Кузюрин Н.Н. Фомин С.А. Сложность комбинаторных алгоритмов. Курс лекций
Подождите немного. Документ загружается.


Подставляя (1.7) в (1.4) проверяем, что T (N) = CN log N, для некоторой константы C:
CN log N = O(N) +
2C
N
(
1
2
N
2
log N −
1
8
N
2
)
= CN log N + (O(N) −
C
4
N)
К сожалению, допущенное нами предположение о равномерности распределения «осей» относительно интерва-
лов, может не встречаться на практике. Например, есть вариации детерминированного алгоритма 11 «Quicksort», для
которых «плохими» будут уже отсортированные (или почти отсортированные) последовательности, а таковые часто
встречаются в реальных задачах. В таких случаях, когда нельзя «сделать случайными» входные данные, можно вне-
сти «элемент случайности» непосредственно в сам алгоритм. В частности, чтобы сохранилась оценка матожидания
(1.6), достаточно сделать вероятностным выбор осевого элемента из разделяемого интервала. Алгоритм 12 «Quicksort-
random» отличается от алгоритма 11 «Quicksort», только строчкой, где задается выбор вероятностный выбор осевого
элемента, однако, как мы увидели, это дает ему возможность «избегать потерь» на входных данных, которые были
«наихудшими» для детерминированного алгоритма, и достигнуть оценки матожидания времени работы (1.6), вне зави-
симости от входных данных.
1.2 Формально об алгоритмах
1.2.1 Машины с произвольным доступом (RAM)
В предыдущих лекциях мы довольствовались качественным, интуитивным понятием «эффективного» алгоритма. Для
построения же математической теории сложности алгоритмов, разумеется, необходимо строгое количественное опре-
деление меры эффективности.
Опыт, накопленный в теории сложности вычислений, свидетельствует, что наиболее удобным и адекватным спосо-
бом сравнения эффективности разнородных алгоритмов является понятие асимптотической сложности, рассмот-
рению которого и посвящен настоящий параграф.
Первое, о чем следует договориться — это выбор вычислительной модели, в которой конструируются наши ал-
горитмы. Оказывается, что как раз этот вопрос не имеет слишком принципиального значения для теории сложности
вычислений, и тот уровень строгости, на котором мы работали в предыдущем параграфе (число выполнений операто-
ров на языке Python) оказывается почти приемлемым. Главная причина такого легкомысленного отношения к выбору
модели состоит в том, что существуют весьма эффективные способы моделирования (или трансляции программ в
более привычных терминах) одних естественных вычислительных моделей с помощью других. При этих моделирова-
ниях сохраняется класс эффективных алгоритмов и, более того, как правило, алгоритмы «более эффективные» в одних
моделях оказываются более эффективными и в других.
Сначала рассмотрим модель, наиболее напоминающую современный компьютер, программируемый непосредствен-
но в терминах инструкций процессора (или на языке Assembler): random access machines, RAM
11
, т.е. «машины со
случайным доступом».
