Desurvire E. Classical and Quantum Information Theory: An Introduction for the Telecom Scientist
Подождите немного. Документ загружается.


7.4 Kolmogorov complexity 117
For instance, n = 11, or 1011 in binary, is encoded as m = 1100111101. This is not a
minimal-length code (as compression algorithms exist), but it surely defines n.Wesee
that this code length is 2 log n + 2 = 2logl(x) + 2. The basic program that describes x
and that can tell the TM to halt after outputting n bits is the same as that which prints x bit
by bit (q
0
), but with an additional instruction giving the value of n. Based on Eq. (7.14)
and the above result, the length of such a program is, therefore,
|
q
0
(x)
|
= K [x
|
l(x)] +
c +2logl(x) +2 ≈ K [x
|
l(x)] + 2logl(x) + c for sufficiently long sequences. But
as we know, if x can be described by some algorithm, the corresponding program
length is such that
|
q(x)
|
≤
|
q
0
(x)
|
, meaning that the complexity of x has the upper
bound
K (x) ≤ K [x
|
l(x)] + 2logl(x) + c. (7.15)
We have established that the complexity K (x) of any string x has an upper bound defined
by either Eq. (7.14)orEq.(7.15).
The knowledge of an upper bound for complexity is a valuable piece of information,
but it does not tell us in general how to measure it. An important and most puzzling
theorem of algorithmic information theory is that complexity cannot be computed.This
theorem can be stated as follows:
There exists no known algorithm or formula that, given any sequence x, a Turing machine can
output K (x).
This leads one to conclude that the problem of determining the Kolmogorov complexity
of any x is undecidable! The proof of this surprising theorem turns out to be relatively
simple,
19
as shown below.
Assume that a program q exists such that a UTM can output the result U [q(x)] = K (x)
for any x. We can then make up a simple program which, given x, could find at least
one string having at least the same complexity as x, which we call K (x) ≡ K. Such a
program r is algorithmically defined as follows:
Input K ,
Fo r n = 1toinfinity,
Define all strings s of length n,
If K (s) ≥ K print s then halt,
Continue.
This program has a length
|
r
|
=
|
q
|
+ 2logl(K ) + c. Since the program length grows
as the logarithm of K , there exists a value K for which
|
r(K )
|
< K . The program
eventually outputs a string s of complexity K (s) ≥ K >
|
r
|
, which is strictly greater
than the program size! By definition, the complexity K (s)ofs is its minimum descriptive
length. By definition, however, there is no TM program that can output s with a length
shorter that K (s). Therefore, the hypothetical program q, which computes K (x)given
x, simply cannot exist. Complexity cannot be computed by Turing machines (or, for that
matter, by any computing machine).
19
As adapted from http://en.wikipedia.org/wiki/Kolmogorov_complexity.

118 Algorithmic entropy and Kolmogorov complexity
∅
1, 0
00, 01, 10, 11
1
2
4
k
=
n
(
k
)
=
0
211
…, 1010111…, …
2
K
−1
…
…
…
K
Figure 7.3 Enumeration of bit strings of size k = 0tok = K − 1.
While complexity cannot be computed, we can show that it is at least possible to
achieve the following:
(a) Given a complexity K , to tell how many strings x have a complexity less than K ,
i.e., satisfying K (x) < K ;
(b) For a string of given length n, to define the upper bound of its complexity, namely,
to find an analytical formula for the upper bound of K [x
|
l(x)] in Eq. (7.15).
To prove the first statement, (a), is a matter of finding how many strings x have a
complexity below a given value K , i.e., satisfying K (x) < K . This can be proven by
the following enumeration argument. Figure 7.3 shows the count of all possible binary
strings of length k,fromk = 0 (empty string) to k = K − 1. The sum of all possibilities
illustrated in the figure yields
K −1
k=0
n(k) =
K −1
k=0
2
k
=
1 − 2
K
1 − 2
= 2
K
− 1 < 2
K
. (7.16)
Each of these possible strings represents a TM program, to which a unique output x
corresponds. There are fewer than 2
K
programs smaller than K , therefore there exists
fewer than 2
K
strings of complexity < K .
