Klir G.J. Uncertainity and Information. Foundations of Generalized Information Theory
Подождите немного. Документ загружается.

uncertainty. The a is not normalized and has no betting interpretation, so
is clearly distinct from a probability.
Uncertainty in Ben-Haim’s theory is not explicitly defined in measure–theoretic
terms. How to describe it within the GIT framework, if possible at all, is an open
question.
10.4. The following is a chronology of those major debates regarding uncertainty and
probability that are well documented in the literature:
•
Probability theory versus evidence theory in artificial intelligence (AI)
—Shafer, Lindley, Spiegelhalter, Watson, Dempster, Kong;
—Statistical Science, 1987, 2(l), 1–44.
•
Bayesian (probabilistic) approach to managing uncertainty in AI versus other
approaches;
—Peter Cheeseman and 23 correspondents;
—Computational Intelligence (Canadian), 1988, 4(l), 57–142.
•
“An AI View of the treatment of uncertainty” by A. Saffioti;
—11 correspondents;
—The Knowledge Engineering Review, 1988, 2(l), 59–91.
•
Cambridge debate: Bayesian approach to dealing with uncertainty versus other
approaches;
—Peter Cheeseman ´ George Klir, Cambridge University, August 1988;
—International Journal of General Systems, 1989, 15(4), 347–378.
•
Fuzziness versus probability;
—Michael Laviolette and John Seaman and 8 correspondents;
—IEEE Transactions on Fuzzy Systems, February 1994, 2(l), 1–42.
•
“The Paradoxical Success of Fuzzy Logic”;
—Charles Elkan and 22 correspondents;
—IEEE Expert, August 1994, 9(4), 2–49.
•
“Probablistic and Statistical View of Fuzzy Methods” by M. Laviolette,
J.W. Seaman, J.D. Barrett, and W.H. Woodall;
—6 responses;
—Technometrics, 1995, 37(3), 249–292.
In many of these debates, the focus is on the relationship between probability
theory and the various novel uncertainty theories. The issues discussed and
the claims presented by defenders of probability theory vary from debate to
debate. The most extreme claims are expressed by Lindley in the first debate
[italics added]:
The only satisfactory description of uncertainty is probability. By this I
mean that every uncertainty statement must be in the form of a probabil-
ity; that several uncertainties must be combined using the rules of proba-
bility; and that the calculus of probabilities is adequate to handle all
situations involving uncertainty. Probability is the only sensible description
of uncertainty and is adequate for all problems involving uncertainty. All
other methods are inadequate....Anything that can be done with fuzzy
422
10. CONCLUSIONS
logic, belief functions, upper and lower probabilities, or any other alterna-
tive to probability, can better be done with probability.
These extreme claims are often justified by referring to a theorem by Cox [1946,
1961], which supposedly established that the only coherent way of representing
and dealing with uncertainty is to use rules of probability calculus. However, it
has been shown that either the theorem does not hold under assumptions stated
explicitly by Cox [Halpern, 1999], or it holds under additional, hidden assump-
tions that are too strong to capture all aspects of uncertainty [Colyvan, 2004] (see
Colyvan’s paper for additional references on this topic).
10.5. The distinction between the broad concept of uncertainty and the narrower
concept of probability has been obscured in the literature on classical, probabil-
ity-based information theory. In this extensive literature, the Hartley measure is
routinely portrayed as a special case of the Shannon entropy that emerges from
the uniform probability distribution. This view is ill-conceived since the Hartley
measure is totally independent of any probabilistic assumptions, as correctly rec-
ognized by Kolmogorov [1965] and Rényi [1970b]. Strictly speaking, the Hartley
measure is based on one concept only: a finite set of possible alternatives, which
can be interpreted as experimental outcomes, states of a system, events, messages,
and the like, or as sequences of these. In order to use this measure, possible alter-
natives must be distinguished, within a given universal set, from those that are
not possible. It is thus the possibility of each relevant alternative that matters in
the Hartley measure. Hence, the Hartley measure can be meaningfully general-
ized only through broadening the notion of possibility. This avenue is now avail-
able in terms of the theory of graded possibilities and other nonclassical
uncertainty theories that are the subject of GIT.
10.6. As shown by Dretske [1981, 1983], a study of semantic aspects of information
requires a well-founded underlying theory of uncertainty-based information.
