Fishwick P.A. (editor) Handbook of Dynamic System Modeling
Подождите немного. Документ загружается.

2-14 Handbook of Dynamic System Modeling
Smaller than
ISA
ISA
ISAISA
Wine
glass
Water
glass
Dessert
fork
Dinner
fork
Crystal
Silverware
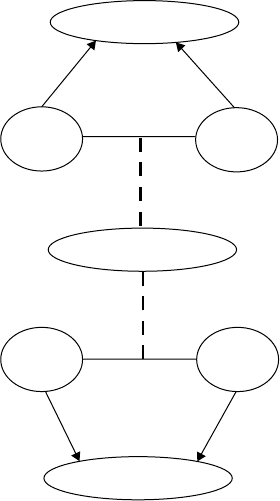
FIGURE 2.3 Part of the semantic memory (Slipnet) used in solving the Tabletop configuration shown in Figure 2.2.
knowledge of the world. The links represent connections between concepts in the world and their length
corresponds to the semantic distances between them (Shepard, 1962). Most importantly, as mentioned
above, it is malleable, i.e., it can change dynamically depending on the concepts that are activated. If, for
example, the concept “smaller than” becomes active because, for example, we notice that dessert forks are
smaller than dinner forks, then we become more sensitive to this relationship for all pairs of concepts for
which it applies (e.g., saucers versus dinner plates, wine glasses versus water glasses, etc.) (see Figure 2.3).
Among the concepts in the semantic memory is “group.” Concepts in semantic memory correspond, at
least approximately, to the agents that will be building structures in Working Memory.
Let us start the process by launching some agent, for example, a “Find-Group” agent. It looks for a
“group” on the table. It does not see forks, knives, spoons, cups, etc. It merely looks for clusters of objects,
any objects. It finds one (say, the group closest to Henry). This causes several things to happen:
•
Activation is sent by the agent to the “group” node in the semantic network. The “group” node in
the semantic network becomes more active.
•
It spawns (i.e., places on the Coderack) a number of finer-grained agents that will, if they run, look
for things that might be inside the just-discovered group. For example, a Find-Group agent that
has found a group on the table, would put several Find-End-Object agents on the Coderack, each
having as a parameter the Group that has just been found. When one of these Find-End-Object
agents runs it will explore an extremity of the Group that was found by its parent Find-Group agent
to determine what the objects at the extremity of the group are.
The added activity of the “group” node in the semantic network causes new “Find-Group” agents to be put
on the Coderack, waiting there to be selected to run. (Here we see the permanent interaction between the
bottom-up processes of the agents and the semantic network.) After a while the Find-Group agents will be
unable to find any more groups. Agents that happen to be on the Coderack will continue to be selected for
a while, but since they would not find any new groups, activation of “group” in the Slipnet will fall. This
will mean that no more new Find-Group agents will be put on the Coderack. The activity of exploring the
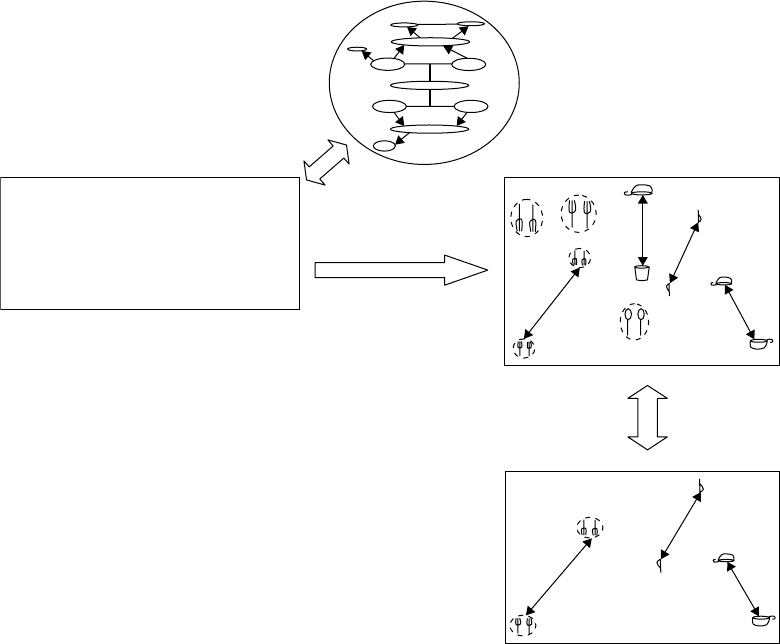
The Dynamics of the Computational Modeling of Analogy-Making 2-15
Semantic
network
Coderack
Codelet
Urgency
Find-group () 20
Find-end-object (Group1) 10
Build-correspondence (knife1, knife2) 5
Build-correspondence (cup1, cup2) 5
Workspace
Worldview
FIGURE 2.4 An illustration of Tabletop in the process of building its representations of the table configuration
in Figure 2.2. Notice that at this relatively early stage of a run of the program, the Worldview contains a cup–cup
correspondence, a correspondence between the two fork groups and one between the two knives. Were the program
to stop now, Eliza would touch the cup on her side of the table. In general, it will end up replacing the cup–cup
correspondence by the more globally coherent cup–glass correspondence, once it has found the mappings between
items and subgroups of items in the two groups of silverware.
