Пирс Б. Типы в языках программирования
Подождите немного. Документ загружается.

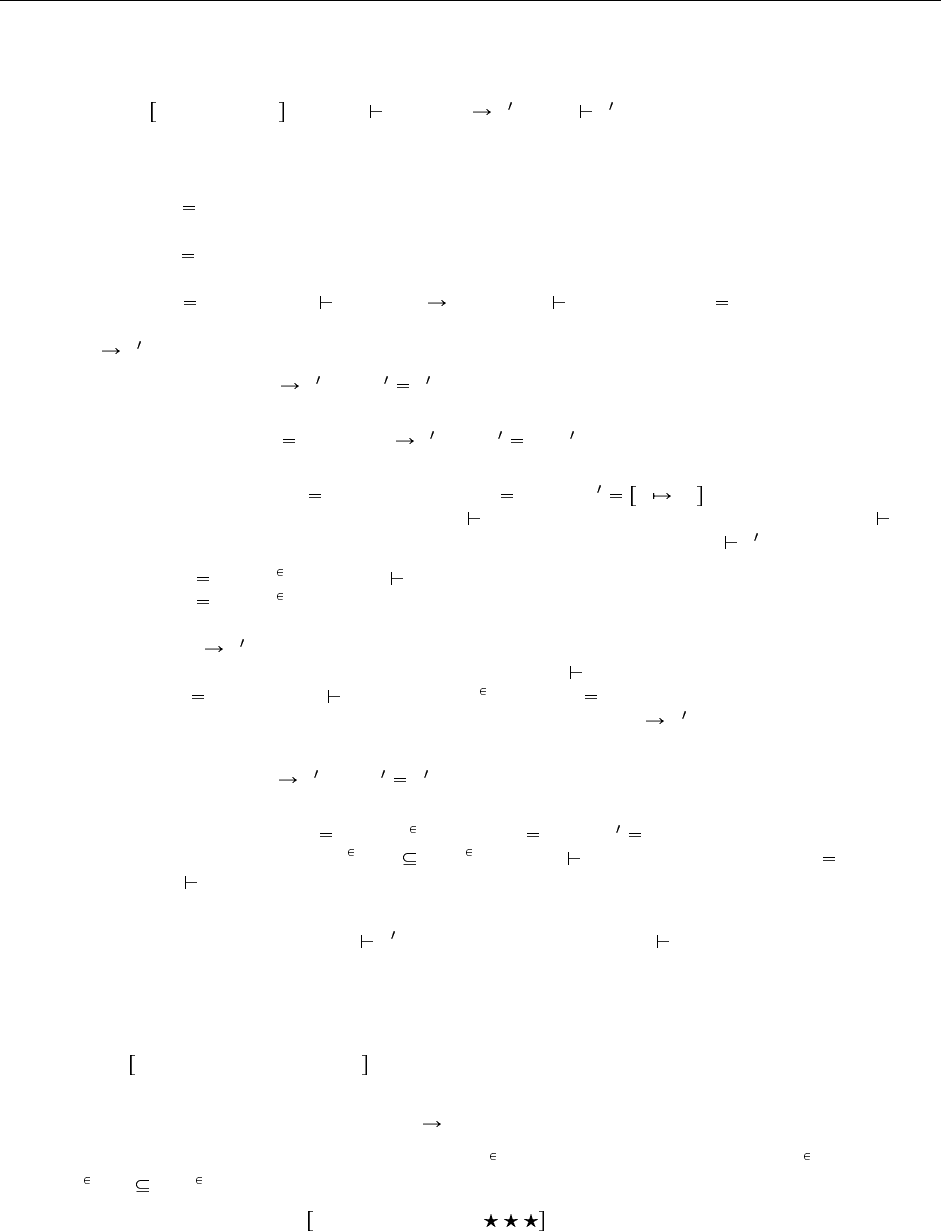
15.3. Свойства наследования и типизации 151
Теорема о сохранении формулируется точно так же, как и раньше. Однако наличие наследования
усложняет ее доказательство в нескольких местах.
Теорема 15.3.5 Сохранение : Если Γ t: T и t t , то Γ t : T.
Доказательство: Прямолинейная индукция по деревьям вывода типов. Большинство случаев подоб-
но доказательству сохранения для простого типизированного лямбда-исчисления (9.3.9). Требуется
рассмотрение новых вариантов для правил типизации записей и для включения.
Вариант T-Var: t x
Не может возникнуть (не существует правил вычисления для переменных).
Вариант T-Abs: t λx:T
1
.t
2
Не может возникнуть (t уже является значением).
Вариант T-App: t t
1
t
2
Γ t
1
: T
11
T
12
Γ t
2
: T
11
T T
12
Исходя из правил вычисления на Рис. 15.1 и 15.2, мы видим, что имеется три правила, позволяющих
вывести t t : E-App1, E-App2 и E-AppAbs. Рассмотрим эти варианты.
Подвариант E-App1: t
1
t
1
t t
1
t
2
Нужный нам результат следует из предположения индукции и правила T-App.
Подвариант T-App2: t
1
v
1
t
2
t
2
t v
1
t
2
Подобным же образом.
