Desurvire E. Classical and Quantum Information Theory: An Introduction for the Telecom Scientist
Подождите немного. Документ загружается.


9.2 Data compression 157
L
∗∗
= 4.577 bit/symbol and
˜
L = 4.212 bit/symbol, respectively, we obtain:
r
∗∗
= 1 −
L
∗∗
5
= 1 −
4.577
5
= 8.46% (Shannon–Fano),
˜
r = 1 −
˜
L
5
= 1 −
4.212
5
= 15.76% (Huffman).
The above compression rates may look modest, and indeed they are when considering
the specific example of the English language. Recall that the mean codeword length
cannot be lower than the source entropy H . Thus, there exists no code for which L < H .
Since, in this example, the source entropy is H = 4.185 bit/symbol, we see that the
compression rate is intrinsically limited to r = 1 − 4.185/5 = 16.3%. But this limit
cannot be reached, since no code can beat the Huffman code, and
˜
r = 15.76%, thus,
represents the really achievable compression limit for this source example.
Here we come to a fine point in the issue of data compression. It could have been
intuitively concluded that, given a source, the compression rate is forever fixed by the
coding algorithm that achieves compression. But as it turns out, the compression rate also
depends on the source distribution itself. To illustrate this point, consider four different
ASCII text sources and check how Huffman compression works out for each of them.
Here are three English sentences, or “datafiles,” which have been made (ridiculously so)
nontypical:
Datafile 1: “Zanzibar zoo zebra Zazie has a zest for Jazz”
Datafile 2: “Alex fixed the xenon tube with wax”
Datafile 3: “The sass of Sierra snakes in sunny season”
The above sentences are nontypical in the fact that certain letters are unusually redundant
for English. Therefore, the frequency distributions associated with the symbol-characters
used are very different from average English text sources. For comparison purposes, we
introduce a fourth example representing an ordinary English sentence of similar character
length:
Datafile 4: “There is a parking lot two blocks from here”
We shall now analyze how much these four sources (or datafiles) can be compressed
through Huffman coding. Table 9.2 shows the corresponding symbol-character fre-
quencies and distributions (overlooking spaces and upper or lower case differences),
codeword assignment, mean codeword length, and compression rate, taking for ref-
erence the fixed-codeword length L
ref
=log
2
26=5, corresponding to a restricted,
five-bit ASCII code.
It is seen from the results in Table 9.2 that the compression ratio varies from 20%
(datafile 4) to about 35% (datafile 3). The difference in compression ratio cannot be
attributed to the datafile length: the best and the worst results are given by datafiles
having the same length of 34–35 characters. With only 28 characters, the shortest
datafile (datafile 2) has a compression ratio of only 27%. The number of different
characters is about the same for datafiles 1–3, but the compression ratio varies from 27%

Table 9.2 Examples of file compression through Huffman coding based on the four sentences shown in the text. For each file, the tables list the characters (
x
), their frequency (
f
), their
probability (
p
(
x
)), the codeword assignment (CW), and the codeword length (
l
(
x
)).
