Nof S.Y. Springer Handbook of Automation
Подождите немного. Документ загружается.

1285
Library Autom
72. Library Automation
Michael Kaplan
Library automation has a rich history of 130 years
of development, from the standardization of card
catalogs to the creation of the machine-readable
cataloging (MARC) communications format and
bibliographic utilities. Beginning in the early 1980s
university libraries and library automation ven-
dors pioneered the first integrated library systems
(ILS). The digital era, characterized by the prolifer-
ation of content in electronic format, brought with
it the development of services for casual users as
well as scholarly researchers — services such as
OpenURL linking and metasearching and library
staff tools such as electronic resource manage-
ment systems. Libraries are now reacting to user
demands for quick, easy, and effective discovery
and delivery such as those they have grown ac-
customed to through the use of Google and other
Internet heavyweights, by developing a new series
of Library 2.0-based discovery-to-delivery (D2D)
applications. These newest offerings deliver an
up-to-date user experience, allowing libraries to
retain their back-office systems (e.g., acquisitions,
cataloging, circulation) and add to or replace them
as needed. In the process libraries can leverage
Web 2.0 services to interconnect systems from
72.1 In the Beginning:
Book Catalogs and Card Catalogs............1285
72.2 Development of the MARC Format
and Online Bibliographic Utilities ..........1286
72.2.1 Integrated Library Systems ............1287
72.2.2 Integrated Library Systems:
The Second Generation .................1289
72.2.3 The Nonroman World:
Unicode Comes to Libraries............1290
72.3 OpenURL Linking and the Rise
of Link Resolvers ..................................1290
72.3.1 Metasearching .............................1291
72.3.2 The Digital Revolution
and Digital Repositories ................1293
72.3.3 Electronic Resource Management ...1293
72.3.4 From OPAC to Next-Generation
Discovery to Delivery.....................1294
72.4 Future Challenges.................................1296
72.5 Further Reading ...................................1296
72.5.1 General Overview .........................1296
72.5.2 Specific Topics..............................1296
References ..................................................1297
different vendors and thereby ensure a gradual
transition toward a new automation platform.
72.1 In the Beginning: Book Catalogs and Card Catalogs
In many ways one can date the beginning of post-
industrial era library automation to the development
of the library catalog card and the associated card
catalog drawer [72.1, 2]. The nature of the origi-
nal library catalog card can be gleaned from this
patent description of the so-called continuous li-
brary catalog card that had evolved to take ad-
vantage of early computer-area technology by the
1970s [72.1]:
a continuous web for library catalogue cards hav-
ing a plurality of slit lines longitudinally spaced
7.5cmapart, each slit line extending 12.5cmtrans-
versely between edge carrier portions of the form
such that upon removal of the carrier portions
outwardly of the slit lines a plurality of standard
7.5cm×12.5cmcatalogue cards are provided.Lon-
gitudinally extending lines of uniquely shaped feed
holes or perforations are provided in the carrier
Part G 72

1286 Part G Infrastructure and Service Automation
Fig. 72.1 Example of a handwritten catalog card (courtesy
of University of Pennsylvania [72.3])
portions of the form which permit printing of the
cards by means of existing high speed printers of
United States manufacture despite the cards be-
ing dimensioned in the metric system and the feed
of the printers being dimensioned in the English
system.
Card catalogs and card catalog drawers are well de-
scribed in this patent that pertains to an update to the
basic card catalog drawer [72.2]:
an apparatus for keeping a stack of catalogue cards
in neat order to be used, for example, in a library. If
necessary, a librarian can replace a damaged cata-
logue card with a new one by just pressing a button
at the bottom of the drawer to enable a compression
spring to eject the metal rod passing through a stack
of catalogue cards. Consequently, the librarian can
freely rearrange the catalogue cards.
Though these devices continued to evolve, the orig-
inals, when standardized at the insistence of Melvil
Fig. 72.2 Example of OCLC-produced catalog (shelflist)
card (courtesy of OCLC [72.4])
Dewey in 1877, led eventually to the demise of large
book catalogs, which, despite their longevity, were at
best unwieldy and difficult to update [72.5]. As we will
see later, the goal here was one of increased produc-
tivity and cost reduction, not that different from the
mission espoused by late 20th century computer net-
works.
The development and adoption of the standard cat-
alog card presaged the popular Library of Congress
printed card set program that, together with a few
commercial imitators, was the unchallenged means of
universalizing a distributed cataloging model until the
mid 1970s. The printed card set program, in turn, was
succeeded by computerized card sets from the Ohio
College Library Center (OCLC), later renamed the
OCLC Online Computer Library Center, Inc.; the Re-
search Libraries Group (RLG); and other bibliographic
utilities. This was largely due to the advantage the utili-
ties had of delivering entire production runs of card sets
that could be both customized in format and at the same
time delivered with card packs already presorted and
alphabetized.
72.2 Development of the MARC Format and Online Bibliographic Utilities
The success of the bibliographic utilities coincided
with several other developments that together led to to-
day’s library automation industry. These developments
were the MARC communication format, the develop-
ment and evolution of university homegrown and then
vendor-based library systems, and finally the growth
of the networking capabilities that we now know as
the Internet and the World Wide Web. In fact, with-
out the development of the MARC format, library
automation would not have been possible. Taken as
a whole, these milestones bookend 130years of library
automation.