table will now be in the hands of other codelets, some of which have been spawned by the Find-Group
agents.
As structures are gradually discovered—for example, the fork subgroups, the spoon subgroups, the
correspondence between the two groups of two spoons (a “correspondence” being a structure, just like a
“group” is a structure), etc.—they are put into the program’s Workspace, where they can be accessed by
the agents.
The best, most coherent structures discovered to date are put into the Worldview. But structures are
continually competing to get into the Worldview from the Workspace. So, for example, early in the
exploration of the table configuration in Figure 2.2, the structure mapping the two cups onto one another
was part of the Worldview (see Figure 2.4). In other words, early on it was considered to be the best
mapping of the object touched by Henry to the object that Eliza should touch. But as the program
gradually discovered the other structures surrounding Henry’s cup and Eliza’s glass, the overall coherence
of the mapping between Henry’s cup and Eliza’s glass grew stronger, until (usually, at least) it displaces
the cup–cup mapping in the Worldview.

2-16 Handbook of Dynamic System Modeling
The overall coherence of structures in the Worldview determines the temperature of the program. If
there is little coherence, then the temperature rises, causing structures in the Workspace to be broken.
This allows new agents to try again and gives the program the possibility of discovering new structures
from the “rubble” of the broken structures. However, if the structures in the Worldview are good and
coherent, temperature falls. When temperature falls low enough, the program stops and picks as its answer
the correspondence in the Worldview containing the touched object.
2.12 The Issue of Scaling Up
One of the important claims about this architecture is that, at least theoretically, it should be capable of
scale up. This is because the program, by design, never examines all possible structures on its way to an
answer. It starts its exploration very broadly and gradually narrows its focus as time goes on, based on
what it has already found. This means that many structures, many potential mappings, many potential
groupings, etc., never get examined to any depth (or, in some cases, are not seen at all) as the program
moves toward an answer.
So, in the example shown in Figure 2.2, if there were, say, 30 groups of objects on the table, instead of
two as there are now, the program would, almost certainly, not explore (or potentially, even find) all of
them. Why? Because very soon after the discovery of the initial, most salient groups, finer-grained agents
would already be exploring these groups. Most probably, if there were a reasonable answer to be found in
these groups, it would be found. Only if this exploration did not lead to an answer in a reasonable time,
would temperature rise and the old structures be broken, thus pushing the program to explore in new
directions. In other words, the amount of exploration that is done is not proportional to the amount of
potential exploration.
2.13 The Potential Long-Term Impact of the
Mechanisms Presented
We have attempted to explain, by means of a number of simple everyday examples, the flexibility of human
analogy-making capabilities. This argues for the importance of programs that develop representations by
means of a continual interaction between a knowledge store and working memory. This crucial ability
will potentially allow scaled-up versions of these programs to navigate safely between the Scylla of hand-
tailored representations designed with the desired mappings in mind and the Charybdis of unfiltered
megarepresentations that entail a combinatorial explosion of mappings. We believe that the mechanism
of context-dependent computational temperature will be a necessary ingredient in programs that will one
day be called truly creative. It allows programs to explore—infrequently, but at least occasionally—highly
improbable areas of space where wonderfully creative answers to a problem could lie.
