Затонский А.В. Пособие по полному жизненному циклу информационных систем
Подождите немного. Документ загружается.

261
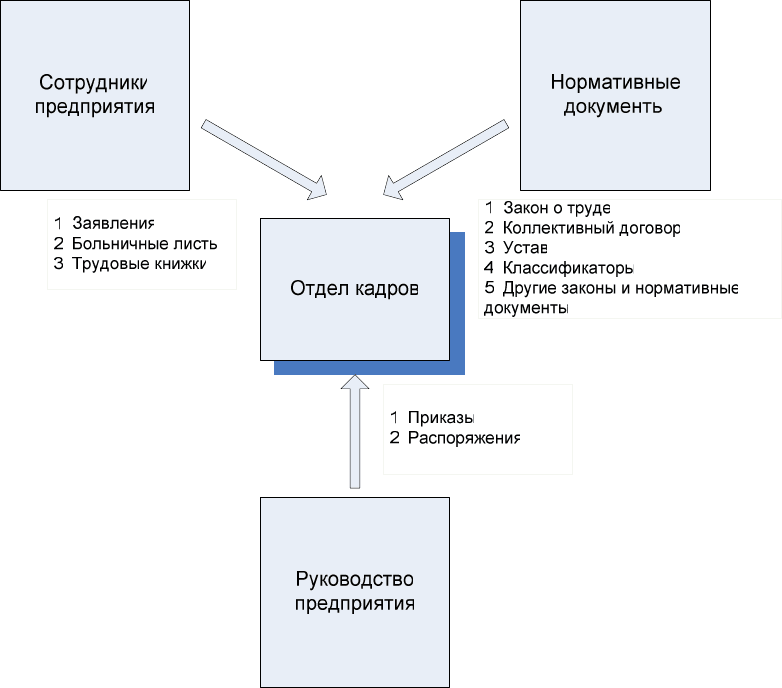
Рис. 94. Примеры исходящих документов
Функции отдела кадров:
Прием на работу новых сотрудников.
Увольнение сотрудников.
Кадровое перемещение:
изменение категории;
изменение должности/специальности ;
изменение разряда;
изменение графика работы;
перевод на другой объект.
Воинский учет.
Учет членства в профсоюзе.
Оформление отпусков.
Оформление больничных листов.
Ведение штатного расписания.
Отчетность:
перед бухгалтерией;
перед пенсионным фондом РФ;
перед статистическими органами;
перед руководством.
262
Еще отдел кадров обязан вести личную карточку на каждого сотрудника.
Составление и хранение перечисленных входящие и исходящие документы
составляют порядка 95% работы отдела кадров.
При приеме на работу обычно сразу же заполняется «Личная карточка»
сотрудника (форма Т-2). Личная карточка содержит наиболее полную
информацию о сотруднике и рассчитана на ее ведение в течение периода
работы сотрудника.
В личной карточке содержатся следующие реквизиты.
• ФИО сотрудника.
• Дата приема.
• Дата увольнения.
• Категория.
• Объект.
• Должность / Специальность.
• Разряд.
• Оклад / Тариф.
• Характер работы.
• Паспорт (вид документа, серия, номер, дата выдачи, кем выдан).
• Адрес проживания (страна, индекс, регион, город, насел. пункт, район,
улица, дом, корпус, квартира). Если адрес по прописке отличается от
адреса проживания, указываются оба адреса.
• Телефон.
• Дата рождения.
• Место рождения.
• Гражданство.
• Пол.
• Семейное положение.
• Является ли членом профсоюза.
• Непрерывный стаж.
• Общий стаж.
• Стаж, дающий право на надбавку за выслугу лет.
• Воинский учет (звание, военкомат, годность, ВУС, спецучет).
• Приказы по сотруднику (прием, отпуска, перемещения, увольнение).
• Страховой номер ПФР.
• ИНН.
• Образование.
и многое другое.