Подвариант T-AppAbs: t
1
λx:S
11
.t
12
t
2
v
2
t x v
2
t
12
По Лемме 15.3.3(1), T
11
<: S
11
и Γ, x:S
11
t
12
: T
12
. Согласно правилу T-Sub, Γ
t
2
: S
11
. Отсюда, используя лемму о подстановке (15.3.4), получаем Γ t : T
12
.
Вариант T-Rcd: t {l
i
=t
i
i 1..n
} Γ t
i
: T
i
для каждого i
T {l
i
:T
i
i 1..n
}
Единственное правило вычисления с записью на левой стороне — E-Rcd. Исходя из предпосылки этого
правила, мы видим t
j
t
j
для некоторого поля t
j
. Требуемый результат следует из предположения
индукции (примененного к соответствующеq предпосылке Γ t
j
: T
j
) и правила T-Rcd.
Вариант T-Proj: t t
1
.l
j
Γ t
1
: {l
i
: T
i
i 1..n
} T T
j
Исходя из правил вычисления на Рис. 15.1 и 15.2, мы видим, что t t может быть выведено из
двух правил: E-Proj, E-ProjRcd.
Подвариант E-Proj: t
1
t
1
t t
1
.l
j
Результат следует из предположения индукции и правила T-Proj.
Подвариант E-ProjRcd: t
1
{k
a
=v
a
a 1..m
} l
j
k
b
t v
b
По Лемме 15.3.3(2), имеем {l
i
i 1..n
} {k
a
a 1..m
} и Γ v
a
: T
i
для каждого k
a
l
i
. В
частности, Γ v
b
: T
j
, как нам и требуется.
Вариант T-Sub: t : S S <: T
Согласно предположению индукции, Γ t : S. По правилу T-Sub, Γ t : T.
Для того, чтобы показать, что правильно типизированные термы никогда не оказываются в тупике,
мы (как и в Главе 9) сначала доказываем лемму о канонических формах, которая указывает нам
возможные виды термов-значений, принадлежащих функциональным типам и типам записей.
Лемма 15.3.6 Канонические формы :
1. Если v — замкнутое значение типа T
1
T
2
, то v имеет вид λx:S
1
.t
2
.
2. Если v — замкнутое значение типа {l
i
:T
i
i 1..n
}, то v имеет вид {k
a
=v
a
a 1..m
}, причем
{l
i
i 1..n
} {k
a
a 1..m
}.
Доказательство: Упражнение Рекомендуется, .
Утверждение и доказательство теоремы о продвижении достаточно близки к тому, что мы уже ви-
дели для простого типизированного лямбда-исчисления. Большинство трудностей, связанных с насле-
дованием, оказалось обработано в лемме о канонических формах, и теперь требуется только несколько
небольших изменений.
rev. 104
152 15.4. Т ипы TOP и BOTTOM
<: Bot Расширяет λ
:
(15.1)
Новые синтаксические формы
T ::= типы:
Bot минимальный тип
Новые правила наследования S <: T
Bot <: T (S-Bot)
Рис. 15.4. Минимальный тип
Теорема 15.3.7 Продвижение : Если t — замкнутый правильно типизированный терм, то либо t
является значением, либо существует некоторый терм t’, такой, что t t .
Доказательство: Прямолинейная индукция по деревьям вывода типов. Вариант с переменной воз-
никнуть не может (поскольку t замкнут). Вариант с лямбда-абстракцией следует немедленно, так
как абстракции являются значениями. Оставшиеся варианты более интересны.
Вариант T-App: t t
1
t
2
t
1
: T
11
T
12
t
2
: T
11
T T
12
Согласно предположению индукции, либо терм t
1
является значением, либо он способен проделать
шаг вычисления. То же самое верно и по отношению к t
2
. Если t
1
способен проделать шаг, применимо
правило T-App1. Если t
1
— значение, а t
2
способен проделать шаг, то применимо правило T-App2.
Наконец, если оба терма t
1
и t
2
являются значениями, то, согласно лемме о канонических формах
(15.3.6), t
1
имеет вид λx:S
11
.t
12
, так что к t применимо правило E-AppAbs.
Вариант T-Rcd: t {l
i
=t
i
i 1..n
} для каждого i 1..n, t
i
: T
i
T {l
i
: T
i
i 1..n
}
Согласно предположению индукции, каждый из термов t
i
либо значение, либо способен проделать
шаг вычисления. Если все они значения, t целиком является значением. Если же какой-либо из них
способен проделать шаг, к t применимо правило E-Rcd.
Вариант T-Proj: t t
1
.l
j
t
1
: {l
i
:T
i
i 1..n
} T T
j
Согласно предположению индукции, терм t
1
либо значение, либо способен проделать шаг вычис-
ления. Если t
1
может проделать шаг, то, по правилу E-Proj, может и t. Если же t
1
— зна-
чение, то, согласно лемме о канонических формах (15.3.6), t
1
имеет вид {k
a
=v
a
a 1..m
}, причем
{l
i
i 1..n
} {k
a
a 1..m
} и для каждого l
i
k
j
, v
j
: T
i
. В частности, l
j
входит в набор меток
{k
a
a 1..m
} терма t
1
, откуда, по правилу E-ProjRcd, мы видим, что и сам терм t способен проде-
лать шаг вычисления.
Вариант T-Sub: Γ t : S S <: T
Результат прямо следует из предположения индукции.
