Растригин Л.А. Адаптация сложных систем
Подождите немного. Документ загружается.

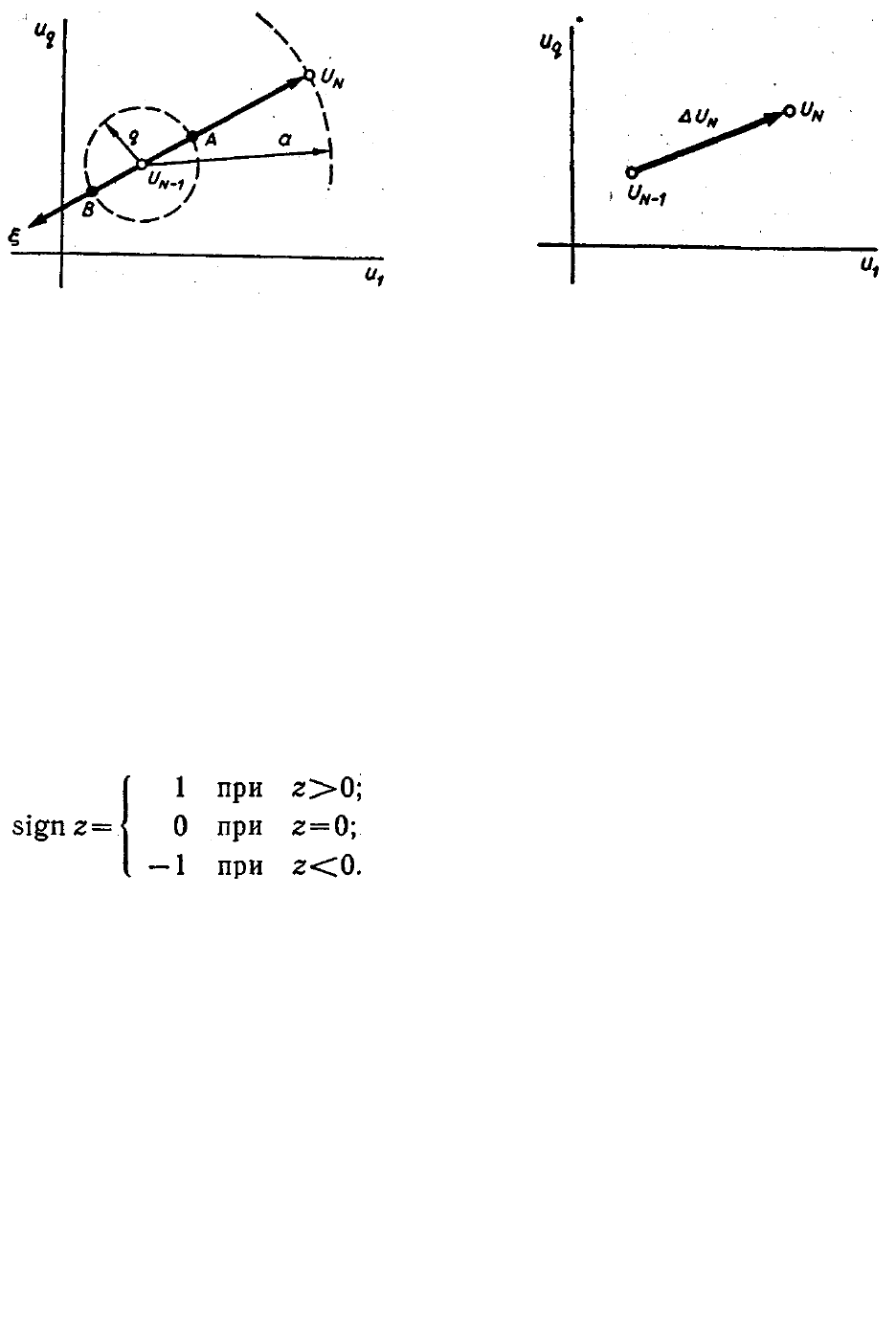
Рис. 3.3.1. Организация рабочего шага алгоритма случайного поиска с парными
пробами.
Рис. 3.3.2. Шаг поиска в пространстве параметров.
где знак шага зависит от значений функции качества в точках A и В
(так, на рис. 3.3.1 Q (А) < Q (В)).
В целом такой алгоритм записывается в виде
U
N
= U
N-1
- aξ sign [ Q (U
N-1
+ gξ) - Q (U
N-1
- gξ)], (3.3.5)
где sign — функция знака:
(3.3.6)
Как видно, здесь на первом этапе
собирается информация о поведении функции качества в области
точки U
N-1
, для чего оценивается ее приращение в случайном
направлении ξ. Радиус g определяет сферу сбора информации (на рис.
3.3.1 показана пунктиром). Сферу радиуса а естественно назвать
сферой принимаемого решения (заметим, что величина рабочего шага
а может быть и меньше, чем пробного g, что характерно для
окончания процесса оптимизации). Свое название этот алгоритм
случайного поиска получил от двух проб в точках А и B,
доставляющих информацию, необходимую для принятия решения.
