Korb K.B., Nicholson A.E. Bayesian Artificial Intelligence
Подождите немного. Документ загружается.

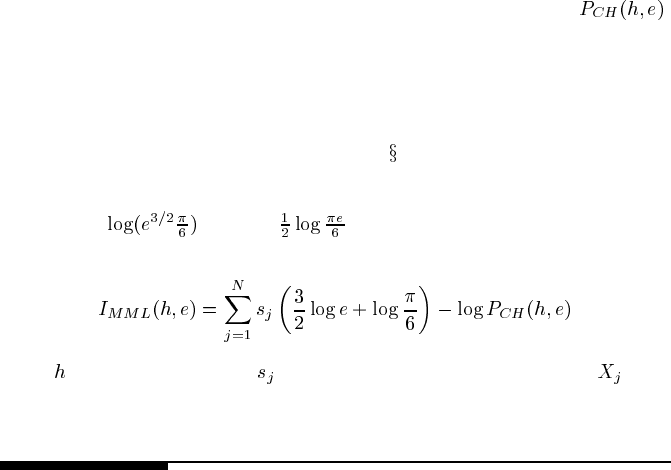
8.6.5 An MML metric for discrete models
We can readily extend this work from linear to discrete causal model discovery. The
MML structural score for TOMs is unaffected, as is the Metropolis search process.
All we need is a new metric for parameters and data. The simplest approach is to ap-
ply an adjustment to the probability distribution of Cooper and Herkovits
.
Bearing in mind that the most significant distinction between their approach and
the MML approach is their assumption of a uniform prior over hypotheses (their
assumption 5, implicitly denying the relevance of multiple linear extensions), the
search being conducted over the TOM space eliminates that distinction. Thus, all
that is required is a simpler adjustment, reflecting the difference between integrat-
ing the parameters out of the computation (as in
8.1) and the MML method, which
estimates the parameters by partitioning the parameter space and selecting the opti-
mal cell for communicating that estimate. The difference amounts to a penalty per
parameter of
bits (i.e., nits — meaning units to the base of the
natural log — see [292]). Hence:
(8.15)
where
ranges over TOMs and is the number of parameters needed for .
8.7 Experimental evaluation
Having seen a number of algorithms for learning causal structure developed, the
natural question to ask is: Which one is best? Unfortunately, there is no agreement
about exactly what the question means, let alone which algorithm answers to it.
There has been no adequate experimental survey of the main contending algorithms.
Some kind of story could be pieced together by an extensive review of the literature,
since nearly every publication in the field attempts to make some kind of empirical
case for the particular algorithm being described in that publication. However, the
evaluative standards applied are uneven, to say the least.
Note that the evaluative question here is not identical to the evaluative question be-
ing asked by the algorithms themselves. That is, the causal discovery algorithms are
aiming to find the best explanatory model for whatever data they are given, presum-
ably for use in future predictive and modeling tasks. For this reason they may well
apply some kind of complexity penalty to avoid overfitting the training data. Here,
however, we are interested in the question of the best model-discoverer, rather than
the best model. We are not necessarily interested in the complexities of the model
representations being found, because we aren’t necessarily interested in the models
as such. Analogically, we are here interested in the intelligence of a learner, rather
than in the “smartness” (or, elegance) of its solutions.
© 2004 by Chapman & Hall/CRC Press LLC
8.7.1 Qualitative evaluation
The TETRAD II publications (e.g., [265, 244]) have used stochastic sampling from
known causal models to generate artificial data and then reported percentages of
errors of four types:
Arc omission, when the learned model fails to have an arc in the true model
Arc commission, when the learned model has an arc not in the true model
Direction omission, when the learned model has not directed an arc required
by the pattern of the true model
Direction commission, when the learned model orients an arc incorrectly ac-
cording to the pattern of the true model
This is an attempt to quantify qualitative errors in causal discovery. It is, however,
quite crude. For example, some arcs will be far more important determiners of the
values of variables of interest than others, but these metrics assume all arcs, and all
arc directions within a pattern, are of equal importance.
Regardless, this kind of metric is by far the most common in the published lit-
erature. Indeed, the most common evaluative report consists of using the ALARM
network (Figure 5.2) to generate an artificial sample, applying the causal discovery
algorithm of interest, and counting the number of errors of omission and commis-
sion. Every algorithm reported in this chapter is capable of recovering the ALARM
network to within a few arcs and arc directions, so this “test” is of little interest in
differentiating between them. Cooper and Herskovits’s K2, for example, recovered
the network with one arc missing and one spurious arc added, from a sample size of
10,000 [54]. TETRAD II also recovers the ALARM network to within a few arcs
[265], although this is more impressive than the K2 result, since it needed no prior
temporal ordering of the variables. Again, Suzuki’s MDL algorithm recovered the
original network to within 6 arcs on a sample size of only 1000 [273].
