Li S.Z., Jain A.K. (eds.) Encyclopedia of Biometrics
Подождите немного. Документ загружается.


Eye Centers
In face recognition, eye center is defined as the geomet-
ric centroid of the close region formed by the upper and
lower eyelids when the eye is opened. In practice, the
midpoint of the left and right eye corners is often used
instead. Because of the changing of gaze, pupil or origin
of the iris circle is not necessarily the eye center.
▶ Face Misalignment Problem
Eye Tracking
The process of measuring either the motion of the eye
relative to the head or the point of gaze, i.e. where
someone is looking. Applications include medical and
cognitive studies, computer interfaces, and marketing
research.
▶ Segmentation of Off-Axis Iris Images
290
E
Eye Centers

F
Face Acquisition
▶ Face Device
Face Aging
Face aging is to predict the future appearance of
human face by learning the aging patterns, child
growth, and adult aging are two type of aging.
▶ And-Or Graph Model for Faces
Face Alignment
LEON GU,TAKEO KANADE
Carnegie Mellon University, Pittsburgh, PA, USA
Synonyms
Face registration; Face matching
Definition
Face alignment is a computer vision technology for
identifying the geometric structure of human faces in
digital images. Given the location and size of a face,
it automatically determines the shape of the face com-
ponents such as eyes and nose. A face alignment pro-
gram typically operates by iteratively adjusting a
▶ deformable models , which encodes the prior knowl-
edge of face shape or appearance, to take into account
the low-level image evidences and find the face that is
present in the image.
Introduction
The ability of understand ing and interpreting facial
structures is important for many image analysis tasks.
Suppose that, if we want to identify a person from a
surveillance camera, a natural approach would be run-
ning the face image of the person through a database
of known faces, examining the differences and identi-
fying the best match. However, simply subtracting one
image from another would not yield the desirable
differences (as shown in Fig. 1), unless two faces are
properly aligned. The goal of face alignment is to
establish correspondence among different faces, so
that the subsequent image analysis tasks can be per-
formed on a common basis.
The main challenge in face alignment arises from
pervasive ambiguities in low-level imag e features. Con-
sider the example s shown in Fig. 2. While the main
face structures are present in the
▶ feature maps, the
contours of face components are frequently disrupted
by gaps or corrupted by spurious fragments. Strong
gradient responses could be due to reflectance, occlu-
sion, fine facial texture, or background clutter. In con-
trast, the boundaries of face components such as nose
and eyebrow are often obscure and incomplete. Look-
ing for face components separately is difficult and
often y ields noisy results.
Rather than searching individual face components
and expecting the face structure to emerge from the
results, a better strategy is imposing the structure explic-
itly from the beginning. A majority of work in the field
are developed based on this strategy. Deformable tem-
plate [1], for example, is an elastic model which resem-
bles face structure by assemblies of flexible curves. A set
#
2009 Springer Science+Business Media, LLC

of model parameters control shape details such as
the locations of various facial subparts and the angles
of hinges which join them. The model is imposed
upon and aligned to an image by varying the para-
meters. This strategy is powerful for resolving low-level
image ambiguities. Inspired by this work, many varia-
tions of deformable face models emerged, including
[2–9]. The common scheme in these work is first to
construct a generic face model, then modify it to
match the facial features found in a particular image.
In this procedure, encoding prior knowledge of human
faces, collecting image evidences of facial features,
and fusing the observations with priors are the three
key problems. Our treatment will follow the method
proposed by Gu and Takeo [8, 9], which addresses the
above problems in a coherent hierarchical Bayes
framework.
Constructing Face Priors
This article concerns with the prior knowledge of
a particular kind, namely shape priors. Suppose that,
a face consists of a set of landmark points, which are
typically placed along the boundaries of face compo-
nents, i.e., S ¼ (x
1
, y
1
, ..., x
n
, y
n
). It can be viewed as a
random vector, and its distribution, commonly called
shape prio r, describes the plausible spatial configu-
rations of the landmark set. A principled way to con-
struct the prior is by learning the distribution from
training samples.
