Журнал - Управляющие системы и машины 2009 №2 Март - Апрель
Подождите немного. Документ загружается.

УСиМ, 2009, № 2 41
c* * *
9
***
, , ,
, , ,
L
OD LWK MPFK
DP MP DF K LV MP
Μ=
c** *
10
***
, , ,
, , ,
L
OD LW K MPFK
DP MP DF K LV MP
Μ=
c** *
11
***
, , ,
, , ,
L
OD LWK MPFK
DP MP DF K LV MP
Μ=
c** *
12
***
, , ,
, , ,
L
OD LW K MPFK
DP MP DF K LV MP
Μ=
c** *
13
***
, , ,
, , ,
L
OD LWK MPFK
DP MP DF K LV MP
Μ=
c** *
14
***
, , ,
, , ,
L
OD LWK MPFK
DP MP DF K LV MP
Μ=
c** *
15
, , ,
*, *, * ,
L
OD LW K MPFK
DP MP DF K LV MP
Μ=
c** *
16
, , ,
*, *, * .
L
OD LW K MPFK
DP MP DF K LV MP
Μ=
(8)
Кортеж символов
cc c
12 16
,,,=Μ Μ…Μ
∑
со-
гласно [4] – сигнатура. Над этой сигнатурой
возможно дальнейшее определение аксиома-
тики. На основе схемы управления при помо-
щи корреспонденции отношений образуется
система нелогических аксиом. Например, од-
ной из аксиом является следующая:
()
1cc
23 6
,
Kor
f
−
ΜΜ ⎯⎯→Μ, (9)
где
Kor
⎯
⎯→ обозначает корреспонденцию от-
ношений.
Покажем графическую иллюстрацию опе-
рации корреспонденции отношений и сформу-
лируем ее содержательную интерпретацию.
Корреспонденция отношений из
c
2
Μ и
c
3
Μ
в
6
Μ показана на рис. 5.
M
P
D
L
K
D
D
M
P
M
P
K
K
L
L
K
o
r
Рис. 5. Иллюстрация операции корреспонденции отношений
Такая операция соответствует выполнению
аксиомы (9). Логика аксиомы позволяет запи-
сать следующий предикат: «Множество обу-
чаемых осваивает количество учебных дисци-
плин и достигает множество компетенций».
Формальная запись, отражающая существо ком-
позиции отношений (рис. 5), имеет вид:
(
)
,, :м
mh
tsp
in j
П Ld k g d
ϕφ
→ o , (10)
где П – трехместный предикат. Система нело-
гических аксиом – основа для правил вывода
БЗ. Множество моделей объектов системы
{
}
,,, ,M
R
M
LDKMP Z
Z
Μ
ΜΜΜ ∈Μ, сигнатура мо-
делей системы и аксиоматика системы, поло-
женная в основу создания правил нечеткого
вывода, составляют теоретическую базу кор-
ректности интеллектуального управления про-
цессом обучения.
Практическая реализация
Предложенная логико-математическая мо-
дель составила основу для разработки основ-
ных модулей, реализующих интеллектуальную
поддержку процесса принятия решений тью-
тором при разработке индивидуальных траек-
торий обучения студентов Одесского нацио-
нального политехнического университета. На
основе структурированных моделей учебных
дисциплин и межпредметных связей между ни-
ми методами нечеткой кластеризации выделе-
ны векторы степеней
интеграции между дис-
циплинами, существенно влияющими на фор-
мирование компетенций бакалавров специаль-
ности 0925 «Автоматизация и компьютерно-ин-
тегрированные технологии» [7]. Реализация ло-
42 УСиМ, 2009, № 2
гического вывода на основе полученной базы
нечётких правил позволяет учесть основные
современные дидактические требования в про-
цессе управления обучением.
Заключение. Полученная модель представ-
ляет собой теоретическую основу для постро-
ения нечетких правил продукций, на базе ко-
торых реализуется нейро-нечеткое управление
процессом формирования индивидуальных
траекторий обучения с учетом внутри- и меж-
предметных связей в условиях компетентност-
ного подхода. Перспективным направлением
является реализация отдельных функций управ-
ляющей системы с помощью многоагентных
технологий
.
1. Gritsenko V., Synytsya K., Manako A. ICT competen-
cies training in information society // Proc. of the
Third Intern. Conf. «New Information Technologies in
Education for All: e-education». – Kiev.: IRTC, 2008. –
P. 9–16.
2. Беспалько В.П. Образование и обучение с участием
компьютеров (педагогика третьего тысячелетия). –
М.: МПСИ, 2002. – 352 c.
3. Растригин Л.А., Эренштейн М.Х. Адаптивное обу-
чение с моделью обучаемого. – Рига: Зинатне,
1988. – 160 с.
4. Белова Л.А., Метешкин К.А., Уваров О.В. Логико-
математические основы управления учебными
про-
цессами высших учебных заведений. – Харьков: Во-
сточно-региональный центр гуманитарно-образова-
тельных инициатив, 2001. – 272 с.
5. Пупков К.А., Коньков В.Г. Интеллектуальные сис-
темы. – М.: МГТУ им. Н.Э. Баумана, 2003. – 348 с.
6. Ерёмкин А.И. Система межпредметных связей в
высшей школе. – Харьков: ХГУ, 1984. – 151 c.
7. Мазурок Т.Л. Нейросетевой анализ должностных
компетенций //
Вестник ХНТУ. – 2008. – № 1(30). –
С. 62–66.
© Т.Л. Мазурок, 2009
z
Окончание статьи В.Б. Артеменко
9. Внедрение дистанционных образователь-
ных технологий в высшей школе, в том числе
и в ЛКА, позволяет реализовать парадигму «от
образования – к самообразованию», предусмат-
ривающую тесную взаимосвязь между ними и
постепенное смещение акцентов. Эта взаимо-
связь базируется на взаимодействии следую-
щих субъектов и объектов образования: сту-
дент – виртуальная обучающая среда – тьютор.
