Alfred DeMaris - Regression with Social Data, Modeling Continuous and Limited Response Variables
Подождите немного. Документ загружается.

NONLINEAR REGRESSION 185
Y final exam score and X diagnostic quiz score, is the exponential model with
additive errors, a nonlinear model. As noted earlier, the model is
Y γ
0
e
γ
1
X
ε.
(5.12)
Before discussing the estimation of this model, I digress briefly and consider
instead the exponential model with multiplicative errors, also shown earlier:
Y γ
0
e
γ
1
X
e
ε
. (5.13)
Note that the only difference between these two models is the error structure: that is,
the manner in which error enters the model. Because of this difference, each model
suggests that the processes generating Y in either case are slightly different. For
example, let’s assume that γ
0
1.5, γ
1
.25, X .75, and ε2. Then according to
model (5.12), the value of Y is
Y 1.5e
.25(.75)
2 .1907,
while model (5.13) has the value of Y as
Y 1.5e
.25(.75)
e
2
.2449.
More generally, however, if ε is characterized by constant variance, model (5.12)
implies that the variance of Y is constant with increasing Y. The multiplicative nature
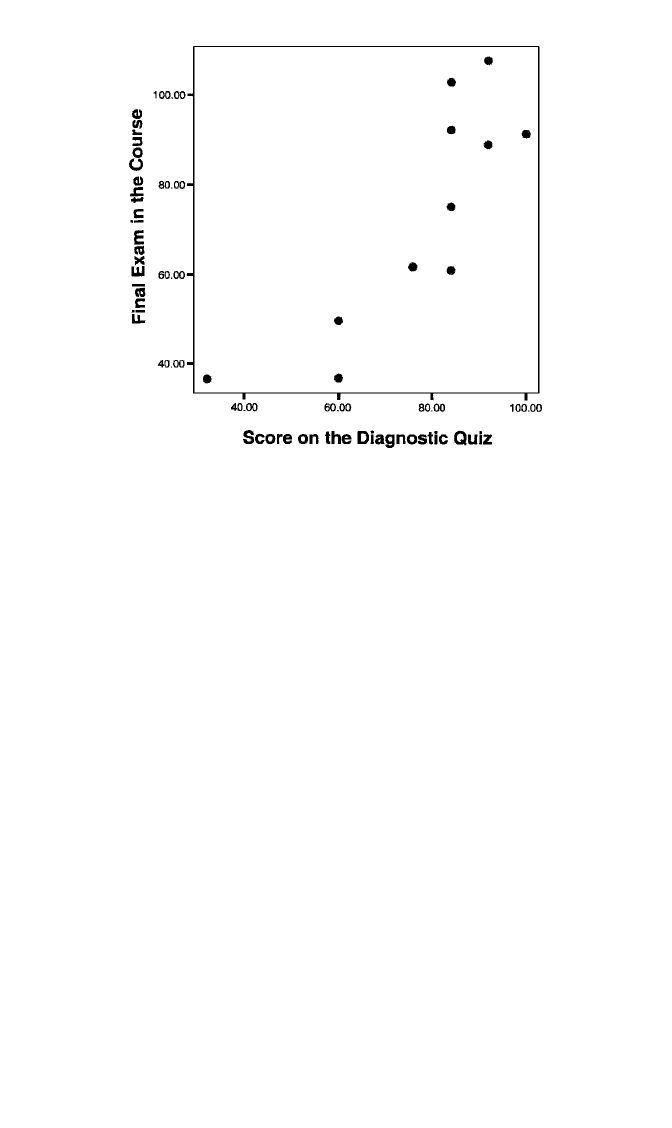
Figure 5.11 Scatterplot of final exam score with score on the diagnostic quiz for 11 students in gradu-
ate statistics.
c05.qxd 8/27/2004 2:53 PM Page 185

of the error term in model (5.13), on the other hand, implies that the variance of Y
increases with increasing Y (Ratkowsky, 1990; the reader is also asked to verify this
in the exercises). Unless there is a compelling theoretical reason for choosing one
error structure over another ahead of time, it will not be a simple matter to decide
which is more reasonable. Based on the scatterplot in Figure 5.11, it does not appear
that a multiplicative error structure is warranted. There does not appear to be a pro-
nounced trend for the variance in Y to increase with Y, with the possible exception
of the large scatter of points at X 84. An examination of model residuals plotted
against fitted values might also reveal which of model (5.12) or model (5.13) is the
correct choice. In the current case, both residual plots (not shown) appeared reason-
able. However, 11 data points are simply too few to allow for a reliable empirical
check on model plausibility. For this reason, I estimate both models, as well as the
simple linear regression model, and compare the results. First I consider the estima-
tion of model (5.13).
