)
13. Kajarekar, S., Ferrer, L., Sonmez, K., Zheng, J., Shriberg, E.,
Stolcke, A.: Modeling NERFs for speaker recognition In: Pro-
ceedings of Odyssey, pp. 51–56 Toledo, Spain (2004)
Speaker Identification and
Verification, SIV
▶ Speaker Recognition, Standardization
Speaker Indexing
The process of determining, who is talking when, is an
integral element of speech data monitoring and
content-based data mining applications.
▶ Speaker Segmentation
Speaker Matching
JEAN-FRANC¸OIS BONASTRE,DRISS MATROUF
LIA - CERI University of Avignon, Avignon, France
Synonyms
Speaker recognition engine; Voice biometric engine
Definition
Speaker matching aims to compare the acquired data
corresponding to an individual against the template
feature set stored in the database. Depending on the
operating mode, the comparison could be done using
only the template related to a given person (detection
or verification tasks) or with all the templates of the
database (identification task).
The speaker matching could be split into three
main functionalities:
Create a template from the feature set extracted
from the enrollment data. Usually, the template is
denoted ‘‘speaker model.’’
Compare a feature set acquired from a sound cap-
tor with a speaker model and output a likelihood
score.
Take an identification decision using this score.
Usually other information are used during this
decision phase, like a model of potential impostors.
In a speaker recognition system, the scores are very
often normalized before to take the decision, using
a
▶ Score Normalization technique.
Introduction
Two main classes of approaches are usually used for
speaker matching:
Direct matching. This kind of approaches don’t
really use a modeling of the speaker voice: the en-
rollment voice sample is used directly as a model
and a similarity function between two voice samples
is used for the score computation. If the time syn-
chronization aspects are taken into account, a dy-
namic time warping algorithm is used in order to
find the best time alignment between the enroll-
ment acoustic feature sequence and the test feature
test sequence.
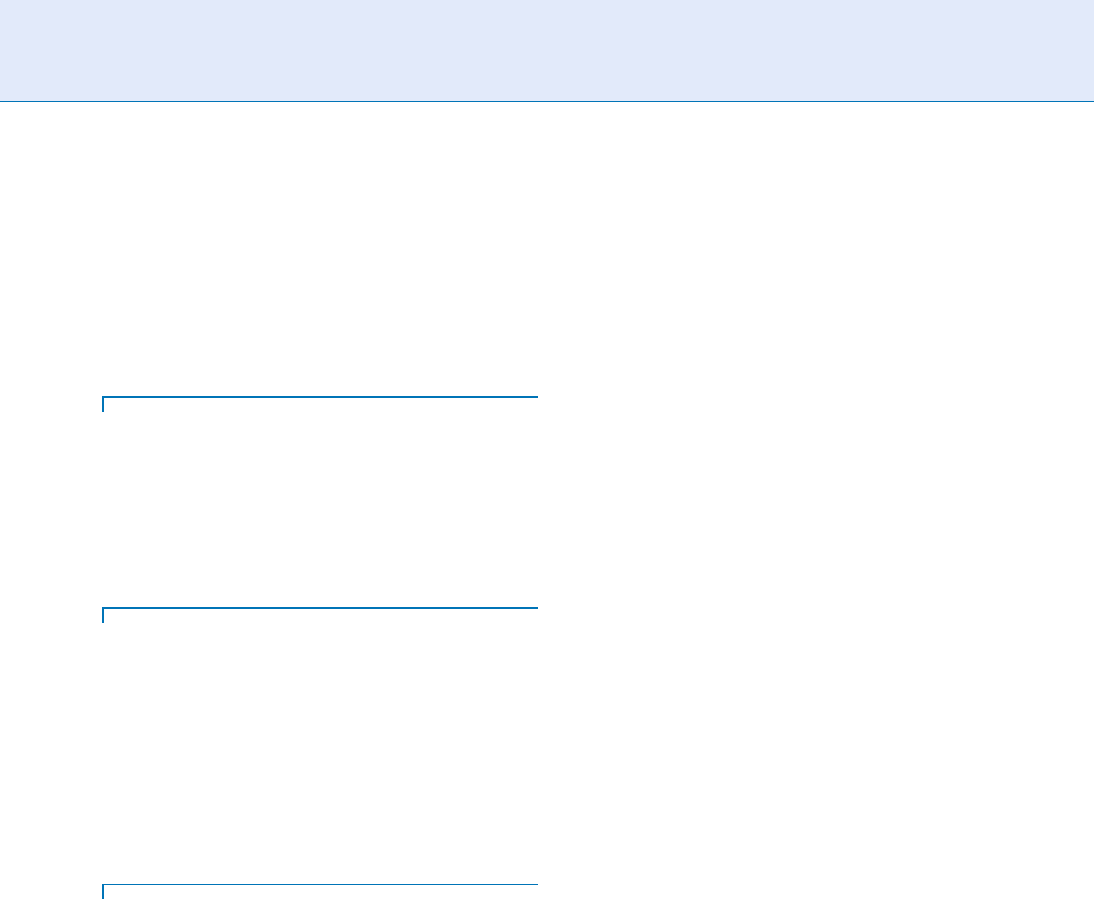
▶ Dynamic Time Warping (DTW)
