Korb K.B., Nicholson A.E. Bayesian Artificial Intelligence
Подождите немного. Документ загружается.

T
yes
yes
no
no
D
T
F
T
F
P(F=pos|T,D)
0.995
0.02
0
0
P(F=neg|T,D)
0.005
0.98
0
0
P(F=unk|T,D)
0
0
1
1
N
Y
N
Y
−220
−60
0
−20
T U(D,T)
U
−C
0
T
Test
Disease
T
Cost
Finding
Disease
0.06
P(Disease=T)
U
Treatment
D
F
F
N
Y
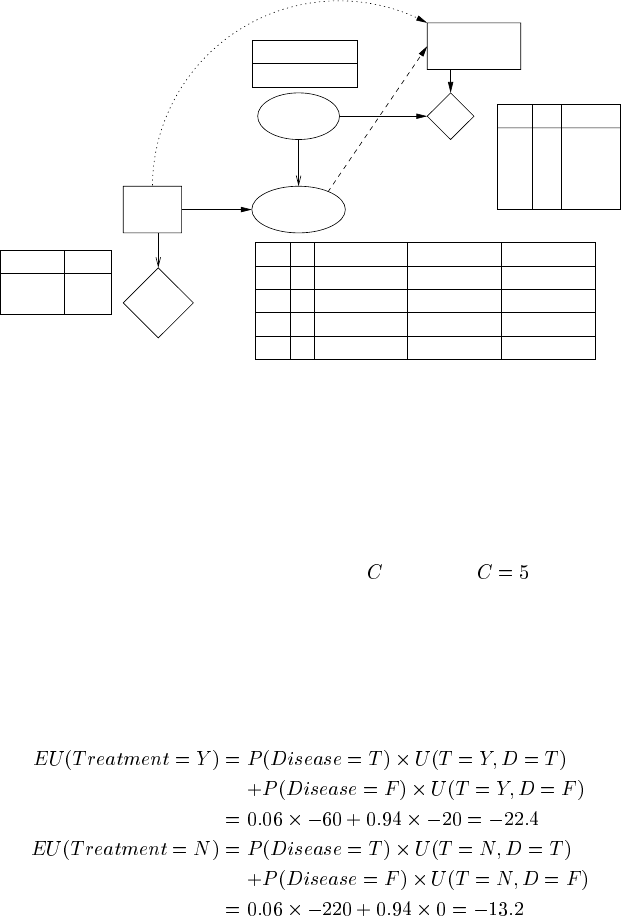
FIGURE 10.2
A decision network for disease treatment.
Let us work through such reasoning with the simple, generic decision network
shown of Figure 10.2. Here there is a single disease node and a single test findings
node. The utility is a function of the disease and the treatment decision. We would
also like to take into account the option for running the test, represented by another
decision node, which also has an associated cost,
.(Acostof is used for the
calculations in the remainder of this section.)
If we do not run the test, the probability of the disease is just the prior (0.30) and
the expected utilities of the treatment options are:
So, without a test, the decision would be not to have treatment.
© 2004 by Chapman & Hall/CRC Press LLC
T
F
no
yes
no
0.06
yes 0.94
0.06
0.94
0.078
0.922
0.239
0.761
0.239
0.761
−20
−60
−220
0
Treat
Treat
D
T
F
T
F
F
T
T
F
T
F
T
F
0.0003
0.9997
0.9997
0.0003
−C
−5.066
Treat
NO
YES
YES
NO
−22.4
−5.066
−25.013
−55.44
−55.44
−172.31
−13.2
D
D
D
D
F
D
Test
−9.02
−9.02
−13.2
−C
−60 −
C
−20 −
C
−60 −
C
−20 −
C
−220 −
C
−220 −
C
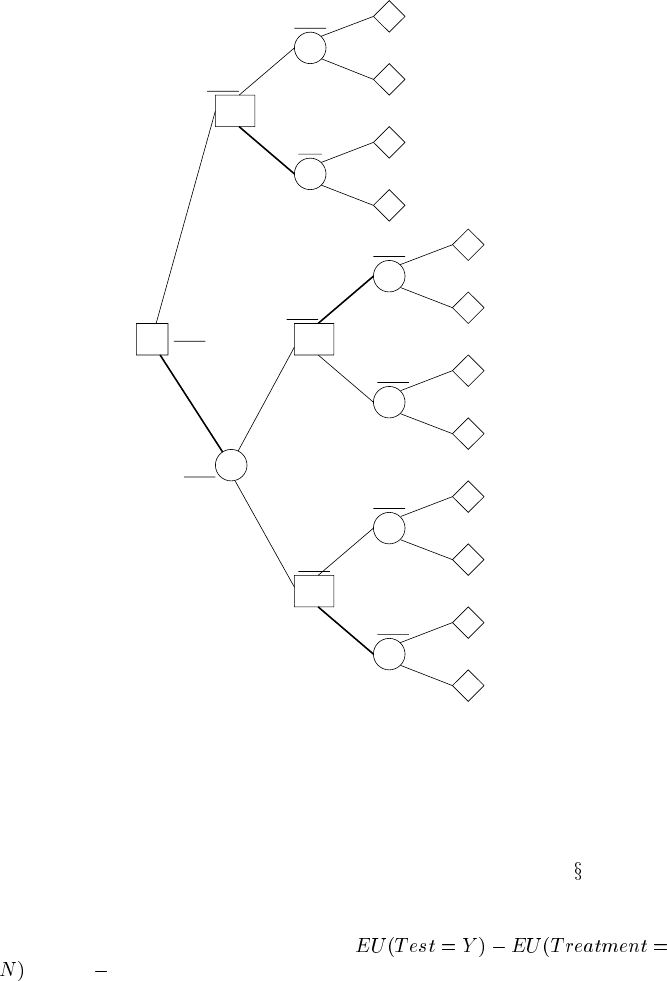
FIGURE 10.3
A decision tree evaluation of the disease test-treatment decision network.
If, on the other hand, we run the test and get a value for the findings (positive or
negative), we obtain the expected utilities of Table 10.4. The decision tree evaluation
for this problem is shown in Figure 10.3, using the method described in
4.4.3.
Hence the expected benefit of running the test, the increase in our expected utility,
is the difference between the expected utility of running the test and the expected util-
ity of our decision without the test, namely:
= -9.02 (-13.20) = 4.18.
What if there are several tests that can be undertaken? In order to determine the
best course of action, ideally we would look at all possible combinations of tests,
including doing none. This will clearly often be impractical. In such cases, a greedy
search may be used, where at each step, the single test with the highest expected
© 2004 by Chapman & Hall/CRC Press LLC

TABLE 10.4
Expected utilities given different test findings (highest
EU given in bold, indicating decision table entry)
EU Treatment
Finding Y N
