Mavko G., Mukerji T., Dvorkin J. The Rock Physics Handbook
Подождите немного. Документ загружается.


missing. Drawing with replacement from the data is equivalent to Monte Carlo
realizations from the empirical CDF. The statistic of interest is computed on all of
the replicate bootstrap data sets. The distribution of the bootstrap replicates of the
statistic is a measure of uncertainty of the statistic.
Drawing bootstrap replicates from the empirical CDF in this way is sometimes
termed nonparametric bootstrap.Inparametric bootstrap the data are first mod-
eled by a parametric CDF (e.g., a multivariate Gaussian), and then bootstrap data
replicates are drawn from the modeled CDF. Both simple bootstrap techniques
described above assume the data are independent and identically distributed. More
sophisticated bootstrap techniques exist that can account for data dependence.
Statistical classification
The goal in statistical classification problems is to predict the class of an unknown
sample based on observed attributes or features of the sample. For example, the
observed attributes could be P and S impedances, and the classes could be lithofacies,
such as sand and shale. The classes are sometimes also called states, outcomes, or
responses, while the observed features are called the predictors. Discussions concerning
many modern classification methods may be found in Fukunaga (1990), Duda et al.
(2000), Hastie et al. (2001), and Bishop (2006).
There are two general types of statistical classification: supervised classification,
which uses a training data set of samples for which both the attributes and classes
have been observed; and unsupervised learning, for which only the observed
attributes are included in the data. Supervised classification uses the training data
to devise a classification rule, which is then used to predict the classes for new data,
where the attributes are observed but the outcomes are unknown. Unsupervised
learning tries to cluster the data into groups that are statistically different from each
other based on the observed attributes.
A fundamental approach to the supervised classification problem is provided by
Bayesian decision theory. Let x denote the univariate or multivariate input attributes,
and let c
j
, j ¼1,..., N denote the N different states or classes. The Bayes formula
expresses the probability of a particular class given an observed x as
Pðc
j
jxÞ¼
Pðx; c
j
Þ
PðxÞ
¼
Pðx jc
j
ÞPðc
j
Þ
PðxÞ
where P(x, c
j
) denotes the joint probability of x and c
j
; P(x jc
j
) denotes the conditional
probability of x given c
j
; and P(c
j
) is the prior probability of a particular class. Finally,
P(x) is the marginal or unconditional pdf of the attribute values across all N states.
It can be written as
PðXÞ¼
X
N
j¼1
PðX jc
j
ÞPðc
j
Þ
17 1.3 Statistics and probability

and serves as a normalization constant. The class-conditional pdf, P(x jc
j
), is estimated
from the training data or from a combination of training data and forward models.
The Bayes classification rule says:
classify as class c
k
if Pðc
k
jxÞ > Pðc
j
jxÞ for all j 6¼ k:
This is equivalent to choosing c
k
when P(x jc
k
)P(c
k
) > P(x jc
j
)P(c
j
) for all j 6¼ k.
The Bayes classification rule is the optimal one that minimizes the misclassifica-
tion error and maximizes the posterior probability. Bayes classification requires
estimating the complete set of class-conditional pdfs P(x jc
j
). With a large number
of attributes, getting a good estimate of the highly multivariate pdf becomes difficult.
Classification based on traditional discriminant analysis uses only the means and
covariances of the training data, which are easier to estimate than the complete pdfs.
When the input features follow a multivariate Gaussian distribution, discriminant
classification is equivalent to Bayes classification, but with other data distribution
patterns, the discriminant classification is not guaranteed to maximize the posterior
probability. Discriminant analysis classifies new samples according to the minimum
Mahalanobis distance to each class cluster in the training data. The Mahalanobis
distance is defined as follows:
M
2
¼ x m
j
T
1
x m
j
where x is the sample feature vector (measured attribute), m
j
are the vectors of the
attribute means for the different categories or classes, and S is the training data
covariance matrix. The Mahalanobis distance can be interpreted as the usual Euclidean
distance scaled by the covariance, which decorrelates and normalizes the components
of the feature vector. When the covariance matrices for all the classes are taken to be
identical, the classification gives rise to linear discriminant surfaces in the feature
space. More generally, with different covariance matrices for each category, the
discriminant surfaces are quadratic. If the classes have unequal prior probabilities, the
term ln[P(class)
j
] is added to the right-hand side of the equation for the Mahalanobis
distance, where P(class)
j
is the prior probability for the jth class. Linear and quadratic
discriminant classifiers are simple, robust classifiers and often produce good results,
performing among the top few classifier algorithms.
