Amaro A., Reed D., Soares P. (editors) Modelling Forest Systems
Подождите немного. Документ загружается.


19Amaro Forests - Chap 17 25/7/03 11:07 am Page 196
196 N.M. Tchebakova and E.I. Parfenova
NA
< 25
25–50
50–75
75–100
100–125
125–150
(a) (b)
Fig. 17.7. Living phytomass (t/ha) of dark-needled forests across the study area under current (a) and a
warmed climate (b). NA means that a species is not available in a given pixel.
by succession stage. The phases of cedar and fir forest successions caused by forest
fires, droughts or insect pest outbreaks (Polikarpov, 1970) repeat in 200–250 years.
Forest gap models (Shugart, 1984) may be used to specify the forest composition of
these mixed cedar and fir stands at different succession stages.
Acknowledgement
This study was supported by the Russian Foundation for Basic Sciences No.
02-04-49888.
References
Alexeyev, V.A. and Birdsey, R.A. (eds) (1998) Carbon Storage in Forests and Peatlands of Russia. USDA
Forest Service, Northeastern Research Station, General Technical Report NE-244, Radnor,
Pennsylvania, 137 pp.
Budyko, M.I. (1974) Climate and Life. Academic Press, New York, 508 pp.
Hulme, M. and Sheard, N. (1999) Climate Change Scenarios for the Russian Federation. Climatic
Research Unit, Norwich, 6 pp.
Nazimova, D.I. (1975) Mountain Dark-needled Forests of West Sayan Mountains. Nauka,
Leningrad, 120 pp.
Parfenova, E.I. and Tchebakova, N.M. (2000) Possible vegetation change in the Altai mountains
under climate warming. Geobotanical Mapping 1998–2000, 26–31.
Polikarpov, N.P. (1970) Complex investigations in mountain forests of West Sayan. In: Zhukov,
A.B. (ed.) Questions of Forestry, Vol. 1. Institute of Forestry, Krasnoyarsk, pp. 26–79.
Polikarpov, N.P., Tchebakova, N.M. and Nazimova, D.I. (1986) Climate and Mountain Forests of
Southern Siberia. Nauka, Novosibirsk, 225 pp.
Reference Books on Climate of the USSR (1964–1970) Issues: 17, 20–24. Gidrometeoizdat,
Leningrad.

19Amaro Forests - Chap 17 25/7/03 11:07 am Page 197
197 Stand Growth and Productivity in a Changing Climate
Savina, L.N. (1986) Bor
eal Forests of Northern Asia during the Holocene. Nauka, Novosibirsk, 192
pp.
Semechkin, I.V., Popova, Y.M. and Popov, V.E. (1985) Stand structure and productivity. In:
Isaev, A.S. (ed.) Pinus sibirica Forests of Siberia. Nauka, Novosibirsk, pp. 117–132.
Shugart, H. (1984) A Theory of Forest Dynamics: the Ecological Implications of Forest Succession
Models. Springer, New York, 278 pp.
Shumilova, L.V. (1962) Botanical Geography of Siberia. Tomsk University Press, Tomsk, 440 pp.
Smagin, V.N., Ilinskaya, S.A., Nazimova, D.I., Novoseltseva, I.F. and Cherednikova, J.S. (1980)
In: Smagin, B.N. (ed.) Forest Types of Mountains of Southern Siberia. Nauka, Novosibirsk,
234 pp.
Tchebakova, N.M., Monserud, R.A. and Leemans, R. (1994) A Siberian vegetation model based
on climatic parameters. Canadian Journal of Forest Research 24, 1597–1607.
19Amaro Forests - Chap 17 25/7/03 11:07 am Page 198

20Amaro Forests Part 3 25/7/03 11:07 am Page 199
Part 3
Estimation Processes
Parameter estimation is required prior to the building of a mathematical code that will be
used by researchers, forest practitioners and managers, or decision makers and policy mak-
ers. Parameter estimates are necessary for process, empirical and hybrid models.
Data quality is a key issue affecting the prospective quality of the model. The sources of
variability are related to the language communication process (the so-called linguistic vari-
ability), the intrinsic variability (intrinsic to the variable that is being measured) and the mea-
surement variability (due to the measurement method).
