Hungerford T.W., Shaw D.J. Contemporary Precalculus: A Graphing Approach
Подождите немного. Документ загружается.

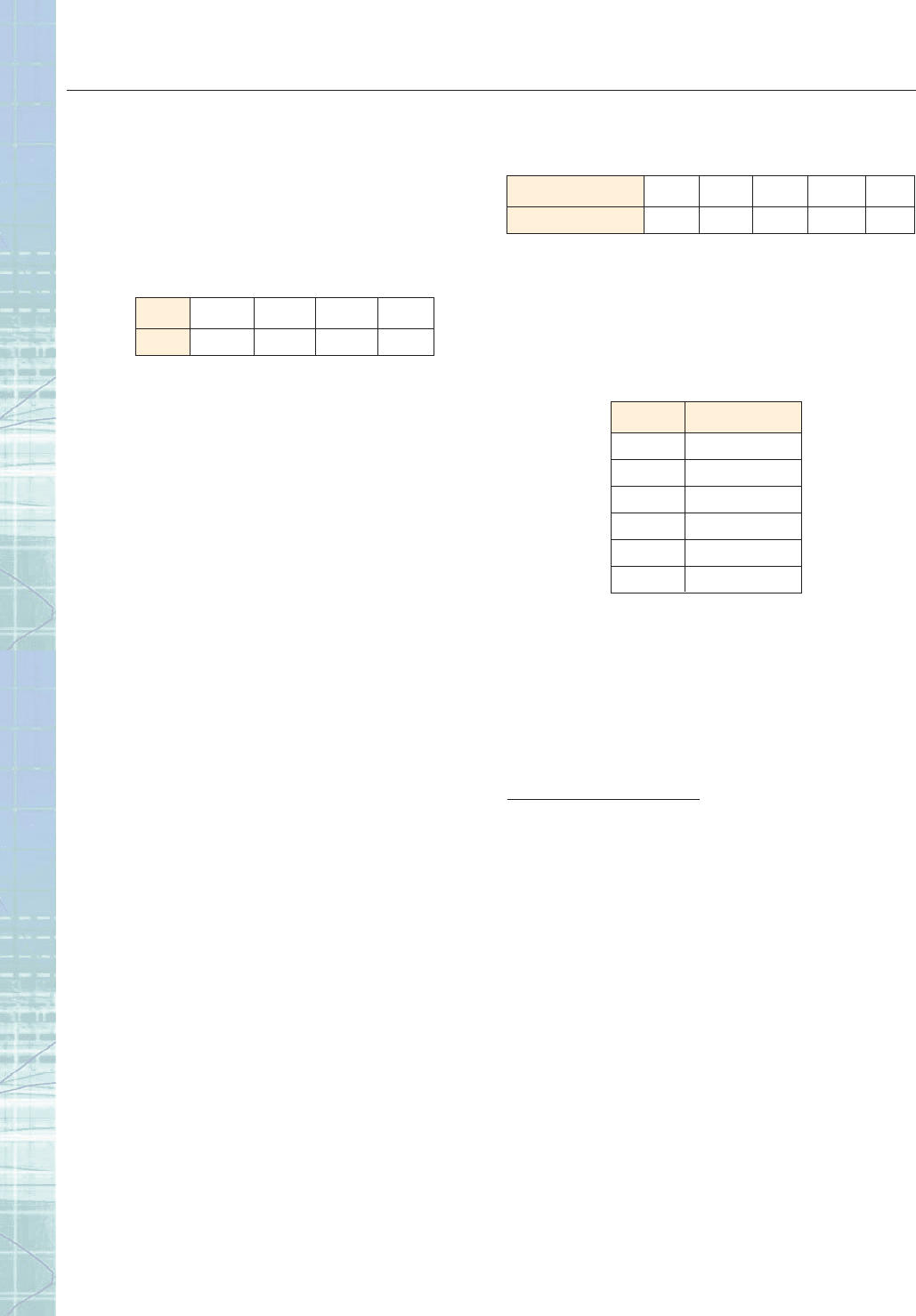
(a) Construct a scatter plot of the data, with x 0 corre-
sponding to 1950 and P measured in thousands.
(b) Does the data appear to be approximately linear? If so,
is there a positive or negative correlation?