15.4. Типы Top и Bottom
Максимальный тип Top не является необходимым элементом простого типизированного лямбда-
исчисления с наследованием; его можно убрать, не нарушая основных свойств системы. Однако боль-
шинство описаний включают этот тип, по нескольким причинам. Во-первых, он соответствует типу
Object, имеющемуся в большинстве объектно-ориентированных языков программирования. Во-вторых,
Top служит удобным техническим инструментом в более сложных системах, где наследование сочета-
ется с полиморфизмом. Например, в Системе F
:
(Главы 26 и 28) наличие типа Top позволяет получить
обыкновенную неограниченную квантификацию на основе ограниченной квантификации, и таким обра-
зом упрощает систему. Более того, в F
:
можно закодировать даже записи, и, таким образом, упростить
систему еще больше (по крайней мере, для целей формального исследования); такое кодирование невоз-
можно без Top. Наконец, поскольку поведение Top устроено несложно, и часто полезно использовать
этот тип в примерах, нет особых причин от него отказываться.
Естественно спросить, можно ли также дополнить отношение наследования минимальным элемен-
том — типом Bot, который является подтипом всякого другого типа. Ответ на этот вопрос положитель-
ный: такое расширение формально представлено на Рис. 15.4
Первое, что стоит заметить — тип Bot пуст; не существует замкнутых значений типа Bot.Если бы
они существовали, скажем, было бы такое значение v, то правило включения вместе с S-Bot позво-
лили бы нам вывести v : Top Top, откуда, по лемме о канонических формах (15.3.6; в нашем
rev. 104

15.5. Наследование и другие элементы языка 153
расширении она по-прежнему выполняется), следовало бы, что терм v должен иметь вид λx:S
1
.t
2
для
некоторых S
1
и t
2
. С другой стороны, по правилу включения, мы также имеем v : {}, откуда по
лемме о канонических формах следует, что v должен быть записью. Но из правил синтаксиса ясно, что
v не может одновременно являться функцией и записью, так что предположение v : Bot ведет к
противоречию.
Пустота Bot не означает бесполезности. Напротив: Bot дает программисту удобный способ выразить
информацию, что некоторая операция (в частности, порождение исключения или вызов продолжения)
не должна возвращать никакое значение. Если мы дадим таким выражениям тип Bot, это даст нам
два полезных результата: во-первых, это сообщает программисту, что никакого результата не ожида-
ется (поскольку если бы выражение имело результат, это оказалось бы значение типа Bot); во-вторых,
это дает знать программе проверки типов, что такое выражение безопасно использовать в контексте,
ожидающем любой тип значения. Например, если терм error из Главы 14, вызывающий исключение,
получит тип Bot, то терм вроде
λx :T.
if <проверка, что x имеет разумное значение> then
<вычислить результат>
else
error
будет правильно типизирован, поскольку, независимо от того, каков тип нормального результата, терм
error может получить тот же самый тип через включение, так что две ветви условного выражения
совместимы, как того требует правило T-If.
1
К сожалению, наличие Bot существенно осложняет задачу построения программы проверки типов
для нашей системы. Простой алгоритм проверки типов в языке с наследованием должен опираться на
рассуждения вроде «если терм-применение t
1
t
2
правильно типизирован, то t
1
должен иметь функ-
циональный тип». При наличии Bot приходится уточнить это утверждение до «если t
1
t
2
правильно
типизирован, то t
1
должен иметь либо функциональный тип, либо Bot»; этот вопрос подробнее обсуж-
дается в §16.4. Сложности еще возрастают в системах с ограниченной квантификацией; см. §28.8.
Эти сложности показывают, что добавление Bot в систему — более серьезный шаг, чем добавление
Top. В системах, рассматриваемых в оставшейся части книги, мы его опускаем.
15.5. Наследование и другие элементы языка
В то время как мы вводим наследование в наше простое исчисление, продвигая его в направлении
полноценных языков программирования, каждый новый элемент языка требует тщательного иссле-
дования, чтобы выяснить, как он взаимодействует с наследованием. В этом разделе мы рассмотрим
несколько конструкций, введенных нами на этот момент.
2
В последующих главах будет обсуждаться
(значительно более сложное) взаимодействие наследования с такими элементами языка, как параметри-
ческий полиморфизм (Главы 26 и 28), рекурсивные типы (Главы 20 и 21) и операторы типов (Глава 31).
15.5.1. Приписывание и приведение типов
Операция приписывания типа t as T введена в §11.4 как разнвовидность проверяемой докумен-
тации, которая позволяет программисту записать в тексте программы утверждение, что некоторый
подтерм составного выражения имеет определенный тип. Приписывание типов также используется
в примерах в тексте этой книги для управления тем, как распечатываются типы — с его помощью
программы проверки типов получают указания, что следует использовать более легкую для чтения
сокращенную форму, а не тот тип, который вычислен для терма во внутреннем представлении.
1
В языках с полиморфизмом, вроде ML, в качестве типа результата для error и других подобных конструкций мы
можем также использовать тип X.X. При этом тот же самый результат достигается другими средствами: вместо того,
чтобы давать error тип, который может быть повышен до любого другого, мы даем ему схему типа, которая может
быть конкретизирована до любого типа. Будучи основанными на различных механизмах, эти два решения в то же время
весьма похожи: в частности, тип X.X также пуст.
