King M.R., Mody N.A. Numerical and Statistical Methods for Bioengineering: Applications in MATLAB
Подождите немного. Документ загружается.


rate) = a·log (body weight) + k). Write a program in MATLAB and use the
normal equations to perform your least-squares regression.
2.13. Data regression of two competing models Table P2.2 gives a measurement of
microvillus tether extraction from a live B-cell as a function of time, along with the
predictions of two different theoretical models. Evaluate which of the two models
provides the best overall fit to the data.
2.14. Transformation of nonlinear equations For the second-order irreversible reaction
A þ A !
k
2
A
2
;
the decrease in reactant concentration C
A
as a function of time t can be exp ressed as
C
A
C
A0
¼
1
1 þ k
2
C
A0
t
;
where C
A0
is the initial concentration of A. Rewrite the above equation so that it is
linear in the two modeling parame ters C
A0
and k
2
.
2.15. Will women’s sprint time beat the men’s in the Olympics someday? In a famous
(and controversial) article in Nature, Tatem and coworkers performed linear regres-
sions on the winning Olympic 100 meter sprint times for men and women (see Table
P2.3) and used these results to predict that the winning women’s sprint time would
surpass the winning men’s time in the summer Olympics of 2156 (Tatem et al.,
2004).
5
Your task is to recreate the analysis of Tatem et al. by performing linear
regressions of the winning women’s and men’s 100 meter sprint times using the
normal equations. Show graphically that the two best-fit lines intersect in the year
2156. Be careful not to include zeros (gaps in the data due to the World Wars and the
absence of women competitors in Olympics prior to 1928) because these spurious
points will bias your regression.
This data set is available at the book’s webs ite www.cambridge.org/* as sprint-
times.dat.
2.16. Number of eyelash mites correlate with host’s age Andrews (1976) hypothesized
that the number of follicle mites living on human eyelashes would correlate with the
age of the host organism, and collected the data given in Table P2.4 (McKillup,
2005).
Table P2.2.
Time (s) Tether length (μm) Model 1 prediction (μm) Model 2 prediction (μm)
0.65 1.0 2.0 1.0
1.30 3.0 4.0 3.0
1.95 4.0 5.0 6.0
5
Although Tatem and coworkers carefully calculated the 95% confidence intervals in their model
predictions (see Chapter 3 for an in-depth discussion on confidence intervals), many researchers have
criticized their extrapolation of the model far beyond the range of available data. Also, various
assumptions must be made, such as neglecting the possible influence of performance-enhancing drugs
and the existence of a future plateau in human abilities.
137
2.14 Problems

Fit these data to a line using the MATLAB function polyfit, and then plot the
data points (as symbols) along with the best-fit line (as a solid line). Also determine
the quality of the fit.
2.17. Lung volume scales with body weight In mammals, the lung volume is found to
scale with the body wei ght. The lung vo lume is measured by the vital capacity, which
is the amount of air exhaled when one first bre athes in with maximum effort and then
breathes out with maximum effort. A higher vital capacity translates into a greater
amount of respiratory gas exchange. People who engage in strenuous work or
exercise tend to have a higher vital capacity. Given the data in Table P2.5
(Schmidt-Nielsen, 1972), show that a power law V = aW
b
fits these data reasonably
well by performing a linear regression using the transformed equation (base 10): log
Table P2.3. Winning times of the men’s and women’s Olympic 100 m
sprints from 1900
Olympic year Men’s winning time (s) Women’s winning time (s)
1900 11.00
1904 11.00
1908 10.80
1912 10.80
1916
1920 10.80
1924 10.60
1928 10.80 12.20
1932 10.30 11.90
1936 10.30 11.50
1940
1944
1948 10.30 11.90
1952 10.40 11.50
1956 10.50 11.50
1960 10.20 11.00
1964 10.00 11.40
1968 9.95 11.08
1972 10.14 11.07
1976 10.06 11.08
1980 10.25 11.06
1984 9.99 10.97
1988 9.92 10.54
1992 9.96 10.82
1996 9.84 10.94
2000 9.87 10.75
2004 9.85 10.93
Source: Rendell, M. (ed.) The Olympics: Athens to Athens 1896–
2004 (London: Weidenfeld and Nicolson, 2004), pp. 338–340.
