Dougherty С. Introduction to Econometrics, 3Ed
Подождите немного. Документ загружается.

PROPERTIES OF THE REGRESSION COEFFICIENTS
5
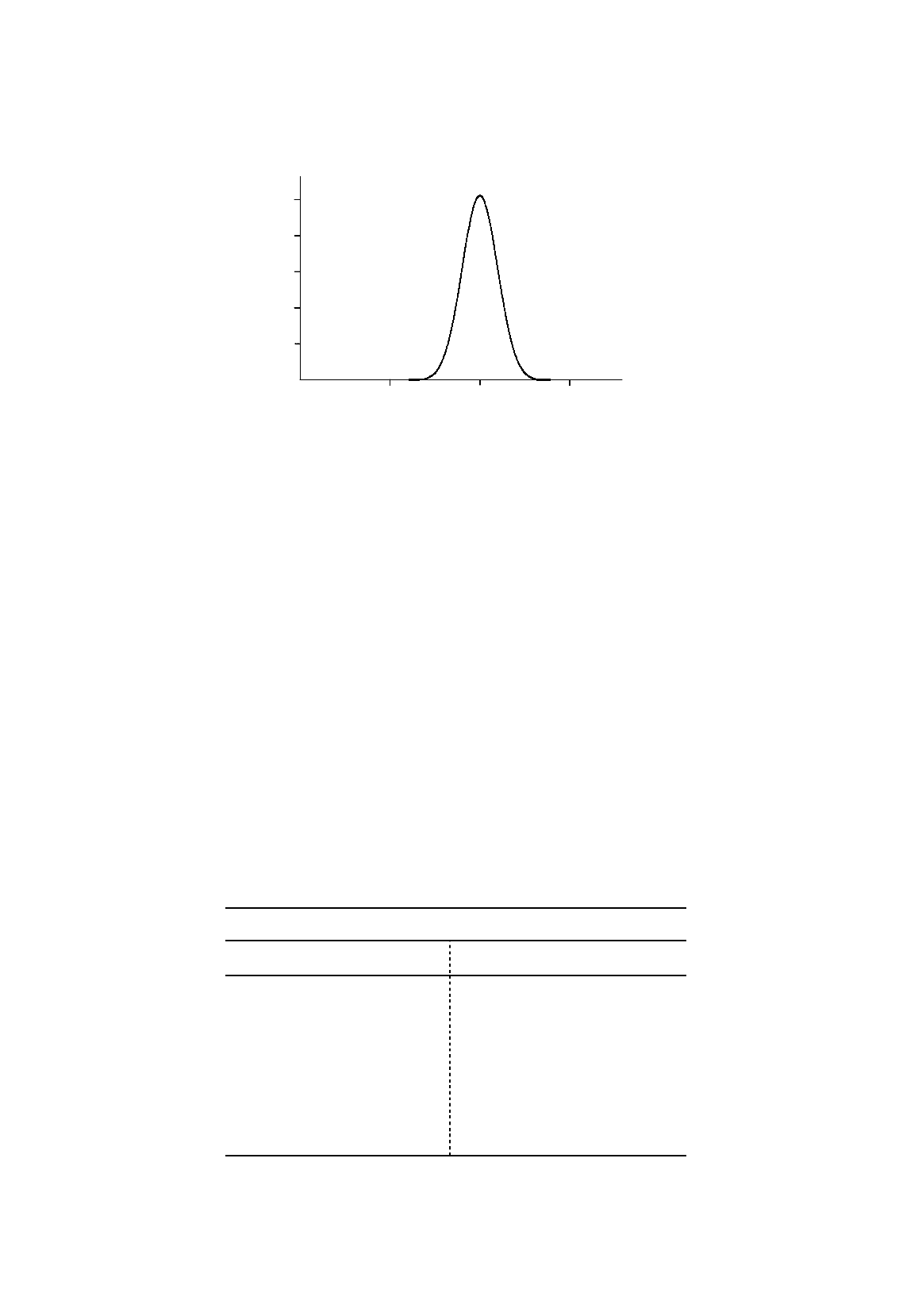
Figure 3.1.
Distribution of
b
2
in the Monte Carlo experiment
It has been asserted that the discrepancies between the regression coefficients and the true values
of the parameters are caused by the disturbance term u. A consequence of this is that the bigger is the
random element, the less accurate will be the estimate, in general.