Estimating the Multiplicative Model
As noted earlier, if we transform Y by taking its log, model (5.13) becomes a linear
model:
log Y α γ
1
X ε, (5.14)
where α log γ
0
. If we can assume that ε is normally distributed with zero mean and
constant variance, σ
2
, this model can be estimated via OLS. Panel (a) of Table 5.5
shows the results of estimating this model, called the log y model in the table, as well
186 MODELING NONLINEARITY
Table 5.5 Regression Models for the Regression of Final Exam Score on Diagnostic
Quiz
(a) Regression Results
Parameter Estimate Linear Model Log y Model Exponential Model
Intercept 11.190 2.868*** 17.129*
Beta 1.094** .018*** .018***
R
2
.690 .718 .717
* p .05. ** p .01. *** p .001.
(b) Iteration History for Exponential Model
Iteration Intercept Beta SSE
0 17.5983 .0176 1893.8412
1 17.0852 .0182 1854.9534
2 17.1307 .0182 1854.9443
3 17.1294 .0182 1854.9443
Note: All R
2
s are calculated as r
2
y,
yˆ
.
c05.qxd 8/27/2004 2:53 PM Page 186

NONLINEAR REGRESSION 187
as estimating the SLR model for Y (the linear model in the table). Both models show
a significant relationship between diagnostic quiz and final exam scores, with the
log y model having slightly greater discriminatory power. The estimates are, of
course, not directly comparable, but the fitted values will be similar. For example,
the linear model predicts final exam scores of 54.45 for X 60 and 89.458 for
X 92. Calculating the fitted values, yˆ , or estimated E(Y), for the log y model is not
quite as straightforward as it might seem. The estimated log of y would be given by
log yˆ 2.868 .018X. But according to Wooldridge (2000), if we simply take
yˆ exp(log yˆ), we will systematically underestimate E(Y ). The reason for this is that
for this model, E(Y ) is given by
E(Y 冟X) exp
冢
σ
2
2
冣
exp(α γ
1
X), (5.15)
where σ
2
is the variance of ε. Therefore, the correct fitted values are given by
yˆ exp
冢
σ
ˆ
2
2
冣
exp(log yˆ),
where the MSE in the regression for log Y would be used as the measure of σ
ˆ
2
.
Wooldridge (2000) explains that these fitted values are not unbiased, but they are
consistent. The development in equation (5.15), however, relies on the normality of
the error term. With an MSE of .03981 in the current example, the fitted values for
X at scores of 60 and 92 for the log y model are 52.874 and 94.057, respectively.
Notice that these are slightly closer to the means of the actual Y values at these X val-
ues (43.25, 98.63) than are the fitted values for the linear model.
Interpreting γ
1
. Interpreting the effect of X in the log y model is facilitated by con-
sidering the ratio of E(Y 冟x 1) to E(Y 冟 x). That is, we examine the ratio of mean
responses for those who are 1 unit higher on X than others. Let c exp(σ
2
/2). Then,
according to equation (5.15), this ratio is
E(
E
Y
(
冟
Y
x
冟
x)
1)
ce
c
α
e
e
α
γ
e
1
(
γ
x
1
x
1)
e
γ
e
1
γ
x
1
e
x
γ
1
e
γ
1
,
which implies that
E(Y 冟x 1) e
γ
1
E(Y 冟x).
In other words, exp(γ
1
) is the multiplicative impact on the mean of Y for each
unit increase in X. Or, 100(e
γ
1
1) is the percent change in the mean for each unit
increase in X. In the current example, each point higher the student scores on
the diagnostic quiz is estimated to increase the average final exam score by
100(e
.018
1) 1.8%. Moreover, an increase of 10 points on the diagnostic quiz
should raise the average final exam score by 100(e
10(.018)
1) 19.7%.
c05.qxd 8/27/2004 2:53 PM Page 187

Discriminatory Power. As is the case with the fitted values, calculation of R
2
is also
affected by equation (5.15). Wooldridge (2000) recommends calculating R
2
using an
approach that depends only on the orthogonality of the errors with X (i.e., the orthog-
onality condition), but not on normality. This approach is as follows. Regress the log
of Y on X, using model (5.14), and obtain log yˆ (i.e., the fitted values from this regres-
sion). Create M exp(log y
ˆ
) for each observation. Then regress Y on M without an
intercept; this is known as a regression through the origin. Obtain the fitted values
from this regression and denote them as yˆ. Then R
2
is calculated as the squared cor-
relation between y and yˆ. Using this procedure resulted in the value of .718 shown
in Table 5.5.