Ключевую
роль в этой триаде выполняет вто-
рой компонент, который можно создавать на
базе «бесплатных» инструментов, интегриро-
ванных в локальную компьютерную сеть ВУЗ.
Эффективность такого подхода можно объяс-
нить ускоренным внедрением дистанционных
образовательных технологий на основании
использования открытых инструментальных
средств, проверенных мировой и отечествен-
ной практикой.
1. Положение о дистанционном обучении (Утверждено
Приказом МОН Украины 21.01.2004 № 40) / Сайт
Укр. ин-та информ. технол. в образовании НТУУ
«Киевский политехнический институт». – http://udec.
ntu-kpi.kiev.ua/
2. Сайт МНУЦИТиС НАН и МОН Украины. – http://
learn.dlab.kiev.ua/
3. Сайт НТУ «Харьковский политехнический инсти-
тут». – http://dl.kpi.kharkov.ua/;http//cde.kpi.kharkov.ua/
4. Сайт ХНУРЭ. – http://virt.kture.kharkov.ua/
5. Сайт КНЭУ им. В. Гетьмана. – http://www.kneu.kiev.
ua/ua/89.htm
6. Сайт КНТЭУ. – http://www.knteu-elearning. kiev.ua/
7. Сайт Луганск.
нац. пед. ун-та им. Т. Шевченко. –
http://www.do.ipo. lg.ua/
8. Сайт Сумск. гос. ун-та. – http://dl.sumdu.edu.ua/
9. Сайт Веб-центра Львовской коммерческой акаде-
мии. – http://virt.lac.lviv.ua/
10. Distance Education for the Information Society: Poli-
cies, Pedagogy, Professional Development / Web-site
The UNESCO Institute for Information Technologies
in Education. – http://www.iite.ru/
© В.Б. Артеменко, 2009
z

УСиМ, 2009, № 2 43
УДК 811:81’246.3
Н.А. Власенко, Н.Л. Кузьминская, А.А. Максименко
Текстометрические исследования многоязычных научных текстов
Описаны текстометрические исследования авторских научных публикаций и корпусов текстов по использованию новых ин-
формационных технологий в образовании на украинском, русском и английском языках с целью выявления особенностей ав-
торского научного стиля.
Textometric researches of authors' scientific publications and texts packages on using new information technologies in education in
Ukrainian, Russian and English languages are described to reveal the features of the author's scientific style.
Описано текстометричні дослідження авторських наукових публікацій та корпусів текстів з використання нових інформацій-
них технологій в освіті українською, російською та англійською мовами з метою виявлення особливостей авторського науко-
вого стилю в освіті.
Введение. Термины текстометрия и лекси-
кометрия, а также соответствующие исследо-
вания не получили должного распространения
не только в украинской научной литературе,
но и на постсоветском пространстве в целом.
Наибольшей популярности эти исследования
получили во Франции, где впервые указанные
термины были введены в научный лексикон
(лексикометрия в 60-х годах, а текстометрия
в 90-х годах прошлого столетия). В Сорбонне
даже создан текстометрический центр. У фран-
коязычной литературе под термином тексто-
метрический анализ («analyse textométrique»)
понимают серию методов, предоставляющих
возможность исследователю формально реор-
ганизовывать тексты и проводить статистиче-
ский анализ корпуса текстов. При этом под
корпусом текстов понимается совокупность
текстов, объединенных с целью сравнения и
служащих базой для квантитативных исследо-
ваний. При лексикометрическом анализе изме-
ряются различные параметры лексико-семан-
тической системы.
Нельзя сказать, что подобные исследования
в Советском Союзе и на постсоветском про-
странстве не проводились и соответствующие
программные системы не разрабатывались. В
большинстве своем эти исследования относили
к направлению квантитативная лингвистика
и называли различными терминами стати-
стический анализ текста, нумерология тек-
ста, квантитативный (количественный) ана-
лиз текста и др. По мнению авторов, термины
лексикометрия и текстометрия точнее отра-
жают суть исследуемого явления. Напрашива-
ется сравнение с биометрией, представляющей
собой совокупность автоматизированных ме-
тодов и средств идентификации человека, ос-
нованных на его физиологической или пове-
денческой характеристике. Так же как биомет-
рические технологии используются в задачах
уникальной идентификации личности, тексто-
метрические технологии могут использоваться
в задачах определения авторства текста, или
более широко – атрибуции текста. Под ат-
рибуцией текста понимают соотнесение тек-
сту соответствующих ему атрибутов: имя соз-
дателя, жанр произведения, время создания и
др. Анализ существующих методов и методик
по определению авторства текстов приведен в
[1]. Вводится понятие авторского инварианта,
под которым понимают количественную харак-
теристику литературных текстов, однозначно
характеризующую произведения одного автора
и принимающую иные значения для произведе-
ний других авторов. В качестве такого автор-
ского инварианта в [2] предлагается использо-
вать частоту употребления 55-ти выделенных
служебных слов (предлогов – 24, союзов – 14,
частиц – 17).
История вопроса
Поиск методов, с помощью которых можно
было бы определить авторство текста, интере-
совал исследователей давно, но наибольшую
остроту и актуальность он приобрел в 70-е го-
ды в связи со скандалом, вызванным сомне-
ниями по поводу авторства М.А. Шолохова пер-
вых двух томов романа «Тихий Дон». Лауреата
Нобелевской премии 1965 г. в области литера-
туры М.А. Шолохова обвиняли в плагиате.

