Королёв А.И. Коды и устройства помехоустойчивого кодирования
Подождите немного. Документ загружается.

Из данной матрицы видно, что столбцы матрицы представляют собой
последовательность чисел, записанных в двоичной системе счисления; младшие
разряды (символы) внизу. Следовательно, строки матрицы G
1
(x) можно
рассматривать как последовательности состояний двоичного суммирующего
счетчика, что условно можно представить так:
,
S
.
.
.
S
1
G(x)
δm
δ1
=
где 1 - последовательность из одних 1,
S
δ1
- последовательность состояний последнего (старшего) разряда
счетчика,
S
δm
- последовательность состояний первого (младшего) разряда
счетчика.
Примечание: перестановка столбцов и строк порождающей матрицы
приводит к эквивалентным кодам. Строки в порождающих матрицах линейно
независимы. Поскольку матрица G
1
(x) имеет четыре строки, то матрица G
2
(x)
будет иметь
6C
2
m
4
2
==
cтрок, которые получаются путем покомпонентного
(поэлементного) перемножения строк матрицы G
1
(x):
.
aa
aa
aa
aa
aa
aa
0100010001000100
0001010000010100
0000110000001100
0101010000000001
1100110000000000
0011110000000000
(x)G
43
42
32
41
31
21
2
⋅
⋅
⋅
⋅
⋅
⋅
=
=
Матрица G
3
(x) будет иметь
4
4
3
==
C
m
E
строки, которые также
формируются перемножением соответствующих строк G
1
(x):
.
aaa
aaa
aaa
aaa
0000010000000100
0100010000000000
0001010000000000
0000110000000000
(x)G
432
431
421
321
3
⋅⋅
⋅⋅
⋅⋅
⋅⋅
=
=
Таким образом, порождающая матрица КРМ с E=3 и n=2
m
=2
4
=16 является рангом
(15
×
16) и вида:
.
(x)G
(x)G
(x)G
(x)G
G(x)
3
2
1
0
=
Данная матрица задает (n, k)=(16, 15) - код над полем Галуа GF(2);
практически это код с проверкой на четность.
Если же принять E=2 и m=4, то можно построить КРМ второго порядка с
порождающей матрицей вида:
,
2
1
0
(x)G
(x)G
(x)G
G(x)
=
которая задает код с параметрами (n, k)=(16,11) над двоичном поле Галуа GF(2);
практически это расширенный код Хэмминга с параметрами (n, k)=(15,11).
При E=1 и m=4 можно построить КРМ первого порядка с порождающей
матрицей вида:
,
1
0
(x)G
(x)G
G(x)
=
которая задает код с параметрами: n=2
m
=2
4
=16 двоичных символов ,

5
1
m
1k =
+=
,
11
5
16
k
n
l
=
−
=
−
=
, 822d
14Em
0
=
=
=
−−
,т.е.(n,k,d
0
)=(16,5,8)- код.
Таким образом, КРМ E-го порядка получается пополнением или
расширением КРМ (E-1) - го порядка, а КРМ (E-1) - го порядка получается из
кода E - го порядка путем выбрасывания символов. Так как КРМ E - го порядка
содержит КРМ (E-1) - го порядка, то его минимальное кодовое расстояние d
0
не
может быть больше d
0
КРМ (E-1) - го порядка и как отмечалось выше КРМ E-го
порядка имеет d
0
=2
m-E
Доказательство этого положения состоит в следующем.
Каждая строка матрицы G
l
(x) имеет четный вес, а сумма двух двоичных кодовых
последовательностей (кодовых векторов) четного веса также имеет четный вес. В
этом случае, все линейные комбинации строк матрицы G(x) имеют четный вес,
а это значит, что все кодовые последовательности имеют четный вес. Матрица
G
E
(x) содержит строки весом
Em
E
w
−
=2 и следовательно, минимальный вес
кода не превышает 2
m-E
, т.е.
Em
w
−
≤
2
min
.
