Voit J. The Statistical Mechanics of Financial Markets
Подождите немного. Документ загружается.

312 10. Risk Management
and because of the insufficient controlling at Barings in general. While the
perception of operational risk is new in banking, it is rather well known in
industry where often hazardous processes are involved in the production or
transport of goods, e.g. in the chemical industry.
The principal challenges faced when attempting to describe operational
risk are its latent character, the absence of data, and the rarity of high-
impact events. While for market risk, plenty of data are publicly available,
and for credit risk, sufficient data are available in banks internally, there are
very few data available on operational risk. Moreover, data on very large
losses which determine the tail of a loss distribution function, are even rarer.
Worse even, however, for a given bank, stationary data time series may be an
impossibility: Usually risk management is improved, in particular in response
to losses suffered.
The modeling of operational risk comprises two important aspects: (i)
the frequency with which operational losses occur, and (ii) the size (dollar
amount) of the loss suffered in the case of an event. Of course, both quantities
will be stochastic. One therefore is interested in determining their probability
density functions. Many operational risks can be insured. Some inspiration
can thus be gained from the standard model of actuarial science [242]. It
postulates that the frequency of events (insurance claims) in a given time
interval, e.g. one year, is random and drawn from a Poisson distribution. The
distribution of the time interval between two claims then follows an expo-
nential distribution with a well-defined life time. Also the size of insurance
claims is random and drawn from a log-normal distribution!
Data collection therefore is an important focus of operational risk con-
trolling. One typically would build up data bases of operational risk losses
across a bank. When loss data are collected by a single bank, such a data base
is of limited value, though, due to the infrequency of losses. E.g., a typical
number for small banks, say with a balance sheet of 3 ×10
9
Euro as a proxy
for size, is 25 loss events per year in excess of 1,000 Euro. The frequency of
losses increases with the size of the bank, giving good statistics for the largest
banks. These organizations, in practice, are so complex, though, that a sta-
tistical analysis at the highest level of hierarchy is too crude to give reliable
information for risk management.
Data collection can be assisted by including data external to the bank.
There are one or two commercial databases which systematically gather de-
scriptions of those operational loss cases made public, e.g. in the press [241].
As an alternative, homogeneous groups of banks pool their loss data according
to well-defined rules, to increase the data base upon which statistical analyses
can be built, and the statistical significance of the results derived. Examples
known to the author are the ORX (Operational Risk EXchange) consortium
of European banks, the data pooling initiative of savings banks in Germany
led by the German Association of Savings Banks, or a data pooling project led
by the Italian Bankers’ Association. These data bases contain standardized
10.4 Types of Risk 313
information on the date of an operational risk loss and on the size of the loss
(gross, net, recoveries, etc.), a description of the scenario underlying the loss,
its categorization in terms of causes and event types, and possibly additional
information on various parameters characterizing the bank where the event
occurred. Frequency and loss distribution functions then are generated and
convoluted by Monte Carlo simulation and analyzed by standard statistical
methods. The goal is to derive the established risk measures such as value at
risk or expected shortfall, on a specified time horizon, e.g. one year.
An important unsolved problem in the inclusion of external loss data into
a bank’s risk model is the rescaling of the external information, to fit the
bank in question. Both the relevant parameters and the functional scaling
relations for the loss frequency and the loss amounts are largely unknown
today. However, as the size of the data pools increases with time, research
into these problems likely will lead to interesting results in the near future.
Also, data seem to indicate that the tails of the loss distributions are much
fatter than expected for a lognormal distribution. The frequency distribution,
on the other hand, apparently is quite well described by a Possonian although
evidence seems to be accumulating in favor of more complex two-parameter
distributions.
