Yanushkevich S.N., Wang P.S.P., Gavrilova M.L., Srihari S.N. (eds.) Image Pattern Recognition. Synthesis and Analysis in Biometrics
Подождите немного. Документ загружается.

April 2, 2007 14:42 World Scientific Review Volume - 9in x 6in Main˙WorldSc˙IPR˙SAB
This page intentionally left blankThis page intentionally left blank
April 2, 2007 14:42 World Scientific Review Volume - 9in x 6in Main˙WorldSc˙IPR˙SAB
Chapter 11
Large-Scale Biometric Identification:
Challenges and Solutions
Nalini K. Ratha
∗
, Ruud M. Bolle
†
, Sharath Pankanti
‡
IBM Thomas J. Watson Research Center,
Exploratory Computer Vision Group,
19 Skyline Drive, Hawthorne, NY 10532, USA
∗
fratha@us.ibm.com
†
bolle@us.ibm.com
‡
sharatg@us.ibm.com
In addition to law enforcement applications, many civil applications
will require biometrics-based identification systems and a large percent-
age is predicted to rely on fingerprints as an identifer. Even
though fingerprint as a biometric has been used in many identification
applications, mostly these applications have been semi-automatic. The
results of such systems often require to be validated by human experts.
With the increased use of biometric identification systems in many real-
time applications, the challenges for large-scale biometric identification
are significant both in terms of improving accuracy and response time.
In this paper, we briey review the tools, terminology and methods used
in large-scale biometrics identification applications. The performance
of the identification algorithms need to be significantly improved to
successfully handle millions of persons in the biometrics database
matching thousands of transactions per day.
Contents
11.1. Introduction ................................... 270
11.2. Biometrics Identification versus Verification . . . . . . . . . . . . . . . . . 271
11.3. Terminology................................... 274
11.4. PositiveIdentificationandVerification .................... 275
11.5. Negative Identification and Screening . . . . . . . . . . . . . . . . . . . . . 275
11.6. BiometricSpecificErrors............................ 276
11.7. Additional Terminology . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 276
11.8. IdentificationMethods ............................. 277
11.9. TheClosed-WorldAssumption......................... 278
11.10. PerformanceEvaluation ............................ 279
269
April 2, 2007 14:42 World Scientific Review Volume - 9in x 6in Main˙WorldSc˙IPR˙SAB
270 Synthesis and Analysis in Biometrics
11.10.1. Simple FA R ( M) and FRR(M) ................... 279
11.10.2. Reliability and Selectivity . . . . . . . . . . . . . . . . . . . . . . 280
11.10.3. CumulativeMatchCurve(CMC) .................. 282
11.10.4. Recall-PrecisionCurve ........................ 282
11.11. FingerprintRecognition ............................ 283
11.12. Conclusions ................................... 286
Bibliography ....................................... 286
Glossary
FTA — Failure to Acquire
FTE — Failure to Enroll
FA R — False Accept Rate
FRR — False Reject Rate
11.1. Introduction
Biometrics-based identification systems use machine representations (temp-
lates) of the biometrics of the multiple, potentially many, enrolled users in
the identification system. When a user presents an input biometric to the
identification system, a template is extracted from the input signal and it
is determined which of the enrolled biometric templates, if any, matches
with the query. Such positive identification systems in effect try to answer
the question,
Who is this?
Identification systems base the answers only on biometric data. No
other means of identification, like an identification number or a user-ID, is
supplied to the system.
There are two identification scenarios: positive and negative identi-
fication, distinguished principally by whether the enrolled subjects are
cooperative users who wish to be identified to receive some benefit or access,
or users who are to be denied access or benefit and consequently may not
want to be recognized (e.g. the watch-list scenario). As noted above, a
positive biometric system answers the question,
Who am I?
A negative biometric system, on the other hand, confirms the truth of
the statement
I am not who I say I am not.

April 2, 2007 14:42 World Scientific Review Volume - 9in x 6in Main˙WorldSc˙IPR˙SAB
Large-Scale Biometric Identification: Challenges and Solutions 271
That is, the subject is a legitimate user who is not on the watch list.
The important difference between these scenarios is in the enrolled subjects,
i.e. voluntary versus involuntary enrollment.
