Kortum P. (ed.) HCI Beyond the GUI. Design for Haptic, Speech, Olfactory, and Other Nontraditional Interfaces
Подождите немного. Документ загружается.


communicate. A well-designed multimodal system gives users the freedom to
choose the modality that they feel best matches the requirements of the task at
hand. Users have been shown to take advantage of multimodal system capabilities
without requiring extensive training. Given a choice, users preferred speech input
for describing objects and events and for issuing commands for actions (Cohen &
Oviatt, 1995; Oviatt & Cohen, 1991). Their preference for pen input increased when
conveying digits, symbols, graphic content, and especially when conveying the
location and form of spatially oriented information (Oviatt, 1997; Oviatt & Olsen,
1994; Suhm, 1998).
As a result of the choice of input they provide to users, multimodal systems
make computing more accessible, lowering input requirement barriers so that a
broader range of users can be accommodated (e.g., by allowing a user with a sen-
sory deficit to use the modality she is most comfortable with). As a consequence,
users become able to control a broader range of challenging, complex applications
that they might not otherwise be able to command via conventional means. These
factors lead to the strong user preference for interacting multimodally that has
been documented in the literature. When given the option to interact via speech
or via pen input in a map-based domain, 95 to 100 percent of the users chose to
interact multimodally (Oviatt, 1997). While manipulating graphic objects on a
CRT screen, 71 percent of the users preferred to combine speech and manual
gestures (Hauptmann, 1989).
Error Reduction via Mutual Disambiguation
A rich set of modalities not only provides for enhanced freedom of expression,
allowing users to choose the modalities that best fit their particular situation, but
may also lead to better recognition when compared for instance to speech-only
(a) (b)
FIGURE
12.1
Multimodal interfaces span a variety of use contexts.
(a) Mobile interface. (b) Collaborative interface.
12 Multimodal Interfaces: Combining Interfaces
392

interfaces (Oviatt, 1999a).
Mutual disambiguation
is used to refer to the positive
effect that recognition in one mode may have in enhancing recognition in another
mode. Analysis of an input in which a user may say “Place three emergency hos-
pitals here <point> here <point> and here <point>” provides a multimodal system
with multiple cues indicating, for instance, the number of objects to be placed,
as the spoken word “three” can be matched to the number of pointing gestures
that are provided via another modality (Oviatt, 1996a). Similarly, misrecognized
commands in each modality may in some cases (e.g., tutorial lectures) be corrected
by exploiting redundancy.
Empirical results demonstrate that a well-integrated multimodal system can
yield significant levels of mutual disambiguation (Cohen et al., 1989; Oviatt,
1999a, 2000). Studies found mutual disambiguation and error suppression ranging
between 19 and 41 percent (Oviatt, 1999a, 2000, 2002).
Similar robustness is found as well in systems that integrate speech and lip
movements. Improved speech recognition results can occur during multimodal
processing, both for human listeners (McLeod & Summerfield, 1987) and sys-
tems (Adjoudani & Benoit, 1995; Tomlinson, Russell, & Brooke, 1996). A similar
opportunity for disambiguation exists in multiparty settings—for instance, when
communicating partners handwrite terms on a shared space, such as a white-
board or a shared document, while also speaking these same terms. The redun-
dant delivery of terms via handwriting and speech is something that happens
commonly in lectures or similar presentation scenarios (Anderson, Anderson
et al., 2004; Anderson, Hoyer et al., 2004; Kaiser et al., 2007). By taking advantage
of redundancy when it occurs, a system may be able to recover the intended
terms even in the presence of misrecognitions affecting both modalities (Kaiser,
2006).
Performance Advantages
Empirical work has also determined that multimodal systems can offer perfor-
mance advantages (e.g., during visual-spatial tasks) when compared to speech-
only processing or conventional user interfaces. Multimodal pen and speech have
been shown to result in 10 percent faster completion time, 36 percent fewer task-
critical content errors, 50 percent fewer spontaneous disfluencies, and shorter and
simpler linguistic constructions (Oviatt, 1997; Oviatt & Kuhn, 1998). When com-
paring the performance of multimodal systems to a conventional user interface
in a military domain, experiments showed a four- to nine-fold speed improvement
over a graphical user interface for a complex military application (Cohen, McGee,
& Clow, 2000).