A good operational risk controlling programme will, however, not rely on
data alone. Apparently extreme views even would suggest not to rely pri-
marily on loss data at all. One problem is that data necessarily describe the
past whereas risk management would prefer to have a more dynamic picture
including the consequences of management action on future risks. More se-
rious, however, is the problem that there is risk even without data: a bank
may face significant operational risks but may not have suffered large losses
in the past – either because of sheer luck or due to the low event probabil-
ity of some scenarios. A data-based operational risk measure would grossly
underestimate the risk situation of the bank. Worse even, risk measures such
as value at risk are strongly affected by extreme losses which, hopefully, oc-
cur seldom enough to prevent good data quality in that range. A qualitative
self-assessment, i.e. expert workshops and interviews where the risk of cer-
tain scenarios is estimated by knowledgable members of staff, are a way out
of this problem. When optimized in view of psychometric evaluation, such
questionnaires may provide more realistic risk estimates than data-based ap-
proaches. Of course, methods such as fuzzy logic and Bayesian networks also
allow to integrate loss data with expert-based risk estimates for consolidated
risk measures.
Very recently, statistical models for operational risk management have
appeared in the physics-oriented literature [243, 244].
314 10. Risk Management
10.4.4 Liquidity Risk
Liquidity risk is the risk that a bank is unable to satisfy all claims of pay-
ment against it, i.e. becomes illiquid. The bank thus would default on some
payments. Liquidity risk in essence appears very similar to credit default risk.
Market conditions often are drivers of liquidity risk for investors. When
a market participant wants to buy or sell an asset, situations may occur
where no counterparty is willing to settle the trade proposed. A standard
example are small cap stocks, either on their home markets or worse, on
foreign markets. Another example are liquid markets turning illiquid in stress
situations, e.g. the crashes discussed in the preceding chapter. Illiquid markets
arise when the complete market hypothesis fails.
Other drivers of liquidity risk may be massive (correlated) credit defaults,
the inability to liquidate collateral taken in to secure credits, etc.
10.5 Risk Management
Suppose that a speculator, or the trading desk of a financial institution, has
taken a position, resp. a set of positions in a market. However, the market
turns against the speculator, and the position looses in value. What should
he do?
As another example, assume that, as a part of its business activities, a
bank has extended a set of loans to its corporate customers, and/or written
a set of options for them. From that moment on, the bank carries a huge
risk: The customers may default on their loans. Or the options may increase
in value, i.e. the obligations of the bank at expiration increase. What action
must the bank take?
10.5.1 Risk Management Requires a Strategy
Ideally, every investment is the result of a strategy and involves opinions
on the evolution of the markets. This strategy should contain statements as
to why the asset was bought, the target value to be reached and time span
needed. Most importantly, an investor must fix the amount of loss he is willing
to accept on his investment when the asset does not follow his view of the
market. This is the starting point of risk management. For a single position,
the point of non-acceptance is a limit on the value of the asset. For a complex
portfolio of traded assets, it may be a limit on the value of the portfolio, or
on the value at risk of the portfolio, or on any other risk measure.
The situation is slightly different for positions in financial instruments
which are taken for business objectives, and not for speculative purposes. The
bank writes an option or extends a loan to satisfy the needs of its customers.
Its business objective is to make money on the fees charged for those services.
It does not intend to hold a risky position in those assets. Here, the strategy
10.5 Risk Management 315
is obvious at first: Eliminate as much risk as possible by a compensating
investment. However, a complete elimination of risk is rarely possible in real
market, and the bank needs a strategy for dealing with the residual risk it is
ready to accept.
10.5.2 Limit Systems
Limit systems provide a classical way to cope with these situations. Consider
the speculator who holds a single asset, e.g. in late 1996 a number of stocks
on Hoechst bought at 35 Euro. The chart of Hoechst corporation can be
found in Fig. 8.4. The stock rises to above 40 Euro during 1997 but, in late
1997 falls below 30 Euro. If the investor cannot accept more than 15% loss
on his position, it seems wise to place a stop-loss order at 30 Euro. The order
is triggered when the price quoted falls below 30 Euro and then acts as an
unlimited sell order.
There are two problems with this strategy of risk limitation. Firstly, it
is not guaranteed that the price at which the order is executed, is 30 Euro,
or even close to that value. This problem is not very serious, perhaps, in a
Gaussian market but can cause large unexpected losses in stress situations
in real markets where the tail of the return distribution is much closer to a
stable L´evy distribution. This point was made by Mandelbrot, cf. Sect. 5.3.3.