2
Большинство расширений, обсуждаемых в этом разделе, не реализованы в программе проверки типов fullsub.
rev. 104

154 15.5. Наследование и другие элементы языка
В языках с наследованием, таких, как C или Java, приписывание типов оказывается намного бо-
лее интересной операцией. Оно часто называется приведением типов и записывается (T)t. Имеется две
совершенно различные формы приведения типов — восходящее и нисходящее. Первая разновидность не
представляет сложностей; вторая, включающая динамическую проверку типов, требует существенного
расширения языка.
Восходящее приведение, где терму приписывается надтип того типа, который был бы ему присвоен
естественным образом, является частным случаем обыкновенной операции приписывания типа. Мы
ссобщаем компилятору терм t и тип T, с точки зрения которого мы хотим «рассматривать» t. Про-
грамма проверки типов убеждается, что T действительно один из типов терма t, пытаясь построить
дерево вывода
.
.
.
Γ t : S
.
.
.
S <: T
Γ t : T
T-Sub
Γ t as T : T
T-Ascribe
с использованием «естественного» типа T, правила включения T-Sub и правила приписывания типа из
§11.4:
Γ t
1
: T
Γ t
1
as T : T
(T-Ascribe)
Восходящее приведение типов можно рассматривать как разновидность абстракции — как способ спря-
тать некоторые детали значения, чтобы их нельзя было использовать в некотором окружающем кон-
тексте. Например, если t является записью (или, в более общем случае, объектом), то при помощи
восходящего приведения можно упрятать некоторые из ее полей (или методов).
Нисходящее приведение, с другой стороны, позволяет нам приписывать термам типы, которые про-
грамма проверки статически приписать им не может. Чтобы разрешить нисходящее приведение, мы
вносим несколько неожиданное изменение в правило типизации для as:
Γ t
1
: S
Γ t
1
as T : T
(T-Downcast)
А именно, мы прверяем, что терм t
1
правильно типизирован (т. е., имеет некоторый тип S), а затем при-
сваиваем ему тип T, не выдвигая при этом никаких требований о взаимном отношении S и T. Например,
с помощью нисходящего приведения мы можем написать функцию, принимающую какой угодно вооб-
ще аргумент, приводящую этот аргумент к типу записи, содержащей числовое поле, и возвращающую
это поле
f = λ(x: Top ) ( x as { a : Nat }). a;
В сущности, прграммист говорит программе проверки типов: «Я знаю (из соображений, слишком слож-
ных, чтобы объяснить их в рамках правил типизации), что f всегда будет применяться к аргументам-
записям, содержащим числовое поле a; я хочу, чтобы ты мне поверила».
Разумеется, слепая вера в такие утверждения имела бы ужасающие последствия для безопасности
нашего языка: если программист почему-либо допустит ошибку и применит f к записи, не содержащей
поля a, результат может (в зависимости от устройства компилятора) быть совершенно непредсказу-
емым. Вместо этого, мы должны руководствоваться принципом «Доверяй, но проверяй». Во время
компиляции программа проверки просто принимает тип, указанный в нисходящем приведении. Одна-
ко она вставляет в код тест, который во время выполнения убедится, что представленное значение на
самом деле имеет нужный тип. Другими словами, правило вычисления для выражений приписывания
типа не должно теперь просто отбрасывать аннотацию, как делало наше исходное правило:
v
1
as T v
1
(E-Ascribe)
а вместо этого должно сравнивать реально наблюдаемый (во время выполнения) тип значения с объ-
явленным типом:
v
1
: T
v
1
as T v
1
(E-Downcast)
Например, если мы применяем вышеуказанную функцию f к аргументу {a=5,b=true}, то наше пра-
вило (успешно) проверит, что {a=5,b=true} : {a:Nat}. С другой стороны, если мы ее применим к
rev. 104
15.5. Наследование и другие элементы языка 155
{b=true}, то правило E-Downcast будет непригодно, и вычисление окажется в тупике. Такая проверка
во время выполнения восстанавливает свойство сохранения типов.
Упражнение 15.5.1 : Докажите это.
Разумеется, при этом мы теряем свойство продвижения, поскольку, безусловно, правильно типизиро-
ванная программа может оказаться в тупике при попытке выполнить неверное нисходящее приведение
типа. Языки, имеющие нисходящее приведение, обычно справляются с этим одним из двух способов: ли-
бо неудачное нисходящее приведение возбуждает динамическое исключение, которое программа может
перехватить и обработать (см. Главу 14), либо вместо операции нисходящего приведения используется
разновидность динамической проверки типа:
Γ t
1
: S Γ, x:T t
2
: U Γ t
3
: U
Γ if t
1
in T then x t
2
else t
3
: U
(T-Typetest)
v
1
: T
if v
1
in T then x t
2
else t
3
x v
1
t
2
(E-Typetest1)
v
1
: T
if v
1
in T then x t
2
else t
3
t
3
(E-Typetest2)
В языках вроде Java нисходящие приведения типов встречаются довольно часто. А именно, с их по-
мощью организуется своего рода «полиморфизм для бедных». Например, «классы-контейнеры» вроде
Set или List в Java мономорфны: вместо того, чобы иметь тип List T (список, содержащий элементы
типа T) для каждого типа T, Java дает программисту только List — тип списков, чьи элементы принад-
лежат максимальному типу Object. Поскольку в Java Object является надтипом всякого другого типа
объектов, это означает, что на самом деле списки могут содержать что угодно: когда нам требуется до-
бавить какой-то элемент к списку, мы просто используем включение и повышаем тип этого элемента до
Object. Однако когда мы извлекаем элемент из списка, процедура проверки типов знает только то, что
он обладает типом Object. Этот тип не позволяет вызывать большинство методов объекта, поскольку
описание Object упоминает только несколько самых общих методов вроде распечатки, имеющихся у
всех объектов Java. Чтобы сделать с элементом что-либо полезное, нам приходится приводить его вниз
к некоторому ожидаемому типу T.