Datafile 1 (zebra) Datafile 2 (xenon) Datafile 3 (snakes) Datafile 4 (parking)
xfp(x)CWl(x) l(x)p(x)xf p(x)CWl(x) l(x)p(x)xf p(x)CWl(x) l(x)p(x)xf p(x)CWl(x) l(x)p(x)
Z 9 0.2500 10 2 0.500 E 5 0.1786 11 2 0.357 S 9 0.2647 01 2 0.529 E 4 0.1143 100 3 0.343
A 7 0.1944 11 2 0.389 X 4 0.1429 000 3 0.429 N 5 0.1471 000 3 0.441 O 4 0.1143 011 3 0.343
E 3 0.0833 0001 4 0.333 T 3 0.1071 0010 4 0.429 A 4 0.1176 110 3 0.353 R 4 0.1143 010 3 0.343
O 3 0.0833 0010 4 0.333 A 2 0.0714 0101 4 0.286 E 4 0.1176 111 3 0.353 T 3 0.0857 1110 4 0.343
R 3 0.0833 0011 4 0.333 H 2 0.0714 0110 4 0.286 I 2 0.0588 1001 4 0.235 A 2 0.0571 0011 4 0.229
B 2 0.0556 1010 4 0.222 I 2 0.0714 0111 4 0.286 O 2 0.0588 1010 4 0.235 H 2 0.0571 0010 4 0.229
I 2 0.0556 1011 4 0.222 N 2 0.0714 1000 4 0.286 R 2 0.0588 1011 4 0.235 I 2 0.0571 0001 4 0.229
S 2 0.0556 00000 5 0.278 W 2 0.0714 1001 4 0.286 F 1 0.0294 00100 5 0.147 K 2 0.0571 0000 4 0.229
F 1 0.0278 00001 5 0.139 B 1 0.0357 1010 4 0.143 H 1 0.0294 00101 5 0.147 L 2 0.0571 11111 5 0.286
H 1 0.0278 10000 5 0.139 D 1 0.0357 1011 4 0.143 K 1 0.0294 00110 5 0.147 S 2 0.0571 11110 5 0.286
J 1 0.0278 10001 5 0.139 F 1 0.0357 00110 5 0.179 T 1 0.0294 00111 5 0.147 B 1 0.0286 11011 5 0.143
N 1 0.0278 10010 5 0.139 L 1 0.0357 00111 5 0.179 U 1 0.0294 10000 5 0.147 C 1 0.0286 11010 5 0.143
T 1 0.0278 10011 5 0.139 O 1 0.0357 01111 5 0.179 Y 1 0.0294 10001 5 0.147 F 1 0.0286 11001 5 0.143
C 0 0.0000 U 1 0.0357 01001 5 0.179 B 0 0.0000 G 1 0.0286 11000 5 0.143
D 0 0.0000 C 0 0.0000 C 0 0.0000 M 1 0.0286 10111 5 0.143
G 0 0.0000 G 0 0.0000 D 0 0.0000 N 1 0.0286 10110 5 0.143
K 0 0.0000 J 0 0.0000 G 0 0.0000 P 1 0.0286 10101 5 0.143
L 0 0.0000 K 0 0.0000 J 0 0.0000 W 1 0.0286 10100 5 0.143
M 0 0.0000 M 0 0.0000 L 0 0.0000 D 0 0.0000
P 0 0.0000 P 0 0.0000 M 0 0.0000 J 0 0.0000
Q 0 0.0000 Q 0 0.0000 P 0 0.0000 Q 0 0.0000
U 0 0.0000 R 0 0.0000 Q 0 0.0000 U 0 0.0000
V 0 0.0000 S 0 0.0000 V 0 0.0000 V 0 0.0000
W 0 0.0000 V 0 0.0000 W 0 0.0000 X 0 0.0000
X 0 0.0000 Y 0 0.0000 X 0 0.0000 Y 0 0.0000
Y 0 0.0000 Z 0 0.0000 Z 0 0.0000 Z 0 0.0000
36 1.0000 28 1.0000 34 1.0000 35 1.0000
Mean CW
length
(bit/symbol)
3.306 3.643 3.265 4.000
Compression
ratio
33.89% 27.14% 34.71% 20.00%

9.2 Data compression 159
to 34.7%. A closer look at the table data shows that the factor that appears to increase the
compression ratio is the frequency spread in the top group of most frequent characters.
If the most frequent characters have dissimilar frequencies, then shorter codewords can
be assigned to a larger number of symbols. We observe that the first three datafiles,
corresponding to nontypical English texts, lend themselves to greater compression than
the fourth datafile, corresponding to ordinary English. There is no need to go through
tedious statistics to conclude beforehand that increasing the length of such English-text
datafiles would give compression ratios increasingly closer to the limit of
˜
r = 15.76%.
Clearly, this is because the probability distribution of long English-text sequences will
duplicate with increasing fidelity the standard distribution for which we have found this
compression limit. On the other hand, shorter sequences of only a few characters might
have significantly higher compression ratios. To take an extreme example, the datafile
“AAA” (for American Automobile Association) takes 1 bit/symbol and, thus, has a
compression ratio of r = 1 −1/5 = 80%. If we take the full ASCII code for reference
(7 bit/character), the compression becomes r = 1 −1/7 = 85.7%.