Estimating the Nonlinear Model
Estimation of the additive exponential model is complicated by the fact that the nor-
mal equations for this model have no closed-form solution or algebraic formula that
can be applied in one step. This can be seen by first considering the SSE for this
model. Writing the sample equation as
Y g
0
e
g
1
X
e,
we see that the residual, e,is
e Y g
0
e
g
1
X
.
The criterion to be minimized by the least squares estimates, in this case, is
SSE 冱(Y g
0
e
g
1
X
)
2
.
The normal equations are found by taking the first partial derivatives of SSE with
respect to, alternately, g
0
and g
1
, setting them to zero, and solving for g
0
and g
1
. The
normal equations in this case are (Neter et al., 1985)
冱
n
i1
y
i
e
g
1
X
i
g
0
冱
n
i1
e
2g
1
X
i
0,
冱
n
i1
y
i
X
i
e
g
1
X
i
g
0
冱
n
i1
X
i
e
2g
1
X
i
0.
Since these equations are nonlinear in the parameter estimates, they have no closed-
form solution and must be solved through iterative methods.
Actually, a more efficient procedure is to find the estimates via a direct search
rather than first finding the normal equations for the model. Perhaps the most com-
mon approach is the Gauss–Newton procedure (Myers, 1986; Neter et al., 1985).
188 MODELING NONLINEARITY
c05.qxd 8/27/2004 2:53 PM Page 188

This technique uses a first-order Taylor series expansion to approximate the nonlin-
ear model with linear terms and then employs OLS to estimate the parameters in an
iterative fashion. A Taylor series expansion of a function of x,f(x), uses a polyno-
mial in x,p(x), to approximate the value of the function in some “neighborhood” of
a given value, a. (A neighborhood of a is some small interval of numbers centered
at X a.) This is accomplished by forcing p(x) and its first n derivatives to match the
value of f(x) and its first n derivatives at X a (Anton, 1984). In the current exam-
ple, we require only the first partial derivatives of Y g
0
e
g
1
X
e with respect to g
0
and g
1
. These are
∂
∂
g
Y
0
e
g
1
X
,
∂
∂
g
Y
1
g
0
Xe
g
1
X
.
We then choose some values for the parameter estimates as starting values for the
iterative search. Call these values g
0
(0)
and g
1
(0)
One choice of starting values, followed
in the current example, was to use the coefficient estimates from the log y model in
Table 5.5. A first-order Taylor series expansion of g
0
e
g
1
X
about g
0
(0)
and g
1
(0)
is
g
0
(0)
e
g
1
(0)
X
e
g
1
(0)
X
(γ
0
g
0
(0)
) g
0
(0)
Xe
g
1
(0)
X
(γ
1
g
1
(0)
),
where γ
0
and γ
1
are the parameter values that we are trying to estimate (i.e., they are
the “variables” in this expression). A Taylor series approximation to the model for Y
is, therefore,
Y ⬇g
0
(0)
e
g
1
(0)
X
e
g
1
(0)
X
(γ
0
g
0
(0)
) g
0
(0)
Xe
g
1
(0)
X
(γ
1
g
1
(0)
) ε.
If we let Y
(0)
Y g
0
(0)
e
g
1
(0)
X
, then
Y
(0)
⬇e
g
1
(0)
X
(γ
0
g
0
(0)
) g
0
(0)
Xe
g
1
(0)
X
(γ
1
g
1
(0)
) ε.
(5.16)
Myers (1986) refers to the left-hand-side of equation (5.16) as the “residual” for Y,
where the parameters of the term
γ
0
e
γ
1
X
are replaced by their starting values.