Table 11.1. There is no generally accepted definition of scale of
identification systems.
Scale # of Individuals # of Stored Samples
Small 330 1,000
Medium 3,300 10,000
Large 33,000 100,000
Very large 330,000 1,000,000
Extremely large 3,300,000 10,000,000
Identification systems by necessity contain a centralized database since
upon each query every enrolled template needs to be accessible for matching
with the input template. There is no general agreement on what database
size would make an identification system “large scale.” Phillips
[
1
]
gives
some approximate definitions for the scale of biometric identification
systems, which are shown in Table 11.1 Of course, there is a theoretical
(if non- constant) upper bound on the scale of the ultimate large-scale
system, the world scale a system which could identify every human being,
perhaps by any finger. The largest human identification system would have
around 60 billion enrolled biometrics.
11.2. Biometrics Identification versus Verification
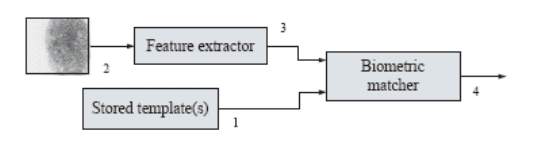
Figure 11.1 shows the basic building blocks of a biometric authentication
system:
(1) A database where one template, in the case of a verification system, or
multiple templates, in the case of an identification system are stored.
(2) An input signal acquisition devise like a fingerprint reader.
(3) A signal processing module that extracts a template representation
from the input signal.
(4) A biometric matcher that compares the two templates and reports the
degree of match in terms of a (normalized) match score or similarity
s ∈ [0; 1].
Biometric identification is based solely on biometric characteristics
of a subject, i.e. it is based only on the biometric signal. Such a
system has access to a biometric database containing biometric samples or
April 2, 2007 14:42 World Scientific Review Volume - 9in x 6in Main˙WorldSc˙IPR˙SAB
272 Synthesis and Analysis in Biometrics
Fig. 11.1. A simple block diagram of the central components of an authentication
system.
representations of the biometrics of the enrollees. A biometric identification
system further has the capability of searching the biometric database to
determine if there are any database entries that resemble the input subject
sample. In the simplest form, the database templates are matched to
the input sample one by one. The output of the matching phase of an
identification system is some candidate list of subject identifiers from the
database that resemble the input biometric.
Biometric verification, on the other hand, differs from identification
in that the presented biometric is only compared with a single enrolled
biometric entity. There may still be a large enrolled population, but the
user presents a token which indicates only the user’s biometric template
from the database for comparison. The statement that is verified by a
verification system is:
“I am who I say I am.”
The user lays a claim on a certain identity and the biometric systems
checks the statement’s identity.
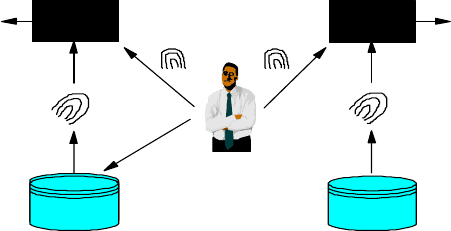
Hence biometric authentication is achieved in one of two ways, both
are illustrated in Fig. 11.2. To the right we have an identification system
where the user presents a biometric and the system establishes the identity
of the user. The left side shows a verification system, which, like an
identification system, has access to a biometric database. This database
contains biometric templates, associated with subjects. However, unlike
in a biometric identification system, a distinct identifier (ID number) is
associated with each biometric template. Hence, from the database, the
biometric template associated with some subject is easily retrieved using
the unique ID. The input to the verification system is a biometric input
sample of the subject in addition to some identifier ID associated with the
identity that the subject claims to be. The output of the matching phase
is an “Accept/Reject” decision — the biometric system either accepts or
rejects the subject’s claim.
April 2, 2007 14:42 World Scientific Review Volume - 9in x 6in Main˙WorldSc˙IPR˙SAB
Large-Scale Biometric Identification: Challenges and Solutions 273
ID/
Name
Yes/No
1 : 1 match
ID
Who am I?
MatchMatch
1:
N
matches
Biometric
database
Biometric
database
I am who I say I am.