Продолжим рассмотрение случайного поиска как метода решения
оптимизационных задач. Удобно алгоритм поиска представлять в виде
правила вычисления приращения (шага) на каждом этапе поиска:
∆U
N
= U
N
- U
N-1
(3.3.7)

(рис. 3.3.2). Алгоритм поиска F в этом случае определяет один шаг
перехода от одного решения к другому, следующему за ним:
∆U = F (U
N-1
). (3.3.8)
Здесь F — по-прежнему алгоритм поиска, т. е. правило, инструкция,
указание, с помощью которого, находясь в точке U
N-1
, можно
определить смещение ∆U к другой, более предпочтительной точке
∆U.
Формально всякий алгоритм должен обладать свойством од-
нозначности, т. е. при одинаковых исходных данных результат его
работы должен быть одинаковым. Такое ограничение позволило
построить довольно стройную теорию алгоритмов, хотя и сузило
возможности этого понятия. Случайный поиск расширяет понятие
алгоритма и снимает «проклятие детерминизма», допуская тем
самым неоднозначность результата при одинаковых исходных
данных.
Естественно подразделить все возможные алгоритмы поиска на
два класса:
— детерминированные, регулярные алгоритмы поиска {F},
обладающие указанным свойством однозначности;
— недетерминированные (случайные, стохастические, вероят
ностные и т. д.) алгоритмы поиска {F
ξ
}, не обладающие свой
ством однозначности, результат работы которых имеет статисти
ческий характер.
Легко показать, что
(3.3.9)
т. е. регулярные алгоритмы поиска являются частным,
точнее — вырожденным случаем стохастических алгоритмов.
Действительно, так как результатом работы стохастического
алгоритма яри одних и тех же исходных данных может быть целое
множество значений рабочего шага {∆U}, то всякий такой алгоритм
устанавливает на этом множестве некоторое распределение ве-
роятностей
F
ξ
→ p (∆U), (3.3.10)
указывающее вероятностную меру каждого конкретного шага ∆U. При
изменении алгоритма будет изменяться и распределение p(∆U). B том
случае, когда это распределение вырождается в δ-функцию, т. е.
множество {∆U} состоит из одного элемента, случайный поиск, ее
порождающий, становится детерминированным. Нетрудно заметить,
что этим случайный поиск обобщает регулярный, а любой
детерминированный поиск является δ-вырождением хотя бы одного
из алгоритмов случайного поиска.

3.3.2. Некоторые простейшие
алгоритмы случайного поиска
Существует огромное число алгоритмов случайного поиска (из
сказанного в конце предыдущего подраздела явствует, что их
значительно больше, чем детерминированных). Рассмотрим наиболее
характерные из них. Начнем с локальных алгоритмов, глобальным
будет посвящен отдельный параграф (§ 3.6).
3.3.2.1. Случайный поиск с линейной тактикой
Случайный поиск такого рода построен с помощью только двух
операторов: случайного шага (ξ) и повторения (+) предыдущего шага.
Действие каждого из этих операторов может привести к одному из
двух результатов: минимизируемая функция Q либо уменьшится
(∆Q<0), либо не уменьшится (∆Q≥0). Здесь
∆Q
N
= Q
N
- Q
N-1
, (3.3.11)
a Q
N
= Q (U
N
) — значение минимизируемой функции на N-м этапе
поиска. В зависимости от результата «включается» тот или иной
оператор.
Алгоритм случайного поиска с линейной тактикой опирается на
следующее очевидное предположение относительно объекта
оптимизации: вероятность удачи (∆Q<0) в удачном ранее направлении
больше, чем в случайном. Иначе говоря, целесообразно повторять
удачные шаги, а при неудаче (∆Q≥0) делать случайный шаг, т. е.
обращаться к оператору ξ.
Линейность тактики алгоритма заключается в имитации линейного
поведения, т. е. в прямом повторении удачного шага. Такая тактика
отличает живые существа (см. § 3.7, где рассмотрены бионические
аспекты случайного поиска).
Алгоритм случайного поиска с линейной тактикой удобно
изобразить в виде двух ориентированных графов переходов от одного
оператора к другому в случае удачного и неудачного шагов (рис.
3.3.3). Как видно, при удаче — уменьшении минимизируемой
функции — алгоритм повторяет (+) тот шаг ∆U, который привел к
этой удаче. При неудаче (∆Q≥0) алгоритм
Рис. 3.3.3.
Графы алгоритма слу-
чайного поиска с линейной такти-
кой: а — при удаче,
б —
при не-
удаче.

обращается к оператору случайности ξ и повторяет его до тех
пор, пока не реализуется условие ∆Q<0, т. е. до первого удачного
случайного шага.
Этот алгоритм можно записать в рекуррентной форме:
(3.3.12)
где а — величина шага ( |∆U| = а ),
a ξ — единичный ( |ξ| = 1 ) случайный вектор, равномерно
распределенный по всем направлениям пространства
оптимизируемых параметров {U}. Это означает, что все
направления случайного вектора ξ равновероятны.
