Peube J-L. Fundamentals of fluid mechanics and transport phenomena
Подождите немного. Документ загружается.

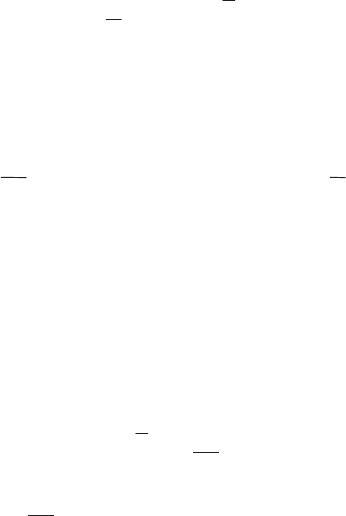
Measurement, Representation and Analysis of Temporal Signals 383
7.3.6.3. Fourier transform of a discretized signal
The sampling function is a periodic function of period T. Its development as a
Fourier series can be immediately written by calculating the Fourier coefficients
(section 7.3.3.1) of the Dirac function on interval [-T/2, T/2]:
integer
1
)(
__
2
ke
T
t-kTt
k
k
k
T
t
j
k
k
T
¦¦
f
f
f
f
S
G
III
Using the previous second expression of function )(
__
t
T
III
and results from
section 7.3.4.2.1, it is easy to obtain:
T
f
kkf
f
F
k
k
1
integer,,)(
1
00
0
_
_
¦
f
f
Q
G
Q
T
II
I
For a discretized signal of finite duration, which can be written as:
integer,)()( kdttst-kTkTs
Nk
Nk
¦
³
f
f
G
the Fourier transform is equal to:
integer-
1
-*
1
)(*
0
0
0
0
2
_
_
kkf
F
f
kf
F
f
e
F
F
F
k
k
s
k
k
s
k
k
k
T
t
j
s
¦
¦¦
f
f
f
f
f
f
Q
Q
G
Q
S
II
I
s.
T
The Fourier transform of the sampled signal is the transform of the signal s(t)
which is completed by a periodization on the frequency axis, with a period equal to
f
0
= 1/T.
The other integral transformations studied earlier can also be applied to
discretized signals. The essential physical notions already discussed for these apply
equally to the discretized signals; of course it is necessary to take account of the
numerical aspects associated with the discretization ([BEE 03], [BEL 02], [FLA 98],
[JER 92], [PRI 91]).

384 Fundamentals of Fluid Mechanics and Transport Phenomena
7.3.6.4.
Errors associated with digital techniques
The digitization of analog signals can be performed by means of devices
comprising a fixed number of digits (8, 12, 16, etc., binary digits). A quantification
(or rounding) error results, which is all the greater as the number of significant
digits is small. For example, the representation on 12 bits allows the representation
of 2
12
(=4,096) numerical values; thus a relative precision far greater than 1/1,000
cannot be hoped for, and this is on condition that the 12 bits are nearly all used. For
example, if the 12 bits allow the representation of numerical values between 0 and
100, the absolute quantification error of a given number is in the order of 100.2
-12
,
i.e. about 0.03; only 5 and 6 bits will be used to represent the number 1.378,
corresponding to a relative accuracy of the order of 2%. The preceding error is
similar to the reading error of measurements on analog apparatus, for which it is
necessary that the quantity to be measured is near of the full scale used.
The errors associated with discretization are greater in proportion to the
evolutionary rapidity of the phenomena as in impulse signals. In practice, an
impulse is applied over a certain duration; if this duration is in the order of a very
small number of temporal points, the measurement error may be very great. This
loss moreover corresponds to irreversible information loss.
In section 7.3.6.3, we saw that signal discretization leads to the periodization of
the Fourier transform of continuous signal. In order to reconstruct this initial signal,
it is thus necessary to conserve one period of the spectrum, and this assumes that the
Fourier transforms of each period do not overlap: if N is the sampling frequency, the
signal spectrum should not contain frequencies greater than N/2. This result
constitutes Shannon’s theorem.
3
In these conditions, by taking the inverse Fourier
transform of the central period of the spectrum, we exactly reconstruct the initial
discretized signal without any information loss.
The result of this, given that any signal will contain parasite noise of various
origins and different characteristics, is that it is necessary to suppress the higher
frequencies vis-à-vis Shannon’s theorem. This is the role of low-pass filters
positioned before the analog-to-digital converter; these filters are called anti-aliasing
filters (as they prevent energy at frequencies higher than the Shannon limit from
appearing in the lower frequencies, this being due to the partial overlapping of two
successive periods of periodized spectrum). We cannot discuss these problems in
greater detail; the interested reader should refer to texts on signal processing.