Before estimating parameters, there are several decisions on data type and data structures
(e.g. dependent and independent, re-measurements, independent, time and spatial series,
class and continuous, and expert knowledge) and the estimation methods that may be used
(e.g. qualitative (expert and literature), moments, maximum likelihood, marginal quasi-
likelihood, penalized quasi-likelihood, parameter recovery, parameter prediction, percentile,
Markov chains, OLS and NOLS, generalized OLS and NOLS, mixed linear and non-linear,
SUR and NSUR, 2SLS and N2SLS, 3SLS and N3SLS, generalized methods, neural networks,
geostatistical and Bayesian techniques).
After parameter estimation and model construction, the next step consists of the process
of verifying the model. The use of simple or more complex tools in order to verify the statisti-
cal assumptions and the evaluation is essential to test the model’s adherence to reality and
the coherency of its results. A very important contribution to this process is the analysis of the
biological interpretation of the parameters.
Parameter estimation is a dynamic task: reality is changing and the knowledge of the real-
ity is also changing. All the priority research topics in this area have the same objective:
reducing uncertainty in the ultimate model predictions.
The possibility of building web-based learning tools draws attention to the fact that many
of the scientific papers submitted for publication are often not very clear, or even difficult to
understand, especially with regard to parameter estimation. To understand the process it is
often necessary to reproduce the methodology, and that can be difficult in many cases. The
availability of a learning tool with some training examples and subsets of the original data,
along with a more in-depth explanation of the methods used, could help in understanding the
methods used and provide additional information that would certainly improve and validate
the proposed procedures.
An existing model needs some updating – after some time it will need to be re-evaluated
and modified: knowledge of the system evolves and the tr
ue situation may change. To
accomplish this task, there are two main possibilities: (i) to start from the beginning (adding
199

20Amaro Forests Part 3 25/7/03 11:07 am Page 200
200 Part 3
new data, re-evaluating the possibility of having new functional forms, new structures, new
methods), or (ii) to develop and use tools to support model updating. Control engineers use
variants of the Kalman filter to update the state of a system in real time, for example. As
process measurements are recorded, they are optimally combined with model predictions in
the filter update step. Such techniques were developed for real-time systems (i.e. short time
steps) and may be very appropriate in process modelling. However, for traditional long-term
growth modelling, the benefit of applying such techniques is questionable when there may
be years between measurements. In the intervening time, it may be more efficient to re-fit the
existing model, develop a completely new model, or use newly developed estimation tech-
niques on existing model forms that were not known at the last calibration.
Tree mortality is one of the key processes in forest ecosystems. It has been modelled tradi-
tionally with logistic regression using the maximum likelihood estimation method. It is com-
mon for individual tree mortality data to include observations from several stands with more
than one mortality tree per stand. As a consequence, the observations (trees in the same
stand) are correlated. Ignoring data structure in mortality data leads to several consequences,
such as underestimation of standard errors for higher-level fixed effects. The generalized lin-
ear mixed models are useful when data are not normally distributed or have been hierarchi-
cally collected. Methods of analysis and measures of model fit appropriate to use in these
situations should be seriously considered.
The quasi-likelihood estimation method used in generalized linear mixed models is
known for its ability to produce efficient estimates without exact information about the likeli-
hood function. Both marginal quasi-likelihood (MQL) and penalized quasi-likelihood (PQL)
estimation methods have been used. The quasi-likelihood methods are attractive because
they are available in commonly used software. However, one should be aware of the possible
limitations of these methods, e.g. in estimation, the often small number of observations at dif-
ferent levels may cause bias in the resulting estimates.
Multi-level mortality models can be improved by: (i) increasing data and variables in the
model; (ii) estimating the mortality model simultaneously with the growth model; and (iii)
developing goodness-of-fit measures in the case of generalized linear mixed models. Increasing
information by obtaining more data can often be done, but it may be difficult to determine what
level is needed. There are often unmeasured variables affecting tree mortality, and inclusion of
this information can often improve the mortality model. However, if the number of variables
increases, the model becomes more complex. The most recently developed mortality models
often have the same independent variables used to describe tree vitality. To improve model esti-
mates, the growth and mortality models may be estimated simultaneously so that the mortality
curve asymptotically approaches the forest self-thinning limit. Developing goodness-of-fit mea-
sures in the case of correlated data is an issue that must be considered in the future.
Modelling methods are commonly assessed based on their properties of unbiasedness,
asymptotic unbiasedness, consistency and efficiency (as related to a standard). They are also
assessed as to their ability to hold properties under different types and distributions of data.
Properties of fitting methods are affected by several variables, including sample size, the num-
ber of parameters to be estimated, the distribution of the model errors and the fitting method.