Алгоритм можно изобразить и более компактно в виде одного
графа, имеющего условные переходы (рис. 3.3.4, условия реализации
переходов — рядом с дугами соответствующих переходов от одного
оператора к другому).
Данный алгоритм имеет очень простую геометрическую ин-
терпретацию. Это по сути дела спуск шагами а в случайном
направлении ξ пространства параметров {U}: последовательное
применение оператора повторения естественно интерпретировать
как спуск по функции Q(U) вдоль направления ξ с заданным шагом а
до тех пор, пока значение функции не начнет увеличиваться. Это
является сигналом, что выбранное направление исчерпано и
надо выбрать новое, случайное. Отсюда и второе название —
алгоритм случайного спуска.
Как видно, случайный фактор ξ в алгоритме вводится в момент
неудачи (∆Q≥0) и, как в гомеостате Эшби, действует до тех пор, пока
не будет найдено перспективное направление, после чего
начинается спуск. Поскольку случай здесь связан с преодолением
неудач и вводится как своеобразное «наказание» за неудачу, этот
алгоритм иногда называют случайным, поиском с наказанием
случайностью.
Теперь рассмотрим специфику и возможности описанного алго-
ритма. Прежде всего об области целесообразного применения.
Пусть р — вероятность того, что случайный шаг ∆U=aξ удачен, а q —
вероятность повторения удачного шага, т. е.
p = Bep (∆Q < 0 | ∆U = aξ); .
q = Bep (∆Q
N
< 0 | ∆Q
N
< 0, ∆X
N
= ∆X
N-1
). (3.3.13)
Рис. 3.3.4. Граф алго
ритма
случайного спуска с
условными переходами.
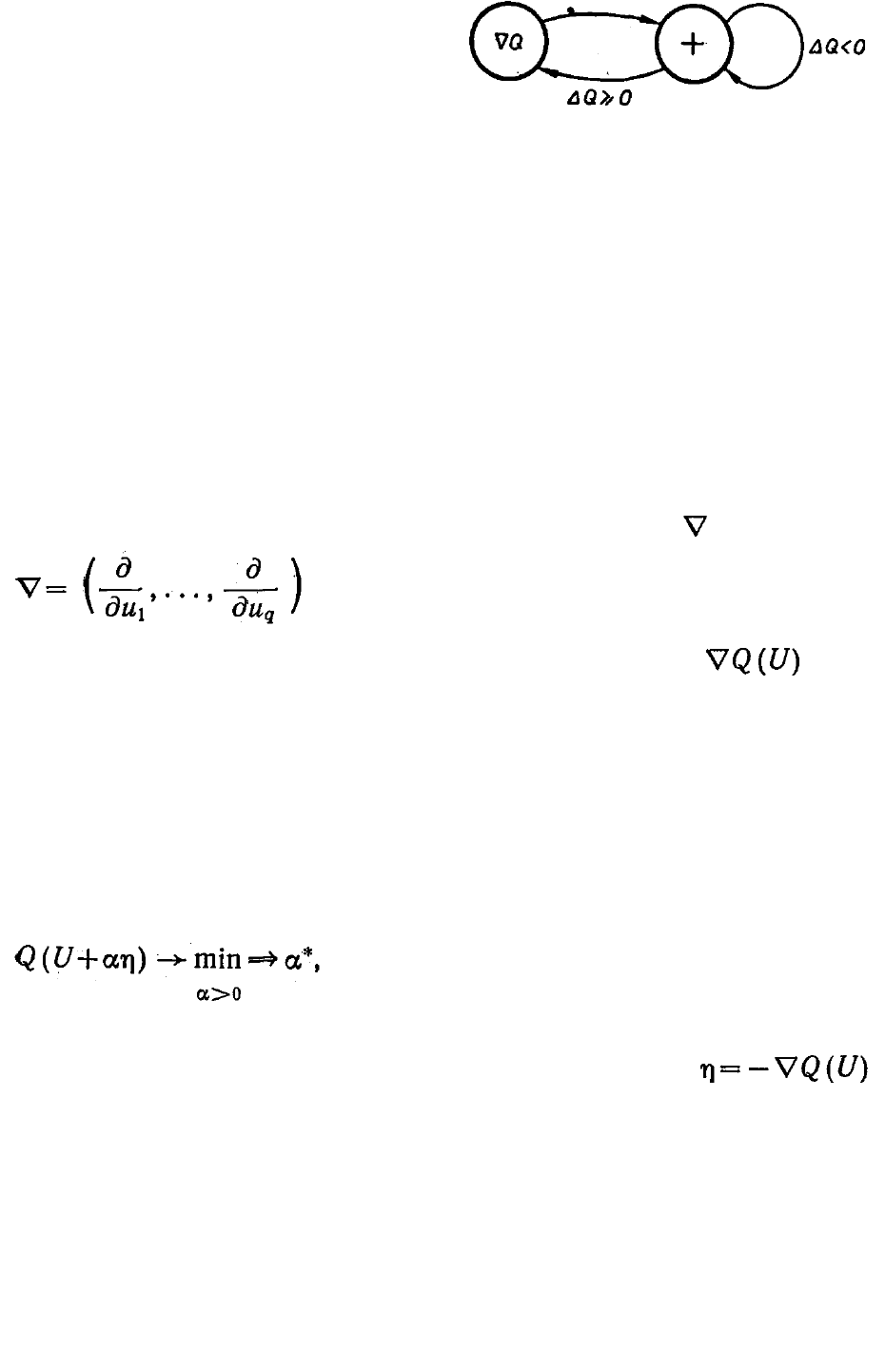
Рис. 3.3.5. Граф алгоритма наиско-
рейшего спуска.