Многократно выдвигались предложения — например, разработчиками языков Pizza (Odersky and
Wadler 1997), GJ (Bracha, Odersky, Stoutamire and Wadler 1998), PolyJ (Myers, Bank and Liskov 1997)
и NextGen (Cartwright and Steele 1998), — ввести в систему типов Java настоящий полиморфизм (см.
Главу 23), поскольку он одновременно безопасней и эффективней трюка с нисходящим приведением
типов, и не требует никаких проверок во время исполнения. С другой стороны, такие расширения уве-
личивают сложность языка, который и так достаточно велик, и нетривиально взаимодействуют с дру-
гими элементами языка (см., например, работы Игараси, Пирса и Уодлера (Igarashi, Pierce and Wadler
1999, 2001)); это усиливает позиции тех, кто считает нисходящие приведения разумным практическим
компромиссом между безопасностью и сложностью.
Нисходящие приведения играют ключевую роль также и в поддержке рефлексии в Java. Использя
рефлексию, программист может потребовать от рабочей среды Java динамической загрузки байт-кода и
порождения экземпляров какого-либо содержащегося там класса. Ясно, что процедура проверки типов
никоим образом не может статически предсказать свойства классов, которые будут загружены таким
образом (к примеру, байт-код может быть получен откуда-нибудь из сети), так что она может только
присвоить новым экземплярам максимальный тип Object. И опять, чтобы осуществить какую-либо
полезную работу, нам приходится приводить новый объект к некоторому ожидаемому типу T, обраба-
тывать исключения, которые могут возникнуть, если класс в байт-коде на самом деле не совместим с
этим типом, и, наконец, использовать этот объект с типом T.
В заключение разговора про нисходящие приведения нужно сделать замечание о реализации. Ис-
ходя из данных нами правил, кажется, что их введение в язык требует добавления всех механизмов
проверки типов в среду времени выполнения. Хуже того, поскольку, как правило, при выполнении
значения представляются иначе, чем во время компиляции (в частности, функции компилируются в
байт-код или в команды машинного языка), похоже, нам придется писать отдельную процедуру для
rev. 104
156 15.5. Наследование и другие элементы языка
<> <: Расширяет λ
:
(15.1) и простые правила для вариантов (11.11)
Новые синтаксические формы
t ::= . . . термы:
<l=t> (без as) постановка тега
Новые правила типизации Γ t : T
Γ t
1
: T
1
Γ <l
1
=t
1
> : <l
1
:T
1
>
(T-Variant)
Новые правила наследования S <: T
<l
i
:T
i 1..n
i
> <: <l
i
:T
i 1..n k
i
> (S-VariantWidth)
для каждого i, S
i
<: T
i
<l
i
:S
i 1..n
i
> <: <l
i
:T
i 1..n
i
>
(S-VariantDepth)
<k
j
:S
j 1..n
j
>является перестановкой<l
i
:T
i 1..n
i
>
<k
j
:S
j 1..n
j
<: <l
i
:T
i 1..n
i
>
(S-VariantPerm)
Рис. 15.5. Варианты и наследование
вычисления типов, производимого при проверке во время выполнения. Чтобы избежать этого, в на-
стоящих языках нисходящие приведения сочетаются с тегами типов — тегами размером в одно слово
(довольно похожими на конструкторы типов данных в ML и на теги вариантов в §11.10), которые
представляют «остаточную» информацию о типах, используемых при компиляции, и служат для ди-
намической проверки наследования. В Главе 19 детально рассматривается пример такого механизма.
15.5.2. Варианты
Правила наследования для вариантов (см. §11.10) почти совпадают с правилами для записей; еслин-
ственное различие в том, что правило наследования в ширину S-VariantWidth позволяет добавлять, а
не отбрасывать, новые варианты при переходе от подтипа к надтипу. Интуиция здесь такова, что выра-
жение с тегом <l=t> принадлежит типу вариантов <l
i
:T
i
i 1..n
>, если его метка l — одна из возможных
меток l
i
, перечисленных в определении типа; добавление новых меток к этому множеству уменьшает
информацию, которой мы располагаем об элементах типа. Вариантный тип с одним вариантом <l
1
:T
1
>
точно указывает, какой меткой обозначаются его элементы; двухвариантный тип <l
1
:T
1
,l
2
:T
2
> гово-
рит, что его элементы отмечены либо меткой l
1
, либо меткой l
2
, и т. д. С другой стороны, когда мы
используем вариантные значения, это всегда происходит в рамках выражения case, где на каждый
вариант, указанный для типа, имеется одна ветвь — если будет больше вариантов, это приведет только
к тому, что предложения case будут включать ненужные дополнительные ветви.