Some techniques only have desirable (usually asymptotic) properties for very large sample
sizes, and may function poorly with small sample sizes. Often, techniques that are based on the
normal distribution of model errors give good results for small samples when the model errors
are indeed normal. For non-normal distributions when the distribution is known, maximum
likelihood estimators give ‘good’ results. However, for very large numbers of parameters to be
estimated, methods requiring search algorithms may become unstable, resulting in local min-
ima, and may show large variations in parameter estimates for different sample data sets.
The following contributions examine these and other issues related to parameter estima-
tion in forest models. The editors wish to acknowledge the efforts of Ana Amaro (Portugal)
and Jeffrey Gove (USA) for coordinating this section, and thank them for their contributions
to this volume.

21Amaro Forests - Chap 18 1/8/03 11:53 am Page 201
18 Estimation and Applications of
Size-biased Distributions in
Forestry
Jeffrey H. Gove
1
Abstract
Size-biased distributions arise naturally in several contexts in forestry and ecology. Simple
power relationships (e.g. basal area and diameter at breast height) between variables are one
such area of interest arising from a modelling perspective. Another, probability proportional to
size (PPS) sampling, is found in the most widely used methods for sampling standing or dead
and fallen material in the forest. Often it is desirable or necessary to estimate a parametric
probability density model based on size-biased data. Traditional equal probability methods
may not be appropriate, or may be less efficient in such circumstances, and estimation is better
conducted utilizing size-biased theory. This chapter surveys some of the possible uses of size-
biased distribution theory in forestry and related fields.
Introduction
Size-biased distributions are a special case of the more general form known as
weighted distributions. First introduced by Fisher (1934) to model ascertainment
bias, weighted distributions were later formalized in a unifying theory by Rao
(1965). Such distributions arise naturally in practice when observations from a sam-
ple are recorded with unequal probability, such as from probability proportional to
size (PPS) designs. Briefly, if the random variable X has distribution f(x;
θ
), with
unknown parameters
θ
, then the corresponding weighted distribution is of the form
fx;
θ
)
=
wx f x ;
θ
)
w
(
()(
E
[
wx
()
]
where w(x) is a non-negative weight function such that E[w(x)] exists.
A special case of interest arises when the weight function is of the form w
(x) =
x
α
. Such distributions are known as size-biased distributions of order α and are
written as (Patil and Ord, 1976; Patil, 1981; Mahfoud and Patil, 1982):
1
USDA Forest Service, Northeastern Research Station, USA
Correspondence to: jhgove@christa.unh.edu or jgove@fs.fed.us
© CAB International 2003. Modelling Forest Systems (eds A. Amaro, D. Reed and P. Soares) 201

21Amaro Forests - Chap 18 1/8/03 11:53 am Page 202
202 J.H. Gove
α
(
fx;
θ
)
=
xf x ;
θ
)
(1)
*
α
(
µ
α
where
µ
= x
α
f(x;
θ
) dx is the αth raw moment of f(x;
θ
). Denote X the original, or
α
equal probability, random variable, and X
*
~f
*
(x;
θ
) the size-biased random variable.
α α
The most common cases of size-biased distributions occur when α=1 or 2; in the
context of sampling, these special cases may be termed length- and area-biased,
respectively.
Weighted distributions have numerous applications in forestry and ecology.
W
arren (1975) was the first to apply them in connection with sampling wood
cells. Van Deusen (1986) arrived at size-biased distribution theory independently
and applied it to fitting distributions of diameter at breast height (DBH) data aris-
ing from horizontal point sampling (HPS) (Grosenbaugh, 1958) inventories.
Subsequently, Lappi and Bailey (1987) used weighted distributions to analyse
HPS diameter increment data. More recently, weighted distributions were used
by Magnussen et al. (1999) to recover the distribution of canopy heights from air-
borne laser scanner measurements. In ecology, Dennis and Patil (1984) use sto-
chastic differential equations to arrive at a weighted gamma distribution as the
stationary probability density function (PDF) for a stochastic population model
with predation effects. In fisheries, Taillie et al. (1995) modelled populations of
fish stocks using weighted distributions. In these last two examples, weighted
distributions were not directly tied to the underlying sample selection method,
but were simply convenient models for the observed data. Recognizing the fact
that weighted distributions may be applied as convenient PDF models, Gove and
Patil (1998) developed a compatible theory, unifying the DBH–frequency and
basal area–DBH distributions based on the quadratic relationship between diam-
eter and basal area. Lastly, Gove (2000) extended the work of Van Deusen (1986)
by providing simulation experiments and guidelines for fitting size-biased distri-
butions to data.
