King M.R., Mody N.A. Numerical and Statistical Methods for Bioengineering: Applications in MATLAB
Подождите немного. Документ загружается.


To test the null hypothesis, we perform the χ
2
goodness-of-fit test. The hypothesized population has a
population proportion of successes equal to 0.85. We want to see if our sample is drawn from a population
that has the same distribution of successes and failures as the hypothesized distribution. We first calculate
the expected sample frequency in each category. If the null hypothesis is true, then, out of 9200 tubes,
7820 are expected to make it to market and 1380 are expected to be defective. We can compare the
observed and expected frequencies using Equation (4.33) to generate the χ
2
test statistic:
χ
2
¼
8420 7820
ðÞ
2
7820
þ
780 1380
ðÞ
2
1380
¼ 306:9:
There are two categories – success and failure, i.e. k = 2. However, the observed and expected
frequencies of scrapped (failed) material are dependent on the observed and expected frequencies in the
success category. This is because the total number of tubes is constrained to 9200. In other words, since
p þ q ¼ 1, then q ¼ 1 p. Once we know p, we will always know q. So, if we know the number of
successes and the total number of outcomes, then we are bound to know the number of failures. In other
words, the frequency of only one category can be varied freely, while the frequency in other category is
fixed by the first. Thus, the frequency count in the failure category, i.e. the last category, provides no new
information. The degrees of freedom associated with this problem are f ¼ k m 1, where m is the
number of population parameters such as mean and variance calculated from the data. Since no
parameters are calculated for this problem, m = 0, and f ¼ k 0 1 ¼ 1.
To clarify the point made above regarding the number of degrees of freedom, we recalculate the χ
2
test
statistic using the definition of χ
2
provided by Equation (4.32) as follows:
χ
2
¼
x npðÞ
2
npq
;
where x is the frequency of successes observed, np is the mean, npq is the variance of the binomial
distribution, and z ¼ðx npÞ=
ffiffiffiffiffiffiffiffiffi
npq
p
. This statistic is associated with one degree of freedom since it has
only one χ
2
term. Alternatively, we can use Equation (4.33) to calculate the test statistic. This equation has
two terms, which we write in terms of binomial variables as follows:
χ
2
¼
o
1
np
ðÞ
2
np
þ
o
2
nq
ðÞ
2
nq
:
Since o
1
þ o
2
¼ np þ nq ¼ n,
χ
2
¼
o
1
npðÞ
2
np
þ
n o
1
ðn npÞðÞ
2
nq
¼
o
1
npðÞ
2
np
þ
o
1
npðÞ
2
nq
¼
ðp þ qÞ o
1
npðÞ
2
npq
¼
x npðÞ
2
npq
:
Here, we have shown that Equations (4.32) and (4.33) are equivalent and that the test statistic is
associated with only one degree of freedom.
Now let’s calculate the p value associated with the calculated test statistic. We set the significance level
at 0.01, since we want to be certain whether a change in scrap rate has occurred:
44
p=1− chi2cdf(306.9, 1)
p=
0
Since p 0.01, we are very confident that the scrap rate has been lowered from 15%. In other words, the
success rate has increased. Note that, even though our hypothesis is non-directional, the direction of
the change is known because we can compare the observed and expected failure frequencies. Because there
are only two categories, it is obvious that if the frequencies in one category significantly increase, then
the frequencies in the second category have concomitantly decreased significantly. If there were more than
two categories, then the χ
2
test cannot tell us which category is significantly different from the others.
277
4.9 Chi-square tests for nominal scale data

We could have also performed the hypothesis test for a single population proportion (using Equation
(4.26)) to test the hypothesis of p = 0.85. Try this yourself. What z statistic and p value do you get? The
p value should be exactly the same since the two tests are essentially equivalent. Since χ
2
¼ z
2
,az value
of
ffiffiffiffiffiffiffiffiffiffiffiffi
306:9
p
is obtained.
We have assumed that use of the χ
2
statistic was valid in Example 4.5. Recall that the
z test was permitted for testing population proportions only if n
^
p
4
5 and
n 1
^
pðÞ
4
5. Example 4.5 fulfils this condition. The use of the χ
2
test procedure is
valid only if the sampling distribution of the binomial variable x c an be approxi-
mated by a normal distribution. Now we discuss the condition of validity for use of
the χ
2
goodness-of-fit test in general. There is some difference in opinion among
statisticians over the minimum allowable expected frequency count in any categor y.
