Alfred DeMaris - Regression with Social Data, Modeling Continuous and Limited Response Variables
Подождите немного. Документ загружается.

ᎏ
1 ⫺
π
i
π
i
ᎏ
⫽ exp(β
0
) exp(β
1
X
i1
) exp(β
2
X
i2
)
...
exp(β
K
X
iK
). (7.19)
The left-hand side of (7.19) is called the odds of event occurrence for the ith case
and is denoted O
i
. The odds is a ratio of probabilities. In particular, it is the ratio of
the probability of the event to the probability of not experiencing the event. If the
odds is, say, 2, the event is twice as likely to occur as not to occur. If the odds is .5,
the event is only one-half as likely to occur as not to occur, and so on. Now suppose
that we have two people, with all covariates the same, except that the first has X
k
equal to x
k
⫹ 1, and the second has X
k
equal to x
k
. The ratio of their odds, or their
odds ratio, denoted ψ
x
k
⫹1
,is
ψ
x
k
⫹1
⫽
ᎏ
O
O
x
k
x
⫹
k
1
ᎏ
⫽
⫽
⫽ exp(β
k
).
exp(β
0
) exp(β
1
X
1
) exp(β
2
X
2
) ⭈⭈⭈exp(β
k
x
k
) exp(β
k
) ⭈⭈⭈exp(β
K
X
K
)
ᎏᎏᎏᎏᎏᎏᎏ
exp(β
0
) exp(β
1
X
1
) exp(β
2
X
2
) ⭈⭈⭈exp(β
k
x
k
) ⭈⭈⭈exp(β
K
X
K
)
exp(β
0
) exp(β
1
X
1
) exp(β
2
X
2
) ⭈⭈⭈exp(β
k
(x
k
⫹ 1)) ⭈⭈⭈exp(β
K
X
K
)
ᎏᎏᎏᎏᎏᎏᎏ
exp(β
0
) exp(β
1
X
1
) exp(β
2
X
2
) ⭈⭈⭈exp(β
k
x
k
) ⭈⭈⭈exp(β
K
X
K
)
NONLINEAR PROBABILITY MODELS 265
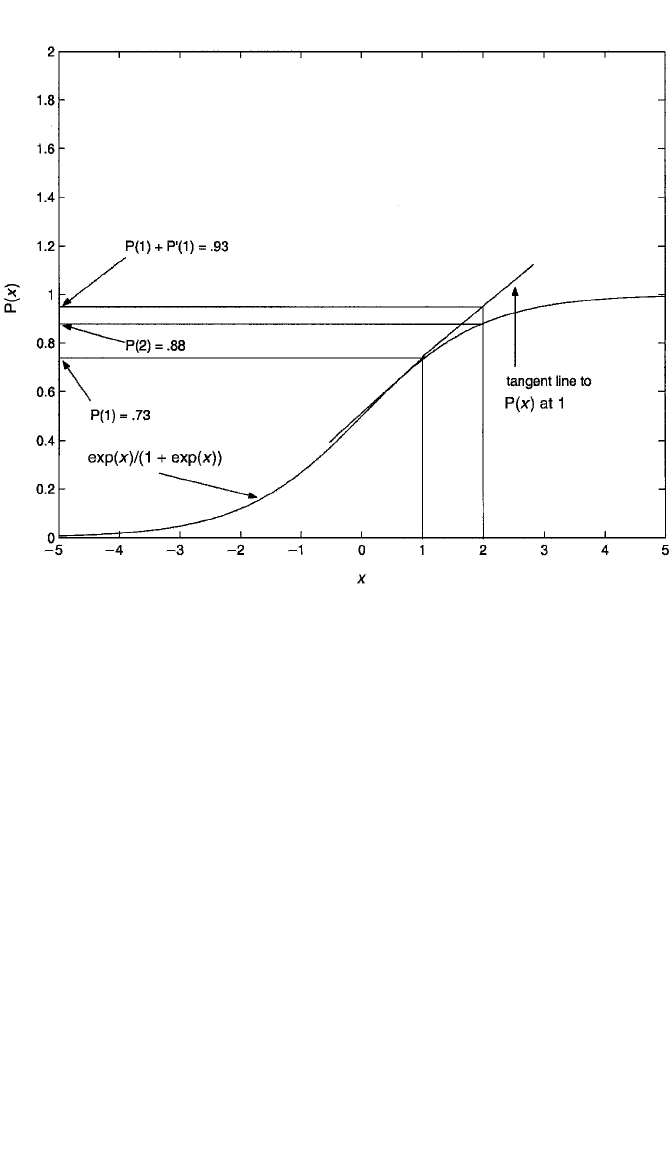
Figure 7.5 First derivative of the logit function with respect to X, versus the unit impact of X on the logit
function.
