Li S.Z., Jain A.K. (eds.) Encyclopedia of Biometrics
Подождите немного. Документ загружается.


7. Fauve, B., Bredin, H., Karam, W., Verdet, F., Mayoue, A.,
Chollet, G., Hennebert, J., Lewis, R., Mason, J., Mokbel, C.,
Petrovska., D.: Some results from the biosecure talking face
evaluation campaign. In: Proceedings of the IEEE International
Conference on Acoustics, Speech and Signal Processing. Las
Vegas, USA (2008)
8. Humm, A., Hennebert, J., Ingold, R.: Spoken signature for user
authentication. SPIE J. Electron. Imaging, Special Section on
Biometrics: ASUI 17(1) (2008)
9. Rabiner, L., Juang, B.H.: Fundamentals of Speech Recognition.
Prentice Hall (1993)
10. Picone, J.: Signal modeling techniques in speech recognition.
Proc. IEEE 81(9), 1214–1247 (1993)
11. Reynolds, D.: Automatic speaker recognition using gaussian
mixture speaker models. Linc. Lab. J. 8(2), 173–191 (1995)
12. Reynolds, D.: An overview of automatic speaker recognition
technology. In: Proceedings of the IEEE International Confer-
ence on Acoustics, Speech and Signal Processing, vol. 4,
pp. 4072–4075 (2002)
Speaker Recognition,
Standardization
JUDITH MARKOWITZ
Consultants, Chicago, IL, USA
Synonyms
Speaker authentication; Speaker biometrics; Speaker
identification and verification, SIV; Voice authentica-
tion; Voice recognition
Definition
The term ‘‘speaker recognition’’ (SR) refers to a group
of technologies that use information extracted from a
person’s speech to perform biometric operations such
as speaker identification and verification (SIV). Stan-
dards for SR are designed to support the development
of applications that can work with technology from
different vendors (application programming inter-
face standards), the sharing of SR data (data inter-
change standards), the transmission of data in real
time (distributed speaker recognition standards), and
the management of data resources in distributed envir-
onments (process-control protocol standards).
Introduction
SR technologies stand at the juncture between ▶ speech-
processing and biometrics. They belong in speech pro-
cessing, because they extract and analyze data from the
▶ stream of speech. They belong in biometrics, because
the data that are extracted describe a physical or be-
havioral characteristic of the speaker and because they
use that information to make decisions regarding the
speaker, usually determining the identity of the speaker
and verifying a claim of identity. Some SR technologies
perform other speaker-related functions, such as plac-
ing the speaker into a category, such as female or
male (
▶ speaker classification); determining whether
the speaker has change d (speaker change); assessing the
speaker’s level of stress or emotion (emotion detection,
voice stress analysis); tracking a specific voice in a
multispeaker communication (speaker/voice track-
ing); separating interleaved and overlapping voices
from each other (
▶ speaker separation); and determin-
ing whether the speaker is lying or telling the truth
(voice lie detection).
Standards for SR come from both speech processing
and from biometrics. They fall into several categories:
1. Application programming interface (API) standards,
2. Sharing of stored SR data (data interchange),
3. Transmission of data in real time (distributed speaker
recognition) and
4. Management of data resources in distributed envir-
onments (process-control protocols).
Application Programming Interface (API)
Standards – Early Work
API standards eliminate the need for programmers
to learn a new set of programming functions for each
SR product. They accomplish this by establishing
a standard set of functions that can be used to
develop applications using any standards-compliant
SR technology.
The bulk of the work on SR standards has been
directed toward the development of standard APIs.
Most of these standards have been crafted by speech-
processing industry consortia or standards bodies and
are extensions of existing standards for
▶ speech
recognition.
1270
S
Speaker Recognition, Standardization

The first and, to date, the most detailed API standard
is the Speaker Verification API (SVAPI) [1, 2]. SVAPI was
constructed by a speech- and biometrics-industry con-
sortium formed in 1996, whose work was sponsored by
Novell Corporation. The goal was to develop a com-
panion to Speech Recognition API (SRAPI), an API
standard for speech recognition on the PC desktop.
SVAPI is a low-to-midlevel standard that covers
enrollment, verification, identification, and speaker
classification with some support for speaker separation.
It handles both centralized and distributed deployments
and includes the functionality for specifying features of
the stream of speech, the inclusion of several types of
normalized scoring, and the characterization of input
from both microphones and telephones. SVAPI consists
of a set of callable Dynamically Linked Library (DLL)
functions. It is written in C++ and Java and runs under
Windows on desktop platforms.
SVAPI 1.0 was released in 1997, but work on the
specification stopped shortly thereafter and the stan-
dard remains largely unsupported. Despite its short life
as a standard, SVAPI has had a lasting impact on API
standards in both biometrics and speech processing.
Work on SVAPI inspired the development of a high-
level, generic API for biometrics that was developed by
The National Registry, Inc. (NRI) under contract with
an agency of the US Department of Defense. The result-
ing specification called Human Authentication API
(HA-API) [3] w as the precursor to the BioAPI specifi-
cation of the BioAPI Consortium (www.bioapi.org).
Proof-of-concept testing began early in 1998 and was
performed on five commercial biometric products,
including one SR product.
HA-API was designed for desktop platforms run-
ning 32-bit Windows operating systems. It supported
stand alone and client–server implementations. HA-API
operations required by SR, such as adaptive updating
voice models (called ‘‘adaptation’’), were retained
when HA-API evolved into the BioAPI specification.