2.14 Conclusions
I would go so far as to say that analogy-making is, to steal a phrase from the literature on consciousness,
The Hard Problem of AI. Not the Impossible Problem, but Very, Very Hard, all the same, and perhaps
also The Central Problem. And one that will not be fully solved for a very long time. Unlike chess, unlike
optical character recognition, unlike wending your way across a desert with a large database of what to
expect, unlike finding someone’s fingerprints or face in a huge database of fingerprints or faces, etc.—all
of which, however difficult, can be precisely specified—the mechanisms of analogy-making are much
harder to pin down. They involve representing situations so that they can be seen one way in one context,
The Dynamics of the Computational Modeling of Analogy-Making 2-17
another way in another context. They involve enormous problems of extracting and aligning just the right
parts of different representations. And what makes this so hard is that almost anything can, under the
right circumstances, be “like” something else. A claw hammer is like a back scratcher. Stiletto heels are
like a Bengal tiger. Thinking a high IQ is enough to succeed at research is like thinking that being tall
is enough to succeed at professional basketball. And so on, ad infinitum. Analogies cover all domains of
human thought. We abstract something from an event in one domain and explain in by an analogy to
something in a completely different domain. And we do this constantly. It is one of our most powerful
means of explaining something new or unusual. Progress in this area will, no doubt, be slow but will,
without question, be one of the key means by which we will move forward in AI.
References
Bolland, S. (2005). FAE: The Fluid Analogies Engine. A Dynamic, Hybrid model of Perception and Men-
tal Deliberation. Unpublished Ph.D. dissertation, Computer Science and Electrical Engineering,
University of Queensland, Brisbane, Australia.
Bolland, S. and Wiles, J. (2000). Adapting Copycat to visual object recognition. Proceedings of the Fifth
Biennial Australasian Cognitive Science Conference, Adelaide, Australia.
Bolland, S. (1997). http://www2.psy.uq.edu.au/CogPsych/Copycat/ and http://www2.psy.uq.edu.au/
CogPsych/Copycat/Tutorial/
Chalmers, D. J., French, R. M., and Hofstadter, D. R. (1992). High-level perception, representation, and
analogy: A critique of artificial intelligence methodology. Journal of Experimental & Theoretical
Artificial Intelligence, 4, 185–211.
Collins, A. M., and Loftus, E. F. (1975). A spreading activation theory of semantic memory. Psychological
Review, 82, 407–428.
Defays, D. (1990). Numbo: A study in cognition and recognition. The Journal for the Integrated Study
of Artificial Intelligence, Cognitive Science and Applied Epistemology. Issues in Connectionism: Part I,
7(2), 217–243.
Falkenhainer, B., Forbus, K. D., and Gentner, D. (1989). The structure-mapping engine. Artificial
Intelligence, 41(1), 1–63.
Forbus, K., Gentner, D., and Law, K. (1995). MAC/FAC: A model of similarity-based retrieval. Cognitive
Science, 19(2), 141–205.
French, R. M. and Kus, E. (2006). KAMA: A temperature-driven model of mate-choice using dynamically
evolving representations. Adaptive Behavior (under review).
French, R. M. (1995). The Subtlety of Sameness. Cambridge, MA: MIT Press.
French, R. M. (1997). When coffee cups are like old elephants or why representation modules don’t make
sense. In A. Riegler, M. Peschl, and A. Von Stein (Eds.), Proceedings of the International Conference
New Trends in Cognitive Science, pp. 158–163 Austrian Society for Cognitive Science.
French, R. M. (2002). The computational modeling of analogy-making. Trends in Cognitive Sciences, 6(5),
200–205.
Gentner, D. (1983). Structure-mapping: A theoretical framework for analogy. Cognitive Science, 7(2),
155–170.
Gentner, D., Holyoak, K., and Kokinov, B. (Eds.) (2001). The Analogical Mind: Perspectives from Cognitive
Science. Cambridge, MA: MIT Press.
Hall, R. (1989). Computational approaches to analogical reasoning: A comparative analysis. Artificial
Intelligence, 39, 39–120.
Hofstadter, D. R., and Mitchell, M. (1992). An overviewof the Copycatproject. In K. J.Holyoak and J. Barn-
den (Eds.), Connectionist Approaches to Analogy, Metaphor, and Case-Based Reasoning. Norwood,
NJ: Ablex.
Hofstadter, D. R. and the Fluid Analogies Research Group (1995). Fluid Concepts and Creative Analogies.
New York: Basic Books.
2-18 Handbook of Dynamic System Modeling
Hofstadter, D. R. (1984). The Copycat Project: An Experiment in Nondeterminism and Creative Analogies.
AI Memo No. 755, Massachusetts Institute of Technology, Cambridge, MA.