7
The above examples have shown that for any given datafile, there exists an optimal
(Huffman) code that achieves maximum data compression. As we have seen, the code-
word assignment is different for each datafile to be compressed. Therefore, one needs to
keep track of which code is used for compression in order to be able to recover the orig-
inal, uncompressed data. This information, which we refer to as overhead, must then be
transmitted along with the compressed data, which we refer to as payload. Since the over-
head bits reduce the effective compression rate, it is clear that the overhead size should
be the smallest possible relatively to the payload. In the previous examples, the overhead
is simply the one-to-one correspondence table between codewords and symbols. Using
five-bit (ASCII) codewords to designate each of the character symbols, and a five-bit
field to designate the corresponding compressed codewords makes a ten-bit overhead
per datafile symbol. Taking, for instance, datafile 3 (Table 9.2), there are 13 symbols,
which produces 130 bits of overhead. It is easily calculated that the payload represents
111 bits, which leads to a total of 130 + 111 = 241 bits for the complete compressed
file (overhead + payload). In contrast, a five-bit ASCII code for the same uncompressed
datafile would represent only 170 bits, as can also be easily verified. The compressed
file thus turns out to be 40% bigger than the uncompressed one! The conclusion is that
7
This consideration illustrates the interest of acronyms. Their primary use is to save text space, easing up
reading and avoiding burdensome redundancies. This is particularly true with technical papers, where the
publication space is usually limited. An equally important use of acronyms is to capture abstract concepts into
small groups of characters, for instance ADSL (asymmetric digital subscriber line) or HTML (hypertext
markup language). The most popular acronyms are the ones that are easy to remember, such as FAQ
(frequently asked questions), IMHO (in my humble opinion), WYSIWYG (what you see is what you get),
NIMBY (not in my backyard), and the champion VERONICA (very easy rodent-oriented netwide index to
computerized archives), for instance. The repeated use of acronyms makes them progressively accepted as
true English words or generic brand names, to the point that their original character-to-word correspondence
is eventually forgotten by their users, for instance: PC for personal computer, GSM for global system for
mobile [communications], LASER for light amplification by stimulated emission of radiation, NASDAQ for
National Association of Securities Dealers Automated Quotations, etc. Language may thus act a natural self-
compression machine, which uses the human mind as a convenient dictionary. In practice, this dictionary is
only rarely referred to, since the acronym gains its own meaning by repeated use.

160 Optimal coding and compression
compression can be efficient with a given datafile, but it is a worthless operation if the
resulting overhead (needed to decompress the data) is significantly larger than the pay-
load. But the “overhead tax” is substantially reduced when significantly longer datafiles
are compressed. The case of plain English-text datafiles is not the best example, because
as their size increases the symbol probability distribution becomes closer to that of the
standard English-source reference, for which (as we have shown) the compression ratio
is limited to
˜
r = 15.76%.
8
One can alleviate the overhead tax represented by the coding-tree information by
using a standard common reference, which is called the codebook. Such a codebook
contains different optimal coding trees for generic sources as varied as standard lan-
guages (English, French, German, etc.), programming-language source codes (C
++
,
Pascal, FORTRAN, HTML, Java, etc.), tabulated records (students, payroll, company
statistics, accounting, etc.), or just raw binary datafiles, for instance. An optimal cod-
ing tree devised for all inventoried source types can also be included in the codebook.
Choosing a specific coding tree from the codebook is called semantic-dependent coding.
This choice means that one has prior knowledge of the type of source or source semantics
considered, and this knowledge guides the choice of the most appropriate code to select
from the codebook menu.
If the codebook contains N coding trees for these different sources, the overhead
only represents log
2
N bits. This overhead must be included at the beginning of the
compressed file, to indicate which coding tree (or source mapping) has been used for
compression. The coding efficiency (or compression ratio) obtained with a codebook is
never greater than that obtained with a case-specific Huffman coding. However, if one
includes the overhead bits in the compressed file, the conclusion could be the opposite.
Indeed, a 1985 experiment consisted in comparing results obtained by compressing
different types of programming-language source codes (out of 530 programs), using
either a codebook or case-by-case Huffman coding, the corresponding overheads being
included into each computation.