Multimodal systems are preferable in visual-spatial tasks primarily because
of the facilities that multimodal language provides to specify complex spatial
information such as positions, routes, and regions using pen mode, while pro-
viding additional descriptive spoken information about topic and actions (Oviatt,
1999b).
12.1 Nature of the Interface
393

12.2
TECHNOLOGY OF THE INTERFACE
Multimodal systems take advantage of recognition-based component technologies
(e.g., speech, drawing, and gesture recognizers). Advances in recognition techno-
logies make it increasingly possible to build more capable multimodal systems.
The expressive power of rich modalities such as speech and handwriting is none-
theless frequently associated with ambiguities and imprecision in the messages
(Bourguet, 2006). These ambiguities are reflected by the multiple potential inter-
pretations produced by recognizers for each input. Recognition technology has
been making steady progress, but is still considerably limited when compared to
human-level natural-language interpretation. Multimodal technology has there-
fore developed techniques to reduce the uncertainty, attempting to leverage
multimodality to produce more robust interpretations.
In the following, a historic perspective of the field is presented (Section 12.2.1).
Sections 12.2.2 and 12.2.3 then present technical concepts and mechanisms and
information flow, respectively.
12.2.1 History and Evolution
Bolt’s “Put that there” is one of the first demonstrations of multimodal user inter-
face concepts (1980). This system allowed users to create and control geometric
shapes of multiple sizes and colors, displayed over a large-format display embed-
ded in an instrumented media room (Negroponte, 1978). The novelty intro-
duced was the possibility of specifying shape characteristics via speech, while
establishing location via either speech or deictic (pointing) gestures. The position
of users’ arms was tracked using a device attached to a bracelet, displaying an
x
on the screen to mark the position of a perceived point location when a user spoke
an utterance. To create new objects, users could for instance say “Create a blue
square here” while pointing at the intended location of the new object. Such
multimodal commands were interpreted by resolving the use of “here” by
replacing it with the coordinates indicated by the pointing gesture. By speaking
“Put that there,” users could select an object by pointing, and then indicate with
an additional gesture the desired new location (Figure 12.2). This demonstration
system was made possible by the emergence of recognizers, particularly for
speech, that for the first time supported multiple-word sentence input and a
vocabulary of a few hundred words.
Early Years
Initial multimodal systems made use of keyboard and mouse as part of a traditional
graphical interface, which was augmented by speech. Spoken input provided
an alternative to typed textual input, while the mouse could be used to provide
12 Multimodal Interfaces: Combining Interfaces
394
pointing information. Examples of early systems include XTRA, a multimodal sys-
tem for completing tax forms (Allegayer et al., 1989), Voice Paint and Notebook
(Nigay & Coutaz, 1993), Georal (Siroux et al., 1995), MATIS (Nigay & Coutaz,
1995), CUBRICON (Neal & Shapiro, 1991), and ShopTalk (Cohen, 1992). Other sys-
tems of this period include Virtual World (Codella et al., 1992), Finger-Pointer
(Fukumoto, Suenaga, & Mase, 1994), VisualMan (Wang, 1995), Jeannie (Vo &
Wood, 1996), QuickTour, Jeannie II, and Quarterback (Vo, 1998), and a multimodal
window manager (Bellik & Teil, 1993).
The sophistication of the speech recognition components varied, with some
systems offering elaborate support for spoken commands. CUBRICON and Shop-
Talk allowed users to ask sophisticated questions about maps and factory pro-
duction flow, respectively. The interfaces of these systems activated extensive
domain knowledge so that users could point to a location on a map (in CUBRI-
CON) and ask “Is this an air base?” or point to a specific machine in a diagram
(in ShopTalk) and command the system to “Show all the times when this machine
was down.”