The purpose of this chapter is to review some of the more recent results on size-
biased distributions pertaining to parameter estimation in for
estry, with special
emphasis on the Weibull family. In addition, some new results and avenues for pos-
sible future research will be presented. Finally, a new computer program with
graphical user interface (GUI) developed by the author for fitting size-biased
Weibull distributions will be briefly discussed.
Size-biased Weibull Distributions
Weibull distributions have found widespread use in forestry for modelling since
they were first introduced by Bailey and Dell (1973). The two- and three-parameter
Weibull PDFs are given as
fx;
θ
)
=
γ
x
γ
−1
e
−
(
x/
β
)
γ
x0
(
β
β
γ
−1
)
/
(
β
β
−
(
(
x−
ξβ
)
γ
fx;
θ
)
=
γ
x −
ξ
e x
ξ
with
θ
= (
γ
,
β
) and
θ
= (
γ
,
β
,
ξ
), respectively. The unknown parameters
γ
> 0,
β
> 0 and
ξ
> 0 are the shape, scale and location parameters to be estimated for a given sample
of data.
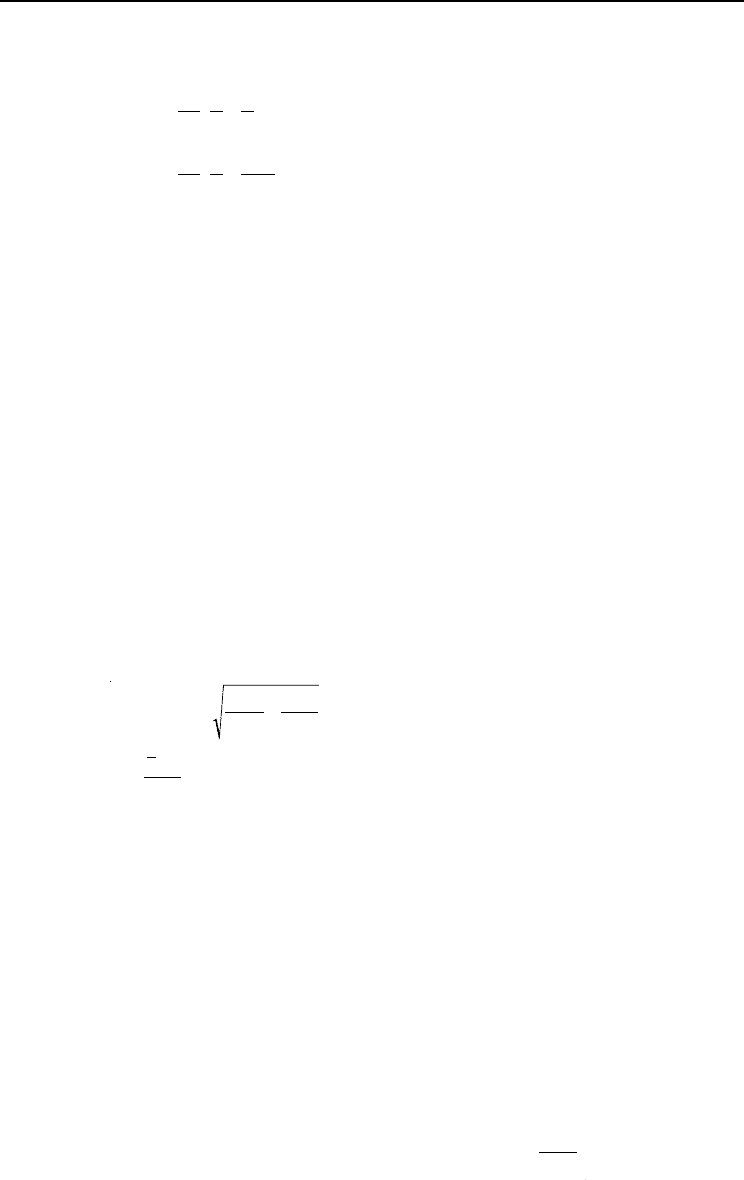
21Amaro Forests - Chap 18 1/8/03 11:53 am Page 203
203 Size-biased Distributions in Forestry
These PDFs can be easily converted to their size-biased counterparts using
Equation 1, namely
x
α
γ
x
γ
−1
*
fx;
θ
)
=
µ
β
β
e
−
(
x/
β
)
γ
x0
α
(
α
α
(
x
α
γ
x −
ξ
γ
−1
−
(
(
x−
ξβ
)
γ
)
/
*
fx;
θ
)
=
µ
α
β
β
e x
ξ
for the two- and three-parameter versions, respectively, with the same restrictions
on the parameters as for the equal probability PDFs. Gove and Patil (1998) have
also shown that the size-biased two-parameter Weibull can be transformed,
through change-of-variables techniques, to the standard gamma distribution. Such
a transformation may be advantageous for simulation studies. For example, Gove
(2000) used the standard gamma to draw probability-weighted samples to simulate
the HPS tally distribution.