1.4 Coordinate transformations
Synopsis
It is often necessary to transform vector and tensor quantities in one coordinate
system to another more suited to a particular problem. Consider two right-hand
rectangular Cartesian coordinates (x, y, z) and (x
0
,y
0
,z
0
) with the same origin, but
18 Basic tools

with their axes rotated arbitrarily with respect to each other. The relative orientation
of the two sets of axes is given by the direction cosines b
ij
, where each element is
defined as the cosine of the angle between the new i
0
-axis and the original j-axis. The
variables b
ij
constitute the elements of a 3 3 rotation matrix [b]. Thus, b
23
is the
cosine of the angle between the 2-axis of the primed coordinate system and the 3-axis
of the unprimed coordinate system.
The general transformation law for tensors is
M
0
ABCD...
¼ b
Aa
b
Bb
b
Cc
b
Dd
...M
abcd...
where summation over repeated indices is implied. The left-hand subscripts (A, B,
C, D,...)on thebs match the subscripts of the transformed tensor M
0
on the left, and
the right-hand subscripts (a, b, c, d,...)match the subscripts of M on the right. Thus
vectors, which are first-rank tensors, transform as
u
0
i
¼ b
ij
u
j
or, in matrix notation, as
u
0
1
u
0
2
u
0
3
0
B
B
@
1
C
C
A
¼
b
11
b
12
b
13
b
21
b
22
b
23
b
31
b
32
b
33
0
B
B
@
1
C
C
A
u
1
u
2
u
3
0
B
B
@
1
C
C
A
whereas second-rank tensors, such as stresses and strains, obey
0
ij
¼ b
ik
b
jl
kl
or
½
0
¼½b½½b
T
in matrix notation. Elastic stiffnesses and compliances are, in general, fourth-order
tensors and hence transform according to
c
0
ijkl
¼ b
ip
b
jq
b
kr
b
ls
c
pqrs
Often c
ijkl
and s
ijkl
are expressed as the 6 6 matrices C
ij
and S
ij
, using the
abbreviated 2-index notation, as defined in Section 2.2 on anisotropic elasticity. In this
case, the usual tensor transformation law is no longer valid, and the change of coordin-
ates is more efficiently performed with the 6 6 Bond transformation matrices
M and N, as explained below (Auld, 1990):
½C
0
¼½M½C½M
T
½S
0
¼½N½S½N
T
19 1.4 Coordinate transformations

The elements of the 6 6 M and N matrices are given in terms of the direction
cosines as follows:
M ¼
b
2
11
b
2
12
b
2
13
2b
12
b
13
2b
13
b
11
2b
11
b
12
b
2
21
b
2
22
b
2
23
2b
22
b
23
2b
23
b
21
2b
21
b
22
b
2
31
b
2
32
b
2
33
2b
32
b
33
2b
33
b
31
2b
31
b
32
b
21
b
31
b
22
b
32
b
23
b
33
b
22
b
33
þ b
23
b
32
b
21
b
33
þ b
23
b
31
b
22
b
31
þ b
21
b
32
b
31
b
11
b
32
b
12
b
33
b
13
b
12
b
33
þ b
13
b
32
b
11
b
33
þ b
13
b
31
b
11
b
32
þ b
12
b
31
b
11
b
21
b
12
b
22
b
13
b
23
b
22
b
13
þ b
12
b
23
b
11
b
23
þ b
13
b
21
b
22
b
11
þ b
12
b
21
2
6
6
6
6
6
6
6
6
6
6
6
4
3
7
7
7
7
7
7
7
7
7
7
7
5
and
N ¼
b
2
11
b
2
12
b
2
13
b
12
b
13
b
13
b
11
b
11
b
12
b
2
21
b
2
22
b
2
23
b
22
b
23
b
23
b
21
b
21
b
22
b
2
31
b
2
32
b
2
33
b
32
b
33