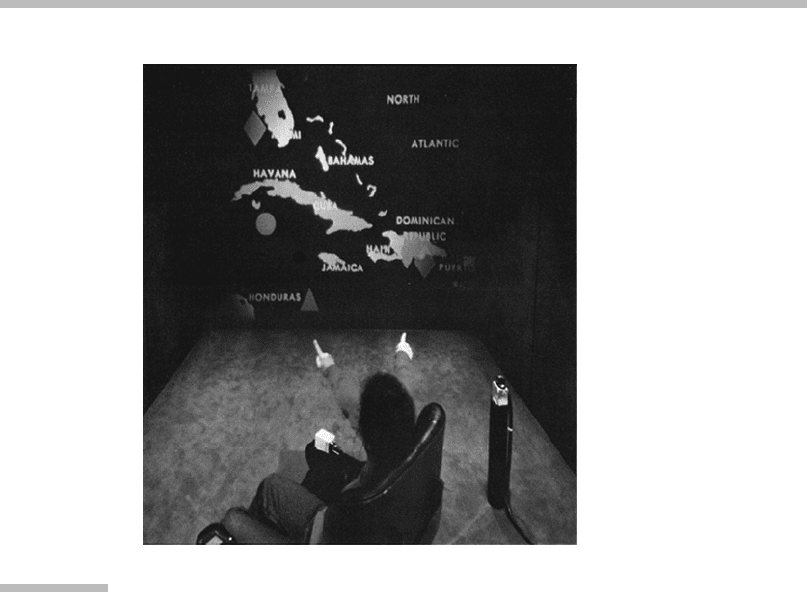
FIGURE
12.2
Bolt’s multimodal demonstrator.
A user moves an object by pointing to it and then the desired new location while
saying, “Put that there.”
Source:
From Bolt (1980). (Courtesy ACM.)
12.2 Technology of the Interface
395

Speech and Pen Systems
Systems started to move away from augmenting graphical interfaces by incorpor-
ating input with a full spoken-language system. During this time, equipment
became available to handle pen input via a stylus, providing a natural second
source of rich information that complements speech (Oviatt et al., 2000). Pen
input made it possible for users to input diagrams and handwritten symbolic
information, in addition to pointing and selection, replacing similar mouse func-
tionality. The availability of more powerful recognition components led in turn
to the development of new techniques for handling parallel, multimodal input.
Pen-based input over a tablet-like surface started to be used to provide addi-
tional commands via sketched gestures (e.g., in TAPAGE [Faure & Julia, 1994]).
Pen input then evolved to provide a second semantically rich modality, comple-
menting and reinforcing the spoken input. Handwriting recognition (e.g., in
Cheyer and Julia, 1995) and more sophisticated gesture recognition (in MVIEWS
[Cheyer & Luc, 1998] and Quickset [Cohen et al., 1997]) provided users with sig-
nificant expressive power via input that did not require the keyboard or the mouse
to be used, providing instead a flexible, truly multimodal alternative input via
speech and pen.
Empirical work in the early 1990s (Oviatt et al., 1992) laid the foundation for
more advanced speech and pen systems such as Quickset (Figure 12.3). Quickset
provides a generic multimodal framework that is still currently used (e.g., by
Charter [Kaiser et al., 2004], a system for collaborative construction of project
schedules). One of the initial Quickset applications was a map-based military
system (which evolved into a commercial application, NISMap [Cohen & McGee,
2004]) (see Section 12.3.3). Using this system, military commanders can enter
battle plan fragments using multimodal language (Figure 12.3). More specifically,
FIGURE
12.3
Quickset/NISMap interface on a Tablet PC.
The keyboard and mouse are replaced by pen and speech input. Sketches
and handwriting on a map are fused with spoken input.
12 Multimodal Interfaces: Combining Interfaces
396

users of the system can draw standard military symbols comprising sketched
and handwritten elements, complemented by speech. For example, a commander
can establish the position of a fortified line by sketching the line on a map and
speaking “Fortified line.”
MVIEWS (Cheyer & Luc, 1998) demonstrated multimodal functionality related
to video analysis activities for military intelligence purposes. MVIEWS integrated
audio annotations of video streams, allowing users to mark and describe specific
targets of interest. By circling an object on a video frame using a stylus, the system
could be commanded via speech to track the object in subsequent frames. Users
could also request to be notified whenever an object selected via a stylus moved,
or whenever activity within a region was detected (e.g., by speaking “If more than
three objects enter this region, alert me.”).