The statement in (b) can be proven as follows. Given any binary string x of length n,we
must find the minimal-length program q that outputs it. Assume first that the string has k
bits of value 1, thus n − k bits of value 0, with 0 < k < n. We can then create a catalog of
all possible strings containing k 1s, and index them in some arbitrary order. For instance,
with n = 4 and k = 2, we have x
1
= 1100, x
2
= 1010, x
3
= 1001, x
4
= 0101, x
5
=
0011, x
6
= 0110. Having this catalog, we can simply define any string x
i
according to
some index i.Givenn and k, the range of index values i is C
k
n
= n!/[k!(n − k)!], which
represents the number of ways to assign k 1s into n bit positions. The program q defining
x must contain information on both k and i . As we have seen, it takes 2 log k + 2 bits
to define k by repeating its bits, with a two-bit delimiter at the end (noting that fancier
compression algorithms of shorter lengths also exist). The second number i can be
defined after the delimiter, but without repeating bits, which occupies a size of log C
k
n
bits. We must also include a generic program, which, given k, generates the catalog.
Assume that its length is c, which is independent of k. The total length of the program
q is, therefore,
|
q(k, n)
|
= 2logk + 2 +log C
k
n
+ c ≡ 2logk + log C
k
n
+ c
. (7.17)

7.4 Kolmogorov complexity 119
The next task is to evaluate log C
k
n
. Using Stirling’s formula,
20
it is possible to show that
for sufficiently large n:
21
log C
k
n
≈ log
1
√
2π
+ nf
k
n
, (7.18)
where the function f is defined by f (u) =−u log u − (1 −u)log(1− u), and, as usual,
all logarithms are in base 2. The function f (k/n) is defined over the interval 0 < k/n <
1. To include the special case where all bits are identical (k/n = 0ork/n = 1) we can
elongate the function by setting f (0) = f (1) = 0, which represents the analytical limit
of f (y) for real y. We note that f (u) is the same function as defined in Eq. (4.14)for
the entropy of two complementary events. Its graph is plotted in Fig. 4.7, showing a
maximum of f (1/2) = 1foru = 1/2.
Substituting Eq. (7.18) into Eq. (7.17), we, thus, obtain:
|
q(k, n)
|
≈ 2logk + nf
k
n
+ c
, (7.19)
where c
is a constant. Consistently, this program length represents an upper bound to
the complexity of string x with k 1s, i.e.,
K (x
|
k
ones
) ≤ 2logk + nf
k
n
+ c
. (7.20)
In the general case, a string x of length n can have any number k of 1 bits, with 0 <
k/n < 1. We first observe that the integer k is defined by the sum of the a
j
bits forming
the string, namely, if x = a
n
a
n−1
...a
2
a
1
(a
j
= 0or1)wehavek =
n
j=1
a
j
. Second,
we observe that since k < n we have log k < log n. Based on these two observations,
the general approximation formula giving the upper bound for the complexity K (x
|
n )
of any binary string of length n defined by x = a
n
a
n−1
...a
2
a
1
(a
j
= 0or1),is:
K (x
|
n ) ≤ 2logn + nf
1
n
n
j=1
a
j
+ c
. (7.21)
To recall, Eq. (7.21) represents the Stirling approximation of the exact definition:
K (x
|
n ) ≤ 2logn + log C
k
n
+ c. (7.22)
20
See Eq. (A9)inAppendix A.
21
Applying Stirling’s formula yields, after some algebra:
C
k
n
≈
1
√
2π
exp
n
1 +
1
2n
ln(n) −
k
n
+
1
2n
ln(k) −
1 −
k
n
+
1
2n
ln
n
1 −
k
n
%
.
In the limit n 1, and after regrouping the terms, the formula reduces to:
C
k
n
≈
1
√
2π
exp
n
−
k
n
ln
k
n
−
1 −
k
n
ln
1 −
k
n
%
=
1
√
2π
2
nf(k/n)
,
where
f (u) =−u
ln u
ln 2
− (1 −u)
ln u
ln 2
(1 −u) ≡−u log
2
u − (1 −u)log
2
(1 −u).