While in his study Dretske relies only on information expressed in terms of the
Shannon entropy, the broader view of GIT allows us now to approach the same
study in a more flexible and, consequently, more meaningful fashion. Studies
regarding pragmatic aspects of information, such as those by Whittemore and
Yovits [1973, 1974] and Yovits et al. [1981], should be affected likewise. Hence,
the use of the various novel uncertainty theories, uncertainty measures, and
uncertainty principles in the study of semantic and pragmatic aspects of infor-
mation will likely be another main, long-term direction of research.
10.7. The aims of GIT are very similar to those of generalized theory of uncertainty
(GTU), which have recently been proposed by Lotfi Zadeh [2005]. However, the
two theories are formulated quite differently. In GTU, information is viewed in
terms of generalized constraints on values of given variables. These constraints
are expressed, in general, in terms of the granular structure of linguistic variables.
In the absence of any constraint regarding the variables of concern, we are totally
ignorant about their actual state. In this situation, our uncertainty about the
actual state of the variables is maximal.Any known constraint regarding the vari-
ables reduces this uncertainty, and may thus be viewed as a source of informa-
tion. The concept of a generalized constraint, which is central to GTU, has many
distinct modalities. Choosing any of them reduces the level of generality. Making
further choices will eventually result in one of the classical theories of uncer-
NOTES 423
tainty. This approach to dealing with uncertainty is clearly complementary to the
one employed in GIT. In the latter, we start with the two classical theories of
uncertainty and generalize each of them by relaxing its axiomatic requirements.
The GTU approach to uncertainty and information is thus top-down—from
general to specific. On the contrary, the GIT approach to uncertainty and infor-
mation is bottom-up—from specific to general. Both approaches are certainly
meaningful and should be pursued. In the long run, results obtained by the two
complementary approaches will eventually meet. When this happens, our under-
standing of information-based uncertainty and uncertainty-based information
will be quite satisfactory.
424
10. CONCLUSIONS

APPENDIX A
UNIQUENESS OF THE
U-UNCERTAINTY
425
In the following lemmas, functional U is assumed to satisfy requirements
(U2), (U3), (U5), (U8), and (U9) as axioms: additivity, monotonicity, expan-
sibility, branching, and normalization, respectively (p. 205). The notation
and is carried over from the formulation of
the branching requirement.
Lemma A.1. For all q, k Œ ⺞,2 £ q £ k £ n, with r = {r
1
, r
2
,...,r
n
}
(A.1)
Proof. By the branching axiom we have
(A.2)
This also shows that the lemma is true for q = 2. We now proceed with a proof
by induction on q. Applying the induction hypothesis to the first term on the
right-hand side of Eq. (A.2), we get
U Urr r rrr r
rrU
rr
rr
rrU
k kkk n
kk k
kk
kk
nk
rkknk
r
10
10
()
=
()
+-
()
-
-
Ê
Ë
ˆ
¯
--
()( )
-+
--
-
-
-+
---+
12 2 1
22
1
2
1
222
, ,..., , , , ,...,
,,
,.
UUrr rrr rr r
rrU
rr
rr
rr
rr
rr
kq k k k
q
kn
kq k kq
kq k
kq k
kq k
kq k
k
r
1
()
=
Ê
Ë
Á
ˆ
¯
˜
+-
()
-
-
-
-
-
-+
--
-+
-
-+
-
-
12 1
12
1
, ,..., , , ,..., , ,...,
, , ,...,
12434
kk
kq k
nk
rq k kq nkq
rr
rrU
-
-+
---+
-
Ê
Ë
Á
ˆ
¯
˜
--
()( )
,
,.
0
10
1
0
m
m
= 000 0, , ,...,
1244344
1
m
m
= 111 1, , ,...,
12434
Uncertainty and Information: Foundations of Generalized Information Theory, by George J. Klir
© 2006 by John Wiley & Sons, Inc.