Other systems of the same generation include IBM’s Human-centric Word
Processor (Oviatt et al., 2000), Boeing’s Virtual Reality (VR) Aircraft Maintenance
Training (Duncan et al., 1999), Field Medic Information System (Oviatt et al.,
2000), and the Portable Voice Assistant (Bers, Miller, & Makhoul, 1998).
The Human-centric Word Processor provides multimodal capabilities for dic-
tation correction. Users can use a pen to mark a segment of text, issuing spoken
commands such as “Underline from here to here <draw line>,” or “Move this sen-
tence <point to sentence> here <point to new location> (Oviatt et al., 2000). The
Field Medic Information System is a mobile system for use in the field by medics
attending to emergencies. Two components are provided—one allowing spoken
input to be used to fill out a patient’s record form, and a second multimodal
unit—the FMA—that lets medics enter information using speech or alternatively
handwriting to perform annotations of a human body diagram (e.g., to indicate
position and nature of injuries). The FMA can also receive data from physiological
sensors via a wireless network. Finally, the patient report can be relayed to a
hospital via a cellular, radio, or satellite link.
More recently, tangible multimodal interfaces have been explored in Rasa
(Cohen & McGee, 2004; McGee & Cohen, 2001). Rasa is a tangible augmented-
reality system that enhances existing paper-based command and control capabil-
ities in a military command post (McGee & Cohen, 2001). Rasa interprets and
integrates inputs provided via speech, pen, and touch. The system reacts by project-
ing information over a paper map mounted on a board, producing spoken prompts,
and inserting and updating elements in a database and military simulators.
Rasa does not require users to change their work practices—it operates by
transparently monitoring users’ actions as they follow their usual routines. Offi-
cers in command posts operate by updating information on a shared map by cre-
ating, placing, and moving sticky notes (Post-its) annotated with military symbols.
A sticky note may represent a squad of an opposing force, represented via stan-
dardized sketched notation (Figure 12.4). As users speak among themselves
while performing updates, sketching on the map and on the sticky notes placed
on the map, Rasa observes and interprets these actions. The map is affixed to a
12.2 Technology of the Interface
397

touch-sensitive surface (a SmartBoard), so that when sticky notes are placed on it,
the system is able to sense the location.
The attributes of introduced entities are integrated by fusing the location
information with the type information provided via the sticky note sketch.
A sketch representing an enemy company may be integrated with a spoken utter-
ance such as “Advanced guard,” identifying type, location, and identity of a unit.
Rasa confirms the interpretation via a spoken prompt of the kind “Confirm:
Enemy reconnaissance company called ‘advanced guard’ has been sighted at
nine-six nine-four.” Users can cancel this interpretation or confirm it either explic-
itly or implicitly, by continuing to place or move another unit.
Speech and Lip Movements
A considerable amount of work has been invested as well in examining the fusion of
speech and lip movements (Benoit & Le Goff, 1998; Bernstein & Benoit, 1996; Cohen
& Massaro, 1993; Massaro & Stork, 1998; McGrath & Summerfield, 1985; McGurk &
MacDonald, 1976; McLeod & Summerfield, 1987; Robert-Ribes et al., 1998; Sumby &
Pollack, 1954; Summerfield, 1992; Vatikiotis-Bateson et al., 1996). These two mo-
dalities are more tightly coupled than speech and pen input or gestures. Systems
that process these two highly correlated modalities strive to achieve more robust
recognition of speech phonemes based on the evidence provided by
visemes
during
physical lip movement, particularly in challenging situations such as noisy environ-
ments (Dupont & Luettin, 2000; Meier, Hu
¨
rst, & Duchnowski, 1996; Potamianos
et al., 2004; Rogozan & Dele
´
glise, 1998; Sumby & Pollack, 1954; Vergo, 1998).
FIGURE
12.4
Users collaborating with Rasa.
Sketches on sticky notes represent military units, placed on specific locations on
a map.
Source:
From McGee and Cohen (2001). (Courtesy ACM.)
12 Multimodal Interfaces: Combining Interfaces
398

Comprehensive reviews of work in this area can be found elsewhere (Benoit et al.,
2000; Potamianos et al., 2004).