The second problem is: What to do next, in particular if an investment in
the Hoechst stock continues to appear promising on longer time scales? When
enter the position again? The straightforward strategy of placing a stop-
buy order at 30 Euro is dangerous, at least. The stop-buy order is triggered
when the stock price exceeds 30 Euro and then behaves as an unlimited buy
order. Again, it is uncertain if the order is executed at or close to 30 Euro.
The difference between the actual buy and sell prices, augmented by the
transaction fees, is a systematic loss due to the strategy.
The same problem arises with a na¨ıve strategy to cover a short option
position [10]. However, the losses usually are bigger due to the leverage of
the options. Stop-loss and stop-buy limits are definitely not advised to cover
short positions in options.
For a complex portfolio, one faces similar limitations. The na¨ıve limit
strategy outlined above would imply to liquidate several positions in the
portfolio which are the main drivers of the limit violation. Both objections
made above, apply here again.
Implementing limits on loan portfolios may be a difficult task because
loans cannot be traded easily. A bank has very few options when, e.g., the
value at risk of a credit portfolio exceeds a pre-set limit. The termination of
loans may be feasible in some instances when the contracts permit. In general,
tough, one can only resort to some of the methods outlined in the following
sections. Notice that a quick remedy to the problem is unlikely because very
often, litigation on contracts may be involved. On the other hand, credit risk
limits often are violated due correlation: A group of borrowers, e.g. from one

316 10. Risk Management
industrial sector, is perceived as more risky in their ability to honor their
obligations. In such a case, a bank can stop extending new loans to any
member of that group of clients. Instead, it could increase lending to those
clients with zero or negative correlations with the risky cluster, and thereby
lower its value at risk back to acceptable levels.
Limit systems for operational risk are considered to be of speculative na-
ture, due to a variety of causes. The lack of reliable data makes any estimate
of risk measures, to be held against a limit, extremely imprecise. Conse-
quently, a limit violation most often is ambiguous. Secondly, operational risk
is driven by the processes in a bank, and the big “portfolio of processes” typ-
ically operating in any bank, renders difficult the assignment of a putative
limit violation to a single process which could be improved in the following.
On the other hand, if a sufficiently clear picture of a limit violation due to
operational risk can be obtained, remedy, even quick, may be available: As
mentioned before, many operational risks can be insured. When an insurance
is contracted, the bank transfers part of its operational risk to the insurance
company. The risk of the bank is reduced promptly.
Traffic light systems are a more flexible form of limit systems. When
the risk measure of a portfolio is far from its limit, the light is green, and
no action is required. When the risk measure approaches the limit, the light
switches to yellow. This is the time to closely monitor the portfolio, to analyse
which components are responsible for the increased risk, and to evaluate
various possible actions. Should the limit be violated, the light turns red,
and immediate action is required.
In spite of the shortcomings mentioned before, as a last line of defense,
every investor should fix a limit where he will liquidate his position or take
any other action suitable to avoid further losses on his portfolio.
10.5.3 Hedging
The Black–Scholes analysis of Sect. 4.5.1 was based on offsetting the sto-
chastic component in a short option position by a suitable long position in
the underlying. The price of the option could then be calculated because the
portfolio constructed was riskless, and its evolution deterministic.
For every option shorted, ∆ shares of the underlying were required to form
a riskless portfolio. This prescription (“∆-hedging”) precisely tells the bank
which has written options for its clients, how to eliminate the risk associated
with the option position. For such a “∆-neutral” portfolio, we have
∂Π
∂S
= −
∂f
∂S
+ ∆ =0,
∂Π
∂t
= rΠ . (10.56)
f is the value of the derivative. The portfolio is immune against small changes
of the price of the underlying and therefore riskless for short times.