One recommendation that has been gaining increasing acceptance is that if n is not
large, the minimum expected frequency in any category should not be less than 5,
otherwise the minimum expected frequency in any category should not be less
than 1. If the expected frequency in any category is found to be less than 1, the
category should be combined with an adjacent category so that the combined
expected frequency is greater than 1 (or 5).
Box 4.10 Distribution of birthweights in two different racial groups in England and Wales
A statistical analysis of birthweights according to racial group for all recorded human births occurring in
England and Wales in the year 2005 was performed (Moser et al., 2008). Table 4.8 presents the
birthweight distributions observed in two specific racial groups that reside in England and Wales.
We want to find out if the birthweights exhibit a normal distribution within each racial population in
England and Wales. The null hypothesis is
H
0
: The human birthweight distribution within any racial subpopulation of England and Wales is
normal.
To calculate the expected or hypothesized frequencies in each birthweight category, we need first to
convert the birthweight ranges that define each category into deviations on the standard normal scale.
We then calculate the area under the standard normal curve defined by the z ranges for each category.
The population parameters μ and σ are estimated from the human birthweight data for each racial group.
Because the observed frequency data are used to obtain two parameters of the hypothesized frequency
distribution, the degrees of freedom associated with the test statistic reduce by 2. We perform the χ
2
goodness-of-fit test to assess normality of birthweight distribution within the White British racial group.
The standardized birthweight variable z is calculated using the equation z ¼ðx μÞ=σ:
The first birthweight category is x < 1.0 kg. The z range for the first birthweight category is from
z ¼∞ to z ¼
1:0 3:393
0:488
¼4:904:
The probability of observing birthweights in this category, under H
0
, is equal to the area under the z
curve from z = −∞ to z ¼4:904. Using the MATLAB normcdf function, we can calculate this
probability. For this function, the default values for μ and σ are zero and one, respectively. Multiplying the
total observed births with the probability gives us the expected frequency in that category:
44
p = normcdf(-4.904)
p=
4.6952e-007
278
Hypothesis testing
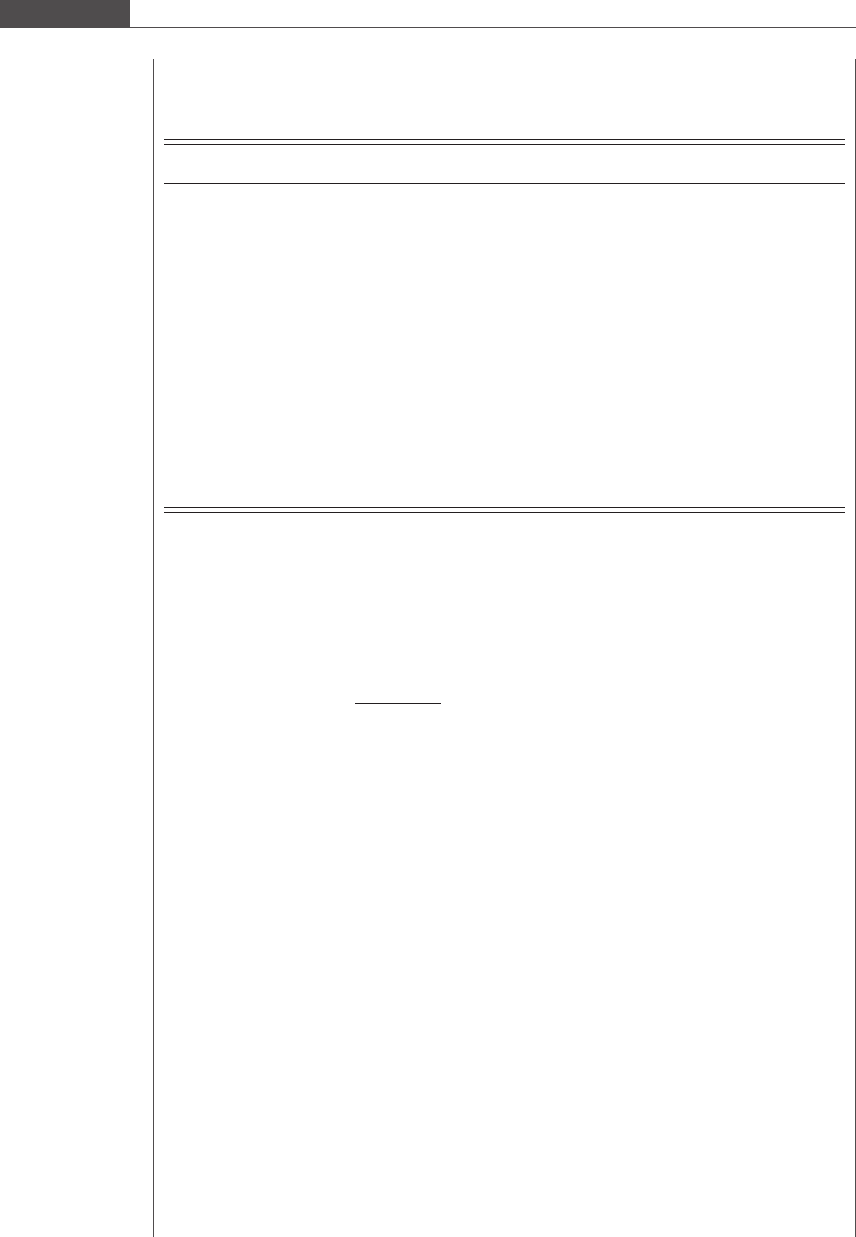
