Li S.Z., Jain A.K. (eds.) Encyclopedia of Biometrics
Подождите немного. Документ загружается.

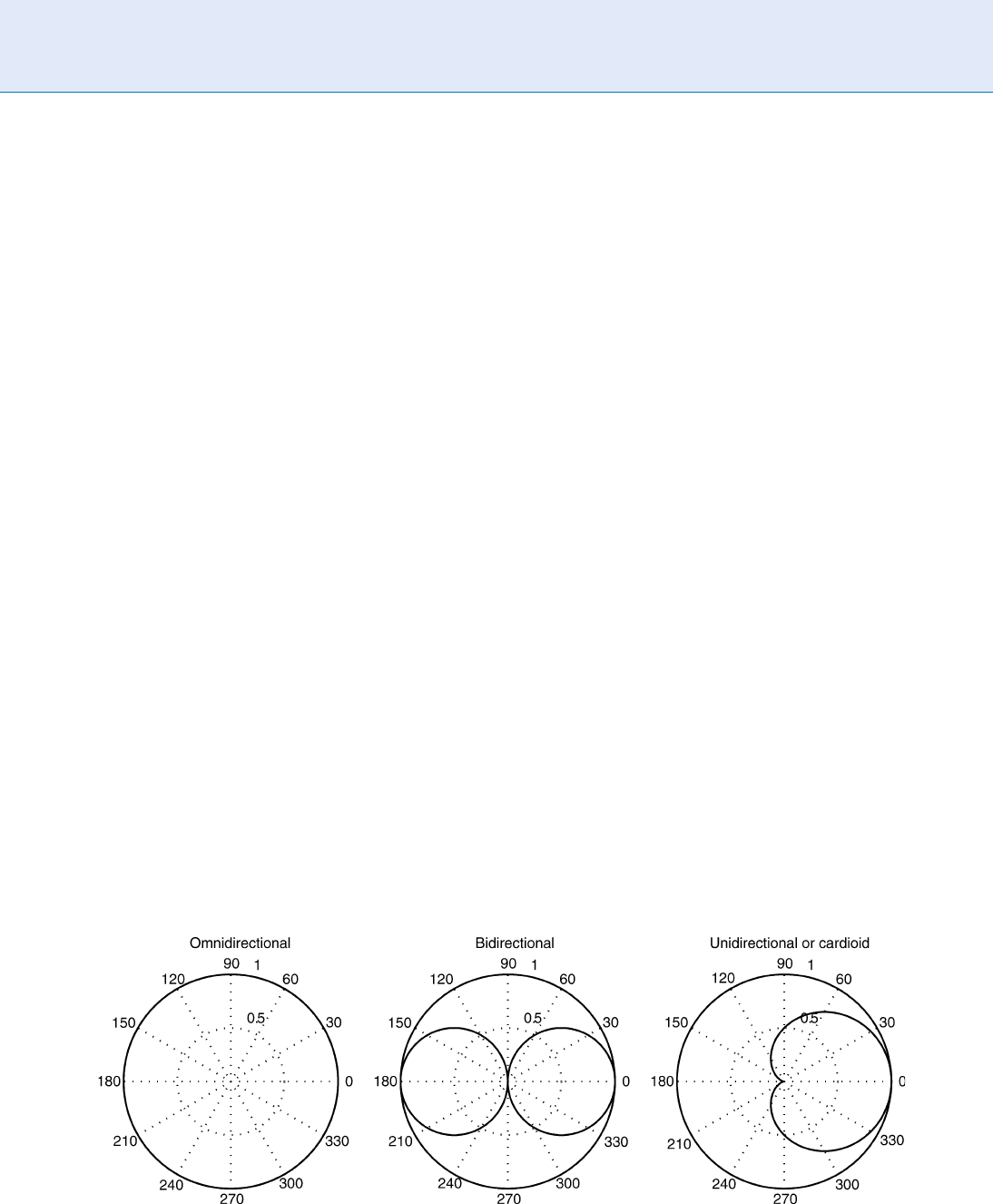
Microphones may be classified by their directional
properties as omnidirectional (or non-directional) and
directional [4]. The latter can also be subdivided into
bidirectional and unidirectional, based on their direc-
tionality patterns. Directionality patterns are usually
specified in terms of the polar pattern of the micro-
phone (Fig. 2).
Omnidirectional microphones. An omnidirectional
(or nondirectional) microphone is a microphone
whose response is indepe ndent of the direction of
arrival of the sound wave. Sounds coming from
different directions are picked equally. If a micro-
phone is built only to respond to the pressure, then
the resultant microphone is an omnidirectional
microphone. These types of microphones are the
most simple and inexpensive and have as advantage
having a very flat frequency response. However, the
property of capturing sounds coming from every
direction with the same sensiti vity is very often
undesirable, since it is usually interesting capturing
the sounds coming from the front of the micro-
phone but not from behind or the laterals.
Bidirectional microphones. If a microphone is built
to respond to the gradient of the pressure in a
particul ar direction, rather than to the pressure
itself, a bidirectional microphone is obtained.
This is achieved by letting the sound wave reach
the diaphragm not only from the front of the
microphone but also from the rear, so that if a
wave comes from a perpendicular direction the
effects on the front and the rear are canceled. This
type of microphones reach the maximum
sensitivity at the front and the rear, and reach
their minimum sensitivity at the perpendicular
directions. This directionalit y pattern is particular-
ly interesting to reduce noises from the sides of the
microphone. For this reason sometimes it is said
that these microphones are noise-canceling micro-
phones. Among the disadvantages of this kind of
microphones, it must be mentioned that their fre-
quency response is not nearly as flat as the one of
an omnidirectional microphone, and it also varies
with the direction of arrival. The frequency re-
sponse is also different w ith the distance from the
sound source to the microphone. Particularly, for
sounds generated close to the microphone (near
field) the response for low frequencies is higher
than for sounds generated far from the microphone
(far field). This is known as the proximity effect. For
that reason frequency responses are given usually
for far-field and near-field conditions, particularly
for close-talking microphones. This type of micro-
phones are more sensitive to the noises produced
by the wind and the wind induced by the pronun-
ciation of plosive sounds (such as /p/) in close-
talking microphones.