∆, however, depends on the price of the underlying, and the hedge must
be adjusted as soon as the price changes. The dependence of ∆ on the price of

10.5 Risk Management 317
the underlying has been discussed in Sect. 4.5.5. In the Black–Scholes analy-
sis, a continuous adjustment of the position in the underlying is assumed,
and the transaction costs associated with this adjustment are neglected. In
practice, only a periodic adjustment of the hedge is possible. During the ad-
justment period, the portfolio no longer is riskless. Bigger price changes in
the underlying may occur, and volatility and interest rates may change. The
time to maturity certainly changes.
A ∆-neutral portfolio can be hedged further against these risk factors. Γ
(Sect. 4.5.5) is the second derivative of the option value with respect to the
underlying. If a ∆-neutral portfolio is hedged to be Γ -neutral in addition, it
is made immune against bigger changes in the price of the underlying. For a
∆-neutral portfolio, we have [10]
Θ +
1
2
σ
2
S
2
Γ = rf , (10.57)
where Θ has been defined in (4.105). A portfolio with a certain Γ can be
made Γ -neutral by adding −Γ/Γ
T
traded options, where Γ
T
is the Γ of the
traded options. After these options have been added, the portfolio is no longer
∆-neutral. An iterative adjustment in the number of shares of the underlying
and in the traded options is necessary to achieve ∆-andΓ -neutrality at the
same time. Even then, the portfolio is ∆-andΓ -neutral only instantaneously.
The last important risk driver of a ∆-neutral portfolio is volatility. The
sensitivity of an option price to changes in volatility is measured by Vega,
(4.109). A ∆-neutral portfolio with V can be hedged against changes in
volatility by adding −V/V
T
traded options with V
T
. Again, the ∆-andΓ -
neutrality of the portfolio must be restored iteratively. Although Γ and V are
quite similar, a Γ -neutral portfolio, in general, in not V-neutral at the same
time. When a ∆-neutral portfolio is hedged against Γ and V at the same
time, two traded options must be added to the portfolio.
Θ is special among the Greeks as it measures the time decay of an option
value. Time is not a stochastic variable. Therefore, a hedge against Θ makes
no sense.
10.5.4 Portfolio Insurance
A portfolio manager may be interested in protecting his portfolio against
falling below a certain limit value X during a certain time span T. Holding a
long position in put options with strike X and maturity T gives the desired
protection.
When the portfolio is well-diversified and mirrors an index, put options on
the index should be bought. For other portfolios, one can determine the cor-
relation of the portfolio with an index or a benchmark asset (the β-parameter
introduced in the next section) on which traded options have been written.
Then a long position in β put options on the index provides the desired
insurance.
318 10. Risk Management
When traded options suitable for the portfolio insurance desired are not
available or the options markets cannot absorb the trades required, the port-
folio manager can synthetically create the options required. The principle
of synthetic replication of options has been explained in Sect. 4.5.6. In the
specific case of insuring a portfolio worth Π against a drop below X,theport-
folio manager must invest, at any time, a fraction −∆(Π, X) of the portfolio
in a riskless asset. As the value of the stock portfolio declines, the fraction
invested in riskless assets increases. Conversely, when the value of the stocks
increases, part of the cash must be used to repurchase stocks.
Of course, portfolio insurance comes with a cost which is the higher the
smaller the amount of losses which the investor is ready to accept. E.g., when
insuring a portfolio representing the DAX (quoted 4343.6 on March 24, 2005)
against dropping below 4200 or 4000 points by year end 2005, the cost of the
put options required was the equivalent of 154 resp. 103 DAX points. Notice
that these options expire on December 8, 2005 already. When protection
against losses effective to December 30, 2005 is required, the put option must
be created synthetically. The cost of an option created synthetically is due to
the fact that the portfolio manager sells low and buys high, in this scheme.