Two extraordinary individuals, Henriette Avram and
Frederick Kilgour, were almost single-handedly re-
sponsible for making possible library automation as
we know it today. During her tenure at the Library
of Congress, Avram oversaw the development of the
MARC format; it emerged as a pilot program in 1968,
Part G 72.2
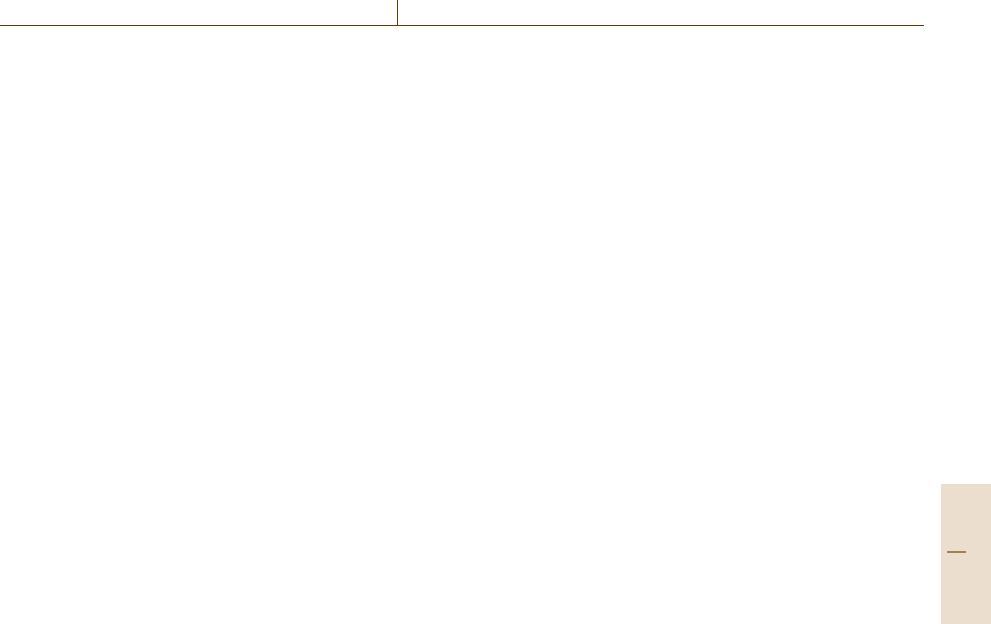
Library Automation 72.2 Development of the MARC Format and Online Bibliographic Utilities 1287
became a US national standard in 1971, and an inter-
national standard in 1973 [72.6]. The MARC standard
bore a direct connection to the development of OCLC
and the other bibliographic utilities that emerged dur-
ing the 1970s. RLG, the Washington Library Network
(WLN), and the University of Toronto Library Au-
tomation System (UTLAS) all sprang from the same
common ground.
Kilgour, who had served earlier at Harvard and Yale
Universities, moved to Ohio in 1967 to establish OCLC
as an online shared cataloging system [72.7]. OCLC
now has a dominant, worldwide presence, serving over
57000 libraries in 112 countries with a database that
comprises in excess of 168million records (including
articles) and 1.75billion holdings.
From the beginning the goals of library automation
were twofold: to reduce the extremely labor-intensive
nature of the profession while increasing the level of
standardization across the bibliographic landscape. It
was, of course, obvious that increasing standardization
should lead to reduced labor costs. It is less clear that
actions on the bibliographic “production room floor”
made that possible. For many years these goals were
a core part of the OCLC mission – the most successful
modern (and practically sole surviving) bibliographic
utility. Founded in 1967, OCLC is a [72.8]
nonprofit, membership, computer library service
and research organization dedicated to the public
purposes of furthering access to the world’s infor-
mation and reducing information costs.
In the early years of library automation, libraries em-
phasized cost reduction as a primary rationale for
automation.
In the early 1970s a number of so-called biblio-
graphic utilities arose to provide comprehensive and
cooperative access to a database comprised of descrip-
tive bibliographic (or cataloging) data – now commonly
known as metadata. One by one these bibliographic
utilities have vanished. In fact, in 2007 OCLC absorbed
RLG and migrated its bibliographic database and bib-
liographic holdings into OCLC’s own WorldCat, thus
leaving OCLC as the last representative of the utility
model that arose in the 1970s.
A hallmark of library automation systems is their
evolution from distinct, separate modules to large,
integrated systems. On the level of the actual biblio-
graphic data this evolution was characterized by the
migration and merger of disparate files that served dif-
ferent purposes (e.g., acquisitions, cataloging, authority
control, circulation, etc.) into a single bibliographic
master file. The concept of such a master file is pred-
icated on avoidance of duplicative data entry; that
is, data should enter the system once and then be
repurposed however needed. A truly continuous, es-
calating value chain of information, from publisher
data to library bibliographic data, still does not ex-
ist. Libraries, especially national libraries such as the
Library of Congress, routinely begin their metadata
creation routines either at the keyboard or with subop-
timal data (often from third-party subscription agents).