positive -55.42 -172.31
negative -25.01 -5.07
benefit is chosen (if this is greater than no test). The price of practicality is that
greedy search can result in a non-optimal sequence, if the outcome of a rejected test
would have made another more informative.
10.3.2 Sensitivity to changes in parameters
Sensitivity analysis can also be applied to the parameters, checking them for cor-
rectness and whether more precision in estimating them would be useful. Most such
sensitivity analyses are one-dimensional, that is, they only vary one parameter at a
time. For many decision problems, decisions will be unaffected by the precision of
either the model or the input numbers. This phenomenon is known as a flat maxi-
mum, as it marks the point beyond which small changes in probabilities or utilities
are unlikely to affect the final decision [59]. Once a flat maximum is observed, no
more effort should be spent refining the model or its inputs. However, even when a
network may be insensitive to a change in one of its parameters, it may well still be
sensitive to changes in combinations of parameters. As always, testing all possible
combinations of parameters is exponentially complex.
It is plausible that the elicitation process can be supported by interactively per-
forming sensitivity analyses of the network during construction, starting with initial
rough assessments [57]. A sensitivity analysis indicates which probabilities require a
high level of accuracy and which do not, providing a focus for subsequent elicitation
efforts.
One can approach sensitivity analysis of BNs either empirically (e.g., [146, 56])
or theoretically (e.g., [167, 150]). The empirical approach examines the effects of
varying the parameters on a query node. It requires first identifying reasonable ranges
for each parameter, then varying each parameter from its lowest to its highest value
while holding all the other variables fixed. The changes in the posterior probability
of the query node may be quantified with a measure such as entropy (see above). Or
when we are concerned with decision making, we can identify at what point (if any)
changes in a parameter can change the decision.
The theoretical approach instead determines a function expressing the posterior
probability of the query node in terms of the parameters. For example, Laskey [167]
computes a partial derivative of the query node with respect to each parameter. In
addition to not requiring additional assessment by the expert, often this function can
be computed efficiently by a modification of the standard inference algorithms.