120 Algorithmic entropy and Kolmogorov complexity
0
2
4
6
8
10
12
0 10 20 30 40 50 60 70 80 90 100 110 120 130
String
x
Complexity
n
= 2
n
= 3
n
= 4
n
= 5
n
= 7
n
= 6
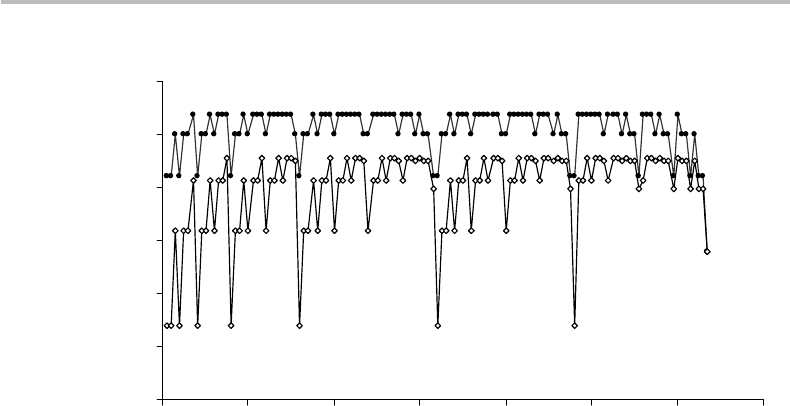
Figure 7.4 Upper bound of conditional complexity K (x
|
n ) for each binary string x of exactly n
bits (n = 2ton = 7), as defined by Eq. (7.21) with the Stirling approximation (open symbols),
and as defined by Eq. (7.22) without approximation (dark symbols). In each series of size n,the
strings x are ordered according to their equivalent decimal value.
Figure 7.4 shows plots of the upper bound of K (x
|
n ) for each binary string of exactly n
bits, according to (a) the Stirling approximation in Eq. (7.21) with c
= log(1/
√
2π) + c
(taking c = 0), and (b) the corresponding exact definition in Eq. (7.22), also taking c = 0.
For each series of length n, the strings x are ordered according to their equivalent decimal
value (e.g., x = 11 corresponds to x = 1011 in the series n = 4, x = 01011 in the series
n = 5, x = 001011 in the series n = 6, etc.).
We first observe from the figure that the upper bound of K (x
|
n ) oscillates between
different values. For even bit sequences (n even), the absolute minima are obtained
for f (u) = 0orC
k
n
= 1, and correspond to the cases where all bits are identical. The
absolute maxima are obtained for f (u) = 1orC
k
n
= 0.5, which corresponds to the cases
where there is an equal number of 0 and 1 bits in the string. For odd bit sequences (n
odd), the conclusions are similar with all bits identical but one (minima) or with an
approximately equal number of 0 and 1 bits in the string.
Second, we observe that the approximated definition (Eq. (7.21)) and the exact defini-
tion (Eq. (7.22)) provide nearly similar results. It is expected that the difference rapidly
vanishes for string lengths n sufficiently large.
Third, we observe that the complexity is generally greater than the string length
n, which appears to be in contradiction with the result obtained in Eq. (7.14), i.e.,
K [x
|
l(x) = n ] ≤ n + c. Such a contradiction is lifted if we rewrite Eq. (7.21)inthe
form:
K (x
|
n ) ≤ n
2logn
n
+ f
k
n
+
c
n
(7.23)
7.4 Kolmogorov complexity 121
0
2
4
6
8
10
12
0 20406080100120140
String
x
Complexity
Figure 7.5 Upper bound of conditional complexity for each binary strings x of length n = 7:
K (x
|
n ), as defined by Eq. (7.22) (dark symbols) and K (x
|
n, k ), as defined by Eq. (7.24) (open
symbols) with k being the number of 1s in the string.