The S.100 Media Resources and Service Protocol [4]
was developed by the Enterprise Computer Telephony
Forum (ECTF). It was an API standard for using
speech recognition (ASR) in computer-telephony.
Support for speaker verification and identification was
added to S.100 version 2 in the form of two parameters:
ASR_ECTF_Verification and ASR_ECTF_Identification.
Their role was to extend the functionality of speech
recognition (ASR) technology. ‘‘When supported,
the ASR resource may be used for speaker identification
and speaker verification, e.g., by training a context with
▶ utterances from a particular speaker [4].’’
API Standards – Current Work
VoiceXML is an XML scripti ng language for develop-
ing speech applications for
▶ interactive voice response
(IVR) applications over the telephone. It is the
dominant standard for ASR and text-to-speech syn-
thesis. Its developers, the World Wide Web Consor-
tium (W3C) and the VoiceXML Forum, are defining
an SR module for the next version of VoiceXML
(version 3.0). The Forum’s Speaker Biometrics Com-
mittee (SBC) has identified the requirements for
the module, and the W3C’s Voice Browser Work-
ing Group is constructing the actual specification.
When completed, the SR module will become part
of a network of speech-processing standards for ser-
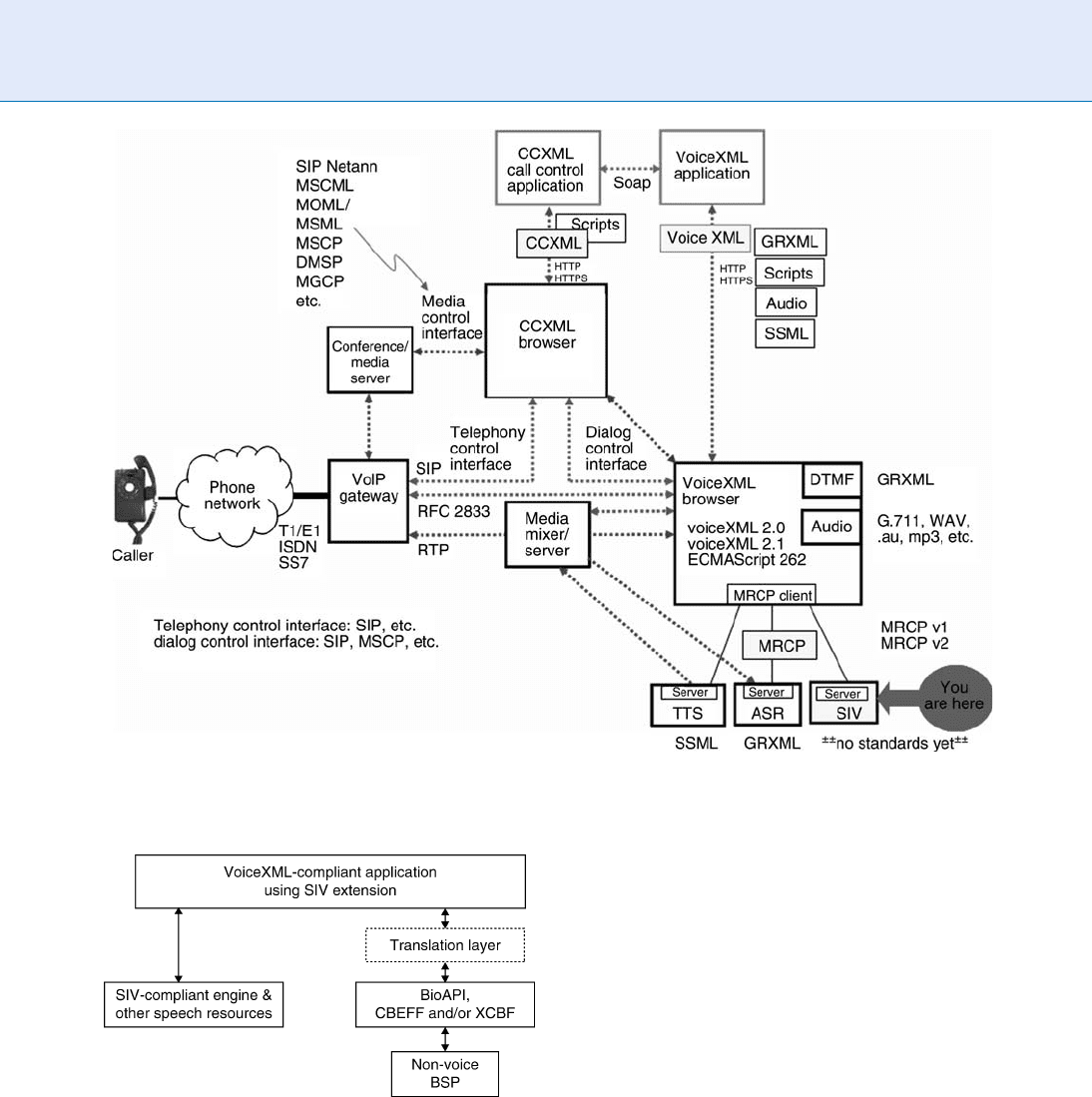
vices-oriented architecture. Figure 1 shows the net-
work and indicates where the SR module (called
‘‘SIV’’) will fit.