This will be illustrated with a second set of Monte Carlo experiments related to the first. We shall
use the same values for
β
1
and
β
2
as before, and the same values of X, and the same source of random
numbers for the disturbance term, but we will now make the disturbance term in each observation,
which will be denoted u', equal to twice the random number drawn: u'
1
= 2rn
1
, u'
2
= 2rn
2
, etc. In fact,
we will use exactly the same sample of random numbers as before, but double them. Corresponding
to Table 3.1, we now have Table 3.3.
Regressing Y on X, we now obtain the equation
ii
XY 58.026.1
ˆ
+=
(3.10)
This is much less accurate than its counterpart, equation (3.8).
T
ABLE
3.3
X u Y X u Y
1 –1.18 1.32 11 3.18 10.68
2 –0.48 2.52 12 –1.84 6.16
3 –1.66 1.84 13 –1.42 7.08
4 0.06 3.94 14 –0.50 8.50
5 –0.76 3.74 15 3.38 12.88
6 –4.38 0.62 16 0.30 10.30
7 2.06 7.56 17 0.04 10.54
8 0.48 6.48 18 –0.22 10.78
9 5.06 11.56 19 –1.82 9.68
10 –0.26 6.74 20 2.84 14.84
probability density
function of
b
2
0.50 0.750.25
10
b
2
8
6
4
2
PROPERTIES OF THE REGRESSION COEFFICIENTS
6
T
ABLE
3.4
Sample b
1
b
2
1 1.26 0.58
2 3.05 0.45
3 2.26 0.39
4 2.28 0.50
5 1.42 0.61
6 1.61 0.52
7 1.44 0.63
8 4.37 0.33
9 0.52 0.65
10 1.88 0.55
Table 3.4 gives the results for all 10 experiments, putting
u
' = 2
rn
. We will call this set of
experiments II and the original set, summarized in Table 3.2, I. Comparing Tables 3.2 and 3.4, you
can see that the values of
b
1
and
b
2
are much more erratic in the latter, although there is still no
systematic tendency either to underestimate or to overestimate.
Detailed inspection reveals an important feature. In Set I, the value of
b
2
in sample 1 was 0.54, an
overestimate of 0.04. In Set II, the value of
b
2
in sample 1 was 0.58, an overestimate of 0.08. Exactly
twice as much as before. The same is true for each of the other nine samples, and also for the
regression coefficient
b
1
in each sample. Doubling the disturbance term in each observation causes a
doubling of the errors in the regression coefficients.
This result follows directly from the decomposition of
b
2
given by (3.6). In Set I the error