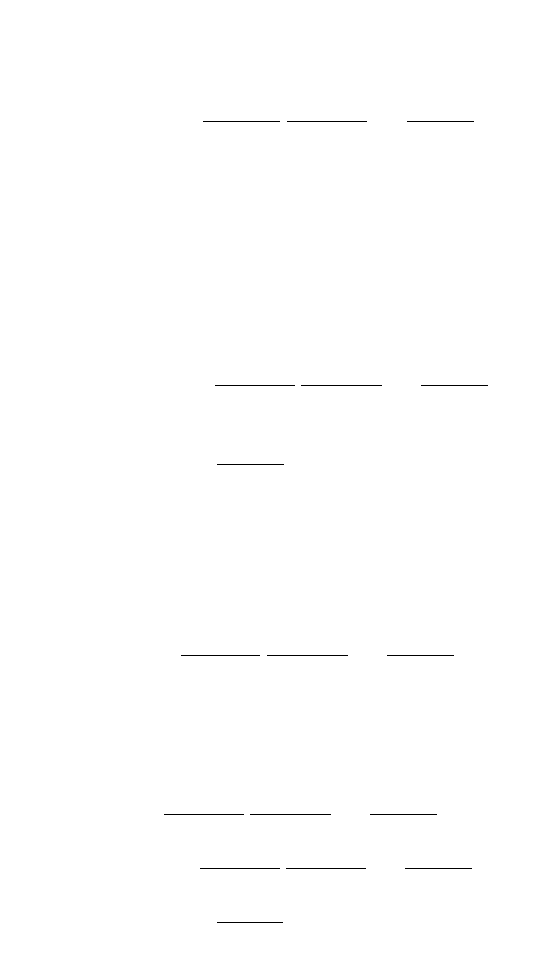
(A.3)
If we substitute this back into Eq. (A.2), we deduce that
(A.4)
Now apply the branching axiom to the quantity
(A.5)
to produce
(A.6)
All three terms on the right-hand side of the equality in Eq. (A.6) are present
in the right-hand side of Eq. (A.3), so that by a simple substitution we con-
clude that which was to be proved:
rrU
rr
rr
rr
rr
rr
rr
rrU
rr
rr
r
kq k kq
kq k
kq k
kq k
kq k
kk
kq k
nk
kq k kq
kq k
kq k
kq
--
-+
-
-+
-
-
-
-+
--
-+
-
-
-
()
-
-
-
-
-
-
Ê
Ë
Á
ˆ
¯
˜
=-
()
-
-
10
1
, , ,..., ,
,,
12
1
1
1 ++
-
-
-
-+
--
-
-
-+
---+
-
-
-
-
Ê
Ë
Á
ˆ
¯
˜
+-
()
-
-
Ê
Ë
ˆ
¯
--
()( )
1
2
2
22
1
2
1
222
r
rr
rr
rr
rrU
rr
rr
rrU
k
kq k
kk
kq k
nk
kk k
kk
kk
nk
kkknk
,..., ,
,,
,.
0
10
10
rrU
rr
rr
rr
rr
rr
rr
kq k kq
kq k
kq k
kq k
kq k
kk
kq k
nk--
-+
-
-+
-
-
-
-+
-
()
-
-
-
-
-
-
Ê
Ë
Á
ˆ
¯
˜
10, , ,..., ,
12
1
1
UUrr rrr rr r
rrU
rr
rr
rr
rr
rr
kq k k k
q
kn
kq k kq
kq k
kq k
kq k
kq k
k
r
1
()
=
Ê
Ë
Á
ˆ
¯
˜
+-
()
-
-
-
-
-
-+
--
-+
-
-+
-
-
12 1
12
2
, ,..., , , ,..., , ,...,
, , ,...,
12434
kk
kq k
nk
kq k kq nkq
kk k
kk
kk
nk
kkknk
rr
rrU
rrU
rr
rr
rrU
-
-+
---+
--
-
-
-+
---+
-
Ê
Ë
Á
ˆ
¯
˜
--
()( )
+-
()
-
-
Ê
Ë
ˆ
¯
--
()( )
,
,
,,
,.
0
10
10
10
2
22
1
2
1
222
Urr r rrr r
Urr r rr r rr r
rrU
rr
k kkk n
kqkk k
q
kk n
kq k kq
kq
12 2 1
12
1
1
1
, ,..., , , , ,...,
, ,..., , , ,..., , , ,...,
,
-+
-
-
+
--
-+
()
=
Ê
Ë
Á
ˆ
¯
˜
+-
()
-
12434
1
kk
kq k
kq k
kq k
kk
kq k
nk
kq k kq nkq
rr
rr
rr
rr
rr
rrU
-
-+
-
-
-
-+
---+
-
-
-
-
-
Ê
Ë
ˆ
¯
--
()( )
, ,..., ,
,.
22
2
0
10
426 APPENDIX A. UNIQUENESS OF THE U-UNCERTAINTY

䊏(A.7)
Lemma A.2. For all k Œ ⺞, k < n, define g(k) = U(1
k
, 0
n-k
), then g(k) = log
2
k.
