Затонский А.В. Пособие по полному жизненному циклу информационных систем
Подождите немного. Документ загружается.


291
Таблица 29
Информационная сущность «KLDOXOD» - ГНИВЦ
Наименование
поля в БД
Тип
(длина)
Тип связи К таблице Наименование в таблице
KOD int(11) 1:M NACH KOD
NAME char(250) Имя
OLDKOD char(2) Старый код
Таблица 30
Информационная сущность «KLVICET» - ГНИВЦ
Наименование
поля в БД
Тип
(длина)
Тип связи К таблице Наименование в таблице
KOD int(11) 1:M NACH KOD
NAME char(250) Имя
OLDKOD char(2) Старый код
Таблица 31
Информационная сущность «UDER» - справочник удержаний
Наименование
поля в БД
Тип
(длина)
Тип связи К таблице Наименование в таблице
VED NXXX
NXXX int(11) 1:M
TAB NXXX
LONG char(25) Полное название
SHORT char(10) Сокращенное название
RASCH char(80) Блок расчета
IN_SUMM bool Суммируемые
IN_SVOD bool В свод
IN_DOPL bool Персональные удержания
IN_FACT bool Из фактического дохода
ZCLC int(1) Порядок расчета
IST int(1) Номер источника
DATETIME char(10)
Дата последних изменений
в таблице
MN int(2) Месяц
YR int(4) Год
Таблица 32
Информационная сущность «IST» - источники финансирования
Наименование
поля в БД
Тип
(длина)
Тип связи К таблице Наименование в таблице
VED UID_ist
UID_ist int(11) 1:M
TAB UID_ist
NAIM char(10) Наименование
Таблица 33
Информационная сущность «SUBPODR» - структура подразделений
Наименование
поля в БД
Тип
(длина)
Тип связи К таблице Наименование в таблице
VED UID_SUBPODR
TAB UID_SUBPODR
UID_SUBPODR int(11) 1:M
OK UID_SUBPODR
NAIM char(30) Наименование
PODR int(1) Родитель

292
Наименование
поля в БД
Тип
(длина)
Тип связи К таблице Наименование в таблице
SCH char(5) Бухгалтерский счет
IST int(1) Номер источника
DATETIME char(10)
Дата последних изменений
в таблице
Таблица 34
Информационная сущность «MN» - настройка месяца
Наименование
поля в БД
Тип
(длина)
Тип связи К таблице Наименование в таблице
VED MN
MN int(2) 1:M
TAB MN
VED YR
YR int(4) 1:M
TAB YR
DINM int(2) Дней в месяце
HINM int(3) Часов в месяце
PROT bool Расчет окончен
RNDF int(2) Округлять
Таблица 35
Информационная сущность «M059_09» - перечисления в АКБ «Урал ФД»
Наименование