(The Library of Congress also makes use of an elec-
tronic cataloging-in-publication program.) The online
information exchange (ONIX) standard presages the ul-
timate extinction of the pure MARC communication
standard as extensible markup language (XML)-based
formats become dominant. Both the hardware/software
and the data strains become ever-more intertwined as
bibliographic automation becomes a subset of the larger
information universe, adopting standards that transcend
libraries.
72.2.1 Integrated Library Systems
The story of modern library automation began with
a few pioneering individuals and libraries in the mid
to late 1960s [72.9–13]. In addition to Avram and Kil-
gour, oneof the more notable was Herman Fussler at the
University of Chicago, whose efforts were supported
by the National Science Foundation. Following the ini-
tial experiments, the university began to develop a new
system, one of whose central concepts was in fact the
bibliographic master file [72.9].
The University of Chicago was not alone. Stan-
ford University (with bibliographic automation of large
library operations using time sharing (BALLOTS)),
the Washington Library Network, and perhaps most
importantly for large academic and public libraries,
Northwestern University (NOTIS) were all actively
investigating and developing systems. NOTIS was em-
blematic of systems developed through the mid 1980s.
NOTIS and others (e.g., Hebrew University’s auto-
mated library expandable program (Aleph 100) that
became the seed of Ex Libris and the Virginia Tech
library system (VTLS)) were originally developed in
university settings. In the 1980s NOTIS was commer-
cialized and later sold to Ameritech in the heyday
of AT&T’s breakup into a series of Baby Bells. The
NOTIS management team eventually moved on and
started Endeavor Information Systems, which was sold
to Elsevier Science and then in turn to the Ex Libris
Group in 2006.
Part G 72.2

1288 Part G Infrastructure and Service Automation
Other systems, aimed at both public and academic
libraries, made their appearance during the 1970s and
1980s. Computer Library Services Inc. (CLSI), Data
Research Associates (DRA), Dynix, GEAC, Innovative
Interfaces Inc. (III), and Sirsi were some of the bet-
ter known. Today only Ex Libris, III, and SirsiDynix
(merged in 2005) survive as major players in the inte-
grated library system arena.
The Harvard University Library epitomizes the vari-
ous stages of library automation on a grand scale. Under
the leadership of the fabled Richard DeGennaro, then
Associate University Librarian for Systems Develop-
ment, Harvard University’s Widener Library keyed and
published its manual shelflist in 60 volumes between
1965 and 1979 [72.14]. At the same time the university
was experimenting with both circulation and acquisi-
tions applications, the latter with the amusing moniker,
computer-assisted ordering system (CAOS), later re-
named the computer-aided processing system (CAPS).
In 1975 Harvard also started to make use of the rela-
tively young OCLC system. As with other institutions,
Harvard initially viewed OCLC as a means to more
efficiently generate catalog cards [72.15].
In 1983 Harvard University decided to obtain the
NOTIS source code from Northwestern University to
unify and coordinate collection development across the
100 libraries that constituted the vast and decentral-
ized Harvard University Library system. The Harvard
system, HOLLIS, served originally as an acquisitions
subsystem. Meantime, the archive tapes of OCLC trans-
actions were being published in microfiche format as
the distributable union catalog (DUC), for the first time
providing distributed access to a portion of the Union
Catalog – a subset of the records created in OCLC.
It was not until 1987 that the catalog master file was
loaded into HOLLIS. In 1988 the HOLLIS OPAC (on-
line public access catalog) debuted, eliminating the
need for the DUC [72.15].
It was, in fact, precisely the combination of the
MARC format, bibliographic utilities, and the emer-
gence of local (integrated) library systems that together
formed the basis for the library information architecture
of the mid to late 1980s. Exploiting the advantages pre-
sented by these building blocks, the decade from 1985
to 1995 witnessed rapid adoption and expansion in the
field of library automation, characterized by maturing
systems and increasing experience in networking. Most
academic and many public libraries had an integrated
library system (ILS) in place by 1990. While the early
ILS systems developed module by module, ILS systems
by this time were truly integrated. Data could finally
be repurposed and reused as it made its way through
the bibliographic lifecycle from the acquisitions mod-
ule to the cataloging module to the circulation module.
Some systems, it is true, required overnight batch jobs
to transfer data from acquisitions to cataloging, but true
integration was becoming more and more the norm.
By the early 1990s libraries were entering the age
of content. Telnet and Gopher clients made possible
the online presence of abstracting and indexing services
(A&I services). Preprint databases arose and libraries
began to mount these as adjuncts to the catalog proper.
DOS-based Telnet clients gave way to Windows-based
Telnet clients. Later in the 1990s, Windows-based
clientsinturngavewaytowebbrowsers.
All thistime, theunderlying bibliographic databases
were largely predicated on current acquisitions. The
key to an all encompassing bibliographic experience
lay in retrospective conversion (Recon) as proven by
Harvard University Library’s fundamental commitment
to Recon. Between 1992 and 1996 Harvard University
added millions of bibliographic records in a concerted
effort to eliminate the need for its thousands of cata-
log card drawers and provide its users with complete
online access to its rich collections. Oxford University
and others soon followed. While it would be incorrect to
say that Recon is a product of a bygone era, most major
libraries do indeed manage the overwhelming propor-
tion of their collection metadata online. This has proven
to be the precursor to the massive digitization projects
underwritten by Google, Yahoo, and Microsoft, all of
which depend to a large degree on the underlying bib-
liographic metadata, much of which was consolidated
during the Recon era.