and take the limit for large n, which gives K (x
|
n ) ≤ nf(k/n) ≤ n = l(x). The upper
bound n = l(x) stems from the fact that f (u) varies from zero to unity. It is a maximum
for u = k/n = 0.5, which corresponds to the case where there is an equal number of 0
or 1 bits in the string. In the case where the number of 1 bits in the string is known, we
have also established from the above that
K (x
|
n, k
ones
) ≤ 2logk + log C
k
n
+ c. (7.24)
It is exactly the same result as in Eq. (7.22) with log n replaced by log k (k ≥ 1). Since
k ≤ n, the upper bound of K (x
|
n, k
ones
) is, therefore, lower than that of K (x
|
n ). The
comparison between the two definitions is shown in Fig. 7.5 for n = 7. We observe from
the figure that K (x
|
n, k
ones
) has a finer structure than K (x
|
n ) as we scan the string
catalog from x = 0000000 to x = 1111111, which reflects the periodic changes in the
number of 1 bits within each of the strings.
Consider next the following problem: given two strings x and y, what is the size of
the smallest program that can output both x and y simultaneously?
A first possibility is that x and y are algorithmically independent, i.e., there is no
algorithm q that is capable of computing both x and y.Letq
x
and q
y
(q
x
= q
y
)be
the two programs describing x and y, respectively, from the same universal Turing
machine U (i.e., U[q
x
] = x, U [q
y
] = y). We can then chain the two programs to form
q
xy
= q
x
q
y
, a program that computes x then y. There is no need for any additional
instruction to the machine. Therefore, the program length is simply |q
xy
|=|q
x
|+|q
y
|.
The minimal length of such a program is:
K (x, y) = min
U
|q
xy
|=min
U
|q
x
|+min
U
|q
y
|≡K (x) + K (y), (7.25)

122 Algorithmic entropy and Kolmogorov complexity
which shows that if two strings are algorithmically independent their joint complexity
K (x, y) is given by the sum of their individual complexities. It is clear that K (x, y) =
K (y, x). What if x and y are not algorithmically independent? This means that the
computation of x provides some clue as to the computation of y. A program calculating
y could be q
y
= q
x
q
y
|
x
. The machine U first computes x then uses the program q
y
|
x
to
compute y.
Next, we shall define the conditional complexity K (y
|
q
x
) , which represents the
minimal size of a program describing y given the program describing x. It is also noted
K (y
|
x∗), with x∗=q
x
, or, for simplicity, K (y
|
x ). This last notation should be used
with the awareness that
|
x is a condition on the program q
x
, not on the string x.
The issue of finding the minimal size of q
y
= q
x
q
y
|
x
is far from trivial. Chaitin
showed
22
that
K (x, y) ≤ K (x) + K (y
|
x ) +c
↔ (7.26)
K (y
|
x ) = K (x, y) − K (x) +c
,
where c represents a small overhead constant, which is one bit for sufficiently long
strings. The second inequality stems from the first, with c
≥ 0 being a nonnegative
constant.
23
Since the joint complexity K (x, y) is symmetrical in the arguments x, y,we
also have
K (x
|
y ) = K (x, y) − K (y) +c
. (7.27)
If x and y are algorithmically independent, it is clear that q
y|x
= q
y
(there is no clue
from x to compute y), or equivalently K (y
|
x ) = K (y), and likewise, K (x
|
y ) = K (x).
In this case, K (x, y) = K (x) + K (y) +c
.
We can now define the mutual complexity K (x; y)ofx and y (note the delimiter “;”)
according to either of the following:
K (x; y) = K (x) + K (y) − K (x, y)
K (x; y) = K (x) − K (x
|
y ) +c
K (x; y) = K (y) − K (y
|
x ) +c
,
(7.28)
where c
is a nonnegative constant. In Eq. (7.28), the last two definitions stem from the
first one and the properties in Eqs. (7.26) and (7.27).
The above results represent various relations of algorithmic complexity between two
strings x, y. We immediately note that such relations bear a striking resemblance with
that concerning the joint or conditional entropies and mutual information of two random-
event sources X, Y according to classical IT.
22
See: G. J. Chaitin, A theory of program size formally identical to information theory. JACM, 22 (1975), 329–
40, www.cs.auckland.ac.nz/CDMTCS/chaitin/acm75.pdf. See also: G. J. Chaitin, Algorithmic information
theory. IBM J. Res. Dev., 21 (1977), 350–9, 496, www.cs.auckland.ac.nz/CDMTCS/chaitin/ibm.pdf.