The expected frequency in category 1 is 402942 4:6952 10
7
¼ 0:1892. Since the expected
frequency in this category is less than unity, we will need to combine this category with the second
birthweight category.
The second category is 1.0 kg ≤ x < 1.5 kg. The z range of the second category is from
z ¼4:904 to z ¼
1:5 3:393
0:488
¼3:879:
The area under the z curve from z ¼4:904 to z ¼3:879 gives us the expected relative frequency
(probability) and is obtained as follows:
44
p = normcdf(-3.879) - normcdf(-4.904)
p=
5.1974e-005
The expected frequency in category 2 is 402942 5:1974 10
5
¼ 20:94.
In a similar fashion we can calculate the expected frequencies for the remaining seven categories.
Table 4.9 shows the method used to calculate the χ
2
test statistic. The degrees of freedom associated
with the test statistic are equal to the (number of categories) – 1 – (number of parameters estimated
from the data). Therefore,
f ¼ k m 1 ¼ 9 2 1 ¼ 6:
The p value for the calculated test statistic χ
2
= 506 926 is
44
p=1– chi2cdf(506926, 6)
p=
0
On inspecting the data, we notice that the observations appear to conform somewhat to a normal
distribution for the middle categories but are grossly non-normal in the first two categories. If we plot the
data, we will see that the observed distribution of birthweights has heavier tails and is skewed more to
the left. Note that the number of observations, n = 402 942, is very large, and in such cases any small
Table 4.8. Frequency distribution of birthweights of live singletons (singly born
babies) for the White British and Asian (Indian) racial groups in England and
Wales
Birthweight, x (kg) White British Asian or Asian British (Indian)
<1 1209 91
1–1.5 2015 122
1.5–2.0 4432 261
2.0–2.5 14506 1159
2.5–3.0 60036 4580
3.0–3.5 143447 6189
3.5–4.0 125718 2552
4.0–4.5 43518 478
>4.5 8059 45
Total live single births 402942 15477
Mean birthweight,
x 3.393 3.082
Standard deviation, s 0.488 0.542
279
4.9 Chi-square tests for nominal scale data

deviations from normality will be sharply magnified. The large number of observations in the low-
birthweight categories may correspond to pre-term births. The percentage of pre-term births (under 37
weeks gestational age) of live singletons among the White British category was found to be 6.1%. Full
term is considered to be a gestational age of 40 weeks. The mean gestational age for this group was
39.31 weeks.
A similar exercise can be performed to determine if the birthweight distribution within the British
Indian racial group is normal (see Problem 4.9).