Unidirectional Microphones. These microphones
have maximum response to sounds coming from
the front of the microphone, have nearly zero re-
sponse to sounds coming from the rear of the
microphone and small response to sounds coming
from the sides of the microphone. Unidirectional-
ity is achieved by building a microphone that
responds to the gradient of the sounds, similar to
Voice Device. Figure 2 Typical polar patterns for omnidirectional, bidirectional and unidirectional (or cardioid)
microphones.
1380
V
Voice Device

a bidirectional microphone. The null response
from the rear is attained by introducing a material
to slow down the acoustic waves coming from the
rear so that when the wave comes from the rear it
takes equal time to reach the rear part and the front
part of the diaphragm, and therefore both cancel
out. The polar pattern of these microphones has
usually the shape of a heart, and for that reason are
sometimes called cardiod microphones. These
microphones have good noise-cancelation proper-
ties, and for these reasons, are very well suited for
capturing clean audio input.
Microphone Location
Some microphones have different frequency response
when the sound source is clos e to the microphone
(near field, or close-talking) and when the sound
source is far from the microphone (far field). In fact,
not only the frequency response, but also the problems
to the voice biometric application and the selection of
the microphone could be different. For this reason a
few concepts about microphone location will be
reviewed.
Close-talking or near-field microphones. These
microphones are located close to the mouth of
the speaker, usually pointing at the mouth of the
speaker. This kind of microphones can benefit from
the directionality pattern to capture mainly the
sounds produced by the speaker, but could also be
very sensitive to the winds produced by the speaker,
if placed just in front of the mouth. The char acter-
istics of the sound captured may be very different
if the microphone is placed at different relative
positions from the mouth, which is sometimes a
problem for voice biometrics applications.
Far-field microphones. These microphones are loca-
ted at some distance from the speaker. They have
the disadvantage that they tend to capture more
noise than close-tal king microphones because
sometimes cannot take advantage of directionality
patterns. This is particularly true if the speaker can
move around as she speaks. In general, far-field
microphone speech is considered to be far more
difficult to process than close-talking speech. In
some circumstances it is possible to take advantage
of microphone arrays to locate the speaker spatially
and to focus the array to listen specially to them.
Specifications
There is an international standard for microphone
specifications [5], but few manufacturers follow it ex-
actly. Among the most common specifications of a
microphone the following must be mentioned.
Sensitivity. The sensitiv ity measures the efficiency
in the transduction (i.e. how much voltage it gen-
erates for an input acoustic pressure). It is
measured in millivolts per Pascal at 1 kHz.
Frequency Response. The frequency response is a
measure of the variation of the sensitivity of a
microphone as a function of the frequency of the
signal. It is usually represented in decibels (dB)
over a range of frequency typically between 0 and
20 kHz. The frequency response is dependent on
the direction of arrival of the sound and the dis-
tance from the sound source. The frequency res-
ponse is typically measured for sound sources very
far from the microphone and with the sound
reaching the microphone from its front direction.
For close talking microphones it is also typical to
represent the frequency response for sources close
to the microphone to take into account the pro-
ximity effect.
Directional Characteristics. The directionality of a
microphone is the variation of its sensitivity as a
function of the sound arrival direction, and is usu-
ally specified in the form of a directionality pattern,
as explained earlier.
Non-Linearity. Ideally, a microphone should be a
linear transducer, and therefore a pure audio tone
should produce a single pure voltage sinusoid at
the same frequency. As microphones are not exactly
linear, a pure acoustic tone produces a voltage
sinusoid at the same frequency but also some har-
monics. The most extended nonlinearity measure
is the total harmonic distortion, THD, which is the
ratio between the power of the harmonics produ-
ced and the power of the voltage sinusoid produced
at the input frequency.
Limiting Characteristics. These characteristics indi-
cate the maximum sound pressure level (SPL) that
can be transduced with limited distortion by the
microphone. There are two different measures,
the maximum peak SPL for a maximum THD,
and the overload, clipping or saturation level. This
last one indicates the SPL that produces the
Voice Device
V
1381
V

maximum displacement of the diaphragm of the
microphone.
Inherent Noise. A microphone, in the absence of
sound, produces a voltage level due to the inherent
noise produced by itself. This noise is measured as
the input SPL that would produce the same output
voltage, which is termed the equivalent SPL due to
inherent noise. This parameter determines the min-
imum SPL that can be effectively transduced by the
microphone.
Dy namic Range. The former parameters define the
dynamic range of the microphone, (i.e. the mini-
mum and maximum SPL that can be effectively
transduced).
Summary
Speech input devices are the first element in a voice
biometric system and are sometimes not given the
attention they deserve in the design of voice biometric
applications. This section has presented some of the
variables to take into account in the selection or design
of a microphone for a voice biometric application. The
right selection, design, and even placement of a micro-
phone could be crucial for the success of a voice bio-
metric system.