Perhaps slightly more interesting is our own empirical study comparing TETRAD
II and CaMML on linear models, systematically varying arc strengths and sample
sizes [65]. The result was a nearly uniform superiority in CaMML’s ability to recover
the original network to within its pattern faster than (i.e., on smaller samples than)
TETRAD II.
8.7.2 Quantitative evaluation
Because of the maximum-likelihood equivalence of dags within a single pattern, it is
clear that two algorithms selecting identical models, or Markov equivalent models,
will be scored alike on ordinary evaluative metrics. But it should be equally clear that
non-equivalent models may well deserve equal scores as well, which the qualitative
scores above do not reflect. Thus, if a link reflects a nearly vanishing magnitude of
causal impact, a model containing it and another lacking it but otherwise the same
may properly receive (nearly) the same score. Again, the parameters for an associ-
ation between parents may lead to a simpler v-structure representing the very same
probability distribution as a fully connected network of three variables (see [293] for
© 2004 by Chapman & Hall/CRC Press LLC

an example). So, we clearly want a more discriminating and accurate metric than the
metrics of omission/commission.
The traditional such metric is predictive accuracy: the percentage of correctly
predicted values of some target variable. In classification problems this has a clear
meaning, but for learning causal models it is generally less than clear which vari-
able(s) might be “targeted” for classification. Predictive accuracy, in any case, suf-
fers from other problems, which we examine in
10.5.1.
Kullback-Leibler divergence (
3.6.5) of the learned model from the model gener-
ating the data is preferable and has been used by some. Suzuki, for example, reported
the KL metric over the ALARM network, showing a better result for his MDL al-
gorithm than that for K2 [273]. KL divergence is normally measured over all the
variables in a model. Because of the Markov equivalence of all models within a pat-
tern (Theorem 6.1), this implies that what is being evaluated is how close the learned
model is to the original pattern, rather than to the original causal model. So this is
not obviously the best method for evaluating causal discovery.
In one study [201], we compared linear CaMML with Heckerman and Geiger’s
BGe metric [103], using the same search algorithm for both. We also used two
distinct kinds of prior probabilities for both: one applying CaMML’s uniform prior
over TOMs (P1) and the other applying a uniform prior over dags within a pattern
(P2), which is more consistent with Heckerman and Geiger’s views. KL divergence
from the original model was measured in two ways. When KL was measured over
all variables in the network, metrics using P2 tended to do best. When KL was
measured over the original leaves only (nodes without children), metrics using P1
did best. The latter measure arguably better reflects the prediction task for causal
discovery; for one thing, if causal structure is misidentified, the leaves are likely to
be misidentified, leading to a worse score on this metric. In this particular study, the
only interesting differences in performance arose from the priors; that is, BGe and
CaMML otherwise performed alike. We discuss some issues of evaluation further in
Chapter 10.
8.8 Summary
There are two distinct approaches to learning causal structure from data. Constraint-
based learning attempts to identify conditional independencies in isolation and to
construct causal models, or patterns, from them. Given perfect access to the condi-
tional independencies, and Reichenbach’s Principle of the Common Cause, we can
reasonably infer that the true causal model lies in one and only one pattern. However,
it is generally not optimal to judge conditional independencies in isolation: the pres-
ence (or absence) of one dependency frequently will confer support or undermine the
presence of another. Metric learners can take advantage of such evidential relevance,
since they score causal models (or patterns) as a whole. Constraint-based learners are
© 2004 by Chapman & Hall/CRC Press LLC
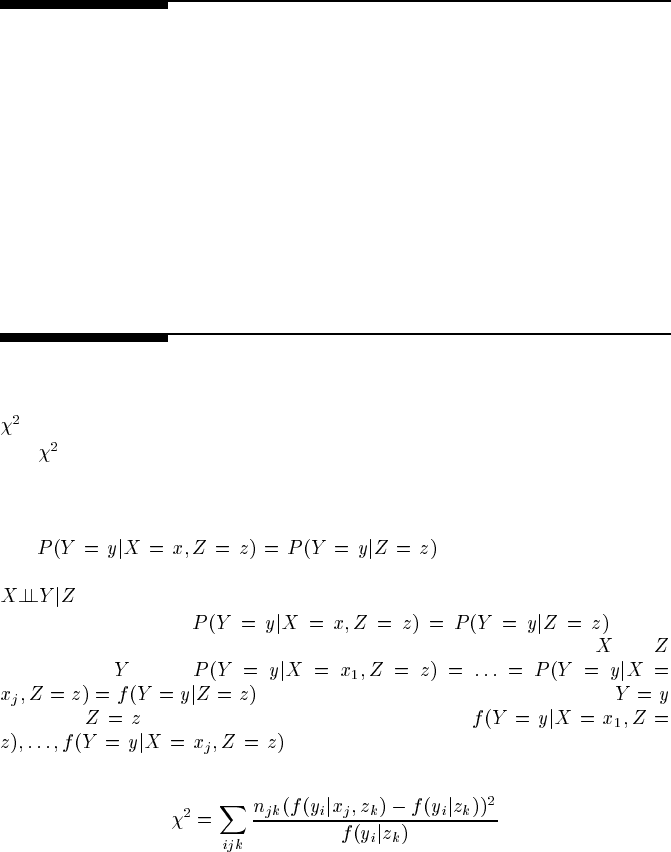
the more popular, because they are simple to understand and implement, and they can
now be found in the leading Bayesian network tools, as well as in TETRAD. The dif-
ferent metric learners appear to have more promise for the long haul, however. Such
experimental literature as exists favors them, although the methodology of evalua-
tion for Bayesian network learners remains unclear. We expand on the question of
evaluation, and especially the evaluation of the Bayesian networks themselves, in
Chapter 10.