The SBC has published several documents related
to its work on the Forum’s web page (http://www.
voicexml.org/biometrics):
1. SIV Glossary [6],
2. SIV Applications [7] a review of existing and po-
tential SR applications, and
3. Speaker Identification and Verification (SIV)
Requirements for VoiceXML Applications [8].
The requirements document specifies the basic func-
tions that an API standard for speaker verification and
identification mu st support: enrollment, verification,
identification, and supervised adaptation. It also estab-
lishes a three-phase ‘‘session’’ as the basic unit of oper-
ation. Those phases are
1. Designation – when the function is specified (e.g.,
verification), and preparatory events occur (e.g., claim
of identity)
2. Audio processing – when speech samples are col-
lected and analyzed and decisions are rendered
3. Cleanup – when temporary files and data are
purged and the sess ion is concluded.
The document denotes a set of basic properties,
including various kinds of thresholds (e.g., decision
Speaker Recognition, Standardization
S
1271
S
threshold, adaptation threshold), timeout s, and limits
(e.g., minimum number of utterances required to per-
form verification). It defines allowable concurrent and
nested sessions and provides support for multifactor
applications. As shown in Fig. 2, the requirements
document also indicates how a VoiceXML SR module
might work with the generic biometric standard, the
BioAPI specification.
Data Interchange Standards
Data exchange/interchange standards support the
sharing and reuse of enrollment, verification, and iden-
tification data. They are needed by a broad spectrum of
operations requiring interoperability, such as product
upgrades that are not backwards compatible, security
audits, inter-bank customer support, and multiagency
intelligence and law-enforcement investigations.
They facilitate the exchange of SR data by providing a
structure that not only transmits the data but also
offers a controlled description of those data. The data
exchanged by a data interchange standard may be raw,
partially-processed/feature data, or fully-processed
model/template data.
The VoiceXML Forum and Technical Committee
M1 (Biometrics) of the InterNational Committee for
Speaker Recognition, Standardization. Figure 1 Network of standards for speech processing [5].
Speaker Recognition, Standardization. Figure 2
Relationship of a VoiceXML module for SR and the BioAPI
specification.
1272
S
Speaker Recognition, Standardization
Information Technology Standards (INCITS) [9] are
collaborating on the development of an American
National Standard for SR. As its name suggests, the
draft standard Speaker Recognition Format for Raw
Data Interchange (SIVR-1) supports the interchange
of raw SR data. SIVR-1 is a format for describing
the data being transmitted for a single SR session. It
supports enrollment, verification, and identifica-
tion operations. Work on SIVR began in 2005 and
the standard is currently wending its way through
separate approval processes by INCITS and the
VoiceXML Forum.
SIVR-1 defines two headers: ‘‘Session’’ and ‘‘In-
stance.’’ It also supports the inclusion of nonstandardized
data (called ‘‘extended’’ data). Since SIVR-1 is an XML
standard, it also specifies an XML schema.
Each SIVR-1 compliant format has a single Session
header. Table 1 contains a subset of the XML elements
included in the Session header. The Session header
contains information that remains constant through-
out the session. Those elements include the date and
time the session took place, the total amount of utter-
ance data included in the sess ion, characteristics of
the channel and input device, and a description
of the data.
These elements are governed by existing standards.
For example, the syntax of the DateAndTime element
must comply with ISO 8601 2004(E) Data Elements
and Interchange Formats – Interchange Formats -
Representation of Dates and Times [10]. Although se-
curity is essential for protecting data stored in an
SIVR-1 format, that element is optional to avoid con-
flict with external security and identity management
technologies that may be applied.
Elements in Table 1 that are ‘‘complex type’’ are
themselves made up of elements. Table 2 displays sev-
eral of the elements that make up the AudioFor-
matHeader, which defines the data that are stored in
and transmitted using SIVR-1.
The element AudioFormat specifies the audio for-
mats to be used to store data in the format. These
audio formats are widely used open standards.
An SIVR-1 format must contain at least one In-
stance Header. Each Instance contains information
that can change from one of the speaker’s utteran ces
to the next within the Session. Instances also contain
the raw data of the utterance. Table 3 displays some of
the elements in the SIVR-1 Instance header.
As Table 3 reveals, each Instance in a Session is
assigned a number. SIVType is included, because
Speaker Recognition, Standardization. Table 1 Representative Elements of SIVR-1 Session Header
Name Status Data Type Value(s)
Purpose Required String Verification
Identification
Enrollment
Multiple
Other
Channel Required Complex type
AudioFormatHeader Required Complex type
Security Optional Complex type
Speaker Optional Complex type
Input device Optional Complex type
Speaker Recognition, Standardization. Table 2
Elements in audio format header
Name Status
Data
Type Value(s)
Byte Order Required hexBinary 0Xff00
Streaming Required boolean 0 or 1
AudioFormat Required string LinearPCM
Mu-Law
A-Law
OGG Vorbis
OGG Stream
Samplingrate Required Integer Samples per
second
BitsPer
Sample
Required Integer
Speaker Recognition, Standardization
S
1273
S

different Instances can utilize different kinds of SR
technolog y as the following examp le illustrates.
Instance 1 Investigator: ‘‘Please say your rank.’’
Speaker: ‘‘Corporal’’
Instance 2 Investigator: ‘‘Please say your ID
number’’
Speaker: ‘‘7398722’’
Instance 3 Investigator: ‘‘Where were you on the
night of March 5, 2007?’’