We also want to know if the mean birthweights in these two racial groups of England and Wales are
different. We can use a z test to compare the mean birthweights of the two samples. Since the sample
sizes are large, we may assume that the standard deviation of the birthweights is an accurate estimate of
the population standard deviation. The test statistic is calculated according to Equation (4.9) as follows:
z ¼
x
1
x
2
ffiffiffiffiffiffiffiffiffiffiffiffi
σ
2
1
n
1
þ
σ
2
2
n
2
q
¼
3:393 3:082
ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi
0:488
2
402942
þ
0:542
2
15477
q
¼ 70:3:
The p value associated with this test statistic is zero. The difference between the mean birthweights
of the two racial groups is highly significant. The 95% confidence interval for the difference in the mean
birthweights of the two racial populations is 311 ± 9 g (10.95 ± 0.32 oz). We may conclude
that, on average, babies of the White British population are heavier than those of the British Indian
population.
Table 4.9. Calculation of the x
2
test statistic based on the observed and expected frequencies
in the nine birthweight categories for the White British racial group
Category
Birthweight,
x (kg)
z range for
White
British
Relative
frequency
Expected
frequency,
e
i
Observed
frequency,
o
i
o
i
e
i
ðÞ
2
e
i
1<1 <−4.904 4.695 ×
10
−7
0.2
}
1209
}
2 1–1.5 −4.904 to
−3.879
5.197 ×
10
−5
20.9
21.1
2015
3224
486
188
3 1.5–2.0 −3.879 to
−2.854
0.0021 848.7 4432 15 129
4 2.0–2.5 −2.854 to
−1.830
0.0315 12 679.1 14 506 263
5 2.5–3.0 −1.830 to
−0.805
0.1768 71 234.1 60 036 1760
6 3.0–3.5 −0.805 to
0.219
0.3763 151 613.0 143 447 440
7 3.5–4.0 0.219 to
1.244
0.3066 123 532.0 125 718 39
8 4.0–4.5 1.244 to
2.268
0.0951 38 313.8 43 518 707
9 >4.5 >2.268 0.0116 4700.2 8059 2400
Sum total ~1.00 402 942 402 942
χ
2
= 506 926
280
Hypothesis testing

Using MATLAB
Statistics Toolbox supplies the function chi2gof that allows users to perform the χ
2
goodness-of-fit test to determine if the observed frequency distribution conforms to
a hypothesized discrete or continuous probability distribution. This function auto-
matically groups the observed data into bins or categories. The default number of
bins is ten. By default, chi2gof tests the fit of the data to the normal distribution.
If the frequency in any bin is less than 5, then adjacent bins are grouped together to
bring the frequency co unt to greater than 5. The simplest syntax for this function is
[h, p] = chi2gof(x)
where h is the result of the test, 0 conveys no significant difference between the
observed and expected distributions, 1 conveys rejection of the null hypothesis, p is
the p value of the χ
2
test statistic, and x is a vector containing the data points.
MATLAB automatically creates ten bins, estimates the population mean and var-
iance from x, and calculates the expected frequencies based on the normal distribu-
tion specified by the estimated population parameters.
More details of the test can be specified using the following syntax:
[h, p] = chi2gof(x, ‘parametername1’, parametervalue1,
‘parametername2’, parametervalue2, ...)
where ‘parametername’ is an optional argument and can be any one or more of
the following:
’nbins’: number of bins to use,
’alpha’: the significance level,
’emin’: the least number of counts in any category,
’cdf’: the expected cumulative distribution function,
’expected’: the expected counts in each bin.
Either the values of ‘cdf’ or ‘expected’ can be specified as arguments; the two
parameters should not be specified together.
For more information on usage and other features of this function type help
chi2gof at the MATLAB command prompt.
4.9.2 Test of independence
The χ
2
test is frequently used to determine whether an association or dependency exists
between two nominal variables. For instance, a medical practitioner may wish to
know if there is a link between long-term use of an allopathic medication and
susceptibility to a particular disease. As another example, a public health care official
may be interested in determining whether smoking habits are linked to body weight
and/or mental health. To perform the χ
2
test of independence, a single sample is drawn
from the reference population and each individual or object within the sample is
classified based on the categories specified by the two variables. The frequency
count or number of observations in the sample that belong to a category is recorded
in a contingency table.Ther number of categories of one variable is listed as r rows in
the table, while the c number of categories of another variable is listed as c columns.