component of
b
2
is given by Cov(
X
,
u
)/Var(
X
). In Set II it is given by Cov(
X
,
u
')/Var(
X
), and
)(Var
),(Cov
2
)(Var
)2,(Cov
)(Var
)',(Cov
X
uX
X
uX
X
uX
==
(3.11)
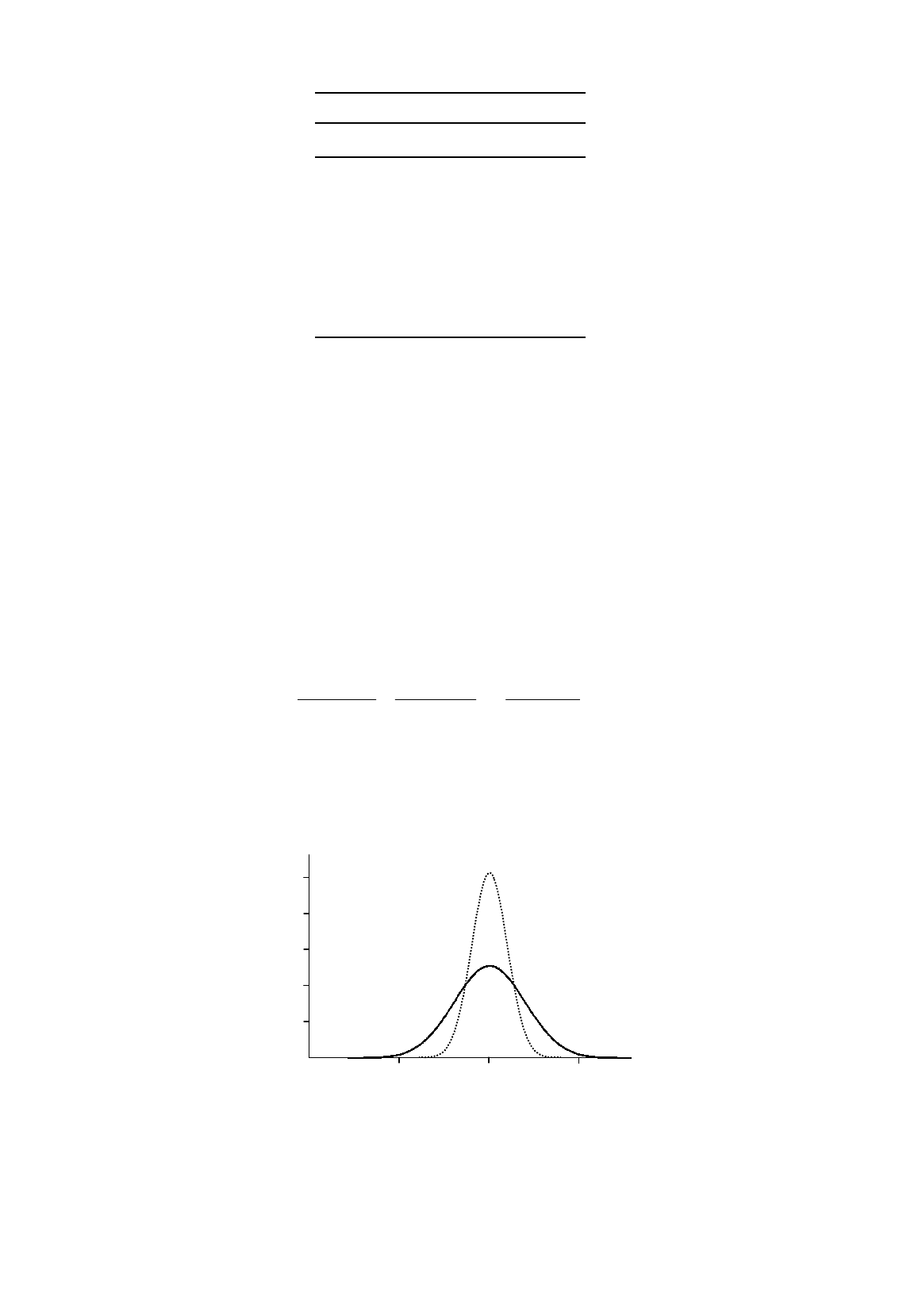
Figure 3.2.
Distribution of
b
2
when the standard deviation of
u
is doubled
probability density
function of
b
2
0.50 0.750.25
10
b
2
8
6
4
2

PROPERTIES OF THE REGRESSION COEFFICIENTS
7
The increase in inaccuracy is reflected in the probability density function for b
2
in Set II, shown as the
solid curve in Figure 3.2. This is still centered over the true value, 0.50, but, if you compare it with
that for Set I, the dotted curve, you will see that it is flatter and wider. Doubling the values of u has
caused a doubling of the standard deviation of the distribution.
3.3 Assumptions Concerning the Disturbance Term
It is thus obvious that the properties of the regression coefficients depend critically on the properties of
the disturbance term. Indeed the latter has to satisfy four conditions, known as the Gauss–Markov
conditions, if ordinary least squares regression analysis is to give the best possible results. If they are
not satisfied, the user should be aware of the fact. If remedial action is possible, he or she should be
capable of taking it. If it is not possible, he or she should be able to judge how seriously the results
may have been affected. We shall list the conditions one by one, explaining briefly why they are
important. The last three will be treated in detail in later chapters.
Gauss–Markov Condition 1: E(u
i
) = 0 for All Observations
The first condition is that the expected value of the disturbance term in any observation should be 0.
Sometimes it will be positive, sometimes negative, but it should not have a systematic tendency in
either direction.
Actually, if an intercept is included in the regression equation, it is usually reasonable to assume
that this condition is satisfied automatically since the role of the intercept is to pick up any systematic
but constant tendency in Y not accounted for by the explanatory variables included in the regression
equation.