Holyoak, K., and Thagard, P. (1989). Analogical mapping by constraint satisfaction. Cognitive Science, 13,
295–355
Hummel, J., and Holyoak, K. (1997). Distributed representations of structure: A theory of analogical
access and mapping. Psychological Review, 104, 427–466.
James, W. (1890). The Principles of Psychology.NewYork:HenryHolt&Co.
Kirkpatrick, S., Gelatt Jr., C. D., and Vecchi, M. P. (1983). Optimization by simulated annealing. Science,
220, 671–680.
Kokinov, B. (1994). A hybrid model of analogical reasoning. In K. Holyoak and J. Barnden (Eds.), Advances
in Connectionist and Neural Computation Theory, Vol. 2, Analogical Connections. Norwood, NJ:
Ablex.
Kokinov, B. and French, R. M. (2003). Computational models of analogy-making. In L. Nadel (Ed.),
Macmillan Encyclopedia of Cognitive Science, vol. 1, pp. 113–118. London: Nature Publishing Group.
Lakoff, G. (1987). Women, Fire, and Dangerous Things: What Categories Reveal about the Mind. Chicago:
University of Chicago Press.
Marshall, J. (2002a). METACAT: http://www.cs.pomona.edu/∼marshall/metacat/
Marshall, J. (2002b). Metacat: A self-watching cognitive architecture for analogy-making. In W. D. Gray
and C. D. Schunn (Eds.), Proceedings of the 24th Annual Conference of the Cognitive Science Society,
pp. 631–636. Mahwah, NJ: Lawrence Erlbaum Associates.
McGraw, G. (1995) Letter Spirit (Part One): Emergent High-Level Perception of Letters Using Fluid
Concepts. Unpublished Ph.D. dissertation, Indiana University, Bloomington, IN. Available at:
http://www.cogsci.indiana.edu/farg/mcgrawg/thesis.html>.
Mitchell, M. and Hofstadter, D. R. (1990). The emergence of understanding in a computer model of
concepts and analogy-making. Physica D, 42, 322–334.
Mitchell, M. (1993). Analogy-Making as Perception: A Computer Model. Cambridge, MA: MIT Press.
Mitchell, M. (2001). Analogy-making as a complex adaptive system. In L. Segel and I. Cohen (Ed.),
Design Principles for the Immune System and Other Distributed Autonomous Systems, pp. 335–359.
New York: Oxford University Press.
Shepard, R. N. (1962). The analysis of proximities: Multidimensional scaling with an unknown distance
function. I. Psychometrika, 27, 125–140.

3
Impact of the Semantic
Web on Modeling and
Simulation
John A. Miller
University of Georgia
Congzhou He
University of Georgia
Julia I. Couto
University of Georgia
3.1 Introduction .................................................................... 3-1
3.2 Semantic Web: Relevant Issues ....................................... 3-2
3.3 Conceptual Basis for Discrete-Event Simulation ........... 3-4
3.4 Types of Mathematical Models ...................................... 3-6
Classification Based on State
•
Time-Based Classification
•
Causality-Based Classification
•
Classification
Based on Determinism
3.5 Adding Semantics to Simulation Models ....................... 3-10
3.6 Overview of DeSO .......................................................... 3-12
3.7 Overview of DeMO ......................................................... 3-14
3.8 Summary ......................................................................... 3-18
3.1 Introduction
During the mid-1990s, the World Wide Web began to substantially impact the use of computer technology.
This sparked the development of the field of Web-based simulation, which is still advancing today. This
chapter will examine how an ongoing major initiative involving the Web, the semantic Web, may further
impact modeling and simulation (M&S).
More specifically, this chapter considers the issue of using semantics in M&S. The impetus for this is
the large initiative to develop the next-generation Web, the semantic Web being developed by the artificial
intelligence (AI), database and information retrieval communities. A complimentary parallel track is
represented by the model-driven architecture (MDA) approach being developed by object management
group (OMG) and the software engineering community. The goal of this initiative is for all software
development to be model-driven.
Semantics (and the semantic Web) will likely impact the M&S community in two ways. First, the
community should develop ontology to delineate, define, and relate the concepts in the field. Ontology for
M&S should be logically connected to more general (or higher level) ontology, e.g., one for mathematics
such as Monet (Caprotti et al., 2004) or one for general knowledge upper ontology such as the suggested
upper merged ontology (SUMO) (Niles and Pease, 2001). Second, simulation models, model components,
and other artifacts should be provided with richer semantic descriptions. The least disruptive way to do
this is through annotation in which the artifacts refer to semantic models (e.g., a concept in ontology).
