Faulon J.L., Bender A. Handbook of Chemoinformatics Algorithms
Подождите немного. Документ загружается.


218 Handbook of Chemoinformatics Algorithms
Thus, we want to make prediction accuracies for different classes close to each
other. Other penalizing schemes are possible; for example, penalty terms are added
only if the differences in the CCR values exceed some threshold. If the classes of
the dataset under study have significantly different sizes (a dataset is imbalanced or
biased), additional modification of Formula 7.9 could be necessary. Usually, in this
case, CCR values for larger classes are higher than for smaller ones, so weights w
i
for classes are introduced (Formula 7.11).
CCR =
K
i=1
w
i
CCR
i
−
1
K
K−1
i=1
K
j=i+1
α
ij
CCR
i
−CCR
j
,
K
i=1
w
i
= 1. (7.11)
Higher weights are given for smaller classes. The sum of the weights is equal
to one.
Target functions and validation criteria for category QSAR models: Category
QSAR with more than two classes should use target functions and validation criteria
other than those used in classification QSAR. These target functions and validation
criteria should consider errors as differences between predicted and observed cate-
gories, or increasing functions of these differences. The total error of prediction over
all compounds is the sum of all errors of predictions for individual compounds. Let
n
ij
be the number of compounds of category i assigned by a model to category j (i,
j = 1, ..., K). Then the total error is calculated as follows (Formula 7.12):
E =
K
i=1
K
j=1
n
ij
f
(
|
i −j
|
)
, (7.12)
where f (|i −j|) is the increasing function of errors and f (0) = 0. In the case of biased
datasets, it would be important to normalize the errors for compounds of category i
on the number of compounds in this category:
E =
K
i=1
1
N
i
K
j=1
n
ij
f (|i −j|), (7.13)
where N
i
is the number of compounds of category i. Finally, it is possible to use
different weights in the calculation of the error: larger weights should be given for
errors for categories including a smaller number of compounds to make the total error
E more sensitive to errors for smaller categories (Formula 7.14).
E = K
K
i=1
w
i
N
i
K
j=1
n
ij
f (|i −j|),
K
i=1
w
i
= 1. (7.14)
The prediction accuracy can be calculated as
A = 1 −
E
E
max
. (7.15a)
Predictive Quantitative Structure–Activity Relationships Modeling 219
According to this definition, 0 ≤ A ≤ 1. If weights are not used, the maximum
possible error E
max
can be calculated as follows (if errors are not normalized):
E
max
=
[K/2]
i=1
N
i
f (|K −i|) +
K
i=[K/2+1]
N
i
f (|i −1|), (7.16a)
or as follows (if errors are normalized):
E
max
=
[K/2]
i=1
f (|K −i|) +
K
i=[K/2+1]
f (|i −1|). (7.16b)
If weights are used, the maximum possible error E
max
can be calculated as
follows (if errors are not normalized):
E
max
= K
K
i=1
max
j
)
w
i
N
i
f (
|
i −j
|
)
*
j = 1, 2, ..., K, (7.16c)
or as follows (if errors are normalized):
E
max
= K
K
i=1
max
j
)
w
i
f
(
|
i −j
|
)
*
, j = 1, 2, , ...K. (7.16d)
An alternative definition of the accuracy is as follows:
A
= 1 −
E
E
exp
, (7.15b)
where E
exp
is the expected error. If weights are not used, the expected error E
exp
can
be calculated as follows (if errors are not normalized):
E
exp
=
1
K
K
i=1
N
i
K
j=1
f (|i −j|), (7.17a)
or as follows (if errors are normalized):
E
exp
=
1
K
K
i=1
K
j=1
f (|i −j|). (7.17b)
If weights are used, the maximum possible error E
max
can be calculated as follows
(if errors are not normalized):
E
exp
=
K
i=1
w
i
N
i
K
j=1
f (|i −j|), (7.17c)
220 Handbook of Chemoinformatics Algorithms
or as follows (if errors are normalized):
E
exp
=
K
i=1
w
i
K
j=1
f (|i −j|). (7.17d)
Prediction statistics for category QSAR models should also be combined with the
corresponding p-values.