Because of their popularity in modelling the traditional DBH–frequency distri-
bution, both the two- and thr
ee-parameter size-biased Weibull PDFs are appropriate
as candidate probability models in all of the applications presented in this chapter.
Size-biased Weibulls: Moment Estimation
Size-biased two-parameter Weibull moment estimators
The development of moment estimators for the size-biased two-parameter Weibull
distribution is given in Gove (2003a). Ther
e, a modified moment estimation scheme
along the lines of Cohen (1965), using the coefficient of variation, is presented. Let
γ
˜
and
β
˜
represent the moment estimates for the shape and scale parameters, respec-
tively; then the moment equations are
2
CV
= ΓΓ
−1
Γ
α
+2
−
Γ
α
+1
(2)
αα
+1
2
Γ
α
Γ
α
˜
x Γ
˜
α
β
=
Γ
˜
α
+1
(3)
where x¯ and
CV are the sample mean and coefficient of variation, respectively, with
Γ
α
= Γ(
α
/
γ
+ 1), Γ
˜
=Γ(
α
/
γ
˜
+ 1) and Γ(k)=
0
∝
x
k1
e
x
dx, k > 0, the gamma function.
α
Equation 2 is solved iteratively for the shape parameter, then the scale parameter
can be found directly by substitution into Equation 3.
Size-biased three-parameter Weibull moment estimators
Unfortunately, the moment equations for the size-biased three-parameter Weibull
ar
e not easily couched in a modified scheme like that for the two-parameter where
the coefficient of variation can be used. Thus, the moment equations for the first
three raw moments are used; these moments can be built up from the moments of
∗
the equal probability three-parameter Weibull (Gove 2003a). Let
µ
∗
= d
ζ
ƒ
α
(x,
θ
)dx
α
,
ζ
denote the
ζ
th raw moment of the size-biased three-parameter Weibull distribution
of order α. Then, it is straightforward to show that
µ
,
=
αζ
*
′
µ
′
+
.
Now, since
α
=1 or
αζ
µ
′
α

21Amaro Forests - Chap 18 1/8/03 11:53 am Page 204
204 J.H. Gove
2 for the most common forestry applications, and ζ = 1,...,3 for the first three raw
moments, it is easy to see from the numerator of
µ
∗
ζ
that the first five raw moments
α
,
of the three-parameter Weibull distribution are required for the estimating equa-
tions. The moments for the three-parameter Weibull are of the form
2
α
µ
=
β
α
Γ
α
+
α
β
α
−1
Γ
ξ
+
α
β
α
−2
Γ
ξ
+
…
+
ξ
(4)
α α
−1
2
α
−2
1
where the coefficients (
α
i
), i = 1,...,
α
follow Pascal’s triangle. Thus, for example, the
*
second raw moment from a length-biased three-parameter Weibull,
µ
1,2
is
3 2 3
µ
β
Γ
3
+ 3
β
Γ
ξ
+ 3
β ξ ξ
Γ
1
2
+
3
=
2
µ
1
β
Γ
1
+
ξ
It should be clear that the moment equations for the length- and area-biased ver-
sions differ. For comparison, the second raw moment from an area-biased three-
*
parameter Weibull is given as
µ
,2
, and is therefore more complicated:
4 3
4
2
2 2 3
+
4
Γ
1
µ
β
Γ
4
+ 4
β
Γ
ξ
+ 6
β
Γ
2
ξ
+ 4
β ξ ξ
=
3
2
µ
β
Γ
2
+ 2
β ξ ξ
Γ
1
+
2
2
The first three moment equations are set equal to the first three sample
moments and solved simultaneously for the estimates
γ
˜ ˜
. Further details are
˜
,
β
,
ξ
given in Gove (2003a,c).