In the early years of library automation, library
systems and library system vendors moved from time-
sharing, as was evident in the case of BALLOTS,to
large mainframe systems. (Time-sharing involves many
users making use of time slots on a sharedmachine.) Li-
brary system vendors normally allied themselves with
a given hardware provider and specialized in specific
operating system environments. The advent of the Inter-
net, andmore especiallythe World WideWeb, fueledby
the growth of systems based on Unix (and later Linux)
and relational database technology (most notably, Or-
acle) – all combined with the seemingly ubiquitous
personal computer – gave rise to the second genera-
tion in library automation, beginning around 1995. As
noted, the most visible manifestation of that to the li-
brary public was the use of browsers to access the
catalogs. This revolution was followed within 5years
by the rapid and inexorable rise of e-Content. The
Part G 72.2
Library Automation 72.2 Development of the MARC Format and Online Bibliographic Utilities 1289
most successful library automation vendors, it is now
clear, are those that possessed a clear and compelling
vision for combining library automation with deliv-
ery of content. The most successful of those vendors
also espouse an e-Content philosophy that is publisher
neutral.
72.2.2 Integrated Library Systems:
The Second Generation
Libraries, often at the direction of their governing bod-
ies, made a generational decision during this period
to migrate from mainframe to client–server environ-
ments. Endeavor Information Systems, founded with
the goal of creating technology systems for aca-
demic, special, and research libraries, was first out of
the starting blocks and had its most successful pe-
riod for about a decade following its incorporation in
1994 [72.16]. It was no accident, given its roots in
NOTIS and its familiarity with NOTIS software and
customers, that Endeavor quickly captured the over-
whelming share of the NOTIS customer base that was
looking to move to a new system. This was partic-
ularly true in the period immediately preceding the
pivotal year 2000, when Y2K loomed large. In plan-
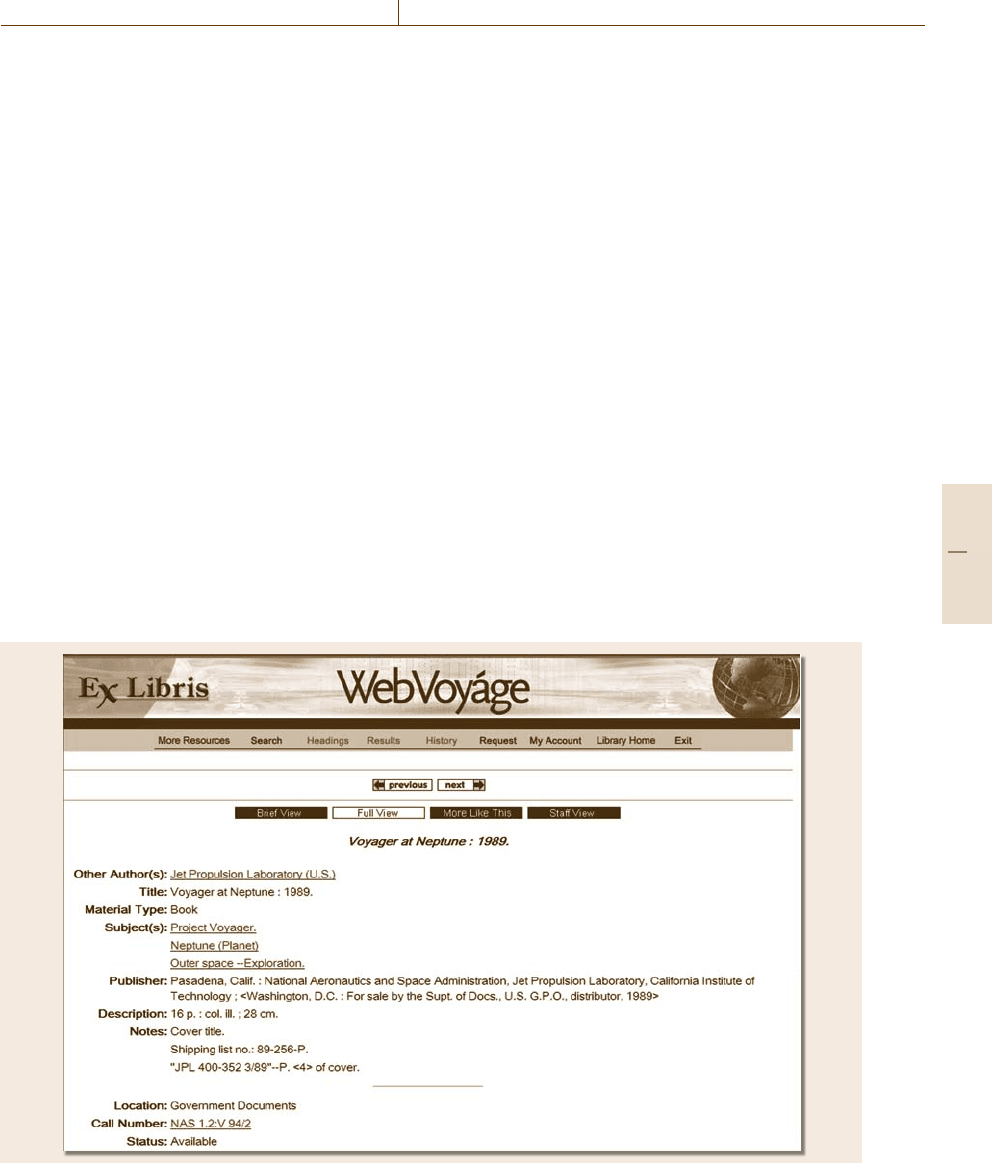
Fig. 72.3 Endeavor (now Ex Libris) WebVoyáge display
ning for the shift to the year 2000 library computer
systems faced the same challenge all other legacy com-
puter faced, namely, reworkingcomputer codeto handle
calendar dates once the new millennium had begun.