The fact that the semanticWeb is being developed and simulation artifactscan be semantically annotated,
begs the question of why do it. This question relates to the basic motivation for having the semantic Web and
its services. For the M&S community, semantics represented in ontology provides standard terminology to
the community and beyond, so that common understanding of concepts and relationships can be achieved,
3-1

3-2 Handbook of Dynamic System Modeling
which, in turn, increases the potential for application interoperability and reuse of simulation artifacts.
Semantic Web technology can also be used for the discovery of simulation components, composition of
simulation components, implementation assistance, verification, and automated testing.
To make the discussions in this chapter more directed, we will develop as we go a small ontology
for discrete-event simulation (DeSO). The purpose of this ontology is to provide a general conceptual
foundation for M&S. Every effort was made to keep the ontology from becoming convoluted. If concepts
were too complex to be defined in a straightforward way, they were left out. At this point, DeSO is a toy
example. Later, we plan to expand and merge it with the more developed discrete-event modeling ontology
(DeMO). DeMO is oriented toward discrete-event modeling techniques such as Markov chains, finite state
machines, Petri nets, and event graphs. We are making DeSO more general in the following ways:
1. Include concepts related to common methodologies for creating simulation models, e.g., those
built using simulation languages (or programming languages augmented with simulation libraries).
DeMO is more oriented toward formal modeling techniques (of course, that was a sensible place
to start since these are well defined, at least mathematically).
2. Take a first step to extend DeMO with concepts from combined continuous and discrete simulation,
without obscuring the discrete event concepts.
3. Include enough concepts to allow, say, a simulation engine to interact with an animation engine.
The animation engine would permit realistic (or at least interesting) rendering using 2D or 3D
graphics. Either engine (simulation or animation) could include software such as a physics engine
to enhance the realism of animation. This is part of the motivation for item 2, allowing, for example,
smooth continuous motion governed by Newton’s laws of motion.
Building such a large ontology is a daunting task, which needs guidance from well-established founda-
tional knowledge. In this work, we use the following foundational sources: modeling, simulation, systems
theory, physics, mathematics, and philosophy.
We endeavored to make our definitions as compatible as we could with existing definitions within
these fields. Many sources were used for this including Wikipedia (Wikipedia, 2006a), WordNet (Miller
et al., 1990), OpenMath (OpenMath, 2006), SUMO (Niles and Pease, 2001), Stanford Encyclopedia of
Philosophy (Zalta, 2006), AstroOnto (Shaya et al., 2006), Simulation reference markup language (SRML)
(Reichenthal, 2002), extensible modeling and simulation framework (XMSF) (Brutzman, 2004), and
discrete-event systems specification (DEVS, 2005) as well as textbooks and papers in a variety of fields (see
References).
Finding and defining the concepts is hard enough, but the subsequent step of determining a minimal set
of useful properties is even more difficult. More important to get right are the relationships between the
concepts. This is where much of the formal semantics comes in, since many of the concepts are defined in
natural (not formal) languages. Indeed, certain semantically primitive concepts are not formally definable.
The rest of this chapter is organized as follows. In Section 3.2, we overview developments in the semantic
Web relevant to creating and using ontology for M&S. Section 3.3 provides a conceptual framework suitable
for defining the top concepts for such ontology. This is followed, in Section 3.4, by high-level classifications
based on these main concepts. Techniques for adding semantics to simulation models are given in Section
3.5. A summary of DeSO is presented in Section 3.6. An overview of DeMO is given Section 3.7. Finally,
Section 3.8 summarizes the chapter.
3.2 Semantic Web: Relevant Issues
Ever since the article was published by Berners-Lee et al. (2001), in the Scientific American, there has been a
great deal of research and development on the semantic Web. Indeed, much of it is rooted in prior research
in knowledge representation,distributed AI, database systems, and information retrieval. A large portionof
the current Web consists of hypertext markup language (HTML) pages (either static or dynamic) intended
for humans to read. To make the Web more accessible by programs (or agents), the Web content needs to
Impact of the Semantic Web on Modeling and Simulation 3-3
be organized better, linking meaning with content. An obvious first step is to replace the formatting tags
of HTML, with ones that are related to content. This is the purpose of the extensible markup language
(XML) and its schema languages: data type definition (DTD) and XML schema definition (XSD). XML is
good for representing nested structures in documents, but is weak regarding named relationships.