Related Entries
▶ Biometric Sample Acquisition
▶ Sample Acquisition (System Design)
▶ Sensors
References
1. Eargle, J.: The Microphone Book, 2nd edn. Focal, Elsevier, Bur-
lington, MA (2005)
2. National Institute of Standards and Technology (NIST ): NIST
Speaker Recognition Evaluation. http://www.nist.gov/speech/
tests/spk/
3. Flichy, P.: Une Histoire de la Communication Moderne. La
Decouverte (1997)
4. Huang, X., Acero, A., Hon, H.W.: Spoken Language Processing.
Prentice-Hall PTR, New Jersey (2001)
5. International Electrotechnical Comission: International Stan-
dard IEC 60268-4: Sound systems equipment, Part 4: Micro-
phones. Geneva, Switzerland (2004)
Voice Evidence
The forensic evidence of voice consists of the quanti-
fied degree of similarit y between the speaker depen-
dent features extracted from the questioned recording
(trace) and the same extracted from recorded speech of
a suspect, represented by his or her model.
▶ Voice, Forensic Evidence of
Voice Recognition
▶ Speaker Recognition, Overview
▶ Speaker Recognition Standardization
Voice Sample Synthesis
JUERGEN SCHROETER
AT&T Labs – Research, Florh am Park, NJ, US
Synonyms
Speech synthes is; Synthetic voice creation; Text-to-
speech (TTS)
Definition
Over the last decade, speech synthesis, the technology
that enables machines to talk to humans, has become
so natural-sounding that a naı
¨
ve listener might assume
that he/she is listening to a recording of a live human
speaker. Speech synthesis is not new; indeed, it took
several decades to arrive where it is today. Originally
starting from the idea of using physics-based models of
the vocal-tract, it took many years of research to per-
fect the encapsulation of the acoustic properties of the
vocal-tract as a ‘‘black box’’, using so-called formant
synthesizers. Then, with the help of ever more
1382
V
Voice Evidence

powerful computing technology, it became viable to
use snippets of recorded speech directly and glue them
together to create new sentences in the form of con-
catenative synthesizers. Combining this idea with now
available methods for fast search, potentially millions
of choices are evaluated to find the optimal sequence of
speech snippets to render a given new sentence. It is the
latter technolog y that is now prevalent in the highest
quality speech synthesis systems. This essay gives a
brief overview of the technology behind this progress
and then focuses on the processes used in creating
voice inventories for it, starting with recordings of a
carefully-selected donor voice. The fear of abusing the
technolog y is addressed by disclosing all important
steps towards creating a high-qualit y synthetic voice.
It is also made clear that even the best synthetic voices
today still trip up often enough so as not to fool the
critical listener.
Introduction
Speech synthesis is the technology that gives compu-
ters the ability to communicate to the users by voice.
When driven by text input, speech synthesis is part of
the more elaborate
▶ text-to-speech (TTS) synthesis,
which also includes text processing (expanding abbre-
viations, for example), letter-to-sound transformation
(rules, pronunciation dictionaries, etc.), and stress and
pitch assignment [1]. Speech synthesis is often viewed
as encompassing the signal-processing ‘‘backend’’ of
text-to-speech synthesis viewed as encompassing the
signal-processing ‘‘backend’’ of text-to-speech synthe-
sis (with text and linguistic processing being carried
out in the ‘‘front-end’’). As such, speech synthesis takes
phoneme-based information in context and transforms
it into audible speech. Context information is very
important because, in naturally-produced speech, no
single speech sound stands by itself but is always highly
influenced by what sounds came before, and what
sounds will follow immediately after. It is precisely
this context information that is key to achieving
high-quality speech output.
A high-quality TTS system can be used for many
applications, from telecommunications to personal
use. In the telecom area, TTS is the only practical way
to provide highly flexible speech output to the caller
of an automated speech-enabled service. Examples of
such services include reading back name and address
information, and providing news or email reading. In
the personal use area, the author has witnessed the
ingenious ‘‘high jacking’’ of AT&T’s web-based TTS
demonstration by a young student to fake his mother’s
voice in a telephone call to his school: ‘‘Timmy will be
out sick today. He cannot make it to school.’’ It seems
obvious that natural-sounding, high quality speech syn-
thesis is vital for both kinds of applications. In the
telecom area, the provider of an automated voice service
might lose customers if the synthetic voice is unintelli-
gible or sounds unnatural. If the young student wants to
get an excused day off, creating a believable ‘‘real-sound-
ing’’ voice seems essential. It is mostly concerns about
the latter kind of potential abuse that motivates this
author to write this essay. In the event that the even
stricter requirement is added of making the synthetic
voice indistinguishable from the voice of a specific per-
son, there is clearly a significantly more difficult chal-
lenge. Shortly after AT&T’s Natural Voices1 TTS
system became commercially available in August 2001,
an article in the New York Times’ Circuits section [2]
asked precisely whether people will be safe from seri-
ous criminal abuse of this technolog y. Therefore, the
purpose of this essay is to demystify the process of
creating such a voice, disclose what processes are
involved, and show current limitations of the technol-
ogy that make it somewhat unlikely that speech syn-
thesis could be criminally abused anytime soon.
This essay is organized as follows. The next section
briefly summarizes different speech synthesis methods,
followed by a somew hat deeper overview of the so-
called Unit Selection synthesis method that currently
delivers the highest quality speech output. The largest
section of this essay deals with creating voice databases
for unit selection synthesis. The essay concludes with
an outlook.
Overview of Voice Synthesis Methods
The voice (speech) synthesis method with the most
vision and potential, but also with somewhat unful-
filled promises, is articulatory synthesis. This method
employs mathematical models of the speech produc-
tion process in the human vocal tract, for example,
models of the mechanical vibrations of the vocal
chords (glottis) that interact with the fluid dynamics
of the laminar and turbulent airflow from the lungs to
the lips, plus linear or even nonlin ear acoustical
Voice Sample Synthesis
V
1383
V

models of sound generation and propagation along the
vocal tract. A somewhat comprehensive review of this
method is given in [3]. Due to high computational
requirements and the need for highly accurate mode l-
ing, articulatory synthesis is mostly useful for research
in speech production. It usually delivers unacceptably
low-quality synthe tic speech.