The two approaches can be used together, by first having a theoretical approach
© 2004 by Chapman & Hall/CRC Press LLC

identify parameters with potentially high impact, then reasonable ranges can be as-
sessed for these, allowing one to compute the sensitivity empirically.
For some time there was a belief common in the BN community that BNs are gen-
erally insensitive to inaccuracies in the numeric value of their probabilities. So the
standard complaint about BNs as a method that required the specification of precise
probabilities (“where will the numbers come from?”) was met with the rejoinder that
“the numbers don’t really matter.” This belief was based on a series of experiments
described in [221], which was further elaborated on in [107]. Clearly, however, the
inference that insensitivity is general is wrong, since it is easy to construct networks
that are highly sensitive to parameter values (as one of the problems in
10.9 shows).
Indeed, more recent research has located some real networks that are highly sen-
sitive to imprecision in particular parameters [146, 279, 41]. The question of how
to identify such sensitive parameters, clearly an important one from a knowledge
engineering perspective, is a current research topic.
There is as yet only limited support in current BN software tools for sensitivity
analysis; see
B.4.
Disease treatment example
Before we leave this topic, let us briefly look at an example of how a decision may
be sensitive to changes in parameters, using the generic disease “test-treatment” se-
quential decision network from Figure 10.2. Figure 10.4 shows how the expected
utilities for the test decision (y-axis) vary as we change a parameter (x-axis), for
three different parameters.
(a) The test cost, C: While EU(Test=N) does not change, we can see that the test
decision will change around the value of C=9.
(b) U(Disease=F,Treatment=Y): In this case, the change in decision from “no” to
“yes” occurs between -5 and -6.
(c) The prior, P(Disease=T): Here, the decision changes between 0.03 and 0.04.
10.4 Case-based evaluation
Case-based evaluation runs the BN model on a set of test cases, evaluating the results
via expert judgment or some kind of prior knowledge of the domain. Test cases can
be used either for component testing, where fragments of the BN are checked, or
for whole-model testing, where the behavior of the full BN is tested. The results
of interest for the test will depend on the domain, sometimes being the decision, or
a diagnosis, or again a future prediction. Ideally, cases would be generated to test
a wide variety of situations, possibly using the boundary-value analysis technique
of software engineering: choosing inputs at the extreme upper and lower values of
© 2004 by Chapman & Hall/CRC Press LLC

-25
-20
-15
-10
-5
0
0
5
10
15
20
EU
Test Cost C
X
Test=yes
Test=no
-14
-13
-12
-11
-10
-9
-8
-7
-6
-5
-4
-3
-20
-15
-10
-5
0
EU
U(Disease=T,Treat=T)
X
Test=yes
Test=no
(a) (b)
-14
-12
-10
-8
-6
-4
-2
0.01
0.015
0.02
0.025
0.03
0.035
0.04
0.045
0.05
0.055
0.06
EU
P(Disease=T)
X
Test=yes
Test=no
(c)
FIGURE 10.4
Sensitivity analysis showing effect of varying a parameter on the test decision,
for three parameters: (a) Cost of test, C; (b) U(Disease=T,Treatment=yes); (c)
P(Disease=T). Parameter value in model marked with X on the x-axis.
available ranges to ensure reasonable network performance across the largest possi-
ble set of conditions. The usability of this approach will depend upon the experts
having enough experience to make useful judgments in all such cases.
Case-base evaluation tends to be informal, checking that expert opinion is being
properly represented in the network. If a great many cases can be brought together,
then more formal statistical methods can be applied. These are discussed immedi-
ately below, as validation methods.
10.4.1 Explanation methods
If a BN application is to be successfully deployed and used, it must be accepted first
by the domain experts and then by the users
. As we have already discussed ( 5.5
and
9.3.2.2), the independence-dependence relations encoded in the BN structure
are not always obvious to someone who is not experienced with BNs. Also, the
Of course the domain experts may also be the intended users.
© 2004 by Chapman & Hall/CRC Press LLC

outcomes of probabilistic belief updating are often unintuitive. These factors have
motivated the development of methods for the explanation of Bayesian networks.
Some of these methods focus on the explanation of the Bayesian network. Others
provide explanations of the conclusions drawn about the domain using the Bayesian
network — that is, how the inference has led from available evidence to the conclu-
sions. This latter is how our NAG would like to be employed eventually (
5.5). The
term “explanation” has also been used to describe the provision of the “most proba-
ble explanation”(MPE) (
3.7.1) of the evidence (e.g., [164]). We view that more as
an inferential matter, however.