The resource description framework (RDF) is useful for indicating that certain entities of interest are
discussed in a document and that these entities are related to other entities in this and other documents.
In this way, it permits logical connections within and between documents. Although, one might think that
hyperlinks in HTML or XLinks in XML documents play a similar role, from a program’s perspective these
are akin to untyped pointers. RDF provides a richer modeling language, and although RDF syntax can be
represented using XML, the underlying abstract models for the two languages are fundamentally different.
The abstract model for XML is tree based, while the model for RDF is graph based (Berners-Lee, 1998;
Johnston, 2005).
The above additions to the Web mainly provide it with better organization, which is key in making
the Web more useful to programs. The real goal of the semantic Web is to make the Web content more
understandable to programs. One approach is to use natural language processing and text understanding.
Long-term research efforts in these areas are beginning to bear fruit, and various algorithms have been
designed to process text at morphological, syntactic, semantic, and discoursal levels with reasonable accu-
racy (Mitkov, 2003). However, they are not the principal focus of current semantic Web research. As already
mentioned, the tags used by XML are more meaningful than the tags used by HTML (e.g., <h3>...</h3>
versus <address>...</address>. Whilecertainly true, this meaningfulness is mainly attributed to human
understanding, but what does it mean to a program? An initial step to make documents more understand-
able to a program is to lessen the program’s need to understand all of the documents individually. This can
be done by relying on a schema that applies to several documents of the same kind. If the program knows the
XSD for a group of documents,then it can more readily process the document. Furthermore, if theprogram
knows the RDF schema (RDFS) for this group, it can process relationships between entities in this group
of documents. This capability is particularly useful for semantic search (Sheth et al., 2005). Whereas, Web
search engines such as Yahoo and Google use keyword search and page ranking schemes, semantic search
follows meaningful links, and has the potential, in specific domains, to enhance precision and recall of doc-
uments as well as direct one to relevant portions of documents (Noronhaand Silva, 2004). (Precisionmeans
the fraction of retrieved documents that are relevant; recall means the fraction of relevant documents that
are retrieved.) Still, the depth of program understanding is rather shallow (useful, but shallow).
Deep understanding approaching human levels is such a long-term goal that something more interme-
diate is needed. For one thing, it would be better to give the tags used in XML documents more precise
definitions. A key aspect of the semantic Web is to provide standard (i.e., agreed upon) definitions of
terms or concepts in a variety of domains. A terminology defines a set of related terms, which may be
classified to form a taxonomy. When named relationships are added, it may be referred to as ontology.
Specifically, ontology concerns the classification of concepts (or classes) as well as their subclasses, proper-
ties, and relationships to other concepts. These defined concepts can also be used to annotate the content
of documents. Finally, instances of these concepts can be created by extracting content from Web pages.
Together the classes, properties, and instances form a knowledge base. The Web ontology language (OWL)
provides this capability for the semantic Web (OWL comes in three types: OWL-Lite, OWL-DL, where
DL stands for description logic, and OWL-Full). Other possible languages for modeling ontology include
the entity-relationship model (Chen, 1976), unified modeling language (UML) (Rumbaugh et al., 1998),
knowledge interchange format (Genesereth and Fikes, 1992), and resource description framework (Klyne
and Carroll, 2004).
Having introduced the term “knowledge base,” we should mention that typically they may also include
rules (or something equivalent). Indeed, the latest part of the semantic Web undergoing standardization
is the semantic Web rule language (SWRL). Rules allow new facts to be generated from existing facts
and relevant rules, thus greatly increasing the expressivity of the knowledge base. Unfortunately, as the
expressivity goes up, so does its complexity. Table 3.1 shows the current set of languages used in the semantic
Web, and includes the complexity class for basic inferencing operations such as subsumption. (We also

3-4 Handbook of Dynamic System Modeling
TABLE 3.1 Semantic Web Languages.
Acronym Language Schema Complexity of
XML Extensible Markup Language DTD, XSD, Relax NG –
RDF Resource Description Language RDFS PTIME
OWL-Lite Web Ontology Language OWL Schema Portion EXPTIME-Complete
OWL-DL Web Ontology Language OWL Schema Portion NEXPTIME-Complete
OWL-Full Web Ontology Language OWL Schema Portion Semi-decidable
SWRL Semantic Web Rule Language – Semi-decidable
note that the ontology definition metamodel (ODM) supporting UML which is under development by
OMG has a proposal to have a description logic core.)