44 УСиМ, 2009, № 2
В 1984 г. норвежские ученые на основе стати-
стических исследований подтвердили авторст-
во М.А. Шолохова [3], а данные, полученные в
[2] на основе анализа частоты употребления
служебных слов, вновь подвергли его сомне-
нию. Даже обнаруженные в 1999 г. рукописи
романа не остановили споров.
Изложенное подтверждает тот факт, что оп-
ределение авторства текста является задачей
достаточно сложной, а полученные результаты
бывают порой противоречивыми. Приведенный
выше пример наглядно демонстрирует, что ис-
пользовать какую-либо одну характеристику
языка автора для задач атрибуции текста не
вполне оправдано. Импонирует методика оп-
ределения авторства, используемая в модели
ЛингвоАнализатора [1].
Доказательство эффективности предлагае-
мых методов или методик разработчики, как
правило, демонстрируют на примере художе-
ственных текстов, а разрабатываемые програм-
мные средства анализируют тексты на одном
языке. С точки зрения авторов, если какая-либо
методика определения атрибуции текста яв-
ляется истинной для одного языка, она должна
быть истинной и для некоторых других язы-
ков. Задачи же атрибуции научного текста
практически не рассматривались, поскольку
научная работа, как правило, выполняется на-
учным коллективом и поэтому статьи и моно-
графии часто пишутся в соавторстве. Считает-
ся, что для научной статьи не столько важен
стиль изложения, сколько структурированно
представленные научные результаты.
Исходя из того факта, что наука восприни-
мается как универсальная, рациональная, без-
личная, такими же воспринимаются и научные
тексты, хотя у каждого из них есть автор или
группа авторов, создавших эти тексты. Такая
кажущаяся «безликость» научного текста от-
крывает путь в науку случайным людям, для
которых она – своеобразный вид бизнеса, где
результат можно получить быстро, тем более,
что Интернет пестрит объявлениями о предос-
тавлении услуг по написанию не только рефе-
ратов, но и научных статей, кандидатских и
докторских диссертаций, а оспорить авторство
научной публикации практически невозможно,
если только она не содержит явный плагиат
известной научной идеи или разработки. Не-
редко мы являемся свидетелями циничного
плагиата, когда заимствуются не только науч-
ные результаты, но и их описания.
Особенности научного текста
Написание научной статьи требует не толь-
ко знания истории проблемы, текущего состо-
яния дел в изучаемой предметной области, ос-
мысления полученного результата и его места
среди подобных результатов, но и определен-
ных навыков писательского мастерства. Для
точного выражения научной мысли нужно най-
ти языковые средства, адекватные этой мысли.
Научный текст отличается формально-логиче-
ским способом изложения, высокой стандарти-
зированностью и насыщенностью специальны-
ми терминами, использованием специальных
слов-организаторов научной мысли (из сказан-
ного следует, в заключение, в результате про-
веденных исследований и др.), приглушенностью
коннотативных (экспрессивно-эмоциональных,
оценочных) оттенков и пр. Исчерпывающий
анализ общенаучного лексикона приведен в [4].
Для анализа научных публикаций решили
воспользоваться разработанной авторами про-
граммой ТextAnalyzer
*
, описанной в [5]. В каче-
стве корпусов текстов были выбраны тексты те-
зисов докладов, представленных на Междуна-
родную конференцию «New information techno-
logies in education for all» (2006 – 2008 гг.),
именуемые далее ITEA2006 [6], ITEA2007 [7] и
ITEA2008 [8]. Поскольку доклады подавались
на трех языках – украинском, русском или
английском (на выбор автора), было сформи-
ровано девять корпусов текстов – по три на
каждый язык. В корпус не включались назва-
ние доклада, сведения об авторах, аннотации и
литература. Уже первые попытки работы про-
граммы ТextAnalyzer с научными текстами, по-
казали следующую специфику научных пуб-
ликаций, не учтенную разработчиками:
*
Программа написана Кузьминским В.Н. и Кузьмин-
ской Н.Л.

УСиМ, 2009, № 2 45
1. В научных публикациях большой про-
цент в сравнении с художественными текстами
составляют сложные слова, пишущиеся через
дефис. В предыдущих исследованиях авторы
статьи использовали дефис в качестве раздели-
теля слова, т.е. термин информационно-образо-
вательные технологии разбивался на три слова
информационно, образовательные и техноло-
гии. Следует учесть, что в сравнении с худо-
жественными текстами в научных публикациях
таких сложных слов достаточно много и такое
разбиение может повлиять на результат анализа.
2. В научных текстах, особенно при описа-
нии вклада в исследуемую проблему других
ученых, используется запись с инициалами, на-
пример С.П. Кудрявцева. Программа разбивала
эту запись на три слова с, п, кудрявцева. В резуль-
тате при подсчете предлога с получали значи-
тельную погрешность, а в частотный словарь
включалось несуществующее слово п и др.
Во избежание подобных ошибок, была соз-
дана новая версия программы TextAnalyzer вер-
сии 2.0, отличная от предыдущей не только
некоторыми дополнительными функциями, но
и интерфейсом.
Описание программы ТextAnalyzer 2.0
Программа написана на объектно-ориенти-
рованном языке программирования C#, рабо-
тающем в среде исполнения .NET Framework
2.0. Новая версия реализована в виде модулей,
что позволяет добавлять новые функции к про-
грамме, не нарушая ее структуру.
Программа TextAnalyzer версии 2.0, в отли-
чие от предыдущей, составляет не только час-
тотный, но и реверсивный словарь для любого
текстового файла, сохраненного в формате txt.
Использование реверсивного словаря, в кото-
ром упорядочиваются слова не по начальным,
а по конечным буквам, позволяет оценивать
морфологические особенности языка автора.
Окно и все меню программы имеют вид
(рис. 1).