Equation (5.16) is now a linear regression model with no intercept (i.e., a regression
through the origin). The “parameters” to be estimated are γ
0
g
0
(0)
and
γ
1
g
1
(0)
,
which enter the model linearly, and the independent variables are
e
g
1
(0)
X
and
g
0
(0)
Xe
g
1
(0)
X
, which are two different transformations of X. OLS is then employed to
estimate equation (5.16), giving us the parameter estimates
b
0
(0)
γ
ˆ
0
g
0
0
,
b
1
(0)
γ
ˆ
1
g
1
0
.
NONLINEAR REGRESSION 189
c05.qxd 8/27/2004 2:53 PM Page 189

These are then used to obtain revised estimates of γ
0
and γ
1
, since
γ
ˆ
0
g
0
(0)
b
0
(0)
,
γ
ˆ
1
g
1
(0)
b
1
(0)
.
We then take γ
ˆ
0
and γ
ˆ
1
as our new starting values for equation (5.16) and reestimate
the equation, again using OLS. We continue in this fashion, each time updating
our old estimates, plugging the updates into equation (5.16), and reestimating the
parameters until the difference between successive coefficient estimates and/or the
difference in successive SSE’s becomes negligible. If the procedure is working cor-
rectly, SSE should continue to get smaller with each successive iteration. At the pres-
ent time, many software programs for nonlinear regression (e.g., SAS) require the
user to supply the expressions for the first partial derivatives of the model with
respect to the parameters, as well as the starting values for the parameters, in order
for the program to run. Assuming that the assumptions on the errors are valid, the
resulting parameter estimates are approximately efficient, unbiased, and normally
distributed in large samples. This means that for large n, the usual regression test sta-
tistics are applicable.
Estimates for the exponential model with additive errors, based on the
Gauss–Newton procedure, are shown in the column “exponential model” in panel (a)
of Table 5.5. They can be compared to those for the log y model by noting that the
comparable parameter in the log y model to the intercept in the exponential model is
exp(2.8678) 17.5983. Although the intercepts are slightly different, the coefficient
for X (diagnostic quiz score) is virtually the same in each model. R
2
for the expo-
nential model is calculated as the square of the correlation between its fitted values
(y
ˆ
) and Y. Again, this is virtually identical to the R
2
for the log y model. Panel (b) of
the table shows the iteration history for the model. The initial estimates are in the
row labeled “iteration 0” and are just the parameter estimates from the log y model.
Convergence, in this case, was quite rapid, occurring in three iterations. Ratkowsky
(1990) observes that convergence to the least squares estimates usually occurs fairly
rapidly from reasonable starting values, especially for relatively simple models. In
fact, even if one mistakenly uses 2.8678 instead of exp(2.8678) as the starting value
for the intercept, convergence still occurs in five iterations. At any rate, all three
models for final exam score in this example appear to produce approximately the
same substantive conclusion regarding the impact of diagnostic quiz scores. In this
particular instance there is no special advantage to employing the nonlinear model.
However, in other cases, it may be the only suitable choice.
EXERCISES
5.1 Based on a probability sample of 680 married couples, Mirowsky (1985)
examined the relationship between depression (Y), a continuous scale ranging
from 0 (“no depression”) to 112 (“maximum depression”) and marital power
190 MODELING NONLINEARITY
c05.qxd 8/27/2004 2:53 PM Page 190

(X). Power was operationalized in terms of who usually made major decisions
in the household, and was an approximately interval-level scale ranging from
1 (“wife always”) to 5 (“husband always”), with a value of 3 indicating that
decisions were made with both partners “having equal say.” One hypothesis
of the study was that depression would exhibit a U-shaped relationship with
power, showing a minimum when power was equally shared. The equations
for husbands and wives were:
Husbands: yˆ a gcontrols 12.343 power 1.944 power
2
.
Wives: yˆ a gcontrols 11.567 power 2.537 power
2
.
(a) Give the partial slope of each equation with respect to power.
(b) Show that each equation represents a U-shaped trend, using selected val-
ues of power.
(c) Using the fact that a U-shaped curve of the form y a bx cx
2
achieves a minimum value when x b/2c, show that minimum depres-
sion occurs for each partner when neither partner dominates decision
making.
5.2 Based on model 4 in Table 5.2, give the partial slope for the impact of health
at 1 standard deviation below mean age, at mean age, and at 1 standard devi-
ation above mean age, given that the standard deviation of age is 16.774.