So many libraries, both large and small, had to re-
place computer systems in the very late 1990s that
1998 and 1999 were banner years in the library com-
puter marketplace, followed by a short-term downturn
in 2000.
Ex Libris Ltd., a relative latecomer to the North
American library market, was founded in Israel in 1983,
originally as ALEPH Yissum, and commissioned to de-
velop a state-of-the-art library automation system for
the Hebrew University in Jerusalem. Incorporated in
1986 as Ex Libris, a sales and marketing company
formed to market Aleph, Ex Libris broke into the Eu-
ropean market in 1988 with a sale to CSIC, a Spanish
network of 80 public research organization libraries
affiliated with the Spanish Ministry of Science and
Technology. This sale demonstrated an early hallmark
of Aleph, namely deep interest in the consortial envi-
ronment.
At roughly the same time as Endeavor was releasing
its web-based client–server system, Voyager, Ex Lib-
ris released the fourth version of the Aleph system,
Part G 72.2

1290 Part G Infrastructure and Service Automation
Fig. 72.4 Catalog record from University of Iowa InfoHawk catalog, with parallel roman-alphabet and Chinese fields
(courtesy of University of Iowa)
Aleph 500. Based on what was to become the industry
standard architecture, Alephfeatured a multi-tier client–
server architecture, support for a relational database,
and – a tribute to its origins and world outlook – sup-
port for the unicode character set. Starting in 1996, with
Aleph 500 as its new ILS stock-in-trade, Ex Libris cre-
ated a US subsidiary and decided to make a major push
into the North American market. At the same time –
and crucially for its success in the emerging e-Content
market – Ex Libris made the strategic commitment to
invest heavily in research and development with the
stated goal of creating a unified family of library prod-
ucts that would meet the requirements of the evolving
digital library world.
72.2.3 The Nonroman World:
Unicode Comes to Libraries
If there is a single accepted analysis of the state of li-
braries and library automation in the 21st century, it is
the fact the library world is but one part of the much
larger information universe and that library standards,
e.g., the MARC format and the American standard code
for information interchange (ASCII) character set, need
to be considered in light of the larger universe of infor-
mation standards, such as XML (ONIX) and unicode.
Those libraries and library vendors that have the most
robust understanding of this fundamental shift have
been most adept at long-term survival.
72.3 OpenURL Linking and the Rise of Link Resolvers
The shift from ASCII to unicode and from MARC to
XML heralded an entire salvo of digital products that
introduced a new concept of library automation – the
ILS was no longer the be all and end all of library au-
tomation – and was marked by Ex Libris’s release of
SFX. SFX was developed in conjunction with Herbert
Van de Sompel (presently a research scientist at the
Los Alamos National Laboratory) and the Universiteit
Ghent in response to what is known as the appropriate
copy problem [72.17]:
Part G 72.3
Library Automation 72.3 OpenURL Linking and the Rise of Link Resolvers 1291
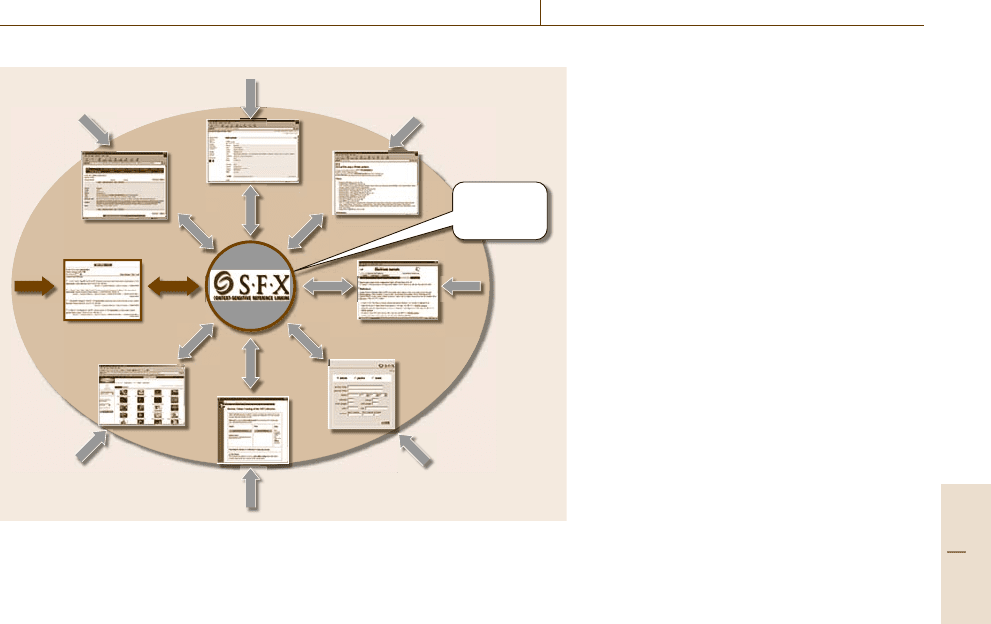
Link
server
Full text
e-Print
ILL/
Doc Del
Reference
manager
Digital
collections
A&I
Portal
OPAC
Fig. 72.5 SFX and OpenURL linking
(after [72.4])
There has been an explosive growth in the number
of scholarly journals available in electronic form
over the internet. As e-Journal systems move past
the pains of initial implementation, designers have
begun to explore the power of the new environment
and to add functionality impossible in the world
of paper-based journals. Probably the single most
important such development has been reference
linking, the ability to link automatically from the
references in one paper to the referred-to articles.