Gauss–Markov Condition 2: Population Variance of u
i
Constant for All Observations
The second condition is that the population variance of the disturbance term should be constant for all
observations. Sometimes the disturbance term will be greater, sometimes smaller, but there should not
be any a priori reason for it to be more erratic in some observations than in others. The constant is
usually denoted
2
u
σ
, often abbreviated to
σ
2
, and the condition is written
2
i
u
σ
=
2
u
σ
for all i (3.12)
Since E(u
i
) is 0, the population variance of u
i
is equal to E(
2
i
u ), so the condition can also be written
22
)(
ui
uE
σ
=
for all i (3.13)
u
σ
, of course, is unknown. One of the tasks of regression analysis is to estimate the standard
deviation of the disturbance term.

PROPERTIES OF THE REGRESSION COEFFICIENTS
8
If this condition is not satisfied, the OLS regression coefficients will be inefficient, and you
should be able to to obtain more reliable results by using a modification of the regression technique.
This will be discussed in Chapter 8.
Gauss–Markov Condition 3: u
i
Distributed Independently of u
j
(i
≠
j)
This condition states that there should be no systematic association between the values of the
disturbance term in any two observations. For example, just because the disturbance term is large and
positive in one observation, there should be no tendency for it to be large and positive in the next (or
large and negative, for that matter, or small and positive, or small and negative). The values of the
disturbance term should be absolutely independent of one another.
The condition implies that
ji
uu
σ
, the population covariance between
u
i
and
u
j
, is 0, because
ji
uu
σ
=
E
[(
u
i
–
µ
u
)(
u
j
–
µ
u
)] =
E
(
u
i
u
j
)
=
E
(
u
i
)
E
(
u
j
) = 0 (3.14)
(Note that the population means of
u
i
and
u
j
are 0, by virtue of the first Gauss–Markov condition, and
that
E
(
u
i
u
j
) can be decomposed as
E
(
u
i
)
E
(
u
j
) if
u
i
and
u
j
are generated independently – see the Review
chapter.)
If this condition is not satisfied, OLS will again give inefficient estimates. Chapter 13 discusses
the problems that arise and ways of getting around them.
Gauss–Markov Condition 4: u Distributed Independently of the Explanatory Variables
The final condition comes in two versions, weak and strong. The strong version is that the
explanatory variables should be nonstochastic, that is, not have random components. This is actually
very unrealistic for economic variables and we will eventually switch to the weak version of the
condition, where the explanatory variables are allowed to have random components provided that they
are distributed independently of the disturbance term. However, for the time being we will use the
strong version because it simplifies the analysis of the properties of the estimators.
It is not easy to think of truly nonstochastic variables, other than time, so the following example
is a little artificial. Suppose that we are relating earnings to schooling,
S
, in terms of highest grade
completed.
Suppose that we know from the national census that 1 percent of the population have
S
= 8,
3 percent have
S
= 9, 5 percent have
S
= 10, 7 percent have
S
= 11, 43 percent have
S
= 12 (graduation
from high school), and so on. Suppose that we have decided to undertake a survey with sample size
1,000 and we want the sample to match the population as far as possible. We might then select what is
known as a stratified random sample, designed so that it includes 10 individuals with
S
= 8, 30
individuals with
S
= 9, and so on. The values of
S
in the sample would then be predetermined and
therefore nonstochastic. Schooling and other demographic variables in large surveys drawn in such a
way as to be representative of the population as a whole, like the National Longitudinal Survey of
Youth, probably approximate this condition quite well.
If this condition is satisfied, it follows that
ii
uX
σ
, the population covariance between the
explanatory variable and the disturbance term is 0. Since
E
(
u
i
) is 0, and the term involving
X
is

PROPERTIES OF THE REGRESSION COEFFICIENTS
9
nonstochastic,
ii
uX
σ
=
E
[{
X
i
–
E
(
X
i
)}{
u
i
–
µ
u
}]
=
(
X
i
–
X
i
)
E
(
u
i
) = 0 (3.15)
Chapters 9 and 10 discuss two important cases in which this condition is unlikely to be satisfied, and
the consequences.
The Normality Assumption
In addition to the Gauss–Markov conditions, one usually assumes that the disturbance term is
normally distributed. You should know all about the normal distribution from your introductory
statistics course. The reason is that if
u
is normally distributed, so will be the regression coefficients,
and this will be useful to us later in the chapter when we come to the business of performing tests of
hypotheses and constructing confidence intervals for
β
1
and
β
2
using the regression results.