(c) Use regression to find a model for the data. Round the
coefficients in your model to three decimal places.
18. The table shows the consumer price index (CPI) in April of
selected years.
136 CHAPTER 2 Graphs and Technology
19. China's oil consumption (in millions of barrels per day) in
selected years is shown in the table.*
(a) Let x 0 correspond to 2000 and use linear regression
to find a model for this data. Round the coefficients to
four decimal places.
(b) Estimate Chinese oil consumption in 2008 and 2018.
20. The approximate sales of Lexus automobiles are shown in
the table.
†
(a) Let x 0 correspond to 2000 and use linear regression
to find a model for this data (in which the number of
vehicles sold is in thousands). Round the coefficients to
four decimal places.
(b) Use your model to estimate sales in 2007.
(c) According to your model, at what rate are sales
increasing?
Year Vehicle Sold
2000 207,000
2001 229,000
2002 236,000
2003 264,000
2004 289,000
2005 300,000
Year 1994 1998 2000 2002
CPI 147.4 162.5 171.3 179.8
Year 2000 2005 2010 2020 2030
Oil Consumption 4.8 6.8 8.5 11.5 14.8
*Data and projections by the Energy Information Administration.
†
Based on data from Autodata Corporation.
For each of the following two models, in which x 0 cor-
responds to 1990, compute the required information for
each blank.
(a) Model: y 4x 131
Data Point Model Point Residual Residual Squared
(4, 147.4) __________ _______ __________
(8, 162.5) __________ _______ __________
(10, 171.3) __________ _______ __________
(12, 179.8) __________ _______ __________
Sum: ______ Sum: __________
(b) Model: y 4.1x 131.5
Data Point Model Point Residual Residual Squared
(4, 147.4) __________ _______ __________
(8, 162.5) __________ _______ __________
(10, 171.3) __________ _______ __________
(12, 179.8) __________ _______ __________
Sum: ______ Sum: __________
(c) Which of the preceding models is the better fit for the
data?

137
Claus Meyer/Black Star Publishing/PictureQuest
Price p Quantity q
(in dollars) (in thousands)
3.25 520
3.00 570
2.75 620
2.50 670
2.25 720
*We use algebra to solve the equation, but you could also use graphical means or an equation solver.
The technological methods are often the best choice for nonlinear supply and demand equations.
DISCOVERY PROJECT 2 Supply and Demand
Economists study the forces at play as buyers and sellers interact in what we call
the market for a product. Because their money is limited, consumers tend to buy
less of a particular product if the price is higher and more if the price is lower. This
is the essence of the demand curve, which is just a depiction of the relationship
between the price of an item and the maximum quantity that people will buy at
that price. The demand curve represents the aggregate demand of all consumers in
a market.
Manufacturers, however, have other considerations. Production costs and lim-
ited resources (materials, labor, technology, and capital, for instance) factor into the
decision to produce at different levels. Ultimately, as the ones supplying (selling)
the product, they want to sell more of them if the price is high and less of them if the
price is low. This is the essence of the supply curve, a depiction of the relationship
between the price of an item and the number of those items the manufacturers are
willing to sell at that price. Like the demand curve, the supply curve represents the
aggregate of all suppliers of a given product.
Here is a simple example of these ideas. The table below shows the quantity
demanded for a hypothetical product at several different prices. You can easily
verify that the equation p 5.85 .005q describes this relationship.
Suppose the supply curve for this product is given by the equation
p .01q 3.75 and that the producer would like to set the price of the product at
$2.80. To find the supply and demand at this price we must solve the appropriate
equation for q when p 2.80.*
Supply Demand
.01q 3.75 p 5.85 .005q p
.01q 3.75 2.80 5.85 .005q 2.80
.01q 6.55 .005q 3.05
q
6
.
.
0
5
1
5
655 q
3
.0
.0
0
5
5
610.

138
These results pose a problem: At a price of $2.80 the producer would be willing
to sell 655,000 items, but the demand curve says that only 610,000 items would
be demanded by consumers at this price. In technical terms, there is a surplus
because supply exceeds demand.
You can readily verify that the situation is reversed when the price is $2.40.