[1, 2] involves a strong dependency on the text
pronounced by the individuals: the text should be
the same during the enrollment and the recogni-
tion phases, the message should have a short dura-
tion (few seconds). The Fig. 1 illustrates the DTW
main principles. For text independent systems,
where the text pronounced by the individuals
could be different between the enrollment and the
recognition phases, a
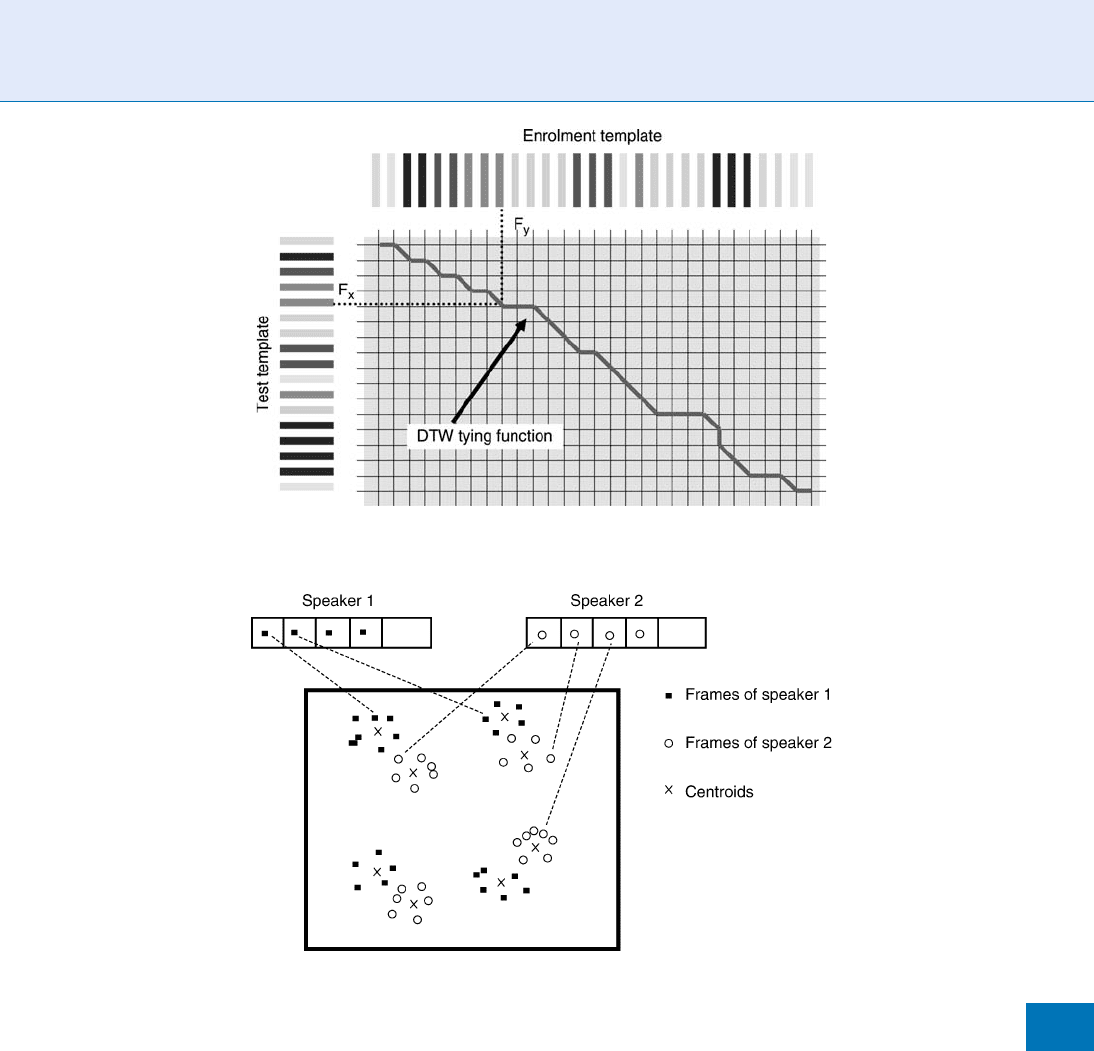
▶ Vector Quantification
(VQ) algorithm is used [2]. The main principle of
VQ is illustrated in Fig. 2. In this case, the VQ
codebook could be seen as a model, but it is in
fact close to a data reduction of the enrollment
sample: only a subset of the feature vectors
extracted from the enrollment data are kept and
the other are withdrawn. The main advantage of
these methods is the low level of needed computer
resources. These methods are also efficient in terms
1258
S
Speaker Identification and Verification, SIV
of identification performance if the variability fac-
tors like utterance text content, microphone or
environmental noises are controlled [1, 3].
Machine learning approaches. In this class of meth-
ods, a speaker voice model is learnt using one or
several enrollment recordings. During the test, the
likelihood of the test data is computed using this
model. Two kind of methods are used: the statis-
tical modeling techniques (mainly GMM or HMM)
and the discriminative classification techniques
(mainly neural networks and SVM). Recently,
mixed approaches were proposed, where a statistical
approach (based on GMM) is used to deal with the
data variability and a discriminative classifier is used
for the decision estimation (SVM).
This chapter will describe more precisely the
Machine Learning based approaches, which associate
the GMM and the SVM.
GMM-UBM (GMM-MAP) Approach
GMM-UBM is the predominate approach used in
speaker recognition systems, particularly for text-
independent task [4]. This approach is based on a
Speaker Matching. Figure 1 DTW principle.
Speaker Matching. Figure 2 Frames distribution of two speakers in the acoustic space. Each speaker can be
characterized by its own distribution modes (centroids).
Speaker Matching
S
1259
S