The justification for the assumption depends on the Central Limit Theorem. In essence, this states
that, if a random variable is the composite result of the effects of a large number of other random
variables, it will have an approximately normal distribution even if its components do not, provided that
none of them is dominant. The disturbance term
u
is composed of a number of factors not appearing
explicitly in the regression equation so, even if we know nothing about the distribution of these factors (or
even their identity), we are entitled to assume that they are normally distributed.
3.4 Unbiasedness of the Regression Coefficients
From (3.6) we can show that
b
2
must be an unbiased estimator of
β
2
if the fourth Gauss–Markov
condition is satisfied:
+=
+=
)(Var
),(Cov
)(Var
),(Cov
)(
222
X
uX
E
X
uX
EbE
β
β
(3.16)
since
β
2
is a constant. If we adopt the strong version of the fourth Gauss–Markov condition and
assume that
X
is nonrandom, we may also take Var(
X
) as a given constant, and so
[]
),(Cov
)(Var
1
)(
22
uXE
X
bE
+=
β
(3.17)
We will demonstrate that
E
[Cov(
X
,
u
)] is 0:

PROPERTIES OF THE REGRESSION COEFFICIENTS
10
[]
[][]
()
[]
0)()(
1
))((
1
))((...))((
1
))((
1
),(Cov
1
1
11
1
=−−=
−−=
−−++−−=
−−=
∑
∑
∑
=
=
=
n
i
ii
n
i
ii
nn
n
i
ii
uuEXX
n
uuXXE
n
uuXXEuuXXE
n
uuXX
n
EuXE
(3.18)
In the second line, the second expected value rule has been used to bring (1/
n
) out of the expression as
a common factor, and the first rule has been used to break up the expectation of the sum into the sum
of the expectations. In the third line, the term involving
X
has been brought out because
X
is
nonstochastic. By virtue of the first Gauss–Markov condition,
E
(
u
i
) is 0 , and hence
E
(
u
) is also 0.
Therefore
E
[Cov(
X
,
u
)] is 0 and
E
(
b
2
) =
β
2
(3.19)
In other words,
b
2
is an unbiased estimator of
β
2
. We can obtain the same result with the weak version
of the fourth Gauss–Markov condition (allowing
X
to have a random component but assuming that it is
distributed independently of
u
); this is demonstrated in Chapter 9.
Unless the random factor in the
n
observations happens to cancel out exactly, which can happen
only by coincidence,
b
2
will be different from
β
2
for any given sample, but in view of (3.19) there will
be no systematic tendency for it to be either higher or lower. The same is true for the regression
coefficient
b
1
. Using equation (2.31),
XbYb
21
−=
(3.20)
Hence
)()()(
21
bEXYEbE
−=
(3.21)
Since
Y
i
is determined by
Y
i
=
β
1
+
β
2
X
i
+
u
i
(3.22)
we have
E
(
Y
i
)=
β
1
+
β
2
X
i
+
E
(
u
i
)
=
β
1
+
β
2
X
i
(3.23)
because
E
(
u
i
) is 0 if the first Gauss–Markov condition is satisfied. Hence
XYE
21
)(
β
β
+=
(3.24)
Substituting this into (3.21), and using the result that
E
(
b
2
) =
β
2
,

PROPERTIES OF THE REGRESSION COEFFICIENTS
11
12211
)()(
β
β
β
β
=−+=
XXbE
(3.25)
Thus
b
1
is an unbiased estimator of
β
1
provided that the Gauss–Markov conditions 1 and 4 are
satisfied. Of course in any given sample the random factor will cause
b
1
to differ from
β
1
.
3.5 Precision of the Regression Coefficients
Now we shall consider
2
1
b
σ
and
2
2
b
σ
, the population variances of
b
1
and
b
2
about their population
means. These are given by the following expressions (proofs for equivalent expressions can be found
in Thomas, 1983, Section 8.3.3):
+=
)(Var
1
2
2
2
1
X
X
n
u
b
σ
σ
and
)(Var
2
2
2
Xn
u
b
σ
σ
=
(3.26)
Equation (3.26) has three obvious implications. First, the variances of both
b
1
and
b
2
are directly
inversely proportional to the number of observations in the sample. This makes good sense. The
more information you have, the more accurate your estimates are likely to be.