Еще одним следствием сочетания наследования и вариантов является то, что мы теперь можем
отказаться от аннотаций в конструкции навешивания тега, и писать просто <l=t> вместо <l=t> as
<l
i
>:T
i
i 1..n
, как нам приходилось делать в §11.10. Тепрь мы можем упростить правило типизации для
этой конструкции и сказать, что <l
1
=t
1
> имеет точный тип <l
1
=T
1
>. Любой более крупный вариантный
тип получается через включение и правило S-VariantWidth.
15.5.3. Списки
Мы уже видели несколько примеров ковариантных конструкторов типов (записи и варианты, а
также функциональные типы по правому аргументу) и один контравариантный конструктор (стрелка,
по левому аргументу). Коструктор List также ковариантен: если у нас есть список, чьи элементы
обладают типом S
1
, и при этом S
1
<: T
1
, то мы можем без опаски считать, что список имеет элементы
типа T
1
.
S
1
<: T
1
List S
1
<: List T
1
(S-List)
15.5.4. Ссылки
Не все конструкторы типов являются либо ковариантными, либо контравариантными. К примеру,
конструктор Ref должен, чтобы сохранить типовую безопасность, рассматриваться как инвариантный.
rev. 104

15.5. Наследование и другие элементы языка 157
S
1
<: T
1
T
1
<: S
1
Ref S
1
<: Ref T
1
(S-Ref)
Чтобы Ref S
1
считался подтипом Ref T
1
, мы требуем, чтобы S
1
и T
1
были эквиваленитны с точ-
ки зрения отношения наследования — каждый должен быть подтипом другого. Это позволяет нам
переупорядочивать поля записей внутри конструктора Ref — скажем, Ref {a:Bool,b:Nat} <: Ref
{b:Nat,a:Bool}, — но ничего больше.
Причина того, что правило наследования настолько ограничено, состоит в том, что в любом данном
контексте значение типа Ref T
1
может использоваться двумя способами: для чтения (!) и записи (:=).
Когда значение используется для чтения, контекст ожидает получить значение типа T
1
, так что, если на
самом деле ссылка вернет значение типа S
1
, нужно, чтобы было S
1
<: T
1
, иначе ожидания контекста
будут нарушены. С другой стороны, если та же самая ссылочная ячейка используется для записи,
то новое значение, предоставляемое контекстом, будет иметь тип T
1
. Если тип ссылки на самом деле
Ref S
1
, кто-нибудь потом может прочитать значение по ссылке и использовать его как S
1
; это будет
безопасно только в случае, когда T
1
<: S
1
.
Упражнение 15.5.2 (1) Напишите короткую программу, которая приведет к ошибке времени
выполнения (т. е., вычислепние зайдет в тупик), если мы откажемся от первой предпосылки S-
Ref. (2) Напишите другую программу, которая приведет к ошибке, если отброжена будет вторая
предпосылка.
15.5.5. Массивы
Ясно, что причины, побудившие нас принять инвариантное правило наследования для ссылок, дей-
ствуют и в случае с массивами, поскольку операции с ними включают как разыменование, так и при-
сваивание.
S
1
<: T
1
T
1
<: S
1
Array S
1
<: Array T
1
(S-Array)
Интересно, что Java разрешает ковариантное наследование для массивов:
S
1
<: T
1
Array S
1
<: Array T
1
(S-ArrayJava)
(в синтаксисе Java, S
1
[] <: T
1
[]). Такая конструкция исходно была введена, чтобы скомпенсировать
отсутствие параметрического полиморфизма при типизации некоторых базовых операций, вроде копи-
рования массивов, но сейчас большинство специалистов считают ее ошибкой в проектировании языка,
поскольку она серьезно влияет на производительность программ, использующих массивы. Это проис-
ходит потому, что небезопасное правило наследования приходится компенсировать проверкой во время
выполнения, при каждом присваивании каждому массиву, чтобы убедиться, что записываемое значе-
ние принадлежит (подтипу) действительного типа элементов массива.
Упражнение 15.5.3 : Напишите короткую программу на Java с использованием массивов,
так, чтобы она проходила проверку типов, но ломалась (порождая ArrayStoreException) во время
выполнения.
15.5.6. Снова ссылки
Путем введения двух новых конструкторов типов, Source («кран» ) и Sink («слив»), можно полу-
чить более мощную реализацию ссылок, впервые исследованную Рейнольдсом (Reynolds 1988) в языке
Forsythe. С интуитивной точки зрения, Source T представляет способность считывать значения типа
T из ячейки (но не присваивать значение), а Sink T представляет способность записывать значение в
ячейку. Ref T сочетает обе эти способности и дает разрешение как на чтение, так и на запись.
Правила типизации для разыменования и присваивания (Рис. 13.1) модифицируются так, чтобы
проверять только соответствующую каждому из них способность:
Буквально «источник». Здесь используется метафора входной и выводящей трубы в какой-либо емкости. — прим.
перев.
rev. 104
158 15.6. Семантика наследования, основанная на преобразованиях типов
Γ Σ t
1
: Source T
11
Γ Σ !t
1
: T
11
(T-Deref)
Γ Σ t
1
: Sink T
11
Γ Σ t
1
: T
11
Γ Σ t
1
:= t
2
: Unit
(T-Assign)
Теперь, если у нас есть только способность считывать значение ячейки, и если имеется гарантия, что
эти значения будут иметь тип S
1
, мы можем без опаски «понизить» эту способность до способности
читать значения типа T
1
, в том случае, если S
1
является подтипом T
1
. Таким образом, конструктор
Source ковариантен.