9
The result was that the codebook approach always
produced higher compression ratios. The conclusion is that, taking into account the
overhead, a nonoptimal coding tree picked from a generic codebook may yield a better
compression performance than a case-specific Huffman coding tree. Other studies have
sought to generate a universal codebook tree, which could apply indifferently to English,
French, German, Italian, Spanish, or Portuguese, for instance. The spirit of the approach
and procedure can be described as follows. First, an optimal coding tree is computed
with all sources combined (taking for database reference the full contents of a number of
recent newspapers, magazines, books, and so on from each language). Second, optimal
coding trees are computed for each individual source. The task then is to identify what
the different trees share in common and devise the universal tree accordingly, subject to
certain constraints to be respected for each language source.
8
Under the simplifying assumption of a single A–Z alphabet without spaces, punctuation, or any other
symbols.
9
See R. M. Capocelli, R. Giancarlo, and I. J. Taneja, Bounds on the redundancy of Huffman codes. IEEE
Trans. Infor. Theory, 32 (1986), 854–7.
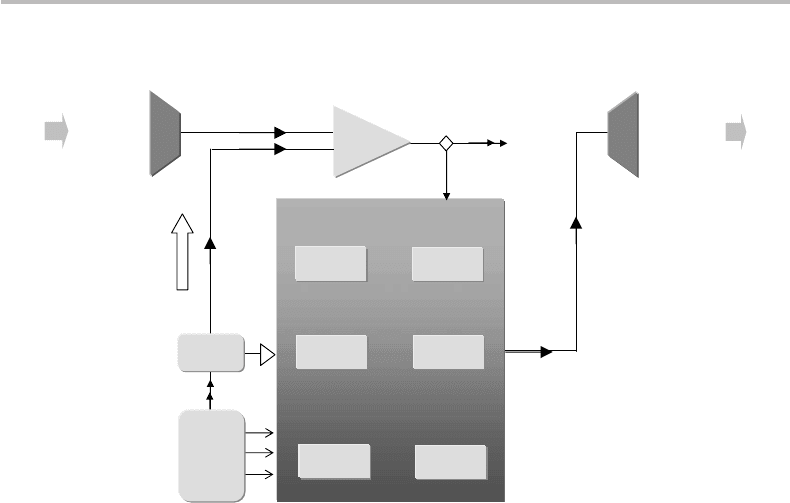
9.2 Data compression 161
Uncompressed
source
X
k
x
Symbol
Input
Comparison
Look-up memory
(compression)
scan
start
stop
CLK
AND
Control
0 Continue
1 Extract
... ...
...
look
...
Codeword
Symbol Codeword
1
y
1
x
k
y
k
x
n
x
n
y
Output
k
y
Compressed
source
Extract
Y
Figure 9.3 Generic implementation of data compression from source X (uncompressed source
symbols x
k
) into source Y (compressed codewords y
k
) through a memory look-up system. The
operation of decompression is the same, with the roles of Y and X being interchanged.
The same code-compression techniques and conclusions apply to data sources far
more complex than text, such as digital sound and still or motion pictures. Such sources
contain large amounts and varieties of random symbols, whose frequency distributions
significantly depart from the uniform and exponential generic types. As we have seen,
this makes compression algorithms all the more efficient. Since the files can be made
arbitrarily large, the overhead tax can become relatively insignificant. Case-specific
compression based on Huffman coding (referred to as Huffman compression) is widely
used in telecom devices such as faxes and modems, and in multimedia applications with
well known standards for music, images, and video, known as MP3, JPEG, and MPEG,
for instance. A brief overview of common compression standards is given in Appendix G.
The task of compressing sound and pictures is, however, made more complex because
the source’s probability distribution is inherently unknown, and no generic codebook
may exist or prove effective. A solution to this problem is referred to as adaptive coding,
where optimal coding trees are devised “on the fly” as new source symbols come in the
sequence. This will be described in Chapter 10.