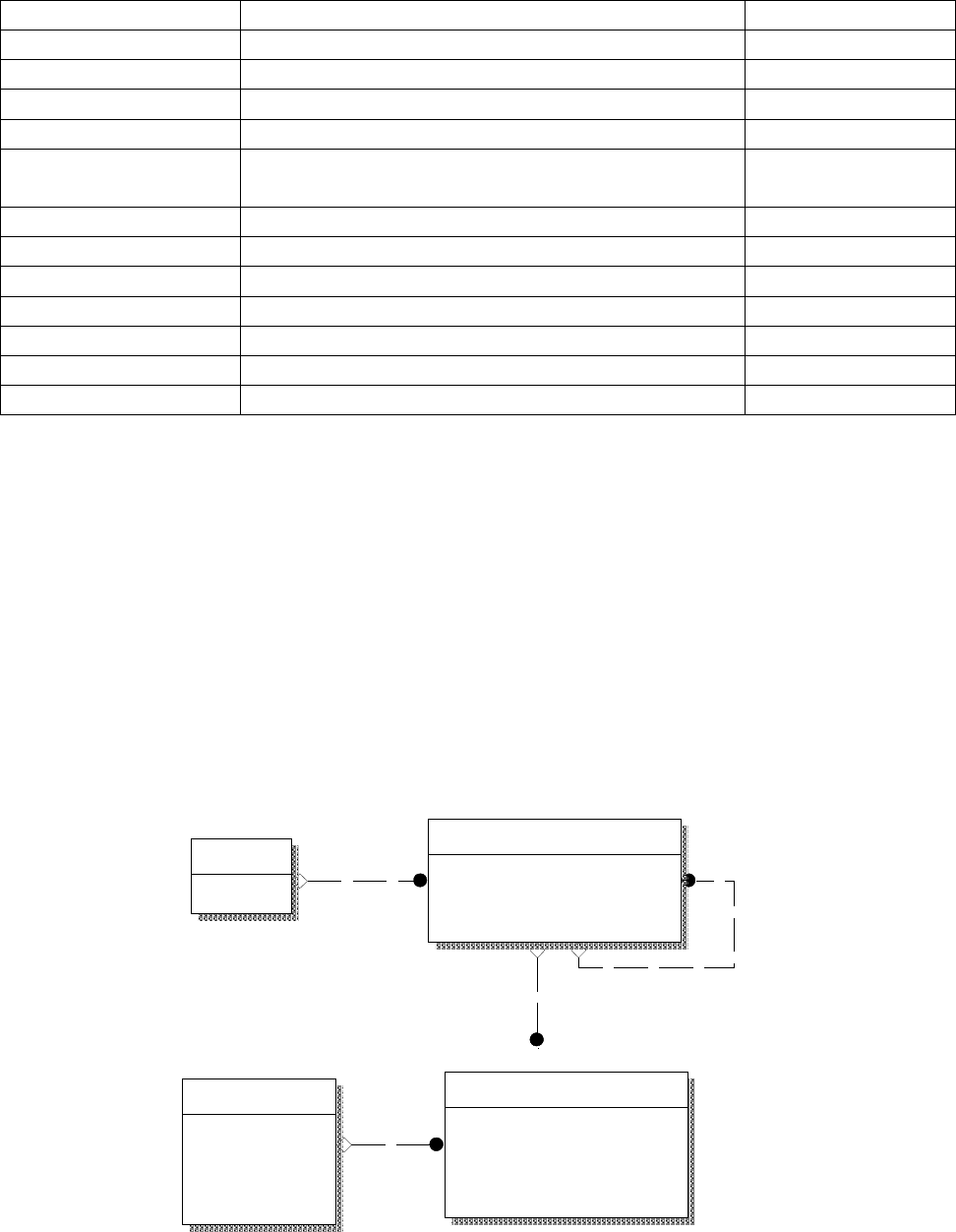
Рассмотрим пример записи данных о работнике в денормализованной
таблице и разделим всю информацию на изменяемую (если работник
увольняется, переводится в другое подразделение, увольняется и т.п.) и условно
неизменную (табл. 22).
263
Таблица 14
Пример записи информации о работнике
Атрибут Значение Неизменный?
Фамилия Иванов +
Имя Иван +
Отчество Иванович +
Дата рождения 31.12.1965 +
Дата
поступления
05.05.2005 -
Подразделение Кирпичный завод -
Участок Формовки -
Оклад 12000 -
Профессия Нет -
Дети 3 -
Льготы Афганистан +
ИНН 5911… +
Отметим, что прием на работу может осуществляться по заявлению,
переводом из другого места, при демобилизации из армии и т.п.; увольнение –
по собственному желанию, по решению суда, для прохождения срочной
службы и т.п.; перевод внутри предприятия или подразделения - временный
или постоянный.