INSITE [271] was an early explanation system that identified the findings that
influence a certain variable and the paths through which the influence flows. It then
generates visual cues (shading and highlighting paths) and verbal explanations of the
probabilistic influences. Explanation methods have been used for teaching purposes.
For example, BANTER [97] is a BN tutoring shell, based on INSITE’s methods,
for tutoring users (such as medical students) in the evaluation of hypotheses and
selection of optimal diagnostic procedures. In BANTER, the use of the BN by the
system to perform its reasoning is completely invisible to the user. GRAPHICAL-
BELIEF [178] is an explanatory system that provides a graphical visualization of
how evidence propagates through a BN.
In addition to supporting a deployed system or being part of the application itself,
such explanation methods can be useful during the iterative evaluation of the KEBN
process. They have been shown to support the detection of possible errors in the
model [97] and can be used by the domain expert to verify the output of the model
[271, 178, 77].
10.5 Validation methods
Validating a Bayesian network means to confirm that it is an accurate representa-
tion of the domain or process being modeled. Much of what we have discussed
above, concerning comparing the behavior of a network with the judgments of ex-
perts, could be considered a kind of validation. However, we will reserve the term
for more statistically oriented evaluation methods and specifically for methods suited
to testing the correctness of a Bayesian network when a reasonably large amount of
data describing the modeled process is available.
First there is a general consideration. The Bayesian networks are (usually) built
or learned under an explicitly causal interpretation. But much validation work in
the literature concerns testing the probability distribution represented by the net-
work against some reference distribution. By a reference distribution (or, reference
model, etc.) we mean a known distribution which is being used as the source for
sample data; typically, this is a Bayesian network which is being used to artificially
generate sample data by simulation. Now, since Bayesian networks within a single
Markov equivalence class can be parameterized so as to yield identical probability
© 2004 by Chapman & Hall/CRC Press LLC
distributions, testing their probability distributions against a reference distribution
fails to show that you have the right causal model. For example, the Kullback-Leibler
divergence (
3.6.5) from the true distribution to the learned distribution will not help
distinguish between the different causal models within a single Markov equivalence
class. There is no consensus view on how to evaluate learned causal models as dis-
tinct from learned probability distributions.
One way of dealing with this problem is to collect experimental data, rather than
simply take joint observations across the variables. In that case, we can represent
the causal interventions explicitly and distinguish between causal models. There are
many reasons why this option may be unavailable, the main one being that collecting
such experimental data may be prohibitively expensive or time consuming.
A more readily available option is to analyze the problem and identify a subset
of nodes which are characteristically going to be the query nodes in application and
another subset which are going to be evidence nodes. Sample data can then be used
to see how well the learned network predicts the values of the query nodes when the
evidence nodes take the values observed in the sample. This can be done whether the
query nodes are answers to diagnostic queries (i.e., causes of the evidence nodes) or
are causally downstream from the evidence nodes. As described so far, this evalua-
tion also does not take into account the causal structure being learned. It will often
turn out that the restricted subnetwork being examined has few Markov equivalent
subnetworks even when the full network does. Alternatively, you can examine causal
structure directly, penalizing errors (as we discussed in
8.7.1). In one of our studies,
we tested learned models restricted to leaf nodes only against the reference model’s
leaf nodes; if our method mislearned causal structure it would misidentify leaves,
thus leading to a higher reported error [201].
The validation methods we consider here evaluate Bayesian networks against real
data, sampled from the real process to be modeled, rather than against data simulated
from reference models. Much of the research literature, however, employs artificial
data, sampled from a reference model. It is important to be clear about the differ-
ence in intent behind these two procedures. If we are testing one machine algorithm
against another (e.g., K2 against CaMML), then sampling from an artificially con-
structed Bayesian network and then seeing whether K2 or CaMML can learn from
the sample data something like the original network makes good sense. In that case
we are testing algorithms against each other. But if we are interested in testing or val-
idating a model for a real process, then we presumably do not know in advance what
the true model is. If we did, we would already be done. So, the practical validation
problem for KEBN is to test some models, constructed by hand or learned by our
machine learning algorithms, against real data reporting the history of the process to
be modeled. All of the methods below are applicable to evaluating against the real
data, except for the Kullback-Leibler divergence (
3.6.5), which is used to motivate
our information reward measure.
© 2004 by Chapman & Hall/CRC Press LLC

10.5.1 Predictive accuracy
Predictive accuracy is far and away the most popular technique for evaluating mod-
els, whether they are Bayesian networks, classification trees, or regression models.