Легко заметить, что описанный алгоритм целесообразно применять
в таких ситуациях, когда часто действует оператор повторения «+»,
так как именно в эти моменты происходит уменьшение
минимизируемой функции. Значит, для эффективной работы
алгоритма необходимо, чтобы вероятность q была велика, а р — не
мала. Например, для линейной функции Q(U) имеем: q = 1 и p = ½, т.
е. идеальные условия. Следовательно, указанный алгоритм
целесообразно применять при оптимизации квазилинейных функций,
т. е. вдали от экстремума U* [275].
Любопытно сравнить этот алгоритм случайного поиска с
известным методом наискорейшего спуска [95], который отличается
от случайного поиска тем, что вместо оператора случайного шага |
используется оператор вычисления градиента :
(3.3.14)
минимизируемой функции, т. е. . Граф
алгоритма наиско-
рейшего спуска приведен на рис. 3.3.5. Как видно, спуск в этом случае
производится в антиградиентном направлении, т. е. в самом
эффективном направлении минимизации для данной локальной
ситуации. (Отсюда появилось ошибочное мнение, что лучшего
метода, чем наискорейший спуск, и быть не может.) Сравним оба
метода для случая, когда величина шага а стремится к нулю. Это
означает, что минимум в процессе спуска определяется точно, т. е.
решается задача минимизации
(3.3.15)
где для случайного поиска η = ξ —
случайный вектор, а для наискорейшего спуска .
Решение α* этой задачи
дает точку лучше исходной:
U
N+1
= U
N
+ α*
N
η
N
, (3.3.16)
где индекс N определяет номер этапа поиска.
Естественно сопоставить оба алгоритма для простейших
объектов оптимизации. Таким простейшим объектом является
квадратичная форма вида
Q (U) = c
1
u
1
2
+ ... + c
q
u
q
2
. (3.3.17)
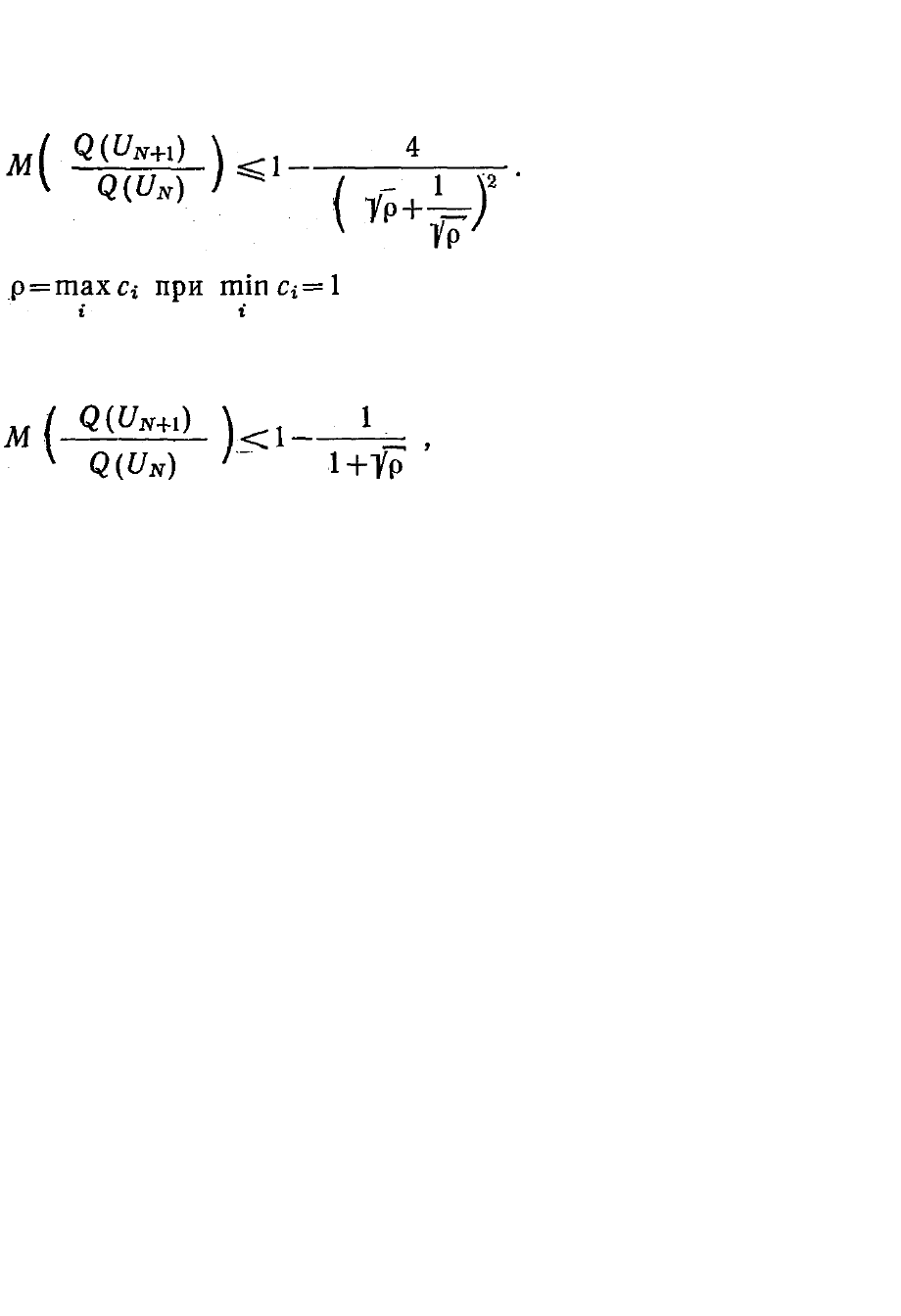
Критерием сопоставления можно выбрать среднее значение от-
ношения Q(U