Biometric
database
Fig. 11.2. The difference of identification and verification.
As opposed to identification applications where a central database is a
requirement, for verification applications, there are two possible database
configurations:
Centralized database. A central database stores the biometric information
of the enrolled subjects. The user presents some identity token (swipes
a card, types a user ID) stating an identity, which allows the retrieval
of the corresponding biometric template. This is compared with the
newly presented biometric sample. This includes applications where
one subject or a small group of subjects is authorized to use some
application, such as, laptop, PDA, and cell phones.
Distributed database. The biometric information is stored in a distributed
fashion (e.g. smartcards). There is no need to maintain a central
copy of the biometric database. A subject presents some biometric
device containing a single biometric template directly to the system, for
instance by swiping a mag-stripe card or presenting a smartcard. The
biometric system can compare this to the newly presented biometric
sample from the user and confirm that the two match.
Typically some additional information, such as an ID or name, is also
presented for indexing the transaction, and the presentation must be made
through a secure protocol.
In practice, many systems may use both kinds of database — a
distributed database for of-line day-to-day verification and a central
database for card-free, on-line verification or simply to allow lost cards
to be reissued without reacquiring the biometric.
April 2, 2007 14:42 World Scientific Review Volume - 9in x 6in Main˙WorldSc˙IPR˙SAB
274 Synthesis and Analysis in Biometrics
11.3. Terminology
As noted above, a biometric identification system can be operated in two
different modes. These modes, in turn, define different error terminologies
for positive and negative identification applications.
Generic
matcher
Match?
Yes
No
RR
Q
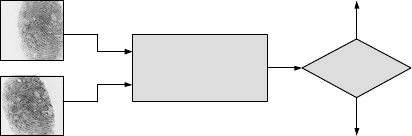
Fig. 11.3. A generic biometric matcher determines if two biometrics look alike.
The generic biometric matcher of Fig. 11.3 takes a query biometric Q
and a reference biometric R as input and gives as output “MATCH/NO-
MATCH” or “Yes/No.” Consequently, such a matcher can make two types
of errors:
(1) A False Match. Decide that the biometrics Q and R are the same,
while in reality they are not.
For the two applications a false match results in a false accept for
positive identification and a false reject for negative identification:
(a) The biometric Q has impersonated biometric R in the member
database and is falsely accepted to enter the system.
(b) Biometric Q mistakenly “looks like” biometric R in the surveillance
database (“watch list”) and is falsely rejected from entering the
system.
(2) A False Non-Match. Decide that the biometrics Q and R are not the
same, while in reality they are.
A false non-match results is a false reject for positive identification and
a false accept for positive identification:
(a) A legitimate biometric Q is falsely rejected from entering the
system because it fails to look like the biometric R in the member
database.
(b) Biometric Q has disguised himself not to look like biometric R in
the watch-list and is falsely accepted to enter the system.
April 2, 2007 14:42 World Scientific Review Volume - 9in x 6in Main˙WorldSc˙IPR˙SAB
Large-Scale Biometric Identification: Challenges and Solutions 275
11.4. Positive Identification and Verification
Positive identification refers to determining that a given individual is
enrolled in a (member) database. The individual is accepted or rejected to
enter some premises or make use of services. Therefore, in this application,
the possible errors
“False accept” and “False reject”
are used:
• False Match → False Accept: A subject is falsely accepted, causing an
intruder to enter the system.
• False Non-Match → False Reject: A legitimate subject is denied service,
is falsely rejected from entering the system.
These are the same errors that can occur in a biometric verification
system. In fact, positive identification is functionally similar to verification.
11.5. Negative Identification and Screening
Negative identification amounts to determining that a subject is not in
some negative databases. This database could for instance be some “most
wanted” database. This is also called “screening,” because the input subject
is in effect screened against the biometric database. This is a very different
biometric system where the possible errors are often referred to as
“False negative” and “False positive”:
• False Match → False Positive: A genuine subject is erroneously flagged
as being on the watch list and is denied service or access.
• False Non-Match → False Negative: A subject on the watch list is
mistakenly not identified as such and is given access.
Biometric identification systems may return multiple candidate matches.