В верхней части окна программы находятся
иконки, с помощью которых можно управлять
программой, а именно импортировать тексто-
вый документ, создавать/пересчитывать сло-
варь, загружать текст и словарь из файла, за-
писывать текст и словарь в файл, изменять на-
стройки языкового интерфейса, экспортиро-
вать словарь и статистику по нему в файл
Excel, выходить из программы.
Рис. 1
До или после загрузки текста в окне про-
граммы нужно указать язык анализируемого
текста, тип создаваемого словаря (частотный
или реверсивный), кроме того в новой версии
появилась возможность включать или выклю-
чать из рассмотрения дефис, инициалы, воз-
можность анализа слов с апострофом и вклю-
чение/исключение чисел сохранилась. Частот-
ный/реверсивный словарь представлен в виде
таблицы, состоящей из четырех столбцов: сло-
во, длина, частота, относительная частота,
аналогично предыдущей версии.
В новой версии в Статистику по тексту
добавлен подсчет однократных слов и их отно-
сительной частоты (рис. 2). Это сделано для
Рис. 2
46 УСиМ, 2009, № 2
подтверждения или опровержения предпо-
ложения, выдвинутого в [9], что доля одно-
кратных лексем (встречающихся в тексте
всего один раз) к общей массе лексем, тяго-
теет к золотому сечению (0,382) с неболь-
шим отклонением в обе стороны. В новой
версии добавлена полная «Статистика по
алфавиту» и появилась возможность экс-
портировать данные в файл Excel.
Лексикометрические и текстометриче-
ские исследования авторского научного
стиля
Для исследования выбраны тексты тези-
сов докладов, представленных одним и тем
же автором (без соавторства)
**
на ITEA2006,
ITEA2007 и ITEA2008, а также корпусов тек-
стов всех тезисов докладов на трех языках,
поданных на эти конференции.
Были выбраны следующие тексты тези-
сов докладов:
• на украинском языке – Артеменко В.Б.
(«Підтримка добування знань і навичок у сис-
темі моніторингу стійкості соціально-економіч-
ного розвитку регіонів» [6], «Моделювання вза-
ємодії учасників Е-навчання на засадах агент-
орієнтованого підходу» [7], «Інституціональна
підтримка дистанційних освітніх технологій у
вищій школі» [8];
• на русском языке – Колос В.В. («Методи-
ки сравнительного и прогностического анализа
телекоммуникационных информационно-обра-
зовательных сред», [6], «Таксономия телеком-
муникационных информационно-образователь-
ных сред» [7], «Информационный мониторинг
телекоммуникационных информационно-образо-
вательных сред» [8];
• на английском языке – Ion Roceanu «“CA-
ROL I” National Defense University`s Elearning
Pilot Centre» [6], «E-education versus e-training»
[10], «Virtual Learning Space Designed to Simu-
**
Исключение составляют тексты тезизов Roceanu –
на ITEA2008 тезисы были поданы в соавторстве, а на
ITEA2007 вообще не подавались и использовались тек-
сты тезисов, представленных этим автором на ICVL
2007 [10].
late Natural Disasters Scenarios and Citizens’
education» [8].
Некоторые из полученных статистических
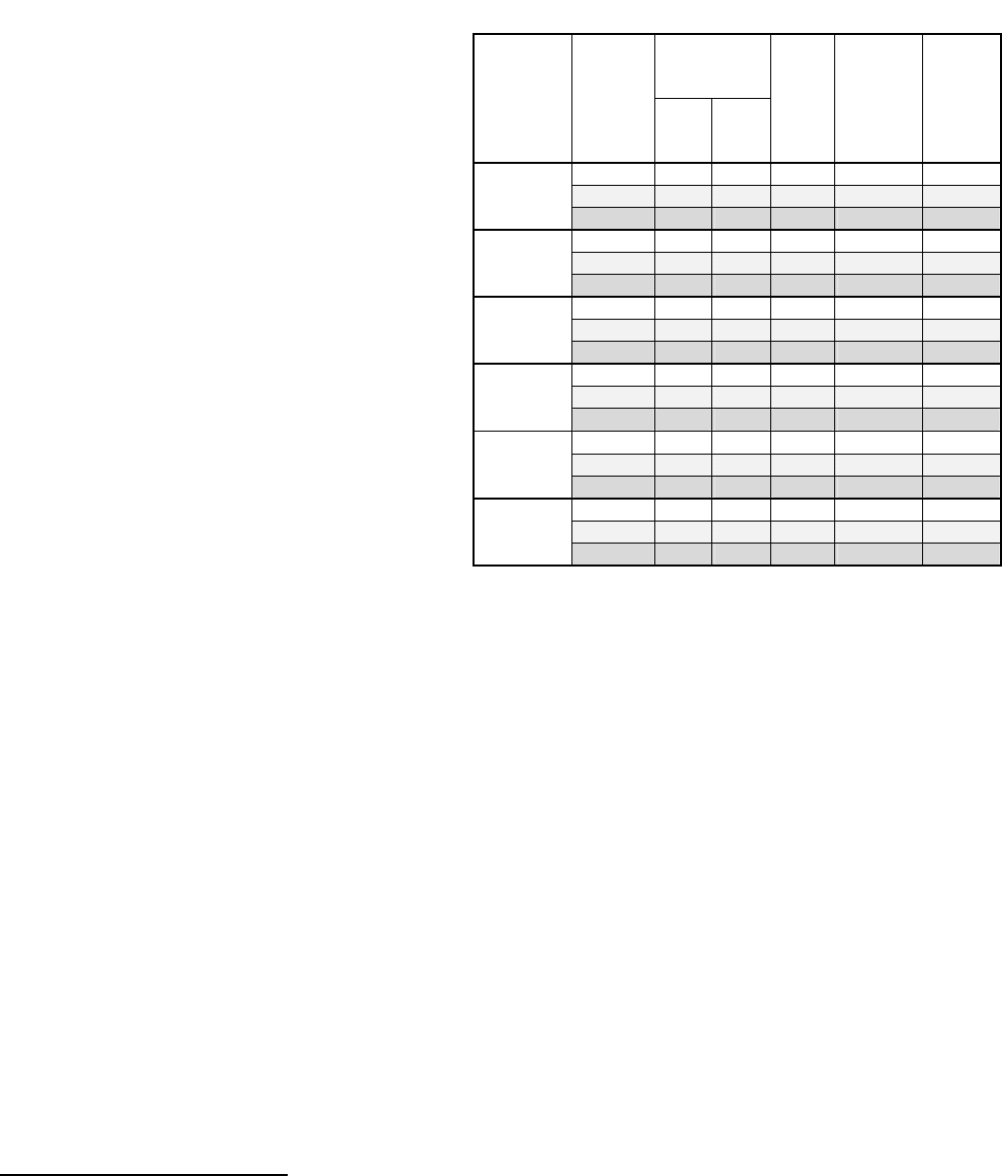
данных приведены в таблице.