138
Systems of linear equations

V = b log W + log a. Evaluate the constants a and b and show that b 1.0. Perform
the linear regression again, this time assuming a linear dependency of vital capacity
V on body weight W . This time the slope you obtain for the straight line will equal
the constant a from the power law.
The tidal volume (T) is the vo lume of air that a person breathes in and out
effortlessly. It is approximately one-tenth of the vital capacity. With this information
only, obtain the relationship between T and W.
2.18. For the problem stated in Box 2.4, plot the residuals of the α
crit
values obtained from
the quadratic fit as a function of height H of the platelet from the wall. Do you
observe a trend in the residuals or simply random scatter?
2.19. Determine the coeffici ent of determination R for fitted curves obtained in Boxes 2.2
and 2.3. What can yo u say about the quality of the fit of the models?
References
Andrews, M. (1976) The Life That Lives on Man (London: Faber & Faber).
Anton, H. A. (2004) Elementary Linear Algebra (New York: Wiley, John & Sons, Inc.).
Bailey, J. E. and Ollis, D. F. (1986) Biochemical Engineering Fundamentals The Mc-Graw Hill
Companies.
Davis, T. H. and Thomson, K. T. (2000) Linear Algebra and Linear Operators in Engineering
(San Diego: Academic Press).
Demmel, J. W. (1997) Applied Numerical Linear Algebra (Philadelphia: Society for Industrial
and Applied Mathematics (SIAM)).
Imai, K., Tientadakul, P., Opartkiattikul, N., Luenee, P., Winichagoon, P., Svasti, J., and
Fucharoen, S. (2001) Detection of Haemoglobin Variants and Inference of Their
Table P2.4.
Age (years) Number of mites
35
613
916
12 14
15 18
18 23
21 20
24 32
27 29
30 28
Table P2.5.
W (kg) 0.3
(rat)
3
(cat)
4
(rabbit)
15
(dog)
35
(pig)
80
(man)
600
(cow)
1100
(whale)
V (liter) 0.01 0.3 0.4 2 6 7 10 100
139
References

Functional Properties Using Complete Oxygen Dissociation Curve Measurements. Br.
J. Haematol., 112, 483–7.
King, M. R. and Hammer, D. A. (2001) Multiparticle Adhesive Dynamics: Hydrodynamic
Recruitment of Rolling Leukocytes. Proc. Natl. Acad. Sci. USA, 98, 14919–24.
Levy, J. H., Goodnough, L. T., Greilich, P. E. et al. (2002) Polymerized Bovine Hemoglobin
Solution as a Replacement for Allogeneic Red Blood Cell Transfusion after Cardiac
Surgery: Results of a Randomized, Double-Blind Trial. J. Thorac. Cardiovasc. Surg.,
124, 35–42.
Livingston, B. M. and Krakoff, I. H. (1970) L-Asparaginase; a New Type of Anticancer Drug.
Am. J. Nurs., 70, 1910–15.
McKillup, S. (2005) Statistics Explained: An Introductory Guide for Life Scientists
(Cambridge: Cambridge University Press).
Mody, N. A. and King, M. R. (2005) Three-Dimensional Simulations of a Platelet-Shaped
Spheroid near a Wall in Shear Flow. Phys. Fluids, 17, 1432–43.
Quick, D. J. and Shuler, M. L. (1999) Use of In Vitro Data for Construction of a
Physiologically Based Pharmacokinetic Model for Naphthalene in Rats and Mice to
Probe Species Differences. Biotechnol. Prog., 15, 540–55.
Schmidt-Nielsen, K. (1972) How Animals Work (Cambridge: Cambridge University Press).
Shen, Y.-C., Wang, M.-Y., Wang, C.-Y., Tsai, T.-C., Tsai, H.-Y., Lee, Y.-F., and Wei, L.-C.
(2007) Clearance of Intravitreal Voriconazole. Invest. Ophthalmol. Vis. Sci., 48, 2238–41.
Sin, A., Chin, K. C., Jamil, M. F., Kostov, Y., Rao, G., and Shuler, M. L. (2004) The Design
and Fabrication of Three-Chamber Microscale Cell Culture Analog Devices with
Integrated Dissolved Oxygen Sensors. Biotechnol. Prog., 20, 338–45.