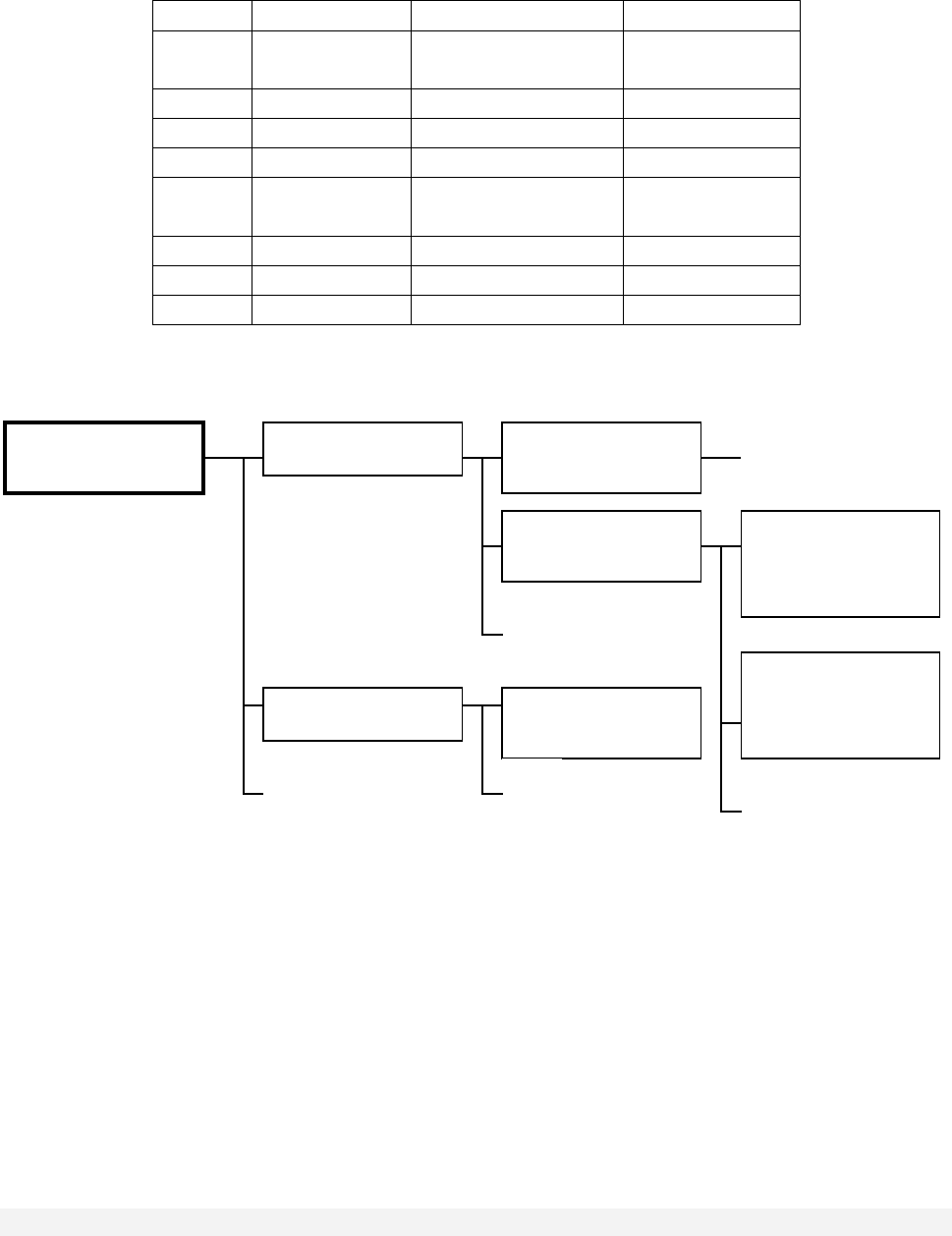
По аналогии с технологическим приемом, представленным на рис. 85, для
организации древовидной структуры подразделений предприятия выделяем его
тип и делаем связь самого на себя («свиное ухо» – необязательно
множественная связь самого на себя). Для нормализации разделим сущность
«работник» на две: содержащую неизменную информацию и изменяемую.
