Kortum P. (ed.) HCI Beyond the GUI. Design for Haptic, Speech, Olfactory, and Other Nontraditional Interfaces
Подождите немного. Документ загружается.

Automatic tag extraction addresses the reluctance many users have of spending
time performing manual annotation of digital photos.
Multimodal group communication has also been used to analyze group behav-
ior in meetings (McCowan et al., 2005; Pianesi et al., 2006; Rienks & Heylen, 2005;
Wainer & Braga, 2001; Zancanaro et al., 2006). Pianesi and Zancanaro and respec-
tive colleagues have been exploring a multimodal approach to the automatic
detection and classification of social/relational functional roles assumed by people
during meetings. Detected roles do not correspond to the hierarchical roles parti-
cipants may have in an organization, but rather reflect attitudes during a meeting.
Two main categories are identified: task and social-emotional. Whereas the former
has to do with facilitation and coordination of task performance (e.g., the defini-
tion of goals and procedures), the latter is concerned with the relationship among
group members (e.g., moderation of group discussions or cooperative attitude
toward other participants).
Using information about speech activity (who is talking to whom at each
moment) a nd localized repetitive m otions (fidgeting) obtained from a visual
channel, the behav ior of participants is classified within five t ask roles and fi ve
social–emotional roles (Zancanaro et al., 2006). The ultimate product of this
FIGURE
12.5
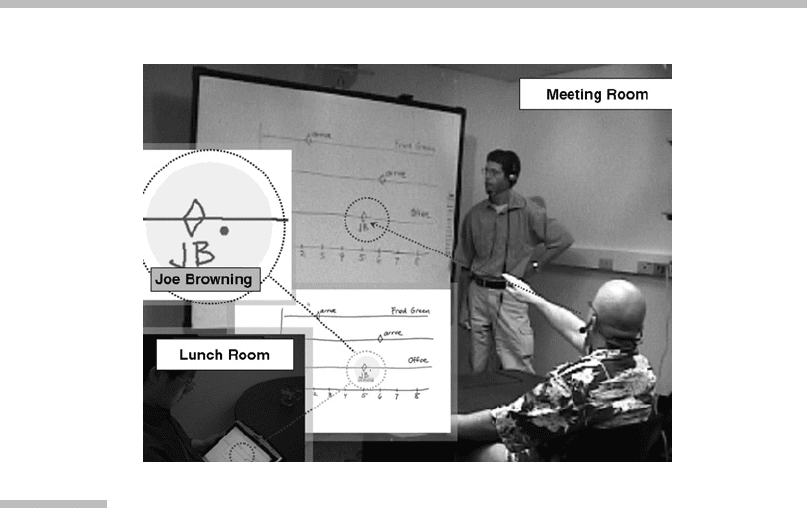
A group of colocated and remote participants (
inset
) using Charter to define a
project schedule.
Sketches over a shared space are propagated to remote users, who can add their
contribution. Charter monitors this interaction and produces an MS-Project chart
at the end of the meeting.
12 Multimodal Interfaces: Combining Interfaces
402

system is a semiautomated “coach” that presents to part icipants episodes of the
meeting during which dysfunctional behavior is detected (e. g., dominant or
aggressive behavior), wit h the goal of improving meeting participation behavior
over time by allowing participants to reflect upon their own actions.
Other work looks into the role of speech amplitude, lexical content, and gaze
to automatically detect who the intended addressee is in interactions involv-
ing groups of people and computational assistants (Jovanovic, op den Akker, &
Nijholt, 2006; Katzenmaier, Stiefelhagen, & Schultz, 2004; Lunsford, Oviatt, &
Arthur, 2006; Lunsford, Oviatt, & Coulston, 2005; van Turnhout et al., 2005).
Speech amplitude is found to be a strong indicator of who participants intend to
address in situations in which a computational assistant is available (Lunsford
et al., 2005, 2006). Directives intended to be handled by the computer are deliv-
ered with amplitude significantly higher than speech directed to human peers,
as indicated by studies of users engaged in an educational-problem–solving task.
Leveraging such a technique, a system is able to automatically determine whether
specific spoken utterances should be interpreted as commands requiring a
response from the system, separating these from the remaining conversation
intended to be responded to by human peers. This open-microphone engagement
problem is one of the more challenging but fundamental issues remaining to be
solved by new multimodal collaborative systems.