N+1
) / Q(U
N
). Очевидно, чем меньше это отношение, тем
лучше алгоритм поиска. Для метода наискорейшего спуска оно
имеет вид [95]
(3.3.18)
Здесь ρ — число
обусловленности:
, а
осреднение произведено по случайной начальной точке U
N
. Для
случайного спуска при q = 2 имеет место следующая оценка [145]:
(3.3.19)
где M — знак математического
ожидания по случайному направлению ξ .
Хорошо видно, что по крайней мере при ρ > 16 случайный
спуск всегда будет эффективнее наискорейшего. Это означает, что
плохо обусловленные задачи (их часто называют овражными) лучше
решать методом случайного поиска. Действительно, чем больше ρ,
тем хуже обусловленной и более «овражной» является задача.
Случайный поиск всегда — даже для очень овражных задач — дает
возможность минимизировать функцию (3.3.17) за один этап при
любых начальных условиях. Антиградиентное движение при
наискорейшем спуске исключает такую возможность. Преимущество
данного алгоритма случайного поиска возникает за счет того, что он
обладает большим спектром возможных направлений спуска, чем
регулярные алгоритмы.
Теперь рассмотрим другой алгоритм случайного поиска, который
построен в определенном смысле обратным образом. Здесь
случайность вводится лишь при удачном шаге и является как бы
поощрением. Такое поведение алгоритма нелинейно, что и
послужило основанием для его наименования.
3.3.2.2. Случайный поиск с нелинейной тактикой
Этот вид поиска фактически модулирует метод проб и ошибок.
Алгоритм построен из двух операторов — случайного шага (ξ) и
оператора «—», причем, как уже говорилось, случайный шаг вводится
в качестве реакции на предыдущую удачу, а при неудаче делается
обратный шаг, т. е. реализуется оператор возврата.
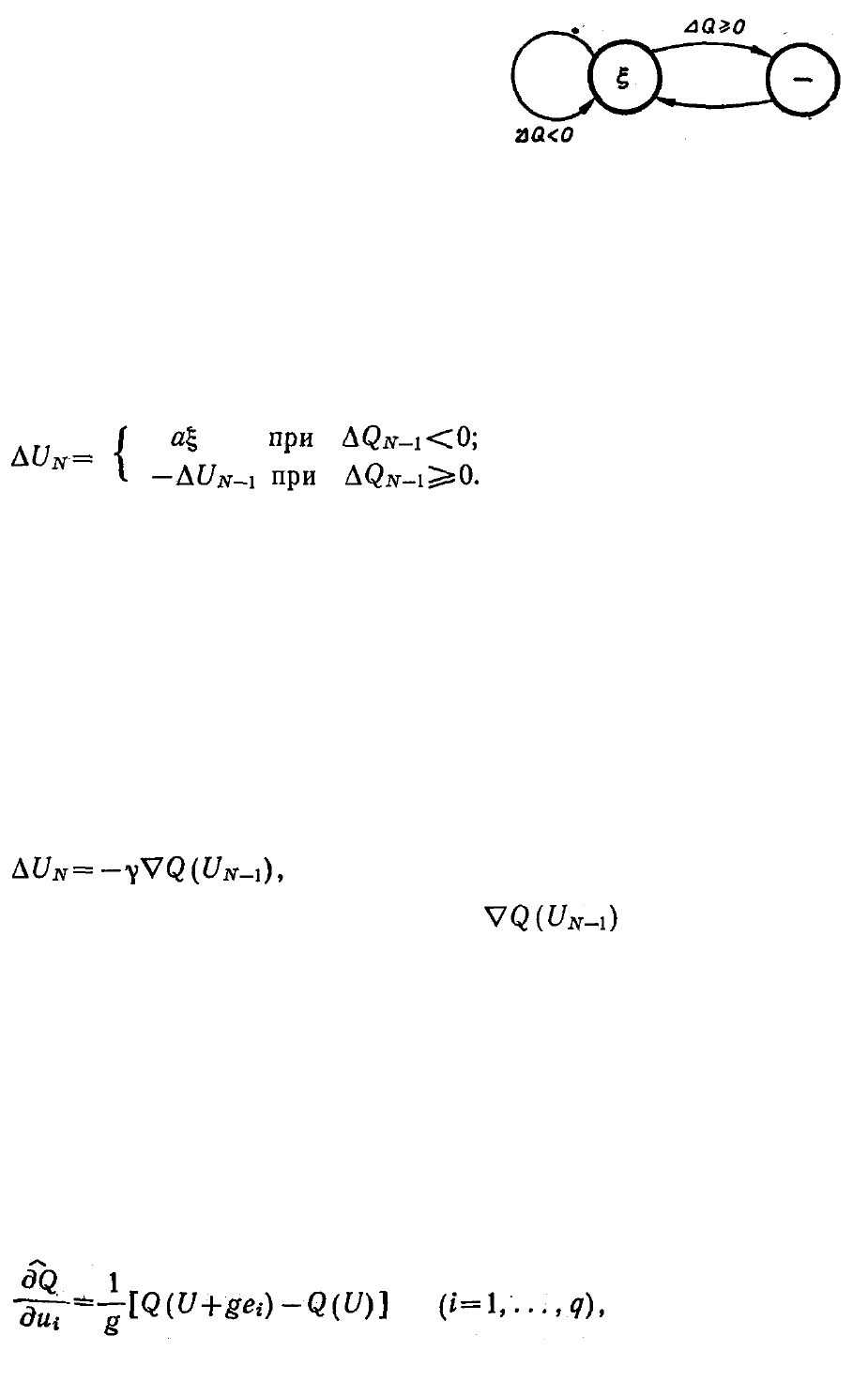
Рис. 3.3.6. Граф алгоритма случайного