Подразделение
УИД_подразделения
УИД_родителя
Код экономического учета
УИД_тип (FK)
Тип
УИД_тип
Название
Работник
УИД_работника
Фамилия
Имя
Отчество
Дата рождения
Переменная информация
Дата
Операция
УИД_работника (FK)
УИД_подразделения (FK)
Рис. 95. ERD подсистемы штатного расписания
264
Примером заполнения таблицы «Подразделение», соответствующих
такой модели, может быть следующая информация (табл. 23)
Таблица 15
Пример заполнения таблицы «Подразделение»
ИД Тип Название Родитель
1 1 (произв-
во)
HNO
3
0
2 2 (цех) 1A 1
3 3 (отдел) Отдел 1/1А 2
4 3 Отдел 2/1А 2
5 4
(бригада)
Сидоров 4
6 4 Петров 4
7 2 1Б 1
8 3 Отдел 1/1Б 7
Это соответствует следующей структуре подразделений (рис. 116).
Рис. 96. Структура подразделений, соответствующая табл. 23
Оценим эффективность такой модели следующим образом.
Предположим, что требуется сформировать список всех работающих в данный
момент сотрудников. Это постоянно решаемая в подобных ИС задача, причем
не только для составления некоторых выходных форм, но и просто для вывода
на экран списка работников подразделения. В качестве иллюстрации приведем
довольно понятный код на FoxPro-подобном языке программирования баз
данных (для простоты предположим, что записи в таблицу переменной
информации вносятся последовательно, в порядке их дат, либо упорядочены
соответствующим индексом):
SELECT MEN // пусть алиас с этим именем соответствует
Производство
HNO3
Цех 1А
Цех 1Б
Отдел 1
цеха 1А
Отдел 2
цеха 1А
Отдел 1
цеха 1Б
Бригада
(бригадир
Сидоров)
Бригада
(бригадир
Петров)
…
…
…
…
…

265
// таблице «Работник»
LOCATE ALL // перебирать всю таблицу работников
DO WHILE FOUND() // пока не дошли до конца таблицы
SELECT PI // перевести фокус на таблицу переменной
информации
LOCATE FOR ID_MEN = MEN.ID AND DAT <= DATE()
// искать все записи в таблице переменной,
// относящиеся к текущему работнику и внесенные
// до текущей даты
DO WHILE FOUND() // пока записи находятся
S.ID = PI.ID // запоминать УИД записи
CONTINUE // и искать следующую
ENDD
SEEK S.ID // перейти на последнюю из найденных записей
IF PI.OPER != VVOD // если признак операции не «уволен»
PRINT MEN.FIO // вывести на экран фамилию работника
END IF
SELECT MEN // вернуть фокус на таблицу работников
CONTINUE // и искать следующего работника
ENDD // конец цикла
Оценим количество записей, которое будет считано в ходе работы этого
фрагмента. Пусть ИС работает в течение 5 лет на среднем предприятии с
численностью работников 1000 человек. Обычная текучесть кадров составляет
от 10% до 20% в год, следовательно, за 5 лет в таблице работников накопится
примерно 1000 * (1+0.15*5) = 1750 записей. В современных условиях
нормально, что каждый год изменяется оклад работника, поэтому 1000
постоянных работников будут иметь, как минимум, по 5 записей в таблице
переменной информации, а уволенные – на одну (увольнение) больше.
Следовательно, таблица переменной информации будет содержать 1000*5 +
750*6 = 9500 записей. При фронтальном переборе приведенный фрагмент
программы переберет 1750 + 1750*9500 = 16.626.750 записей; из расчета 0,001
с/запись это займет 27 минут. При использовании индекса время перебора всех
записей таблицы переменной информации пропорционально
2
log 9500 13.2
C C
⋅ ≈ ⋅
, где
1
C
≥
. То есть даже при использовании индекса вывод
списка работников на экран замедлится минимум в 13 раз!
Кроме того, структура таблицы «работник» вряд ли будет настолько
простой. Для работы отдела кадров, как показывают исследования документов,
необходима примерно следующая структура таблиц «Работники» и других (рис.
117).