Общие выводы по данным таблицы:
• Полученные данные подтверждают резуль-
таты как наших исследований[5, 8], так и ис-
следований других авторов, состоящие в том,
что независимо от анализируемых текстов (ху-
дожественных, научных, корпусов текстов или
авторских текстов) средняя длина слова анг-
лийского слова как в тексте, так и словаре, по-
строенном на базе этого текста, как правило,
короче, чем у текстов на украинском и рус-
ском языках, а средняя длина украинских слов
практически всегда короче русских в текстах
одного функционального стиля.
• Соотношение золотого сечения можно на-
блюдать в авторских научных текстах, напи-
санных на русском и украинском языках, и
практически не возможно в авторских научных
текстах на английском языке. На корпусах на-
учных текстов по использованию новых ин-
формационных технологий в обучении такое
соотношение невозможно для трех рассматри-
ваемых языков.
Т а б л и ц а
Среднее ко-
личество букв
в слове
Тексты
Конфе-
ренция
в тек-
сте
в сло-
варе
Коэф-
фици-
ент бо-
гатства
лекси-
ки
Среднее
количе-
ство слов
в предло-
жении
Относи-
тельная
частота
одно-
кратных
слов
ITEA2006
7,1064 8,2654 0,5184 18,07692 0,3794
ITEA2007
6,6798 7,9417 0,5268 19,70423 0,3724
Артеменко
ITEA2008
6,7782 8,4063 0,4585 20,44444 0,3147
ITEA2006
6,9581 9,0776 0,2414 20,41085 0,1357
ITEA2007
6,8822 9,1778 0,2315 20,58518 0,1315
Корпус
текстов на
укр.языке
ITEA2008
6,9003 8,9848 0,23 19,18498 0,1259
ITEA2006
7,7608 9,0576 0,4637 17,86364 0,3149
ITEA2007
7,9693 9,1349 0,4828 14,14474 0,3265
Колос
ITEA2008
7,6429 9,1407 0,4398 22,54321 0,2985
ITEA2006
7,2645 9,6486 0,2083 17,91322 0,1109
ITEA2007
7,4815 9,5571 0,3024 18,09293 0,1762
Корпус
текстов на
рус.языке
ITEA2008
7,5121 9,4507 0,3266 18,49815 0,1954
ITEA2006
5,3539 6,7836 0,3139 28,0122 0,1855
ICVL 2007
5,4645 7,0041 0,3613 24,30909 0,2274
Roceanu
ITEA2008
5,7716 7,2202 0,3356 29,52727 0,2026
ITEA2006
5,4487 7,6712 0,1564 18,72736 0,0699
ITEA2007
5,6786 7,6348 0,2395 18,53015 0,1336
Корпус
текстов на
анг.языке
ITEA2008
5,4435 7,6503 0,1573 18,69821 0,067
УСиМ, 2009, № 2 47
• Коэффициент богатства лексики (отноше-
ние количества уникальных слов ко всем сло-
вам текста) авторских научных текстов выше,
чем корпусов текстов аналогичной научной
тематики.
Что касается особенностей авторского сти-
ля, то здесь выделяются работы Roceanu, где
намного превышаются значения среднего ко-
личества слов в предложении в сравнении с
корпусом английских текстов
. При рассмотре-
нии текстов отмечено, что для указанного ав-
тора характерны длинные перечисления, что
естественно влияет на длину предложения. Для
текстов Колос В.В. характерно употребление
длинных слов, при этом употребление слож-
ных слов, пишущихся через дефис, минималь-
но. Среди данных таблицы по текстам Артемен-
ко В.Б. больших отклонений от данных корпу-
сов украинских текстов не выявлено, но при
анализе словаря отмечен большой процент слов
на английском языке и сложных слов типа
агент-орієнтований, інформаційно-комуніка-
ційні, навчально-методичні, науково-навчальний,
науково-педагогічний и др. Эти же особенно-
сти авторского стиля прослеживаются и в тек-
стах автора, написанных на русском (см. ста-
тью Артеменко В.Б. в этом журнале).
В текстах Артеменко В.Б. и Колос В.В. про-
верена устойчивость такого параметра, как до-
ля служебных слов из списка [2]. Полученные
данные по статьям Артеменко – 0,018; 0,026;
0,014822 и Колос – 0,0197201; 0,0204841;
0,0169769. Такую нестабильность можно объ-
яснять малым объемом тезисов, который суще-
ственно меньше задекларированного в [2] до-
пустимого размера для получения достовер-
ных результатов – 16 тыс. слов, поэтому невоз-
можно подтвердить или опровергнуть досто-
верность этого параметра для научных текстов.