Proof. By the expansibility axiom we know that U(1
k
, 0
n-k
) = U(1
k
). By the
additivity axiom g(k + l ) = g(k) + g(l), so by a proof identical to that of
Theorem 2.1 we can conclude that g(k) = log
2
k. 䊏
Lemma A.3. For k Œ ⺞, k ≥ 2, and r Œ ⺢,0 £ r £ 1, we have
(A.8)
where r
n-k
represents
Proof. Let r be the possibility profile 1
k
, r
n-k
. Form the joint possibility profile
r
2
, where both marginal possibility profiles are equivalent to r. It is simple to
check that has this property. Now . First, we
can deduce from the additivity axiom that
(A.9)
Second, by applying Lemma A.1, we get
(A.10)
We also know by the expansibility axiom that U(r) = U(r, 0) for any possibil-
ity profile r, and we can apply Lemma A.1 to any possibility profile and this
will make the final q possibility values zero. Let us perform this operation upon
the first term on the right-hand side of the equality in Eq. (A.10),
Substituting Eq. (A.7) into Eq. (A.10), we calculate that
UU
U
U
k
nk
kn k
nn
n
n
nn
110
1
10
,,,
,.
r
22
2
2
-
-
-
-
()
=
()
+
()
-
()
r
r
UU
U
U
U
knk
k
nk
knk
k
nk
r1
1
10
10
2
222
2
222
2
1
1
()
=
()
=
()
+-
()( )
--
()( )
-
-
-
-
,
,
,
,
r
r
r
r
UUUUrrrr
2
2
()
=
()
+
()
=
()
.
UU
knk
r1
2
222
()
=
()
-
,r
r1
2
222
=
-knk
, r
rrr r, , ,..., .
nk-
1244344
Ukn
knk
1 r
-
()
=-
()
+1
22
rrlog log ,
UUrr rrr rr r
rrU
rr
rr
rr
rr
rr
kq k k k
q
kn
kq k kq
kq k
kq k
kq k
kq k
k
r
1
()
=
Ê
Ë
Á
ˆ
¯
˜
+-
()
-
-
-
-
-
-+
--
-+
-
-+
-
-
12 1
12
1
, ,..., , , ,..., , ,...,
, , ,...,
12434
kk
kq k
nk
kq k kq nkq
rr
rrU
-
-+
---+
-
Ê
Ë
Á
ˆ
¯
˜
--
()( )
,
,.
0
10
1
APPENDIX A. UNIQUENESS OF THE U-UNCERTAINTY 427

(A.11)
Now using the expansibility axiom to drop all final zeros and Lemma A.2 to
replace U(1
k
) with log
2
k,
(A.12)
We now finish the proof by remembering that ,
that U(1
k
, r
n
) = U(r), and that log
2
x
2
= 2log
2
x:
䊏(A.13)
Theorem A.1. The U-uncertainty is the only functional that satisfies the
axioms of expansibility, monotonicity, additivity, branching, and normalization.
Proof. The proof is by induction on n, the length of the possibility profile. If
n = 2, then we can apply Lemma A.3 to get the desired result immediately.
Assume now that the theorem is true for n - 1; then we can use the
expansibility and branching axioms in the same way as was used in the proof
of Lemma A.3 to replace r
n
with zero:
(A.14)
We can now apply Lemma A.3 to the term U(1
n-1
,(r
n
/r
n-1
), 0) and drop termi-
nal zeros,
(A.15)
UUrr r
r
r
r
n
r
r
n
rn
Ur r r
rr n r n
r
n
n
n
n
n
n
n
n
nn n
r
()
=
()
+-
Ê
Ë
ˆ
¯
-
()
+
È
Î
Í
˘
˚
˙
--
()
=
()
+-
()
-
()
+
-
-
-
--
-
-
-
12 1
1
1
2
1
2
12
12 1
12 2
11
1
1
, ,...,
log log
log
, ,...,
log log
nn
nn n
nn
n
Ur r r r n r n
Ur r r r
n
n
-
-
-
-
()
=
()
--
()
+
=
()
+
-
12
12 1 2 2
12 1 2
1
1
1
log
, ,..., log log
, ,..., log .
UUrr r
Ur r r
Ur r r
rU
r
r
rU
n
n
n
nn
n
n
nn
r
1
1
()
=
()
=
()
=
()
+
Ê
Ë
ˆ
¯
-
()
-
--
-
--
12
12
12 1
11
1
11
0
00
0
00
, ,...,
, ,..., ,
, ,..., , ,
,,
,, .
22
21 1
1
22
22
22
UU n n
kn
Un k
rr
r
()
=
()
+-
+-
()
--
()
()
=+-
()
rr
rr
rr
log log
log log
log log .