23
From the first definition in Eq. (7.26) we obtain K (y
|
x ) ≥ K (x) − K (x, y) −c, therefore, there exists a
constant c
≥ 0 for which K (y
|
x ) = K (x) − K (x, y) +c
.

7.5 Kolmogorov complexity vs. Shannon’s entropy 123
Indeed, to recall from Chapter 5, the conditional and joint entropies are related
through
H(X
|
Y ) = H (X, Y ) − H (Y ) (7.29)
and
H(Y
|
X ) = H (X, Y ) − H (X), (7.30)
which are definitions similar to those in Eqs. (7.26) and (7.27) for the conditional
complexity. From Chapter 5, we also have, for the mutual information,
H(x; y) = H(X ) + H (Y ) − H(X, Y )
H(x; y) = H(X ) − H (X
|
Y )
H(x; y) = H(Y ) − H(Y
|
X ),
(7.31)
which are definitions similar to that in Eq. (7.28) for the mutual complexity. It is
quite remarkable that the chaining relations of conditional or joint complexities and
conditional or joint entropies should be so similar (except in algorithmic IT for the
finite constant c
, which is nonzero in the general case), given the conceptual differences
between Kolmogorov complexity and Shannon entropy! As a matter of fact, such a
resemblance between algorithmic and classical IT is not at all fortuitous. As stated at
the beginning of this chapter, complexity and entropy are approximately equal when it
comes to random events or sequences: the average size of a minimal-length program
describing random events or sequences x from a source X is, indeed, approximately
equal to the source entropy, or K (x)
X
≈ H(X ). The conceptual convergence between
algorithmic entropy and Shannon entropy is formalized in the next section.
7.5 Kolmogorov complexity vs. Shannon’s entropy
As we have seen, complexity can be viewed as a measure of information, just like
Shannon’s entropy. The key difference is that complexity K (x) measures the information
from an individual event x, while entropy H (X ) measures the average information from
an event source X. Despite this important conceptual difference, I have shown in the
previous section the remarkable similarity existing between chain rules governing the
two information measures. In this section, I shall formally establish the actual (however
approximate) relation between Shannon’s entropy and Kolmogorov complexity.
Consider a source X of random events x
i
with associated probabilities p(x
i
). For
simplicity, we will first assume that the source is binary, i.e., the only two possible
events are x
1
= 0orx
2
= 1, thus p(x
2
) = 1 − p(x
1
). We can record the succession
of n such events under the form of a binary string of length n, which we define as
x = x
(1)
i
x
(2)
i
x
(3)
i
...x
(n)
i
with i = 1, 2.

124 Algorithmic entropy and Kolmogorov complexity
We can then estimate the upper bound of the conditional complexity of K (x
|
n )
according to Eq. (7.21), which I repeat here with the new notations:
K (x
|
n ) ≤ 2logn + nf
1
n
n
j=1
x
( j)
i
+ c, (7.32)
where (to recall) f (u) =−u log
2
u − (1 −u)log
2
(1 − u).
Next, we take the expectation value
24
of both sides in Eq. (7.32) to obtain:
K (x
|
n )
≤
,
2logn + nf
1
n
n
j=1
x
( j)
i
+ c
-
= 2logn + c +n
,
f
1
n
n
j=1
x
( j)
i
-
≤ 2logn + c +nf
1
n
n
j=1
.
x
( j)
i
/
(7.33)
= 2logn + c +nf
(
q
)
≡ 2logn + c +nH(X ).
To get the above result, we have made use of three properties.
r
First, we have applied Jensen’s inequality, which states that for any concave
25
function
F,wehave
F(u)
≤ F(
u
);
r
Second, we made the substitution x
( j)
i
=
x
i
= x
1
p(x
1
) + x
2
p(x
2
) ≡ q;
r
Third, we have used the property F
(
q
)
= H (X), which is the definition of the entropy
of a binary, random-event source X,seeEq.(4.13).