Threshold moving: Finally, when predicting a compound by a biased dataset,
threshold moving can be used. For example, if a compound’s predicted class or cat-
egory is 1.6, by rounding it is assigned to class 2. However, if a model is built for
a biased dataset with class or category 1 being much smaller than class or category
2, it can be assigned to class or category 1; if the threshold between categories is
moved from 1.5 to, say, 1.7, then all compounds with predicted class or category
lower than 1.7 are assigned to class or category 1, otherwise they are assigned to class
or category 2.
7.3 VALIDATION OF QSAR MODELS: Y-RANDOMIZATION
To establish model robustness, the Y-randomization (randomization of the response
variable) test should be used. This test consists of repeating all the calculations with
scrambled activities of the training set. Ideally, calculations should be repeated at
least five or 10 times. The goal of this procedure is to establish whether models
built with real activities of the training set have good statistics not due to overfitting
or chance correlation. If all models built with randomized activities of the training
set have statistically significantly lower predictive power for the training or the test
set, then the models built with real activities of the training set are reliable. Using
different parameters of a model development procedure, multiple QSAR models are
built that have acceptable statistics. Suppose that the number of these models is m. The
Y-randomization test can also give n models with acceptable statistics. For acceptance
of models developed with real activities of the training set, the condition n m should
be satisfied. In Refs. [2,3], we have introduced the measure of robustness R = 1 −
n/m.IfR > 0.9, the models are considered robust and their high predictive accuracy
cannot be explained by chance correlation or overfitting. The Y-randomization test
is particularly important for small datasets. Unfortunately, in many publications on
QSAR studies, the Y-randomization test is not performed but all QSAR practitioners
must be strongly encouraged to use this simple procedure.
7.4 VALIDATION OF QSAR MODELS: TRAINING AND TEST SET
RESAMPLING. STABILITY OF QSAR MODELS
If a model has a high predictive accuracy for one division into the training and test
sets, it must be tested using other divisions. It is particularly important for small
datasets, when division into three sets (training, test, and independent validation)
is impossible, since the smaller is the number of objects for building models, the
worse are the chances of building a truly predictive model. We are proposing here a
Predictive Quantitative Structure–Activity Relationships Modeling 221
new method, namely training and test set resampling, a nonparametric technique that
could be used to estimate statistics and confidence intervals for a population of objects
when only a representative subset of the population is available (a dataset used to build
models). “Resampling” means multiple random divisions of a dataset into training
and test sets of the same size as were used for building models. The training sets are
used for the calculation of internal prediction accuracy, such as cross-validation q
2
for continuous problems, or CCR and/or A for classification or category QSAR (see
Formulas 7.8 through 7.18). The corresponding test sets are used for the calculation
of the correlation coefficient between predicted and observed response variables,
and coefficients of determination and slopes of regression lines of predicted versus
observed and observed versus predicted response variables through the origin for
continuous problems. In case of classification or category response variable, test sets
are used for estimation of the total classification accuracy as well as classification
accuracy for each class or category. Prior to prediction of compounds from the test
set, the AD for the corresponding training set should be defined (see Section 7.5).
Prediction should be made only for those compounds of the test sets that are within
the ADs of the training sets. We argue that predictive models should have similar
statistics to those obtained with the initial training and test sets. Large differences
between model statistics will evidence that the model is unstable. Average statistics
values obtained using the training and test set resampling approach are expected to
be better estimates of the population statistics than those obtained with the initial
training and test sets. It will be also possible to estimate confidence intervals of the
model statistics, which are important characteristics of the model stability.
A similar method of validation, which is used in QSAR and other data analysis
areas, is bootstrapping [9–11]. Like the resampling of training and test sets, boot-
strapping is a nonparametric approach to obtain estimates of statistics and confidence
intervals for a population of objects when only a representative subset of the popu-
lation is available. Bootstrapping consists of choosing N objects with returns from a
dataset of N objects. Due to returns of the selected objects to the initial dataset, some
objects will be included in the bootstrapped datasets several times, while others will
not be included at all. It has been shown that if the procedure is repeated many times
(about 1000 times or more), average bootstrapped statistics are good estimates of
population statistics. Bootstrapping can be used separately for training and test sets.