The reverse operation of back-translating a coded datafile or a codeword sequence,
is called decompression. Figure 9.3 illustrates the generic system layout used for code
compression or decompression. As the figure shows, a dedicated memory provides the
one-to-one correspondence between source symbols and codewords (compression) or
the reverse (decompression). The operation of extracting the information stored in the

162 Optimal coding and compression
memory is called table look-up. The memory is scanned address by address, until the
symbol (or codeword) is found, in which case the corresponding codeword (or symbol)
is output from the memory. It is, basically, the same operation as if we look at Table 9.1
(the memory) to find the codeword for the source character U (the output or answer
being 10111), or to find the source character for the codeword 110000100 (the output or
answer being J). Note that decompression with a Huffman code is easier than with any
other code, because we know from the codeword length and prefix where to look at in the
memory. For a machine, it takes a simple program to determine at what memory location
to start the look-up search, given the codeword size and prefix bits. For block codes (see
next section), the compression/decompression operation is similar, but compression
first requires arranging the input symbols into sequences of predefined size (e.g., bytes
for binary data). As Fig. 9.3. illustrates, the compression/decompression apparatus is
completed with a control subsystem ensuring a certain number of generic functions,
including synchronization between the input symbol or codewords and the memory.
Assigning individual codewords to each source symbol, in a way that is uniquely
decodable, corresponds to what is called lossless compression. The idea conveyed by
this adjective is that no information is lost through the compression. Assuming that
the compressed source remains unaltered by storage or transmission conditions, the
reverse operation of code decompression results in a perfect restitution of the original
symbol sequence, with no alteration or error. In contrast, lossy compression algorithms
cause some information loss, which translates into errors upon decompression. This
information loss, and the restitution errors, is sufficiently minor to remain unnoticed, as
in a sound track or a movie picture. Such lossy compression algorithms are inherently
not applicable to data files, where absolute exactness is a prerequisite, as in any text
document (press, literature, technical) or tabulated data (services, finance, banking,
records, computer programs).
9.3 Block codes
So far in this chapter, I have described different codes with either fixed-length or variable-
length codewords. In this section, we shall consider yet another coding strategy, which
consists in encoding the symbols by blocks. The result is a block code, a generic term,
which applies to any code that manipulates groups of codewords, either by concatenation
or by the attribution of new codewords for specific groups of source symbols.
Most generally, block codes can be attributed different “sub-blocks” or fields.For
instance, a given field can be reserved for the payload (the sequence of codewords to be
transmitted) and another field to the overhead (the information describing how to handle
and decompress the payload). Block codes are used, for instance, in error-correction,
which will be described in Chapter 11. Here, we shall focus on the simplest type of
block codes, which make it possible to encode source symbols with higher bit/codeword
efficiency. As we shall see, block coding results in significantly longer codewords, and
the codeword dictionary is also significantly greater. The key advantage is that the mean
bit/codeword is considerably reduced, which enables much more data to be packed per

9.3 Block codes 163
Block
symbol
p
Block
codeword
0.25
x
1
x
1
0.600.400.35 1 1.00
10
0.35
0.250.200.20
0.190.160.10
0.10
x
1
x
2
1 0.40 0
010
0.200.20
0.190.160.100.10
0.10
x
1
x
3
1 0.25 0 001
0.19
0.160.100.100.10
0.10
x
2
x
1
1
0.20
0
000
0.10
0.10
0.10
0.10
0.10
x
3
x
1
1
0.16 0
1111
0.10
0.100.10
0.090.08
0.08
0.05
0.05
x
1
x
4
1 0.10 0
0110
0.100.09
0.080.080.050.05
0.05
x
4
x
1
1 0.10 0
11101
0.080.080.050.050.050.040.04
x
2
x
2
1 0.09 0
11011
0.050.050.050.040.040.04
x
2
x
3
1 0.08 0 11010
0.050.040.040.040.04
x
3
x
2
1 0.05 0
11001
0.040.040.040.04
x
3
x
3
1 0.04 0
11000
0.040.040.030.02
x
2
x
4
1
0.04 0
01110
0.030.020.02
x
3
x
4
1 0.04
0
111001
0.020.02
x
4
x
2
1 0.02
0
111000
0.02
x
4
x
3
1 0.02 0 011111
0.01
x
4
x
4
0
011110
Figure 9.4 Block coding by symbol pairs x
i
x
j
of the source X ={x
1
, x
2
, x
3
, x
4
}, with respective
probabilities p(x) ={0.5, 0.2, 0.2, 0.1} through the Huffman-coding algorithm. The column at
left shows the block codeword probabilities in decreasing order. The column at right shows the
block codeword assignment resulting from the algorithm implementation.
transmitted bit. I shall illustrate this property with three examples, which have also been
designed to make the subject entertaining.