Solving the supply and demand equations when p 2.40 shows that consumer
demand is 690,000 items, but producers are only willing to sell 615,000. In this
case, there is a shortage because demand exceeds supply.
When there is a surplus, sellers are inclined to lower the price because stor-
ing unsold items (or having to discard perishable ones) is expensive. When there
is a shortage, consumers are willing to pay more in order to get a product they
want. These tendencies push the market toward the equilibrium point, at which
buyers and sellers agree on both price and quantity. This occurs when
quantity demanded quantity supplied.
The price p at this point is called the equilibrium price, the price at which supply
equals demand.
The equilibrium point can be found graphically by finding the intersection
point of the supply curve and the demand curve. Because economists normally
put price ( p) on the vertical axis and quantity (q) on the horizontal axis, we follow
the same convention here (using X in place of q and Y in place of p when graph-
ing on a calculator). Figure 1 shows that the equilibrium point for our example is
(640, 2.65), which means that the equilibrium price is $2.65 and that 640,000
items will be demanded and supplied at that price.
Figure 1
Supply and demand curves provide quantities that correspond to a limited collec-
tion of feasible prices at a given point in time. So the corresponding equations are
valid only in this range and may not be valid outside of it. In our example, the
equations are valid when 520 q 720, which determines the viewing window
in Figure 1.
When these ideas are used to make business decisions, the first step is to
determine the supply and demand equations. This is often done by using statisti-
cal data from a trial market, as in the following exercises.
Supply: Y = .01X − 3.75
Demand: Y = −.005X + 5.85
DISCOVERY PROJECT 2
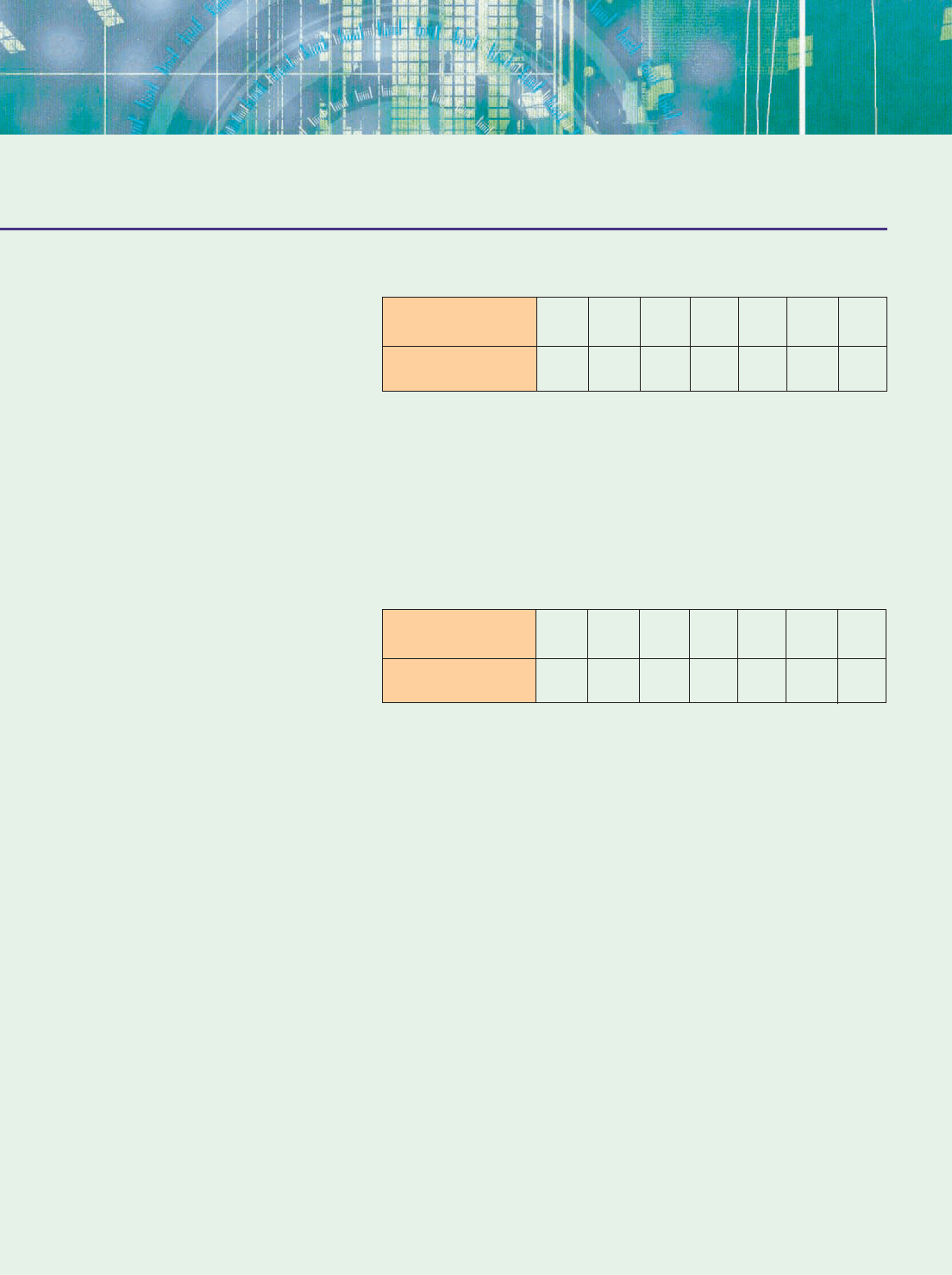
139
1. An economist obtained the following data about the demand for oranges.
Find a linear demand equation of the form p mq b either by using
linear regression or by using the first and last data points [(10, .93) and
(15.5, .60)]. If you use regression, round the coefficients to four decimal
places.
2. Use the model you found in Exercise 1 to find the quantity demanded at a
price of 75¢ per pound.
3. The economist in Exercise 1 also obtained this data about the supply of
oranges.
Find a linear supply equation of the form p mq b either by using lin-
ear regression or by using the first and last data points, as in Exercise 1.