Selecting the same compounds several times into the training sets is unacceptable for
some QSAR methodologies like kNN. On the other hand, training and test set resam-
pling is free from this disadvantage, because in different realizations it will include
the same objects in the training or in the test set. Thus, after many realizations, both
training and test sets will be represented by all objects included in the dataset. To
obtain population statistics estimates, we shall use the same approaches as used for
bootstrapping. They are described elsewhere [10–12].
The authors of a recent publication [13] assert that cross-validation and boot-
strapping are not reliable in estimating the true predictive power of a classifier, if a
dataset includes less than about 1000 objects, and suggest the Bayesian confidence
intervals should be used instead. Cross-validation and bootstrapping are particularly
unreliable for small datasets (including less than about 100 compounds). But 95%
Bayesian confidence intervals for these datasets are very wide [13]. The authors show
222 Handbook of Chemoinformatics Algorithms
that the Repeated Independent Design and Test [14] introduced earlier does not solve
the problem of cross-validation and bootstrapping. The procedure consists of split-
ting a dataset into two parts (which are called design bag and test bag) and repeated
selection of objects from these bags into training and test sets with replacement.
7.5 APPLICABILITY DOMAINS OF QSAR MODELS
Formally, a QSAR model can predict the target property for any compound for which
chemical descriptors can be calculated. However, if a compound is highly dissimilar
from all compounds of the modeling set, reliable prediction of its activity is unlikely
to be realized. A concept of AD was developed and used to avoid such an unjustified
extrapolation in activity prediction. Classification of existing definitions of AD was
given in recent publications by Jaworska and colleagues [15,16]. Here, we will follow
this classification [paragraphs (i) through (v)].
i. Descriptor-range based: AD is defined as a hyperparallelepiped in the
descriptor space in which representative points are distributed [6,17,18].
Dimensionality of the hyperparallelepiped is equal to the number of descrip-
tors, and the size of each dimension is defined by the minimum and maximum
values of the corresponding descriptor or it stretches beyond these limits to
some extent up to predefined thresholds. The drawbacks of this definition
are as follows. Generally, the representative points are distributed not in the
entire hyperparallelepiped, but only in a small part of it. For example, in
many cases, principal component analysis (PCA) shows that a small number
of PCs explains 90–95% of the variance of descriptor values; this means that
the representative points are predominantly distributed along a hyperplane
of much lower dimensionality than that of the entire descriptor space. It is
as if, in the three-dimensional hypercube, the points would be concentrated
around one of its diagonals, while most of the space in the cube would be
empty. Another possibility is that there are structural outliers in the dataset,
which were not removed prior to QSAR studies. Even one such outlier can
enormously increase the size of the hypercube, and the area around the outlier
will contain no other points. Consequently, for many compounds within the
hypercube, prediction will be unreliable.
ii. Geometric methods: convex hull AD: AD is defined as a convex hull of
points in the multidimensional descriptor space [19]. The drawbacks of the
convex hull AD are the same as those for the descriptor-range-based AD:
the representative points might be distributed not in the entire convex hull,
but only in a small part of it. Outliers not removed prior to QSAR mod-
eling may significantly increase the volume of the convex hull. Besides,
in many cases, especially for small datasets, the number of descriptors
exceeds the number of compounds. In this case, the convex hull is not
unique.
iii. Leverage based: Leverage for a compound is defined as the corresponding
diagonal element of the hat matrix [20]. A compound is defined as outside
of the AD if its leverage L is higher than 3 K/N, where K is the number
Predictive Quantitative Structure–Activity Relationships Modeling 223
of descriptors and N is the number of compounds. The drawbacks of the
leverage-basedAD are as follows. (a) for each external compound, it is neces-
sary to recalculate leverage; (b) if there are cavities in the representative point
distribution area, a compound under prediction in this area will be considered
to be within the AD (see Figure 6.2).
iv. Probability density distribution based: It is believed that more reliable pre-
dictions are in the areas of higher density of representative points than in
sparse density. Drawbacks: (a) there is a problem of estimating the local den-
sity distribution function of points. For example, if a query point is close
to the border of the area occupied by representative points, the probability
density function can be underestimated; (b) in fact, prediction will be more
precise, if nearest neighbors of the query compound have similar activities.