поля в БД
Тип
(длина)
Тип связи К таблице Наименование в таблице
FIO char(38) Фамилия, имя, отчество
ACCOUNT char(20) Номер счета
SUMMA int(10) Сумма
VED int(10) M:1 VED Относится к ведомости
Таблица 36
Информационная сущность «PROFESS» - справочник профессий
Наименование
поля в БД
Тип
(длина)
Тип связи К таблице Наименование в таблице
PROFESS int(11) 1:M OK PROFESS
NAIM char(65) Наименование полное
SOCR char(15) Сокращенное название
TERR char(3) Код
OS_USL1 char(6)
OS_USL2 char(15)
Особые условия труда
S_OSN char(7) Основания выслуги
S_MES int(2) Исключение месяцев
S_DAY int(2) Исключение дней
DOPSVED char(13)
Код дополнительных
сведений
V_OSN char(7) Вид особых условий
V_HR int(2) Часов
V_MN int(2) Минут
DATETIME char(10)
Дата последних изменений
в таблице

293
Таблица 37
Информационная сущность «TAB» - табель
Наименование
поля в БД
Тип
(длина)
Тип связи К таблице Наименование в таблице
TIM int(8) Время
DAYS int(2) Рабочих дней
KDAYS int(2) Календарных дней
ZCLC int(1) Уровень расчета
DATETIME char(10)
Дата последних изменений
в таблице
N001 int(10) NACH оклад
… …
SUBPODR int(11) M:1 SUBPODR TAB
IST int(11) M:1 IST TAB
Таблица 38
Информационная сущность «KLADR» - справочник населенных пунктов ГНИВЦ
Наименование
поля в БД
Тип
(длина)
Тип связи К таблице Наименование в таблице
CODE int(11) 1:M MEN CODE
NAME char(40) Название
SOCR char(10) Вид населенного пункта
INDEX char(6) Почтовый индекс
GNINMB char(4) Инспекция ФНС
Таблица 39
Информационная сущность «KLDOK» - справочник видов документов ГНИВЦ
Наименование
поля в БД
Тип
(длина)
Тип связи К таблице Наименование в таблице
KOD int(11) 1:M MEN KOD
NAME char(25) Название
KNAIM char(6) Сокращенное название
KONSER char(29) Вид кода документа
Таблица 40
Информационная сущность «KLSTR» - справочник стран ГНИВЦ
Наименование
поля в БД
Тип
(длина)
Тип связи К таблице Наименование в таблице
KOD int(11) 1:M MEN KOD
NAME char(30) Название
Таблица 41
Информационная сущность «STREET» - справочник улиц ГНИВЦ
Наименование
поля в БД
Тип
(длина)
Тип связи К таблице Наименование в таблице
CODE int(11) 1:M MEN CODE
NAME char(40) Название