One level higher in abstraction, and much more
practical in its use, is formant synthesis. This method
captures the characteristics of the resonances of
the human vocal tract in terms of simple filters. The
single-peaked frequency characteristic of such a filter
element is called formant. Its frequency, bandwidth
(narrow to broad), and amplitude fully specify each
formant. For adult vocal tracts, four to five formants
are enoug h to determine their acoustic filter character-
istics. Phonetically most relevant are the lowest three
formants that span the vowel and sonorant space of a
speaker and a language. Together with a suitable wave-
form generator that approximates the glottal pulse,
formant synthesis systems, due to their highly versatile
control parameter sets, are very useful for speech per-
ception research. More on formant synthesis can be
found in [4]. For use as a speech synthesizer, the
computational requirements are relatively low, making
this method the preferred option for embedded appli-
cations, such as reading back names (e.g., ‘‘calling
Mom’’) in a dial-by-voice cellular phone handset. Its
storage requirements are miniscule (as little as 1 MB).
Formant synthesis delivers intelligible speech when
special care is given to consonants.
In the 1970s, a new method started to compete
with the, by then, well-established formant synthesis
method. Due to its main feature of stitching together
recorded snippets of natural speech, it was called con-
catenative synthesis. Many different options exist for
selecting the specific kin d of elementary speech units
to concatenate. Using words as such units, although
intuitive, is not a good choice given that there are many
tens of thousands of them in a language and that each
recorded word would have to fit into several different
contexts with its neighbors, creating the need to record
several versions of each word. Therefore, word-based
concatenation usually sounds very choppy and artifi-
cial. However, subword units, such as diphones or
demisyllables turned out to be much more useful be-
cause of favorable statistics. For English, there is a
minimum of about 1500
▶ diphones that would need
to be in the inventory of a diphone-based
concatenative synthesizer. The number is only slightly
higher for concatenating
▶ demisyllables. For both
kinds of units, however, elaborate methods are needed
to identify the best single (or few) instances of units to
store in the voice inventory, based on statistical mea-
sures of acoustic typicality and ease of concatenation,
with a minimum of audible g litches. In addition, at
synthesis time, elaborate speech signal processing is
needed to assure smooth transitions, deliver the de-
sired prosody, etc. For more details on this method, see
[5]. Concatenative synthesis, like formant synthesis,
delivers highly intelligible speech and usually has no
problem with transients like stop consonants, but usu-
ally lacks naturalness and thus cannot match the qual-
ity of direct human voice recordings. Its storage
requirements are moderate by today’s standards
(10–100 MB).
Unit Selection Synthesis
The effort and care given to creating the voice inventory
determines to a large extent the quality of any concatena-
tive synthesizer . For best results, most concatenative syn-
thesis researchers well up into the 1990s employed a
largely manual off-line process of trial and error that
relied on dedicated experts. A selected unit needed to fit
all possible contexts (or made to fit by signal processing
such as, stretching or shrinking durations, pitch scaling,
etc.). Howev er, morphing any given unit by signal proces-
sing in the synthesizer at synthesis time degrades voice
quality . So, the idea was born to minimize the use of signal
processing by taking advantage of the ever increasing
power of c omputers to handle ever increasing data sets.
Insteadofoutrightmorphingaunittomakeitfit,the
synthesizer may try to pick a suitable unit fr om a large
number of available candidates, optionally followed b y
much more moderate signal processing. The objective
is to find automatically the optimal sequence of unit
instances at synthesis time, given a large inventory of
unit candidates and the available sentence to be synthe-
sized. This new objective turned the speech synthesis
problem into a rapid search problem [6].
The process of selecting the right units in the in-
ventory that instantiate a given input text, appropri-
ately called unit selection, is outlined in Fig. 1. Here,
the word ‘‘two’’ (or ‘‘to’’) is synthesized from using
diphone candidates for silence into ‘‘t’’ (/#-t/), ‘‘t’’
into ‘‘uw’’ (/t-uw/), and ‘‘uw’’ into silence (/uw-#/).