It is required for positive identification that the list of candidate matches is
of size 1, or at least that the candidate list can be quickly narrowed down
to size 1 by some other match mechanism. For negative identification, it
is desired that the candidate list is small so it can be examined by human
operators. For each identification there should be a small number of false
positives.
April 2, 2007 14:42 World Scientific Review Volume - 9in x 6in Main˙WorldSc˙IPR˙SAB
276 Synthesis and Analysis in Biometrics
11.6. Biometric Specific Errors
In addition to the above misclassification errors, there are error rates
associated with error conditions that are more specific to biometrics.
(1) The Failure to Acquire (FTA) rate is the percentage of the target
population that does not possess a particular biometric, i.e. does not
deliver a usable biometric sample.
Here what the exact definition of a FTA is subtle. It can be that a
subject does not possess the biometric that is needed for enrollment,
i.e. the subject is missing an eye; or it can be that a subject’s biometric
cannot be measured, say, the fingerprint of a brick layer (the ridges
have been worn away). Technology may well be improved so that this
latter subject can be enrolled at some future point.
(2) The Failure to Enroll (FTE) rate. Another variable is the FTE
rate, which is the proportion of the population that somehow cannot
be enrolled because of limitations of the technology or procedural
problems.
These two failure errors are specific to biometrics and therefore are very
basic error rates that are encountered in any biometric scenario, and are
errors that are encountered both in verification and identification systems.
Both FTA and FTE are partially due to intrinsic biometric properties and
limitations in state of the art of the biometrics.
11.7. Additional Terminology
There is some more terminology that is specifically related to biometric
identification:
Filtering. Narrowing down the search by using non-biometric parameters
like sex, age group, nationality, etc.
Binning. Cutting down the search by using an additional biometric,
e.g. fingerprint ridge flow pattern (whorl, arch, etc.).
Penetration rate. This is the expected proportion of the database to be
used for the search operation when binning or filtering is employed.
For example, the use of gender to filter the database will result in a 50
percent penetration rate.
A related definition is the identification rank when a identification
system returns a candidate list from the database.
Identification rank. It is the position of the correct entry in the probable
candidate list. In an ideal identification system, the identification rank
April 2, 2007 14:42 World Scientific Review Volume - 9in x 6in Main˙WorldSc˙IPR˙SAB
Large-Scale Biometric Identification: Challenges and Solutions 277
should be always 1. However, in real-world systems, the correct identity
occurs in the top K,withsomeK<<M.
11.8. Identification Methods
We describe how a practical identification system operates to see the types
of answers it returns. Typically an identification system will run in one
of three modes of operation, depending on the application for which it is
being used. In each mode, some subject presents a biometric to the system
and that biometric is compared to the biometric samples enrolled in the
database M. In some cases every enrolled sample in the database will be
compared, but in others only some subset of M is compared.
For simplicity we consider the former case, with a database M of M
enrolled subjects, i.e. the 1 : M search problem in its most general case.
The three modes of operation are related to the three primary criteria for
choosing the subset of M:
Threshold-based. This approach is effectively the same as repeating the
operation of 1:1 verification for each person in the database. The
query biometric template B is compared with each of the enrolled
biometrics to obtain a match/non-match decision. This is typically
done by computing the scores s(B; B
m
),m=1,...,M for all enrolled
templates B
m
∈ M and considering as matches all those candidates
with scores exceeding some threshold t
o
. The complete list of all
matching idenfitities is returned. If no candidate matches (e.g. no
score exceeds the threshold), the person is presumed not to be in the
database.
Rank-based. The system always returns some vector of fixed size, K,of
the enrolled identities that best match the presented biometric. This
requires an ability to rank (sort) the items in the database. The ranking
might be based on scores. With K = 1 the system returns a single
candidate corresponding to the person in the database most likely to
be the same as the input query biometric Q. Notethatitisusually
not necessary to rank all the identities in M. Producing a ranked
short-list of the best K items can be accomplished more efficiently
than sorting all M enrollees. However, in the most general (and most
computational complex case) the output vector is just a permutation
or re-ordering or ranking of database vector M. It is a vector whose
meaning depends upon the relation between the input biometric and
the enrolled biometrics.