Multimodal Presentation
The planning and presentation of multimodal output, sometimes called
multi-
modal fission
, employs audio and graphical elements to deliver system responses
across multiple modalities in a synergistic way. Some of the systems and frame-
works exploring multimodal presentation and fission are MAGIC (Dalal et al.,
1996), which employs speech and a graphical display to provide information on
a patient’s condition; WIP (Wahlster et al., 1993); and PPP (Andre, Muller, & Rist,
1996). SmartKom (Wahlster, 2006) is an encompassing multimodal architecture
that includes facilities for multimodal fission as well.
Multimodal presentation sometimes makes use of animated characters that
may speak, gesture, and display facial expressions. The study of the correlation
of speech and lip movements discussed in the previous section is also relevant
in informing the construction of realistic animated characters able to synchronize
their lip movements with speech (Cohen & Massaro, 1993). Further work on ani-
mated characters has explored ways to generate output in which characters are
able to gesticulate and use facial expressions in a natural way, providing for rich
multimodal output (Nijholt, 2006; Oviatt & Adams, 2000). For overviews of the
area, see, for example, Andre
´
(2003) and Stock and Zancanaro (2005).
Vision-Based Modalities and Passive Interfaces
Facial expressions, gaze, head nodding, and gesturing have been progressively
incorporated into multimodal systems (Flanagan & Huang, 2003; Koons, Sparrell,
& Thorisson, 1993; Lucente, Zwart, & George, 1998; Morency et al., 2005;
Morimoto et al., 1999; Pavlovic, Berry, & Huang, 1997; Turk & Robertson, 2000;
Wang & Demirdjian, 2005; Zhai, Morimoto, & Ihde, 1999). Poppe (2007) presents
a recent overview of the area.
Further incorporation of modalities is expected as vision-based tracking and
recognition techniques mature. Of particular interest are the possibilities that
vision-based techniques introduce a means for systems to unobtrusively collect
information by passively monitoring user behavior without requiring explicit user
engagement in issuing commands (Oviatt, 2006b). Systems can then take advan-
tage of the interpretation of natural user behavior to automatically infer user state,
to help disambiguate user intentions (e.g., by using evidence from natural gaze to
refine pointing hypotheses), and so forth.
Eventually, it is expected that systems may take advantage of the information
provided by multiple sensors to automatically provide assistance without requir-
ing explicit user activation of interface functions. The ability to passively observe
and analyze user behavior and proactively react (e.g., Danninger et al., 2005;
Oliver & Horvitz, 2004) are of special interest for groups of users that may be
collaborating, as elaborated in the next subsection.
12.2 Technology of the Interface
399

Collaborative Multimodal Systems
Recently, considerable attention has been given to systems that interpret the com-
munication taking place among humans in multiparty collaborative scenarios,
such as meetings. Such communication is naturally multimodal—people employ
speech, gestures, and facial expressions, take notes, and sketch ideas in the course
of group discussions.
A new breed of research systems such as Rasa (McGee & Cohen, 2001), Neem
(Barthelmess & Ellis, 2005; Ellis & Barthelmess, 2003), and others (Falcon et al.,
2005; Pianesi et al., 2006; Rienks, Nijholt, & Barthelmess, 2006; Zancanaro, Lepri,
& Pianesi, 2006) have been exploiting multimodal collaborative scenarios, aiming
at providing assistance in ways that leverage group communication and attempt to
avoid adversely impacting performance.
Processing unconstrained communication among human actors introduces
a variety of technical challenges. Conversational speech over an open microphone
is considerably harder to recognize than more constrained speech directed to a
computer (Oviatt, Cohen, & Wang, 1994). The interpretation of other modalities
is similarly more complex. Shared context that may not be directly accessible to
a system is relied on very heavily by communicating partners (Barthelmess,
McGee, & Cohen, 2006; McGee, Pavel, & Cohen, 2001).
Devising ways to extract high-value items from within the complex group
communication streams constitutes a primary challenge for collaborative multi-
modal systems. Whereas in a single-user multimodal interface, a high degree of
control over the language employed can be exerted, either directly or indirectly,
systems dealing with group communication need to be able to extract the informa-
tion they require from natural group discourse, a much harder proposition.