Tatem, A. J., Guerra, C. A., Atkinson, P. M., and Hay, S. I. (2004) Athletics: Momentous
Sprint at the 2156 Olympics? Nature, 431, 525.
Viravaidya, K. and Shuler, M. L. (2004) Incorporation of 3t3-L1 Cells to Mimic
Bioaccumulation in a Microscale Cell Culture Analog Device for Toxicity Studies.
Biotechnol. Prog., 20, 590–7.
Viravaidya, K., Sin, A., and Shuler, M. L. (2004) Development of a Microscale Cell Culture
Analog to Probe Naphthalene Toxicity. Biotechnol. Prog., 20, 316–23.
140
Systems of linear equations

3 Probability and statistics
3.1 Introduction
Variability abounds in our environment, such as in daily weath er patterns, the
number of accidents occurring on a certain highway per week, the number of
patients in a hospital, the response of a group of patients to a particular type of
drug, or the birth/death rate in any town in a given year. The “observed” occurrences
in nature or in our man-made environm ent can be quantitatively described using
“statistics” such as mean value, standard deviation, range, percentiles, and median.
In the fields of biology and medicine, it is very difficult, and often impossible, to
obtain data from every individual that possesses the characteristic of interest that we
wish to observe. Say, for instance, we want to assess the success rate of a coronary
drug-eluting stent. To do this, we must define our population of interest – patients
who underwent coronary stent implantation. It is an almost impossible task to track
down and obtain the medical records of every individual in the world who has been
treated with a drug-eluting stent, not to mention the challenges faced in obtaining
consent from patients for collection and use of their personal data. Therefore we
narrow our search method and choose only a part of the population of interest
(called a sample), such as all Medicare patients of age >65 that received a coronary
stent from May 2008 to April 2009. The statistics obtained after studying the
performance of a drug-eluting stent exactly describe the sample, but can only serve
as estimates for the population, since they do not fully describe the varied experi-
ences of the entire population. Therefore, it is most critical that a sample be chosen
so that it exhibits the variability inherent in the population without systematic bias.
Such a sample that possesses the population characteristics is called a representative
sample. A sample can be a series of measurements, a set of experimental observa-
tions, or a number of trials.
A statistic is calculated by choosing a random sample from the entire population
and subsequently quantifying data obtained from this sample. If the individuals that
make up the sample exhibit sufficient variation, the sample-derived statistic will
adequately mimic the behavior of the whole population. A common method to
generate a sample is to conduct an extensive survey. In this case, the sample includes
all the individuals who respond to the survey, or from whom data are collected. For
example, a health insurance company may request that their customers provide
feedback on the care received during a doctor’s visit. Depending on the number of
responses, and the characteristics of the people who responded, the sample may
either (1) constitute a sizably heterogeneous group of individuals that can reliably
represent the entire population from which the sample was drawn, or (2) contain too
few responses or consist of a homogeneous set of ind ividuals that does not mimic the
variability within the population. The method of sampling is an important step in
obtaining reliable statistical estimates and is discussed in Section 3.3. In the event
that an inadequate sample is used to obtain information from which we wish to infer

the behavior of the entire population, the derived estimates may be misleading and
lie far from the actual values.
We are specifically interested in understanding and quantifying the variability
observed in biological data. What do we mean by variability in biology? Due to
varying environmental and genetic factors, different individuals respond in a dis-
similar fashion to the same stimulus. Suppose 20 16-year-old boys are asked to run
for 20 minutes at 6 miles/hour. At the end of this exercise, three variables – the
measured heart rate, the blood pressure, and the breathing rate – will vary from one
boy to another. If we were to graph the measured data for each of the three variables,
we would expect to see a distribution of data such that most of the values lie close to
the average value. A few values might be observed to lie further away from the
average. It is important to realize that the differences in any of these measurements
from the average value are not “errors.” In fact, the differences, or “spread,” of the
data about the average value are very important pieces of information that charac-
terize the differences inherent in the population. Even if the environmental condi-
tions are kept constant, variable behavior cannot be avoided. For example, groups
of cells of the same type cultured under identical conditions exhibit different growth
curves. On the other hand, identical genetically engineered plants may bear different
numbers of flowers or fruit, implying that environmental differences such as con-
ditions of soil, light, or water intake are at work.