In the limit of large n, the result in Eq. (7.33) yields:
K (x
|
n )
n
≤
2logn
n
+
c
n
+ H (X) ≈ H (X ). (7.34)
This result means that for strings of sufficiently long length n, the average “per bit”
complexity
K (x
|
n )
/n has the source entropy H(X ) as an upper bound. This can
be equivalently stated: the average complexity of a random bit string,
K (x
|
n )
, is
upper-bounded by the entropy n H (X) of the source that generates it. Note that the same
conclusion is reached concerning nonbinary sources having M-ary symbols.
26
24
Since all events are independent, the probability of obtaining the string x = x
(1)
i
x
(2)
i
x
(3)
i
...x
(n)
i
is p(x) =
0
n
j=1
p(x
( j)
i
). The expectation value
K (x )
thus means
x
p(x)K (x), or the statistical average over all
possibilities of strings x.
25
Jensen’s inequality applies to concave functions, which have the property that they always lie below any
chord (such as
√
x, −x
2
,orlog(x )).
26
T. M. Cover and J. A. Thomas, Elements of information theory (New York: John Wiley & Sons, 1991).

7.6 Exercises 125
Next, we try to find a lower bound to
K (x
|
n )
/n. To each string x corresponds a
minimal-length program q, which is able to output x from a universal Turing machine U ,
i.e., U (q, n) = x. It will be shown in Chapter 8 that the average length L =l(q)of such
programs cannot exceed the source entropy, nH(X). Equivalently stated, the source’s
entropy is a lower bound of the mean program length, i.e., nH(X ) ≤ L.Itisalso
shown there that if the program length for each q is chosen such that l(q) =−log p(x),
then the equality stands, i.e., L = nH(X). Here, I shall conveniently use this property
to complete the demonstration. As we know, the conditional complexity K (x
|
n )is
precisely the shortest program length that can compute x.Thus,wehave
K (x
|
n )
=
l(q)
= L ≥ nH(X ), and
H(X ) ≤
K (x
|
n )
n
. (7.35)
Combining the results in Eqs. (7.34) and (7.35), we obtain the double inequality
H(X ) ≤
K (x
|
n )
n
≤
2logn
n
+
c
n
+ H (X). (7.36)
It is seen from the final result in Eq. (7.36) that as the string length n increases, the
two boundaries converge to H(X ), and thus the per-bit complexity
K (x
|
n )
/n and the
source entropy H (X ) become identical. For the purpose of the demonstration, we needed
to consider “bits” and “strings.” But we could also consider X
∗
as a random source of
strings x with probability p(x) and entropy H(X
∗
). Thus, we have
K (x)
≈ H (X
∗
)as
the asymptotic limit, which eliminates the need to refer to a “per-bit” average complexity.
The above result, thus, establishes the truly amazing and quite elegant property
according to which Kolmogorov complexity and Shannon’s entropy give very similar
measures of information. Such an asymptotic relationship holds despite the profound
conceptual difference existing between algorithmic and Shannon information theories.
7.6 Exercises
7.1 (M): Use a Turing machine to add the two numbers i = 4 and j = 2, using the
action table in Table 7.3.
7.2 (B): Use a Turing machine to subtract the two numbers i = 4 and j = 3, using the
action table in Table 7.5.
7.3 (T): Solve Exercise 7.2 first. Then complete the subtraction algorithm by introduc-
ing a new TM state aiming to clean up the useless 0 in the output tape sequence,
in the general case with i ≥ j.
7.4 (T): Define, for a Turing machine, an algorithm Comp, and a corresponding action
table, whose task is to compare two integers i, j, and whose output is either
Comp(i ≥ j) = 0orComp(i < j) = 1. Clue: begin the analysis by solving Exer-
cise 7.2 first.

126 Algorithmic entropy and Kolmogorov complexity
7.5 (T): Determine the number of division or subtraction operations required to convert
the unary number
N
1
= 11 1111 1111 1111 0
into its decimal (N
10
) representation. Notes: (a) separators _ have been introduced
in the definition of N
1
for the sake of reading clarity; (b) the convention of the
unary representation chosen here is 1
10
= 10.
7.6 (T): Show how a Turing machine can convert the binary number
M
2
= 1001
into its unary (M
1
) representation. Note: use the convention for the unary repre-
sentation 1
10
= 10.