12.2.2 Concepts and Mechanisms
A primary technical concern when designing a multimodal system is the definition
of the mechanism used to combine—or
fuse
—input related to multiple modalities
so that a coherent combined interpretation can be achieved. Systems such as
Bolt’s (1980) “Put that there” and other early systems mainly processed speech,
and used gestures just to resolve
x
,
y
coordinates of pointing events. Systems that
handle modalities such as speech and pen, each of which is able to provide seman-
tically rich information, or speech and lip movements, which are tightly correlated,
require considerably more elaborate fusion mechanisms. These mechanisms
include representation formalisms, fusion algorithms, and entirely new software
architectures.
Multimodal fusion emerges from the need to deal with multiple modalities not
only as independent input alternatives, but as also able to contribute parts or elements
of expressions that only make sense when interpreted synergistically (Nigay &
Coutaz, 1993). When a user traces a line using a pen while speaking “Evacuation
route,” a multimodal system is required to somehow compose the attributes of the
spatial component given via the pen with the meaning assigned to this line via
speech.
A well-designed multimodal system offers, to the extent possible, the capabil-
ity for commands to be expressible through a single modality. Users should be
able to specify meanings using only the pen or using just speech. It must be noted,
12.2 Technology of the Interface
403

though, that specifying spatial information via speech is not preferred by users in
general (Oviatt, 1997; Oviatt & Olsen, 1994; Suhm, 1998). It may be required in
situations in which users are constrained to using speech (e.g., while driving).
Early and Late Fusion
In order to be able to integrate interpretations generated by multiple disparate
unimodal recognizers, these interpretations need to be represented in a common
semantic representation formalism. A multimodal integration element then ana-
lyzes these uniform semantic representations and decides how to interpret them.
In particular, it decides whether to fuse multiple individual elements, for example
a spoken utterance and some pointing gestures or handwriting, or whether such
input should be considered to represent individual commands that should not
be composed into a combined interpretation. In the former case, we say that a
multimodal
interpretation was applied, and in the latter that the interpretation
was
unimodal
.
Two strategies that have been explored to deal with the combination of mod-
alities are late, or
feature fusion
, and early, or
semantic fusion
.
Early-fusion techniques are usually employed when modalities are tightly
coupled, as is the case for instance for speech and lip movements. Early fusion
is achieved by training a single recognizer over a combination of features provided
by each of the modalities. Such features may be composed from some representa-
tion of phonemes from a speech modality and
visemes
characterizing lip move-
ments provided by a visual modality. The advantage of early fusion is that
parallel input from each modality is used concurrently to weight interpretation
hypotheses as the recognition takes place. This results in many cases in enhanced
recognition accuracy, even when one of the signals is compromised (e.g., speech
in noisy environments) (Dupont & Luettin, 2000; Meier et al., 1996; Potamianos
et al., 2004; Rogozan & Dele
´
glise, 1998; Sumby & Pollack, 1954; Vergo, 1998).
Late- or semantic-fusion techniques employ multiple independent recogni-
zers (at least one per modality). A sequential integration process is applied over
the recognition hypotheses generated by these multiple recognizers to achieve a
combined multimodal interpretation. Late fusion is usually employed when two
or more semantically rich modalities such as speech and pen are incorporated.
This approach works well in such cases because each recognizer can be
trained independently over large amounts of unimodal data, which is usually
more readily available, rather than relying on typically much smaller multimodal
corpora (sets of data). Given the differences in information content and time scale
characteristics of noncoupled modalities, the amount of training data required to
account for the wide variety of combinations users might employ would be prohi-
bitively large. A system would for instance need to be trained by a large number of
possible variations in which pen and speech could be used to express every single
command accepted by a system. Given individual differences in style and use
12 Multimodal Interfaces: Combining Interfaces
404

conditions, the number of alternatives is potentially very large, particularly for
systems supporting expressive modalities such as pen and speech.
By employing independent unimodal recognizers, systems that adopt a late-
fusion approach are able to use off-the-shelf recognizers. That makes it possible
for late-fusion systems to be more easily scaled and adapted as individual recogni-
zers are replaced by newer, enhanced ones. In the rest of this discussion, we
concentrate primarily on late-fusion mechanisms.
12.2.3 Information Flow
In general terms, in a multimodal system multiple recognizers process input gen-
erated by sensors such as microphones, instrumented writing surfaces and pens,
and vision-based trackers (Figure 12.6). These recognizers produce interpretation
hypotheses about their respective input.