Face appears in different scales and orientations.
First we need to transform all training face images into
a common coordinate frame. One popular approach is
general procrustes analysis [10]. It consists of two
recursive steps: computing the mean shape, and
Face Alignment. Figure 2 The major difficulty in face alignment is low-level image ambiguities. Face topologies
could be significantly corrupted in the gradient feature maps (second row), due to various factors such as reflectance,
occlusion, fine facial texture, and background clutter.
Face Alignment. Figure 1 To compare two face images, by directly adding them or subtracting one from another
does not produce the desired result. Face alignment enables to establish correspondences between different images,
so that the subsequent tasks can be performed on a common basis.
292
F
Face Alignment

aligning each training shape with the mean by a rigid
transformation. These two steps are repeated until the
differences between the mean and the training shapes
are minimized.
Next, we construct shape prior from the aligned
training samples. The spatial arrangement of facial
landmarks, although deformable, has to satisfy certain
constrains. For example, it is often reasonable to as-
sume that face shape is normally distributed, therefore,
to learn the distribution we simply compute the mean
and the covariance of the training shapes. More specif-
ically, since the intrinsic variability of face structure
is independent to its representation, e.g., the number
of landmarks, we can parameterize face shape in a low-
dimensional subspace [6, 8], such as
S ¼ Fb þ m þ E: ð1Þ
The columns of F denote the major ‘‘modes’’ of shape
deformations, and the elements of b controls the mag-
nitude of deformation on the corresponding mode.
This model has a nice generative interpretation: the
shape vector S is generated by first adding a sequence
of deformations {F
i
b
i
} into the mean shape m, then
permuting the resultant shape by an Gaussian noise
E Nð0; s
2
Þ. From a geometric perspective, the
matrix F span a low-dimensional subspace which is
centered at m, the deformation coefficient b is the
projection of S in the subspace, and E denotes the
deviation of S from the subspace. If assuming the ele-
ments of b to be independently normal, i.e.,
b Nð0; SÞ and S is diagonal, the distribution
over the shape S is a constrained Gaussian,
S Nðm; FSF
t
þ s
2
IÞ. The model parameters m, F,
S, and s can be learned from training data. This model
is also known as probabilistic principal component
analysis [11] in the field of machine learning.
Detecting Facial Features
Stronggradient response is not the onlyway to characterize
facial features. Some feature points may corr espond to
a weaker secondary edge in local context instead of the
strongest; other points such as eye corners may have rich
image structure that is more informative than gradient
magnitude. Facial feature modeling can be made
more effective by constructing detectors specific to each
individual feature. One simple detector [2], for example,
is a normal distribution built on the local gradient
structures of each point. The distribution is learned
Face Alignment. Figure 3 Face alignment results from Gu and Kanade [9].
Face Alignment
F
293
F

from training face images, and applied to evaluate the
target image. Concatenating the best candidate position
(u
i
,v
i
) of each feature point, we obtain an ‘‘observation’’
Q ¼ (u
1
,v
1
,...,u
n
,v
n
) of the face shape that is likely to
be present in the image. The observation is related with
the aligned shape S by a rigid transformation
Q ¼TðS; yÞþ; ð2Þ
where y ¼{t, s, r} denotes the transformation parameters
(translation, scale, and rotation), and is an additi ve
observation noise. The conditional p(QjS) remains to
be normal if the transformation T is linear, e.g., rigid or
affine. More sophisticated detectors have been developed
to produce better observations, however, after decades
of research people have learned that individual featur e
detectors are effective only up to a point and cannot be
expected to retrieve the entire face structure.