c07.qxd 8/27/2004 2:54 PM Page 265

That is, O
x
k
⫹1
⫽ exp(β
k
)O
x
k
, or, exp(β
k
) is the factor (Long, 1997), or multiplicative,
change in the odds for each unit increase in X
k
, net of other regressors.
More on the Odds Ratio. Because the odds ratio is such a staple of interpretation
in logistic regression, it is worth some elaboration. Consider the zero-order
relationship between substance abuse and violence for our 4095 couples: Of the
3857 couples with no substance abuse, 485 reported violence. For this group,
the probability of violence is 485/3857 ⫽ .126, and their odds of violence is there-
fore .126/ (1 ⫺.126) ⫽ .144. Among the 238 couples with substance abuse problems,
70 reported violence. Their probability of violence is therefore 70/238 ⫽ .294,
implying an odds of violence of .294/(1 ⫺ .294) ⫽ .416. To quantify the “effect” of
substance abuse on violence, we compute the ratio of these odds, or
.416/.144 ⫽ 2.889. That is, substance abuse raises the odds of violence by a factor of
2.889. Or, the odds of violence is 2.889 times higher for those with substance abuse
problems. Notice that it is incorrect to say that those with substance abuse problems
are “2.889 times as likely” to be violent, since this suggests that their probability of
violence is 2.889 times higher. In fact, their probability of violence is only
.294/.126 ⫽ 2.333 times higher. The ratio of probabilities, called the relative risk,is
equivalent to the odds ratio only if the probabilities are both very small. The reason
for this is that for two people, a and b, their odds ratio can be written
ψ
a,b
⫽
ᎏ
π
π
a
b
/
/
(
(
1
1
⫺
⫺
π
π
a
b
)
)
ᎏ
⫽
ᎏ
π
π
a
b
ᎏ
ᎏ
1
1
⫺
⫺
π
π
b
a
ᎏ
.
The first term in the rightmost expression is the relative risk. If both probabilities are
small, the second term in this expression will be close to 1, in which case the odds
ratio is approximately equal to the relative risk.
Logistic regression effects can also be expressed in terms of percent changes in
the odds. The percent change in the odds for a unit increase in X
k
is
% O
x
k
⫹1
⫽ 100
冢
ᎏ
O
x
k
⫹
O
1
⫺
x
k
O
x
k
ᎏ
冣
⫽ 100
冢
ᎏ
O
O
x
k
x
⫹
k
1
ᎏ
⫺1
冣
⫽ 100[exp(β
k
) ⫺ 1].
For example, based on the logit estimates in Table 7.1, every year longer the couple
had been together at time 1 lowers the odds of violence by 100[exp(⫺.046) ⫺ 1] ⫽
⫺4.5, or about 4.5%. Each unit increase in male isolation increases the odds of
violence by 100[exp(.02) ⫺ 1] ⫽ 2.02, or 2.02%. Now if two people are c units apart
on X
k
, where c is any value, their odds ratio is ψ
x
k
⫹c
⫽ exp(β
k
c), and the percent
change in the odds for a c-unit increase in X
k
is 100[exp(β
k
c) ⫺ 1]. With respect to
relationship duration, again, being together 10 years longer lowers the odds of vio-
lence by 100[exp(⫺.046 ⫻ 10) ⫺ 1] ⫽⫺36.872, or about 37%. Or, a 5-unit increase
in male’s isolation elevates the odds of violence by 100[exp(.02 ⫻ 5) ⫺ 1] ⫽ 10.517,
or about 10.5%.