4. Use the model you found in Exercise 3 to find the price at which produc-
ers are willing to supply 1,300,000 tons of oranges.
5. Find the equilibrium point for the situation in Exercises 1 and 3. What is
the equilibrium price? How many oranges will be supplied/demanded at
this price?
6. Here are the equations of the curves for the sale of apples:
p .06q .2 and p .04q .7,
where p is in dollars and q is in 100,000 tons.
(a) Which curve is supply and which one is demand? How can you tell?
(b) Find the equilibrium point. What is the equilibrium price? How many
apples will be supplied/demanded at this price?
7. Graph p .28 together with the demand and supply curves of Exercise 6.
Is this price above or below the equilibrium price? Would this price lead to
a surplus, a shortage, or neither? Explain.
Price per pound 0.20 0.36 0.45 0.55 0.65 0.75 1.00
(dollars)
Quantity supplied 10 11.4 12.4 13.5 14.6 15.5 18
(in 100,000 tons)
Price per pound 0.93 0.90 0.84 0.70 0.65 0.63 0.60
(dollars)
Quantity demanded 10 10.6 11.5 13.8 14.7 15.1 15.5
(in 100,000 tons)
This page intentionally left blank
FUNCTIONS AND GRAPHS
Looking for a house?
If you buy a house, you’ll probably need a mortgage.
If you can get a low interest rate, your monthly
payments will be lower (or, alternatively, you can afford
a more expensive house). The timing of your purchase
can make a difference because mortgage interest rates
constantly fluctuate. In mathematical terms, rates are
a function of time. The graph of this function provides
a picture of how interest rates change. See Exercise 47
on page 174.
141
Chapter
© Bob Perzel/Mira.com/drr.net
1976 1980 1984 1988 1992 1996
15
18%
12
9
6
2000 2004

142
Income
At Least But Less Than Tax
0 $12,500 2.1%
$12,500 $25,000 $262.50 3.45% of amount over $12,500
$25,000 $693.75 4.8% of amount over $25,000
*2006 rates for a single person with one exemption and no deductions; actual tax amount may vary
slightly from this formula when tax tables are used.
Chapter Outline
Interdependence of
Sections
3.1 Functions
3.2 Functional Notation
3.3 Graphs of Functions
3.3.A Special Topics: Parametric Graphing
3.4 Graphs and Transformations
3.4.A Special Topics: Symmetry
3.5 Operations on Functions
3.6 Rates of Change
3.7 Inverse Functions
The concepts of functions and functional notation are central to modern
mathematics and its applications. In this chapter, you will be introduced to
functions and operations on functions, learn how to use functional nota-
tion, and develop skill in constructing and interpreting graphs of functions.