Example 9.1: Four-event source
Consider the four-event source X ={x
1
, x
2
, x
3
, x
4
} previously analyzed in Fig. 9.1,
which is defined by the distribution p(x) ={0.5, 0.2, 0.2, 0.1}. As we have seen,
its entropy is H(X ) =1.76 bit/symbol, and its optimal mean length (Huffman
coding) is L(X ) =1.80 bit/symbol. The corresponding coding efficiency is η =
1.76/1.80 = 97.8%. We shall now implement block-coding by grouping the sym-
bols in ordered pairs (x
i
x
j
), forming the new and extended 16-event source
X
={x
1
x
1
, x
1
x
2
, x
1
x
3
,...,x
4
x
2
, x
4
x
3
, x
4
x
4
} with associated probabilities p(x
i
x
j
) =
p(x
i
)p(x
j
), the events being assumed to be independent. It is a patient exercise to
determine the Huffman code for X
. The result is shown in Fig. 9.4, with details and
results summarized in Table 9.3. We find that the extended source entropy is H (X
) =
3.522 bit/symbol, which is equal to 2H(X), as expected for a source of joint independent
events. Then we find that the mean codeword length is L(X
) =3.570 bit/word. The cod-
ing efficiency is, therefore, η = 3.522/3.570 = 98.65%, which is an improvement on the
previous efficiency η = 97.77% of the single-codeword Huffman code. Since each block
code represents a pair of symbols, the actual mean symbol length is L(X
)/2 = 1.78 bit/
symbol. This reduction in symbol length may look small with respect to L(X) =
1.80 bit/symbol for the single-symbol code but, as we have seen, it has a noticeable
impact on coding efficiency.
We can continue to improve the coding efficiency by grouping symbols in ordered
triplets (x
i
x
j
x
k
), quadruplets (x
i
x
j
x
k
x
l
), or n-tuplets (x
i
x
j
x
k
,...,x
#
) of arbitrary large
sizes, corresponding to a source X
(n)
assigned with 4
n
individual codewords. The source
X
(n)
is referred to as the nth extension of the source X .
As we know well from Shannon’s source-coding theorem,(Chapter 8), the mean code-
word length is
ˆ
L(X
(n)
) ≥ H (X
(n)
) = nH(X). For large n,wehave
ˆ
L(X
(n)
) ≈ nH(X),

Table 9.3 Block coding by symbol pairs x
i
x
j
of the source X ={x
1
, x
2
, x
3
, x
4
}, with respective probabilities p(x) ={0.5, 0.2, 0.2, 0.1} through the Huffman coding
algorithm. The table at left shows the block codeword probabilities and the corresponding entropy of the extended source X
={x
1
x
1
, x
1
x
2
, x
1
x
3
,...x
4
x
2
, x
4
x
3
, x
4
x
4
}.
The table at right shows the block symbols ordered in decreasing probabilities with their Huffman block-codeword assignment.