Confidence intervals for odds ratios can be found by exponentiating the endpoints
of confidence intervals for the coefficients. As an example, a 95% confidence inter-
val for the effect of relationship duration on the logit of violence, from Table 7.1, is
266 REGRESSION WITH A BINARY RESPONSE
c07.qxd 8/27/2004 2:54 PM Page 266

⫺.046 ⫾ 1.96(.005) ⫽ (⫺.056, ⫺.036). A 95% confidence interval for the ratio of the
odds of violence for those who are a year apart on relationship duration is then
[exp(⫺.056), exp(⫺.036)] ⫽ (.946, .965). In other words, we can be 95% confident
that each year longer the couple had been together at time 1 lowers the odds of vio-
lence by between 3.5 and 5.4%.
Odds ratios are also useful in estimating changes in the probability of event occur-
rence with changes in predictors once a baseline probability has been calculated. For
example, let our baseline couple be married, nonminority, alcohol/drug-free, and
average in relationship duration, female’s age at union, male isolation, and economic
disadvantage. This couple’s odds of violence is exp(⫺2.151) ⫽ .1164. Now, the prob-
ability is equal to O
i
/(1 ⫹ O
i
), so the couple’s probability of violence is .1164/(1 ⫹
.1164) ⫽ .1043. If this couple were to develop a substance abuse problem, we would
estimate that their odds of violence would become (.1164) [exp(1.029)] ⫽ .3257. This
means that their probability of violence would be .3257/(1 ⫹ .3257) ⫽ .2457, or they
would experience a .1414 increase in the probability of violence. In that logit
coefficients are especially interpretable, logistic regression will be the focus of the rest
of this chapter and the next chapter as well.
Standardized Coefficients. In linear regression, standardized coefficients are often
employed to compare the relative impacts of different predictors in the same equa-
tion. The standardized coefficient is the product of the unstandardized coefficient
times the ratio of the standard deviation of X
k
to the standard deviation of Y. In logis-
tic (or probit) regression, calculating a standardized coefficient is not as straightfor-
ward. Based on the latent-variable development of these models, we would need an
estimate of the standard deviation of Y*, in which case the standardized coefficient
would be
b
s
k
⫽ b
k
ᎏ
s
s
y
x
*
k
ᎏ
.
But Y* is unobserved, so its standard deviation is not readily estimated [but see
Long (1997) for a suggested estimation procedure]. One solution (found in earlier
versions of SAS) is to partially standardize the coefficients by multiplying them by
s
x
k
/σ
ε
, where σ
ε
is the standard deviation of the error term in the latent-variable
equation. In logit, σ
ε
is equal to about 1.814, the square root of π
2
/3 (in probit, it is
equal to 1). Applying this transformation to the coefficients for relationship duration
(SD ⫽ 12.823), female’s age at union (SD ⫽ 7.081), and male’s isolation (SD ⫽
6.296) in the logit equation for violence, we get partially standardized coefficients of
⫺.325, ⫺.105, and .069, respectively. Consistent with the magnitudes of the unstan-
dardized coefficients, the partially standardized coefficients point to the effect of
relationship duration as being the largest of the three in magnitude.
Numerical Problems. Estimation via maximum likelihood is frequently plagued by
numerical difficulties. Some of these are also common to estimation with least
squares. For example, multicollinearity creates the same types of problems in logis-
tic regression and other binary response models that it does in OLS: inflation in the
NONLINEAR PROBABILITY MODELS 267
c07.qxd 8/27/2004 2:54 PM Page 267

magnitudes of estimates as well as in their standard errors, or in the extreme case,
counterintuitive signs of coefficients (Schaefer, 1986). Collinearity diagnostics are
not necessarily available in logit or probit software (e.g., none are currently provided
in SAS’s procedure LOGISTIC). However, in that collinearity is strictly a problem
connected with the explanatory variables, it can also be addressed with linear regres-
sion software. In SAS, I use collinearity diagnostics in the OLS regression proce-
dure (PROC REG) to evaluate linear dependencies in the predictors. The best single
indicator of collinearity problems is the VIF for each coefficient (as discussed in
Chapter 6). As mentioned previously, VIF’s greater than about 10 signify problems
with collinearity.