The methods of collection of numerical data, its analysis, and scientifically sound
and responsible interpretation, for the purposes of generating descriptive numbers
that characterize a population of interest, are collectively prescribed by the field of
statistics, a branch of mathematics. The need for statistical evaluations is pervasive
in all fields of biomedicine and bioengineering. As scientists and engineer s we are
required to calculate and report statistics frequently. The usefulness of published
statistics depends on the methods used to choose a representative (unbiased)
sample, obtain unbiased data from the sample, and analyze and interpret the
data. Poorly made decisions in the data collection phase, or poor judgment used
when interpreting a statistical value, can render its value useless. The statistician
should be well aware of the ethical responsibility that comes with de signing the
experiment that yields the data and the correct interpretation of the data. As part of
the scientific community that collects and utilizes statistica l values on a regular
basis, you are advised to regard all published statistical information with a critical
and discerning eye.
Statistical information can be broadly classified into two categories: descriptive
statistics and inferential statistics. Descriptive statistics are numerical quantities that
condense the information avail able in a set of data or sample into a few numbers,
and exactly specify the characteristics exhibited by the sample, such as average
weight, size, mechanical strength, pressure, or concentration. Inferential statistics
are numerical estimations of the behavior of a population of individuals or items
based on the characteristics of a smaller pool of information, i.e. a representative
sample or data set. Some very useful and commonly employed descriptive statistics
are introduced in Section 3.2. The role of probability in the field of statistics and
some important probability concepts are discus sed in Section 3.3.InSection 3.4,we
discuss two widely used discrete probability distributions in biology: the binomial
distribution and the Poisson distribution. The normal distribution, the most widely
used continuous probability distribution, is covered in detail in Section 3.5, along
with an introduction to inferential statistics. In Section 3.6, we digress a little and
discuss an important topic – how errors or variability associated with measured
142
Probability and statistics
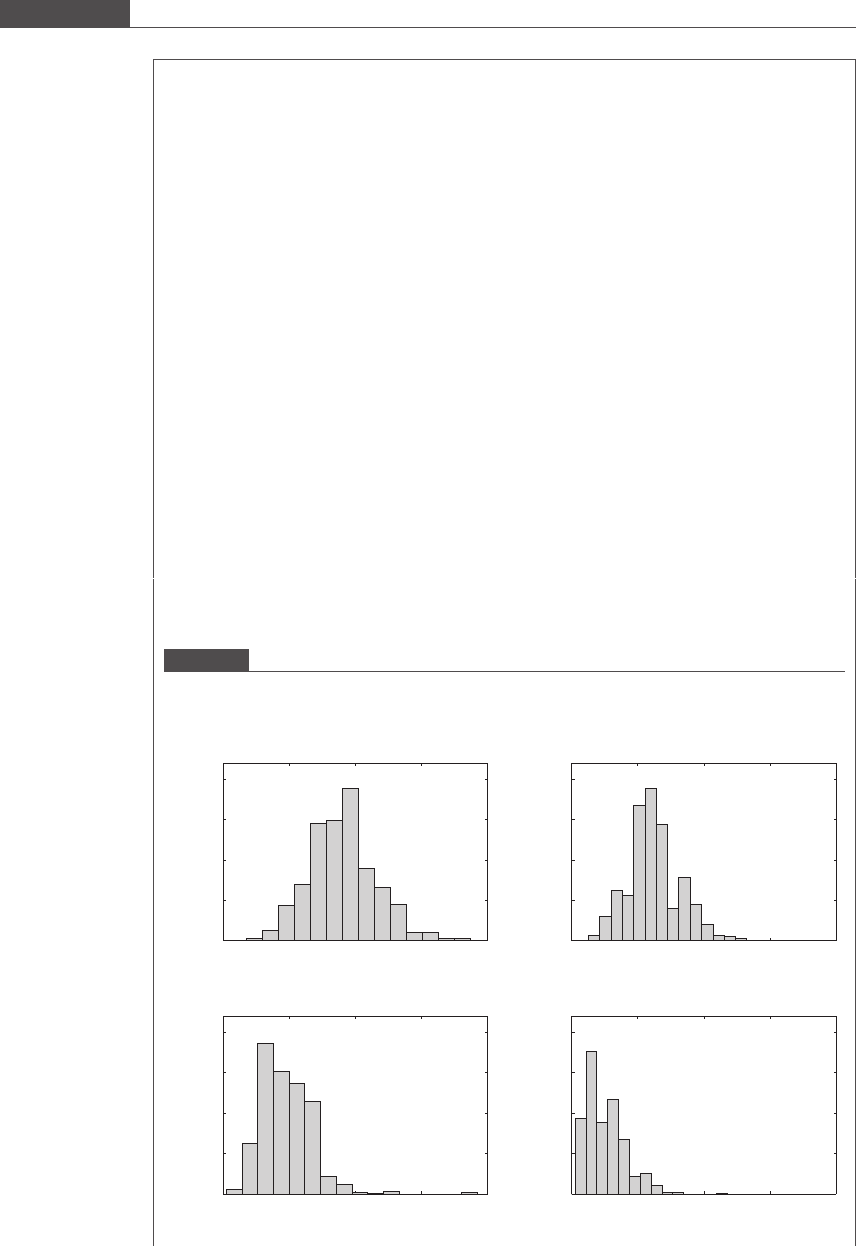
Box 3.1 Physical activity of children aged 9–15
Obesity in youth is associated with lack of sufficient physical activity. The US Department of Health and
Human Services has proposed that children require a minimum of 60 minutes of moderate to vigorous
physical activity on a daily basis. A study was conducted during the period 1991–2007 to assess the
activity levels of children of ages ranging from 9 to 15 on weekdays and weekends (Nader et al., 2008).
The purpose of this study was to observe the patterns of physical activity that the youth engaged in. Their