Predictive accuracy is assessed relative to a target variable by:
1. Examining each joint observation in the sample
2. Adding any available evidence for the other nodes (i.e., non-target nodes)
3. Updating the network
4. Taking the predicted value for target variable to be that which then has the
highest probability
5. And comparing this with the actual value for that variable in the observation
For example, if a model attempting to relate measured attributes of mushrooms to
their edibility reported for a particular mushroom that the probability of it being
edible is 0.8, then it would be taken as predicting edibility. Running through the
entire sample, we can record the frequency with which the model gets its prediction
right. That is its predictive accuracy. We could equivalently report its error rate as
100% minus its predictive accuracy.
If the sample data have been used to learn the model in the first place (i.e., they are
the training data) — whether learning the causal structure, the parameters or both —
then they cannot safely be reused to gauge the model’s predictive accuracy. In that
case, the model is not being tested on its predictions, but just on how well it has been
tuned to the training data. Fit to the training data can be very far from the ability of
the model to predict new values. When a fixed sample must be used for both training
and testing a model, a plausible approach is divide the data into separate training and
test sets, for example, in a 90% and 10% split. The model’s predictive accuracy on
the test set will now provide an estimate of its generalization accuracy,howwell
it can predict genuinely new cases, rather than rewarding overfitting of the training
data.
A single such test will only provide a crude idea of predictive accuracy. It amounts,
in fact, to a sample of size one of the model’s predictive accuracy and so provides
no opportunity to judge the variation in the model’s predictive accuracy over similar
test sets in the future. If the training-test procedure can be repeated enough times,
then each predictive accuracy measure will provide a separate sample, and the whole
sample can be used to assess the variation in the model’s performance. For example,
it then becomes possible to perform an orthodox statistical significance test to assess
one model’s accuracy against another’s. There may be no opportunity to collect
enough data for such repeated testing. There may nevertheless be enough data for
k-fold cross validation, which reuses the same data set, randomly generating 90-10
splits k times
.
Standard significance tests appear to be biased for k-fold cross validation and are better replaced by a
special paired t-test; see Dietterich [75].
© 2004 by Chapman & Hall/CRC Press LLC
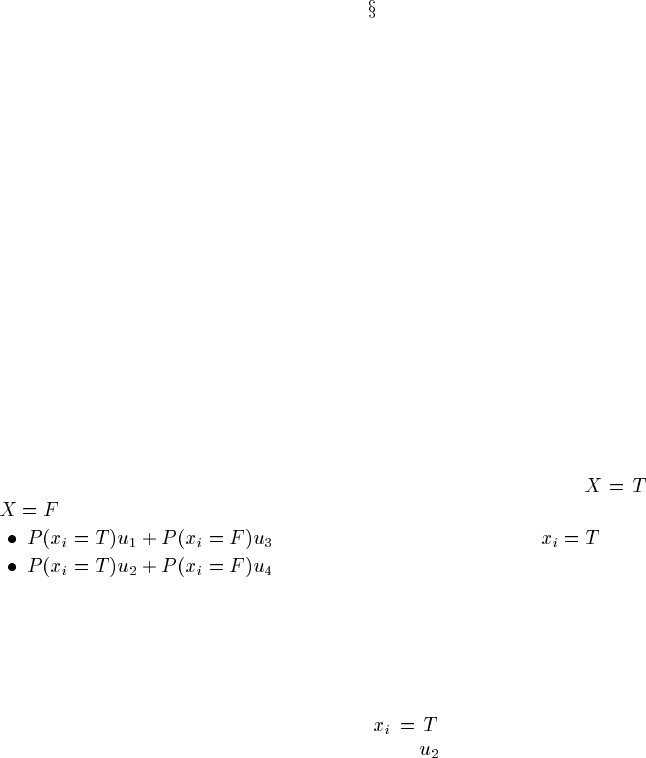
Predictive accuracy is relatively simple to measure, and for that reason may pro-
vide your best initial guide to the merit of a model. Unfortunately, predictive accu-
racy is not your best final guide to a model’s merit: there are excellent reasons to
prefer other measures. A fundamental problem is that predictive accuracy entirely
disregards the confidence of the prediction. In the mushroom classification prob-
lem, for example, a prediction of edibility with a probability of 0.51 counts exactly
the same as a prediction of edibility with a probability of 1.0. Now, if we were
confronted with the first prediction, we might rationally hesitate to consume such a
mushroom. The predictive accuracy measure does not hesitate. According to stan-
dard practice, any degree of confidence is as good as any other if it leads to the same
prediction: that is, all predictions in the end are categorical, rather than probabilistic.