b
33
b
31
b
31
b
32
2b
21
b
31
2b
22
b
32
2b
23
b
33
b
22
b
33
þ b
23
b
32
b
21
b
33
þ b
23
b
31
b
22
b
31
þ b
21
b
32
2b
31
b
11
2b
32
b
12
2b
33
b
13
b
12
b
33
þ b
13
b
32
b
11
b
33
þ b
13
b
31
b
11
b
32
þ b
12
b
31
2b
11
b
21
2b
12
b
22
2b
13
b
23
b
22
b
13
þ b
12
b
23
b
11
b
23
þ b
13
b
21
b
22
b
11
þ b
12
b
21
2
6
6
6
6
6
6
6
6
6
6
6
4
3
7
7
7
7
7
7
7
7
7
7
7
5
The advantage of the Bond method for transforming stiffnesses and compliances is
that it can be applied directly to the elastic constants given in 2-index notation, as
they almost always are in handbooks and tables.
Assumptions and limitations
Coordinate transformations presuppose right-handed rectangular coordinate systems.
20 Basic tools
2
Elasticity and Hooke’s law
2.1 Elastic moduli: isotropic form of Hooke’s law
Synopsis
In an isotropic, linear elastic material, the stress and strain are related by Hooke’s law
as follows (e.g., Timoshenko and Goodier, 1934):
ij
¼ ld
ij
e
aa
þ 2me
ij
or
e
ij
¼
1
E
½ð1 þ nÞ
ij
nd
ij
aa
where
e
ij
¼ elements of the strain tensor
ij
¼ elements of the stress tensor
e
aa
¼ volumetric strain (sum over repeated index)
aa
¼ mean stress times 3 (sum over repeated index)
d
ij
¼ 0ifi 6¼ j and d
ij
¼ 1ifi ¼ j
In an isotropic, linear elastic medium, only two constants are needed to specify the
stress–strain relation completely (for example, [l, m] in the first equation or [E, v],
which can be derived from [l, m], in the second equation). Other useful and conveni-
ent moduli can be defined, but they are always relatable to just two constants. The
three moduli that follow are examples.
The Bulk modulus, K, is defined as the ratio of the hydrostatic stress, s
0
, to the
volumetric strain:
0
¼
1
3
aa
¼ Ke
aa
The bulk modulus is the reciprocal of the compressibility, b, which is widely used to
describe the volumetric compliance of a liquid, solid, or gas:
b ¼
1
K
21

Caution
Occasionally in the literature authors have used the term incompressibility as an
alternate name for Lame
´
’s constant, l, even though l is not the reciprocal of the
compressibility.
The shear modulus, m, is defined as the ratio of the shear stress to the shear strain:
ij
¼ 2me
ij
; i 6¼ j
Young’s modulus, E, is defined as the ratio of the extensional stress to the exten-
sional strain in a uniaxial stress state:
zz
¼ Ee
zz
;
xx
¼
yy
¼
xy
¼
xz
¼
yz
¼ 0
Poisson’s ratio, which is defined as minus the ratio of the lateral strain to the axial
strain in a uniaxial stress state:
v ¼
e
xx
e
zz
;
xx
¼
yy
¼
xy
¼
xz
¼
yz
¼ 0
P-wave modulus, M ¼ V
2
P
, defined as the ratio of the axial stress to the axial strain
in a uniaxial strain state:
zz
¼ Me
zz
; e
xx
¼ e
yy
¼ e
xy
¼ e
xz
¼ e
yz
¼ 0
Note that the moduli (l, m, K, E, M) all have the same units as stress (force/area),
whereas Poisson’s ratio is dimensionless.