Second, the variances are proportional to the variance of the disturbance term. The bigger the
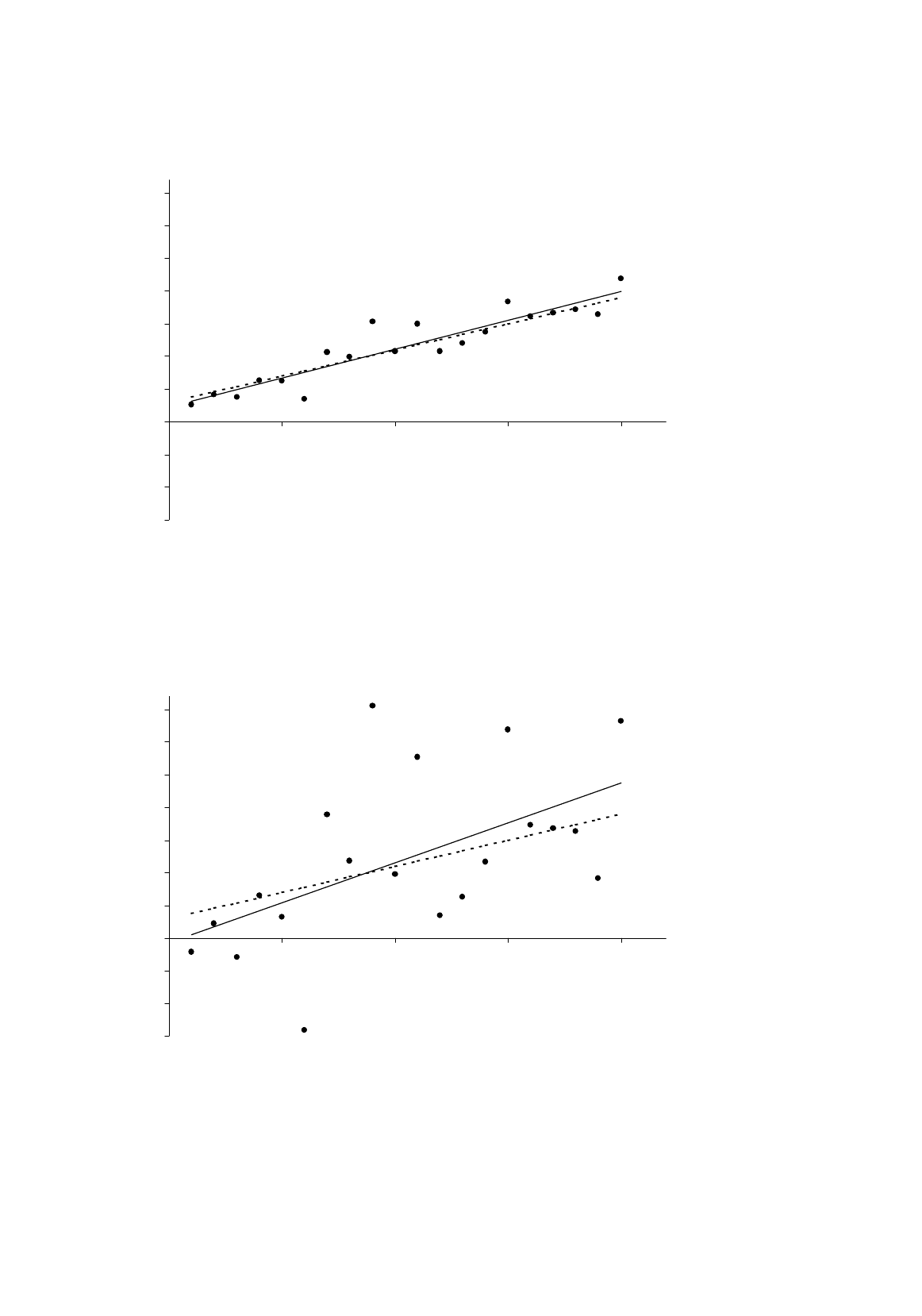
variance of the random factor in the relationship, the worse the estimates of the parameters are likely
to be, other things being equal. This is illustrated graphically in Figures 3.3a and 3.3b. In both
diagrams the nonstochastic component of the relationship between
Y
and
X
, depicted by the dotted
line, is given by
Y
i
= 3.0 + 0.8
X
i
(3.27)
There are 20 observations, with the values of
X
being the integers from 1 to 20. The same random
numbers are used to generate the values of the disturbance term, but those in the Figure 3.3b have been
multiplied by a factor of 5. As a consequence the regression line, depicted by the solid line, is a much
poorer approximation to the nonstochastic relationship in Figure 3.3b than in Figure 3.3a.