Other problems are more unique to maximum likelihood estimation. The first per-
tains to zero cell counts. If the cross-tabulation of the response variable with a given
categorical predictor results in one or more zero cells, it will not be possible to esti-
mate effects associated with those cells in a logistic regression model. In an earlier
article (DeMaris, 1995) I presented an example using the 1993 General Social
Survey in which the dependent variable is happiness, coded 1 for those reporting
being “not too happy,” and 0 otherwise. Among categorical predictors, I employ
marital status, represented by four dummy variables (widowed, divorced, separated,
never married) with married as the reference group, and race, represented by two
dummies (black, other race), with white as the reference group. Among other mod-
els, I try to estimate one with the interaction of marital status and race. The prob-
lem is that among those in the “other race” category who are separated, all
respondents report being “not too happy,” leaving a zero cell in the remaining cate-
gory of the response. I was alerted that there was a problem by the unreasonably
large coefficient for the “other race ⫻ separated” term in the model and by its asso-
ciated standard error, which was about 20 times larger than any other. Running the
three-way cross-tabulation of the response variable by both marital status and race
revealed the zero cell. An easy solution, in this case, was to collapse the categories
of race into “white” versus “nonwhite” and then to reestimate the interaction. If col-
lapsing categories of a categorical predictor is not possible, it could be treated as
continuous, provided that it is at least ordinal scaled (Hosmer and Lemeshow, 2000).
A problem that is much more rare occurs when one or more predictors perfectly
discriminates between the categories of the response. (Actually, it’s when some lin-
ear combination of the predictors, which might be just one predictor, discriminates
the response perfectly.) Suppose, as a simple example, that all couples with incomes
under $10,000 per year report violence and all couples with incomes over $10,000
per year report being nonviolent. In this case, income completely separates the out-
come groups. Correspondingly, the problem is referred to as complete separation.
When this occurs, the maximum likelihood estimates do not exist (Albert and
Anderson, 1984; Santner and Duffy, 1986). Finite maximum likelihood estimates
exist only when there is some overlap in the distributions of explanatory variables
for groups defined by the response variable. If the overlap is only marginal—say, at
a single or at a few tied values—a problem of quasicomplete separation develops. In
either case, the analyst is again made aware that something is amiss by unreasonably
268 REGRESSION WITH A BINARY RESPONSE
c07.qxd 8/27/2004 2:54 PM Page 268

large estimates, particularly of coefficient standard errors. SAS also provides a warn-
ing if the program can detect separation problems. Surprisingly, the suggested solu-
tion for this problem is to revert to OLS regression. One advantage of the LPM over
logit or probit is that estimates of coefficients are available under complete or quasi-
complete separation (Caudill, 1988).
An example of quasicomplete separation comes from a recent analysis of 1995
data from a national sample of American women (DeMaris and Kaukinen, 2003).
Using logistic regression, we examined the impact of violent victimization on the
tendency to engage in binge drinking among a sample of 7353 women from the
NVAWS survey (described in Chapter 1). The coefficient for needing dental care due
to a physical assault was ⫺14.893 with a standard error of 1556.7, and SAS pro-
vided a warning that there was “possibly” a quasicomplete separation problem.
Upon closer inspection, we saw that the dummy for needing dental care exhibited
no variation among the binge drinkers—all had values of 0, whereas values of 0 and
1 were observed among the nonbinge drinkers. An easy solution to the problem was
simply to eliminate this dummy from the set of regressors.
EMPIRICAL CONSISTENCY AND DISCRIMINATORY POWER
IN LOGISTIC REGRESSION
In this final section of the chapter we take up the issues of empirical consistency and
discriminatory power. Here, the focus is on the logistic regression model, as more
work has been done in these areas on the logit model than on other specifications.