Fusing Prior with Image Observations
Combining the deformation model (1) with the trans-
formation model (2) a hierarchical Bayes model is
established that simulates how a random observation
Q is generated from the deformation magnitude b and
the transformation parameters y. In this framework,
the face alignment task is to modify shape priors to
take into account the image evidences, arriving at the
target face shape in images. EM algorithm is typically
used for inferring the posterior b and y, and analy tic
solutions exist for both E and M steps when the trans-
formation is linear. This framework has been extended
to model three-dimensional transformations for align-
ing multi-view faces [8], and nonlinear shape defor-
mations for dealing with face images with exaggerated
facial expressions [9]. Figure 3 shows a few alignme nt
results from [9].
Summary
Significantprogresseshavebeenmadeinfacealignment
in recent years. The hierarchical Bayes formulation intro-
duced in this article provides a systematic way to resolve
low-level image ambiguities and exploit prior knowledge.
Face alignment has a wide range of applications includ-
ing face recognition, expression analysis, facial anima-
tion, lip reading, and human–computer interaction.
Related Entries
▶ Deformable Models
▶ Face Warping
▶ Feature Map
References
1. Yuille, A.L., Hallinan, P.W., Cohen, D.S.: Feature extraction from
faces using deformable templates. Int. J. Comput. Vision 8(2),
99–111 (1992). DOI http://dx.doi.org/10.1007/ BF001271 69. URL
http://www.stat.ucla.edu/~yuille/pubs/optimize_p apers/ DT_
IJCV1992.pdf
2. Cootes, T.F., Taylor, C., Cooper, D., Graham, J.: Active shape
models – their training and their applications. Comput. Vision
Image Understanding (1995)
3. Wiskott, L., Fellous, J.M., Kruger, N., von der Malsburg, C.:
Face recognition by elastic bunch graph matching. IEEE
Trans. Pattern Anal. Mach. Intell. 19(7), 775–779 (1997).
DOI http://dx.doi.org/10.1109/34.598235. URL http://www.
face-rec.org/algo rithms/EBGM/WisFelKrue99-FaceRecogni-
tion-JainBook.pdf
4. Blanz, V., Vetter, T.: A morphable model for the synthesis of
3d-faces. In: ACM SIGGRAPH (1999)
5. Cootes, T., Edwards, G., Taylor, C.: Active appearance models
23(6), 681–685 (2001)
6. Zhou, Y., Gu, L., Zhang, H.: Bayesian tangent shape model: Esti-
mating shape and pose parameters via Bayesian inference, pp. I:
109–116 (2003). URL http://www.cs.cmu.edu/gu/publication/
alignment_cvpr03.pdf
7. Zhang, Z., Liu, Z., Adler, D., Cohen, M.F., Hanson, E., Shan, Y.:
Robust and rapid generation of animated faces from video
images – a model-based modeling approach. Int. J. Comput.
Vision (2004)
8. Gu, L., Kanande, T.: 3d alignment of face in a single image. In:
CVPR (2006)
9. Gu, L., Kanade, T.: A generative shape regularization model for
robust face alignment. In: The Tenth European Conference on
Computer Vision (2008)
10. Goodall, C.: Procrustes methods in the statistical analysis of
shape. J. Royal Statistical Society. Series B (Methodological) 53,
285–339 (1991).
11. Jipping, M., Bishop, C: Probabilistic principal component anal-
ysis. J. Royal Statistical Society (1999).
Face Alignment Error
▶ Face Misalignment Problem
294
F
Face Alignment Error
Face Biometric
▶ Face Recognition, Over view
Face Camera
▶ Face Device
Face Databases and Evaluation
DMITRY O. GORODNICHY
Laboratory and Scientific Services Directorate, Canada
Border Services Agency, Ottawa, ON, Canada
Synonyms
Face recognition performance evaluation
Definition
Face Databases are imagery data that are used for testing
▶ face processing algorithms. In the contents of bio-
metrics, face databases are collected and used to evaluate
the performance of face recognition biometric systems.