1384
V
Voice Sample Synthesis
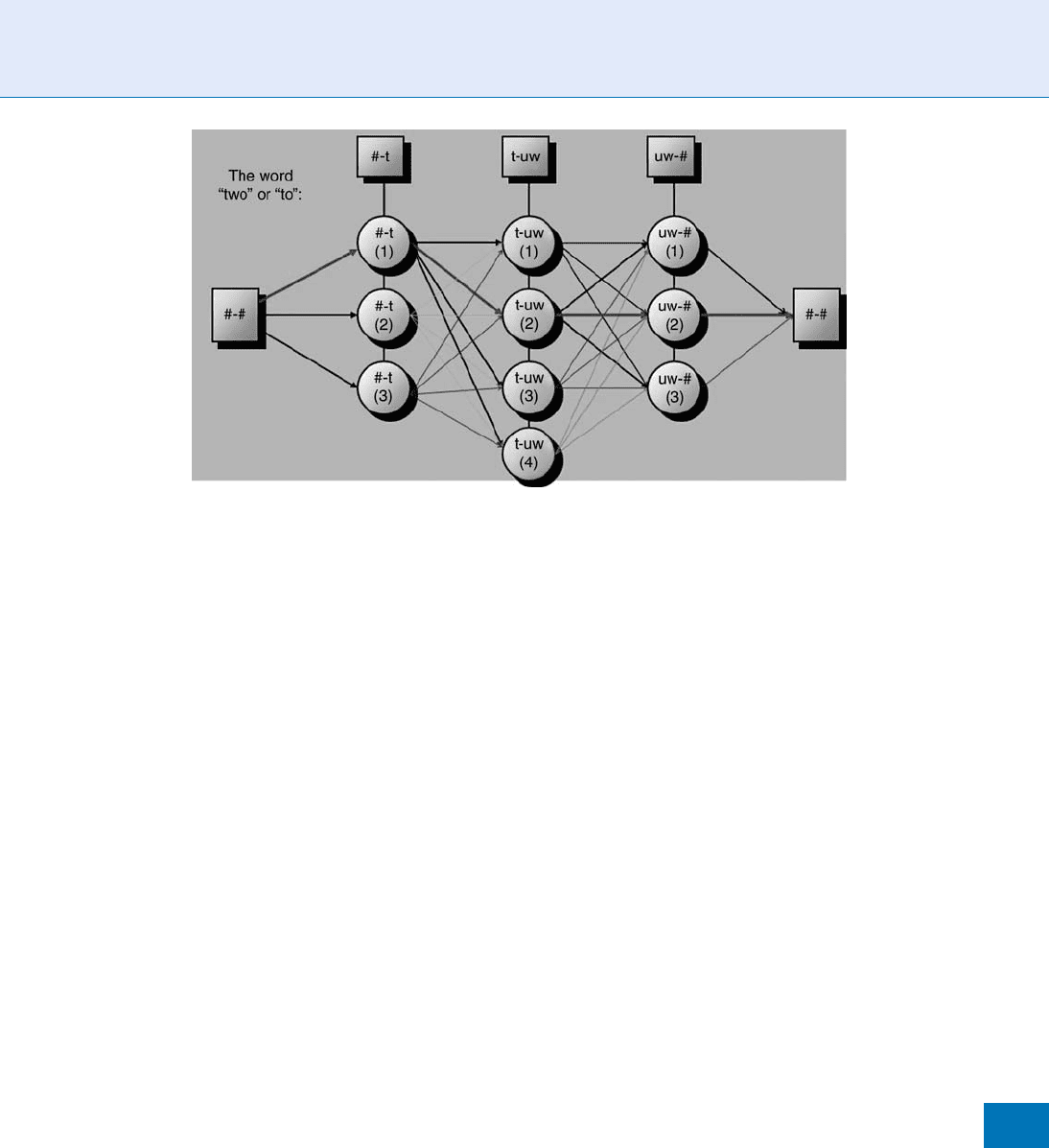
Each time slot (column in Fig. 1) has several candi-
dates to choose from. Two different objective distance
measures are employed. First, transitions from one
unit to the next (depicted by arrows in the figure) are
evaluated by comparing the speech spectra at the end
of the left-side unit candidates to the speech spectra at
the beginning of the right-side unit candidates. These
are n*m comparisons, where n is the num ber of unit
candidates for the left column of candidates, and m is
the number of unit candidates in the right-side column
of candidates. Second, each node (circle) in the net-
work of choices depicted in Fig. 1 has an intrinsic
‘‘goodness of fit’’ measured by a so-called target cost.
The ideal target cost of a candidate unit measures the
acoustic distance of the unit against a hypothetical unit
cut from a perfect recording of the sentence to be
synthesized. However, since it is unlikely that the
exact sentence would be in the inventory, an algorithm
has to estimate the target cost using symbolic and
nonacoustic cost components such as the difference
between desired and given pitch, amplitude, and con-
text (i.e., left and right phone sequences).
The objective of selecting the optimal unit sequence
for a given sentence is to minimize the total cost that is
accumulated by summing transitional and target costs
for a given path through the network from its left-side
beginning to its right-side end. The optimal path is
the one w ith the minimum total cost. This path
can be identified efficiently using the Viterbi search
algorithm [7].
More detailed information about unit selection syn-
thesis can be found in [1, 8]. The latter book chapter also
summarizes the latest use of automatic speech recogni-
tion (ASR) technology in unit selection synthesis.
Voice Creation
Creating a simple-minded unit selectio n synthesizer
would involve just two steps: First, record exactly the
sentences that a user wants the machine to speak; and
second, identify at ‘‘synthesis’’ time the input sentence
to be spoken, and then play it back. In practice units
are used that are much shorter than sentences to be
able to create previously unseen input sentences, so
this simple-minded paradigm would not work. How-
ever, when employing a TTS front-end that converts
any input text into a sequence of unit specifications,
intuition may ask for actually playing back any inven-
tory sentence in its entirety in the odd chance that the
corresponding text has been entered. Since the transla-
tion of text into unit-based tags and back into speech is
not perfect, the objective is unlikely to ever be fully
met. In practice, however, the following, somewhat
weaker objective holds: as long as the text to be synthe-
sized is similar enough to that of a corresponding
recording that actually exists in the inventory, a high
output voice quality can be expected. It is for this
reason that unit-selection synthesis is particularly well
suited for so-called limited domain synthesis, such as
Voice Sample Synthesis. Figure 1 Viterbi search to retrieve optimal diphone units for the word ‘‘two’’ or ‘‘to’’.
Voice Sample Synthesis
V
1385
V
weather reports, stock reports, or any automated tele-
com dialogue application (banking, medical, etc.)
where the application designer can afford the luxury
of recording a special inventory, using a carefully se-
lected voice talent. High quality synthesis for general
news or email reading is usually much more difficult to
achieve because of coverage issues [9].
Because unit selection synthe sis, to achieve its best
quality results, mimics a simple tape recorder playback,
it is obvious that its output voice quality largely
depends on what material is in its voice inventory.
Without major modifications/morphing at synthesis
time, the synthesizer output is confined to the qualit y,
speaking st yle, and emoti onal state of the voice that
was recorded from the voice talent/donor speaker. For
this reason, careful planning of the voice inventory is
required. For example, if the inventory contains only
speech recorded from a news anchor, the synthesizer
will always sound like a news anchor.