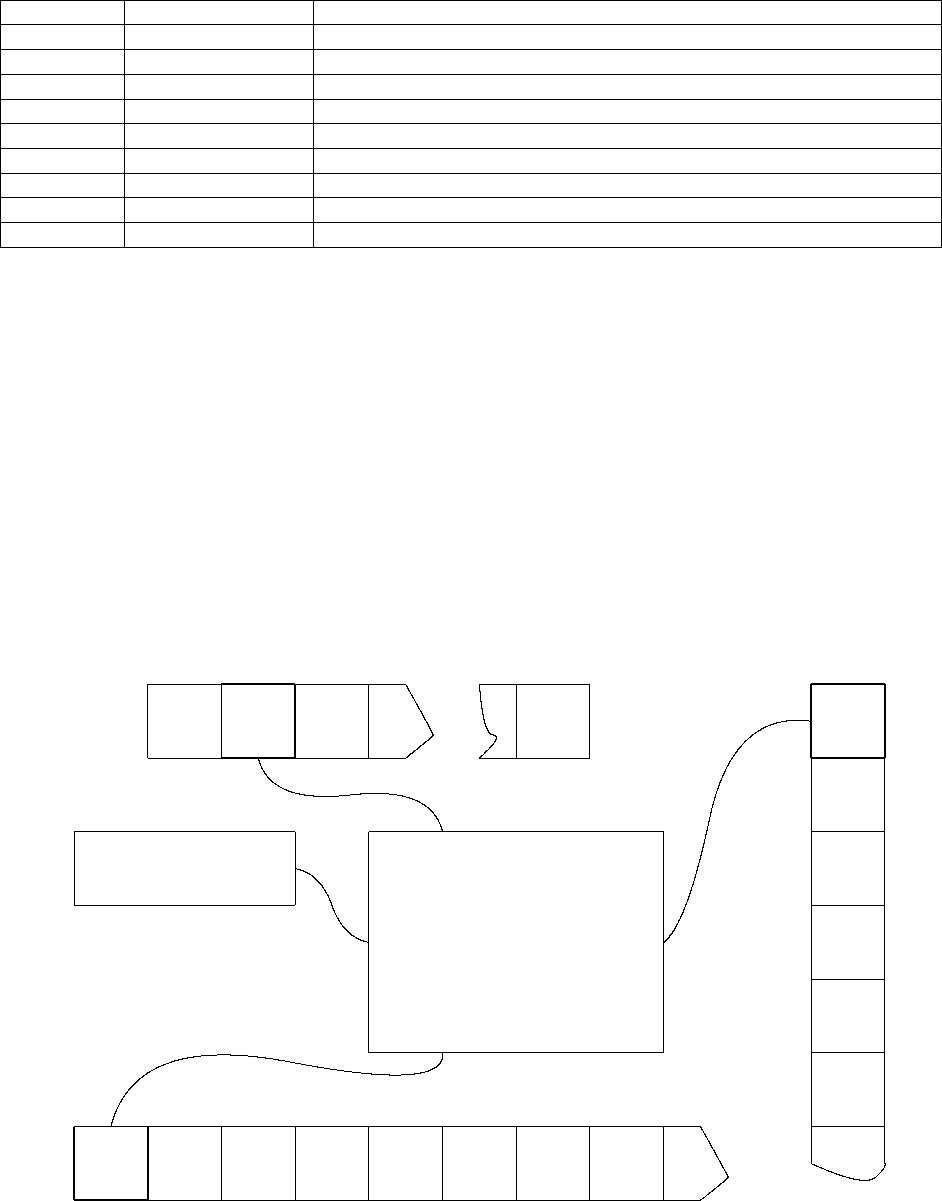
RAM-машина состоит из (См. Рис. 1.2.1):
• Конечная входная read-only лента, куда записываются входные данные.
• Полубесконечная выходная write-only лента, куда записываются результат работы машины.
• Бесконечное число регистров r
0
, r
1
, r
2
, . . . ,, каждый из которых может хранить целое число, причем регистр r
0
является выделенным, и называется «сумматором» — этот регистр используется при арифметических операциях
как накопитель, т.е. как второй операнд и место хранения результата.
• Программа, состоящая из конечного числа инструкций, каждая из которых содержит адрес и команду с операн-
дом. Список команд приведен в Таблице 1.2. Важный, характеристический момент — в качестве операнда можно
использовать как произвольный регистр, так и регистр, номер которого хранится в другом регистре — так назы-
ваемая косвенная адресация.
• Регистр-счетчик «PC», указывающий на текущую команду.
На самом деле, легко видеть, что практически все высокоуровневые конструкции языков программирования, типа
циклов, легко моделируются на ассемблере RAM — машин:
11
в теории сложности вычислений под машинами традиционно понимают single-purpose machines, т.е. машины, созданные для решения какой-
либо одной фиксированной задачи. В привычных терминах это скорее программы.