3.1 Functions
■ Understand the definition of a function.
■ Recognize functions in various formats: table, graph, verbal
description.
■ Define a function using an equation or a graph.
■ Create a table of inputs and outputs.
While it is possible to think of functions as completely abstract mathematical ob-
jects, it is usually simpler to picture a function as a description of how one quan-
tity determines another.
EXAMPLE 1
The amount of state income tax Louisiana residents pay depends on their income.
The way that the income determines the tax is given by the following tax law.*
Section Objectives
3.4
3.3 3.6
3.1 3.2 3.7
3.5
So if a single person’s income were $30,000 the income tax would be 693.75
.048(5,000) $933.75. ■
EXAMPLE 2
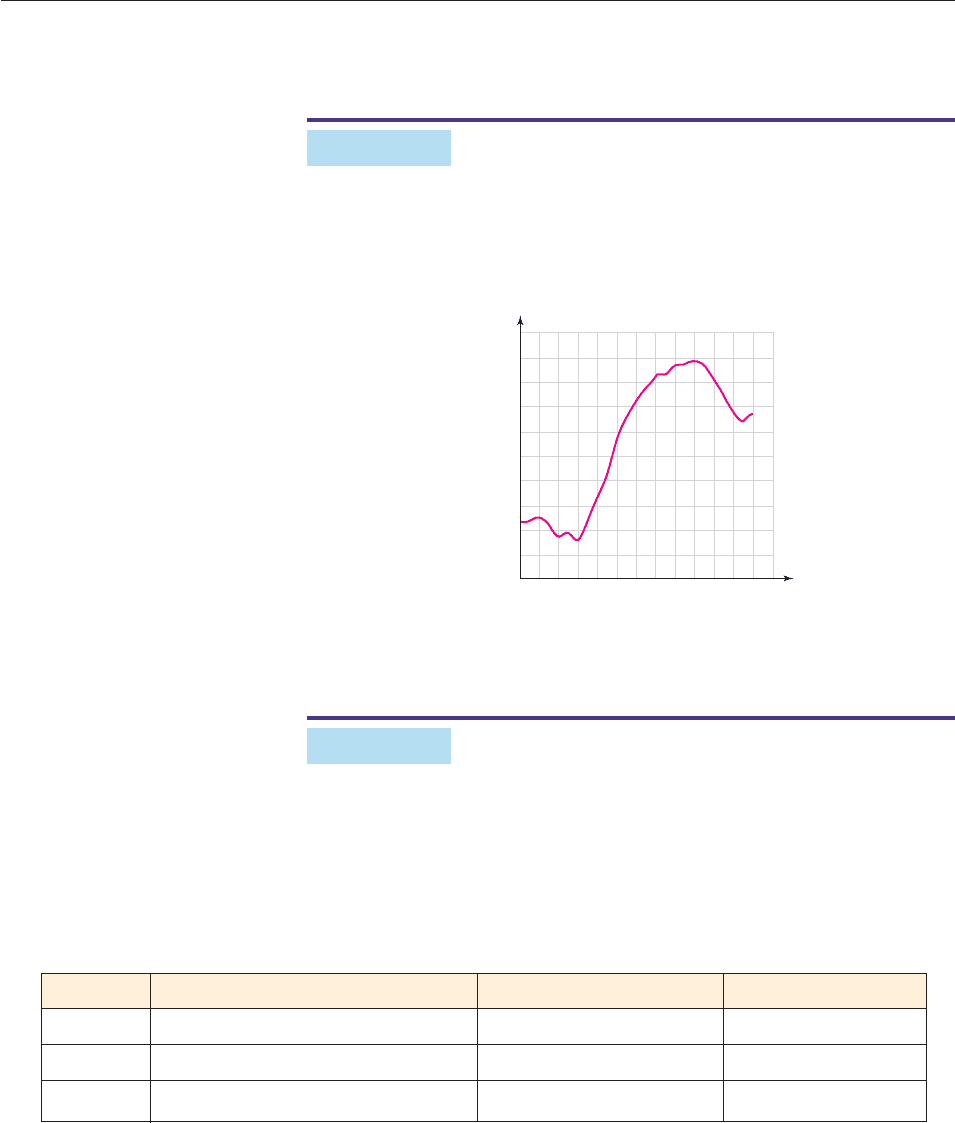
The graph in Figure 3–1 shows the temperatures in Cleveland, Ohio, on April 11,
2001, as recorded by the U.S. Weather Bureau at Hopkins Airport. The graph
indicates the temperature that corresponds to each given time. For example, at
8 A.M. on April 11, 2001, the temperature was 47°F. ■
Figure 3–1
EXAMPLE 3
Suppose a rock is dropped straight down from a high place. Physics tells us that
the distance traveled by the rock in t seconds is 16t
2
feet. Therefore, after 5 sec-
onds the rock has fallen 16(5
2
) 400 feet. ■
These examples share several common features. Each involves two sets of
numbers, which we can think of as inputs and outputs. In each case, there is a rule
by which each input determines an output, as summarized here.