Face recognition evaluation is the procedure that is
used to access the recognition quality of a face recog-
nition system. It involves testing the system on a set of
face databases and/or in a specific setup for the pur-
pose of obtaining measurable statistics that can be used
to compare systems to one another.
Introduction: Factors Affecting Face
Recognition Performance
While for humans recognizing a face in a photograph or
in video is natural and easy, computerized face recogni-
tion is very challenging. In fact, automated recognition
of faces is known to be more difficult than recogni-
tion of other imag ery data such as iris, vein, or finger-
print images due to the fact that the human face is a
non-rigid 3D object which can be observed at different
angles and which may also be partially occluded. Spe-
cifically, face recognition systems have to be evaluated
with respect to the following factors [1]:
1. Face image resolution – face images can be cap-
tured at different resolutions: face images scanned
from documents may have very high resolution,
while face captured with a video camera will mostly
be of very low resolution,
2. Facial image quality – face images can be blurred
due to motion, out of focus, and of low con-
trast due to insufficient camera exposure or aper-
ture, especially when captured in uncontrolled
environment,
3. Head orientation – unless a person is forced to face
the camera and look straight into it, will unlikely be
seen under the same orientation on the captured
image,
4. Facial expression – unless a person is quiet and
motionless, the human face constantly exhibits a
variety of facial expressions
5. Lighting conditions – depending on the location of
the source of light with respect to the camera and
the captured face, facial image will seen with differ-
ent illumination pattern overlaid on top of the
image of the face,
6. Occlusion – image of the face may be occluded by
hair, eye-glasses and clothes such scarf or
handkerchief,
7. Aging and facial surgery – compared to fingerprint
or iris, person faces chan ges much more rapidly
with time, it can also be changed as a result of
make-up or surgery.
There are over thirty publicly available face databases.
In addition, there are Face Recognition Vendor Test
(FRVT) databases that are used for independent
evaluation of Face Recognition Biometric Systems
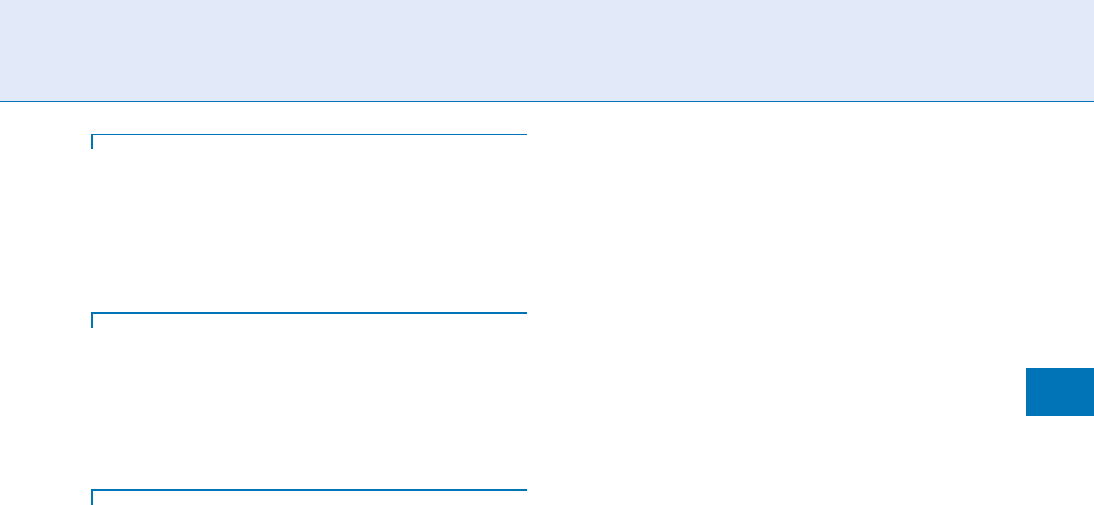
(FRBS). Table 1 summarizes the features of the most
frequently used still image facial databases, as pertain-
ing to the performance factors listed above. More
details about each database can be found at [2–4]
and below are presented some of them. For the list of
some video-based facial databases, see [5].