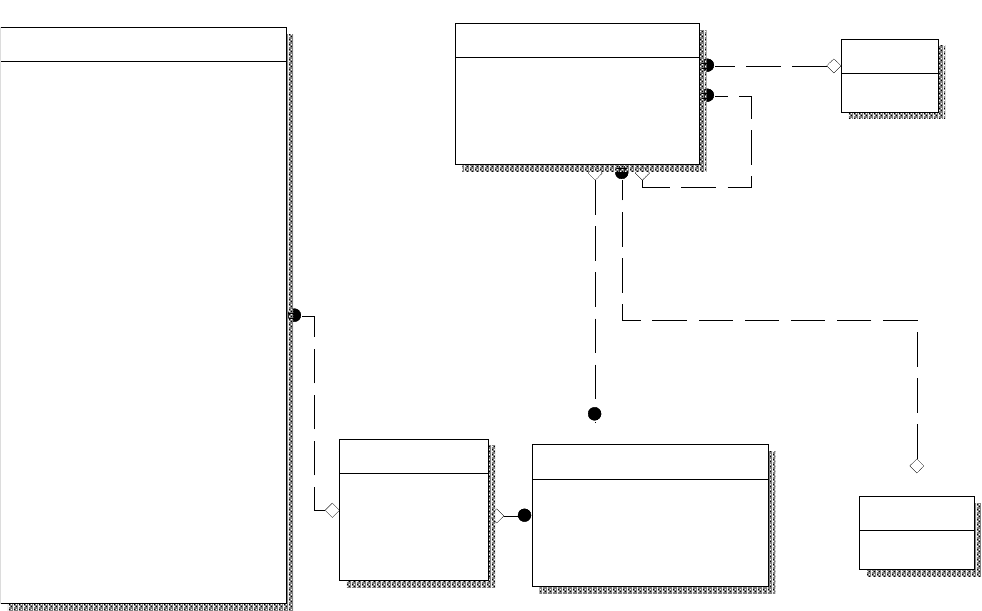
266
Подразделение
УИД_подразделения
УИД_родителя
Код экономического учета
УИД_тип (FK)
Код (FK)
Тип
УИД_тип
Название
Работник
УИД_работника
Фамилия
Имя
Отчество
Дата рождения
Переменная информация
Дата
Операция
УИД_работника (FK)
УИД_подразделения (FK)
Постоянная информация
УИД_работника (FK)
Дата последнего приема
Дата последнего увольнения
Дата для расчета выслуги лет
Дата для расчета 13й зарплаты
ИНН
Свидетельство ПФР
Почтовый индекс
Область
Район
Город
Улица
Дом
Корпус
Квартира
Телефон
Номер паспорта
Серия паспорта
Дата выдачи паспорта
Кем выдан паспорт
Номер военного билета
Категория учета
Другие подобные данные
Коды учета
Код
Название
Рис. 97. Модифицированная структура данных
Таблица «Постоянная информация», на самом деле, находится в
отношении 1:1 к таблице «Работник». В нее относятся поля, которые не
требуются для формирования списка работников, обычно показываемого на
экране. Поэтому разделение полей между этими таблицами довольно условно,
и оно может быть другим, или же все поля «Постоянной информации» могут
быть перенесены в «Работники».
Таблица «Коды учета» расширяет модель на область экономического
учета, а именно, учета затрат на заработную плату в разрезе по направлениям
деятельности. Каждому направлению, или статье затрат (например,
«Перевозки», «Ремонт оборудования», «Административные затраты»,
«Основное производство» и т.п.), присваивается код. Один и тот же код может
соответствовать деятельности разных подразделений, отсюда связь 1:M между
ними.