8.9 Bibliographic notes
In addition to what we have presented here, there are a host of other learning tech-
niques that attempt to ply the tradeoff between model simplicity and data fit by ap-
plying “penalties” to some measure of model complexity, including BIC (Bayesian
information criterion) [245] and AIC (Akaike information criterion) [242].
A good early review of the causal discovery literature is Buntine’s guide [36].
Jordan’s anthology contains a number of useful articles on various aspects of causal
discovery [135]. Neapolitan’s Learning Bayesian Networks [200] treats some aspects
of causal discovery we do not have the time for here.
8.10 Technical notes
test.
The
test is a standard significance test in statistics for deciding whether an ob-
served frequency fails to match an expected frequency. It was proposed in the text
as a substitute in the PC algorithm for the partial correlation significance test when
applying the algorithm to discrete variables. In particular, it can be used to test whe-
ther
across the different possible
instantiations of the three variables (or, sets of variables), in order to decide whether
.
The assumption that
can be
represented by taking the expected frequencies in the CPT cells (treating
and
as parents of )tobe
, where this last is the frequency with which
given that . The observed frequencies are then just
. The statistic for running a significance test on
the discrepancy between these two measures is:
© 2004 by Chapman & Hall/CRC Press LLC
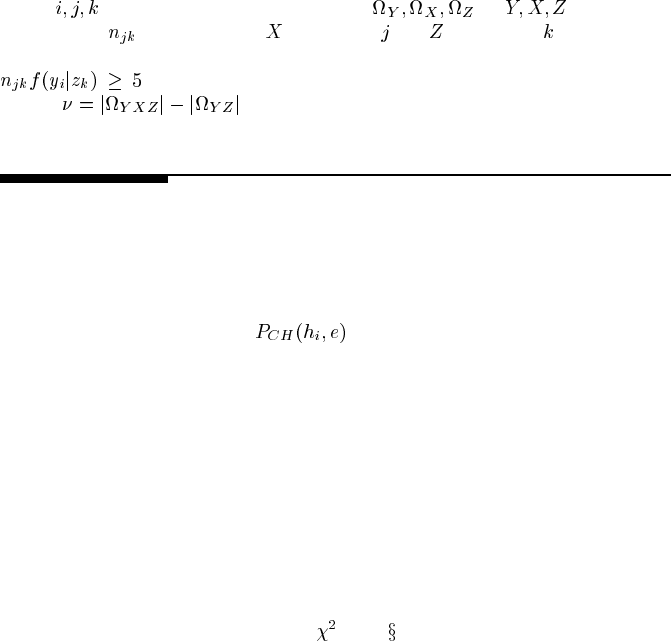
where
index the possible instantiations of respectively
and there are
samples where takes value and takes value .
For conducting such a significance test, it is generally recommended that
for each possible combination. The degrees of freedom for the
test are
.
8.11 Problems
Programming Problems
Problem 1
Implement the Bayesian metric
of (8.3) for discrete causal models.
Problem 2
Implement one of the alternative metrics for discrete causal models, namely MDL,
or MML (or BDe, after reading [103]).
Problem 3
Implement a simple greedy search through the dag or TOM space. Test the result on
artificial data using one or more metrics from prior problems.