The construction of a contingency table is illustrated below using an example.
Public health officials are interested in determining if the smoking status of a
person is linked to alcohol consumpt ion. If the sample size is large enough, the χ
2
test
281
4.9 Chi-square tests for nominal scale data
can be used to look for a dependence of smoking behavior on alcohol consumption.
In this example, the first nominal variable “smoking status” contains two categories:
“current smoker” and “non-smoker,” and the second nominal variable “drinking
status” has two categories: “current drinker” and “non-drinker.” We can construct a
contingency table (see Table 4.10) that has two rows based on the two categories for
“smoking status” and two columns based on the categories for “drinking status.”
Note that “smoking status” can also be listed column-wise and “drinking status”
row-wise, i.e. we can transpose the rows and columns of the table since there is no
particular reason to place one variab le on the rows and the other on the columns.
Since this contingency table has two rows and two columns, it is called a 2 × 2
contingency table. Upon combining the categories of both nominal variables we
obtain four mutually exclusive and exhaustive categories:
(1) current smoker and drinker,
(2) current smoker but non-drinker,
(3) non-smoker but current drinker, and
(4) non-smoker and non-drinker.
Each of the four categories comprises one cell in the contingency table. The row
totals and the column totals are called marginal totals. The total of all column totals
is equal to the total of all row totals, and is called the grand total. The grand total is
equal to the sample size n.
To test for an association between the two variables, we draw a random sample of
size n from the population. The individuals within the sampl e are classified into any
one of the four cells and the frequency counts are listed in Table 4.10. The frequen-
cies observed for each cell are w, x, y,andz. Since the cells represent categories that
are mutual ly exclusive and exhaustive, w þ x þ y þ z ¼ n.
The null hypothesis of the χ
2
statistical test of indepen dence states that the two
classification variables are independent of each other. Note that the null hypothesis
does not contain any references to a population parameter, and thus the χ
2
statistical
test of independence is a true non-parametric test. If there is no association between
smoking tobacco and drinking alcoholic beverages then the smoking population will
have the same distribution of drinkers vs. non-drinkers as the non-sm oking pop-
ulation. The two variables of classification “smoking status” and “drinking status”
are said to be indepe ndent when any change in the population distribution of one
variable does not influence the population distribution of the other variable. For
example, if 30% of the population consists of smokers, and this proportion drops to
20%, the proportion of drinkers in the population will not change if the two
variables are independent. In the language of probability, we say that when two
events are independent of each other, the probability of one event occurring is not
influenced by the knowledge of whether the second event has occurred. If “smoking
Table 4.10. A2× 2 contingency table for smoking and drinking status
Current drinker Non-drinker Total
Current smoker wxw+x
Non-smoker yzy+z
Total w+y x+z w+x+y+z =n
282
Hypothesis testing

status” and “drinking status” are independent outcomes, and the following out-
comes are defined:
S: person is a smoker,
NS: person is a non-smoker,
D: person is a drink er,
ND: person is a non-drinker,
then, if a person is randomly chosen from the population, the conditional proba-
bility that the person drinks if he or she is a smoker is given by
PDjSðÞ¼PðDÞ;
and the conditional probability that the person drinks if he or she is a non-smoker is
given by
PDjNSðÞ¼PDðÞ:
Therefore, the joint probability of selecting a person that smokes and drinks is
PS
\
DðÞ¼PSðÞPDjSðÞ¼PSðÞPDðÞ:
The joint probability that the person smokes but does not drink is
PS
\
NDðÞ¼PSðÞPNDjSðÞ¼PSðÞPNDðÞ:
The theory of joint probability of independent events is used to calculate the
expected frequencies under the null hypothesis for each cell of the contingency
table. We use the frequency counts from the sample to estimate the joint probabil-
ities. The probability that a person in the population is a current smoker is calculated
as ðw þ xÞ=n. The probability that a person in the population is a current drinker is
estimated as ðw þ yÞ=n. If the null hypothesis is true, the joint probability of
encountering a person who smokes and drinks is simply the product of the individual
probabilities, or
PS
\
DðÞ¼PSðÞPDðÞ¼
w þ x
n
w þ y
n
:
To obtain the expected frequency of observing individuals who smoke and drink for
the sample size n, we need to multiply the probability PS
\
DðÞby n. The expected
frequency for the event S
\
D is calculated as
w þ xðÞw þ yðÞ
n
:
To obtain the expected frequency for the cell in the (1,1) position, we simply multiply
the first column total with the first row total and divide the product by the grand
total. Similarly, the expected frequency for the cell in the (2,1) position is estimated
as
y þ zðÞw þ yðÞ
n
;
which is the product of the second row total and the first column total divided by the
grand total. Once the expected frequencies are calculated for all r × c cells, the χ
2
test
statistic is calculated using the formula given by Equation (4.33), where k, the
283
4.9 Chi-square tests for nominal scale data

number of categories, is equal to r × c and the degrees of freedom associated with the
test statistic is r 1ðÞc 1ðÞ. Remember that the observed or expected frequency
in the last (rth or cth) category is dependent upon the distribution of frequencies in
the other (r –1orc – 1, respectively) categories. The last category supplies redundant
information and is therefo re excluded as a degree of freedom. Let’s illustrate the χ
2
test of independence with an example.