3
A usual and equivalent statement of Shannon’s theorem is that a signal comprising only
frequencies up to p Hz must be sampled at 2p Hz at least, so as not lose any information.
Measurement, Representation and Analysis of Temporal Signals 385
7.3.6.5.
Discrete transformations of discretized signals
The transforms described above operate on signals with continuous or discrete
values, but they provide continuous values. These need to be discretized in order
that they can be stored or transformed numerically. In most practical cases,
numerical calculations of integral transforms are performed by means of algorithms
applied to discretized signals that directly provide discrete values.
As a result of binary representation of numerical values, transform algorithms
can be greatly simplified for ensembles of values whose number is a power of two.
The fast Fourier transform is performed by means of a fast algorithm proposed by
Tuckey. Any signal s(t), which is discretized into 2
n
values, will have a discrete
Fourier transform that contains as many values in the frequency domain as the
discretized temporal signal contained. There has thus not been any data reduction
compared with the initial signal. However, for a real signal, on account of the
properties of evenness, the number of significant values is equal to 2
n-1
.
Furthermore, the discretization of an unknown signal can create difficulties.
Consider a temporal signal composed of p narrow impulses. Its analysis and
representation are clearly quite simple in the continuous temporal domain. However,
the discretization obtained by temporal sampling will constitute a rather poor
representation of the signal s(t) if the impulses do not occur at the measurement
instants. On the other hand, the Fourier transform of the discretized signal is a sum
of complex exponentials the properties of which are not immediately obvious.
This difficulty is also encountered in the frequency domain for the identification
of one or several isolated peaks (harmonic oscillations) if the central frequencies of
the peaks are not equal to one of the frequencies of the sampled spectrum obtained.
It is for this reason that if we want an accurate measure of a spectrum’s peak
amplitude (a sound spectrum for example), it is important to choose window
functions which broaden the peak, while at the same time suppressing the secondary
lobes of the Fourier transform of the window ([BEL 98], [HIG 93], [MAD 98]).
7.3.7. Data compression
7.3.7.1.
Introduction
Files containing raw numerical values can be extremely large, even after
transformation. Images for example, in comparison with sound and text, consume an
enormous quantity of data when digitized. Experimental modern measurements also
produce large quantities of numerical data. It is thus necessary to reduce the size of
the files for storage by exploiting the power of processors, and it would not be
appropriate to discuss signal representation without recalling certain specific
386 Fundamentals of Fluid Mechanics and Transport Phenomena
procedures of data compression. This is achieved by exploiting particular
properties of data that result from arithmetic or numerical properties of the signal
studied or of one of its transforms.
Data compression procedures may or may not be accompanied by data loss.
Their efficiency can be evaluated by means of a degree of compression (volume of
the compressed file/volume of initial file). These are classed according to two main
categories depending on the arithmetic or analytic nature of the characteristics that
are exploited.
7.3.7.2.
Arithmetic methods of data compression
A sequence of numerical values often presents particular combinational
properties: for example, real numbers have a periodic decimal development. Any
data file comprises a sequence of numerical values, which is not the result of pure
chance, as they always represent some specific information. This implies that the
file belongs to a certain class of files and it therefore possesses certain arithmetic
particularities, which can be demonstrated. For example, an image is not made up of
numerical values chosen at random – it includes certain structures (contours, color-
ranges, etc.) which correspond to the images it represents. An image constituted of
random pixels will most likely not represent anything at all. Similarly, a sequence of
letters chosen randomly has a very small probability of representing a text. To
clarify this, consider the following: the number of permutations, without repetition,
of the 26 letters of the alphabet (equal to 26!) is of the order of 4 × 10
26
. If we admit
repetition, the number of combinations is much greater. It is clear that this number is
far greater than the number of meaningful sentences comprising only 26 letters that
it is possible to write in a given language. Text files thus form a particular class of
files.
The combinatory particularities of a class of files can be used in order to define
appropriately adapted representation conventions. It is therefore possible to estimate
that such an encoding of a file will allow the reduction of its size. Of course, the
reverse decoding operation must be possible without any ambiguity.