SOCR char(10) Вид
INDEX char(6) Почтовый индекс
GNINMB char(4) Номер ФМС
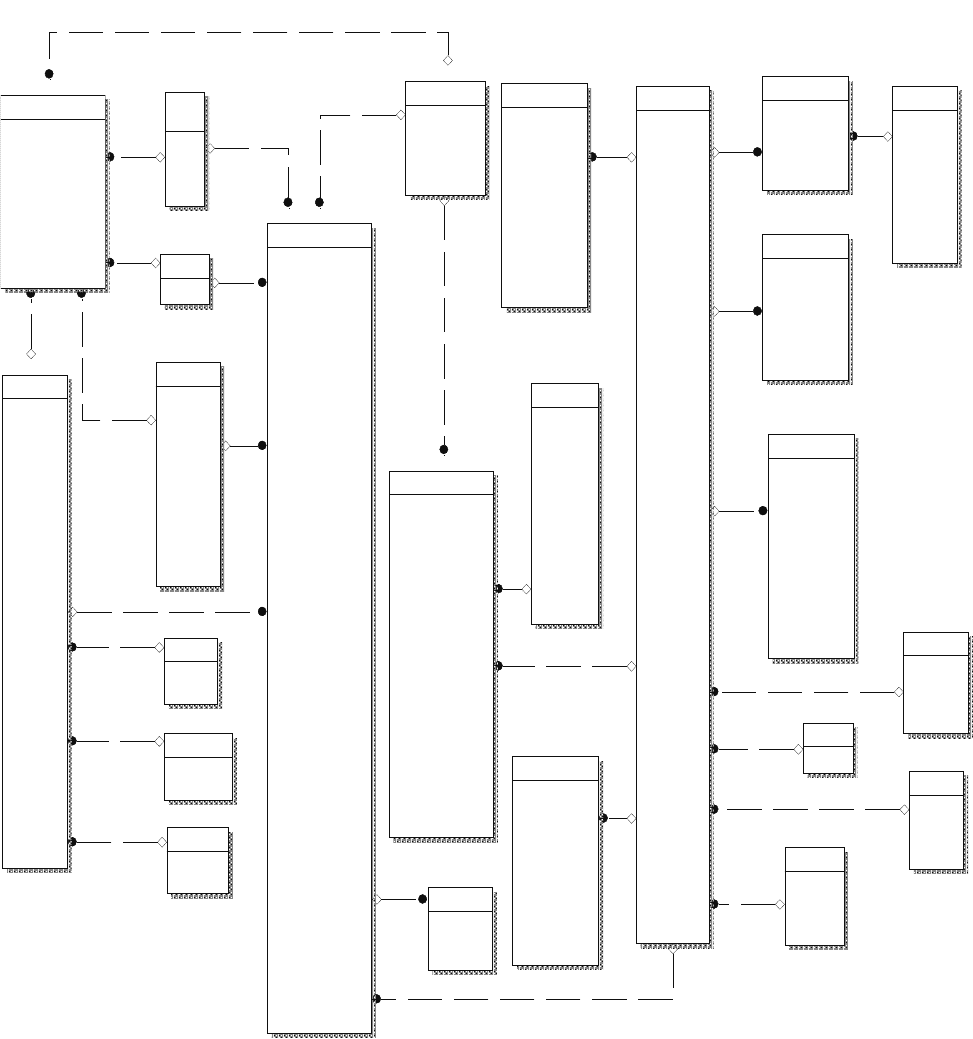
294
BOLN
Dat1
Dat2
Mn
Yr
Sum
Dn
DatReg
Nom
DateTime
Dn2
Sum2
Uid_men (FK)
DOPLATA
Fld
Dat1
Dat2
Sum
Procent
Blc
Osnov
Okr
Ord
DateTime
Uid_men (FK)
IST
UID_ist
Naim
KLDOXOD
Kod
Name
Skidka
KLSKID
Kod
Name
OldKod
KLSTR
Kod
Name
MEN
Uid_men
Fam
Name
Otc
Dser
Dnom
DateRog
Pindex
RegKod
RaiName
TownName
NaspName
UlName
Dom
Korp
Kv
DokKod
Cntr
Ls
Pol
Punkt
Distr
Region
Strana
D_Dok
Kem_Vid
Phone
Ank
Pck
Dok_name
INN
Motp
Insbk
Dat_wrk
Dat_13
Dat_vsl
Dat_uvo
Comment
Mesto
SvidPF
Iscp
Date_Reg
LgotPn
LgotSn
Snv
Inv
LgotMAX
Lg101
Lg102
Polis
DateTime
Code (FK)
Kod (FK)
MHEAD
Uid_mh
Dat
Num
Mn
Yr
Comm
Sum
Ist
Fld
DateTime
MLINE
Sum
Comment
DateTime
Uid_mh (FK)
Uid_men (FK)
MN
Mn
Yr
Dinm
Hinm
Prot
Rndf
MO59_09
FIO
Account
Summa
NACH
Nxxx
Long
Short
IN_Fzp
IN_Med
IN_Otp
IN_Bol
IN_Kft
IN_Pfr
IN_Svod
IN_Summ
IN_Tab
IN_Vsgd
IN_Dopl
IN_Fact
Obl_Pf
Obl_Al
Obl_II
Rasch
Gni1
Gni2
Zclc
Skidpn
Skidsn
Ist
DateTime
Mn
Yr
Obl_Fss
Kod (FK)
Ok
Tabn
LgotDet
Oklad
Prof
Rkt
Uderclc
Nprof
Razr
Dat
Oper
No_Uder
Lgot5
Lgot
Lgot3
Tarif
Mesto
LgotDet2
DateTime
Uid_men (FK)
Uid_subpodr (FK)
PROFESS (FK)
OTPUSK
Dat1
Dat2
Comm
Mn
Yr
Sum
DN
DN1
Sum1
Sum88
DateTime
Uid_men (FK)
PROFESS
PROFESS
Naim
Socr
Terr
Os_usl1
Os_usl2
S_osn
S_mes
S_day
DopSved
V_osn
V_hr
V_mn
DateTime
PROGUL
Dat1
Dat2
Comm
Dn
Typ
DateTime
Uid_men (FK)
SUBPODR
Uid_subpodr
Naim
Podr
Sch
Ist
DateTime
Tab
Mn (FK)
Yr (FK)
Tim
Days
KDays
Zclc
DateTime
Uid_subpodr (FK)
UID_ist (FK)
Nxxx (FK)
UDER
Nxxx
Long
Short
Rasch
IN_summ
IN_svod
IN_dopl
IN_fast
Zclc
Ist
DateTime
Mn
Yr
VED
Mn (FK)
Yr (FK)
Tim
Kday
Days
Sumv
Sumf
Mezh
Sumo
Mesto
Vtab
Vclc
Dopvsgd
Doposgd
Doppn
Zclc
Snbase
Ssbase
Sn1base
Ss1base
Fssbase
Sfssbase
Pf
Pfc
Pfn
Fss
Ffoms
Tfoms
Spf
Spfc
Spfn
Sfss
Sffoms
Stfoms
Sbst
Ssgd
Sskid
Osgd
Dd30
Pn30
Dd35
Pn35
Ist
Istab
Datetime
Uid_subpodr (FK)
UID_ist (FK)
Nxxx (FK)
Uid_men (FK)
Kladr
Code
Name
Socr
Index
Gninmb
Kldok
Kod
Name
Knaim
Kontser
KLVICET
Kod
Name
Oldkod
STREET
Code
Name
Socr
Index
Gninmb
Рис. 110. Информационная модель ИС.