Empirical Consistency
Recall that empirical consistency refers to the property that Y behaves in accordance
with model predictions. One way to assess this might be as follows. For each distinct
covariate pattern in the data, compare the observed numbers of observations falling
into the interest (Y ⫽ 1) and reference (Y ⫽ 0) categories on Y with the expected num-
bers from the hypothesized model. A chi-squared test could then inform us whether or
not the fit of observed to expected frequencies is within sampling error. Unfortunately,
with at least one continuous covariate in the model, the number of covariate patterns
in the data is usually close to the sample size. In that case, there is only one observa-
tion in each covariate pattern, and the chi-squared statistic does not have the desired
chi-squared distribution under the null hypothesis of a good model fit. This statistic
would have the chi-squared distribution only when the expected frequencies are large
(Hosmer and Lemeshow, 2000).
Hosmer and Lemeshow (2000) solve this problem by grouping the covariate pat-
terns in such a way that the expected frequencies can become large as n increases,
allowing the appropriate asymptotic principles to operate. In particular, the Hosmer–
Lemeshow goodness-of-fit test for logistic regression groups observations by deciles
of risk. That is, group 1 consists of the n/10 subjects with the lowest predicted
EMPIRICAL CONSISTENCY AND DISCRIMINATORY POWER 269
c07.qxd 8/27/2004 2:54 PM Page 269

probabilities of being in the interest category on Y; group 2 consists of the n/10
subjects with the next-lowest predicted probabilities of being in the interest
category on Y, and so on. Once these 10 groups have been identified, the expected
number of observations in the interest category on Y in each group is calculated as
the sum of the π
ˆ
over all subjects in that group. Similarly, the expected number of
cases in the reference category is the sum of (1 ⫺ π
ˆ
) over all cases in the same group.
The numbers of cases observed in the interest and reference categories are readily
tallied from the data. The Hosmer–Lemeshow statistic is then the Pearson chi-squared
statistic for the 10 ⫻ 2 table of observed and expected frequencies. Under the null
hypothesis that the model is empirically consistent, this statistic has approximately
a chi-squared distribution with 8 degrees of freedom (Hosmer and Lemeshow, 2000).
A significant χ
2
indicates a model that is not empirically consistent. Hosmer and
Lemeshow (2000) suggest that a conservative rule regarding the sample size needed
for this test is that all expected frequencies should exceed 5.
Table 7.3 shows the results of employing this test with the logit model in Table
7.1. The table shows each decile of risk, along with the number of couples in each
group (which should be generally around 4095/10 艐410), the number of violent
couples, the expected number of violent couples based on the model, the number of
nonviolent couples, the expected number of nonviolent couples based on the model,
and finally, the Hosmer–Lemeshow χ
2
. As is evident, the χ
2
is just significant at
p ⫽ .046. This suggests that the model is not quite empirically consistent. We will
see in Chapter 8 that this is due to the omission of some important effects from the
model.
270 REGRESSION WITH A BINARY RESPONSE
Table 7.3 Observed and Expected Frequencies of Violent and Nonviolent Couples
within Deciles of Risk According to the Logit Model of Table 7.1
Decile
Violent Nonviolent
of Risk N Obs. Exp. Obs. Exp.
1 413 19 14.34 394 398.66
2 412 30 24.50 382 387.50
3 409 24 33.95 385 375.05
4 412 34 42.55 378 369.45
5 410 42 49.33 368 360.67
6 409 68 55.83 341 353.17
7 411 69 62.72 342 348.28
8 410 65 69.64 345 340.36
9 410 72 80.35 338 329.65
10 399 132 121.66 267 277.34
Total 4095 555 554.87 3540 3540.13
Hosmer–Lemeshow χ
2
15.743
df 8
p .046
c07.qxd 8/27/2004 2:54 PM Page 270

Discriminatory Power
Here I consider two different approaches to assessing discriminatory power: the
classification table and analogs of the OLS R
2
.
Classification Tables. One means of assessing the ability of the model to discrimi-
nate among categories of the response is to examine whether it can accurately clas-
sify observations into each category of Y. Following the biostatistics literature, I
refer to observations that fall into the interest category as cases and those falling into
the reference category as controls (Hosmer and Lemeshow, 2000). A classification
table for logistic regression is a cross-tabulation of case versus control status based
on model predictions, against whether or not observations are actually cases or con-
trols. Table 7.4 presents the classification table for couple violence based on the logit
model in Table 7.1. The model-based classification procedure is as follows. We pick
a criterion value for π
ˆ
, and if an observation’s model-generated π
ˆ
is greater than that
criterion, it is classified as a case; otherwise, it is classified as a control. By default,
the criterion is usually taken to be .5, and this is the value used to construct Table 7.4.