21

Алгоритм 12 Быстрая сортировка с вероятностным выбором оси
def quicksort (A):
def swap (i, j): # Перестановка i-го и j-го элементов массива A
← A[i]; A[i] ← A[j]; A[j] ←
Перестановка элементов в интервале [left:right) массива А, таким образом, что, возникают три интервала: в первой
части массива все элементы < осевого значения pivotValue а во второй = осевому значению. а во третьей > осевого
значения.
def partition ( , , ):
print funcname (), A[ : ], ,
← i ← # Нижний и текущий индексы
← − 1 # Верхний индекс
while i ≤ : # Пока есть область не просмотренных элементов.
if A[i] < : # Если элемент меньше оси
swap (i, ) # гоним его в начало интервала
← + 1 # сужаем область слева
i ← i + 1
elif A[i] > : # Если элемент больше оси
swap (i, ) # гоним его в конец интервала
← − 1 # сужаем область справа
else: # A[i]=pivotValue
i ← i + 1 # сужаем область слева
print , A[ : ], A[ : + 1], A[ + 1: ]
return ( , )
def qsort_interval ( , ):
if > + 1: # Если в интервале [left:right) хотя бы два элемента
print funcname (), A[ : ]
( , ) ← partition ( , , A[ .randrange ( , )])
qsort_interval ( , )
qsort_interval ( + 1, )
← .Random (6666) # Инициализируем генератор случайных чисел.
qsort_interval (0, len (A))
return A
22
LOAD OP r
0
← OP Загрузить операнд в сумматор
STORE OP r
OP
← r
0
Сохранить сумматор в регистре
ADD OP r
0
← r
0
+ OP Прибавить операнд к сумматору
SUB OP r
0
← r
0
− OP Вычесть операнд из сумматора
READ OP r
OP
← input Загрузить ячейку из входной ленты в r
OP
и перейти к следующей.
WRITE OP OP → output Записать OP в текущую ячейку выходной ленты и сдвиг к следующей.
JUMP OP P C ← OP Установить счетчик команд в OP .
JGTZ OP P C ← OP : r
0
> 0 Установить счетчик команд в OP , если r
0
> 0
JZERO OP P C ← OP : r
0
= 0 Установить счетчик команд в OP , если r
0
= 0
HALT Остановить работу.
Здесь операнд OP может быть:
• целым числом, например 7, −1917;
• значением регистра, например r
12
, r
34
;
• значением регистра, указанного в другом регистре. Например, операнд ∗r
14
означает значение регистра, номер
которого указан в регистре r
14
.
Таблица 1.2: RAM — машина со случайным доступом: Список команд.
x
2
x
3
x
n
Program Counter
x
1
RAM–Program
y
1
y
2
y
3
y
4
y
5
y
6
y
7
y
8
входная read-only лента
выходная write-only лента
z
O
r
0
r
1
r
2
r
3
r
4
r
5
z
0: LOAD r1
1: ADD 3
2: STORE r7
3: LOAD 77
4: STORE ∗r7
5: JUMP 100
. . .
Рис. 1.1: RAM — машина со случайным доступом
23

...
for i in range( 1..78 ):
...
=⇒
...
0777:LOAD 1
0778:STOREr
17
0779:
...
1038:
1039:LOAD r
17
1040:SUB 78
1041:JGTZ 0779
...
(1.8)
Переменные других типов (булевы, строки, структуры) тоже можно моделировать — с помощью целых чисел и
косвенной адресации.
Обратите внимание, что несмотря на «примитивный ассемблер», RAM-машины потенциально мощней любых су-
ществующих компьютеров, и физически нереализуемы — т.к. оперируют бесконечной памятью, доступ к любой ячейке-
регистру которой осуществляется мгновенно при выполнении соответствующей инструкции, и каждая ячейка этой па-
мяти может содержать произвольное целое число (т.е. не ограничена по размеру). Но эта модель уже дает возмож-
ность вводить более-менее формальные определения времени выполнения программы, и соответственно, сложности
алгоритма.