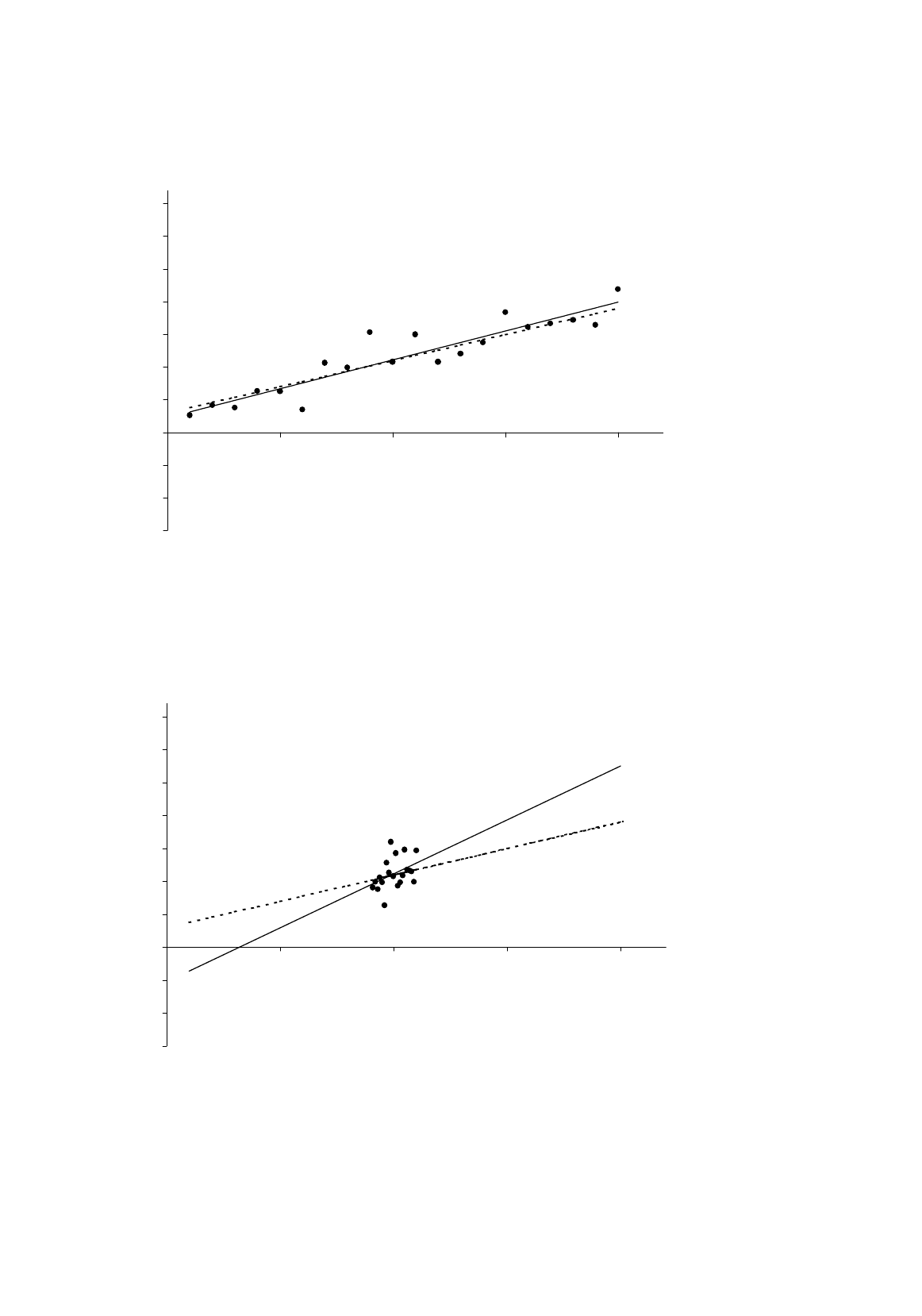
Third, the variance of the regression coefficients is inversely related to the variance of
X
. What is
the reason for this? Remember that (1) the regression coefficients are calculated on the assumption
that the observed variations in
Y
are due to variations in
X
, but (2) they are in reality
partly
due to
variations in
X
and
partly
to variations in
u
. The smaller the variance of
X
, the greater is likely to be
the relative influence of the random factor in determining the variations in
Y
and the more likely is
regression analysis give inaccurate estimates. This is illustrated by Figures 3.4a and 3.4b. The
nonstochastic component of the relationship is given by (3.27), and the disturbance terms are identical.