We see that of the 555 couples actually observed to be violent, only 6 were
classified as violent by the model. The sensitivity of classification, or the proportion
of actual cases that are classified as cases, is 6/555, or 1.08%. The specificity of
classification, or the proportion of actual controls that are classified as controls, is
3537/3540, or 99.92%. The false positive rate, or the proportion of actual controls
that are classified as cases, is 1 ⫺ specificity, or .08%. Notice that the sensitivity is
higher than the false positive rate, and this is typically what we find. If the model
affords no improvement in prediction of the response over what could be achieved
by random guessing, these will be the same. In this particular example, specificity
is very high but sensitivity is abysmally low. However, the proportion correctly
classified is (6 ⫹ 3537)/4095⫽ .8652, or 86.52% of observations. The proportion
EMPIRICAL CONSISTENCY AND DISCRIMINATORY POWER 271
Table 7.4 Classification Table for Violence Based on the Logit Model
in Table 7.1
Observed
Classified Violent Nonviolent Total
Violent 6 3 9
Nonviolent 549 3537 4086
Total 555 3540 4095
Criterion .50
Sensitivity 1.08%
Specificity 99.92%
False positive rate .08%
Percent correctly classified 86.52%
Percent correct by chance 76.57%
c07.qxd 8/27/2004 2:54 PM Page 271

classified correctly can be quite misleading, as it is here, because it depends both on
the proportion of cases falling into the interest category on Y and on the classification
criterion. Because the probability of violence in the sample is relatively low, very
few cases’ predicted values meet the .5 criterion. Hence, almost all of the cases are
predicted to be controls. As most of the cases are, indeed, controls, we get correct
predictions most of the time. But ideally, we want good prediction of cases as well
as good prediction of controls.
We can get a sense of how good the percent correctly classified is by consider-
ing what that would be if we ignored the model. Of course, we could just predict
that everyone is nonviolent and be correct 86.45% of the time. However, this mis-
classifies all of the violent couples. The preferred chance classification rule is one
that maximizes prediction of both controls and cases. Following the reasoning I
articulated in prior work (DeMaris, 1992), the chance classification rate is figured
as follows. In that 13.55% of couples in the sample are violent, we predict, with
probability equal to .1355, that a couple is violent. On the other hand, we predict,
with probability equal to 1 ⫺ .1355 ⫽ .8645, that a couple is nonviolent. What is
the chance that we will make a correct prediction? Our prediction is correct if an
actual case was predicted to be a case and an actual control was predicted to be a
control. Now, since couples are actually violent with probability equal to .1355 and
actually nonviolent with probability equal to .8645, the probability of a correct
prediction is
P(case predicted to be a case)P(observation is a case)
⫹ P(case predicted to be a control)P(observation is a control).
In this case, we have .1355
2
⫹ .8645
2
⫽ .7657, or 76.57% of couples will be cor-
rectly predicted, based only on the marginal (i.e., sample) probability of violence. In
general, the chance correct prediction rate is p
2
⫹ (1 ⫺ p)
2
, where p is the sample
proportion in the interest category on Y.