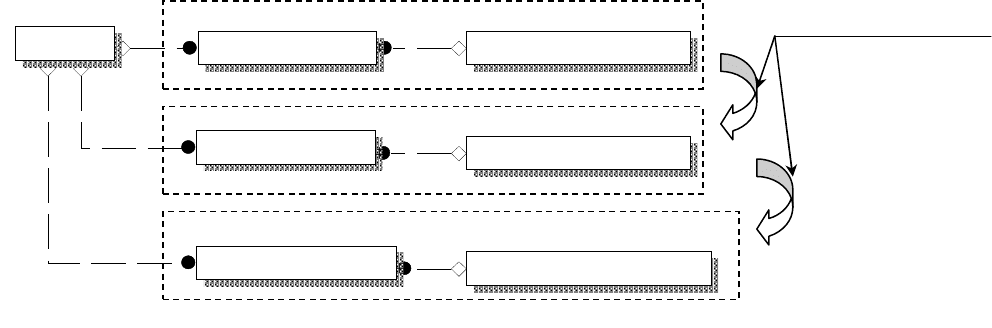
295
«Страничная» модель
Идея модели заключается в том, что каждый месяц формируются
(первоначально – копируются из прошлого месяца) свои справочники и свои
файлы работников, расчетной ведомости, табеля (рис. 99) и т.п. При этом в
пределах месяца используется либо ячеечная, либо строковая модель, это не
имеет значения.
Технически это может быть сделано по-разному. Данные физически
могут оставаться даже в одной таблице, если используется ячеечная модель.
При использовании строковой модели с хранением в структуре ведомости
справочников, каждый месяц либо должен создаваться отдельный файл, имя
которого содержит указание на расчетные месяц и год, либо файлы с тем же
именами переписываются при открытии месяца в новую папку. Последний
подход, вероятно, логичнее, так как не приводит к массовому переименованию
файлов MEN, OK и т.д. При использовании SQL-сервера, в базе данных
создаются новые таблицы с разными именами, а в программе может
использоваться единый алиас для доступа к таблицам текущего месяца.
В последнем случае, строковая модель предоставляет возможность
защиты данных прошлых месяцев на уровне, более низком, чем интерфейсный.
Во всех остальных вариантах защитить данные от несанкционированного
изменения, тем более, с применением внешних по отношению к ИС средств,
весьма затруднительно, если вообще возможно. Ни ОС, ни большинство SQL-
серверов не позволяют эффективно защищать часть таблицы, если в другой ее
части надо интенсивно изменять данные. Скажем, защита при помощи
триггеров сделает систему значительно медленнее.
Итак, страничная модель позволяет дополнять и удалять виды
начислений и удержаний, и изменения не отражаются на более ранних месяцах.
Но, в качестве недостатков, можно отметить, что затрудняются расчеты,
охватывающие несколько месяцев. В отличие от предыдущих моделей, они
подразумевают уже не смену ключа поиска, а множественные переключения
Работник
Строки июня 2006 Справочник июня 2006
Строки июля 2006
Строки августа 2006
Справочник июля 2006
Справочник августа 2006
Копируются
каждый месяц
Рис. 111. «Страничная» модель данных
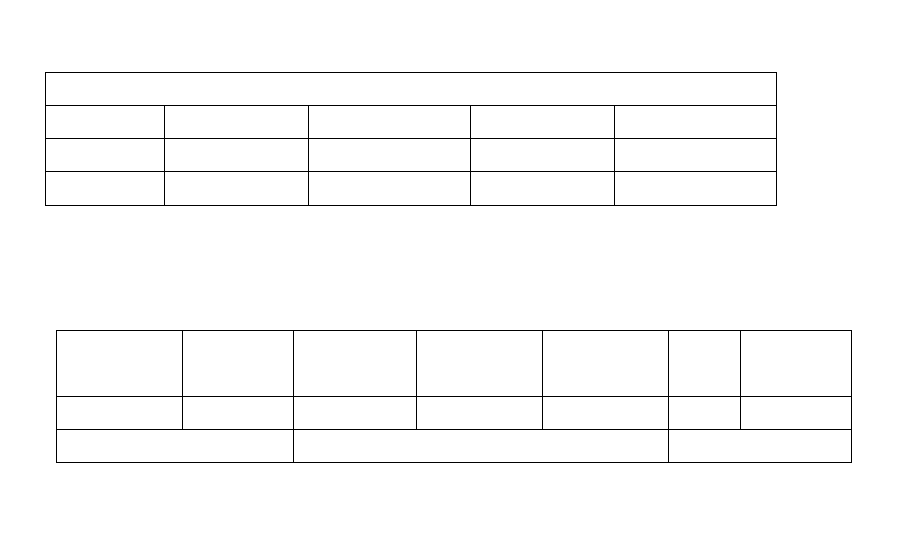
296
алиаса между различными таблицами. Кроме того, при использовании SQL
программа, осуществляющая программное копирование таблиц, должна иметь
высокий приоритет, что снижает общую безопасность ИС. Правда, то же самое
можно сказать и про изменение структуры таблиц в строковой модели.