Заключение. К сожалению, сегодня нельзя говорить
о том, что в текстометрии как художественных, так и
научных текстов, есть параметр, способный дать досто-
верный результат авторства текста, аналогичный анали-
зу ДНК или отпечатков пальцев в биометрии. Тем не
менее доказать авторство как художественных, так и
научных текстов возможно, проанализировав серию па
раметров
. Для облегчения работы исследователям необ-
ходимо специлизированное программное обеспечение,
позволяющее проводить разноплановые измерения текста.
Применение предложенной здесь программы Text-
Analyzer версии 2.0 уже дает неплохие результаты. Го-
товится дополнительный модуль сравнения словарей,
что поможет не только улучшить достоверность опре-
деления авторства, но и определить тенденции в разви-
тии языка вообще и языка
науки, в частности; отследить
появление новых слов и терминов, а также слов и тер-
минов, исчезающих из употребления.
1. Хмелев Д. Краткая история разработки методик
определения авторского стиля. – http://www.rusf.
ru/books/analysis/history.htm
2. Фоменко В.П., Фоменко Т.Г. Авторский инвариант
русских литературных текстов. Новая хронология
Греции: Античность в средневековье. – М.: Изд-во
МГУ, 1996. –
Т. 2. – С. 768–820. – http://lib.ru/FO-
MENKOAT/greece.txt
3. Кто написал «Тихий Дон»? (Проблема авторства
«Тихого Дона») / Г. Хьетсо, С. Густавссон, Б. Бек-
ман и др. М.: Книга, 1989. – 186 с. – http://feb-
web.ru/ feb/sholokh/critics/h89/h89-0162.htm
4. Большакова Е.И., Васильева Н.Э., Морозов С.С. Лек-
сико-синтаксические шаблоны для автоматического
анализа научно-технических текстов. – http://www.
raai.org/resurs/papers/kii-2006/doklad/Bolshakova.doc
5. Власенко Н.А., Кузьминская Н.
Л., Максименко А.А.
Многоязычие в эпоху глобализации: исследование
и примеры использования // УСиМ. – 2008. – №1. –
С. 60–70.
6. Сборник трудов Первой междунар. конф. «Новые
информационные технологии в образовании для
всех», 29–31 мая 2006 года,. – К.: Академпериоди-
ка, 2006. – 530 с.
7. Сборник трудов Второй междунар. конф. «Новые
информационные технологии в образовании для
всех: состояние и перспективы развития», 21–23 но
-
яб. 2007 года. – К.: Академпериодика, 2007. – 458 с.
8. Сборник трудов Третьей междунар. конф. «Новые
информационные технологии в образовании для
всех: система электронного образования», 1–3 окт.
2008 г. – К.: Академпериодика. – 2008. – 468 с.
9. Мартыненко Г.Я. Золотое сечение в нумерологии
текста. – http://www.trinitas.ru/rus/doc/0232/004a/
02321035.htm
10. Roceanu Ion E-education versus e-training Life Long
Learning perspective // The 2nd Intern. Conf. on Vir-
tual Learning, ICVL 2007. – http://www.cniv.ro/2007/
disc2/icvl/documente/pdf/invited/invited3.pdf
© Н.А. Власенко, Н.Л. Кузьминская, А.А. Максименко, 2009
z

48 УСиМ, 2009, № 2
УДК 681.3: 658.56
С.А. Петров
Категориально-информационная модель адаптивной системы
непрерывного обучения
Рассмотрена категориально-информационная модель адаптивной системы поддержки непрерывного обучения, построенная в
рамках теории распознавания образов и информационного критерия функциональной эффективности. Показан процесс опти-
мизации технологических и дидактических параметров системы поддержки обучения. Предложен вероятностный алгоритм
дообучения системы в процессе ее функционирования и определения момента ее полного переобучения.
A categorial-information model of the adaptive system to support the lifelong learning built in the framework of the theory of pattern
recognition and an information criterion of performance is considered. The process of optimization of technological and didactic pa-
rameters of the system of learning support is described. A probabilistic algorithm to adapt the system in its functioning and to deter-
mine the moment of its full retraining is suggested.
Розглянуто категоріально-інформаційну модель адаптивної системи підтримки неперервного навчання, побудовану в межах
теорії розпізнавання образів та інформаційного критерію функціональної ефективності. Показано процес оптимізації техноло-
гічних та дидактичних параметрів системи підтримки неперервного навчання. Запропоновано ймовірнісний алгоритм донав-
чання системи в процесі її функціонування та визначення моменту її повного перенавчання.
Введение. Современные системы поддержки
дистанционного образования основаны на экс-
пертно-эмпирических моделях, в основу кото-
рых положены концепции, разрабатываемые
отечественными и зарубежными учеными [1–
3]. Развитие информационных технологий зна-
чительно опережает уровень формального опи-
сания и математического обоснования суще-
ствующих систем поддержки непрерывного об-
разования, трансформируя их в системы транс-
портировки контента к потребителю данных
систем.
Серьезная проблема, сдерживающая раз-
витие дистанционных систем и систем управ-
ления непрерывным обучением (СУНО), это
недостаточное развитие формальных обще-
признанных математических концепций их
построения и функционирования. Жизненный
цикл функционирования систем поддержки при-
нятия решения, систем сопровождения учеб-
ного процесса состоит из следующих этапов:
• сбор данных и экспертных оценок в пред-
метной области функционирования СУНО:
• формирование математического описания
конструирование параметров функционирова-
ния системы и их оптимизация;
• работы в реальном времени (тестирова-
ние) с возможностью адаптации к обучаемому
и дообучения системы [4, 5].
В силу различных подходов к реализации
этапов функционирования системы не суще-
ствует единых стандартов в синтезе СУНО.