поиска с нелинейной тактикой.
Граф алгоритма с нелинейной тактикой показан на рис. 3.3.6. Как
видно, он проще алгоритма с линейной тактикой. Здесь успех
происходит за счет того, что используются только те случайные шаги,
которые удачны, а неудачные устраняются (исправляются) с
помощью операции возврата.
Рекуррентная формула алгоритма имеет вид
(3.3.20)
Рассмотрим область
целесообразного использования этого алгоритма. Элементарный
анализ показывает, что его следует применять в ситуациях со
значительной нелинейностью, когда нецелесообразно повторять
удачные шаги, так как вероятность повторного успеха (3.3.13) мала
(q≈0). Такой бывает ситуация в районе экстремума U* или на дне
оврага минимизируемой функции. Именно в этих случаях нелинейная
тактика имеет существенное преимущество перед линейной.
Сравним этот алгоритм с известным детерминированным методом
поиска — градиентным алгоритмом:
(3.3.21)
где γ — определенный коэффициент, а — градиент
функции Q(U) в точке U
N-1
Будем сравнивать эти алгоритмы по
удельным потерям на поиск, т. е. потерям «на единицу успеха».
Потери обычно связаны с вычислением значения
минимизируемой функции и их естественно измерять
количеством вычислений этой функции. Так, для реализации
одного шага случайного поиска необходимо вычислить ∆Q, т. е.
дважды определить значение функции (3.3.11), следовательно, затраты
будут равны двум единицам. Каждый шаг по методу градиента (3.3.21)
требует q+1 вычислений значений функции Q. Действительно, для
оценки частных производных градиента (3.3.14) необходимо
вычислить
(3.3.22)
где g — база
оценки, а e
i
— i-й орт. Очевидно, что успех одного этапа обоих

алгоритмов будет разным: успех случайного поиска,
разумеется, будет меньше, чем градиентного, который сделает
шаг в лучшем (антиградиентном) направлении.