В итоге необходимо отметить, что каждая архитектура хранения
пригодна для использования в ИС заработной платы, независимо от реализации
(архитектуры) расчетов.
Алгоритмы расчетов
Как указано выше, расчеты включают расчет начислений, удержаний и
налогов на ФОТ. Начисления зависят либо от выработки, либо от ранее
начисленных оклада, тарифа и т.п. и свойств работника (реже – подразделения).
Кроме того, необходимо учитывать реально выплаченные деньги, так как
выплата может производиться несколько раз за один месяц.
Все рассмотренные модели хранения позволяют организовать расчет,
остается рассмотреть детали его алгоритмической реализации при
использовании различных моделей.
Как указывалось выше, основой для расчета начислений является
табельный учет (рис. 132). В зависимости от выбранной модели хранения,
рассмотрим формирование табелей и перенос из них в ведомость тех
начислений, величина которых непосредственно связана с выработкой.
Ячеечная модель позволяет в ней же хранить табельную информацию –
дату, количество часов и подразделений, в котором часы отработаны (рис. 133).
Как и ячеечная модель ведомости, она является самой компактной и гибкой.
Использование «ячеечного» табеля позволяет в той же таблице фиксировать
перемещения работника по подразделениям и совмещение должностей. Но за
Расчетная ведомость
Июнь 2006
Часов Дней Оклад Тариф
Иванов 160 22 3800 0
Петров
80 10 0 1843,40
Табель учета рабочего времени:
Иванов
1 июня 2 июня 3 июня 4 июня 5 июня … 30
июня
8 часов 8 часов
6 часов 13 часов
13 часов
8 часов
Дворник Дворник + охранник 50% Дворник
Рис. 112. Перенос выработки из табеля в расчетную ведомость
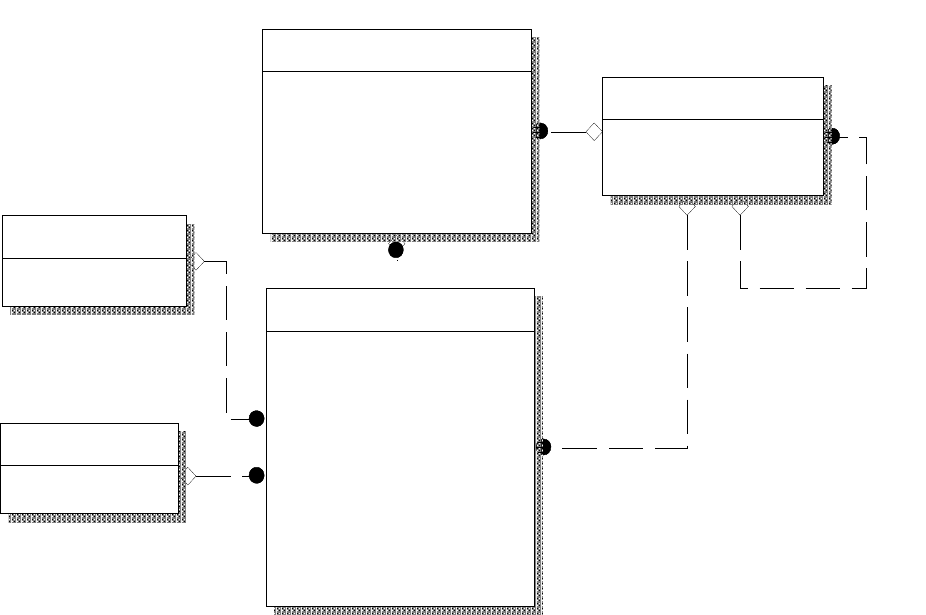
297
это приходится платить усложнением алгоритмической части. Так, при
использовании модели на рис. 133, алгоритм должен отличать ячейки,
относящиеся к табелю (в которых указаны дата и выработка) от ячеек
ведомости, в которых эти поля не заполняются. Кроме того, по мере
накопления данных замедляются расчеты накопительных сумм наподобие
ВСГД и остатка на начало месяца. Автором проверено на практике, что
замедление от месяца к месяцу работы ИС нервирует пользователей, даже если
они досконально осведомлены о причинах и их принципиальной
неустранимости. Пользователю (а тем более, заказчику МПС) очень не
нравится выражение «невозможно» по отношению к ИС.