This kind of portfolio insurance has also been implemented in “absolute
return” investment strategies and products which have become popular with
investors after the strong decline of the world stock markets in the years 2000–
2003. In a benchmark-related investment strategy, the portfolio manager, by
active management, tries to generate an outperformance of his portfolio with
respect to a benchmark. However, in bear markets, the portfolio still may
decline in value. The strategy was successful when the porfolio decline is
less than the decline in the benchmark. On the other hand, absolute return
strategies attempt to achieve a minimal absolute performance, independent
of the evolution of a benchmark. E.g., when the minimum return targeted is
zero, we have an investment where the protection of the capital invested is
attempted. The implementation of the absolute return strategy can be costly,
though, and lowers the performance of the investment.
Notice that the portfolio insurance scheme discussed in Sect. 8.3.1 also is
a rough way of creating an option synthetically.
10.5.5 Diversification
Correlation between assets is extremely important in risk management. The
hedging of option positions discussed before, relies on the negative correlation
between a short position in a call option and a long position in the underlying
asset. More specifically, ∆ measures the correlation between the option and
the underlying, and the sign of ∆ and of the option position (long/short)
determine how a riskless hedge can be constructed.
We have seen another important example of the influence of correlation.
For the special case of N time series of identically distributed uncorrelated

10.5 Risk Management 319
assets (10.34) gives the evolution of the portfolio value at risk from the equiv-
alent risk measure of a single time series. The corresponding evolution for
identically distributed, perfectly correlated time series is given in (10.35). It
turns out that the value at risk of the perfectly correlated portfolio exceeds
that of the uncorrelated portfolio by a factor
√
N. Apparently then, a sys-
tematic optimization of the tradeoff between risk and return in a portfolio
should be feasible.
Markowitz was the first to show that in portfolios containing several as-
sets, one can optimize (within limits) a tradeoff between risk and return
[253]. His quanitative theory derives the essential parameters for this opti-
mization – not surprisingly correlation. Markowitz’ theory essentially relies
on Gaussian markets, and volatility as the measure of risk. The application
to non-Gaussian markets is taken from Bouchaud and Potters [17].
In the following, we consider a portfolio with value Π, constituted by M
risky assets with values S
i
and one riskless asset with value S
0
. p
i
denotes
the fraction of portfolio value contributed by the asset i,andp
i
< 0, i.e.,
short selling, is allowed. Then,
Π =
M
i=0
p
i
S
i
,
M
i=0
p
i
=1. (10.58)
Uncorrelated Gaussian Price Changes
Each of the assets has a return µ
i
and a variance σ
2
i
. Then, the return of the
portfolio is
¯µ =
M
i=0
q
i
µ
i
, (10.59)
and its variance is
σ
2
=
M
i=1
q
2
i
σ
2
i
, (10.60)
where q
i
= p
i
S
i
/Π accounts for the different values of the assets in the
portfolio. One can now choose a return rate ¯µ of the portfolio and then
minimize its variance σ
2
at fixed ¯µ, using the method of Lagrange multipliers.
Taking the derivative
∂
∂q
i
(σ
2
− λ¯µ)
q
i
=q
i
=0, (i =0), (10.61)
leads to
q
i
= λ
µ
i
− µ
0
2σ
2
i
,λ=
2(¯µ − µ
0
)
+
M
j=1
µ
j
−µ
0
σ
j
2
. (10.62)
320 10. Risk Management
The riskless asset has q
0
=1−
+
M
i=1
q
i
, and the optimal p
i
are obtained
by solving the linear system of equations relating them to the q
i
through S
i
.