Public Databases
One of the first and most used databases is AT&T
(formerly ‘‘Olivetti ORL’’) database [6] that contains
Face Databases and Evaluation
F
295
F

ten different images of each of 40 distinct subjects. For
some subjects, the images were taken at different times,
varying the lighting, facial expressions (open/closed eyes,
smiling/not smiling) and facial details (glasses/no glasse s).
All the images were taken against a dark homogeneous
backgroundwiththesubjectsinanupright,frontalposi-
tion (with tolerance for some side movement).
The other most frequently used dataset is developed
for FERET program [7]. The images were collected in a
semi-controlled environment. To maintain a degree of
consistency throughout the database, the same physi-
cal setup was used in each photography session. A
duplicate set is a second set of images of a person
already in the database and was usually taken on a
different day. For some individuals, over 2 years had
elapsed between their first and last sittings, with some
subjects being photographed multiple times.
The Yale Face Database [8] contains images of
different facial expression and configuration: center-
light, w/glasses, happy, left-light, w/no glasses, normal,
right-light, sad, sleepy, surprised, and wink. The Yale
Face Database B provides single light source images of
10 subjects each seen under 576 viewing conditions
(9 poses x 64 illumination conditions). For every sub-
ject in a particular pose, an image with ambient (back-
ground) illumination was also captured.
The BANCA multi-modal database was collected as
part of the European BANCA project, which aimed
at developing and implementing a secure system with
enhanced identification, authentication, and access con-
trol schemes for applications over the Internet [9]. The
database was designed to test multimodal identity ver-
ification with various acquisition devices (high and low
quality cameras and microphones) and under several
scenarios (controlled, degraded, and adverse).
To investigate the time dependence in face recogni-
tion, a large database is collected at the University of
Notre Dame [10]. In addition to the studio recordings,
two images with unstructured lighting are obtained.
University of Texas presents a collection of a large
database of static digital images and video clips of faces
[11]. Data were collected in four different categories:
still facial mug shots, dynamic facial mug shots, dy-
namic facial speech and dynamic facial expression. For
the still facial mug shots, nine views of the subject,
ranging from left to right profile in equal-degree
steps were recorded. The sequence length is cropped
to be 10 s.
The AR Face Database [12] is one of the largest
datasets showing faces with different facial expressions,
illumination conditions, and occlusions (sun gl asses
and scarf).
XM2VTS Multimodal Face Database provides five
shots for each person [13]. These shots were taken at one
week intervals or when drastic face changes occurred
in the meantime. During each shot, people have been
asked to count from ‘‘0’’ to ‘‘9’’ in their native language
(most of the people are French speaking), rotate the head
from 0 to90 degrees, again to 0, then to +90 and back
to 0 degrees. Also, they have been asked to rotate the
head once again without glasses if they wear any.
CMU PIE Database is one of the largest datasets
contains images of 68 people, each under 13 different
poses, 43 different illumination conditions, and with
four different expressions [14].
The Korean Face Database (KFDB) contains facial
imagery of a large number of Korean subjects collected
under carefully controlled conditions [15] . Similar to
the CMU PIE database, this database has images with
varying pose, illumination, and facial expressions were
recorded. In total, 52 images were obtained per subject.
The database also contains extensive ground truth
information. The location of 26 feature po ints (if visi-
ble) is available for each face image.
CAS-PEAL Face Database is another large-scale
Chinese face database with different sources of varia-
tions, especially Pose, Expression, Accessories, and
Lighting [16].