При использовании строковой модели (рис. 128) учет выработки явно
отделен от прочих расчетов. При этом увеличение табеля никак не влияет на
размер (а следовательно, производительность обработки) расчетной ведомости.
Поэтому, несмотря на некоторую нерациональность в размещении данных, с
точки зрения автора использование строковой модели все-таки
предпочтительнее.
Кроме того, на практике, не всегда организуется почасовой учет
выработки, так как табели ведутся в других подразделениях, а не в бухгалтерии.
По окончании месяца их передаю расчетчику, который переносит сумму часов,
дней и рассчитанного вручную заработка (тарифа, оклада, некоторых
начислений) из табеля в ведомость. Если табельщик ведет только почасовой
Рис. 113. Ячеечная модель с учетом выработки
Работник
УИД_работника
Фамилия
Имя
Отчество
Дата рождения
УИД подразделения (FK)
Ячейка
УИД_работника (FK)
УИД начисления (FK)
УИД удержания (FK)
УИД подразделения (FK)
Месяц
Год
Дата
Часов
Значение
Подразделение
УИД подразделения
Название
УИД родителя
Начисления
УИД начисления
Название
Удержания
УИД удержания
Название
298
учет, то нормативы, оклады, тарифы, в соответствии с должностью берутся из
штатного расписания, и производится расчет.
Все виды начислений (рис. 134) можно классифицировать по времени и
алгоритмам расчета. Эта классификация будет определяющей при принятии
решения о способе хранения алгоритма и его настроек, то есть
информационной модели.
Назовем постоянными начисления, величина (алгоритм, коэффициенты)
которых не меняются от месяца к месяцу, или меняются редко. Это, например,
доплаты за классность, вредность, ученую степень или звание, районный
коэффициент и т.п. Их имеет смысл сохранить в таблице базы данных
(DOPLATA, рис. 130) в виде настроек алгоритма для каждого работника.
Переменные доплаты (разовые премии, материальная помощь и т.д.)
назначаются приказом по организации от раза к разу, а потому могут вноситься
расчетчиком вручную непосредственно в расчетную ведомость, то есть не
требуют отдельной таблицы для хранения. Аналогично, можно в той же
таблице хранить настройки удержаний (алименты, штрафы, перечисления по
решению суда и т.п.), отличая их от начислений по названию поля в
соответствии с принципами, отраженными на рис. 128.
Таблица 42
Информационная модель таблицы настроек алгоритма доплат
Поле (рис. 130) Назначение поля
FLD Поле в ведомости (соответствует названию поля)
DAT1 С даты
DAT2 По дату
SUM Сумма
PROCENT Процент, рассчитываемый от выражения в поле BLC
BLC От каких полей рассчитывается процент
OSNOV Комментарий
OKR
Округлять до знака (1 – до копеек, -1 – до десятков
рублей и т.п.)
ORD Приоритет расчета
DATETIME Дата последних изменений в таблице
UID_MEN Идентификатор работника
Прочие начисления
По времени По алгоритму
Постоянные Переменные Константные Зависимые
Рис. 114. Варианты алгоритмов расчетов
н
а
числений

299
Часть начислений («зависимые») для своего расчета требуют
предварительно знать уже посчитанные значения других переменных
ведомости. Так, для расчета уральского коэффициента требуется знать тариф и
доплату за классность. Последняя, в свою очередь, зависит от тарифа.