Обобщая рассмотренные системы можно раз-
делить их на следующие группы:
• системы, базирующиеся на аддитивных
схемах;
• системы, базирующиеся на байесовских
алгоритмах принятия решений;
• нейросетевые и генетические алгоритмы;
• нечеткие системы принятия решений;
• алгоритмы, базирующиеся на анализе ин-
формационной компоненты системы.
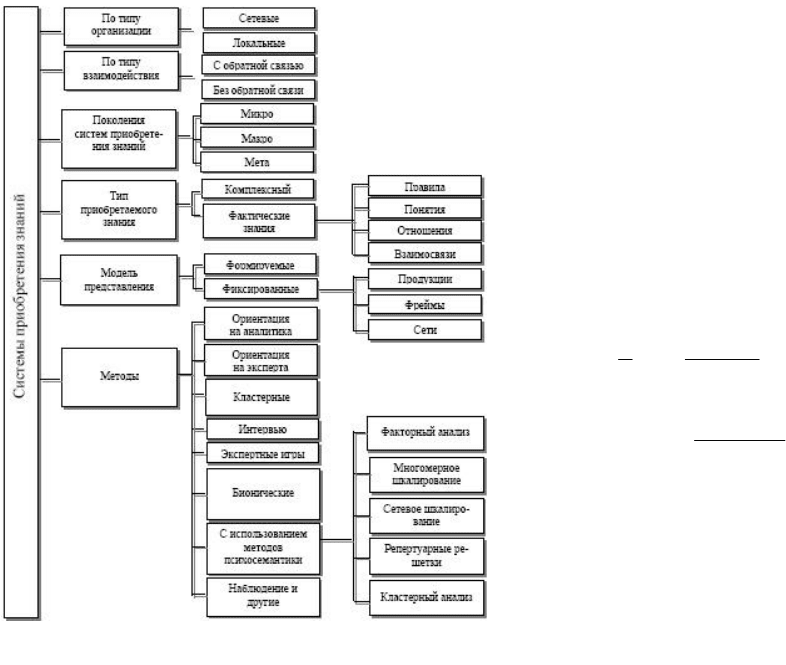
Существует несколько различных класси-
фикаций систем приобретения знаний [6], то-
пология которых показана на рис. 1.
Синтезом системы поддержки непрерывно-
го обучения являются первые два этапа, непо-
средственно влияющие на эффективность ра-
боты системы на третьем этапе ее жизненного
цикла. Особенно это важно, когда система пред-
лагает пользователю индивидуальную траекто-
рию обучения, оценку его уровня знаний, адап-
тивное формирование вспомогательного обра-
зовательного материала.
Постановка задачи
Рассмотрим обобщенную постановку задачи
синтеза систем поддержки непрерывного обу-
чения. Пусть множество входных данных сис-
УСиМ, 2009, № 2 49
темы будет представлено: G − множество вход-
ных сигналов системы − множество данных,
которые могут быть получены в результате на-
чального функционирования системы, а имен-
но статистических данных о действиях пользо-
вателя во время использования системы, отве-
ты на контрольные вопросы, замеры времени,
затраченного на различные виды работ, дан-
ных о структуре образовательного материала и
др.; T − множество моментов сбора информа-
ции, которые функционально разделимы в
контексте взаимодействия пользователя с сис-
темой; Ω − открытое множество характери-
стик объекта (слушателя), формируемых путем
применения определенного оператора над
множествами G и T; Z − множество возможных
функциональных состояний объекта (слушате-
ля). S – множество выходных реакций системы
с возможностью формирования корректирую-
щего воздействия на систему. Матрица вида
«объект-свойство» Y формируется оператором
Ф, применяемым для четверки < G, T, Ω, Z, S >.
Оператор Ф представляет собой алгоритм ги-
бридного кластер-анализа, который используя
обобщенные метрики мехаланобиуса формиру-
ет классы характеристик, параметрически опи-
сывающих возможные функциональные состо-
яния объекта [7, 8].
Построение модели СУНО
Для определения функциональной эффектив-
ности системы сопровождения непрерывного
обучения используется обобщенная информа-
ционная мера Кульбака, имеющая вид [6]
[]
=+−+
⎟
⎟
⎠
⎞
⎜
⎜
⎝
⎛
+
+
= )вб()(
вб
log
2
1
21
21
2
DD
DD
E
m
[]
.)вб(2
вб
)вб(2
log
2
+−
⎟
⎟
⎠
⎞
⎜
⎜
⎝
⎛
+
+−
=
. (1)
Для ее вычисления нам необходимо перейти
в пространство Хемминга. Оператор
ж
, дей-
ствующий на обучающую матрицу Y, прово-
дит ее бинаризацию формируя эквивалентную
ей матрицу X, использует систему контроль-
ных допусков, начальная база значений кото-
рой формируется во время работы гибридного
алгоритма кластерного анализа. Оператор и
действуя на матрицу X формирует геометри-
ческие параметры гипперсфер, описывающих
множество значений векторов Х
i
i = 1…
N, ко-
торые относятся к определенному функцио-
нальному состоянию.
Исходя из определения (1) значение крите-
рия функциональной эффективности (КФЕ) мо-
жет лежать в диапазоне от нуля до единицы.
Учитывая то, что КФЕ показывает адекватность
разработанной модели системы поддержки не-
прерывного обучения, задачей оператора
Ψ
по
оптимизации параметров функционирования
системы является поиск таких значений пара-
метров функционирования, при которых значе-
ние КФЕ будет достигать асимптотического
максимума в области определения его функ-
ции на основе обучающей выборки Y. В каче-
стве параметров оптимизации могут быть вы-
браны: система контрольных допусков, гео-
метрические параметры гиперсфер, дидакти-
ческие и технологические параметры тестиро-
Рис. 1. Обобщенная классификация систем приобретения знаний
50 УСиМ, 2009, № 2
вания. Множество I хранит значение КФЕ в
процессе оптимизации параметров функцио-
нирования системы на i-м шаге. Оператор г
определяет множество
||q
ℑ точностных харак-
теристик, необходимых для вычисления КФЕ.