A more general and deeper discussion of semantics and ontology as well as their relationship to the
semantic Web is given in the appendix. Although all the semantic Web languages are important, the OWL is
the most relevant to this chapter. We may use it to define and relate terms or concepts in the fields of M&S.
In the next section, we develop a conceptual foundation or basis for M&S. From this conceptualization,
we create an OWL. This ontology is broad, but currently shallow. This ontology also includes a few SWRL
rules. Later in this chapter, we overview DeMO, which is narrower and deeper.
3.3 Conceptual Basis for Discrete-Event Simulation
In this section, we develop a conceptual framework that is needed to clearly capture the foundational
concepts of discrete-event M&S. A secondary goal is to provide a very general framework for discrete-event
modeling, including combined discrete-continuous modeling. A tertiary goal is to keep this framework
as simple as possible. This last goal, may allow naivety to creep in, especially with regards to continuous
modeling. For example, with continuous modeling, energy-based modeling may work better than state-
based modeling (Cellier, 1991). Keep in mind that the main purpose of this framework is to create basic
ontological concepts for understanding the field of discrete-event simulation and modeling.
The model world begins as an empty void with space and time coordinates (Wikipedia, 2006b).
•
Time.Lett ∈T indicate a point in time. Typically, T would be a subset of real numbers R or
integers
Z.
•
Space.Letx ∈X indicate a point or location in a vector space X. For example, X could be the 3D
vector space
R
3
or something more abstract. Taken together, space and time may be viewed as a
space-time continuum (as in relativity theory). We, however, continue to treat time as a special
dimension in space-time. The void is then filled with objects, which are principally entities. Entities
are the things that exist in the model world. If entities do not interact, the entities that exist at
the start of simulation would simply move at a constant velocity (or remain at rest) forever. To
allow entities to interact, additional entities need to be introduced into the model world. These
agents may cause changes to entities such as entity creation, destruction, property updates, and
acceleration. Events are used to model changes that occur instantaneously (or nearly so). Forces are
used to model changes that occur smoothly over time.
•
Entity. An entity k is an object that exists in space-time. It is also uniquely identifiable. Examples of
entities include customers in banks, golf balls flying through the air, and even molecules in boiling
water. As the number of entities becomes very large, modeling techniques that deal withaggregations
of entities offer advantages. In many cases, the models will deal with properties of aggregations such
as pressure, temperature, or weight rather than the entities (or aggregate entities) themselves.
•
Event. An event is an object that does not exist in space-time, rather it exists only in the time
dimension. It has a creation time, but the important time is its occurrence time. When the event
occurs, it may affect other entities, trigger other events, or modify forces. For example, it may create
Impact of the Semantic Web on Modeling and Simulation 3-5
FIGURE 3.1 DeSO Visualization.
(or destroy/cancel) other events, increase (or decrease) forces, move entities, or change entity prop-
erties. An event is considered to occur instantaneously and therefore can produce discontinuities
in the trajectories of entities within space-time (see below and Figure 3.1). To relate the event to
space-time, we assume that it is associated with a particular main entity or agent. Finally, the event
must specify what action is to be performed. The action may be specified as algebraic equations,
difference equations, or in general using action logic (all of which may be implemented using a
programming or simulation language). The type of action determines the type of the event (e.g.,
an arrival event or a departure event). The complete set of event types is denoted by the set E.
•
Force. Complementary to events that have immediate effects, forces make changes over time. This
corresponds to the worldview provided by classical physics, e.g., as exemplified by Newton’s laws
of motion. Force laws are typically expressed as differential equations. A common force to use is
gravity, which in simulations/animations makes the motion of entities look more realistic.
•
State.Let{w(t)|t ≥0} be the process (e.g., a stochastic process) representing the evolution of the
model world over time. We would like to be able to stop the process at some time t
, and save the
minimal amount of information from the initial conditions w(t
0
) and the current world w(t
), so
that the process can be resumed without affecting any future results. How this is done and how the
dynamics are expressed in terms of this information largely defines the type of modeling technique
that is applied. We assume that the following are defined at the beginning of the world w(t
0
): the
range of time for the model world to exist, the space for entities in the model world to exist in, the
event action logic (for discrete changes), the forces (for continuous changes), and an initial event
(or events) to initiate the simulation.