It is not necessarily true in high density distribution areas. Moreover, in these
areas, activity outliers and even activity cliffs are more likely to be encoun-
tered; hence, if they are not taken care of prior to or during QSAR studies,
they might pose serious problems. Bayesian classifiers belong to this type of
algorithms. Let the density distribution functions at point x for each class i
be p(x | i), and the a priori probability for class i be P(i). Then the point x
is assigned to the class for which p(x|i) P(i) is the highest (the approach is
adapted from a lecture on Pattern Recognition [21] and generalized).Another
approach, the R-NN curve approach, was developed by Guha et al. [22]. The
number of neighbors of each compound in the descriptor space is considered
as a function of distance to this compound. Low values of this function for
short distances to this compound mean that the distribution density of com-
pounds in the neighborhood of this compound is low; hence, this compound
can be considered as an outlier.
v. Ensemble based: This method was applied to water solubility data [23]. It
consists of the following steps. (a) For a query compound, find nearest neigh-
bors with known activities in the database. If the similarity to all compounds
in the database is below a predefined threshold, a compound is considered to
be outside of the AD. Atom-centered fragments were used as descriptors and
a modified Dice coefficient was used as a similarity measure. (b) Predict these
compounds by multiple models. In the paper, seven models for assessing the
compounds’ solubility built by other authors were considered. (c) Select a
model that predicted these compounds most accurately. (d) Predict the query
compound by this model. Drawbacks and criticism: A large amount of data
should be available. The authors used a database of more than 1800 com-
pounds with known water solubility. For most of the targets, so much data
are not available. If models were built by the same authors, a question would
arise why the database compounds were not used in model building, which
would increase the predictive accuracy of their models.
vi. Distance-basedAD: In our studies, theAD is definedas the Euclidean distance
threshold D
cutoff
between a compound under prediction and its closest nearest
neighbor of the training set. It is calculated as follows:
D
cutoff
=D+Zs. (7.18)

224 Handbook of Chemoinformatics Algorithms
Here, D is the average Euclidean distance between each compound and
its k nearest neighbors in the training set (where k isthe parameter optimized in
the course of QSAR modeling, and the distances are calculated using descrip-
tors selected by the optimized model only), s is the standard deviation of these
Euclidean distances, and Z is an arbitrary parameter to control the significance
level [2,3,7,24]. We set the default value of this parameter Z at 0.5, which
formally places the allowed distance threshold at the mean plus one-half of
the standard deviation. We also define theAD in the entire descriptor space. In
this case, the same Formula 7.18 is used, k = 1, Z = 0.5, and Euclidean dis-
tances are calculated using all descriptors. Thus, if the distance of the external
compound from its nearest neighbor in the training set within either the entire
descriptor space or the selected descriptor space exceeds these thresholds, the
prediction is not made. We have also investigated changes of predictive power
by changing the values of Z-cutoff. We have found that in general, predictive
power decreases while Z-cutoff value increases (unpublished observations).
Instead of Euclidean distances, other distances and similarity measures can
be used.
vii. Consensus prediction value of the activity of a query compound by an ensem-
ble of QSAR models is calculated as the average overall prediction values. For
classification and category QSAR, the average prediction value is rounded to
the closest integer (which is a class or category number); in the case of imbal-
anced datasets, rounding can be performed using the moving threshold (see
Section 7.2). Predicted average classes or categories (before rounding) that
are closer to the nearest integers are considered more reliable. For example,
before rounding, one compound has the prediction value of 1.2, but the other
has 1.4; hence, both compounds are predicted to belong to class 1. Prediction
for the first compound is considered more reliable. Using these prediction
values, AD can be defined by a threshold of the absolute difference between
the predicted and the rounded predicted activity (unpublished observations).
Another recent publication considering problems of AD definitions and
prediction accuracy [25] highlights the following methods [(viii) through
(xi)].
viii. Target property should influence the AD, for instance, Ref. [26] recommends
using different weights w
n
(n = 1, ..., N) for descriptors in the calculation
of distances between compounds, that is, the distance between compounds i
and j is calculated as
D
ij
=
,
-
-
.