Speaker: ‘‘I was home alone.’’
ASRUsed is included, because some of the instances
may use ASR, while other instances may not. It is more
likely, for example, that ASR would be used for
instances 1 and 2, which are the
▶ text-prompted and
▶ text-dependent technology than for instance 3, which
is text-independent and requires a different type of ASR.
As w ith the elements of the Session header, the
complex type element Utterance consists of several
other elements that include the quality of the raw
audio data and audio-format information that deviates
from the default values specified in the AudioFor-
matHeader element of the Session.
In 2007, the Joint Technical Committee 1 (JTC 1) of
the International Standards Organization (ISO) and the
International Electrotechnical Commission (IEC) ap-
proved a project for the development of an international
standard under JTC1 Subcommittee 37 – Biometrics
(No. 1.37.19794–13, Voice data) that is similar in
scope to the INCITS/VoiceXML project. This project
differs from the INC ITS/VoiceXML project in that it is
developing binary and XML versions and will have
header for standardized feature as wel as far raw data.
Distributed Speaker Recognition
Standards
The real-world conditions under which SR must oper-
ate are not always optimal. SR data are captured by an
increasingly diverse spectrum of heterogeneous, third-
party input devices that process the data, using one of a
growing number of standard audio formats so that they
can be transmitted over telecommunications and data
networks. Those networks (called ‘‘channels’’) differ in
their acoustic characteristics, bandwidths, and quality.
These variables affect the performance of even the most
accurate SR technology and are represented in the data-
interchange headers presented in the previous sections.
One method for reducing the impact of differences
in data quality and processing associated with input
devices and channels is to embed tech nology into
input devices that perform standardized preprocessing
and feature extraction before the data are sent over the
channels. If those operations produce the features that
are needed to perform speech recognition or SR, the
embedded technology is called ‘‘distributed speech/
speaker recognition’’ (DSR).
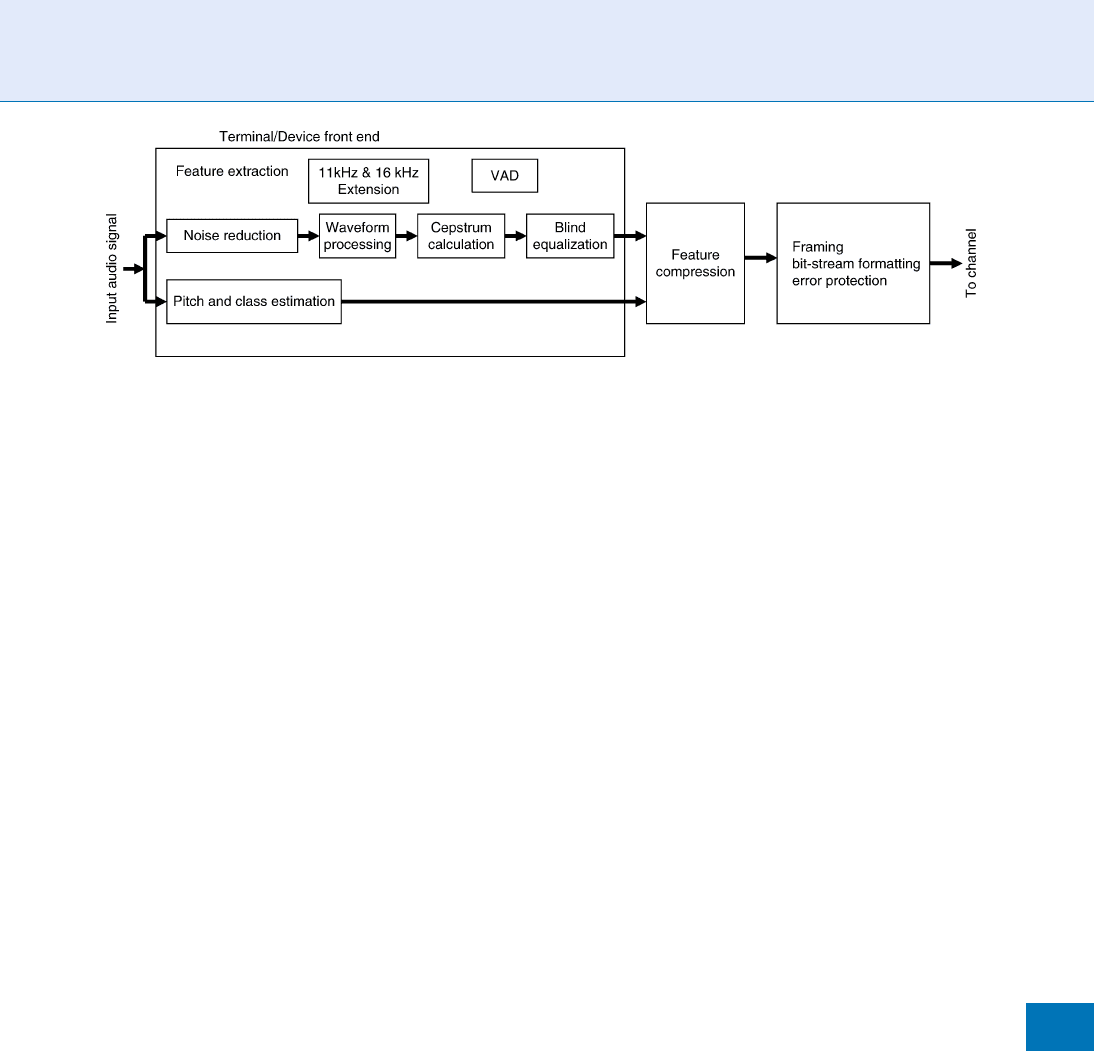
In 2000, the European Telecommunications Stan-
dards Institute (ETSI) published a standard for extracting
those common featur es [11] in support of speech rec-
ognition. As Fig. 3 indicates, the embedded technology
(‘‘terminal front end’’) performs error-reduction, noise
reduction, compression, and other operations in addi-
tion to feature extraction before transmitting the data.