UUU
knk
1rr
222
2
2, r
-
()
=
()
=
()
UU nn
kn
knk
knk
11
222
2
2
2
2
2
2
11
, , log log
log log .
rr
-
-
()
=
()
+-
+-
()
--
()
rr
rr
UU U U
UUU
knk
k
nk k nk
k
nk
kn k
nn n
n
nn
11 10 10
10 1 10
222 2 2 22 2
22 2
11,, , ,
,, , .
rr
-- - -
-
--
()
=
()
+-
()( )
--
()( )
=
()
+
()
-
()
rr
rr
428 APPENDIX A. UNIQUENESS OF THE U-UNCERTAINTY
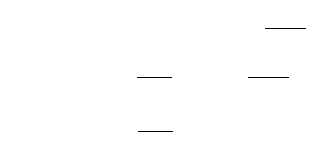
Applying the induction hypothesis, we conclude
䊏
(A.16)
UUrr r r
n
n
r
i
i
r
n
n
r
i
i
nn
in
i
n
i
i
n
r
()
=
()
+
-
=
-
+
-
=
-
-
=
-
=
Â
Â
12 1 2
22
2
1
2
2
1
11
1
, ,..., log
log log
log .
APPENDIX A. UNIQUENESS OF THE U-UNCERTAINTY 429

APPENDIX B
UNIQUENESS OF THE
GENERALIZED HARTLEY
MEASURE IN THE
DEMPSTER–SHAFER
THEORY
A proof of uniqueness of the generalized Hartley measure in the
Dempster–Shafer theory (DST) that is presented here is based on the follow-
ing six axiomatic requirements:
Axiom (GH1) Subadditivity. For any given joint body of evidence, ·F, mÒ on
X ¥ Y, and the associated marginal bodies of evidence, ·F
x
, m
x
Ò and ·F
Y
, m
Y
Ò
Axiom (GH2) Additivity. For any noninteractive bodies of evidence ·F
x
, m
x
Ò
and ·F
Y
, m
Y
Ò, on X and Y, respectively, and the associated joint body of
evidence, ·F, mÒ, where
for all A ΠF
x
and all B ΠF
Y
,
Axiom (GH3) Symmetry. GH is invariant with respect to permutations of
values of the basic probability assignment function within each group of
subsets of X with equal cardinalities.
GH m GH m GH m
XY
()
=
()
+
()
.
FF F=¥ ¥
()
=
()
◊
()
XY X Y
mA B m A m B and
GH m GH m GH m
xY
()
£
()
+
()
.
Uncertainty and Information: Foundations of Generalized Information Theory, by George J. Klir
© 2006 by John Wiley & Sons, Inc.
430

APPENDIX B. UNIQUENESS OF THE GENERALIZED HARTLEY MEASURE IN THE DST 431
Axiom (GH4) Branching. GH(m) = GH(m
1
) + GH(m
2
) for any three bodies
of evidence on X, ·F, mÒ, ·F
1
, m
1
Ò, and ·F
2
, m
2
Ò, such that
where
and
Axiom (GH5) Continuity. GH is a continuous functional.
Axiom (GH6) Normalization. GH(m) = 1 when m(A) = 1 and |A| = 2.
The requirements of subadditivity, additivity, continuity, and normalization
are obvious generalizations of their counterparts for the U-uncertainty. The
requirement of symmetry states that the functional GH (measuring nonspeci-
ficity) should depend only on values of the basic probability assignment func-
tions and the cardinalities of the sets to which these values are allocated and
not on the sets themselves.
The branching requirement states the following: Given a basic probability
assignment function on X, if we maintain its values, but one of its focal subsets
(e.g., subset A) is replaced with a singleton (thus obtaining basic probability
assignment function m
1
) and, separately, replace all remaining focal subsets of
m (i.e., all except A) with singletons (thus obtaining function m
2
), then the sum
of the nonspecificities of m
1
and m
2
should be the same as the nonspecificity
of the original basic probability assignment function m.
It can be now established, via the following theorem, that the generalized
Hartley measure defined by Eq. (6.27) is uniquely characterized by the
axiomatic requirements (GH1)–(GH6).
Theorem B.1. Let M denote the set of all basic probability assignments func-
tions in DST and let GH denote a functional of the form
GH:,
.
M Æ•
[
)
0
mA m A m A
mB m B m B
mC m C m C
()
=
()
=
()
()
=
()
=
()
()
=
()
=
()
12
121
121
AA BB CC
ABC
111
111
1
ÕÕÕ
= = =◊◊◊=
, , ,...,
,
F
F
F
=
{}
=
{}
=
{}
ABC
ABC
AB C
,,,...,
,,,...,
,,,...,
11
211