Each of these examples may be mentally represented by an idealized calculator
that has a single operation key: A number is entered [input], the rule key is pushed
[rule], and an answer is displayed [output]. The formal definition of function
incorporates these common features (input/rule/output), with a slight change in
terminology.
4812
A.M. P.M.
Noon
Time of Day
Temperature (degrees Fahrenheit)
16 20 24
x
y
40°
50°
60°
70°
SECTION 3.1 Functions 143
Set of Inputs Set of Outputs Rule
Example 1 All incomes All tax amounts The tax law
Example 2 Hours since midnight Temperatures during the day Time/temperature graph
Example 3 Seconds elapsed after dropping the rock Distance rock travels Distance 16t
2
Think about the phrase “exactly one output.” In Example 2, for each time of day,
there is exactly one temperature. But it is quite possible to have the same temper-
ature (output) occur at different times (inputs). In general,
For each input, the rule of a function determines exactly one output.
But different inputs may produce the same output.
Although real-world situations, such as Examples 1–3, are the motivation for
functions, much of the emphasis in mathematics courses is on the functions them-
selves, independent of possible interpretations in specific situations, as illustrated
in the following examples.
EXAMPLE 4
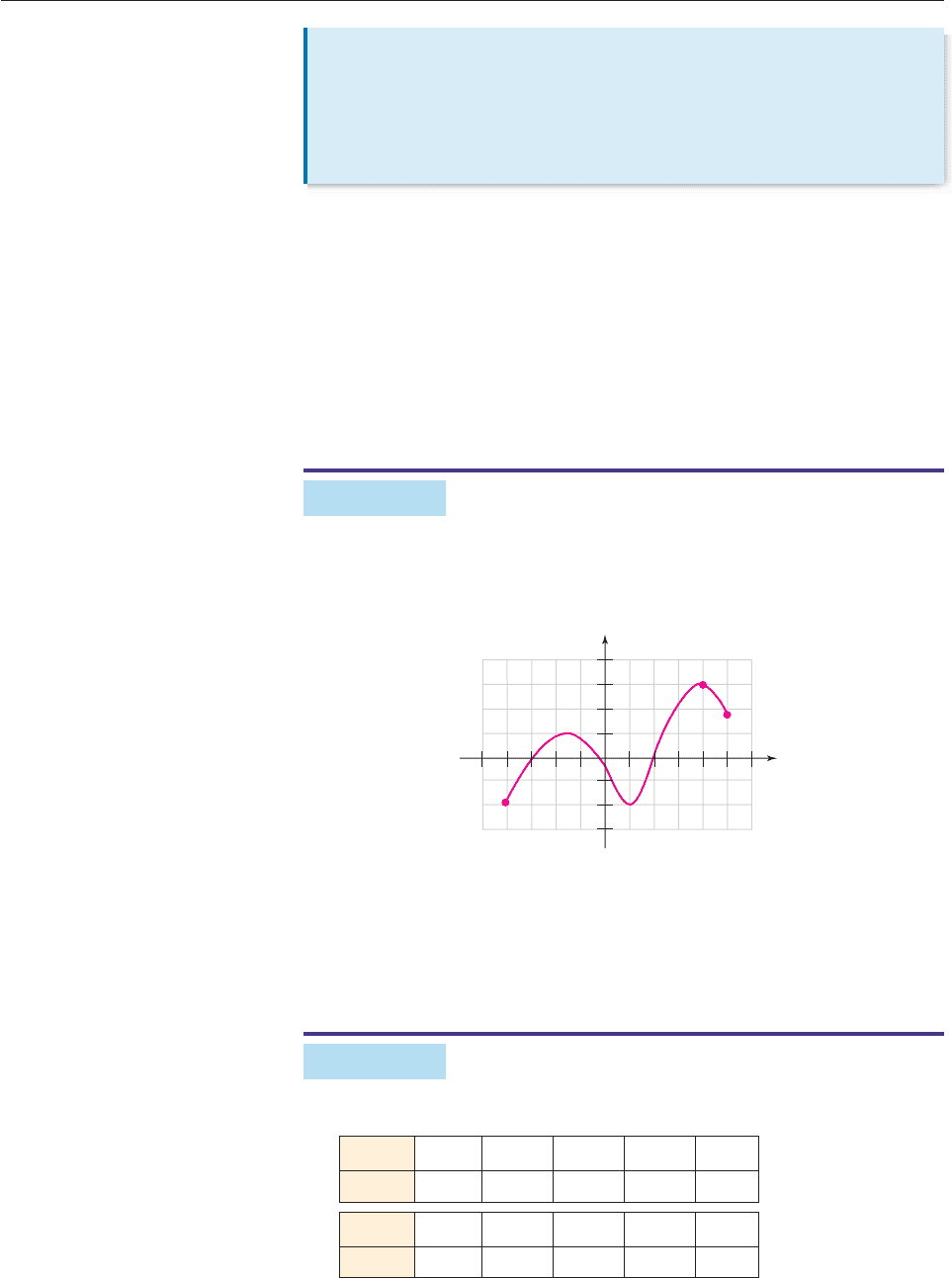
The graph in Figure 3–2 defines a function whose rule is as follows:
For input x, the output is the unique
number y such that (x, y) is on the graph.
Figure 3–2
Input 4, for example, produces output 3 because (4, 3) is on the graph. Similarly,
(3, 0) is on the graph, which means that input 3 produces output 0. Since the first
coordinates of all points on the graph (the inputs) lie between 4 and 5, the domain
of this function is the interval [4, 5]. The range is the interval [2, 3] because all the
second coordinates of points on the graph (the outputs) lie between 2 and 3. ■
EXAMPLE 5
Could either of the following be the table of values of a function?
(a)
(b)
2
2
1 4 63
(4, 3)
5
3
4
1
−2−3−5 −1−4
−2
−1
x
y
144 CHAPTER 3 Functions and Graphs
Functions
A function consists of
A set of inputs (called the domain);
A rule by which each input determines exactly one output;
A set of outputs (called the range).
Input 4 20 2 4
Output 21 7 1 3 7
Input 321 35
Output 402 69
TECHNOLOGY TIP
The greatest integer function is
denoted INT or FLOOR on TI and
HP-39gs, and INTG on Casio. It is
in this menu/submenu:
TI: MATH/NUM
HP-39gs: MATH/REAL
Casio: OPTN/NUM
SOLUTION
(a) Two different inputs (2 and 4) produce the same output, but that’s okay
because each input produces exactly one output. So this table could represent
a function.