Temporal Constraints
Temporal constraints play an important role is deciding whether multiple uni-
modal elements are to be integrated or not (Bellik, 1997; Johnston & Bangalore,
2005; Oviatt, DeAngeli, & Kuhn, 1997). In most systems, a
fixed temporal thresh-
old
determines, for instance, whether a spoken utterance is to be fused with pen
gestures, or whether multiple pen gestures should be fused together. In general,
if input from different modalities has been produced within two to four seconds
of each other, integration is attempted. In practical terms, that means that sys-
tems will wait this much time for users to provide additional input that might be
potentially used in combination with a preceding input.
While this approach has been successfully used in systems such as Quickset
(Cohen et al., 1997) and MATCH (Johnston & Bangalore, 2005), its use introduces
delays in processing user commands that equal the chosen threshold. More
recently, learning-based models have been developed that adapt to user-specific
thresholds (Huang & Oviatt, 2005). By employing user-specific models that take
into account the empirical evidence of multimodal production, system delays
are shown to be reduced 40 to 50 percent (Gupta & Anastasakos, 2004; Huang,
Oviatt, & Lunsford, 2006).
Response Planning
In general, a multimodal integration element produces a potentially large number
of interpretations, some of which may be multimodal and others may be unimo-
dal. The most likely interpretation hypothesis is then chosen as the current input
interpretation, and the other less likely ones are removed from consideration.
This choice is sometimes influenced by a
dialog manager
, which may exploit
additional contextual information to select the most appropriate interpretation
(Johnston & Bangalore, 2005; Wahlster, 2006).
12.2 Technology of the Interface
405
Once an interpretation is chosen, a system response may be generated.
Response planning depends very heavily on the specifics of each system and its
domain and intended functionality. A response may consist of multimodal/multime-
dia display during which users are presented with graphical and audio/spoken out-
put on a computer or within a virtual-reality environment, sometimes embodied as
an animated character (Cassell et al., 2000; Nijholt, 2006). Other responses may
include interacting with another application, such as updating a military planning
information system or driving simulation (Cohen & McGee, 2004; Johnston et al.,
1997), updating an MS-Project schedule (Kaiser et al., 2004), or supporting remote
collaboration (Barthelmess et al., 2005).
A considerable amount of work on planning and presentation has been pur-
sued by systems and frameworks such as MAGIC (Dalal et al., 1996), WIP (Wahlster
et al., 1993), PPP (Andre, Muller, & Rist, 1996), and SmartKom (Wahlster, 2006).
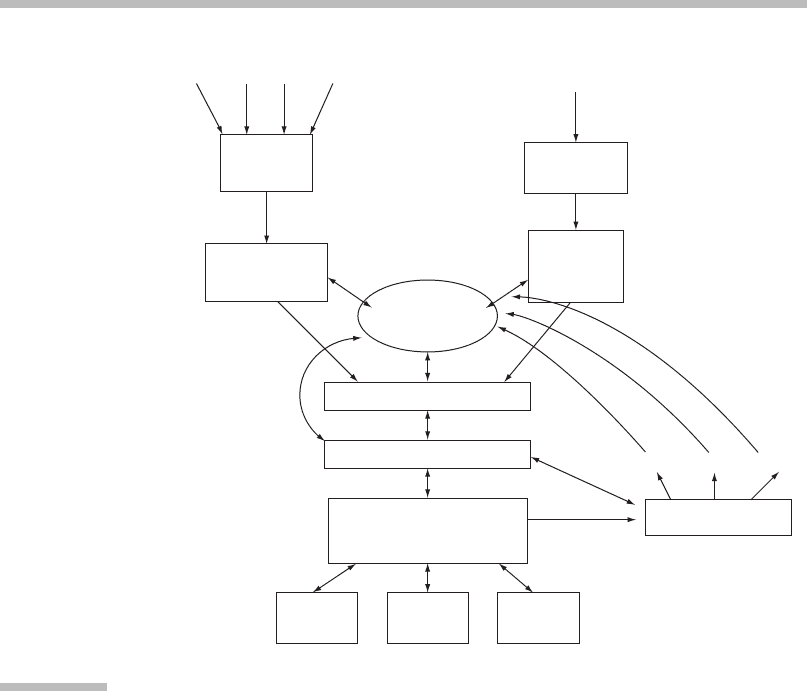
Feature/frame
structures
Feature/frame structures
Gesture
Understanding
Gesture
Recognition
Multimodal Integration
Dialog Manager
App1 App2 App3
Response Planning
Graphics VR TTS
Application Invocation
and Coordination
Feature/frame structures
Context
Management
Pen Glove Laser Touch
Microphone
Speech
Recognition
Natural-
Language
Processing
FIGURE
12.6
Generic conceptual architecture of a multimodal system.