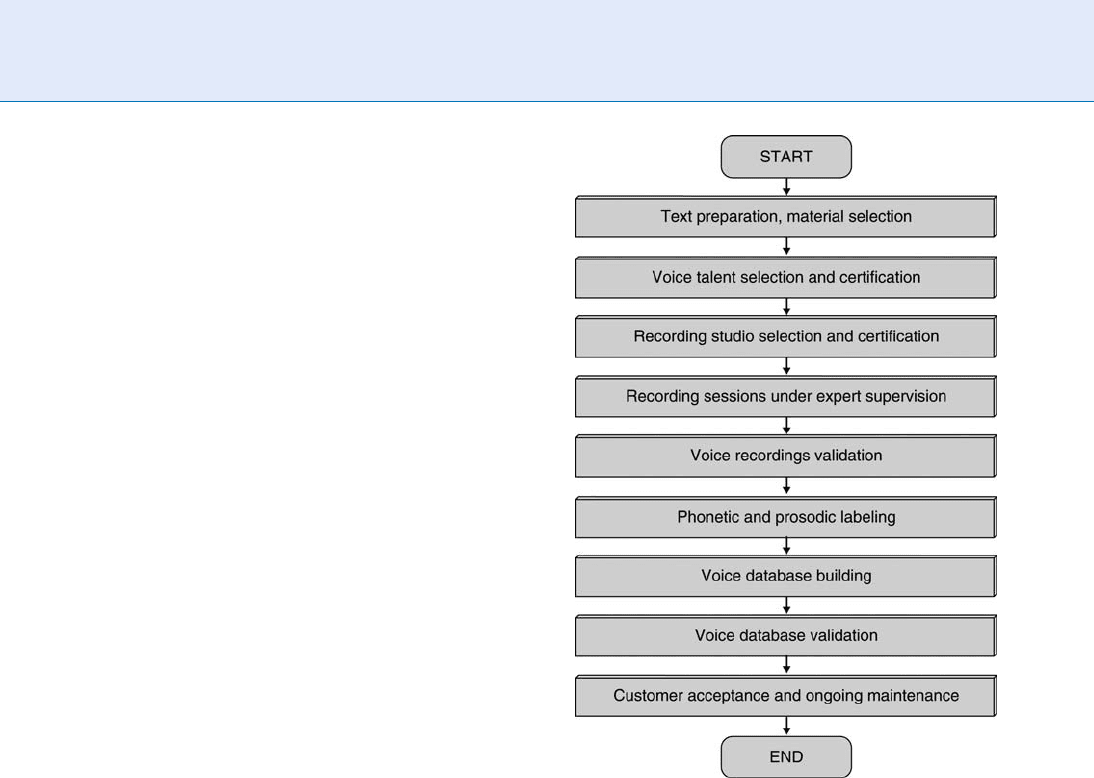
Several issues need to be addressed in planning a
voice inventory for a unit selection synthesizer. The
steps involved are outlined in Fig. 2, starting with text
preparation to cover the material selected. Since voice
recordings cannot be done faster than real time, they
are always a major effort in time and expense. To get
optimal results, a very strict quality assurance process
for the recordings is paramount. Furthermore, the
content of the material to be recorded needs to be
addressed. Limited domain synthesis covers typical
text for the given application domain, including greet-
ings, apologies, core transactions, and good-byes. For
more general use such as email and news reading,
potentially hundreds of hours of speech need to be
recorded. However, the base corpus for both kinds of
applications needs to maximize linguistic coverage
within a small size. Including a core corpus that was
optimized for traditional diphone synthesis might
satisfy this need. In addition, news material, sentences
that use the most common names in different prosodic
contexts, addresses, and greetings are useful. For limited
domain applications, domain-specific scripts need to
be created. Most of them require customer input
such as getting access to text for existing voice
prompts, call flows, etc. There is a significant danger
in underestimating this step in the planning phase.
Finally, note that a smart and frugal effort in designing
the proper text corpus to record helps to reduce the
amount of data to be recorded. This, in turn, will speed
up the rest of the voice building process.
Quality assurance starts with selecting the best pro-
fessional voice talent. Besides the obvious criteria of
voice preference, accent, pleasantness, and suitability
for the task (a British butler voice might not be appro-
priate for reading instant messages from a banking
application), the voice talents needs to be very consis-
tent in how she/he pronounces the same word over time
and in different contexts. Speech production issues
might come into play, such as breath noise, frequent
lip smacks, disfluencies, and other speech defects. A
clearly articulated and pleasant sounding voice and a
natural prosodic quality are important. The same is true
for consistency in speaking rate, level, and style. Surpris-
ingly, good sight reading skills are not very common
among potential voice talents. Speakers with heavy
vocal fry (glottal vibration irregularities) or strong
nasality should be avoided. Overall, a low ratio of
usable recordings to total recordings done in a test
run is a good criterion for rejecting a voice talent.
Voice Sample Synthesis. Figure 2 Steps in unit selection
voice inventory creation.
1386
V
Voice Sample Synthesis

Pronunciations of rare words, such as foreign names,
need to be agreed upon beforehand and their realiza-
tions monitored carefully. Therefore, phonetic supervi-
sion has to be part of all recording sessions.
Next, the recording studio used for the recording
sessions should have almost ‘‘anechoic’’ acoustic char-
acteristics and a very low background noise in order to
avoid coloring or tainting the speech spectrum in any
way. Since early acoustic reflections off a nearby wall or
table are highly dependent on the time-varying geom-
etry relative to the speaker’s mouth and to the micro-
phone, the recording engineer needs to make sure that
the speaker does not move at all (unrealistic) or mini-
mize these reflections. The recording engineer also
needs to make sure that sound levels, and trivial things
like the file format of the recordings are consistent and
on target. Finally, any recorded voice data needs to be
validated and inconsistencies between desired text and
actually spoken text reconciled (e.g., the speaker reads
‘‘vegetarian’’ where ‘‘veterinarian’’ was requested).