FRVT Databases
Face Recognition Vendor Tests (FRVT) provide inde-
pendent government evaluations of commercially
available and prototype face recognition technologies
[4]. These evaluations are designed to provide
U.S. Government and law enforcement agencies with
information to assist them in determining where and
how facial recognition technology can best be
deployed. In addition, FRVT results serve to identify
future research directions for the face recognition com-
munity. FRVT 2006 follows five previous face recogni-
tion technology evaluations – three FERET evaluations
(1994, 1995 and 1996) and FRVT 2000 and 2002.
FRVT provides two new datasets that can be used
for the purpose: high computational intensity test
(HCInt) data set and Medium Computational Intensity
test (MCInt) data set. HCInt has 121,589 operational
well-posed (i.e. frontal to within 10 degrees) images of
37,437 people, with at least three images of each person.
296
F
Face Databases and Evaluation

The images are provided from the U.S. Department of
State.s Mexican non-immigrant visa archive. The
images are of good quality and are gathered in a consis-
tent manner, collected at U.S. consular offices using
standard issue digital imaging apparatus whose specifi-
cation remained fixed over the collection period.
The MCInt data set is composed of a heterogeneous
set of still images and video sequences of subjects in a
variety of poses, activities and illumination conditions.
The data are collected from several sources, captured
indoors and outdoors, and include lose-range video
clips and static images (with over hundred individuals),
high quality still images, Exploration Video Sequences
(where faces move through the nine facial poses used for
the still images) and Facial Speech Videos (where two
video clips were taken of individuals speaking, first in a
neutral way, then in an animated way).
Face Evaluation
For an evaluation to be accepted by the biometric
community, the performa nce results have to published
along with the evaluation protocol. An evaluation pro-
tocol describes how the experiments are run and
how the data are collected. It should be written in
sufficient detail so that users, developers, and vendors
can repeat the evaluation.
The main attributes of the evaluation protocol are
described below.
Image Domain and Face Processing Tasks
There are two image domains where Face Recognition
Biometric Systems (FRBS) are applied:
1. Face recognition in documents (FRiD), in particular,
face recognition from Machine Readable Travel
Documents (MRTD).
2. Face recognition in video (FRiV), also referred to as
Face in Crowd problem, an example of which is face
recognition from surveillance video and TV.
These two image domains are very different [17]. The
systems that perform well in one domain may not
perform well in the other [18].
FRiD deals with facial data that are of high spacial
resolution, but that are very limited or absent in
▶ temporal domain – FRiD face images would nor-
mally have intra-ocular distance (IOD) of at least 60
pixels, which is the distance defined by the
▶ canonical
face model established by International Civil Aviation
Organization (ICAO) for MRTD. There will however
be not more than one or very few images available of
the same person captured over a period of time.
In contrast, FRiV deals with facial images that are
available in abundance in temporal domain but which
are of much lower spatial resolution. The IOD of facial
images in video is often lower than 60 pixels, due to
the fact that face normally occupies less than one eighth
of a video image, which itself is relatively small (352
240 for analog video or 720 480 for digital video)
compared to a scanned document image. In fact, IOD of
faces detected in video is often just slightly higher than or
equal to 10 pixels, which is the minimal IOD that per-
mits automatic detection of faces in images [19].
While for FRiD facial images are often extracted
beforehand and face recognition problem is considered
in isolation from other face processing problems, FRiV
requires that a system be capable of performing several
other facial processing tasks prior to face recognition,
such as face detection, face tracking, eye localization, best
facial image selection or reconstruction, which may also
be coupled with facial image accumulation and video
snapshot resolution enhancement [20]. Evaluation of
FRBS for FRiD is normally performed by testing a sys-
tem on static facial images datasets described above.
To evaluate FRBS for FRiV however, it is much more
common to see the system testing performed as a pilot
project on a real-life video monitoring surveillance task
[21], although some effort to evaluate their perfor-
mance using prerecorded datasets and motion pictures
has been also suggested and performed [5].
Use of Color
Color information does not affect the face recognition
performance [22], which is why many countries still
allow black-n-white face pictures in passport docu-
ments. Color however plays an important role in face
detection and tracking as well as in eye localization.