Work is now being done to extend ETSI DSR to SIV.
In order to accomplish that, several additional features
need to be extracted from the speech signal [12].
Since most developers of speech recognition and
SR technology use a core set of common features, the
development of a DSR standard seems reasonable. The
problem facing ETSI DSR and other DSR standards is
Speaker Recognition, Standardization. Table 3
Representative Elements of SIVR-1 Instance Header
Name Status
Data
Type Value(s)
Instance
number
Required Integer
SIVType Required String Text-dependent
Text –prompted
Text-
independent
Unknown
ASRUsed Required String Yes
No
Unknown
Type of Prompt
Content
Required String None
Text
Binary
Pointer
Both
Utterance Required Complex
type
1274
S
Speaker Recognition, Standardization
that each speech recognition and SR vendor approaches
feature extracting in a unique way and those differences
are considered to be part of the vendor’s ‘‘secret sauce.’’
Process-Control Protocols
Process control/data transport standards facilitate real-
time communications among the disparate elements of
a system. They enable applications, servers, input
devices, and SR technology to exchange data in real
time quickly, effectively, and smoothly. This is parti-
cularly important in the burgeoning web-services/
services-oriented architecture (SOA) environment,
which often involves complex network interactions
among different kinds of ‘‘nodes.’’ Those nodes include
devices (e.g., telepho nes), resources (e.g., an SR prod-
uct), applications , and servers.
One standard that is used to support SR in SOA is
the Simple Object Access Protocol (SOAP). SOAP is
a W3C standard for exchanging messages (called a
‘‘data transport protocol’’) that can be used over
HTTP and HTTPS (for secured transpor t). It allows
one network node (e.g., a client) to send a message to
another node (e.g., a browser or server) and to get an
immediate response. SOAP is a generic data-transport
protocol; it makes no mention of SR and does not
address issues of special concern to tr ansmission of
audio data.
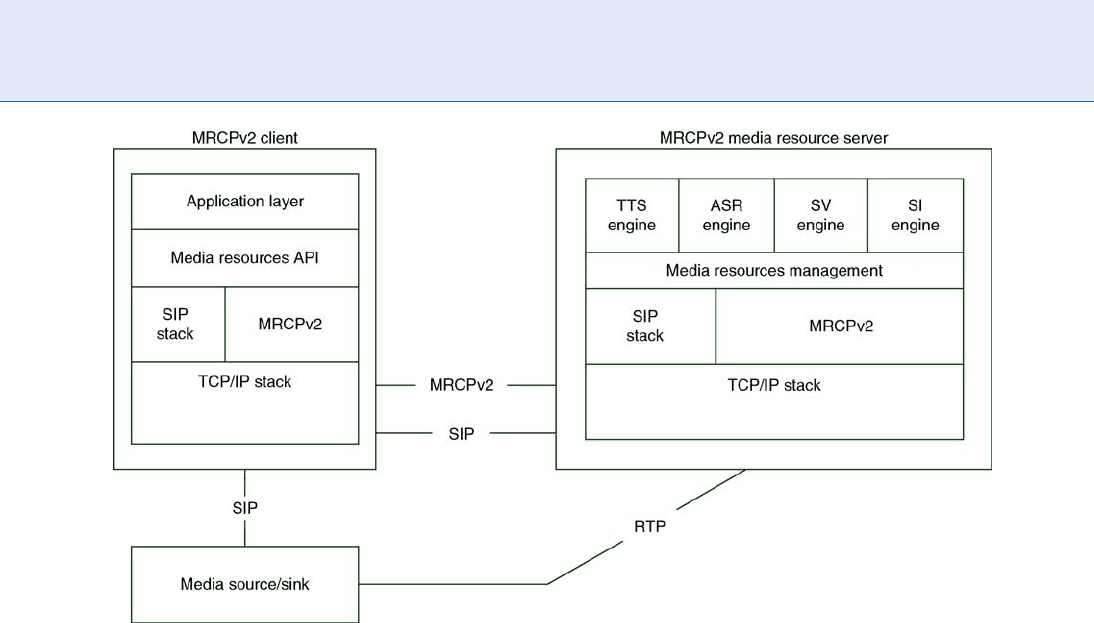
Unlike SOAP, the Media Resources Control Protocol
(MRCP) was created specifically to control voice-
related resources and to support the transpor t of
speech data in SOA and IVR environments. As shown
in Fig. 4 , MRCP mediates between the servers that
house the speech and SR technologies (called ‘‘media
processing resources’’) and applications or other enti-
ties on the network (called ‘‘clie nts’’) that need to
communicate with them. Figure 4 provides a more
detailed view of the architecture of MRCPv2.