N
n=1
w
n
(X
in
−X
jn
)
2
. (7.19)
The weights in Formula 7.19 could be proportional to the coefficients with
which the corresponding descriptors are included in the QSAR model. AD
is based on the distances defined by Formula 7.19 rather than the Euclidean
distances. Descriptors should be autoscaled.
Predictive Quantitative Structure–Activity Relationships Modeling 225
ix. The distance of a query compound i to the model D
i,model
is defined as
the smallest Mahalanobis distance between this compound and all com-
pounds of the training set [27]. It has been shown that for an ensemble of
the Bayesian regularized neural networks, these distances correlate with the
errors of predictions for query compounds.
x. It has been shown that for an ensemble of neural network models, the smaller
standard deviation of predicted activities of query compounds corresponds to
smaller errors of prediction [28].
xi. Distance to a model and standard deviation were combined in one measure
called combined distance, which is the product of the standard deviation and
the distance to the model [29]. Different definitions of distances to a model
are considered in Ref. [30].
7.6 CONSENSUS PREDICTION
The consensus prediction approach is based on the central limit theorem [31], which
can be formulated as follows. If X
1
, X
2
, ..., X
n
is a sequence of random variables
from the same distribution with mean μ and variance σ
2
, then for sufficiently large
n, the average X has approximately normal distribution with mean μ and variance
σ
2
/n. Thus, ideally, if we use top predictive models with identical predictive power,
consensus prediction of a compound’s activity is expected to give better (or at least
more stable) prediction (or at least more stable) accuracy than each of the individual
models. Now let us include more and more predictive models in our consensus pre-
diction. As soon as all these models have comparable predictive power, the accuracy
of prediction in terms of the variance will continue to increase. But when we start to
include models with lower predictive power, the error of consensus prediction starts
to increase and the prediction accuracy and precision typically go down. The consen-
sus prediction of biological activity for an external compound on the basis of several
QSAR models is more reliable and provides better justification for the experimental
exploration of hits.
External evaluation set compounds are predicted by models that have passed all
validation criteria described in Sections 7.3 and 7.4. Each model has its own AD, and
each compound is predicted by all models for which it is within the corresponding
AD. Actually, each external compound should be within the AD of the training set
within the entire descriptor space as well; see Section 7.5 (vi). A useful parameter for
consensus prediction is the minimum number (or percentage) of models for which a
compound is within the AD; it is defined by the user. If the compound is found within
theAD of a relatively small number of models, it is considered to be outside of theAD.
Prediction value is the average of predictions by all these models. If the compound
is predicted by more than one model, the standard deviation of all predictions by
these models is also calculated. For classification and category QSAR, the average
prediction valueis rounded to the closest integer (which is a class or category number);
in the case of imbalanced datasets, rounding can be done using the moving threshold
(see Section 7.2).
Predicted average classes or categories (before rounding), which are closer to the
nearest integers, are considered more reliable [24]. Using these prediction values, the
226 Handbook of Chemoinformatics Algorithms
AD can be defined by a threshold of the absolute difference between the predicted
and the rounded predicted activity. For classification and category QSAR, the same
prediction accuracy criteria are used as for the training and test sets (see Formulas
7.8 through 7.17). The situation is more complex for the continuous QSAR. In this
case, if the range of activities of the external evaluation set is comparable to that
for the modeling set, criteria 7.1 through 7.4 are used. If calculations with multiple
external evaluation sets are carried out, and all external evaluation sets are obtained in
the manner of external leave-group-out cross-validation, criteria 7.1 through 7.4 can
be used as well. Sometimes, however, the external evaluation set may have a much
smaller range of activities than the modeling set; hence, it may not be possible to
obtain a sufficiently large R
2
value (and other acceptable statistical characteristics)
for it. In this case, we recommend using the MAE or the SEP in the following way
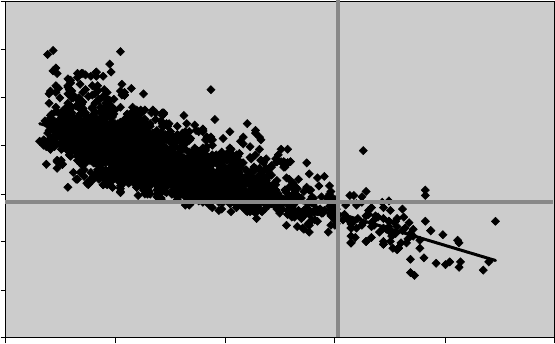
(Figure 7.2).