Collaborative systems are furthermore characterized by their vulnerability to
changes in work practices, which often result from the introduction of technology
(Grudin, 1988). As a consequence, interruptions by a system looking for explicit
confirmation of potentially erroneous interpretations may prove too disruptive.
This in turn requires the development of new approaches to system support that
are robust to misrecognitions and do not interfere with the natural flow of group
interactions (Kaiser & Barthelmess, 2006).
Automatic extraction of meeting information to generate rich transcripts
has been one of the focus areas in multimodal meeting analysis research. These tran-
scripts may include video, audio, and notes processed by analysis components
that produce transcripts (e.g., from speech) and provide some degree of semantic
analysis of the interaction. This analysis may detect who spoke when (which is some-
times called “speaker diarization”) (Van Leeuwen & Huijbregts, 2006), what topics
were discussed (Purver et al., 2006), the structure of the argumentation (Verbree,
Rienks, & Heylen, 2006b), roles played by the participants (Banerjee & Rudnicky,
2004), action items that were established (Purver, Ehlen, & Niekrasz, 2006), structure
of the dialog (Verbree, Rienks, & Heylen, 2006a), and high-level turns of a meeting
12 Multimodal Interfaces: Combining Interfaces
400

(McCowan et al., 2005). This information is then made available for inspection via
meeting browsers (Ehlen, Purver, & Niekrasz, 2007; Nijholt et al., 2006). Some of this
work still relies primarily on the analysis of speech signals, although some additional
work focuses on incorporation of additional modalities.
Multimodal collaborative systems have been implemented to monitor users’
actions as they plan a schedule (Barthelmess et al., 2005; Kaiser et al., 2004). Other
systems observe people discussing photos and automatically extract from multi-
modal language key terms (tags) useful for organization and retrieval (Barthelmess
et al., 2006). Pianesi and colleagues (2006) and Zancanaro and coworkers (2006)
have proposed systems that analyze collaborative behavior as a group discusses
how to survive in a disaster scenario. These systems passively monitor group inter-
actions, analyze speech, handwriting, and body movements, and provide results
after the observed meetings have concluded.
The Charter system (Kaiser et al., 2004, 2005), derived from the Quickset sys-
tem (Cohen et al., 1997), observes user actions while building a Gantt chart. This
diagram, a standard representation of schedules, is based on placing lines, repre-
senting tasks, and milestones, represented by diamond shapes, within a temporal
grid. Users build a chart by sketching it on an instrumented whiteboard or a
Tablet PC (Figure 12.5). Sketch recognition identifies the graphical symbols.
A multimodal approach to label recovery (Kaiser, 2006) matches handwritten labels
to the redundant speech in the temporal vicinity of the handwriting, as users say,
for instance, “The prototype needs to be ready by the third week <write prototype
next to milestone symbol>.” The mutual disambiguation provided by this redun-
dant speech and handwriting accounts for up to 28 percent improvement in label
recognition in test cases (Kaiser et al., 2007). Once the meeting is over, the system
automatically produces a MS-Project rendition of the sketched chart.
The Charter system has been more recently extended to support remote col-
laboration by letting users who are not colocated visualize sketches made at
a remote site and contribute elements to the shared Gantt chart, by using a stylus
on a Tablet PC or sheets of digital paper (Barthelmess et al., 2005). The support for
remote collaboration also incorporates a stereo vision–based gesture recognizer—
MIT’s VTracker (Demirdjian, Ko, & Darrell, 2003). This recognizer identifies nat-
ural gestures made toward the whiteboard on which the Gantt chart is sketched,
and automatically propagates the gesture as a halo so that remote participants
become aware of pointing performed at remote sites.
The multimodal photo annotator described by Barthelmess, Kaiser, and col-
leagues (2006) exploits social situations in which groups of people get together
to discuss photos to automatically extract tags from the multimodal communica-
tion taking place among group members. These tags are representative terms that
are used to identify the semantic content of the photos. Tags can be used to per-
form clustering or to facilitate future retrieval. By leveraging the redundancy
between handwritten and spoken labels, the system is able to automatically
extract some of these meaningful retrieval terms (Kaiser, 2006; Kaiser et al., 2007).
12.2 Technology of the Interface
401