Led by Oren Beit-Arie (presently Ex Libris’s chief
strategy officer), SFX (which stands for special ef-
fects) was not only a commercial success but also
became generically associated with the standard known
as OpenURL linking. In much the same way as Xerox
is synonymous with photocopying, so SFX has become
synonymous with context-sensitive linking. Released in
2000, SFX now has an installed base of over 1500 li-
braries and research centers worldwide
Librarians, especially systems librarians, are well
known as staunch proponents of standards. Thus it was
an extremely astute move when Ex Libris took the
initiative to have the National Information Standards
Organization (NISO) adopt the OpenURL as a NISO
standard.
The OpenURL framework for context-sensitive ser-
vices was actually approved on a fast-track basis as
ANSI/NISO Z39.88 in 2005 [72.18]:
The OpenURL framework standard defines an
architecture for creating OpenURL framework ap-
plications. An OpenURL framework application is
a networked service environment, in which pack-
ages of information are transported over a network.
These packages have a description of a referenced
resource at their core, and they are transported with
the intent of obtaining context-sensitive services
pertaining to the referenced resource. To enable
the recipients of these packages to deliver such
context-sensitive services, each package describes
the referenced resource itself, the network context
in which the resource is referenced, and the context
in which the service request takes place.
72.3.1 Metasearching
Ex Libris quickly followed its success with SFX by ex-
panding into the area of metasearching. Also known
as federated searching, metasearching was another re-
sponse to the proliferation of online journals and online
content. MetaLib (and competing products) were the
initial bibliographic answer to the problem posed by
commercial search engines such as Yahoo or Google,
namely that much content had come quickly to live
outside the realm of the library catalog. Metasearch
enables users – power and nonpower users, whether
the general public or undergraduates, graduate students,
post-doctoral students, and faculty – to retrieve the
Part G 72.3
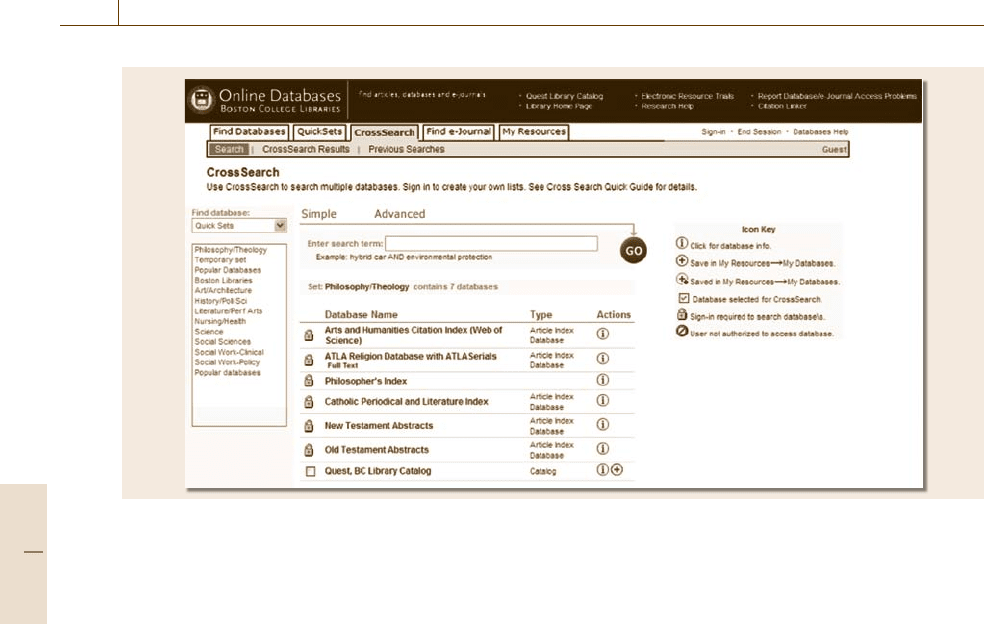
1292 Part G Infrastructure and Service Automation
Fig. 72.6 Boston College MetaQuest, with quick sets
most comprehensive set of results in a single search,
including traditional bibliographic citations, abstract-
ing and indexing service information, and the actual
fulltext whenever it is available. Before long, numer-
ous offerings of both OpenURL link resolvers and
metasearch applications were available in the biblio-
graphic arena.