MRCPv2 specifies the messages that can be sent
between the two parties, how the resources are to be
used, and how these messages are to be carried over a
transport layer. Figure 4 shows the two parties involved
in the communication (client, resource server); the
speech-processing resources that may be involved;
and how the Session Initiation Proto col (SIP), the
Transmission Cont rol Protocol (TCP), and Real-Time
Transport Protocol (RTP) are utilized.
An interaction between a client and a media re-
source server is called a ‘‘session.’’
A separate session may be created for each resource
(e.g., a speaker-verification product and an ASR prod-
uct) or a single session may involve multiple resources.
For example, it supports the establishment of a single
session for ASR and spe aker verification that allows
both resources to operate on the same utterances. The
client uses Session Initiation Protocol (SIP) to start
and end sessions and to establish an MRCP control
channel with the media server so that the client can use
the server’s media processing resources. Once that is
accomplished, MRCP-compliant messages can be sent
between the client and the server. The SIP-labeled
line between the client and the server, as shown in
Fig. 4, indicates that SIP is also used to ensure that
messages and audio are properly sent and received.
The commands/functions for speaker verification
and identification are the ‘‘messages’’ that enable the
client to control the SR operation within the session.
They include commands to start and end sessions, to
verify, identify, and get intermediate-level results.
MRCP is based on a requirements document that
includes speaker verification and identification among
the technologies to be supported [13], even thou gh
those technologies were not incorporated into MRCP
Speaker Recognition, Standardization. Figure 3 ETSI Distributed Speech Recognition (DSR).
Speaker Recognition, Standardization
S
1275
S
version 1. SR has been a dded to version 2, which also
addresses security considerations, prim arily for SR
sessions.
MRCP version 1 (MRCPv1) was developed jointly
by Cisco Systems, Inc., Nuance Communications, and
Speechworks Inc. and has become a widely used stan-
dard within the speech-processing industry[14].
MRCPv2 was created by a speech-industry consortium
within the Internet Engineering Technology Forum
(IETF) and is in its final stages of approval [15].
Related Entries
▶ Biometrics, Overview
▶ Common Biometric Exchange Format Framework
standards
▶ Remote Authentication
▶ Speaker Authentication
▶ Voice
References
1. Markowitz, J.: The Speaker Verification Application Program-
mers Interface Standard (SVAPI). In: Harper, D. (ed.) Biome-
triCon’97: Conference Proceeding. Diane Publishing Company,
Darby, PA (1997)
2. Novell Corporation: SRAPI and SVAPI Source Code. (2006).
http://developer.novell.com/wiki/index.php/SRAPI_and_SVAPI_
Source_Code
3. Colombi, J.: Interface Specification: Human Authentication –
Application Program Interface (HA-API) Ver. 2.0. United States
Biometrics Consortium, Fort Meade, MD, (1998)
4. Enterprise Computer Technology Forum: S.100 Media Services
Volume 6: Media Resources and Services, Revision 2.0 (1998).
http://www.comptia.org/sections/ectf/Documents/s100r2v6.pdf
5. Markowitz, J., Rehor, K.: Standards for speaker recognition.
In: Proceedings of Biometric Consortium’06, Baltimore, MD
(2006)
6. Skerpec, V. (ed.): Speaker Identification and Verification (SIV)
Glossary. VoiceXML Forum (2007). http://www.voicexml.org/
biometrics/
7. Daboul, C., Eckert, M. (eds.): Speaker Identification and Verifi-
cation Applications. VoiceXML Forum (2006). http://www.
voicexml.org/biometrics/
8. Daboul, C., Shinde, P (eds.): Speaker Identification and Verifi-
cation (SIV) Requirements for VoiceXML Applications Ver. 2.0.
VoiceXML Forum (2007). http://www.voicexml.org/biometrics/
9. INCITS 456, Speaker Recognition Format for Raw Data Inter-
change (SIVR) (2008). http://www.techstreet.com/incitsgate.
tmpl
10. ISO, ISO 8601 2004(E) Data Elements and Interchange Formats –
Interchange Formats – Representation of Dates and Times.
Geneva: International Standards Organization (2004)
11. European Telecommunications Standards Institute: Distributed
Speech Recognition; Front-end feature extraction algorithm;
Compression algorithms. ETSI document ES 201 108 V1.1.2
2000–04 (2000)
Speaker Recognition, Standardization. Figure 4 MRCPv2 Architecture.
1276
S
Speaker Recognition, Standardization

12. Broun, C.C., Campbell, W.M., Pearce, D., Kelleher, H.:
Distributed speaker recognition using the ETSI distributed
speech recognition standard. In: Proceedings of the Internation-
al Conference on Artificial Intelligence, pp. 1:244–248 (2001).
http://nsodl.org/resource/2200/2006H
13. Oran, D.: Requirements for Distributed Control of Automatic
Speech Recognition (ASR), Speaker Identification/Speaker Veri-
fication (SI/SV), and Text-to-Speech (TTS) Resources, Internet
Informational RFC 4313 (2005). http://www3.tools.ietf.org/
html/rfc4313
14. Shanmugham, S., Monaco, P., Eberman, B.: A Media Resource
Control Protocol (MRCP) Internet Informational RFC 4463,
(2006). http://www.ietf.org/rfc/rfc4463.txt
15. Shanmugham, S., Burnett, D.: Media Resource Control Protocol
Version 2 (MRCPv2) (2007) NOTE: This is draft 17. As of
December, 2008 it was the current draft. Upon final approval a
stable IETF Internet Informational RFC reference number will
be assigned. http://tools.ietf.orglid
Speaker Segmentation
LAURA DOCIO-FERNAND EZ,CARMEN GARCIA-MATEO
Department of Signal Theory and Communications,
University of Vigo, Vigo, Spain
Synonyms
Speaker change detection; Speaker clustering; Speaker
diarization
Definition
Speaker segmentation is the process of partitioning an
input audio stream into acoustically homogeneous
segments according to the speaker identity. A t ypical
speaker segme ntation system finds potential speaker
change points using the audio characteristics.