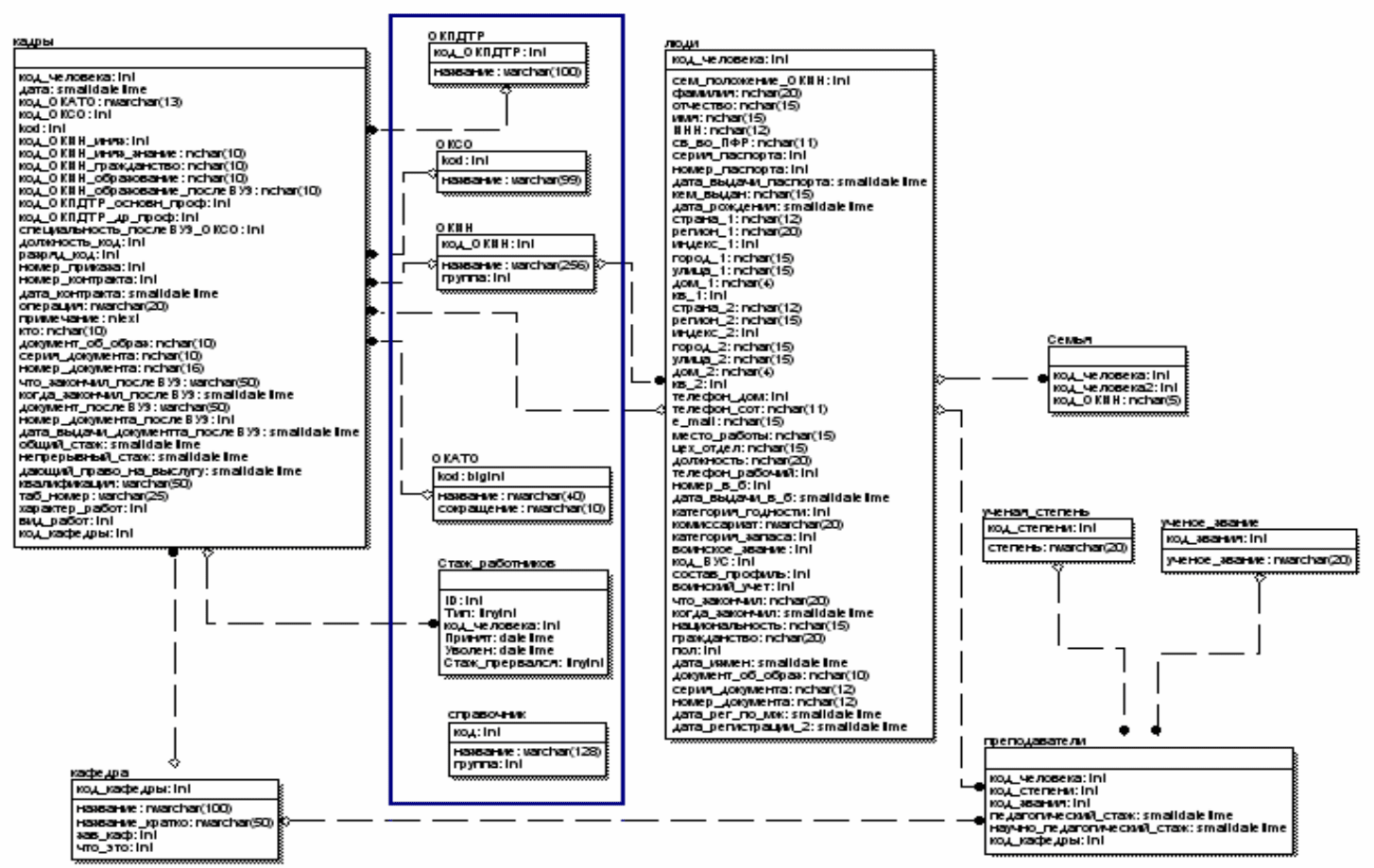
Пример реальной модели данных отдела кадров высшего учебного
заведения с учетом всех используемых справочников приведен на рис. 98. По
сравнению с рис. 97, здесь ситуация осложняется необходимостью отдельного
учета преподавателей, закрепленных за кафедрами, от прочих работников и
студентов. Для хранения информации о работниках используются таблицы
«Люди» (общая информация для всех работников и студентов), «Кадры»
(общее для всех работников) и «Преподаватели» (атрибуты, характеризующие
только преподавателей).
Возможны и другие расширения модели при необходимости организации
учета:

267
• военнообязанных;
• групп секретности и т.д.