By 2005 many institutions had made their primary
bibliographic search gatewaynot the library catalog, but
their metasearch application. Boston College is a good
example. Its library catalog, Quest, is but one of the
numerous targets searchable through its metasearch ap-
plication, MetaQuest.
By now libraries and their users had bought whole-
heartedly into the combination of metasearching and
linking – it is the combination of these two approaches
for dealing with the e-Content universe that makes
them together vastly more powerful than either alone.
Troubles loomed, though, in the absence of standards
for metasearching. NISO once again stepped forward
and created the NISO Metasearch Initiative. NISO de-
scribed the challenge as [72.19]:
Metasearch, parallel search, federated search,
broadcast search, cross-database search, search
portal are a familiar part of the information com-
munity’s vocabulary. They speak to the need for
search and retrieval to span multiple databases,
sources, platforms, protocols, and vendors at one
time. Metasearch services rely on a variety of ap-
proaches to search and retrieval including open
standards (such as NISO’s Z39.50), proprietary
API’s, and screen scraping. However, the absence
of widely supported standards, best practices, and
tools makes the metasearch environment less effi-
cient for the system provider, the content provider,
and ultimately the end-user.
Standards are invaluable, but in the library world
standards – aimed at providing consistency in search-
ing – are all the more important. As knowledge seekers
move from one environment to the next with the change
of a uniform resource locator (URL), they also expect
consistent behavior across these various informationen-
vironments. It is particularly encouraging, therefore, to
see how the public responds. An article in the Octo-
ber 7, 2005 Harvard Crimson shows the opinion of
a student at one of the world’s most prestigious univer-
sities [72.20]:
Of the many things to change at Harvard over
the summer...there is one new development that
students may not have noticed but that come term-
paper time will make a world of difference. That
change is the switch from Harvard University Li-
brary’s (HUL) e-Resources website to the new
e-Research @ Harvard Libraries website. HUL has
done a tremendous job with the neweasy-to-use site,
Part G 72.3
Library Automation 72.3 OpenURL Linking and the Rise of Link Resolvers 1293
and we applaud them for dreamingup such a helpful
resource.
The new e-Research page puts a high-tech user in-
terface on top of Harvard’s vast array of online
subscriptions, making resources more readily ac-
cessible – whether users know the exact journal
they are looking for or are just poking around for
sources. But the best thing about the new e-Research
page is the plethora of features it provides that
take full advantage of computers to make research
easier ... within seconds you can find what you
are looking for, either in fulltext online or a Find
it @ Harvard button that tells you exactly where in
Harvard’s huge library system to look.
Within two short paragraphs two of the major tools
of 21st century librarianship and e-Scholarship emerge:
metasearching (e-Research) and OpenURL linking
(Find It @ Harvard). The library catalog (HOLLIS) is
mentioned, too, but it is but one amid a vast array of
electronic resources.Looming over all this is thespecter
of Google, whose seemingly endless series of innova-
tions and content-related initiatives is in turn pushing
the frontiers of automation within the library systems
world itself.
72.3.2 The Digital Revolution
and Digital Repositories
Three other areas of institutional bibliographic automa-
tion were under discussion and development between
2002 and 2007: digital repositories, electronic resource
management systems, and new models of resource dis-
covery and delivery.
As with early developments in library automation,
one of the first efforts to manage digital objects, espe-
cially textual objects, began in auniversity environment.
In 2000 the Massachusetts Institute of Technology
Libraries and Hewlett-Packard embarked on a joint re-
search project that we now know as DSpace – an early
digital asset management (DAM) system.
DSpace introduced the concept of an institutional
repository (IR) [72.21],
a robust, software platform to digitally store...
collections and valuable research data, which had
previously existed only in hard copies...anarchiv-
ing system that stores digitalrepresentations of ana-
log artifacts, text, photos, audio and films...capable
of permanently storing data in a non-proprietary
format, so researchers can access its contents for
decades to come.
DSpace is an open-source software toolkit. Au-
tomation vendors realized this was a fertile field for
institutions not inclined to go the toolkit approach. Var-
ious products have emerged; notable among them are
CONTENTdm, developed at the University of Wash-
ington and now owned by OCLC; and Ex Libris’s
DigiTool. An open-source newcomer to the field is
Fedora, which will likely appeal to the same group of li-
braries interested in DSpace [72.22]. All these products
are designed for deposit, search, and retrieval. While
they have maintenance aspects about them, they are not
true preservation systems.
Libraries and archives, as recognized custodians
of our intellectual and cultural heritage, have long
understood the value of preservation and ensuring lon-
gitudinal access to the materials for which they have
accepted custodianship. As more and more materials
are digitized, particularly locally important cultural her-
itage materials, or are born digital, these institutions
have begun to accept responsibility for preserving these
materials. Recently (2007) the National Library of New
Zealand leapt to the forefront of digital preservation
by developing a National Digital Heritage Archive
(NDHA) program to ensure the ongoing collection,
preservation, and accessibility of its digital heritage col-
lections. This multiyear program, begun in conjunction
with Endeavor Information Systems and continued by
Ex Libris, aims to preserve digital objects for nothing
less than the life of the custodial bodies [72.23].