5.3 Demonstrate with some selected values for γ
0
, γ
1
, x, and ε that for the multi-
plicative exponential model [i.e., model (5.13)], the variance of Y increases
with increasing Y, whereas the variance of Y is constant with increasing Y in
the nonlinear exponential model [i.e., model (5.12)]. (Hint: One choice of val-
ues is γ
0
1.5, γ
1
.25, x 1, 2, 3, 4, 5, and ε .5, .5).
5.4 An analysis of the 2320 respondents in the GSS98, examining the relationship
between sexual frequency (Y), age (centered), and education (centered),
found the following results for three different models:
Model 1: yˆ 3.103 .04 age .001 age
2
.019 education; R
2
.2233.
Model 2: yˆ 2.818 .049 age .035 education .001 age * education;
R
2
.1982.
Model 3: yˆ 3.108 .039 age .001 age
2
.029 education .001 age *
education .00005 age
2
* education; R
2
.2238.
(a) Perform global tests for the age * education interaction and for the curvi-
linearity of the relationship between sexual frequency and age.
(b) Given that the standard deviation of education is 2.894, give the partial
slope of yˆ in model 3 with respect to age at 1 standard deviation below
mean education, at mean education, and 1 standard deviation above mean
EXERCISES 191
c05.qxd 8/27/2004 2:53 PM Page 191

education. Compare the nonlinear interaction effect here to that for the
nonlinear interaction of age with health in Table 5.2.
5.5 For the data in Table 5.4, if the diagnostic quiz is divided up approximately
into quartiles, an unconstrained model for final exam scores, using three dum-
mies representing quartiles 2 to 4 produces R
2
.7937. A model with just the
quartile variable (coded 1 to 4) gives R
2
.7848. Moreover, a model with the
centered, continuous versions of diagnostic quiz and its square (the quadratic
model) has yˆ 69.716 1.376 quiz .012 quiz
2
.
(a) Test whether a linear model fits as well as the unconstrained model.
(b) Using the quadratic model, if the mean quiz score is 77.667 and the stan-
dard deviation is 18.642, give the predicted final exam scores for quiz
scores of 60 and 92.
(c) For the quadratic model, give the partial slope for quiz score at 1 standard
deviation below mean quiz scores, at mean quiz scores, and at 1 standard
deviation above mean quiz scores.
5.6 For the following nonlinear models from Ratkowsky (1990), find ∂y/∂x and
∂y/∂θ
p
for each parameter θ
p
(i.e., for each different parameter in the model):
(a) y log(x α).
(b) y 1/(x α).
(c) y log(α βx).
(d) y α βγ
x
.
5.7 Using the couples dataset, estimate the multiplicative exponential model for
COITFREQ as a function of MALEAGE. In particular:
(a) Give the equation for log yˆ.
(b) Interpret the effect of MALEAGE. What percent reduction in coital fre-
quency is expected for a 10-year gain in male’s age?
(c) Give the estimated expected value of Y (i.e., yˆ) for couples in which the
male partner is 25, 35, and 55.
(d) Give the R
2
value for the model.
(e) Examine the residuals for plausibility of the assumptions on the errors.
5.8 Using the couples dataset, estimate the additive exponential model for COIT-
FREQ as a function of MALEAGE (you’ll need software that has a nonlinear
regression procedure here). Use the sample coefficients from the multiplica-
tive exponential model as starting values. In particular:
(a) Give the equation for yˆ.
(b) Interpret the effect of MALEAGE. What percent reduction in coital fre-
quency is expected for a 10-year gain in male’s age?
(c) Give the estimated expected value of Y (i.e., yˆ) for couples in which the
male partner is 25, 35, and 55.
(d) Give the R
2
value for the model.
(e) Examine the residuals for plausibility of the assumptions on the errors.
192 MODELING NONLINEARITY
c05.qxd 8/27/2004 2:53 PM Page 192

5.9. Regard the following data for 30 cases:
XZ YXZ Y
0 2.0845 3.56774 5 3.7676 .41187
0 .3866 .32872 5 6.5101 .78784
0 .9488 1.03347 5 7.7405 .97970
1 .7751 1.43186 6 6.6440 1.62030
1 2.892 2.87661 6 7.9871 .56195
1 2.8461 3.24443 6 7.7051 1.65471
2 5.2616 .16583 7 5.0887 .60902
2 5.9740 1.60710 7 11.4823 .94752
2 2.1966 1.22054 7 9.5552 .41412
3 3.8658 .72971 8 7.8112 .98601
3 .3804 .47408 8 8.2402 1.35958
3 3.4555 .12573 8 4.1219 .90526
4 6.8522 1.21795 9 4.9838 .16067
4 4.7659 .95917 9 6.3705 .51194
4 9.2228 3.19808 9 11.9198 .47474
(a) Estimate the following model for these data: E(Y) α βX
1/3
γZ
δZX
1/3
, and give the sample equation.