findings were significant, in that the amount of moderate to vigorous physical activity of these children
showed a steep decline with age.
Participants were recruited from ten different cities from across the USA. The children were required
to wear an accelerometer around their waist throughout the day for seven days. The accelerometer
measured the level of physical activity, which was then converted to energy expended in performing
activities of varying intensities using established empirical equations. Figure 3.1 shows histograms or
frequency distribution curves depicting the amount of moderate to vigorous activity that children of ages
9, 11, 12, and 15 engaged in; n indicates the number of participants in the sample. Note that n
decreased as the children increased in age, either due to some families opting out of the study or older
children experiencing discomfort wearing the accelerometer (an obtrusive and bulky gadget) during
school hours.
A histogram is a frequency distribution plot, in which the number of occurrences of an observation
(here the duration of moderate to physical activity) is plotted. A histogram is commonly used to provide
a pictorial description of data and to reveal patterns that lend greater insight into the nature of the
phenomenon or process generating the data. Easy comparison is enabled by setting the axis limits equal
in each subplot.
Figure 3.1
Histograms of the amount of time that children of ages 9–15 spent in performing moderate to vigorous
physical activity during the weekday (Nader et al., 2008).
0 100 200 300 400
0
50
100
150
200
Number of children
Age 9; n = 839
0 100 200 300 400
0
50
100
150
200
Age 11; n = 850
0 100 200 300 400
0
50
100
150
200
Moderate to vi
g
orous physical activity per weekday (minutes)
Number of children
Age 12; n = 698
0 100 200 300 400
0
50
100
150
200
Age 15; n = 604
(a) (b)
(c) (d)
143
3.1 Introduction

quantities propagate in arithmetic operations that combine these quantities. The
concepts developed in Section 3.6 require you to be familiar with material covered in
Sections 3.2 and 3.5. In the last section of the chapter (Section 3.7) we revisit the
linear least-squares regression method of parameter estimation that was discussed in
Chapter 2. Here, we show how to calculate the error associated with predictions of
the linear least-squares regression technique.
3.2 Characterizing a population: descriptive statistics
Laboratory experiments/testing are often performed to generate quantifiable results,
such as oxygen consumption of yeast cells in a bioreactor, mobility of fibroblasts, or
concentration of drug in urine. In most cases, each experimental run will produce
different results due to
(1) variability in the individuals that make up the population of interest,
(2) slight discrepancies in experimental set-up such as quantity of media or amount of
drug administered,
(3) fluctuations in measuring devices such as weighing balance, pH meter, or spectro-
photometer, and
(4) differences in environmental conditions such as temperature or amount of sunlight
exposure.