If a lower criterion value is employed, we can achieve greater sensitivity, although
at the expense of specificity. For example, if the criterion is .1355, the marginal pro-
portion of violent couples, sensitivity increases to 66.67%, but specificity drops to
58.19%, and the false positive rate is 41.81%. The percent correctly classified, more-
over, falls to only 59.34%. We could continue varying the criterion value in this man-
ner, each time examining properties of the classification. In fact, this is the strategy
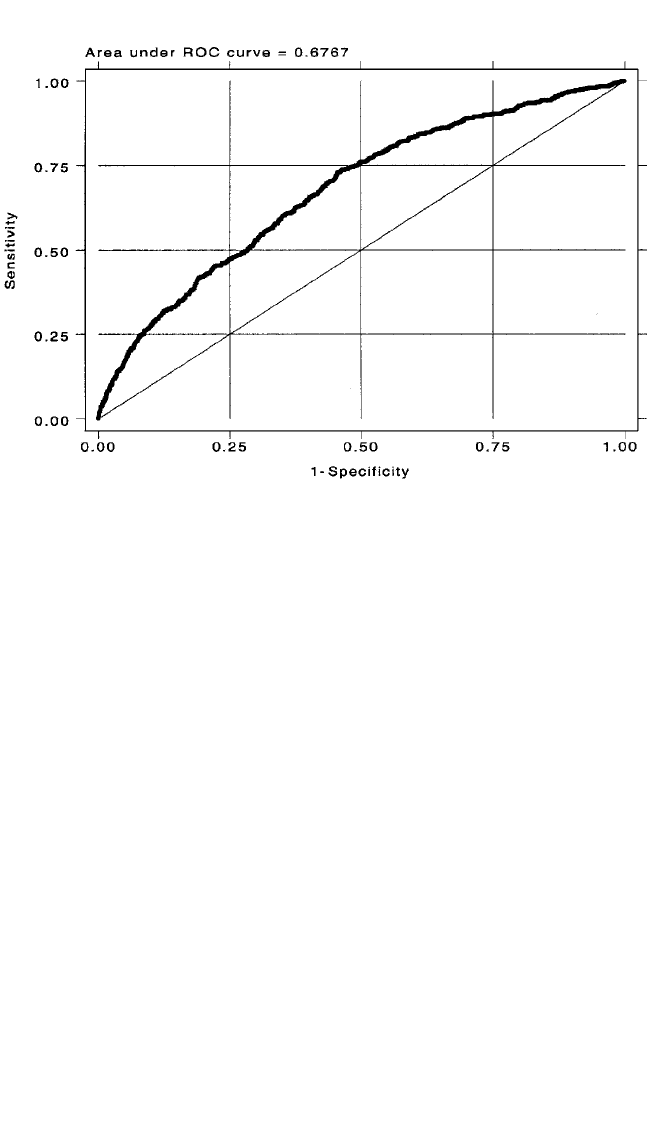
behind the receiver operating characteristic (ROC) curve (Hosmer and Lemeshow,
2000; Kramar et al., 2001). This is a plot of the sensitivity against the false positive
rate resulting from the criterion being varied throughout the range 0 to 1. Such a plot
is shown in Figure 7.6 for the logit model of couple violence. Ideally, the plot should
form a bow-shaped curve over the 45⬚ line in the center of the plot, the line repre-
senting no improvement in prediction afforded by the model. The key statistic in
evaluating the quality of the ROC is the area under the curve (AUC). This area is
interpreted as the likelihood that a case will have a higher π
ˆ
than a control across
the range of criterion values investigated (Hosmer and Lemeshow, 2000). Hosmer
and Lemeshow (2000) suggest the following guidelines regarding AUC:
272 REGRESSION WITH A BINARY RESPONSE
c07.qxd 8/27/2004 2:54 PM Page 272
AUC ⫽ .5 The model has no discriminatory power.
.7 ⬍ AUC ⬍ .8 The model has acceptable discriminatory power.
.8 ⬍ AUC ⬍ .9 The model has excellent discriminatory power.
AUC ⬎ .9 The model has outstanding discriminatory power.
As the AUC in Figure 7.6 is .6767, the logit model in Table 7.1 does not quite
have acceptable discriminatory power.
Analogs of R
2
. In linear regression, R
2
is the most commonly used measure for
assessing the discriminatory power of the model. R
2
possesses three properties that
make it especially attractive for this purpose. First, it is standardized to fall in the
range [0,1], equaling 0 when the model affords no predictive efficacy over the mar-
ginal mean, and equaling 1 when the model perfectly accounts for, or discriminates
among, the responses. Second, it is nondecreasing in x, meaning that it cannot decrease
as regressors are added to the model. Third, it can be interpreted as the proportion of
variation in the response accounted for by the regression. Although many R
2
analogs
have been suggested for logistic regression (see, e.g., Long, 1997; Mittlboeck and
Schemper, 1996), they fail to satisfy one or more of these properties. As a conse-
quence, none is in standard use. In this section I discuss a handful of such measures,
beginning with the two that I think are best.