Energy considerations require that the following relations always hold. If they do
not, one should suspect experimental errors or that the material is not isotropic:
K ¼ l þ
2m
3
0; m 0
or
1 < n
1
2
; E 0
In rocks, we seldom, if ever, observe a Poisson’s ratio of less than 0. Although
permitted by this equation, a negative measured value is usually treated with suspi-
cion. A Poisson’s ratio of 0.5 can mean an infinitely incompressible rock (not
possible) or a liquid. A suspension of particles in fluid, or extremely soft, water-
saturated sediments under essentially zero effective stress, such as pelagic ooze, can
have a Poisson’s ratio approaching 0.5.
Although any one of the isotropic constants (l, m, K, M, E, and n) can be derived in
terms of the others, m and K have a special significance as eigenelastic constants
(Mehrabadi and Cowin, 1989)orprincipal elasticities of the material (Kelvin, 1856).
The stress and strain eigentensors associated with m and K are orthogonal, as discussed
in Section 2.2. Such an orthogonal significance does not hold for the pair l and m.
22 Elasticity and Hooke’s law
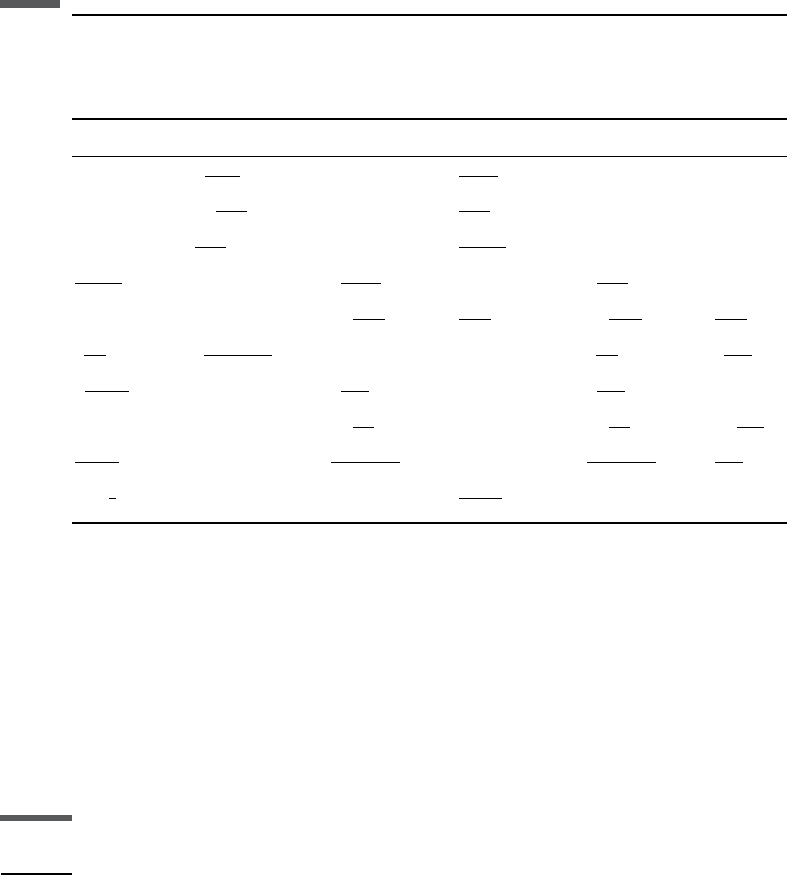
Table 2.1.1 summarizes useful relations among the constants of linear isotropic
elastic media.
Assumptions and limitations
The preceding equations assume isotropic, linear elastic media.
2.2 Anisotropic form of Hooke’s law
Synopsis
Hooke’s law for a general anisotropic, linear, elastic solid states that the stress s
ij
is
linearly proportional to the strain e
ij
, as expressed by
ij
¼ c
ijkl
e
kl
in which summation (over 1, 2, 3) is implied over the repeated subscripts k and l. The
elastic stiffness tensor, with elements c
ijkl
, is a fourth-rank tensor obeying the laws of
tensor transformation and has a total of 81 components. However, not all 81 com-
ponents are independent. The symmetry of stresses and strains implies that
c
ijkl
¼ c
jikl
¼ c
ijlk
¼ c
jilk
Table 2.1.1 Relationships among elastic constants in an isotropic material
(after Birch, 1961).