i. Build a plot of MAE or SEP against R
2
for the prediction of the test sets by
models used in consensus prediction.
ii. On the plot, build straight lines for the threshold R
2
value (see Figure 7.2) and
the corresponding MAE or SEP value for the external evaluation set. These
lines are parallel to coordinate axes.
iii. If there are many models (e.g., more than 10% of the total number of models
used in consensus prediction) in the upper right quadrant defined by the lines
builton step (ii), then the prediction of the external evaluation set is acceptable;
otherwise it is unacceptable. Actually, the greater the number of models in
this area, the better the prediction of the external evaluation set.
y
=
–0.34x + 0.47
R
2
= 0.59
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0 0.2 0.4 0.6 0.8 1
RMSD
RMSD = f(R
2
) 2866 models
R
2
FIGURE 7.2 Prediction power for the external evaluation set.
Predictive Quantitative Structure–Activity Relationships Modeling 227
We have used consensus prediction in many studies [2,3,24,32–35] and have shown
that, in most cases, it gives better prediction and coverage than most of the individ-
ual predictive models. Thus, we recommend using consensus prediction for virtual
screening of chemical databases and combinatorial libraries for finding new lead
compounds for drug discovery.
About 2866 models were built for a dataset of anticonvulsants. The dataset con-
sisted of 91 compounds; 15 compounds were randomly selected as the external
evaluation set, and a modeling set of 76 compounds was divided into training and test
sets using the sphere-exclusion algorithm. Consensus prediction of the external eval-
uation set by acceptable models (for all these models, LOO cross-validation q
2
≥ 0.5
and R
2
≥ 0.6 for the test set; other statistics [see Formulas 7.2 through 7.4] were also
acceptable) gave SEP = 0.286. Is this prediction acceptable? Each dot on the plot cor-
responds to prediction of a test set by one model built using the corresponding training
set. Points corresponding to acceptable models are on the right side of the vertical thick
line. The horizontal red line corresponds to SEP = 0.286 for the external evaluation
set. There are only seven points in the top right quadrant, while there are 110 models
with R
2
≥ 0.6. Hence, consensus prediction of the external evaluation set is poor.
7.7 CONCLUDING REMARKS
In both Chapters 6 and 7, we have discussed the need for developing reliable QSAR
models that could be employed for accurate activity (or property) prediction of
external molecules. We have considered some of the most important components
of the QSAR modeling workflow. Particular attention was paid to the issue of model
validation. It is important to recognize that all the steps of the workflow described
in these two chapters should be carried out; skipping any of these steps may lead to
models with poor prediction for external compounds, that is, those that were not used
in model building or selection, which will essentially undermine the entire exercise.
For example, the presence of structural and/or activity outliers in the modeling set may
lead not only to poor models, but (what is even worse) to models with overestimated
q
2
and R
2
(Figure 7.3). Thus, we cannot agree with the following statement [36]:
“Outliers are compounds which are predicted incorrectly—with large residual.” Too
small training sets may also result in the impossibility to build predictive models, or
(what is even worse) in models with delusively good statistics. Too small test sets can
lead to statistically insignificant results, because the null hypothesis that the model
predicts no better than random selection cannot be rejected with a reasonable sig-
nificance level. Incorrect target functions for biased datasets can give overestimated
(or sometimes underestimated) prediction accuracy. Without rigorous validation of
QSAR models including making predictions for compounds in the external evalua-
tion set, there is no empirical evidence that the models are externally predictive at all
and that they can be used in virtual screening. Without establishing the model AD,
activities of compounds with no similarity to those for which the model was built will
be predicted, which makes no sense at all.
The entire process of combi-QSAR modeling can be almost entirely automated.
In this scenario, ideally, a user can be given an opportunity to select descriptor col-
lections and model development procedures. Then descriptor matrices (Table 6.1) are