Следовательно, в таблице для хранения настроек алгоритма следует указать не
только алгоритм (поле BLC в табл. 33), но и последовательность расчета
(поле ORD, табл. 50). При этом необходимо предусмотреть, чтобы некоторые
виды начислений рассчитывались в зависимости от переменных доплат.
Предлагается рассчитывать переменные доплаты, например,
между 5 и 6 приоритетами полей основной ведомости.
Расчет удержаний отличается тем, что алгоритмы не
зависят от значений накопительных сумм. Исключением
является налог на доходы физических лиц, алгоритм расчета которого
рассмотрен в предыдущем параграфе.
Налоговый учет
В последнее время все большее количество фискальных органов
принимает данные от организаций в виде файлов, иногда сопровождаемых
бумажными носителями. Это Пенсионный фонд РФ, Федеральная налоговая
служба, фонды медицинского страхования и другие. Следовательно, в целях
налогового учета информационная система должна решать ряд следующих
задач:
• Собственно, расчет налоговых показателей
• Формирование электронных документов для передачи (текстовый файл,
XLS-файл, XML-файл или файл другого формата).
• Передача файла с защитой от внесения изменений и аутентификацией
отправителя, обычно осуществляемыми электронной цифровой
подписью.
Последняя задача на практике решается при помощи стандартных
программных средств, предоставляемых налогоплательщикам, тогда как
решение второй задачи требует внесения в информационную модель
определенных изменений. Один из вариантов реализации представлен на рис.
130, где в сущности VED созданы атрибуты VSGD, OSGD и другие,
необходимые для расчета НДФЛ.
Альтернативным вариантом является формирование денормализующих
модель документов, например, справок по форме 2-НДФЛ, в явном виде.
Документы подобного рода всегда используются только в режиме «на чтение»,
что дает возможность рассматривать почти все атрибуты документа как один
неатомарный атрибут. В этом случае информационная модель будет иметь
примерно следующий вид (рис. 135).
Технологич
е
ский
прием
300
Справка
Номер
УИД типа (FK)
УИД работника (FK)
Дата выдачи
Дата передачи
BLOB-текст
Тип справки
УИД типа
Название
Работник
УИД работника
Фамилия
Имя
Отчество
Рис. 115. Фрагмент информационной модели налоговой отчетности
Включение типа справки в первичный ключ (и, соответственно,
построение индекса по нему) в данном случае оправдано, так как никогда не
возникает необходимости выбрать из БД справки нескольких типов в одном
запросе.
Хранение текста документа в поле таблицы дает один побочный
эффект: при любых изменениях исходных таблиц содержимое хранимого
документа не изменяется. Это, кроме использования в
описанной ситуации, полезно, например, при хранении
бухгалтерских актов сверок, форм, заполняемых при
лицензировании ВУЗа данными о преподавателях, библиотеке и лабораториях
(см. следующий параграф) и даже исходящих документов организации в
случае, если они формируются автоматически (например, мастером слияния
редактора MS WORD). Подобным образом просто организовать и хранение
различных версий документов, что также часто востребовано.
Вывод
На примере столь сложной предметной области как расчет заработной
платы продемонстрированы различные подходы к построению
информационных моделей, не имеющих однозначных преимуществ друг перед
другом. В данном случае, изменения в информационных моделях сказываются
также на алгоритмах расчетов, особенно сложных, охватывающих несколько
временных периодов, а также связанных с подготовкой документов,
подлежащих передаче в фискальные органы.
Автор в свое время, много лет назад, сделал огромную ошибку, написав
программу расчета зарплаты с «вшитым» в структуру БД трудноизменяемым
справочником начислений и удержаний, полями типа «OKLAD», «TARIF»,
«PREMIA», «NALOG» и т.п. Честное слово, это худшее, что может сделать
практикующий программист для себя и своего будущего. Как и в этой, в любой
задаче тщательное проектирование информационной структуры, связанное с
глубоким изучением предметной области, рассмотрение различных вариантов
может в дальнейшем здорово упростить или усложнить поддержку и развитие
информационной системы.
Технологич
е
ский
прием