KE l vMm
l þ 2m/3 m
3lþ2m
lþm
—
l
2ðlþmÞ
l þ 2m —
—9K
Kl
3Kl
—
l
3Kl
3K–2l 3(K – l)/2
—
9Km
3Kþm
K–2m/3
3K2m
2ð3KþmÞ
K þ 4m/3 —
Em
3ð3mEÞ
— m
E2m
ð3mEÞ
E/(2m)–1 m
4mE
3mE
—
—— 3K
3KE
9KE
3KE
6K
3K
3KþE
9KE
3KE
9KE
l
1þn
3n
l
ð1þnÞð12nÞ
n
——l
1n
n
l
12n
2n
m
2ð1þnÞ
3ð12nÞ
2m(1 þ v) m
2n
12n
— m
22n
12n
—
—3K(1 – 2v)3K
n
1þn
—3K
1n
1þn
3K
12n
2þ2n
E
3ð12nÞ
—
En
ð1þnÞð12nÞ
—
Eð1nÞ
ð1þnÞð12nÞ
E
2þ2n
M
4
3
m — M 2m
M2m
2ðMmÞ
——
23 2.2 Anisotropic form of Hooke’s law

reducing the number of independent constants to 36. In addition, the existence of a
unique strain energy potential requires that
c
ijkl
¼ c
klij
further reducing the number of independent constants to 21. This is the maximum
number of independent elastic constants that any homogeneous linear elastic medium
can have. Additional restrictions imposed by symmetry considerations reduce the
number much further. Isotropic, linear elastic materials, which have maximum
symmetry, are completely characterized by two independent constants, whereas
materials with triclinic symmetry (the minimum symmetry) require all 21 constants.
Alternatively, the strains may be expressed as a linear combination of the stresses
by the following expression:
e
ij
¼ s
ijkl
kl
In this case s
ijkl
are elements of the elastic compliance tensor which has the same
symmetry as the corresponding stiffness tensor. The compliance and stiffness are
tensor inverses, denoted by
c
ijkl
s
klmn
¼ I
ijmn
¼
1
2
ðd
im
d
jn
þ d
in
d
jm
Þ
The stiffness and compliance tensors must always be positive definite. One way to
express this requirement is that all of the eigenvalues of the elasticity tensor
(described below) must be positive.
Voigt notation
It is a standard practice in elasticity to use an abbreviated Voigt notation for the
stresses, strains, and stiffness and compliance tensors, for doing so simplifies some of
the key equations (Auld, 1990). In this abbreviated notation, the stresses and strains
are written as six-element column vectors rather than as nine-element square
matrices:
T ¼
1
¼
11
2
¼
22
3
¼
33
4
¼
23
5
¼
13
6
¼
12
2
6
6
6
6
6
6
4
3
7
7
7
7
7
7
5
E ¼
e
1
¼ e
11
e
2
¼ e
22
e
3
¼ e
33
e
4
¼ 2e
23
e
5
¼ 2e
13
e
6
¼ 2e
12
2
6
6
6
6
6
6
4
3
7
7
7
7
7
7
5
Note the factor of 2 in the definitions of strains, but not in the definition of stresses.