Block p
ij
= Block Block
Symbol i Symbol jp(x
i
) p(x
j
) symbol p(x
i
)p(x
j
) −p
i
p
j
log
2
p
ij
symbol p
ij
codeword l(x
i
x
j
) p
ij
l(x
i
x
j
)
x
1
x
1
0.5 0.5 x
1
x
1
0.250 0.500 x
1
x
1
0.250 10 2 0.500
x
2
0.5 0.2 x
1
x
2
0.100 0.332 x
1
x
2
0.100 010 3 0.300
x
3
0.5 0.2 x
1
x
3
0.100 0.332 x
1
x
3
0.100 001 3 0.300
x
4
0.5 0.1 x
1
x
4
0.050 0.216 x
2
x
1
0.100 000 3 0.300
x
2
x
1
0.2 0.5 x
2
x
1
0.100 0.332 x
3
x
1
0.050 1111 4 0.400
x
2
0.2 0.2 x
2
x
2
0.040 0.186 x
1
x
4
0.040 0110 4 0.200
x
3
0.2 0.2 x
2
x
3
0.040 0.186 x
4
x
1
0.040 11101 5 0.250
x
4
0.2 0.1 x
2
x
4
0.020 0.113 x
2
x
2
0.020 11011 5 0.200
x
3
x
1
0.2 0.5 x
3
x
1
0.100 0.332 x
2
x
3
0.100 11010 5 0.200
x
2
0.2 0.2 x
3
x
2
0.040 0.186 x
3
x
2
0.040 11001 5 0.200
x
3
0.2 0.2 x
3
x
3
0.040 0.186 x
3
x
3
0.040 11000 5 0.200
x
4
0.2 0.1 x
3
x
4
0.020 0.113 x
2
x
4
0.020 01110 5 0.100
x
4
x
1
0.1 0.5 x
4
x
1
0.050 0.216 x
3
x
4
0.050 111001 6 0.120
x
2
0.1 0.2 x
4
x
2
0.020 0.113 x
4
x
2
0.020 111000 6 0.120
x
3
0.1 0.2 x
4
x
3
0.020 0.113 x
4
x
3
0.020 011111 6 0.120
x
4
0.1 0.1 x
4
x
4
0.010 0.066 x
4
x
4
0.010 011110 6 0.060
1.000 1.000
Extended source
entropy
3.522
Mean block length 3.570
bit/word
Efficiency 98.65%

9.3 Block codes 165
or
ˆ
L(X
(n)
)/n ≈ H(X ) =1.76 bit/symbol and for the coding efficiency, η ≈ 100%. This
example shows that one can reach the theoretical limit of 100% coding efficiency with
arbitrary accuracy, but at the price of using an extended dictionary of codewords, most
with relatively long lengths.
Example 9.2: 26-event source; the English-language characters
Block coding may not be so practical when applied to sources having more than two
events. This is because Huffman coding is very close to being the most efficient, and the
extra complexity introduced by using an extended source with a long list of variable-
length codewords is not so much worth it. To illustrate this point, consider the case
of the English language. For simplicity, it can be viewed as a 26-event source, namely
producing the A–Z symbol characters, which we call X
(1)
. The key question we want
to address here is: “Could one use a different alphabet and its associated block code
to convey more information in any length of text?” Indeed, is it possible to squeeze
a piece of English text by means of a super-alphabet? One may conceive of such a
super-alphabet as being made from character pairs (also called digrams), representing
altogether 26 × 26 = 676 new symbol characters. Thus, all English books and written
materials using this super-alphabet would be twice as short as the originals! This would
reduce their production costs, their price and weight, and possibly they could be faster to
read. But such improvements would be at the expense of having to learn and master the
use of 676 different characters.
10
Here, the point is not to propose changing the English
alphabet, but rather to analyze how text information could be compressed for saving
memory space and speeding up transmission between computers. To build this new
code, we ought to assign the shortest codewords to the most frequently used digrams,
10
Two illustrative examples of “super-alphabets” are the symbolic/ideographic/logogram kanjis of the Chinese
and Japanese languages. In Japanese, children must learn 1006 kanjis (Gakushuu) over a six-year elementary
school cycle. To read Japanese newspapers one must master 1945 official kanjis (J
¯
oy
¯
o). The J
¯
oy
¯
o extends
to 2928 kanjis when including people’s names. Note that written Japanese is completed with two syllabary
alphabets (Hiragana and Katakana), each having 46 different characters. In modern Chinese, literacy
requires mastering about 3000 kanjis, while educated people may know between 4000 and 5000 kanjis.
Comprehensive Chinese dictionaries include between 40 000 and 80 000 kanjis. These impressive figures
should not obscure the fact that Western languages also have phenomenal inventories of dictionary words,
despite their limited 26-character (or so) alphabets. Apart from technical literature, a few thousand words
are required to master reading and writing English, with up to 10 000 for the most educated people. The
inventories of French and German come to 100 000 to 185 000 words, while English is credited with a
whopping 500 000 words (750 000 if old English is included). As with oriental languages, it is not clear,
however, if such a profusion of language “codewords” is truly representative of any current or relevant
use. Another consideration is that words in Western languages are usually recognized “at once” by the
educated human brain, without detailed character-by-character analysis, which in fact makes alphabetical
codewords similar to super-alphabetical symbols, just like Chinese or Japanese kanjis. The latter might
be more complex to draw and to memorize (especially concerning their individual phonetics!), but they
have a more compact form than the alphabet-based Western “codewords.” However, the key advantage
of languages using limited-size alphabets (such as based on 26 characters, and 28 or 29 for Swedish or
Norwegian) is the easiness to learn, read, pronounce, and write words, especially in view of handwriting
skills and adult personalization. With super-alphabets, these different tasks are made far more difficult
(without considering complex spelling and pronunciation rules).