(b)Give ∂yˆ/∂X and ∂yˆ/∂Z.
(c) Give the impact (i.e., partial slope) of X at the mean of Z and at 1 stan-
dard deviation below and above the mean.
(d) Give the impact of Z at the mean of X and at 1 standard deviation below
and above the mean.
(e) Graph Y against X at the mean of Z and at 1 standard deviation below and
above the mean.
5.10 Using the kids dataset, partition the variable PERMISIV approximately into
sextiles using the following ranges: 8, (8,10], (10,12], (12,14], (14,16],
and 16.
(a) Plot the mean of ADVENTRE against sextiles of PERMISIV. Does the
trend appear linear?
(b) Use the sextile-coded version of PERMISIV to perform the test of lin-
earity in the regression of ADVENTRE on PERMISIV.
(c) Test the quadratic model in PERMISIV sextiles against the unconstrained
model employed in part (b).
(d) Using the continuous and centered version of PERMISIV, estimate the
quadratic model of ADVENTRE. Regardless of significance levels of the
coefficients, give the slope of PERMISIV on ADVENTRE at the mean of
PERMISIV and at 1 standard deviation below and above the mean. What
type of curve is indicated? (Note that PERMISIV ranges from 4 to 20.)
5.11 Using the couples dataset, partition the variable DURYRS approximately into
deciles, using the following ranges: 1.42, (1.42, 2.92], (2.92, 4.75], (4.75, 7],
EXERCISES 193
c05.qxd 8/27/2004 2:53 PM Page 193

(7, 10.92], (10.92, 15.92], (15.92, 20.58], (20.58, 29.75], (29.75, 40.83],
40.83.
(a) Plot the mean of DISAGMT against deciles of DURYRS. Does the trend
appear linear?
(b) Use the decile-coded version of DURYRS to perform the test of linearity
in the regression of DISAGMT on DURYRS.
(c) Test the quadratic model in DURYRS deciles against the unconstrained
model employed in part (b).
(d) Using the continuous and centered version of DURYRS, estimate the
quadratic model of DISAGMT. Regardless of the significance levels of
the coefficients, give the slope of DURYRS on DISAGMT at the mean of
DURYRS and at 1 standard deviation below and above the mean. What
type of curve is indicated? (Note: DURYRS ranges from .17 to 60.58.)
5.12 Regard the following nonlinear model for E(Y): E(Y) α βγ
x
. Letting
α 5, β 2, and γ .35:
(a) Evaluate the slope (i.e., the first derivative of Y with respect to X) of X’s
impact on Y at X 0, 2.5, and 5.
(b) Find E(Y ) at X 0, 2.5, and 5.
(c) Graph the relationship between Y and X for X in the range [0,5] assuming
these parameter values.
5.13 Regard the following nonlinear model for E(Y): E(Y ) log(α βX). Letting
α 5, β 2:
(a) Evaluate the slope of X’s impact on Y at X 0, 2.5, and 5.
(b) Find E(Y ) at X 0, 2.5, and 5.
(c) Graph the relationship between Y and X for X in the range [0,5] assuming
these parameter values.
5.14 Regard the following nonlinear model for E(Y ):
E(Y)
1exp(
β
β
1
2
β
3
X)
.
Letting β
1
5, β
2
2, and β
3
.35:
(a) Evaluate the slope of X’s impact on Y at X 0, 2.5, and 5.
(b) Find E(Y ) at X 0, 2.5, and 5.
(c) Graph the relationship between Y and X for X in the range [0,5] assuming
these parameter values.
5.15 Identify the type of curve exemplified by each of the following equations for
X in the range [10, 10].
(a) yˆ .5 2x .5x
2
.
(b) yˆ 3 .75x .25x
2
.
194 MODELING NONLINEARITY
c05.qxd 8/27/2004 2:53 PM Page 194