Problem 4
Implement the PC algorithm using the
from 8.10. Compare the results experi-
mentally with one of the metric causal discovery programs from prior problems.
Evaluation Problem
For this problem you should get and install one or more of the causal discovery
programs: TETRAD IV, WinMine or CaMML. For instructions see Appendix B.
Problem 5
Run the causal discovery program on some of the data sets at our book web site. Try
the program with and without giving it prior information (such as variable order).
Evaluate how well it has done in one of two ways:
1. In terms of either predictive accuracy, KL distance or information reward (see
Chapter 10).
2. By qualitative or quantitative comparison with an alternative causal discovery
program (perhaps from one of the problems above, or also downloaded by
you).
© 2004 by Chapman & Hall/CRC Press LLC
Part III
KNOWLEDGE
ENGINEERING
© 2004 by Chapman & Hall/CRC Press LLC
By now we have seen what Bayesian networks are, how they can represent uncer-
tain processes of a considerable variety, how they can be conditioned to reflect new
information, make decisions, perform causal modeling and optimize planning under
uncertainty. We have seen how causal structures can be parameterized from data
once learned or elicited. And we have also seen how such structures can be learned
in the first place from observational data, either by taking advantage of conditional
independencies in the data or by using Bayesian metrics. What is largely missing
from the story so far is a method for putting all of these ingredients together in a
systematic way.
In Chapter 9 we apply some of the more useful ideas of software engineering, and
recent experiences of ourselves and others working with Bayesian networks, toward
the development of such a method, which we call KEBN: Knowledge Engineering
with Bayesian Networks. Part of the method necessarily includes techniques for
evaluating Bayesian networks once developed or learned. In Chapter 10 we first
present evaluation methods employing expert judgment, including sensitivity analy-
sis, which tests the sensitivity of networks to parameters. Then we discuss some of
the more prominent traditional and new approaches to evaluating Bayesian networks
using sample data.
In Chapter 11 we return to the presentation of Bayesian network applications, but
this time with the idea of illustrating some of the KEBN processes and other issues
raised in Part III.
© 2004 by Chapman & Hall/CRC Press LLC

9
Knowledge Engineering with Bayesian
Networks
9.1 Introduction
Within the Bayesian network research community, the initial work in the 1980’s and
early 1990’s focused on inference algorithms to make the technology computation-
ally feasible. As it became clear that the “knowledge bottleneck” of the early ex-
pert systems was back — meaning the difficulties of finding human domain experts,
extracting their knowledge and putting it into production systems — the research
emphasis shifted to automated learning methods. That is necessary and inevitable.
But what practitioners require then is a overarching methodology which combines
these diverse techniques into a single “knowledge engineering” process, allowing
for the construction Bayesian models under a variety of circumstances, which we
call Knowledge Engineering with Bayesian Networks,orKEBN.
In this chapter we tie together the various techniques and algorithms we have pre-
viously introduced for building BNs and supplement them with additional methods,
largely drawn from the software engineering discipline, in order to propose a general
methodology for the development and deployment of BNs. We supplement this in
the next chapter with methods for evaluating Bayesian networks, giving an outline
of a comprehensive methodology for modeling with Bayesian networks. No one has
fully tested such a methodology, so our KEBN model must remain somewhat spec-
ulative. In any case, we can illustrate some of its major features with a number of
case studies from our experience, which we proceed to do in Chapter 11.
9.1.1 Bayesian network modeling tasks
When constructing a Bayesian network, the major modeling issues that arise are:
1. What are the variables? What are their values/states?
2. What is the graph structure?
3. What are the parameters (probabilities)?
When building decision nets, the additional questions are:
4. What are the available actions/decisions, and what impact do they have?
5. What are the utility nodes and their dependencies?
6. What are the preferences (utilities)?
© 2004 by Chapman & Hall/CRC Press LLC

Expert elicitation is a major method for all of these tasks. Methods involving
automated learning from data, and adapting from data, can be used for tasks 1-3 (if
suitable data are available). We have described the main techniques for tasks 2 and
3 in Chapters 6, 7 and 8. Task 1 has been automated as well, although we do not
go into these methods in this text. Identifying variables is known in the machine
learning literature as unsupervised classification; see, for example, Chris Wallace’s
work on Snob [290, 291]. There are many techniques for automated discretization,
for example [193]. On the other hand, very little has been done to automate methods
for tasks associated with building decision networks and we do not cover them in
this text. In the remainder of this chapter we shall first focus on how to perform all
the tasks using expert elicitation, then we shall consider methods for adaptation,
combining elicitation with machine learning, in
9.4.