S
1
<: T
1
Source S
1
<: Source T
1
(S-Source)
С другой стороны, способность записывать значения типа S
1
в данную ячейку может быть понижена до
способности записывать значения некоторого меньшего типа T
1
: конструктор Sink контравариантен.
T
1
<: S
1
Sink S
1
<: Sink T
1
(S-Sink)
Наконец, мы выражаем интуицию, что тип Ref T
1
представляет комбинацию способностей к чтению и
к записи, при помощи двух правил наследования, которые позволяют понизить ссылку Ref до крана
Source или до слива Sink.
Ref T
1
<: Source T
1
(S-RefSource)
Ref T
1
<: Sink T
1
(S-RefSink)
15.5.7. Каналы
Такая же интуиция (и те же самые правила наследования) служит основанием подхода к типам
каналов, представленного современными языками для параллельного программирования вроде Pict
(Pierce and Turner 2000; Pierce and Sangiorgi 1993). Главное наблюдение здесь состоит в том, что с точ-
ки зрения типизации канал межпроцессного взаимодействия ведет себя точно так же, как ссылочная
ячейка: его можно использовать для чтения и для записи, и, поскольку трудно статически опреде-
лить, какие операции чтения соответствуют каким операциям записи, едиственный простой способ
обеспечить типовую безопасность состоит в требовании, чтобы все значения, передаваемые по кана-
лу, принадлежали одному типу. Теперь если мы передадим какому-либо процессу только способность
писать в определенный канал, он может без опаски передавать эту способность кому-либо, кто обеща-
ет записывать в канал значения меньшего типа — конструктор «канал для записи» контравариантен.
Подобным образом, если мы передаем только способность читать из канала, эту способность можно
безопасно понизить до способности читать значения любого большего типа — конструктор «канал для
чтения» является ковариантным.
15.5.8. Базовые типы
В полноразмерном языке с богатым набором базовых типов часто полезно бывает ввести отношения
наследования между этими базовыми типами. Например, во многих языках булевские значения true
и false на самом деле представляются в виде чисел 1 и 0. Мы можем, если пожелаем, показать это
программисту, введя аксиому наследования Bool <: Nat. Тогда становятся возможными компактные
выражения вроде 5*b вместо if b then 5 else 0.
15.6. Семантика наследования, основанная на преобразованиях
типов
На протяжении этой главы мы следовали интуиции, что наследование «семантически несуществен-
но». Наличие наследования никак не влияет на процесс исполнения программ; наследование лишь поз-
воляет добавить некоторую гибкость в правила типизации. Такая интерпретация проста и естественна,
rev. 104
15.6. Семантика наследования, основанная на преобразованиях типов 159
но она ведет к некоторым потерям в эффективности — особенно при численных расчетах и при до-
ступе к полям записей, — и эти потери могут оказаться неприемлемыми в высокопроизводительных
реализациях. В этом разделе мы сделаем набросок альтернативной семантики на основе преобразова-
ния типов и обсудим некоторые вопросы, возникающие уже в связи с таким новым подходом. При
желании этот раздел можно пропустить.
15.6.1. Проблемы семантики, основанной на подмножествах
Как мы видели в §15.5, часто бывает удобно разрешить наследование между различными базовыми
типами. Однако некоторые «интуитивно понятные» отношения включения между базовыми типами
могут оказаться вредными с точки зрения производительности. Допустим, например, что мы введем
аксиому Int <: Float, так, чтобы можно было использовать целые числа в вычислениях с плавающей
точкой без явных преобразований — например, писать 4.5 + 6 вместо 4.5 + intToFloat(6). При се-
мантике, основанной на подмножествах это означает, что множество целых числовых значений должно
буквально являться подмножеством значений с плавающей точкой. Однако в большинстве реальных
машин конкретные представления целых чисел и чисел с плавающей точкой совершенно различны:
целые обычно представлены в форме кодов с дополнением до двух, а числа с плавающей точкой разде-
лены на поля мантиссы, показателя степени и знаковое, плюс имеются некоторые особые случаи вроде
NaN (не-число).
Чтобы согласовать такое расхождение в представлениях с семантикой на основе подмножеств, мы
можем принять общее теговое (или упакованное) представление для чисел: целое число представляется
как машинное целое, снабженное тегом (располагающимся либо в отдельном слове-заголовке, либо в
старших разрядах слова, содержащего само целое число), а число с плавающей точкой представляется
как машинное число с плавающей точкой, снабженное другим тегом. В таком случае тип Float относит-
ся ко всему множеству помеченных тегами чисел, в то время как Int относится только к помеченным
целым.
Такая схема вполне разумна: она соответствует стратегии представления, реально применяемой
во многих современных реализациях языков, где теговые биты (или слова) нужны также при сборке
мусора. Недостаток ее состоит в том, что всякая элементарная операция над числами должна реализо-
вываться как сочетание проверки тега на аргументах, нескольких машинных команд для извлечения
самого числа, одной команды для самой операции, и пары команд для навешивания тега на результат.