Если мы будем принимать в расчет только число выполненных команд, то таким образом мы определим так назы-
ваемые однородные меры сложности.
Более реалистично было бы учитывать битовый размер операндов при выполнении каждой команды. Например,
можно считать, что время выполнения каждой команды пропорционально сумме логарифмов значений операндов, (т.е.
их суммарной битовой длине), а общее время работы программы на рассматриваемых входных данных как суммарное
время выполнения всех индивидуальных команд. Таким образом мы можем определить различные логарифмические
меры сложности.
Очевидно, логарифмическая сложность всегда больше однородной.
С другой стороны, обратите внимание, что определенная нами RAM-машина не включает в число основных опера-
ций умножение и деление (хотя в литературе такой вариант машин со случайным доступом иногда рассматривается).
Допустим, что однородное время работы некоторой машины со случайным доступом без умножения и деления при
работе на входных данных x
1
, . . . , x
m
, битовая длина каждого из которых не больше n равно t. Так как при выполнении
любого индивидуального оператора максимальная битовая длина может возрасти не более, чем на 1, в ходе выполнения
всей программы встречаются лишь числа битовой длины не более (t + n), и, стало быть, логарифмическая сложность
превышает однородную не более, чем в (t + n) раз. В частности (см. обсуждение в разделе 1.1), с точки зрения эф-
фективности, однородная и логарифмическая сложности равносильны, и выбор одной из них в основном определяется
внутренней спецификой рассматриваемой задачи.
Если же добавить умножение и деление к списку элементарных операций, то это исключит равносильность одно-
родной и логарифмической сложности. Следующий известный способ быстро переполнить память карманного кальку-
лятора (алгоритм 13 «Переполнение памяти умножением»)
Алгоритм 13 Быстрое переполнение памяти в присутствии умножения.
Вход: Натуральное t
R ← 2
for all i ∈ 1..t do
R ← R × R
end for
имеет однородную сложность (t + 1) и логарифмическую порядка экспоненты 2
t
. Как показывает обсуждение в
разделе 1.1, этот алгоритм не может считаться эффективным с точки зрения логарифмической сложности (хотя и по
совершенно другим причинам, нежели переборные алгоритмы), и чтобы избежать неприятных эффектов такого рода
мы не включаем умножение (и тем более деление) в список основных операций. В тех же случаях, когда умножение
используется «в мирных целях», его в большинстве случаев можно промоделировать с помощью сложения следующим
очевидным образом:
Отметим, что единственную серьезную конкуренцию машинам со случайным доступом как основы для построе-
ния теории сложности вычислений на сегодняшний день составляют так называемые машины Тьюринга, которых мы
будем рассматривать в следующем разделе. Их принципиальное отличие состоит в отсутствии непрямой индексации:
после проведения каких-либо действий с некоторой ячейкой процессор («головка») может перейти лишь в одну из
24

Алгоритм 14 Простой способ вычисления произведения R
1
· R
2
на RAM.
Вход: Натуральные R
1
, R
2
Выход: R
1
× R
2
R ← 0
for all i ∈ 1..R
1
do
R ← R + R
2
end for
return R
«соседних» ячеек. Машины Тьюринга, как и логарифмическая сложность, удобны при рассмотрении комбинаторных
задач с небольшим количеством числовых параметров, а также (в силу своей структурной простоты) для теоретических
исследований.
1.2.2 Машины Тьюринга и вычислимость
Введение
Неформально, Машина Тьюринга (далее МТ) представляет собой автомат с конечным числом состояний и неограни-
ченной памятью, представленной набором одной или более лент, бесконечных в обоих направлениях. Ленты поделены
на соответственно бесконечное число ячеек, и на каждой ленте выделена стартовая (нулевая) ячейка. В каждой ячейке
может быть записан только один символ из некоторого конечного алфавита Σ, где предусмотрен символ ? для обозна-
чения пустой ячейки.