9.2 The KEBN process
9.2.1 KEBN lifecycle model
A simple view of the software engineering process construes it as having a lifecycle:
the software is born (design), matures (coding), has a lengthy middle age (mainte-
nance) and dies of old age (obsolescence). Our best effort at construing KEBN in
such a lifecycle model (also called a “waterfall” model) is shown in Figure 9.1. Al-
though we prefer a different view of KEBN (presented just below), the lifecycle is a
convenient way of introducing many aspects of the problem, partly because it is so
widely known and understood.
Building the Bayesian network is where the vast majority of research effort in
KEBN has gone to date. In the construction phase, the major network components
of structure, parameters and, if a decision network, utilities (preferences) must be
determined through elicitation from experts, or learned with data mining methods,
or some combination of the two.
Evaluation aims to establish that the network is right for the job, answering such
questions as: Is the predictive accuracy for a query node satisfactory? Does it re-
spect any known temporal order of the variables? Does it incorporate known causal
structure? Sensitivity analysis looks at how sensitive the network is to changes in
input and parameter values, which can be useful both for validating that the network
is correct and for understanding how best to use the network in the field.
Field testing first puts the BN into actual use, allowing its usability and performance
to be gauged. Alpha testing refers to an intermediate test of the system by inhouse
people who were not directly involved in developingit; for example, by other inhouse
BN experts. Beta testing is testing in an actual application by a “friendly” end-user,
who is prepared to accept hitting bugs in early release software. For software that
is not being widely marketed, such as most BNs, this idea may be inapplicable —
although domain experts may take on this role. Acceptance testing is surely required:
© 2004 by Chapman & Hall/CRC Press LLC
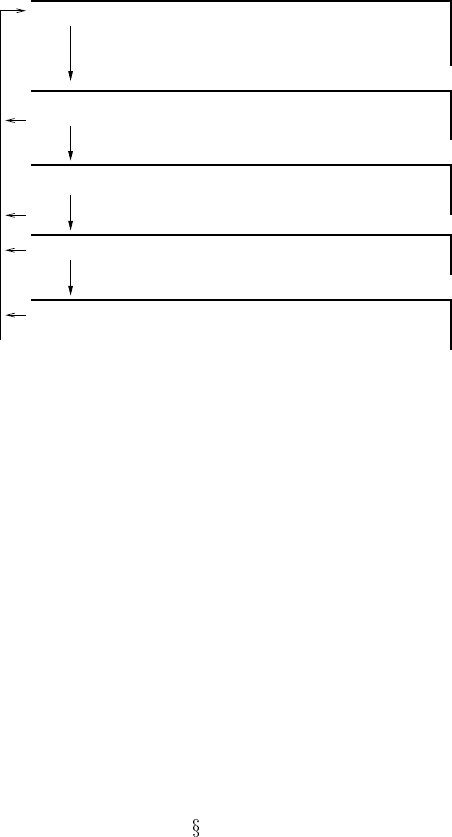
3) Field Testing
2) Validation
4) Industrial Use
5) Refinement
i) Structure
ii) Parameters
iii) Preferences
1) Building the BN
Collection of Statistics
Sensitivity Analysis
Acceptance Testing
Alpha/Beta Testing
Accuracy Testing
Regression Testing
Updating Procedures
FIGURE 9.1
A KEBN lifecycle model.
it means getting the end users to accept that the BN software meets their criteria for
use.
Industrial use sees the BN in regular use in the field and requires that procedures
be put in place for this continued use. This may require the establishment of a new
regime for collecting statistics on the performance of the BN and statistics monitor-
ing the application domain, in order to further validate and refine the network.
Refinement requires some kind of change management regime to deal with requests
for enhancement or fixing bugs. Regression testing verifies that any changes do not
cause a degradation (regression) in prior performance.
In this chapter we will describe detailed procedures for implementing many of
these steps for Bayesian network modeling. Those which we do not address specif-
ically, such as how to do regression testing and acceptance testing, do not seem to
have features specific to Bayesian network modeling which are not already addressed
here. We refer you to other works on software engineering which treat those matters
in the notes at the end of the chapter (
9.6).
9.2.2 Prototyping and spiral KEBN
We prefer the idea of prototyping for the KEBN process to the lifecycle model. Pro-
totyping interprets the analogy of life somewhat differently: as an “organism,” the
software should grow by stages from childhood to adulthood, but at any given stage it
is a self-sufficient, if limited, organism. Prototypes are functional implementations
of software: they accept real input, such as the final system can be expected to deal
with, and produce output of the type end-users will expect to find in the final system.
What distinguishes early form prototypes from the final software is that the func-
© 2004 by Chapman & Hall/CRC Press LLC