Изощренные оптимизации в компиляторе могут уничтожить часть лишних действий, но даже с луч-
шими из имеющихся методов производительность сильно страдает, особенно в коде, содержащем много
численной работы, вроде графических или научных вычислений.
Другая проблема с производительностью возникает, когда наследование сочетается с записями — в
частности, при применении правила перестановки полей Наше простое правило вычисления для про-
екции поля
{l
i
=v
i 1..n
i
}.l
j
v
j
(E-ProjRcd)
можно читать так: «найти среди меток полей записи l
j
, и вернуть соответствующее значение v
j
». Од-
нако в настоящей реализации мы, безусловно, не хотим проводить линейный просмотр полей записи в
поисках нужной метки. В языке без наследования (или с наследованием, но без правила перестановки)
можно получить значение намного быстрее: если метка l
j
идет третьей в типе записи, то мы уже во
время компиляции знаем, что все значения данного типа будут содержать l
j
как третье поле, так что
во время выполнения нам вовсе не нужно смотреть на метки (мы вообще можем исключить их из пред-
ставления записей во время выполнения, в сущности, превращая записи в кортежи). Чтобы получить
значение поля l
j
, мы порождаем команду косвенной загрузки через регистр, указывающий на начало
записи, с постоянным смещением в 3 слова. Наличие правила перестановки делает этот метод невоз-
можным, поскольку информация, что некоторое значение записи принадлежит типу, где l
j
является
третьим полем, ничего не говорит нам о том, где на самом деле внутри записи хранится поле l
j
. Опять
же, сложные оптимизации и трюки кодирования могут уменьшить потери, но в общем случае проекция
поля может потребовать некоторой формы поиска во время выполнения.
3
3
Похожие наблюдения применимы и к поиску полей и методов объектов в языках, где наследование объектов позволяет
перестановку полей. Именно по этой причине, например, Java ограничивает наследование между классами так, что новые
поля могут добавляться только в конце. Наследование между интерфейсами (а также между классом и интерфейсом)
rev. 104
160 15.6. Семантика наследования, основанная на преобразованиях типов
15.6.2. Семантика, основанная на п реобразовании типов
Обе эти проблемы можно решить, если принять другую семантику, где наследование «исчезает при
компиляции» и заменяется преобразованиями типа во время выполнения. Если, скажем, во время про-
верки типов Int повышается до Float, то во время выполнения мы физически изменяем преставление
числа с машинного целого на машинное число с плавающей точкой. Подобным образом использование
правила перестановки при наследовании компилируется в участок кода, который физически изменяет
порядок полей записи. После этого элементарные численные операции и доступ к полям могут выпол-
няться без дополнительных расходов на снятие тегов или поиск.
С интуитивной точки зрения, сематика, основанная на преобразованях типа, для языка с наследо-
ванием выражается в виде функции, которая переводит термы этого языка в язык нижнего уровня,
где наследование отсутствует. В конечном счете этот низкоуровневый язык может быть машинным
кодом некоторого конкретного процессора. Однако для целей изложения мы можем продолжить об-
суждение на более абстрактном уровне. В качестве исходного языка мы примем язык, используемый
нами в большей части этой главы — простое типизированное лямбда-исчисление с наследованием и
записями. Для низкоуровневого целевого языка мы выбираем язык чистого простого типизированного
лямбда-исчисления с записями и типом Unit (мы используем последний, чтобы смоделировать Top).
Формально компиляция представляется тремя функциями перевода — для типов, для наследования
и для типизации. В случае типов функция перевода просто заменяет Top типом Unit. Мы записываем
эту функцию как J K.
JTopK Unit
JT
1
T
2
K JT
1
K JT
2
K
J{l
i
:T
i
i 1..n
}K {l
i
:JT
i
K
i 1..n
}
Например, JTop {a:Top,b:Top}K Unit {a:Unit,b:Unit}. (Остальные функции перевода также бу-
дут обозначаться J K; из контекста всегда будет ясно, которая функция имеется в виду.)
Чтобы перевести терм, мы должны знать, где при выводе его типа используется правило включе-
ния, поскольку именно в этих местах будет вставлено преобразование типа во время выполнения. Оин
из удобных способов формализовать это наблюдение — определить перевод как функцию на деревьях
вывода утверждений о типизации. Подобным образом, чтобы породить функцию преобразования, пере-
водящую значения типа S в тип T, мы должны знать не только сам факт, что S является подтипом T, но
и почему это так. Мы добиваемся этого, порождая преобразования из деревьев вывода наследования.
Для формализации перевода требуется соглашение по именованию деревьев вывода. Запись C ::
S <: T будет означать «C — дерево вывода наследования с заключением S <: T». Подобным образом,
D :: Γ t : T будет значить «D — дерево вывода типов с заключением Γ t : T».
Рассмотрим сначала функцию, которая на основе дерева вывода C для утверждения о наследова-
нии S <: T порождает преобразование JCK. Преобразование это не что иное как функция (в целевом
языке перевода λ ) из типа JSK в тип JTK. Определение рассматривает варианты последнего правила,
разрешает перестановку — иначе интерфейсы оказались бы практически бесполезны, — и руководство по языку явно
предупреждает, что поиск метода в интерфейсе в общем случае происходит медленнее, чем в классе.
rev. 104