Example 4.7
In the IVF outcomes study described in Box 4.7, one large sample of 6164 patients was drawn from the
population defined as female residents of the state of Massachusetts who sought IVF treatment. The
subjects of the sample were classified on the basis of two nominal variables: maternal age group and
outcome of IVF treatment at each cycle. The sample is believed to represent adequately the age distribution
of women who seek IVF treatment and the likelihood of success of IVF treatment within the population. The
authors of the study wished to find out if the probability of success, i.e. live-birth outcome, following IVF
treatment is dependent on or associated with maternal age. In this example, we will be concerned with
outcomes after the first IVF cycle, but prior to subsequent IVF cycles. Subjects were classified into any one
of four categories based on maternal age, which is the first variable. The other classification variable is the
outcome of one cycle of IVF treatment, i.e. whether a live-birth event occur red. The second variable is a
dichotomous variable that can have only two values, “yes” or “no.” At the end of the first IVF cycle, two
outcomes are possible for each patient age group. We want to find out if the probability of a live-birth event
is independent of maternal age. We construct a 2 × 4 contingency table as shown in Table 4.11. The age
groups are listed as columns and the treatment outcomes are listed as rows. Alternatively, we could
create a 4 × 2 contingency table with the age groups listed as rows and the IVF live-birth outcomes listed
column-wise.
The complementary statistical hypotheses for this problem are as follows:
H
0
: “Live birth outcome as a result of IVF is independent of maternal age.”
H
A
: “Live birth outcome as a result of IVF is dependent on maternal age.”
The expected frequencies for each cell of the 2 × 4 contingency table are calculated and listed in
Table 4.12.
The test statistic is given by
χ
2
¼
X
24
i¼1
o
i
e
i
ðÞ
2
e
i
¼
866 656:5ðÞ
2
656:5
þ
370 333:4ðÞ
2
333:4
þ
þ
1183 973:8
ðÞ
2
973:8
¼ 286:0:
The associated degrees of freedom is given by f ¼ 4 1ðÞ2 1ðÞ¼3. The p value is calculated
using the chi2cdf function of MATLAB and is found to be <10
–16
. If we choose α = 0.05, p α and the
Table 4.11. A2× 4 contingency table of live births resulting from IVF treatment in
four maternal age groups
Maternal age (years)
<35 35 to <38 38 to <40 ≥40 Total
Live birth 866 370 168 107 1511
No live birth 1812 990 668 1183 4653
Total 2678 1360 836 1290 6164
284
Hypothesis testing

test result is highly significant. We reject the null hypothesis and conclude that the response to IVF
treatment is linked with maternal age. However, we do not know if our conclusion applies to all maternal age
groups considered in the study, or to only some of them. When the number of categories k within either of
the two nominal variables exceeds 2, rejection of the null hypothesis simply tells us that the variables are
associated. We cannot conclude whether the alternate hypothesis applies to all categories of the variable
(s) or only to some of them. This limitation is similar to that encountered with the one-factor ANOVA test.