Функциональная модель учета заработной платы
Для анализа предметной области была собрана информация о функциях
будущей ИС, в результате была разработана
3
модель IDEF0, корневой уровень
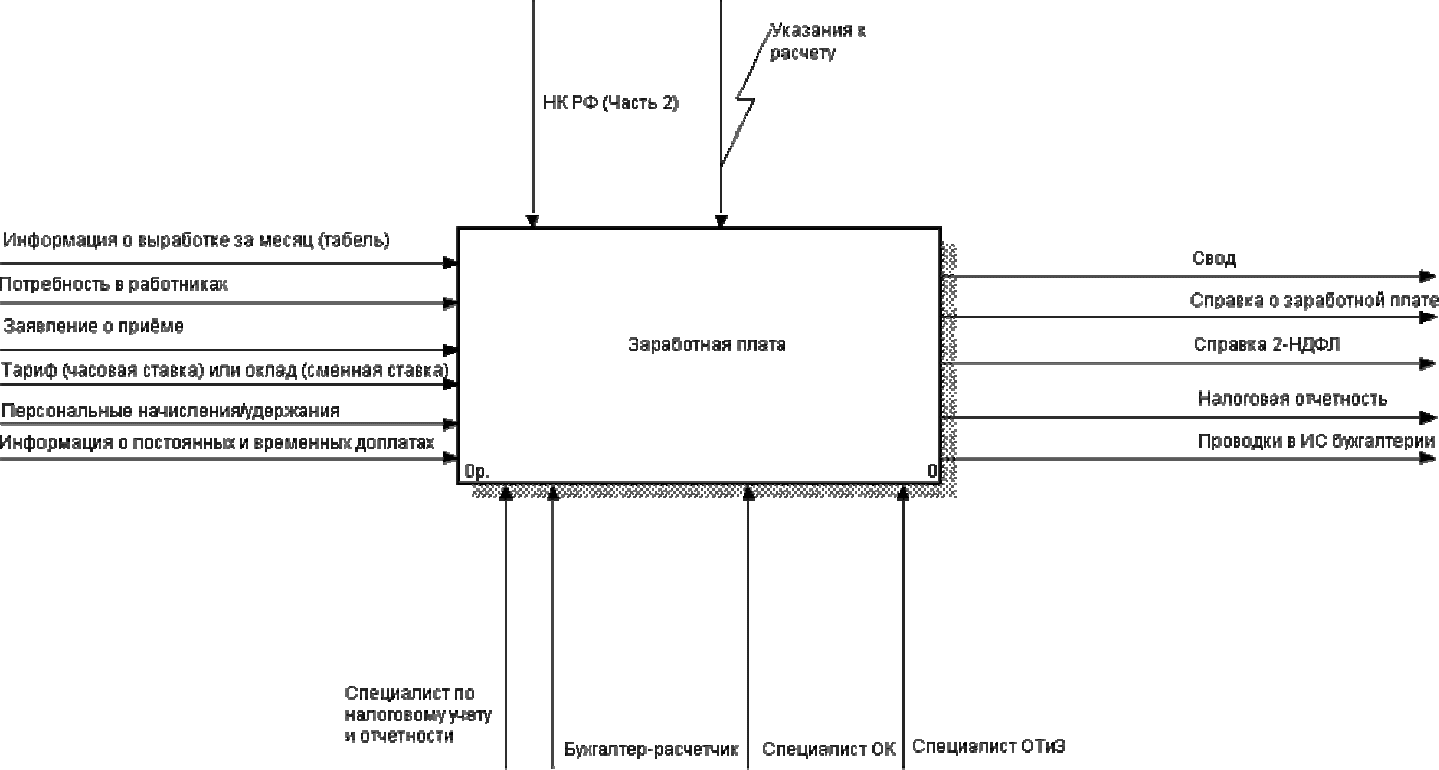
которой представлен на рис. 119.
На входе:
• Информация о выработке за месяц (табель);
• Потребность в работниках;
• Заявление о приеме;
• Тариф (часовая ставка) или оклад (сменная ставка);
• Персональные начисления и удержания;
• Информация о постоянных и временных доплатах.
• Управление осуществляется следующими нормативными документами:
• Налоговый кодекс (НК) РФ (Часть 2);
• Указания к расчету.
• Механизмами являются:
• Специалист по налоговому учету и отчетности;
• Бухгалтер – расчетчик;
• Специалист отдела кадров (ОК);
• Специалист отдела труда и заработной платы (ОТиЗ).
На выходе получаем следующую документацию:
• Свод;
• Справка о заработной плате;
• Справка 2-НДФЛ (Налог на доходы физических лиц);
• Налоговая отчетность;
• Проводки в ИС бухгалтерии.
Далее производим декомпозицию функционального блока. Получившаяся
диаграмма второго уровня содержит функциональные блоки, отображающие
главные подфункции функционального блока контекстной диаграммы и
называется дочерней по отношению к нему (рис. 101).