(b) The input 3 produces two different outputs (4 and 6), so this table cannot
possibly represent a function. ■
EXAMPLE 6
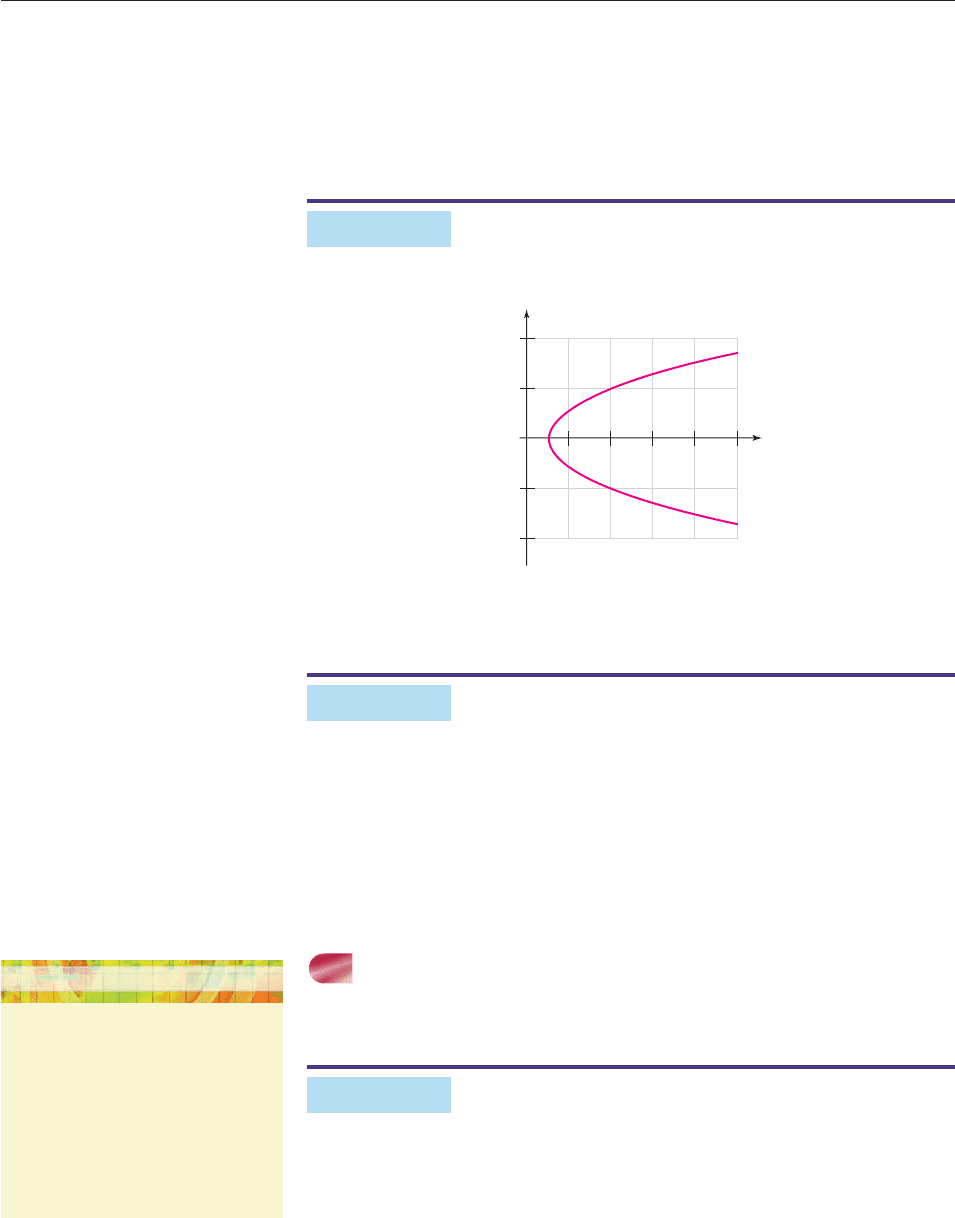
Using the procedure of Example 4, does this graph define a function?
Figure 3–3
SOLUTION No, because the input 4, for example, produces two outputs 2
and 2. (Both (4, 2) and (4, 2) are on the graph.) ■
EXAMPLE 7
The greatest integer function is the function whose domain is the set of all real
numbers, whose range is the set of integers, and whose rule is:
For each input x, the output is the largest integer that is less than or
equal to x. We denote the output by x. For example:
5 5 4.124 4
5
3
1 p 3
3 3 1.5 2 0.01 1 p 4 ■
FUNCTIONS DEFINED BY EQUATIONS AND GRAPHS
Equations in two variables are not the same things as functions. However, many
equations can be used to define functions.
EXAMPLE 8
The equation 4x 2y
3
5 0 can be solved uniquely for y:
2y
3
4x 5
y
3
2x
5
2
y
3
2x
5
2
.
246810
0
2
−2
4
−4
x
y
SECTION 3.1 Functions 145