Разделив потери на успех, получим удельные потери на поиск
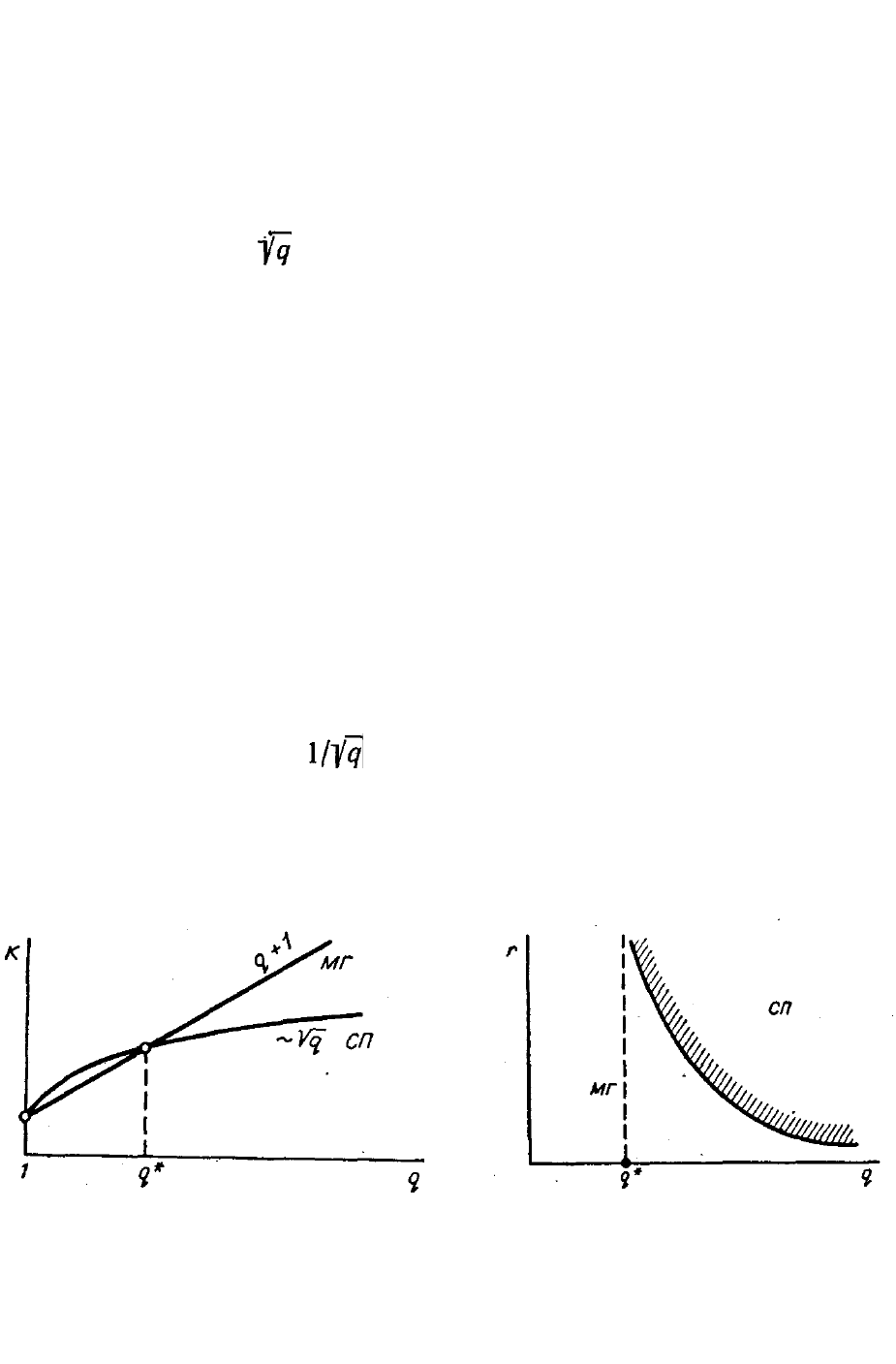
(К), поведение которых в функции размерности задачи q показано на
рис. 3.3.7 для обоих алгоритмов. Хорошо видно, что при решении
простых задач, т. е. при q<q*, более целесообразно применять
метод градиента (МГ), а для задач большой размерности (q>q*)
лучше случайный поиск (СП), у которого потери на поиск
пропорциональны . Любопытно, что критическая сложность
q*, разграничивающая оба метода, невелика (q* = 3—5). Для
линейного объекта q* = 3 [161].
Интересно рассмотреть влияние близости к экстремуму U* на
сравнительную эффективность обоих алгоритмов. Пусть г —
расстояние до экстремума r = | U — U*|. Тогда на плоскости па-
раметров r и q имеет место разделение на зоны целесообразного
использования алгоритмов по критерию удельных потерь на
поиск, показанное на рис. 3.3.8. Из рисунка видно, что зона слу-
чайного поиска достаточно велика и его лучше использовать для
приближенного решения сложных задач. Уточнять решение
(r→0) следует методом градиента. Процесс оптимизации заклю-
чается в движении по вертикали (см. рис. 3.3.8) с переходом из зоны
случайного поиска (СП) в зону метода градиента (МГ).
Таким образом, алгоритм случайного поиска с нелинейной,
тактикой является эффективным методом оптимизации многопа-
раметрических задач. Его эффективность падает с ростом размер-
ности пропорционально , а не 1/q, как у регулярных методов. Это
делает случайный поиск надежным методом решения сложных
задач.
Выше уже говорилось, что случайный поиск можно рассмат-
ривать как способ сбора информации о поведении минимизируе-
Рис. 3.3.7. Поведение потерь на поиск при изменении размерности оптимизи-
руемого объекта. СП — случайный поиск (с нелинейной тактикой), МГ — метод
градиента.
Рис. 3.3.8. Области целесообразного применения алгоритмов случайного поиска
(СП) и метода градиента (МГ).