Publishing experimental results in a tabular format containing long lis ts of
measured quantities provides little insight and is cumbersome and inefficient for
the scientific and engineering community. Instead, experimental results or sample
data are efficiently condensed into numerical quantities called descriptive statistics
that characterize the population variable of interest. An important distinction
should be noted. Any numerical measure derived from sample data is called a
The mean value for the duration of moderate-to-vigorous physical activity is calculated for each age
group, and given in Table 3.1.
The mean value shifts to the left, i.e. reduces with increase in age. Why do you think the activity
levels reduce with age? A drawback of this study is the bias inherent in the study. The activity levels of
children were underpredicted by the accelerometer, since it was not worn during periods of the day
when children participated in swimming and contact sports.
The spread of the value about the mean can also be calculated using various statistics described in
later sections. Just by visually inspecting the histograms, you can observe that the amount of the spread
about the mean value reduces with age. Study Figure 3.1. What does the amount of spread and its
variation with age tell you?
Table 3.1. Average daily physical activity for the four
age groups studied
Age
group
Mean moderate to vigorous physical activity
per weekday (minutes)
9 181.8
11 124.1
12 95.6
15 49.2
144
Probability and statistics

statistic. Statistics are used to infer characteristics of the population from which the
sample is obtained. A statistic is interpreted as an approximate measure of the
population characteristic being studied. However, if the sample includes every
individual from the population, the statistic is an accurate representation of the
population behavior with respect to the property of interest, and is called a po pula-
tion parameter.
In order to define some useful and common descriptive statistics, we define the
following:
*
n is the sampl e size (number of individuals in the sample) or the number of
experiments,
*
x
i
are the individual observations from the experiments or from the sample; 1 ≤ i ≤ n.
3.2.1 Measures of central tendency
The prim ary goal in analyzing any data set is to provide a single measure that
effectively represents all values in the set. This is provided by a number whose
value is the center point of the data.
The most common measure of central tendency is the mean or average . The mean
of a data set x
i
is denoted by the symbol
x, and is calculated as
x ¼
P
n
i¼1
x
i
n
: (3:1)
While the mean of a sample is written as
x, the mean of a population is represented
by the Greek letter μ to distinguish it as a population parameter as oppos ed to a
sample statistic. If the population size is N, the population mean is given by
μ ¼
P
N
i¼1
x
i
N
:
Equation (3.1) calculates the simple mean of the sample. Other types of means
include the weighted mean, geometric mean, and harmonic mean. While the mean
of the sample will lie somewhere in the middle of the sample, it will usually not
coincide with the mean of the population from which the sample is derived.
Sometimes the population mean may even lie outside the sample’s range of values.
The simple mean is a useful statistic when it coincides with a point of convergence
or a peak value near which the majority of the data points lie. If the data points tend
to lie closely adjacent to or at the mean value, and this can be verified by plotting a
histogram (see Figure 3.1), then the probability of selecting a data point from the
sample with a value close to the mean is large. This is what one intuitively expects
when presented with an average value. If Figure 3.1(a) instead looked like Figure 3.2,
then using the mean to characterize the data would be misleading . This distribution
shows two peaks, rather than one peak, and is described as bimodal (i.e. having two
modes; see the definition of “mode” in this section).