Arithmetic methods of compression involve searching for numerical structures in
a sequence of values of a file and exploiting the multiplicity of their occurrence. Let
us consider three examples:
– the method of repetition involves “factorizing” the sequences which are
repeated one after another; for example, a sequence of 30 identical values (96 for
example) for consecutive pixels of an image will be denoted 96*30 instead of (96,
96, 96, etc.); a suitable convention for writing the file is obviously necessary;
– the dictionary method involves recognizing the structure of values which are
repeated and are thus indexed; the name “dictionary” derives from the fact that a
Measurement, Representation and Analysis of Temporal Signals 387
text is not a random sequence of letters, but rather a sequence of words which we
sort and store in a dictionary, indexing them by order of their appearance in the
dictionary. The compressed file is thus the dictionary, and the text is encoded with
the order numbers of the words used. While the words of a text are easy to read,
numerical structures (sequences of similar bytes) of an image file must be sought
with a suitable algorithm. It is also possible to establish a partial dictionary by not
encoding isolated values, which are not recognized as part of a repeated structure.
This method is applicable to all types of files.
– the Huffman method, which is entirely statistical, is based on the fact that in
language, all the letters are not used with the same frequency. In French, for
example, the probability of encountering the vowel “a” is 17.3%, whereas that of
encountering the consonant “w” is 0.05%. Now, letters are encoded on 8 bits
(ASCII characters). In general, a byte file contains variable occurrences for the
different bytes which are possible, while the Huffman method consists of encoding
the bytes encountered in a source file with variable binary lengths such that the most
frequent data are encoded on a very short binary length, rare bytes being represented
by a binary length which is greater than the average. The few bits lost on the rare
bytes are quickly recovered for the more frequent bytes (“a” is 346 times more
frequent than “w”). As the number of bits encoded is now variable, it is necessary to
establish a criterion that allows us to distinguish between successive encoded
elements. The encoded file will finally comprise the used source code file and the
encoded message. Its establishment requires the implementation of a suitable
algorithm; data reading, in other words the reconstruction of the initial file, is
performed by means of a decoding algorithm (decompression).
The Huffman method is applicable to all kinds of file (text, image, music, etc.)
since it can establish a table of byte frequencies when the file is read. Despite its age
(it dates from 1952), this method remains competitive, as research has improved its
capacity to compress data.
All of the above methods of data compression are no-loss methods, as it is
possible to completely reconstruct the initial file. They do not use any underlying
“physical” property of the file structure, the algorithms detecting the structure of
repetitions in a purely logical manner. A suitable data compression code leads to a
reduction of the file volume. Its efficiency is related to the degree of repetition of
the file entities (bits, bytes, structures, etc.).
7.3.7.3.
Analytical methods
Let us note first of all that the representation of a signal by an analytical formula
can be considered as signal encoding, its decoding being performed by numerical
calculation with formulae used for analytical representation. However, in most
388 Fundamentals of Fluid Mechanics and Transport Phenomena
situations, the signal is constituted by a sequence of numerical values that cannot be
represented by an analytical formula.
Any kind of understanding of the physical structure of the phenomena
represented can allow the identification of numerical particularities.
Transformations, which are adapted to the physical processes encountered, will
reduce the amount of data significant for that phenomenon: for example, the Fourier
transform of a harmonic function only gives non-zero values for the amplitude and
phase for one frequency. The broadening due to the finite length of the observation
window will increase the number of values in the vicinity of the signal frequency. In
these conditions it suffices to retain the data with sufficiently high values, by
adopting the convention that frequencies which are not retained have zero
amplitude. This manner of writing the results of the Fourier transform constitutes
data compression.
MP3 (Mpeg Audio Layer 3) encoding for sound files is based on a
psychoacoustic model and uses 10 to 12 times less data than a standard sound file.
Recall that one second of stereo sound on a CD comprises 2*44,200 values (the
sensitivity of the ear is 0-20 kHz, the sampling frequency which must be respected
(Shannon) is greater than 40 kHz). This encoding is a little destructive, but this loss
is nearly imperceptible to the human ear:
– we eliminate the sounds of a sequence which will not be perceived by the ear,
the frequencies being close to those of the dominant sound whose energy is much
greater (“masking effect”);
– we also eliminate, by means of Fletscher and Munsen curves which determine
the perceptual limits of the ear, all those sounds for which the level and frequencies
are weaker than the values of these curves: thus for an average level, the sensitivity
of the ear is maximum between 1,000 and 5,000 Hz; it decays strongly below 300-
400 Hz, and it also decays from 8,000 Hz. Sounds outside a certain range are thus
eliminated;
– in the case of stereo recording, we compress the data in mono in the low
frequencies, the difference in phase of the low frequency sound between the two
ears being so small as to be imperceptible to the listener.