КРМ E-го порядка позволяют исправлять 12
2
1
1
−⋅≤
−−Em
исп
t ошибочных
символов и восстанавливать k информационных символов. Данную
корректирующую способность обеспечивает алгоритм декодирования КРМ,
предложенный Ридом [3,4]. Алгоритм Рида отличается от большинства
алгоритмов декодирования тем, что позволяет восстановить информационные
символы прямо из принятой кодовой последовательности. В этом алгоритме
декодирования не дается точного значения самой ошибки и не используются
промежуточные переменные, например, синдром. Сущность алгоритм
декодирования Рида состоит в следующем:
предположим, что имеется декодер для КРМ (E-1)-го порядка,
исправляющего
12
2
1
1
−⋅≤
−−Em
исп
t
ошибочных информационных символов;
требуется разработать декодер для КРМ E-го порядка, исправляющего
12
2
1
1
−⋅≤
−−Em
исп
t ошибочных символов, сведя этот случай к предыдущему;
так как КРМ нулевого порядка может быть декодирован с использованием
мажоритарного алгоритма декодирования, то данный алгоритм декодирования
может быть применен к КРМ более высоких порядков.
Для реализации алгоритма декодирования кодирование информации КРМ
производиться следующим способом:
-передаваемый информационный блок разбивается на (E+1) сегментов,
положив
[
]
E10
,...II,I
=
i , где сегмент I
i
содержит
i
m
информационных символов,
-каждый информационный сегмент умножается на один блок матрицы G(x).
Кодирование можно представить поблочным умножением вектора - строки на
матрицу:
[ ]
G(x)
(x)G
.
.
.
(x)G
.
.
.
(x)G
(x)G
,...II,IF(x)
E
l
1
0
E10
⋅=
⋅= i
(5.21)
-предположим, что информационная последовательность разбита на сегменты
следующим образом: каждому информационному сегменту соответствует один из
E блоков порождающей матрицы G(x), который при кодировании умножается на
этот сегмент (или наоборот - сегмент на блок).
После принятия кодовой последовательности F'(x) декодер пытается
восстановить информационные символы в E-м сегменте и после этого определяет
вклад этих символов в принятую кодовую последовательность и вычесть его из
принятой последовательности; далее задача декодирования уже сводится к
декодированию КРМ (E-1)-го порядка. Таким образом, алгоритм декодирования

КРМ E-го порядка представляет собой последовательность мажоритарных
алгоритмов декодирования и начинается декодирование с нахождения
информационных символов в E-м сегменте.
Представим принятую кодовую последовательность F
'
(x) в следующем виде
(x),G(x)(x)F
'
li ⊕⋅=
где
)(
x
l
- помеха. Дaлее декодер восстанавливает
информационный сегмент
E
I
, а затем вычисляет разность
[ ]
(x),
(x)G
.
.
.
(x)G
.
.
.
(x)G
(x)G
I,...,I,I(x)GI(x)F(x)F
1E
l
1
1
1E10EE
'''
l⊕
⋅=⋅−=
−
−
(5.22)
которая является искаженной кодовой последовательностью КРМ (E-1) - го
порядка.
Рассмотрим декодирование информационного символа i
k-1
, т.е. (k-1) - го
символа, который умножается на последнюю строку матрицы G
E
(x).
Декодируется этот символ путем вычисления
Em
−
2
проверочных уравнений
(проверочных сумм) по
E
2
символов из
m
2
символов принятой кодовой
последовательности, так что каждый принятый символ входит только лишь в одно
проверочное уравнение (формируется система
Em
−
2
раздельных проверок), а
декодируемый информационный символ i
k-1
входит во все проверки. При
отсутствии ошибок все проверки дают значение информационного символа i
k-1
,
но даже, если имеется не более )12
2
1
( −⋅
−Em
ошибок более половины проверок
будут правильно давать значение информационного символа i
k
-1
.

Формирование проверок (проверочных сумм) выполняется по следующему
правилу:
первая проверка есть сумма по модулю два первых двух символов
принятой кодовой последовательности;
вторая проверка есть сумма по модулю два вторых
E
2
символов принятой
кодовой последовательности и т.д.