Any business, or animal, which behaved this way would have a very short life span!
In language we have previously introduced (see
9.3.3.1), predictive accuracy pays
no attention to the calibration of the model’s probabilities. So, we will now consider
three alternative metrics which do reward calibration and penalize miscalibration.
10.5.2 Expected value
In recognition of this kind of problem, there is a growing movement in the machine
learning community to employ cost-sensitive classification methods. Instead of pre-
ferring an algorithm or model which simply has the highest predictive accuracy, the
idea is to prefer an algorithm or model with the best weighted average cost or benefit
computed from its probabilistic predictions. In other words, the best model is that
which produces the highest expected utility for the task at hand.
Since classifications are normally done with some purpose in mind, such as se-
lecting a treatment for a disease, it should come as no surprise that utilities should be
relevant to judging the predictive model. Indeed, it is clear that an evaluation which
ignores utilities, such as predictive accuracy, cannot be optimal in the first place,
since it will, for example, penalize a false negative of some nasty cancer no more
and no less than a false positive, even if the consequences of the former swamp the
latter.
Here is a simple binomial example of how we can use expected value to evaluate
a model. Suppose that the utilities associated with categorically predicting
or are as shown in Table 10.5. Then the model’s score would be
across those cases where in fact ,and
otherwise.
Its average score would be the sum of these divided by the number of test cases,
which is the best estimate of the expected utility of its predictions, if the model is
forced to make a choice about the target class.
This expected value measurement explicitly takes into account the full probability
distribution over the target class. If a model is overconfident, then for many cases
it will, for example, attach a high probability to
when the facts are other-
wise, and it will be penalized with the negative utility
multiplied with that high
probability.
© 2004 by Chapman & Hall/CRC Press LLC
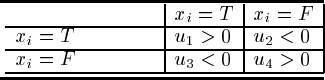
TABLE 10.5
Utilities for binary classification and
misclassification
predicted
predicted
This approach to evaluating predictive models is, in fact, quite paradigmatically
Bayesian. The typical Bayesian approach to prediction is not to nominate a highest
probability value for a query variable given the evidence, but instead to report the
posterior probability distribution over the query node. Indeed, not only do Bayesians
commonly hesitate about nominating a predicted class, they even hesitate about nom-
inating a specific model for classifying. That is, the ideal Bayesian approach is to
compute a posterior distribution over the entire space of models, and then to combine
the individual predictions of the models, weighting them according to their posteri-
ors. This mixed prediction will typically provide better predictions than those of
any of the individual models, including that one with the highest posterior proba-
bility. This is the hard-core Bayesian method, as advocated, for example, by Richard
Jeffrey [123]. But in most situations this ideal method is unavailable, because it
is computationally intractable. More typical of scientific practice, for example, is
that we come to believe a particular scientific theory (model), which is then applied
individually to make predictions or to guide interventions in related domains.
The expected value measurement is the best Bayesian guide to evaluating individ-
ual models; it is the Bayesian gold standard for predictive evaluation. In effect, it
obliges the model to repeatedly gamble on the values of the target variable. The best
model will set the optimal odds (probabilities) for the gamble, being neither under-
confident nor overconfident. The underlying idea, from Frank Ramsey [231], is to
take gambling as a useful metaphor for decision making under uncertainty.
As everything, this method comes at a price: in particular, we must be able to es-
timate the utilities of Table 10.5. For many applications this will be possible, by the
various elicitation methods we have already discussed. But again, in many others the
utilities may be difficult or impossible to estimate. This will especially be true when
the model being developed has an unknown, unexplored, or open-ended range of po-
tential applications. It may be, for example, that the industrial environment within
which the model will be employed is rapidly evolving, so that the future utilities
are unknown. Or, in the case of many scientific models, the areas of application are
only vaguely known, so the costs of predictive error are only vaguely to be guessed
at. So, we now turn to evaluative methods which share with predictive accuracy the
characteristic of being independent of the utility structure of the problem. They nev-
ertheless are sensitive to over- and underconfidence, rewarding the well-calibrated
predictor.
10.5.3 Kullback-Leibler divergence
There are two fundamental ingredients to gambling success, and we would like our
measure to be maximized when they are maximized:
© 2004 by Chapman & Hall/CRC Press LLC