– finally we use Huffman compression, without loss, which associates an
encoding which is shorter in proportion to the frequency of data sequences. The
single use of this method provides 20-25% of the compression.
the source signal is also decomposed into sub-bands during the Fourier
transform. The psychoacoustic model is used in these sub-bands which are
quantified by thresholds. The assembly of the sub-bands is then realized.
Measurement, Representation and Analysis of Temporal Signals 389
Data compression is thus based on quite general properties [SAY 00]) either due
to purely arithmetic statements, or to some general structural property, such as the
oscillatory phenomena for music, speech data, or the specific occurrence of letters in
a text. Obviously, a Fourier transformation will not have any value for compression
of text file data.
7.4. Choice of representation and obtaining pertinent information
7.4.1. Introduction
Knowledge is structured by successive levels of systems which are more or less
interlinked, and to each of which there corresponds a category of properties, and
whose properties are attributed at each level in order that they can be synthesized at
the next level. Epistemologically speaking, these are elaborated by means of a
“system-analysis” methodology, which is discussed in Chapter 8. It begins with
formal logic and extends as far as the science of living systems. The idea of
pertinent information is thus difficult to define in an absolute sense, as it depends on
the context and the objective of the analysis performed. We will position ourselves
here at the level of the physics of systems of continuous media in flows, acoustic
and transfer phenomena included.
The representation of physical phenomena, arising from simulation or
experimentation, now consists of tables of numerical values that contain all the
corresponding information. Let us assume for example that we have a recording of
the instantaneous velocity modulus of a turbulent flow at 20 points and with 400
measurements per second for 1 minute. We obtain an ensemble of numerical values
containing 40 x 20 x 60 = 48,000 values. The reading of these values is of little
interest to the human mind. At most, we might note that the velocity varies over
certain intervals, and that these values seem to be associated here or there as broad
groups. The graphical representation of the velocity values as a function of time
provides curves whose reading may provide some further indications to the trained
eye, but the information content thus recognized will appear rather small. For at
least a century, we have observed turbulent fluctuations, and despite this, the
science of turbulence remains incomplete.
The choice of representation obviously depends on the objective that is in view.
The detailed reproduction of a signal can be realized from a numerical recording,
eventually using a lossless compression of the data. We will tolerate some small
losses for the approximate reproduction (MP3 procedures for music, JPEG for
images, etc.). We may eventually choose a variable step size in the discretization so
as to suitably represent the rapid variations of phenomena in different zones (in
certain compression procedures, or in finite element calculation).
390 Fundamentals of Fluid Mechanics and Transport Phenomena
A signal may similarly be studied with a view of its analysis in order to
recognize certain global properties that are represented by synthetic information. An
integral transform does not generally lead to an economy in the numerical
representation of the initial signal; this is only possible by means of specific
transforms which allow an adapted representation which simplifies the presentation
of information (Fourier transforms, etc.). An integral transform is only of interest in
cases where the physical properties of the signal are analogous to its kernel (section
7.3.4). An adapted representation of a signal thus results from a knowledge of its
properties and, as this is often achieved thanks to a suitable form of representation,
we find ourselves confronted by certain difficulties. Hence, we have to find the
answer to a question which is always phrased in a manner corresponding to our
known concepts. If the answer needs other concepts unknown to us, it will be very
difficult to find in what direction the solution is: the human mind is progressing
from a known place to a nearly known place. In other words, we should never forget
that we will only find what we set out to find, and we only ever seek with ideas
which we know! Could Galileo imagine or ever understand the laws of mechanics in
the 17th century without the knowledge of the derivative?
We will study signal-analysis problems and information processing in the case
of audible sound signals, which are less complex than turbulence, at least in
appearance.
7.4.2. An example: analysis of sound
7.4.2.1.
Introduction
Sound amounts to pressure fluctuations that propagate in a fluid medium. Their
origin may be due to internal fluid mechanisms (aerodynamic sound for example),
or to the vibration of solid surfaces which are in contact with the fluid, or to the
interaction of fluid with solid surfaces. The structure of a sound field depends both
on the production mechanism and the conditions of propagation. Sound signals are
complex and very often contain important information whose scientific analysis can
be difficult. We will here limit our discussion to audible sounds whose spectral
content is contained between 20 Hz and 20 kHz.
The complexity of an audible sound signal results from Shannon’s theorem,
which requires at least 40,000 values per second in order for the sound to be
characterized. The reader can calculate the (very large) number of sound sequences
that are possible in one second by assuming that each numerical value is encoded on
8 bits.