На каждой ленте имеется головка чтения-записи, и все они подсоединены к «управляющему модулю» МТ — ав-
томату с конечным множеством состояний Γ. Имеется выделенное стартовое состояние «START» и состояние завер-
шения «STOP». Перед запуском МТ находится в состоянии «START», а все головки позиционированы на нулевые
ячейки соответствующих лент. На каждом шаге все головки считывают информацию из своих текущих ячеек и посы-
лают ее управляющему модулю МТ. В зависимости от этих символов и собственного состояния управляющий модуль
производит следующие операции:
1. Посылает каждой головке символ для записи в текущую ячейку каждой ленты
2. Посылает каждой головке одну из команд «LEFT»,«RIGHT»,«STAY»;
3. Выполняет переход в новое состояние (которое, впрочем, может совпадать с предыдущим).
Теперь то же самое более формально.
Определение 1 Машина Тьюринга это набор T = hk, Σ, Γ, α, β, γi, где
• k ≥ 1 — натуральное число,
• Σ, Γ — конечные множества входного алфавита и состояний соответственно,
• ? ∈ Σ — символ-пробел, ST ART, ST OP ∈ Γ — выделенные состояния,
• α, β, γ — произвольные отображения:
α : Γ × Σ
k
→ Γ
β : Γ × Σ
k
→ Σ
k
γ : Γ × Σ
k
→ {−1, 0, 1}
k
Т.е. α задает новое состояние, β — символы для записи на ленты, γ — как двигать головки. Удобно считать, что
алфавит Σ содержит кроме «пробела» ? два выделенных символа, 0 и 1
12
.
Под входом для МТ подразумевается набор из k слов (k-кортеж слов из Σ
∗
), записанных на k лентах начиная
с нулевых позиций. Обычно, входные данные записывают только на первую ленту, и под входом x подразумевают k-
кортеж hx, 0, . . . , 0i.
Результатом работы МТ на некоем входе является также k-кортеж слов из Σ
∗
, оставшихся на лентах. Для про-
стоты также удобно считать, что результатом является только слово на последней ленте, а все остальное — просто
12
Обычно вовсе ограничиваются Σ ≡ {?, 0, 1}
25

мусор. Также считается, что входное слово не содержит пробелов ? — иначе было бы невозможно определить, где
кончается входное слово
13
. Алфавит входного слова будем обозначать Σ
0
= Σ \ {?}.
Если что-то осталось непонятным, посмотрите алгоритм 15 «Симулятор MT» — симулятор работы МТ, который
мы будем использовать, чтобы проиллюстрировать процесс работы машин Тьюринга. Он принимает на вход описание
машины Тьюринга в виде хэш-таблицы (Cм. Рис. 1.2). Обратите также внимание на альтернативное представление
машин Тьюринга в виде ориентированных графов, где вершинами являются состояниями, возможные переходы между
ними — ребрами, причем начало ребра помечено символом, который должен быть на ленте для активации перехода, а
конец ребра помечен символом, который пишется на ленту, и командой перемещения головки («L»,«R»,«»).
Примеры
Рассмотрим несколько примеров машин Тьюринга.
1. «удвоение строки»: Рис. 1.2.
2. «унарное сложение»: Рис. 1.3.
3. «распознавание четных строк»: Рис. 1.4.
4. «Распознавание строки, с одинаковым количеством 0 и 1»: Рис. 1.5 и 1.6.