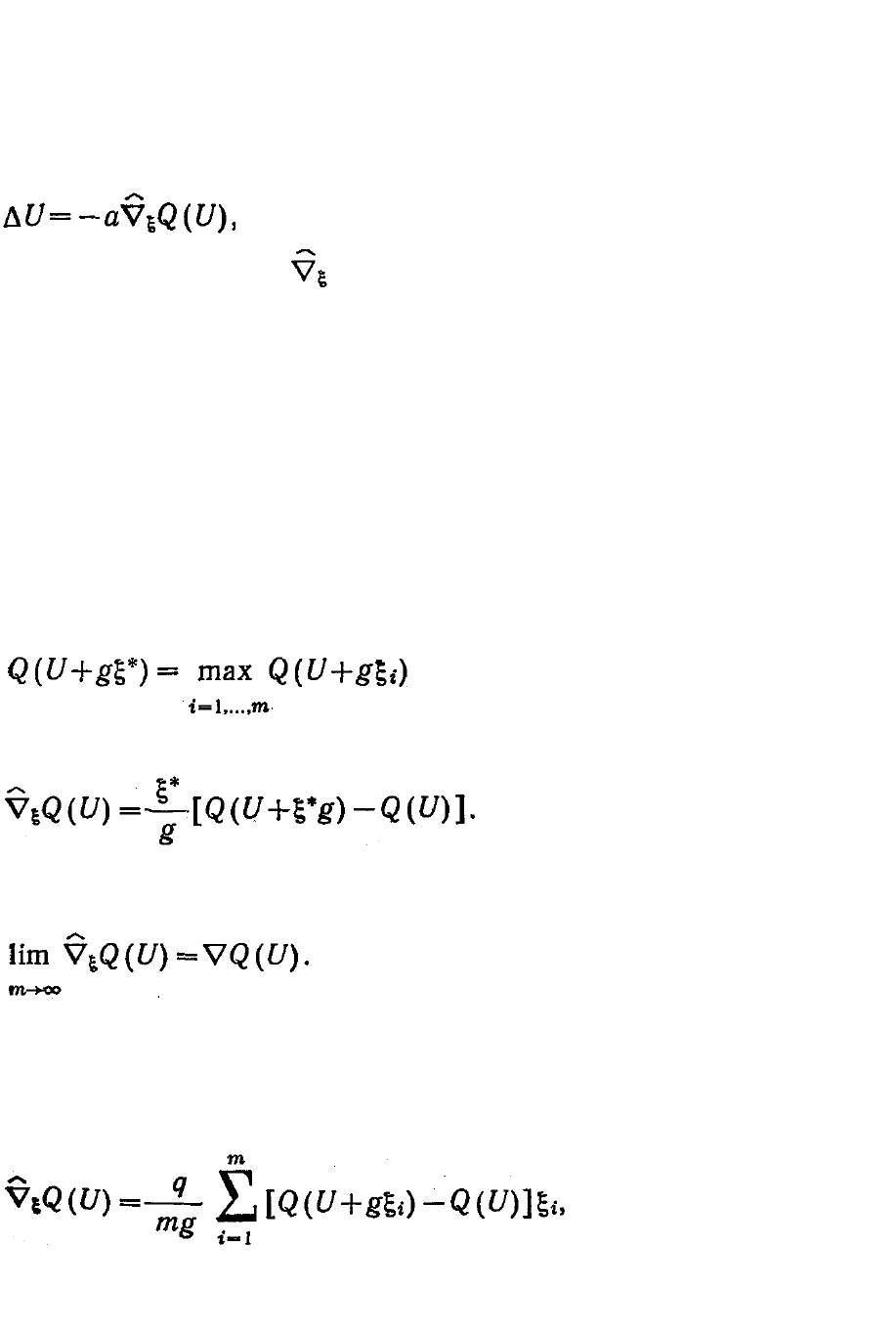
мой функции. Такой информацией облагает оценка градиента,
указывающего направление наиболее интенсивного увеличения
функции. Поэтому естественно рассмотреть алгоритмы случайного
поиска, использующие стохастические оценки градиента. Рабочий
шаг при этом организуется так же, как и у градиентного алгоритма
(3.3.21):
(3.3.23)
где — стохастическая оценка градиента. Способ
такой оценки и отличает алгоритм поиска.
3.3.2.3. Случайный поиск по наилучшей пробе
Этот алгоритм сводится к определению значений минимизи-
руемой функции в т случайных точках:
U
i
= U + gξ
i
(i = 1, ..., m), (3.3.24)
где ξ
i
— i-я реализация единичного случайного, вектора, равномерно
распределенного в пространстве {U}. Выбор направления ξ*
наилучшей пробы определяется очевидным выражением:
(3.3.25)
и дает оценку градиента в виде
(3.3.26)
Очевидно, что при т→∞ эта
оценка стремится к точному значению градиента, т. е.
3.3.2.4. Метод стохастического градиента
Стохастический градиент оценивается по формуле [164]:
(3.3.27)
т. е. представляет собой
сумму всех случайных векторов ξ
i
с весами, равными приращениям
минимизируемой функции в данных случайных направлениях.