Audible sounds have the particularity of sending the human brain a signal with
which a sensation is associated; this is then compared to memories and eventually

Measurement, Representation and Analysis of Temporal Signals 391
interpreted. It is clear that these mechanisms of recognition are the consequence of
training with respect to the usual sounds of our environment, which constitutes only
a very small part of the ensemble of possible sound sequences. It is precisely
because we already have an intuitive understanding of these sounds that we will
take them as an example for discussing signal analysis and synthesis methodologies.
The interpretation of audible sounds by the brain concerns the domain of
psychoacoustics. We will not discuss the structure of the human hearing system. For
questions associated with acoustic signals, it is sufficient to note that the response of
the ear is non-linear, sensations being moreover recorded on a logarithmic scale.
Now any action of a linear filter on a linear combination of harmonic signals leads
to another linear combination of harmonic signals of the same frequencies. On the
other hand, any non-linear operation on a linear combination of harmonic signals
of discrete frequencies will create new frequency components (harmonics and sub-
harmonics); for example, consider the signal s(t) which is the sum of harmonic
signals of frequencies 2n and 3n ( n
S
Z
2 ):
ttats
Z
Z
3cos2cos)(
Its square s
2
can be written:
»
¼
º
«
¬
ª
ttttats
ZZZZ
5cos6cos4cos
2
1
cos1
22
The signal thus obtained does not contain the initial frequencies 2n and 3n which
are replaced by the harmonics 4n, 5n, 6n, and the sub-harmonics of the frequency n.
However, the spectral composition in relative value is here independent of the
amplitude a. In general this is not the case, and the global amplitude variation of a
sound signal modifies the spectral content as soon as the non-linear operation is not
simple. The reader can easily verify that the spectral composition of the signal
ss
D
2
depends on the constant value
D
.
This leads to the human ear hearing frequencies that do not have any physical
existence: this is the question of the “missing fundamental”, the ear hearing the
previous sub-harmonics ([BER 90], [KIN 82]). Navier-Stokes equations being non-
linear, turbulence evolution is a strongly non-linear dynamic process in which
frequencies associated with turbulent fluctuations are increasing (turbulent energy
cascade [MAT 00]).
7.4.2.2.
Hearing and time-frequency analysis
As the ear has a spectral response that is rather logarithmic for sound levels, it is
not a good instrument for evaluating the spectral content of a sound. The spectral
392 Fundamentals of Fluid Mechanics and Transport Phenomena
content of sounds perceived by the human ear does not vary significantly if we
modify the sound level; this can be easily verified by listening to music on a high-
quality system (except at very low sound level). However, the elementary
calculations of the last section show how the ear can hear sounds whose frequencies
do not exist in the sound spectrum. This phenomenon has been known for a long
time in music, where suitable harmonic combinations can lead to the belief in the
presence of a fundamental frequency that does not exist. The interested reader can
see texts treating psychoacoustics and musical acoustics. Fourier analysis of sound
differs from the perception that the ear can have of sound; in what follows we will
leave aside the problem of sound sensation, and we will limit our results to the
physical analysis performed using time-frequency techniques.
7.4.2.3.
“Natural” sounds
We will designate by the term “natural” sounds all those sounds that are
generated mechanically in our environment. These are produced by vibration of
solid bodies (plates, shells, membranes, etc.), by oscillations in fluid velocity
(musical wind instruments, speech, the wind, etc.) or by interactions between solids
and fluids (wavemakers, vibrating walls under the influence of a flow, etc.). These
sounds result from the properties of the movement of fluids and solids. There is
incidentally no physical difference between musical sounds (which are in principle
agreeable to the ear) and industrial sounds that are often a nuisance. The two
categories of sound are produced by means of impacts (percussion instruments, a
hammer, etc.) friction (violin, squeaking of brakes, etc.), by airflows (flute, pipes
which blow, speech, etc.). These properties of natural or forced vibration are quite
well known in many relatively un-complicated instances.
“Natural” sounds are thus particular categories of sound signals whose
function or utility is quite varied:
– familiar sounds are part of the environment and the context of normal life; any
modification of these is immediately perceived as new information; the absence of
any sound can quickly become oppressive, as we can experience by spending time
in an anechoic chamber;
– suitable musical sounds have a relaxing and agreeable effect, which may vary
depending on the individual;
– sounds emitted by a sound source allow the identification of the position and
nature (at least partially) of its source; an anomaly in the content of a sound can
serve to identify an anomaly in the functioning of the source (for example, listening
to the sound of the engine of a car or of an industrial process): we have here a
diagnostic function which is beginning to be used in certain software of preventive
maintenance ([BOU 98], [WAN 06]);