Для каждой машины показано:
• табличное описание, в формате, подаваемом на вход алгоритму 15 «Симулятор MT»;
• граф переходов, где вершинами являются состояния, возможные переходы между ними — ребрами, причем на-
чало ребра помечено символом, который должен быть на ленте для активации перехода, а конец ребра помечен
символом, который пишется на ленту, и командой перемещения головки («L»,«R»,«»);
• истории выполнения, для различных лент, где для каждого такта выделено положение головки и указано текущее
состояние.
Упражнение 9 Постройте машину Тьюринга, которая записывает входное двоичное слово в обратном по-
рядке.
Упражнение 10 Постройте машину Тьюринга, которая складывает два числа, записанные в двоичной си-
стеме. Для определенности считайте, что записи чисел разделены специальным символом алфавита «+».
Заметим, что в различной литературе встречается великое множество разновидностей определений МТ — ограни-
чивается число лент, например до одной, причем, бесконечной только в одном направлении, или вводится «защита от
записи» на все ленты, кроме одной, разумеется, и т.п.
Однако несложно, хотя и несколько утомительно, показать эквивалентность всех этих определений, в смысле вы-
числительной мощности. Мы тоже слегка затронем эту тему.
Для начала введем понятие универсальной машины Тьюринга, которая уже напоминает больше современный
программируемый компьютер, чем механическую шкатулку.
Пусть T = hk + 1, Σ, Γ
T
, α
T
, β
T
, γ
T
i и S = hk, Σ, Γ
S
, α
S
, β
S
, γ
S
i, k ≥ 1, две МТ, а p ∈ Σ
∗
0
. Итак, T с программой p
симулирует S, если для произвольного слова x
1
, . . . , x
k
∈ Σ
∗
0
,
1. T останавливается на входе (x
1
, . . . , x
k
, p) тогда и только тогда, если S останавливается на (x
1
, . . . , x
k
);
2. В момент остановки T, на первых k лентах такое же содержимое, как на лентах S, после остановки на том же
входе.
Определение 2 k + 1 ленточная МТ T универсальна, если для любой k-ленточной МТ S (над алфавитом Σ),
существует программа p ∈ Σ
∗
0
, на которой T симулирует S.
Теорема 1 Для любого k ≥ 1 и любого алфавита Σ, существует (k + 1) ленточная универсальная МТ.
13
Можно конечно разрешить пробелы во входном слове, ?, но тогда придется зарезервировать еще один символ — «конец ввода».