Multiple recognizers are used for gesture and speech input.
Source:
From Oviatt
et al. (2000).
12 Multimodal Interfaces: Combining Interfaces
406

12.3
CURRENT IMPLEMENTATIONS
OF THE INTERFACE
Even though few commercial multimodal applications are available, multimodal-
ity has been explored in a variety of different areas and formats, including
information kiosks, mobile applications, and ultramobile applications based on
digital-paper technology. Multimodal interfaces have also been used to promote
accessibility. This section examines some representative examples of interfaces
in each of these areas and form factors.
12.3.1 Information Kiosks
Kiosks providing a variety of services, such as tourist and museum information,
banking, airport checking, and automated check-out in retail stores, are becoming
more prevalent. The majority of these devices use touch and keypad as data entry
mechanisms, producing responses via graphical displays and sometimes speech
and audio. Given the requirements for robustness and space constraints, key-
boards and mice are not usually available (Johnston & Bangalore, 2004). Multi-
modal interfaces provide additional means of interaction that do not require
keyboard or mice as well, and may therefore provide an ideal interface option
for kiosks. In this section, some representative examples are presented.
MATCHKiosk
MATCHKiosk (Johnston & Bangalore, 2004) is a multimodal interactive city guide
for New York City and Washington, DC, providing restaurant and subway/metro
information. The kiosk implementation is based on the mobile MATCH multimodal
system (Johnston et al., 2002).
This interactive guide allows users to interact via speech, pen, and touch.
Responses are also multimodal, presenting synchronized synthetic speech, a life-
like virtual agent, and dynamically generated graphics (Figure 12.7). The system
helps users find restaurants based on location, price, and type of food served.
A user may ask for information using speech, as in “Find me moderately priced
Italian restaurants in Alexandria.” The same query can be expressed multimod-
ally, for instance by speaking “Moderate Italian restaurants in this area <circle
area on the map>,” or by using just the pen, for instance by circling an area in
the map and handwriting “Cheap Italian.” It also provides subway directions
between locations, for instance, when a user asks, “How do I get from here <point
to map location> to here? <point to map location>,” or just circles a region with
the pen and handwrites “Route.”
System output combines synthetic speech synchronized with the animated
character’s actions and coordinated with graphical presentations. The latter may
12.3 Current Implementations of the Interface
407

consist of automatic panning and zooming of the map portion of the display, such
as showing route segments.
A variety of mechanisms are implemented to let users fine-tune their queries
and correct misrecognitions. An integrated help mechanism is also available, and
is automatically activated when repeated input failures are detected.
SmartKom-Public
SmartKom is a flexible platform that includes facilities for handling multi-
modal input and output generation (Wahlster, 2006). SmartKom-Public is a kiosk
instantiation (Figure 12.8) of the architecture (Horndasch, Rapp, & Rottger, 2006;
Reithinger et al., 2003; Reithinger & Herzog, 2006). This kiosk, mounted inside a
telephone booth, provides gesture and facial recognition via cameras, microphone,
graphical display, and audio output.
The kiosk provides information about movies in the city of Heidelberg,
Germany, as well as communication facilities, such as document transmission.
This discussion will focus on the movie information functionality. A user may initi-
ate a dialog with the system by speaking, “What’s playing at the cinemas tonight?”
The system responds by showing a listing of movies, as well as a map displaying
the locations of the theaters (Figure 12.9 on page 410). An animated character—
Smartakus—provides spoken information such as “These are the movies playing
tonight. The cinemas are marked on the map.” Users can then ask for specific infor-
mation multimodally—“Give me information about this one <point to the display>
for example”—causing the system to display the text showing details
(a) (b)
FIGURE
12.7
MATCHKiosk.
(a) Hardware. (b) User interface.
Source:
From Johnston and Bangalore (2004).
(Courtesy Association of Computational Linguistics.)
12 Multimodal Interfaces: Combining Interfaces
408

of the selected movie. The system also provides ticket reservations, supported
by dialogs in which users may choose seats. Finally, the system is able to pro-
vide information about how to get to a specific location, such as a particular
movie theater.
12.3.2 Mobile Applications
Multimodal interfaces provide a natural way to overcome the intrinsic limitations
of displays (usually small) and input mechanisms of mobile devices. The ability to
use speech or pen is also important in accommodating the variety of mobile use
contexts. Speech can be used, for instance, while walking or driving; a pen interface
FIGURE
12.8
SmartKom-Public.