The first issue to be considered is: What is the theoretical criterion being esti-
mated? This depends on the nature of the binary response. If the response is a proxy
for a latent scale, Y*, the quantity of interest could be considered to be the variation
EMPIRICAL CONSISTENCY AND DISCRIMINATORY POWER 273
Figure 7.6 Receiver operating characteristic curve for the logit model in Table 7.1.
c07.qxd 8/27/2004 2:54 PM Page 273

in Y* accounted for by the regression. Recall from Chapter 3 that P
2
is the population
proportion of variation in Y that is variation in the linear predictor. In that the logistic
regression coefficients are estimates of the effects of the regressors on Y*, an estima-
tor of the P
2
for the regression of Y*, suggested by McKelvey and Zavoina (1975), is
R
2
MZ
⫽
ᎏ
V
冢
冱
V
冢
b
冱
k
X
b
k
冣
k
X
⫹
k
冣
π
2
/3
ᎏ
,
(7.20)
where the b
k
are the sample logistic regression coefficients, and therefore V(冱b
k
X
k
) is
an estimate of the variance of the linear predictor for the regression of Y*. The term
π
2
/3 is the variance of ε for this regression, because the error is assumed to follow the
standard logistic distribution. Therefore, the denominator of equation (7.20) is an esti-
mate of V(Y*). Because the numerator and denominator are each consistent for their
population counterparts, R
2
MZ
is a consistent estimator of the P
2
for Y*. For the logit
model in Table 7.1, R
2
MZ
⫽ .127. R
2
MZ
is the measure that I recommend if one is inter-
ested in the variation accounted for in the latent scale underlying the binary response.
An extensive simulation found R
2
MZ
to be least biased and closest to the actual param-
eter value across a range of conditions, compared to several other estimators of P
2
in
logistic regression (DeMaris, 2002c). Although R
2
MZ
has an explained variance inter-
pretation and is bounded by 0 and 1, it is not necessarily nondecreasing in x.
On the other hand, suppose that the response is a naturally dichotomous variable,
with no underlying continuous referent. It turns out that a generalization of the variance-
decomposition principle invoked in Chapters 2 and 3 to derive P
2
can be drawn upon to
decompose the variation in a binary variable. From Greene (2003), a general expression
for the decomposition of the variance of Y in a joint distribution of Y and x is
V(Y) ⫽ V
x
[E(Y 冟x)] ⫹ E
x
[V(Y 冟x)].
That is, the variance in Y equals the variance of the conditional mean of Y given x plus
the mean of the conditional variance of Y given x. Dividing through by V(Y ) results in
1 ⫽
ᎏ
V
x
[
V
E
(
(
Y
Y
)
冟x)]
ᎏ
⫹
ᎏ
E
x
[
V
V
(
(
Y
Y
)
冟x)
ᎏ
. (7.21)
Applying these principles to the linear regression model leads to the expression for P
2
(see Chapter 3). Now in linear regression, V(Y 冟x) ⫽ V(ε) ⫽ σ
2
, and the average of σ
2
over x is just σ
2
. So the second term on the right-hand side of (7.21) is just σ
2
/V(Y )
for the linear regression model. Recall that the variance of a binary response, however,
is π(1 ⫺ π), which is a function of the conditional mean. Therefore, the conditional
variance of Y given x,V(Y 冟x), is π(1 ⫺ π) 冟 x. Hence, a binary-response analog of P
2
,
which I denote by ∆,is
∆ ⫽ 1 ⫺
ᎏ
E
x
[π
π
(
(
1
1
⫺
⫺
π
π
)
)
冟x]
ᎏ
, (7.22)
where π in the denominator is the population marginal probability that Y ⫽ 1 (its
sample counterpart is p).
274 REGRESSION WITH A BINARY RESPONSE
c07.qxd 8/27/2004 2:54 PM Page 274