Всего формируется
Em
−
2
проверо и по предположению имеется
)12
2
1
( −⋅
−Em
ошибочных символов, а мажоритарное голосование (принятие
решения о декодируемом информационном символе по большинству одинаковых
результатов сформированных проверок) дает правильное значение i
k-1
-го
символа.
Так для рассмотренного КРМ с параметрами (n,k)=(16,15) эти
4
2
2
24
=
=
−
−
Em
проверки имеют следующие выражения:
3210
1
)10(
CCCCП ⊕⊕⊕=
,
111098
3
)10(
CCCCП ⊕⊕⊕=
,
7654
2
)10(
CCCCП ⊕⊕⊕= ,
15141312
4
)10(
CCCCП ⊕⊕⊕= .
Если произошла ошибка только в одном символе, то ошибочной будет
также только одна проверка, а мажоритарное голосование по остальным трем
проверкам позволяет правильно восстановить информационный символ i
(10)
.
В случае возникновения двух ошибок ни одно значение проверок не
встречается чаще других (нет большинства одинаковых результатов решения
проверок), что позволяет обнаружить только наличие ошибок в принятой кодовой
последовательности, в частности - наличие двукратных ошибок.
Аналогичным способом может быть декодирован любой информационный
символ, который умножается на одну из строк матрицы (x)G
E
; это
обеспечивается тем, что любая строка матрицы (x)G
E
ничем не выделяется
среди остальных. Перестановкой столбцов матрицы (x)G
E
можно добиться того,
что любая строка будет выглядеть также, как последняя строка матрицы (x)G
E
.

Следовательно, можно использовать те же самые проверки, соответственно
переставив индексы у символов, входящие в эти проверки. После построения
Em
−
2
проверок каждый символ будет декодироваться мажоритарным способом.
После того, как информационные символы данного сегмента будут определены,
их вклад в кодовую последовательность вычитается из принятой кодовой
последовательности. Эта процедура эквивалентна построению кодовой
последовательности КРМ (E-1)-го порядка. Последний сегмент
информационных символов данного кода определяется также с использованием
алгоритма мажоритарного декодирования. Такая процедура декодирования
информационных символов продолжается до тех пор, пока не будут
декодированы все информационные символы. Таким образом, декодирование
КРМ E-го порядка осуществляется поэтапно от определения информационных
символов
E
I сегмента E до определения информационных символов
0
I нулевого
сегмента.
5.5.2. Синтез функциональных схем кодека, реализующего
мажоритарный алгоритм декодирования кодов Рида-Маллера
Синтез функциональных схем кодека выполним для КРМ первого порядка с
параметрами: n=8 двоичных символов, m= 38log
2
=
, E=1,
4
2
2
d
13Em
===
−−
и
4
1!2!
3!
1C1
m
1k
n
E
E
=+=+=
+=
двоичных символа.
Порождающая матрица данного КРМ имеет следующее построение
.