В результате декомпозиции функциональный блок «Заработная плата»
был представлен в виде пяти связанных процессов:
1. Учет справочной информации (А-1).
Вход – информация о постоянных и временных доплатах;
Выход – структурные подразделения, наименования должностей и др. для
составления и хранения штатного расписания и информации ОК, расчетные
ведомости для расчета заработной платы;
Механизм – бухгалтер-расчетчик;
3
Разработчик – Пастухова Ю.Г., студентка направления ИВТ БФ ПГТУ
268
Рис. 98. Модифицированная структура данных
269
Рис. 99 Контекстная диаграмма
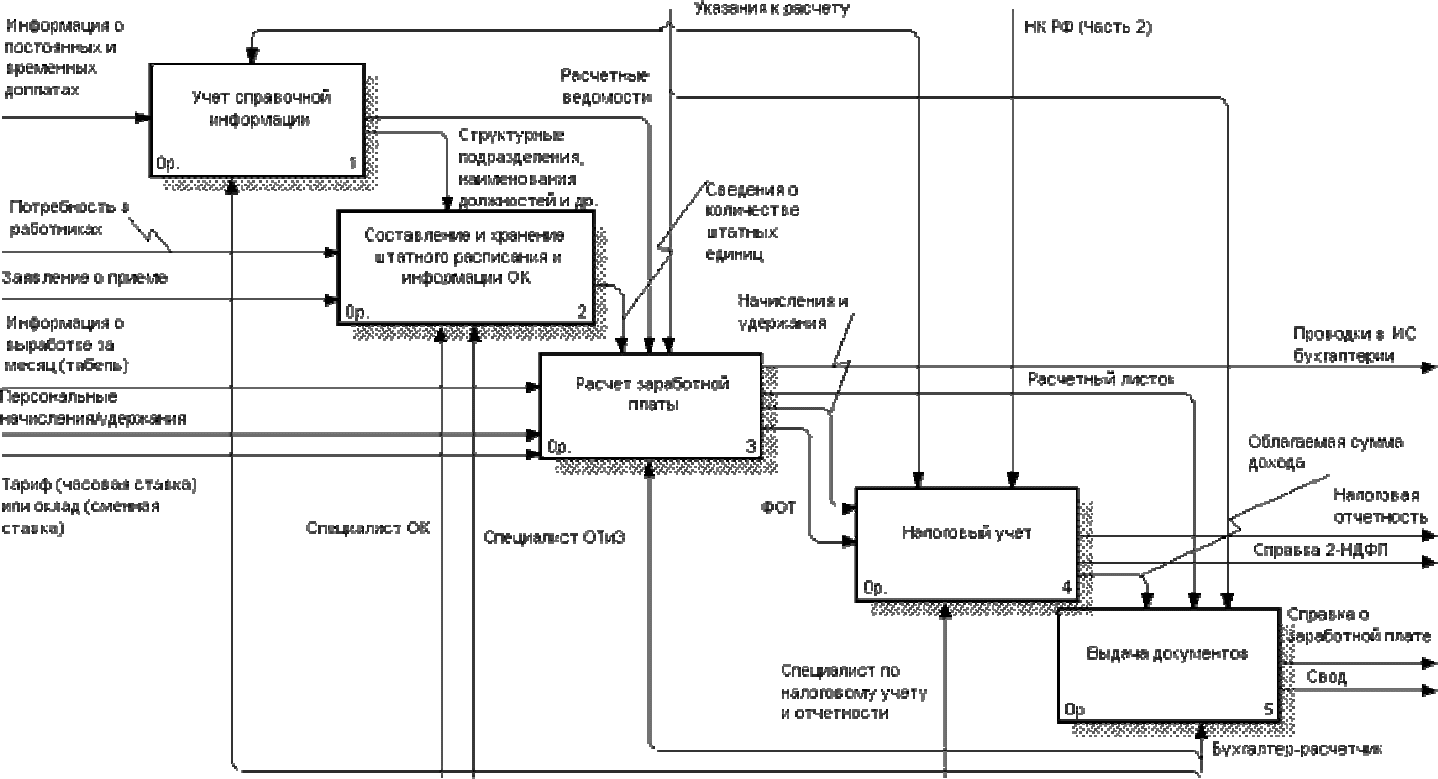
270
Рис. 100. Декомпозиция блока «Заработная плата»