With the Voigt notation, four subscripts of the stiffness and compliance tensors are
reduced to two. Each pair of indices ij(kl) is replaced by one index I(J) using the
following convention:
24 Elasticity and Hooke’s law

ijðklÞ IðJÞ
11 1
22 2
33 3
23; 32 4
13; 31 5
12; 21 6
The relation, therefore, is c
IJ
¼ c
ijkl
and s
IJ
¼ s
ijkl
N, where
N ¼
1 for I and J ¼ 1; 2; 3
2 for I or J ¼ 4; 5; 6
4 for I and J ¼ 4; 5; 6
8
>
<
>
:
Note how the definition of s
IJ
differs from that of c
IJ
. This results from the factors
of 2 introduced in the definition of strains in the abbreviated notation. Hence the
Voigt matrix representation of the elastic stiffness is
c
11
c
12
c
13
c
14
c
15
c
16
c
12
c
22
c
23
c
24
c
25
c
26
c
13
c
23
c
33
c
34
c
35
c
36
c
14
c
24
c
34
c
44
c
45
c
46
c
15
c
25
c
35
c
45
c
55
c
56
c
16
c
26
c
36
c
46
c
56
c
66
0
B
B
B
B
B
B
@
1
C
C
C
C
C
C
A
and similarly, the Voigt matrix representation of the elastic compliance is
s
11
s
12
s
13
s
14
s
15
s
16
s
12
s
22
s
23
s
24
s
25
s
26
s
13
s
23
s
33
s
34
s
35
s
36
s
14
s
24
s
34
s
44
s
45
s
46
s
15
s
25
s
35
s
45
s
55
s
56
s
16
s
26
s
36
s
46
s
56
s
66
0
B
B
B
B
B
B
@
1
C
C
C
C
C
C
A
The Voigt stiffness and compliance matrices are symmetric. The upper triangle
contains 21 constants, enough to contain the maximum number of independent
constants that would be required for the least symmetric linear elastic material.
Using the Voigt notation, we can write Hooke’s law as
1
2
3
4
5
6
0
B
B
B
B
B
B
@
1
C
C
C
C
C
C
A
¼
c
11
c
12
c
13
c
14
c
15
c
16
c
12
c
22
c
23
c
24
c
25
c
26
c
13
c
23
c
33
c
34
c
35
c
36
c
14
c
24
c
34
c
44
c
45
c
46
c
15
c
25
c
35
c
45
c
55
c
56
c
16
c
26
c
36
c
46
c
56
c
66
0
B
B
B
B
B
B
@
1
C
C
C
C
C
C
A
e
1
e
2
e
3
e
4
e
5
e
6
0
B
B
B
B
B
B
@
1
C
C
C
C
C
C
A
25 2.2 Anisotropic form of Hooke’s law

It is very important to note that the stress (strain) vector and stiffness (compliance)
matrix in Voigt notation are not tensors.
Caution
Some forms of the abbreviated notation adopt different definitions of strains, mov-
ing the factors of 2 and 4 from the compliances to the stiffnesses. However,
the form given above is the more common convention. In the two-index notation,
c
IJ
and s
IJ
can conveniently be represented as 6 6 matrices. However, these
matrices no longer follow the laws of tensor transformation. Care must be taken
when transforming from one coordinate system to another. One way is to go back
to the four-index notation and then use the ordinary laws of coordinate transform-
ation. A more efficient method is to use the Bond transformation matrices,
which are explained in Section 1.4 on coordinate transformations.
Voigt stiffness matrix structure for common anisotropy classes
The nonzero components of the more symmetric anisotropy classes commonly used
in modeling rock properties are given below in Voigt notation.
Isotropic: two independent constants
The structure of the Voigt elastic stiffness matrix for an isotropic linear elastic
material has the following form:
c
11
c
12
c
12
000
c
12
c
11
c
12
000
c
12
c
12
c
11
000
000c
44
00
0000c
44
0
00000c
44
2
6
6
6
6
6
6
4
3
7
7
7
7
7
7
5
; c
12
¼ c
11
2c
44
The relations between the elements c and Lame
´
’s parameters l and m of isotropic
linear elasticity are
c
11
¼ l þ 2m; c
12
¼ l; c
44
¼ m
The corresponding nonzero isotropic compliance tensor elements can be written in
terms of the stiffnesses:
s
11
¼
c
11
þ c
12
c
11
c
12
ðÞc
11
þ 2c
12
ðÞ
; s
44
¼
1
c
44
Energy considerations require that for an isotropic linear elastic material the
following conditions must hold:
K ¼ c
11
4
3
c
44
> 0; m ¼ c
44
> 0
26 Elasticity and Hooke’s law