01010101
00110011
00001111
11111111
(x)G
4,8
=
Кодирование информации КРМ осуществляется путем умножения
исходного информационного сообщения
3210
aaaaQ(x)
=
на порождающую
матрицу, т.е. по правилу
765432104,8
δδδδδδδδ(x)GQ(x)F(x)
=
⋅
=
. В этом случае
формируются кодовые последовательности неразделимого кода, которые
содержат по n=8 двоичных символов. Процесс кодирования (формирование
кодовых последовательностей) может быть реализован с использованием как
сумматоров по модулю два, так и двоичного счетчика. Принимаем вариант
построения кодека КРМ с использованием сумматоров по модулю два для чего
составим уравнения формирования кодовых символов )δδδδδδδδ(
7
6
5
4
3
2
1
0
,
которые имеют следующий вид:
,
0
0
0
1
00
0
aaδ =⋅
=
.,
,, , , ,
3332107323206
313105304210320
2101
aδaaaaδaδaaaδ
aδaaaδ aaδaaaδaaδaaδ
⊕=⊕⊕⊕=⊕=⊕⊕=
⊕
=
⊕
⊕
=
⊕
=
⊕
⊕
=
⊕
=
⊕
=
В соответствии с данными уравнениями обобщенная функциональная схема
кодера кода Рида-Маллера с параметрами (n,k,d
0
) = (8,4,4) будет иметь следующее
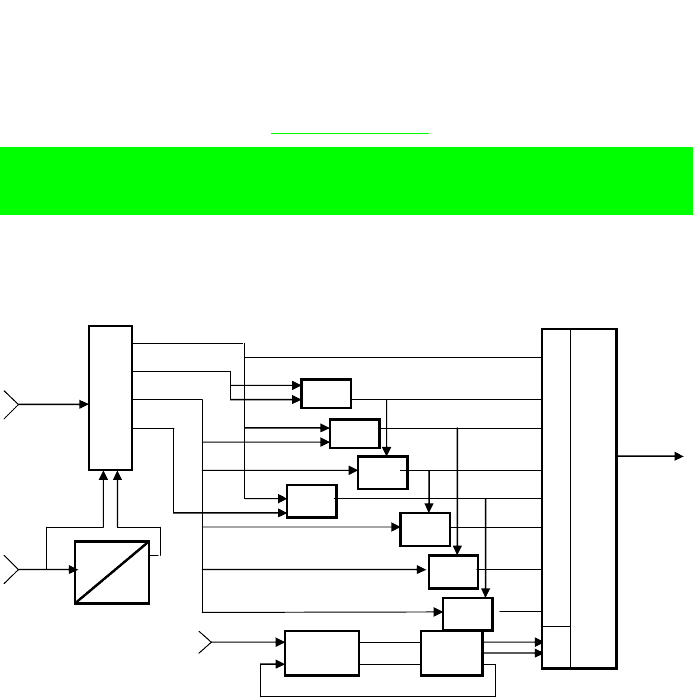
построение (рис.5.19).
Рис.5.19. Обобщенная функциональная схема кодера кода Рида-Маллера
первого порядка с (n,k,d
0
) = (8,4,4)
М2
М2
Вых.
F(x)
КРИ
-
1/4
a
0
a
1
a
2
a
3
Вх
.
Q(x)
Вх.
ДШ Дв.сч.
f
T2
=n· f
T1
:4
f
T1
f
T
Вх.
М2
М2
М2
М2
М2
δ
0
δ
1
δ
2
δ
3
δ
4
δ
5
δ
6
δ
7
MX
I
У
Принцип работы кодера аналогичен принципу работы кодера ЦК,
функциональная схема которого приведена на рис.5.10. Кодер формирует
кодовые последовательности несистематического кода. Путем перестановки
столбцов и суммирования строк можно сформировать каноническую
порождающую матрицу КРМ и кодер будет формировать кодовые
последовательности разделимого кода.
Для синтеза функциональной схемы декодера КРМ, реализующего
мажоритарный алгоритм декодирования, необходимо сформировать систему
раздельных проверочных уровней (проверок). Система раздельных проверок
формируется на основе порождающей матрицы G
4,8
(x) и имеет следующую
структуру:
,δδa
,δδa
,δδa
,δδa
761
541
321
101
⊕=
⊕=
⊕=
⊕
=
,δδa
,δδa
,δδa
,δδa
752
642
312
202
⊕=
⊕=
⊕=
⊕
=
.δδa
,δδa
,δδa
,δδa
733
623
513
403
⊕=
⊕=
⊕=
⊕
=
Для определения а
0
необходимо использовать полученные значения а
1
, а
2
, а
3
,
также результат решения уравнения истинности, т.е. а
0
= δ
0
.В соответствии с
данной системой раздельных уравнений обобщенная функциональная схема
декодера КРМ будет иметь следующее построение (рис.5.20).Выполним оценку
корректирующей способности разработанного кодека КРМ, используя для этого
сформированные системы проверочных уравнений. Предположим, что на вход
кодера КРМ (рис.5.19) поступило информационное сообщение Q (х), состоящее
из нулевых двоичных символов, т.е. Q (х) = а
0
а
1
а
2
а
3
= 0000. Кодер, в этом
случае, сформирует кодовую последовательность F(x), состоящую также из
одних нулевых двоичных символов , т.е. F(x) = δ
7
δ
6
δ
5
δ
4
δ
3
δ
2
δ
1
δ
0
= 00000000. Пусть при передаче по каналу связи искажению подверглись два
первых кодовых символа, т.е. 00000011)x(F
'
=
.