Introduction
Segmenting an audio–visual stream by its constituent
speakers is essential in many application domains.
First, for audio–visual documents, speaker changes
are often considered natural points around which to
structure the document for navigation by listeners
(
▶ speaker indexing). In broadcast news, for example,
speaker changes typically coincide with story changes
or transitions. Audio recordings of meetings, presenta-
tions, and panel discussions are also examples where
organizing audio segments by speaker identity can
provide useful navigational cues to listeners. Further-
more, an accurate speaker segmentation system is also
necessary for effective audio content analysis and
understanding, audio information retrieval, speaker
identification-verification-tracking, and other audio
recognition and indexing applications. In fact, speaker
segmentation is an important subproblem of the
▶ speaker diarization task, which is used to answer
the question Who spoke when?. Speaker segme ntation
focuses on finding out when a person is speaking and
the main goa l is to mark where speaker changes occur,
i.e., to divide a speech signal into a sequence of speaker-
homogeneous regions. Typically, there is no prior
knowledge about the speech characteristics of the
speakers or the number of different speakers before
the process starts, so these have to be derived, in an
unsupervised manner, from the same data that are
going to be used to find the speaker changing points.
Second, speaker segmentation relates to automatic
transcription of speech. In many scenarios, the per-
formance of automatic speech recognition can benefit
greatly from speaker adaptation, whether supervised
or unsupervised. Speaker segmentation, while not a
strict prerequisite for speaker adaptation, is important
for performing adaptation on multispeaker data, as
it can provide the recognizer with homogeneous
speaker data.
Speaker segmentation has sometimes been referred to
as speaker change detection and is closely related
to acoustic change detection. It has received much atten-
tion recently. For a given audio stream, speaker segmen-
tation systems find the times when there is a change of
speaker in the audio. On a more general level, acoustic
change detection aims at finding the times when there is
a change in the acoustics in the recording, which includes
speech/nonspeech, music/speech and others. Thus,
acoustic change detection can detect boundaries within
a speaker turn when the background conditions change.
With the rapid increase in the availability of multi-
media data archives, efficient segmentation, indexing
and retrieval of audio–visual data is quite an important
task in many applications. Automatic metadata ex-
traction from video and audio recordings enables the
development of sophisticated multimedia content man-
agement applications which can help users manage their
Speaker Segmentation
S
1277
S

personal recordings. For real world audio–visual data
the text can be generated using automatic speech recog-
nition (ASR), the speaker labeled using speaker recogni-
tion, and the speaker turns and segments derived can be
used for indexing the associated audio and video.
The general unsupervised speaker segmentation
problem, in addition to not having models or other
information to help segment the speech data by speaker,
brings several additional obstacles that complicate the
task of separating the segments of one speaker from the
segments of another speaker. For example, multispea-
ker speech data typically includes several short seg-
ments. Short segments are difficult to analyze because
of the inherent instability of short analysis windows. In
addition, more than one speaker may be talking at the
same time in multispeaker speech data and the seg-
ments may be contaminated with the speech of another
speaker. Also, the accuracy of the segmentation process
is affected by background noise and/or music. This
leads to the need of modeling of these artifacts, which
in turn increases system complexity. Other difficulties
are related to the dynamic fine-tuning of some para-
meters that improve the accuracy of the segmentation
algorithms. It is also a major concern into optimizing
the system performance in terms of access times and
signal processing speed. It is highly desirable that these
segmentation tasks are accomplished automatically
with the least user intervention but additionally these
need to be performed fast and accurately.
The task of speaker segmentation can be considered
as an evolution of a Voice Activity Detection (VAD),
also referred to as Speech Activity Detection (SAD).
VAD constitutes a very basic task for most speech-
based technologies (Speech Coding, automatic speech
recognition (ASR), Speaker Recognition (SR), speaker
segmentation, voice recording, noise suppression and
others). The classification of an audio recording in
speech and nonspeech segments can be utilized to
achieve more efficient coding and recognition.
Grouping together segments from the same speaker,
i.e.,
▶ speaker clustering, is also a crucial step for
segmentation. Speaker segmentation followed by
speaker clustering is referred to as speaker diarization.
Diarization has received much attention recently. It
is the process of automatically splitting the audio re-
cording into speaker segments and determining which
segments are uttered by the same speaker. In general,
diarization can also encompass speaker verification and
speaker identification tasks.