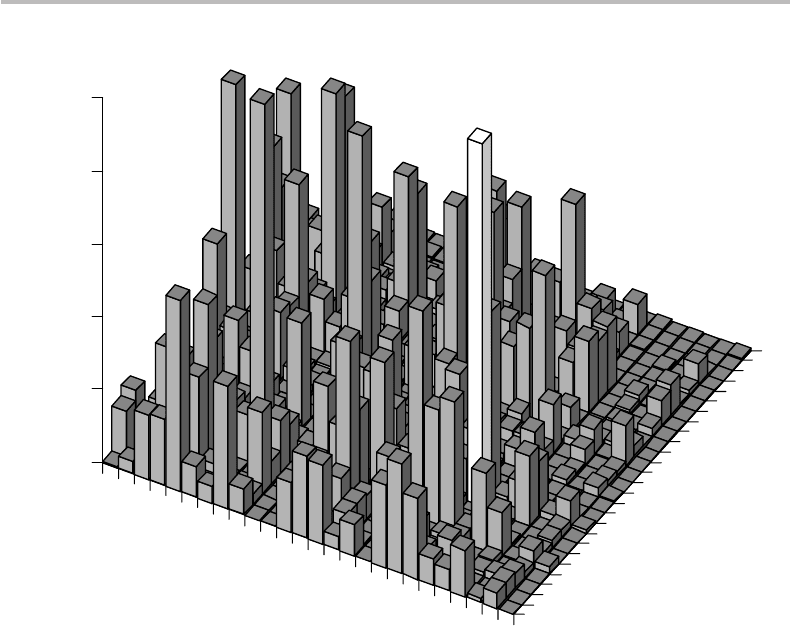
166 Optimal coding and compression
1
3
5
7
9
11
13
15
17
19
21
23
25
S1
S4
S7
S10
S13
S16
S19
S22
S25
0.000
0.005
0.010
0.015
0.020
0.025
Conditional count
Figure 9.5 Two-dimensional histogram of the 26 × 26 = 676 English-letter digrams. Each row,
corresponds to the distribution of counts c(y|x), where x is the first letter of the digram. The
front row corresponds to the distribution c(A|x). The most frequent English digram, TH,
corresponding to c(H |T ) is highlighted.
and the longest codewords to the less frequently used ones. A two-dimensional histogram
obtained by counting the frequency of English digrams xy out of a 10 000-letter text
is shown in Fig. 9.5.
11
Each of these counts is noted c(y|x), see note.
12
We can view
these digrams as forming an extended language source X
(2)
, with virtually independent
super-alphabet symbols of probability p(xy) = c(y|x)/10 000.
13
We can then rearrange
them in order of decreasing frequency, as shown in Fig. 9.6 for the leading group
(c(y|x) ≥ 100).
14
From the figure, we observe that the three most frequent digrams are
TH, HE, and AN. It immediately comes to the mind that one could readily change these
11
Plotted after analyzing raw data from: H. Fouch
´
e-Gaines, Cryptanalysis, a Study of Ciphers and Their
Solutions (New York: Dover Publications, 1956).
12
The conversion of the histogram data c(y|x) into conditional probabilities p(y|x )isgiven
by the property N
x
c(y|x) p(x) ≡ p(y) ≡
x
p(y|x)p(x), which gives p(y|x) = Nc(y|x) =
c(y|x) p(y)/
x
c(y|x) p(x).
13
For simplicity, the 27th “space” character was omitted in this count, as reflecting a tradition of old
cryptography; single letters are, therefore, not included, but this does not change the generality of the
analysis, since they can be coded as digrams with “space” as a second character.
14
It is no surprise that we find TH, HE, AN, and IN as the most frequent digrams in English, suggesting an
inflation of words and word prefixes, such as THE, THEN, THERE, HE, HERE, AN, AND, IN, and so on.