In Figure 3.4a the values of
X
are the integers from 1 to 20. In Figure 3.4b, the values of
X
are the
numbers 9.1, 9.2, ..., 10.9, 11. In Figure 3.4a, the variance in
X
is responsible for most of the variance
in
Y
and the relationship between the two variables can be determined relatively accurately. However,
in Figure 3.4b, the variance of
X
is so small that it is overwhelmed by the effect of the variance of
u
.
As a consequence its effect is difficult to pick out and the estimates of the regression coefficients will
PROPERTIES OF THE REGRESSION COEFFICIENTS
12
Figure 3.3a.
Disturbance term with relatively small variance
Figure 3.3b.
Disturbance term with relatively large variance
-15
-10
-5
0
5
10
15
20
25
30
35
0 5 10 15 20
Y
X
regression line
nonstochastic
relationship
-15
-10
-5
0
5
10
15
20
25
30
35
0 5 10 15 20
Y
X
nonstochastic
relationship
regression line
PROPERTIES OF THE REGRESSION COEFFICIENTS
13
Figure 3.4a.
X
with relatively large variance
Figure 3.4b.
X
with relatively small variance
-15
-10
-5
0
5
10
15
20
25
30
35
0 5 10 15 20
X
Y
regression line
nonstochastic
relationship
-15
-10
-5
0
5
10
15
20
25
30
35
0 5 10 15 20
Y
X
regression line
nonstochastic
relationship

PROPERTIES OF THE REGRESSION COEFFICIENTS
14
be relatively inaccurate.
Of course, Figures 3.3 and 3.4 make the same point in different ways. As can be seen from
(3.26), it is the relative size of
2
u
σ
and Var(X) that is important, rather than the actual size of either.
In practice, one cannot calculate the population variances of either b
1
or b
2
because
2
u
σ
is
unknown. However, we can derive an estimator of
2
u
σ
from the residuals. Clearly the scatter of the
residuals around the regression line will reflect the unseen scatter of u about the line Y
i
=
β
1
+
β
2
X
i
,
although in general the residual and the value of the disturbance term in any given observation are not
equal to one another. Hence the sample variance of the residuals, Var(e), which we can measure, will
be a guide to
2
u
σ
, which we cannot.
Before going any further, ask yourself the following question. Which line is likely to be closer to
the points representing the sample of observations on X and Y, the true line Y
i
=
β
1
+
β
2
X
i
or the
regression line
i
Y
ˆ
= b
1
+ b
2
X
i
? The answer is the regression line, because by definition it is drawn in
such a way as to minimize the sum of the squares of the distances between it and the observations.
Hence the spread of the residuals will tend to be smaller than the spread of the values of u, and Var(e)
will tend to underestimate
2
u
σ
. Indeed, it can be shown that the expected value of Var(e), when there
is just one explanatory variable, is [(n – 2)/n]
2
u
σ
. However, it follows that, if one defines
2
u
s by
)(Var
2
2
e
n
n
s
u
−
=
(3.28)
2
u
s will be an unbiased estimator of
2
u
σ
(for a proof, see Thomas).
Using (3.26) and (3.28), one can obtain estimates of the population variances of b
1
and b
2
and, by
taking square roots, estimates of their standard deviations. Rather than talk about the “estimate of the
standard deviation of the probability density function” of a regression coefficient, which is a bit
cumbersome, one uses the term “standard error” of a regression coefficient, which in this text will
frequently be abbreviated to s.e. For simple regression analysis, therefore, one has
s.e.(b
1
) =
+
)(Var
1
2
2
X
X
n
s
u
and s.e.(b
2
) =
)(Var
2
Xn
s
u
(3.29)
The standard errors of the regressions coefficient will automatically be calculated for you as part of the
computer output.
These relationships will be illustrated with the Monte Carlo experiment described in Section 3.2.
In Set I, u was determined by random numbers drawn from a population with 0 mean and unit
variance, so
2
u
σ
= 1. X was the set of numbers from 1 to 20, and one can easily calculate Var(X),
which is 33.25. Hence
2158.0
25.33
5.10
1
20
1
2
2
1
=
+=
b
σ
, (3.30)
and