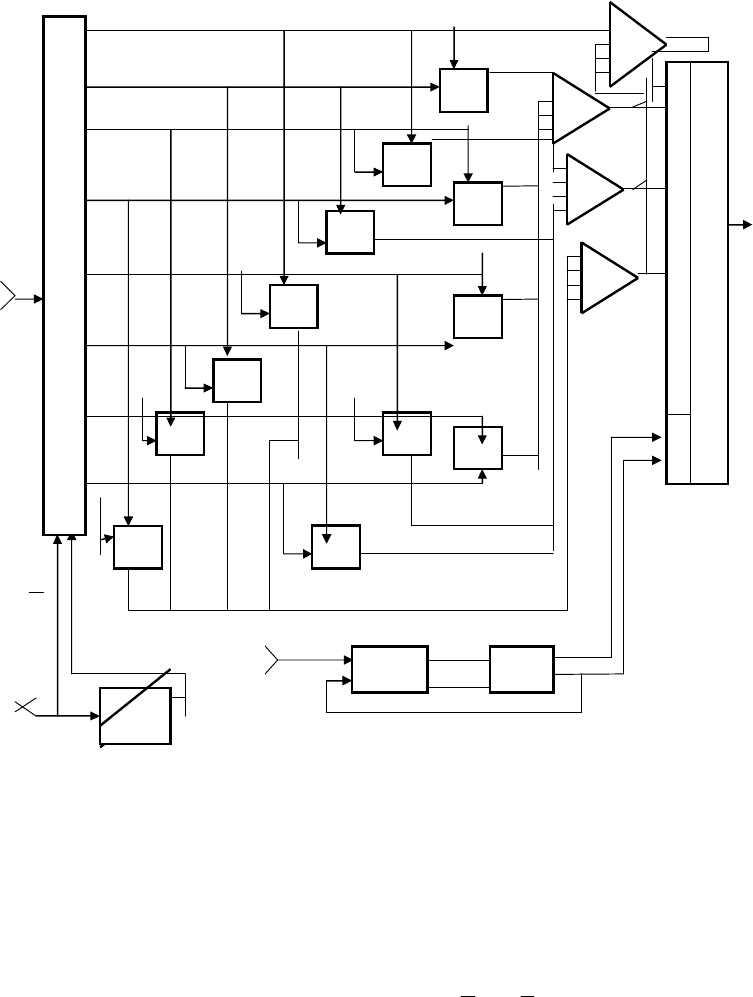
Рис.5.20. Обобщенная функциональная схема декодера кода Рида-Маллера
первого порядка с (n,k,d
0
) = (8,4,4)
В декодере KPM (рис. 5.20), в соответствии с уравнениями порождающей
матрицы G
4,8
(х), будут сформированы следующие значения информационных
символов (пороги срабатывания всех мажоритарных элементов (МЭ
1
…МЭ
4
)
декодера устанавливаются равными
31
2
4
1
2
П =+=+
µ
=
, μ-количество
проверочных уравнений):
а'
3
М2
М2
М2
М2
а'
2
а'
2
а'
2
а'
1
а'
3
МЭ4
...
а
3
Дш
Дв.сч.
f
T
Вх.
δ
0
δ
1
δ
2
δ
3
δ
4
δ
5
δ
6
δ
7
М2
М2
а'
1
а'
1
М2
М2
М2
а'
1
а'
2
а
2
МЭ3
I
У
MX
Вых.
Q
(
x
)
М2
а'
3
a'
3
:4
f
T1
f
T2
Вх.
а
0
М2
КРИ
-
1/8
М2
МЭ1
МЭ2
а
1
а
3
Вх.
F'(x)