Another useful measure of the central tendency of a data set is the median. If the
data points are arranged in ascending order, then the value of the number that is the
middle data point of the ordered set is the median. Half the numbers in the data set
are larger than the median and the other half of the data points are smal ler. If n is
odd, the median is the ð n þ 1ðÞ=2Þth number in the set of data points arranged in
increasing order. If n is even, then the median is the average of the n=2ðÞth and the
n=2 þ 1ðÞth numbers in the set of data points arrange d in increasing order. The
145
3.2 Characterizing a population: descriptive statistics
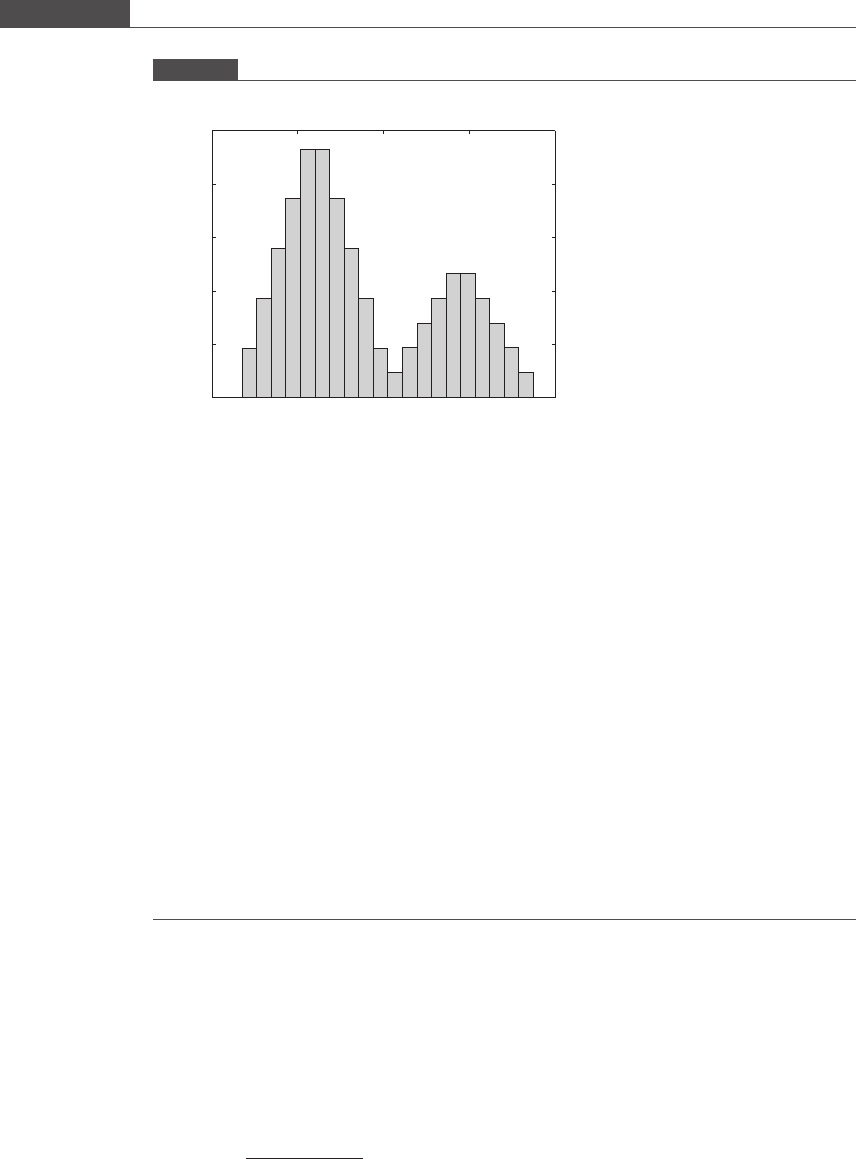
median can be a particularly useful statistic when data points far removed from the
median (outliers) are present in a sample, which tend to shift the mean away from its
point of central tendency.
The mode is the number that appears with greatest frequency and is another
method of characterizing the central tendency of data.
Using MATLAB
MATLAB offers several functions to calculate measures of central tendency. The
MATLAB functions mean, median, and mode are among the six different options
that MATLAB provides to measure the central tendency of data. One syntax for mean is
mu = mean(x)
where x can be a vector or a matrix. If x is a matrix, then MATLAB
1
returns a row
vector containing the means of each column of x.Ifx is a vector, MATLAB returns a
scalar value.
3.2.2 Measures of dispersion
Dispersion refers to the spread of data points ab out the mean. Three common
measures of dispersion in a data set are range, variance, and standard deviation.
The range is the difference between the largest and smallest values in the data set or
sample. While the range is very easy to calculate, it only carries information regard-
ing two data points and does not give a comprehensive picture of the spread of the
other (n – 2) data points about the mean.
Variance is the average of the squared deviations of each data point from the
mean value. For a population of size N, the variance, σ
2
, is calculated as
σ
2
¼
P
N
i¼1
ðx
i
μÞ
2
N
; (3:2)
Figure 3.2
Bimodal distribution.
0 100 200 300 400
0
20
40
60
80
100
Moderate to vigorous physical activity
per weekday (minutes)
Frequency
1
When MATLAB encounters a matrix during any statistical operation, by default it treats the matrix
rows as individual observations and views each column as a different variable.
146
Probability and statistics