72.3.3 Electronic Resource Management
On the serial side of the bibliographic house, the
e-Journal evolution of the 1990s turned rapidly into the
e-Journal avalanche of the 21st century. Libraries and
information centers that subscribed to thousands or tens
of thousands of print journals found themselves facing
a very different journal publication model when pre-
sented with e-Journals. Not only have libraries had to
contend with entirely new models – print only, print
with free e-Journal, e-Journal bundles or aggregations,
often in multiple flavors from competing publishers
and aggregators – but also these e-Journals came with
profoundly different legal restrictions on use of the
e-Content. Libraries found themselves swimming up-
stream against a rushing tide of e-Content. A number
of institutions (among them Johns Hopkins University,
Massachusetts Institute of Technology, and the Univer-
Part G 72.3

1294 Part G Infrastructure and Service Automation
sity Libraries of Notre Dame) developed homegrown
systems to contend with the morass; most others relied
on spreadsheets and quantities of paper.
Into this fray stepped the Digital Library Founda-
tion (DLF), which convened a small group of e-Journal
and e-Content specialists to identify the data elements
required to build an electronic resources management
(ERM) system. This study, developed in conjunction
with a group of vendors and issued in 2004 as Elec-
tronic Resource Management: Report of the DLF ERM
Initiative (DLF ERMI), was one of the few times since
the development of the MARC standard that a standard
predated full-blown system development [72.24].
Systems developers adopted the DLF ERMI initia-
tive to greater or lesser degrees as dictated by their
business interests and commitment to standards. Un-
like the OpenURL link resolvers and metasearch tools,
electronic resource management tools addressed an au-
dience that was primarily staff, harking back to the
original goal of library automation: to make librarians
more productive.
Innovative Interfaces Inc. was the first vendor to re-
lease an ERM product. Serials Solutions, one of the
newer players, whose origins lay in providing catalog
copy for e-Journals and A-to-Z lists for e-Journals, has
the 360Resource Manager offering.
72.3.4 From OPAC to Next-Generation
Discovery to Delivery
A deeply held tenet of librarians is that they have
a responsibility to provide suitably vetted, authorita-
tive information to their users. In the years since the
rise of Google as an Internet phenomenon, librarians
have shown enormous angst in the reliance, particularly
among the generation that has come of age since the
dawn of the Internet, on whatever they find in the first
page of hitsfrom any ofthe mostpopular Internet search
engines. Critical analysis and the intellectual value of
the resulting hits are less important to the average user
than the immediacy of an online hit, especially if it oc-
curs onthe firstresults page. Libraries continue to spend
in the aggregate hundreds of millions of dollars on con-
tent, both traditional and electronic, yet have failed to
retain even their own tuition-paying clientele.
OCLC, to its credit, confronted the issue head on
with a report it issued in 2005 [72.25]. In the report
OCLC demonstrates quite conclusively that ease of
searching and speedy results, plus immediate access to
content, are the most highly prized attributes users de-
sire in search engines. Unfortunately, the report shows
that libraries and library systems rank very low on this
scale. On the other hand, when it comes to a question of
authoritative, reliable resources, the report shows that
libraries are clear winners. The question has serious im-
plications for the future of library services. How should
libraries and library system vendors confront this co-
nundrum?
The debate was framed in part by a series of lec-
tures thatDale Flecker, associate director of the Harvard
University Library for Planning and Systems, gave in
2005 on: OPACS and our changing environment: ob-
servations, hopes, and fears. The challenge he framed
was the evolution of the local research environment that
comprises multiple local collections and catalogs. Har-
vardUniversity, for example, had (and stillhas) separate
catalogs for visual materials, geographic information
systems, archival collections, social science datasets,
a library OPAC, and numerous small databases. Li-
censed external services have proliferated: in 2005
Harvard had more than 175 search platforms on the
Harvard UniversityLibrary portal – all in addition to In-
ternet engines, online bookstores, and so forth. Flecker
expressed hope that OPACs would evolve to enable
greater integration with the larger information envi-
ronment. To achieve this, OPACs (or their eventual
replacements) would have to cope with both the Inter-
net and the explosion of digital information that was
already generating tremendous research and innovation
in search technology. Speed, relevance (ranking), and
the ability to deal with very large results sets would be
the key to success – or failure [72.26].
Once again, the usual series of library automation
vendors stepped up. In truth, they were already work-
ing on their products but this time they were joined by
yet another set of players in the library world. North
Carolina State University adopted Endeca [72.27], best
known as a data industry platform, to replace its library
OPAC: “Endeca’s unique information access platform
helps people find, analyze, and understand information
in ways never before possible” [72.27]. As the NCSU
authors Antelman et al. noted in the abstract to their
2006 paper [72.28],
Library catalogs have represented stagnant tech-
nology for close to twenty years. Moving toward
a next-generation catalog, North Carolina State
University (NCSU) Libraries purchased Endeca’s
Information Access Platform to give its users
relevance-ranked keyword search results and to
leverage the rich metadata trapped in the MARC
record to enhance collection browsing. This pa-
Part G 72.3