Оператор ϕ вычисляет максимальное значение
КФЕ, являющееся элементом терм-множества
E. Оператор U выполняет дообучение СУНО в
процессе ее функционирования: во время ра-
боты в режиме тестирования для определения
принадлежности вектора-реализации к некото-
рому классу, характеризующему определенное
функциональное состояние объекта [1], ставит
в соответствие вектору-реализации числовое
значение, равное расстоянию от геометричес-
кого центра контейнера до заданной точки в
пространстве характеристик объекта, описы-
ваемого множеством Ω . В случае массового
скопления векторов-реализаций в значитель-
ном удалении от геометрического центра кон-
тейнера необходимо проводить процедуру пе-
реобучения системы [7].
Ниже показана категориальная модель функ-
ционирования СУНО.
(2)
Практический эксперимент
Для экспериментального подтверждения кор-
ректности построенной модели выбран курс
«Программирование». В качестве входных дан-
ных взяты ответы студентов на тестовые во-
просы по первому модульному циклу. Базовым
классом функционального состояния СУНО вы-
бран класс «отлично», первый класс – «хоро-
шо», второй класс – «удовлетворительно», тре-
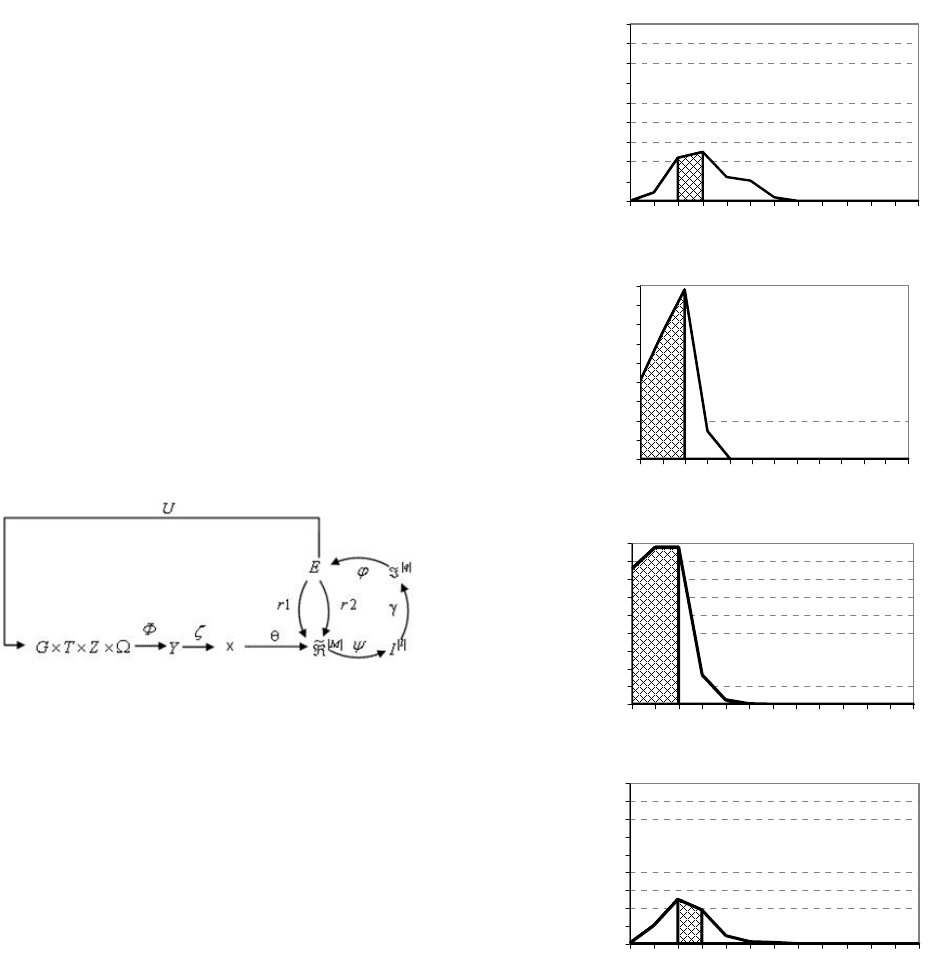
тий – «неудовлетворительно». Числовые зна-
чения КФЕ и
точносных характеристик пока-
зывают значительное пересечение классов функ-
циональных состояний объекта:
•
для базового класса E
*
= 0,70751; D
1
= 0,75;
β = 0,11;
•
для первого – E
1
= 4,39232; D
1
= 1,00;
β = 0,00;
•
для второго – E
2
= 4,39232; D
2
= 1,00;
β = 0,00;
•
для третьего – E
3
= 1,24119; D
1
= 0,79;
β = 0,14.
0,00
0,50
1,00
1,50
2,00
2,50
3,00
3,50
4,00
4,50
12345678910111213
*
0
E
*
0
d
а
0,00
0,50
1,00
1,50
2,00
2,50
3,00
3,50
4,00
4,50
135791113
*
1
d
*
1
E
б
0,00
0,50
1,00
1,50
2,00
2,50
3,00
3,50
4,00
4,50
12345678910111213
*
2
d
*
2
E
в
0,00
0,50
1,00
1,50
2,00
2,50
3,00
3,50
4,00
4,50
12345678910111213
*
3
d
*
3
E
г
Рис. 2. График изменения КФЕ при обучении СУНО для четырех
классов: а – базовый класс – «отлично»; б – первый
класс – «хорошо»; в – второй класс – «удовлетворитель-
но»; г – третий класс – «неудовлетворительно»