Automatic labeling of large speech corpora is a
crucial step because manual labeling by linguists is
slow (up to 500 times real time) and potentially incon-
sistent (different human labelers disagree). Therefore,
an automatic speech recognizer (ASR) is used in
so-called forced alignment mode for phonetic labeling.
Given the text of a sentence, the ASR identifies the
identities and the beginnings and ends of all
▶ pho-
nemes. ASR might employ several passes, star ting from
speaker-independent models, and adapting these mod-
els to the given single speaker, and his/her speaking
style. Adapting the pronunciation dictionary to the
specific speaker’s individual pronunciations is vital to
get the correct phoneme sequence for each recorded
word. Pronunciation dictionaries used for phonetic
labeling should also be used in the synthesizer. In
addition, an automated prosodic labeler is useful for
identifying typical stress and pitch patterns, prominent
words, and phrase boundaries. Both kinds of automat-
ic labeling need to use paradigms and conventions
(such as phoneme sets and symbolic
▶ prosody tags)
that match those used in the TTS front-end at synthe-
sis time. A good set of automatic labeling and other
tools allowed the author’s group of researchers to
speed up their voice building process by more than
100 times over 6 years.
Once the recordings are done, the first step in the
voice building process is to build an index of which
sound (phoneme) is where, normalize the amplitudes,
and extract acoustic and segmental features, and
then build distance tables used to trade off (weigh)
different cost components in unit selection in the last
section. One important par t of the runtime synthesiz-
er, the so-called Unit Preselection (a step used to nar-
row down the potentially very large number of
candidates) can be sped up by looking at statistics
of triples of phonemes (i.e., so-called triphones) and
caching the results. Then, running a large independent
training text corpus through the synthesizer and
gathering statistics of unit use can be used to build a
so-called join cache that eliminates recomputing join
costs at runtime for a significant speedup. The final
assembly of the voice database may include reordering
of units for access efficiency plus packaging the voice
data and indices.
Voice database validation consists of comprehen-
sive, iterative testing with the goal of identifying bad
units, either by automatic identification tools or by
many hours of careful listening and ‘‘detective’’ work
(where did this bad sound come from?), plus repair.
Allocating sufficient testing time before compute-
intensive parts of the voice building process (e.g.,
cache building) is a good idea. Also, setting realistic
expectations with the customer (buyer of the voice
database) is vital. For example, the author found that
the ‘‘damage’’ that the TTS-voice creation and synthe-
sis process introduces relative to a direct recording
seems to be somewhat independent of the voice talent.
Therefore, starting out with a ‘‘bad’’ voice talent will
only lead to a poorer sounding synthetic voice. Reduc-
ing the TTS damage over time is the subject of ongoing
research in synthesis-related algorithms employed in
voice synthesis.
The final step in unit selection voice creation is for-
mal customer acceptance and, potentially, ongoing
maintenance. Formal customer acceptance is needed
to avoid disagreements ov er expected and delivered qual-
ity, coverage, etc. Ongoing maintenance assures high
quality for slightly different applications or application
domains, including, for example, additional recordings.
Conclusion
This essay highlighted the steps involved in creating a
high-quality sample-based speech synthesizer. Special
focus was given to the process of voice inventory
creation.
Voice Sample Synthesis
V
1387
V

From the details in this essay, it should be clear
that voice inventory creation is not trivial. It involves
many weeks of expert work and, most importantly, full
collaboration with the chosen voice talent. The idea of
(secretly) recording any person and creating a synthet-
ic voice that sounds just like her or him is simply
impossible, given the present state of the art. Collecting
several hundreds of hours of recordings necessary to
having a good chance at success of creating such a voice
inventory is only practical when high-quality archived
recordings are already available that were recorded
under very consistent acoustic conditions. A possible
workable example would be an archive containing a
year or more of evening news read by a well-known
news anchor. Even then, however, on e would need to
be concerned about voice consistency, since even slight
cold infections, as well as more gradual nat ural changes
over time (i.e., caused by aging of the speaker) can
make such recordings unusable.
An interesting extension to the sample synthesis of
(talking) faces was made in [10]. The resulting head-
and-shoulder videos of synthetic personal agents are
largely indistinguishable from video recordings of the
face talent. Again, similar potential abuse issues are a
concern.
One specific concern is that unit-selec tion voice
synthesis may ‘‘fool’’ automatic speaker verification
systems. Unlike a human listener’s ear that is able to
pick up the subtle flaws and repetitiveness of a
machine’s renderings of a human voice, today’s speaker
verification systems are not (yet) designed to pay at-
tention to small blurbs and glitches that are a clear
giveaway of a unit selection synthesizer’s output, but
this could change if it became a significant problem. If
this happens, perceptually undetectable watermarking
is an option to identify a voice (or talking face) sample
as ‘‘synthetic’’. Other procedural options include ask-
ing for a second rendition of the passphrase and
comparing the two versions. If they are too similar
(or even identical), reject the speaker identity claim
as bogus.