26

Алгоритм 15 Симулятор работы машины Тьюринга
def execute_MT ( , ):
k ← [ ]
T ← [ ]
← [ ] + [: ]
← { : [ ], : 1, : }
← [ ]
← 0
while 1:
← + 1
if we reach the end of the tape — enlarge it
if [ ] ≥ len ( [ ]):
[ ].append ( )
the symbol we are looking at
← [ ][ [ ]]
perform transition
← ( [ ], ( ))
← T [ ]
Just cloning entire configuration: (state,head position,tape)
← [ ][: ]
← dict ( )
[ ] ←
←
changing state
[ ] ← [0]
write new symbol
← [1][0]
[ ][ [ ]] ←
move head
← [1][1]
if = : [ ] ← [ ] − 1
if = : [ ] ← [ ] + 1
tracking configuration
.append ( )
if stop state - finishing
if [ ] = [ ] ∨ > 1000 :
break
return
27
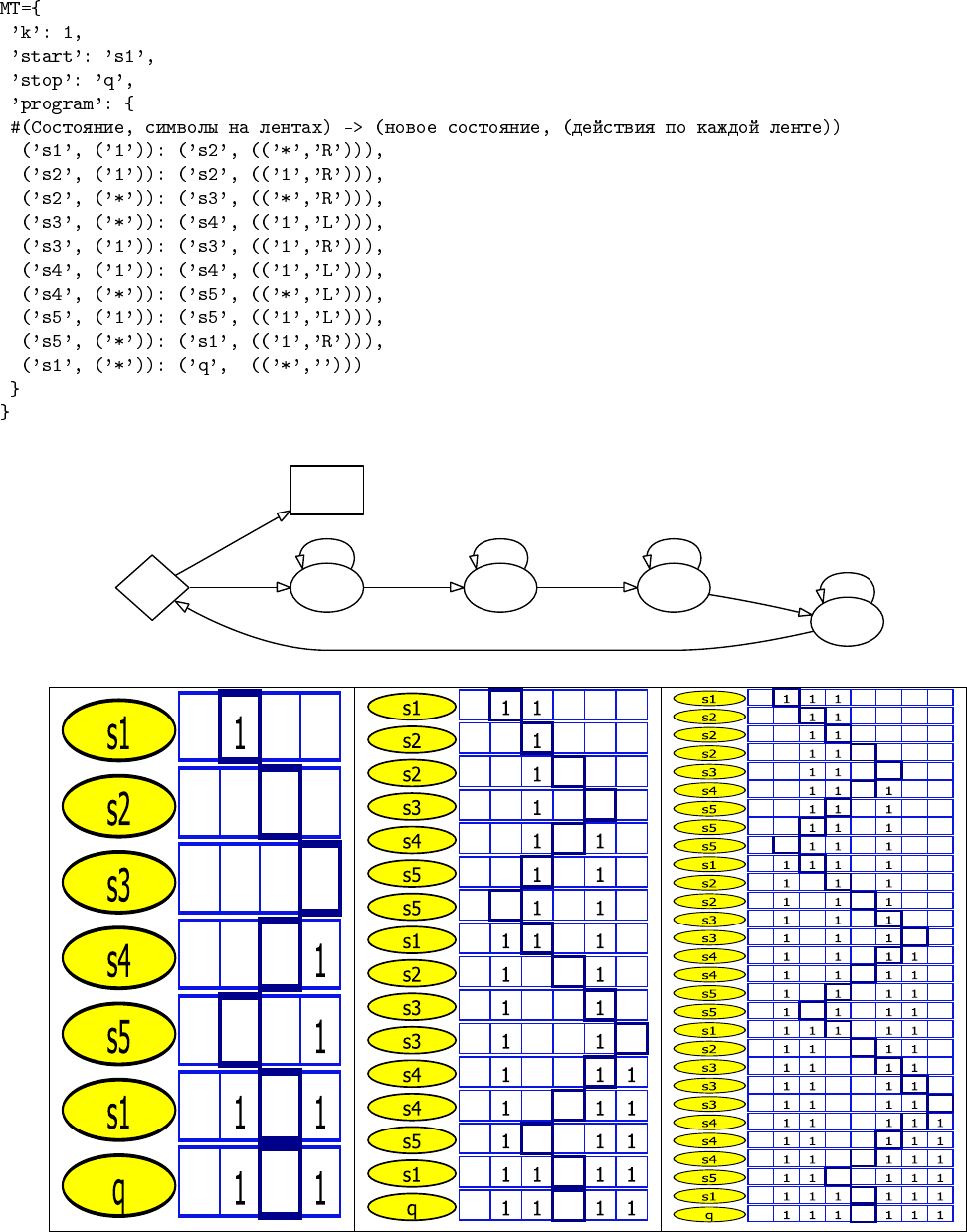
Рис. 1.2: Пример МТ: удвоение строки
s1
q
*
*
s2
*R
1
s51R
*
1L
1
1R
1
s3
*R
*
1R
1
s4
1L
* *L
*
1L
1
28

Рис. 1.3: Пример МТ: унарное сложение
1pass
1R
1
2pass
1R
*
qdel1 del2
*L
1
rewind
*L
1
*R
*
1L
1
*L
*
1R
1
29
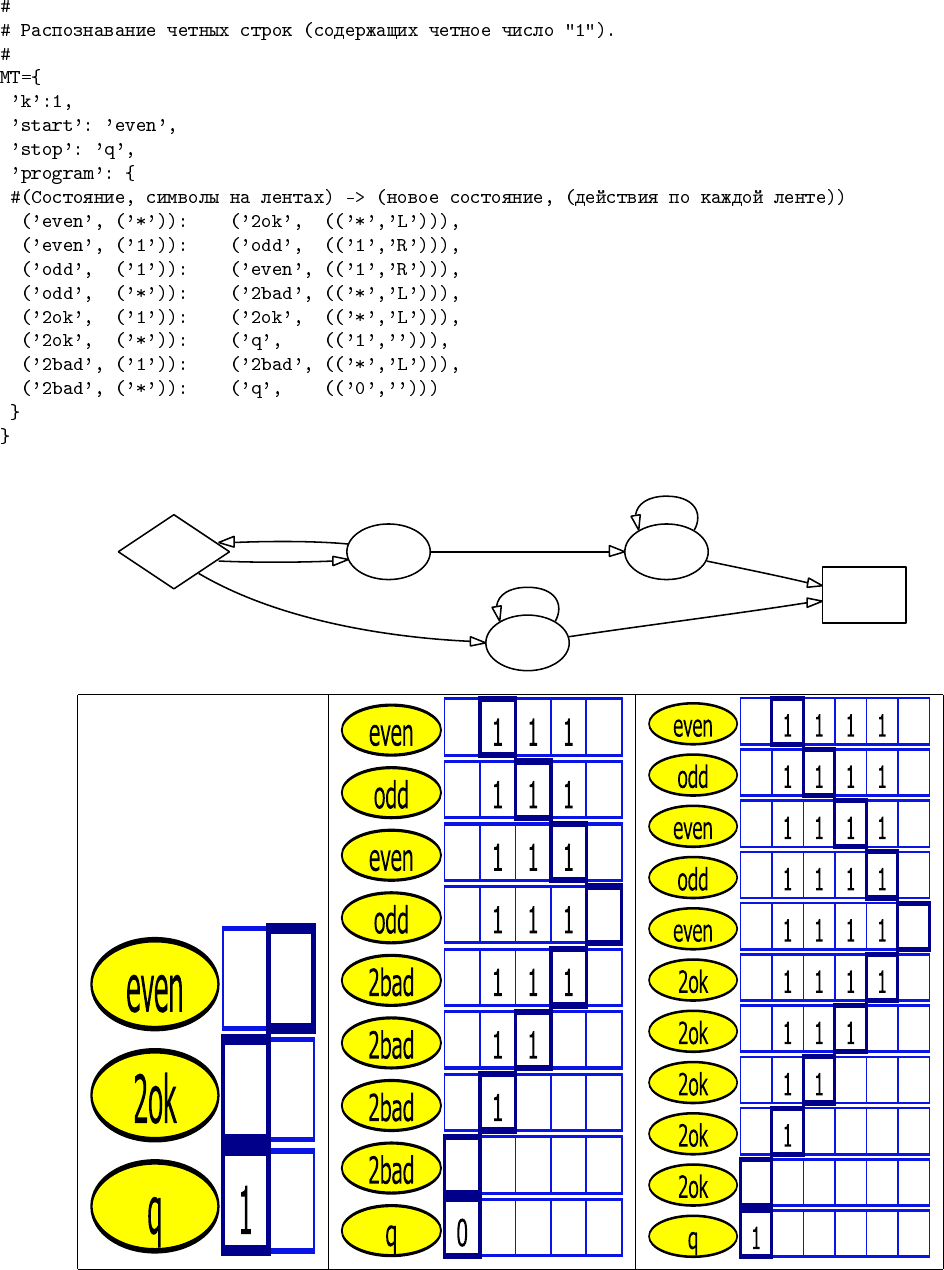
Рис. 1.4: Пример МТ: распознавание четных строк
even odd
1R
1
2ok
*L
*
q
2bad
0
*
*L
1
1R
1
*L
*
1
*
*L
1
30