Size-biased Weibulls: Maximum Likelihood Estimation
The maximum likelihood estimators (MLEs) for size-biased Weibulls can be found
by building up from the equal probability likelihood, just as in the case of the three-
parameter moment estimators in the previous section. The equal probability three-
parameter Weibull log-likelihood is
n n
1
γ
ln L = nln
γ
+
(
γ
− 1
)
∑
ln
(
x
i
−
ξ
)
−
β
γ
∑
(
x
i
−
ξ
)
β
γ
i=1 i=1
and the two-parameter log-likelihood follows directly by setting ξ = 0.
The size-biased form was first given by Van Deusen (1986), where he noted that
it was composed of the equal pr
obability log-likelihood plus a constant and a correc-
tion term. He also noted that the purpose of the correction was to account for the
fact that the observations are drawn with unequal probability. The general form of
the size-biased log-likelihood is given as
n
ln * = ln +
α
∑
ln x − nln
µ
′
i
α
L L
i=1
where the second term is constant, depending only on the data, and thus may be
dropped if desired.
In addition, the gradient vector and Hessian matrix of first- and second-order
partial derivatives ar
e also of the same form (Gove 2003a). For example, the gradient
∂ln L *
=
∂ln L
− n
ρα
γ
()
∂
γ
∂
γ
∂ln L *
=
∂ln L
− n
ρα
equations for the size-biased three-parameter Weibull follow the form
β
()
∂
β
∂
β
∂ln L *
=
∂ln L
− n
ρα
ξ
()
∂
ξ
∂
ξ

21Amaro Forests - Chap 18 1/8/03 11:53 am Page 205
205 Size-biased Distributions in Forestry
Notice that the correction term (n
ρ
θ
i
(α )) depends on the size-biased order α . Thus,
there are unique corrections associated with length- and area-biased log-
likelihoods. The Hessian matrix follows the same pattern, being composed of the
equal probability and correction components. Detailed equations for the three-para-
meter gradient and Hessian are presented in Gove (2003a). In the two-parameter
size-biased Weibull, the equations are much simpler, due to the simpler nature of
the raw moment
µ
α
in that distribution. The gradient equations for the two-parame-
ter case are given in Gove (2000).
The Basal Area-size Distribution
As mentioned earlier, the basal area-size distribution (BASD) is the size-biased dis-
tribution of order α = 2 of the traditional DBH–frequency distribution (Gove and
Patil, 1998). The relationship can easily be shown algebraically and arises, not from
sampling theory, but purely from the quadratic relationship between DBH and basal
area. If the random variable X is tree diameter, then X
∼ƒ
( x;
θ
) is the DBH–frequency
distribution. From it, we normally calculate the number of trees in the ith diameter
class (N
i
), once the parameters
θ
have been estimated from sample data
x
N
i
= N
u
i
f
(
x;
θ
)
dx
(5)
∫
x
l
i
where x
l
i
and x are the lower and upper diameter class limits, respectively, and N is
u
i
the total number of trees per hectare.
The BASD comes about by redistributing the probability mass in terms of
basal ar
ea, rather than tree frequency. The random variable in both cases is still
DBH. The BASD can then be used to calculate the basal area (B
i
) in the ith DBH
class as
x
*
B
i
= B
∫
x
l
i
u
i
f
2
(
x;
θ
)
dx
*
where B is the stand basal area per hectare. Thus, X
2
*
∼ƒ
2
(x;
θ
).
Gove and Patil (1998) presented several examples of stands fitted with a para-
meter r
ecovery model, all with the same basal area and number of trees, but span-
ning a wide range of the two-parameter Weibull parameter space. As an example,
the stand in their Figure 1d has been re-fitted with a three-parameter Weibull model
and is presented in Fig. 18.1. This figure shows the empirical histogram for the
DBH–frequency distribution along with the Weibull curve fitted by ML. Also shown
is the corresponding BASD curve, which shares the same estimated parameter vec-
tor
θ
ˆ
from ML.
Estimation of Weibull Parameters under Size-biased Sampling
Arguably, the two most useful forms of size-biased distributions arising in forestry
are the length- and area-biased models. Length-biased data arise from line intersect
samples (LIS) (Kaiser, 1983), horizontal and vertical line samples (HLS, VLS)
(Grosenbaugh, 1958) and transect relascope sampling (TRS) (Ståhl, 1998). Area-
biased data arise naturally from HPS and vertical point sampling (VPS)
(Grosenbaugh, 1958), and from point relascope sampling (PRS) (Gove et al., 1999) for
coarse woody debris. In this section these links are explored in more detail, with
special emphasis on the distribution of HPS tally tree diameters.