This platform is a kiosk instantiation mounted in a telephone booth. From
http://www.
smartkom.org/eng/project_en_frames.pl?public_en.html
. (Courtesy German Research
Center for Artificial Intelligence GmbHo.)
12.3 Current Implementations of the Interface
409

may provide the privacy required in public settings in which speech is not appro-
priate. The challenge in developing mobile multimodal interfaces is in building
systems that are compatible with the low-powered processing units found in most
mobile devices. The following two interfaces illustrate the characteristics and
approaches used by mobile multimodal systems.
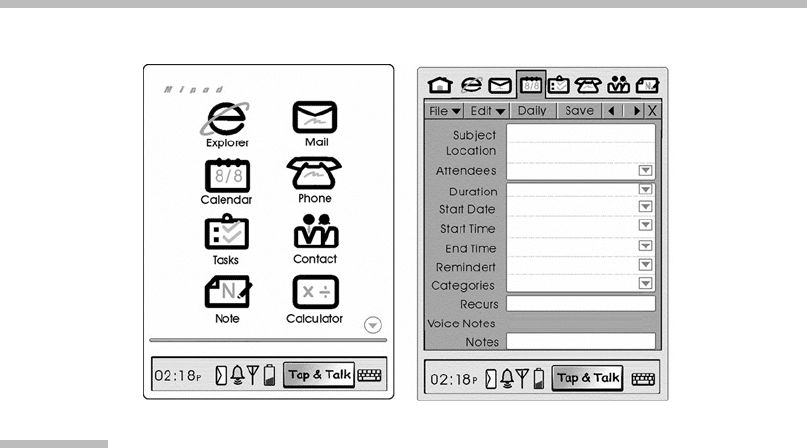
Microsoft MiPad
Microsoft developed a multimodal mobile application—MiPad (Multimodal Inter-
active Notepad,
http://research.microsoft.com/srg/mipad.aspx
) (Deng et al.,
2002; Huang et al., 2001)—that demonstrates pen and speech input on a portable
digital assistant (PDA). Pen input is used to select icons and to activate voice
recognition via a “tap-to-talk” software button (Figure 12.10).
The system interprets spoken commands, and is able to initiate e-mail, set up
appointments, and manage contact lists. Using this system, users are able to say,
for example, “Send mail to Nicky,” causing the system to open up an e-mail dialog
with the recipient already filled out (K. Wang, 2004). The user can then dictate the
content of the message. Users can also tap with the stylus on a form field, such as
the “To” field of an e-mail. This provides the system with contextual information
that will help the system select interpretations, as in, for example, preferring
“Helena Bayer” to “Hello there” as an interpretation when an e-mail Recipient field
FIGURE
12.9
SmartKom-Public interface.
The interface presents a listing (in German) of the locations showing
Terminator 3
.
Source:
From Reithinger and Herzog (2006); courtesy of
Springer.
12 Multimodal Interfaces: Combining Interfaces
410
is selected. Finally, correction can be performed multimodally by selecting a
misrecognized word by tapping with the stylus and then speaking it again.
Kirusa’s Multimodal Interface
Kirusa offers a platform for the development of multimodal mobile applications
intended for wireless phone providers. Its functionality is illustrated by a sports
sample application (
http://www.kirusa.com/demo3.htm
). This application pro-
vides an interface structured as menus and forms that can be activated and filled
out multimodally. Menu items can be selected by pen tap or by speech. Form
fields can be selected via taps and filled via speech; fields can also be selected
by speaking the name of the field.
Besides the structured graphical information (menus and forms) the interface
presents synthesized speech, hyperlinks, and videos. Multimodal input is demon-
strated by video control commands, such as zooming by issuing the command
“Zoom in here <tap on location>” while a video is being displayed (Figure 12.11).
12.3.3 Ultramobile Digital-Paper–Based Interfaces
Despite the widespread introduction of technology, a considerable number of
users still prefer to operate on paper-based documents. Rather than diminishing,
the worldwide consumption of paper is actually rising (Sellen & Harper, 2003).
Paper is lightweight, high definition, highly portable, and robust—paper still
“works” even after torn and punctured. Paper does not require power and is not
FIGURE
12.10
Microsoft’s MiPad.
The interface, displaying icons and a form that can be activated multimodally.
From
http://research.microsoft.com/srg/mipad.aspx.
(Courtesy Microsoft.)
12.3 Current Implementations of the Interface
411