Speaker clustering also belongs to the pattern
classification family. Clustering data into classes is a
well-studied technique for statistical data analysis, with
applications in many fields, and, in general, can be
defined as unsupervised classification of data, i.e.,
without any a priori knowledge about the classes or
the number of classes. In the speaker diarization task,
the clustering process should result, ideally, in a single
cluster for every speaker identity. The most common
approach is to use a hierarchical agglomerative cluster-
ing approach in order to group together segments
from the same speaker [1]. Hierarchical agglomerative
clustering typically begins with a large number of clus-
ters which are merged pair-wise, until arriving (ideally)
at a single cluster per speaker. Since the number of
speakers is not known a priori, a threshold on the
relative change in cluster distance is used to determine
the stopping point (i.e., number of speakers). Deter-
mining the number of speakers can be difficult in appli-
cations where some speakers speak only during a very
short period of time (e.g., in news sound bites or back
channels in meetings), since they tend to be clustered in
with other speakers. Although there are several para-
meters to tune in a clustering system, the most crucial is
the distance function between clusters, which impacts
on the effectiveness of finding small clusters.
Examples of Efforts to Foster Speaker
Segmentation Research
The Defense Advanced Research Projects Agency
(DARPA) and U.S. National Science Foundation have
promoted research in speech technologies for a w ide
range of tasks from the late 1980s. Additionally, there
are significant speech research programs elsewhere in
the world, such as European Union funded projects.
The Information Technology Laboratory (ITL) of
the National Institute of Standards and Technology
(NIST), has the broad mission of supporting U.S. indu-
stry, government, and academia by promoting U.S.
innovation and industrial competitiveness through
advancement of information technology measurement
science, standards, and technology in ways that enhance
economic security and improve our quality of life.
From 1996 the N IST Speech Group, collaborating
with several other Government agencies and research
institutions, contributes to the advancement of the
state-of-the-art in human language technologies and
1278
S
Speaker Segmentation

related multimodal technologies that employ machine
learning approaches by
Developing measurement methods and algorithms
Providing annotated corpora for development and
evaluation
Coordinating challenge-task-focused benchmark
tests
Sponsoring evaluation-oriented workshops
Building test-bed systems
Benchmark tests, implemen ted within this community
since 1987, are used to track the development of several
speech technologies. These tests, which provide diag-
nostic information that helps to identify the strengths
and weaknesses of the technology, have facilitated
increased accuracy and robustness of the t echnology
over time.
In 1996 NIST also started the 1996 ARPA CSR
Hub-4 evaluation (1996–1999). The purpose of this
evaluation is to improve the basic performance of
speaker-independent unlimited-vocabulary recogni-
tion systems using Broadcast News Sources. In this
task speaker segmentation enables speaker normaliza-
tion and adaptation techniques to be used effectively to
integrate speech recognition.
In 1997 NISTstarted the Hub-5E evaluation (1997–
2001) that focuses on the task of transcribing conver-
sational speech into text. This task is posed in the
context of conversational telephone speech.
Since 1996, NIST has also organized yearly Speaker
Recognition (SR) evaluation campaigns, focusing on the
automatic
▶ speaker detection and ▶ speaker tracking
tasks. In 2000, the NIST SR evaluation introduced the
speaker segmentation evaluation as a new task.
With the DARPA EARS (Effective, Affordable,
Reusable Speech-to-Text) program (2002–2004) the
focus moves on a new task, denoted rich transcription,
which addresses the need for systems that generate
high accuracy, readable transcripts. Here, semantic
information is not the only element of interest. Indeed,
acoustics-based information (sounds, speech qu alities,
speaker information, ...), discourse-based informa-
tion (disfluencies, emotion, ...), as well as linguistic
information (topic, named enti ties, ...) may also be
used to enrich the transcription and to help for index-
ing audio documents. Speaker characteristics are obvi-
ously an important information in this context.
The EARS program supports several evaluation
tasks that are administrated by the NIST under the
Rich Transcription (RT) heading. The specific research
tasks are broadly categorized as supporting either
Speech-to-Text (STT) or Metadata Extraction (MDE).
While STT emphasizes getting the words right, MDE is
concerned with structuring STToutput to be maximally
readable for humans and downstream automatic pro-
cesses by humans and machines. The Metadata Extrac-
tion (MDE) component is designed to enrich the raw
word sequence generated by STT systems, by introdu-
cing additional information (e.g., who is speaking, how
the word stream breaks into sentence units, how to
correct the word sequence based on verbal edits) that
plays a fundamental role not just in t ranscribing the true
speech content but also in facilitating downstream
processing by humans and machines.
For this reason, since 2003 the speaker segmenta-
tion system evaluation had joined in the Rich Tran-
scription evaluation campaigns and had left the
Speaker Recognition evaluation campaign.
The NIST RT metadata MDE task has been includ-
ing several tracks:
MDE ‘‘Who Spoke When’’ Speaker Diarization
focused on speaker segm entation and clustering.
MDE ‘‘Who Said What’’ Speaker Diarization.
MDE Speech Activity Detection.
MDE Source Localization.
Structural MDE concerned with identifying
sentence-like units and detecting disfluencies.
The RT evaluation corpora have included different
domains: broadcast news, conversational telephone
speech, conference room meetings, and lecture room
meetings. The segmentation challenges are different
for the different tasks according to their quality of
recordings, number of speakers, the speaking duration
of each speaker, and the sequence of speaker changes,
etc. But usually high-level speaker segmentation tech-
niques work well over different domains.
Operation of a Speaker Segmentation
System
A basic speaker segmentation system consists of three
main steps. First, the input signal is processed to
extract a set of acoustic features. Second, a speech/
nonspeech detector separates target speech regions
from the given audio clip. And lastly, the speaker
change detector identifies potential speaker changing
Speaker Segmentation
S
1279
S