The minimal variance is then
σ
2
=
(¯µ − µ
0
)
2
+
M
j=1
µ
j
−µ
0
σ
j
2
. (10.63)
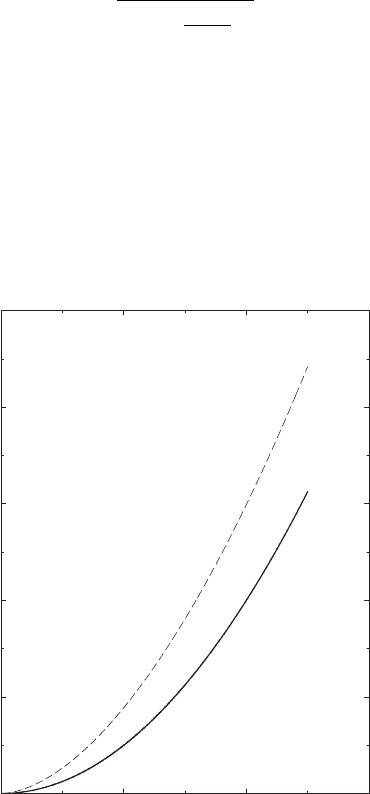
The variance of the optimal portfolio therefore depends quadratically on
the excess return over a riskless asset. This is shown as the solid line in
Fig. 10.1. The optimization procedure may also be carried out with con-
straints (e.g., no short selling, p
i
> 0, etc.). This leads to more Lagrange
multipliers for equality constraints, or more complex problems for inequal-
ity constraints. Quite generally, the curve moves upward, say to the dashed
line, when more constraints are added. The region below the solid line (the
“efficient frontier”) cannot be accessed: there are no portfolios with less risk
than the optimal ones just calculated.
0.0 10.0 20.0 30.0
Return
0.0
1.0
2.0
3.0
4.0
5.0
Risk
Fig. 10.1. Risk-return diagram of a mixed portfolio. In the absence of constraints,
the optimal portfolios have a quadratic dependence of variance on return (solid
line). In the presence of constraints, or for non-Gaussian statistics, the curve moves
upward (dashed line). The region below the solid line is inaccessible. Reprinted
from J.-P. Bouchaud and M. Potters: Th´eorie des Risques Financiers, by courtesy
of J.-P. Bouchaud.
c
1997 Diffusion Eyrolles (Al´ea-Saclay)
10.5 Risk Management 321
Uncorrelated L´evy Distributed Price Changes
We now assume that the price variations of the assets in our portfolio are
L´evy distributed (5.44), and follow Bouchaud and Potters [17]. In order to use
the generalized central limit theorem, Sect. 5.4, we must further assume that
all exponents are equal to µ, so that the main difference of the distributions
is the amplitude A
µ
i
of their tails,
p(δS
i
) →
µA
µ
i
|δS
i
|
1+µ
as δS
i
→−∞. (10.64)
Then, we can rescale the asset variables as X
i
= p
i
S
i
, and these variables
are drawn from distributions p(δX
i
)=p
µ
i
p(δS
i
), and the convolution theorem
can be applied to a sum of these random variables. The value of the portfolio
is precisely such a sum (10.58). Then, its variations are distributed according
to
p(δΠ) ∼
µA
µ
Π
|δΠ|
1+µ
with A
µ
Π
=
M
i=1
p
µ
i
A
µ
i
. (10.65)
Minimal value at risk Λ
var
is equivalent to minimal amplitude A
µ
Π
,at
fixed return ¯µ, (10.59). The optimization condition is
∂
∂q
i
,
M
i=1
q
µ
i
A
µ
i
− λ¯µ
-
q
i
=q
i
=0. (10.66)
It follows that
q
i
=
λ
µ
i
− µ
0
µA
µ
i
1/(µ−1)
,λ=
µ(¯µ − µ
0
)
µ−1
+
M
j=1
µ
i
−µ
0
A
i
µ/(µ−1)
µ−1
. (10.67)
The effective amplitude A
µ
Π
=
+
M
i=0
(p
i
)
µ
A
µ
i
,wherep
i
is obtained from q
i
by solving a linear system of equations, is then proportional to Λ
var
. Λ
var
vs.
¯µ −µ
0
behaves in a way similar to the dashed line in Fig. 10.1.
Correlated Gaussian Price Changes
Correlations between two or more time series, or between two or more sto-
chastic processes, are measured by the covariance matrices introduced in
Sect. 5.6.5. For two processes following geometric Brownian motion, (4.53),
and representing the returns of two financial assets, the covariance matrix is
C
ij
=
7
δS
i
S
i
δS
j
S
j
8
− µ
i
µ
j
. (10.68)
The total variance of the processes is then