Therefore, for testing recognition from video, color
video streams should be used.
Scenario Taxonomy
The following scenario taxonomy is established to cat-
egorize the performance of biometric systems [23]:
Face Databases and Evaluation
F
297
F
Face Databases and Evaluation. Figure 1 Face databases, categorized by the factors affecting the performance of face
recognition systems: such as number of probes, face image resolution, head orientation, face expression, changed in
lighting, image quality degradation, occlusion, and aging.
298
F
Face Databases and Evaluation

cooperative vs. non-cooperative, overt vs. covert, habi-
tuated vs. non-habituated, attended vs. non-attended,
public vs. private, standard vs. non-standard. When
performing evaluation of FRBS, these categories have
to be indicated.
Dataset Type and Recognition Task
Two types of datasets are possible for recognition
problems:
1. Closed dataset, where each query face is present in
the database, as in a watch list in the case of nega-
tive enrollment, or as in a list of computer users or
ATM clients, in the case of positive enrollment,
2. Open dataset, where query faces may not be (or
very likely are not) in the database, as in the case of
surveillance video monitoring.
FRBS can be used for one three face recognition tasks:
1. Face verification, also referred to as authentifica-
tion or 1 to 1 recognition, or positive verification,
as verifying ATM clients,
2. Face identification, also referred to as or 1 to N
(negative identification – as detecting suspects from
a watch list), where a query face is compared against
all faces in a database and the best match (or the best
k matches) are selected to identify a person.
3. Face classification, also referred to as categoriza-
tion, where a person is recognized as belonging to
one of the limite d number of classes, such as de-
scribing the person’s gender (male, female), race
(caucasian, asian etc), and various medical or ge-
netic conditions (Down’s Syndrome etc).
While the result of the verification and identification
task are used as hard biometrics, the results from
classification can be used as soft biometrics, similar to
person’s height or weight.
Performance Measures
The performance is evaluated against two main errors
a system can exhibit:
1. False accept (FA) also known as false match (FM) ,
false positive (FP) or type I error.
2. False reject (FR) also known as false non-match
(FNM) or false negative (FN) or type 2 error.
By applying a FRBS on a significantly large data set of
facial images, the total number of FA and FR are
measured and used to compute one or several of the
following cumulative measurements and figures of
merit (FOM). For verification systems,
1. FA rate (FAR) with fixed FR rate.
2. FR rate (FRR), or true acceptance rate (TAR = 1 –
FRR), also known as true positive (or hit) rate, at
fixed FA rate.
3. Detection Error Trade-off (DET) curve, which is
the graph of FAR vs FRR, which is obtained by
varying the system parameters such as match
threshold.
4. Receiver Operator Characteristic (ROC) curve,
which is similar to DET curve, but plots TAR
against FAR.
5. Equal error rate (EER), which the FAR measured
when it equals FRR.
For identification tasks,
1. Identification rate, or rank-1 identification, which
is number of times when the correct identity is
chosen as the most likely candidate.
2. Rank-k identification rate (Rk), which is number of
times the the correct identity is in the top k most
likely candidates.
3. Cumulative Match Characteristic (CMC), which
plots the rank-k identification rate against k .
The rates are counted as percentages to the number of
faces in a databases. DET and ROC curves are often
plotted using logarithmic axes to better differentiate
the systems that shows similar performance.
Similarity Metrics, Normalization, and
Data Fusion
Different t ypes of metrics can be used to compare
▶ feature vectors of different faces to one another.
The recognition results can also be normalized. Proper
covariance-weighted metrics and normalization should
be used when comparing the performance results
obtained on different datasets.
When temporal data are available, as when recog-
nizing a person from a video sequence, the recognition
results are often integrated over time in a procedure
known as evid ence accumulation or data fusion. The
details of this should be known.
Face Databases and Evaluation
F
299
F