Related Entries
▶ Hidden Markov Model (HMM)
▶ Speaker Databases and Evaluation
▶ Speaker Matching
▶ Speaker Recognition, Overview
▶ Speech Production
References
1. Schroeter, J.: Basic principles of speech synthesis, In: Benesty, J.
(ed.) Springer Handbook of Speech Processing and Communi-
cation, Chap. 19 (2008)
2. Bader, J.L.: Presidents as pitchmen, and posthumous play-by-
play, commentar y in the New York Times, August 9 (2001)
3. van Santen, J., Sproat, R., Olive, J., Hirschberg, J., (eds.): Prog-
ress in speech synthesis, section III. Springer, NY (1997)
4. Holmes, J.N.: Research report formant synthesizers: cascade or
parallel? Speech Commun. 2(4), 251–273 (1983)
5. Sproat, R. (ed.): Multilingual text-to-speech synthesis. The bell
labs approach. Kluwer Academic Publishers, Dordrecht MA
(1998)
6. Hunt, A., Black, A.W.: Unit selection in a concatenative speech
synthesis system using a large speech database. In: Proceedings
of the ICASSP-96, pp. 373–376, GA, USA (1996)
7. Forney, G.D.: The viterbi algorithm. Proc. IEEE 61(3), 268–278
(1973)
8. Dutoit, T.: Corpus-based speech synthesis, In: Benesty, J. (ed.)
Springer Handbook of Speech Processing and Communication,
Chap. 21 (2008)
9. van Santen, J.: Prosodic processing. In: Benesty, J. (ed.) Springer
Handbook of Speech Processing and Communication, Chap. 23
(2008)
10. Cosatto, E., Graf, H.P., Ostermann, J., Schroeter, J.: From
audio-only to audio and video text-to-speech. Acta Acustica
90, 1084–1095 (2004)
Voice Verification
▶ Liveness Assurance in Voice Authentication
Voice, Forensic Evidence of
ANDRZEJ DRYGA J L O
Swiss Federal Institute of Technology Lausanne
(EPFL), Lausanne, Switzerland
Synonym
Forensic speaker recognition
Definition
Forensic speaker recognition is the process of determin-
ing if a specific individual (suspected speaker) is the
1388
V
Voice Verification

source of a questioned voice recording (trace). The
forensic application of speaker recognition technology
is one of the most controversial issues within the wide
community of researchers, experts, and police workers.
This is mainly due to the fact that very different methods
are applied in this area by phoneticians, engineers, law-
yers, psychologists, and investigators. The approaches
commonly used for speaker recognition by forensic
experts include the aural-perceptual, the auditory-
instrumental, and the automatic methods. The forensic
expert’s role is to testify to the worth of the evidence by
using, if possible a quantitative measure of this worth.
It is up to other people (the judge and/or the jury) to
use this information as an aid to their deliberations
and decision.
This essay aims at presenting forensic automatic
speaker recognition (FASR) methods that provide a
coherent way of quantifying and presenting recorded
voice as scientific evidence. In such methods, the evi-
dence consists of the quantified degree of similarity
between speaker-dependent features extracted from
the trace and speaker-dependent features extracted
from recorded speech of a suspect. The interpretation
of a recorded voice as evidence in the forensic context
presents particular challenges, including within-speaker
(within-source) variability, between-speakers (between-
sources) variability, and differences in recording sessions
conditions. Consequently, FASR methods must provide
a probabilistic evaluation which gives the court an indi-
cation of the strength of the evidence given the estimated
within-source, between-sources, and between-session
variabilities.
Introduction
Speaker recognition is the general term used to include
all of the many different tasks of discriminating people
based on the sound of their voices. Forensic speaker
recognition involves the comparison of recordings of
an unknown voice (questioned recording) with one
or more recordings of a known voice (voice of the
suspected speaker) [1, 2].
There are several types of forensic speaker recog-
nition [3, 4]. When the recognition employs any
trained skill or any technologically-supported proce-
dure, the term technical forensic speaker recognition
is often used. In contrast to this, so-called naı
¨
ve for-
ensic speaker recognition refers to the application of
un-reflected everyday abilities of people to recognize
familiar voices.
The approaches commonly used for technical foren-
sic speaker recognition include the aural-perceptual,
auditory-instrumental, and automatic methods [2].
Aural-perceptual methods, based on human auditory
perception, rely on the careful listening of recordings
by trained phoneticians, where the perceived differ-
ences in the speech samples are used to estimate the
extent of similarity between voices [3]. The use of
aural-spectrographic speaker recognition can be con-
sidered as anoth er method in this approach. The
exclusively visual comparison of spectrograms in what
has been called the ‘‘
▶ voiceprint ’’ approach has come
under considerable criticism in the recent years [5]. The
auditory-instrumental methods involve the acoustic
measurements of various parameters, such as the aver-
age fundamental frequency, articulation rate, formant
centre-frequencies, etc. [4]. The means and variances
of these parameters are compared. FASR is an estab-
lished term used when automatic speaker recognition
methods are adapted to forensic applications. In auto-
matic speaker recognition, the statistical or determin-
istic models of acoustic features of the spe aker’s voice
and the acoustic features of questioned recordings are
compared [6].
FASR o ffers data-driven methodology for quanti-
tative interpretation of recorded speech as evidence.
It is a relatively recent application of digital speech
signal processing and pattern recognition for judicial
purposes and particularly law enforcement. Results
of FASR based investigations may be of pivotal im-
portance at any stage of the course of justice, be it the
very first police investigation or a court trial. FASR
has been gaining more and more importance ever
since the telephone has become an almost ideal
tool for the commission of certain criminal o ffences,
especially drug dealing, extor tion, se xual harassment,
and hoax calling. To a certain degree, this is undoubt-
edly a conseq uence o f the h ighly-developed and fully
automated telephone ne tworks, which may safegu ard
a perpetrator’s anonymity. Nowadays, speech com-
munications technology is accessible anywhere, any-
time and at a low price. It helps to connect people,
but unfortunately also makes criminal activities
easier. Therefore, the identity of a speaker and the
interpretation of recorded s peech as ev idence in
theforensiccontextarequiteoftenatissueincourt
cases [1, 7].
Voice, Forensic Evidence of
V
1389
V