Since the χ
2
test assumes that the sample proportion within each category has a
normal sampling distribution, the sample size must be large enough to justify use of
this test. For contingency tables with one degree of freedom, all cell counts should be
greater than 5 in order to use the χ
2
test of independence. If there is more than one
degree of freedom, the minimum cell count allowed may decrease to as low as 1, as
long as the frequency count of at least 80% of the cells is greater than or equal to 5.
4.9.3 Test of homog eneity
The χ
2
test of homogeneity is used when independent random samples are drawn
from two or more different populations, and we want to know if the distribution of
the categories of a nominal variable is similar in those populations. In other words,
we want to know if the populations are homogeneous with respect to the nominal
variable of interest. The χ
2
test of homogeneity tests the null hypothesis that all
populations are similar or hom ogenous with respect to the distribution of a nominal
variable. The χ
2
test of homogeneity is performed in a very similar fashion to the χ
2
test of independence. The homogeneity test also requires the construction of a
contingency table, which is a tabular description of the frequency of observations
within each category for each sample. The names of the different samples can be
listed either row-wise or column-wise in the table. In this book, each sample is listed
as a column in the table. If there are k samples, the contingency table has k columns.
The different categories of the nominal variable are listed as rows. If there are
r categories and k independent samples drawn from k populations, then we have
an r × k contingency table.
We reconsider the illustration provided in Section 4.9.2 of a study that seeks a
relationship between smoking status and alcohol status. We modify the test con-
ditions so that we begin with two populations: (1) individuals that consume alcoholic
beverages regularly, and (2) individuals that do not consume alcoholic beverages. A
random sample of size n
i
is drawn from each population, where i = 1 or 2. We want
to determine whether smoking is more prevalent in the drinking population. Thus,
we wish to compare the frequency distribution of smoking status within both
Table 4.12. Expected frequencies of live births resulting from IVF treatment in four
maternal age groups
Maternal age (years)
<35 35 to <38 38 to <40 ≥40 Total
Live birth 656.5 333.4 204.9 316.2 1511
No live birth 2021.5 1026.6 631.1 973.8 4653
Total 2678 1360 836 1290 6164
285
4.9 Chi-square tests for nominal scale data

samples to determine if the two populations are homogeneous with respect to the
variable “smoking status.” The null hypothesis stat es that
H
0
: The proportion of smokers is the same in both the drinking and non-drinking
population.
The alternate hypothesis is
H
A
: The proportion of smokers in the drinking population is different from that in
the non-drinking population.
The 2 × 2 contingency table is shown in Table 4.13. Note that the column totals are
fixed by the experimental investigator and do not indicate the proportion of drinkers
in the population. The grand total is equal to the sum of the individual sample sizes.
Under the null hypothesis, the samples are derived from populations that are
equivalent with respect to distribution of smoking status. The best estimate of the
true proportion of smokers in either population can be obtained by pooling the
sample data. If H
0
is true, then an improved estimate of the proportion of smokers
within the drinking and non-drinking population is ðw þ xÞ=n. Then, the expected
frequency of smokers for the sample derived from the drinking population is equal
to the proportion of smokers within the population multiplied by the sample size, or
n
1
w þ x
n
:
Thus, the expected frequen cy for cell (1, 1) is equal to the product of the first row
total and the first column total divided by the grand total n. Simi larly, the expected
frequency for cell (1, 2) is equal to the product of the first row total and the second
column total divided by the grand total n. Note that the formula for calculating the
expected frequencies is the same for both χ
2
tests of independence and homogeneity,
even though the nature of the null hypothesis and the underlying theory from which
the formula is derived are different. Limitations of the use of the χ
2
test of homoge-
neity when small frequencies are encountered are the same as that discussed for the
χ
2
test of independence.
For a χ
2
test of homogeneity involving a 2 × 2 contingency table, the χ
2
method is
essentially equivalent to the z test for equality of two population proportions. The p
value that is obtained by either method should be exactly the same for the same set of
data, and you can use either statistical method for analyzing sample data. Both test
methods assume a normal sampling distribution for the sample proportion, and
therefore the same conditions must be met for their use.
Table 4.13. A2× 2 contingency table for smoking distribution within the drinking and
non-drinking population
Drinking population Non-drinking population Total
Current smoker wx w+x
Non-smoker n
1
–w n
2
–x n
1
+n
2
–w–x
Total n
1
n
2
n
1
+n
2
=n
286
Hypothesis testing