Лупанов О.Б. Курс лекций по дискретной математике
Подождите немного. Документ загружается.


Определение. Пусть дана последовательность {a
i
}. Про изводящей функцией этой последовательности на-
зывается формаль ный ряд
∞
X
i=0
a
i
x
i
. (24)
Биномиальные коэффициенты. Пусть x
1
, . . . , x
n
— формальные объ екты. Пусть X = {x
1
, . . . , x
n
}. Рас-
смотрим всевозможные k-элементные подмножества в множестве X. Это всевозможные выборки x
i
1
, . . . , x
i
k
.
Выпишем соответствующую производящую функцию:
(1 + x
1
) · (1 + x
2
) · . . . · (1 + x
n
) =
n
X
k=0
X
S⊂X
|S|=k
Y
x
j
∈S
x
j
. (25)
Что такое произвольное подмножество в X? Всякий элемент x
k
либо входит в него (этому соответствует сла гае-
мое x
k
в соответствующем множителе), либо не входит (это му соответствует слагаемое 1). А теперь, поскольку
нас интересует т олько количество k-элементных подмножеств, можно подставить x
i
= x и получить искомую
производящую функцию:
(1 + x)
n
=
n
X
k=0
C
k
n
x
k
. (26)
Сочетания с повторениями. В этом случае каждый элемент может вс тречаться уже не один раз, а сколько
угодно. Значит, каждая скобка должна содержать формальную с умму всех степеней переменной x
i
:
(1 + x
1
+ x
2
1
+ x
3
1
+ . . .) · (1 + x
2
+ x
2
2
+ x
3
2
+ . . .) · . . . · (1 + x
n
+ x
2
n
+ x
3
n
+ . . .) =
∞
X
k=0
X
s
i
>0
s
1
+...+s
n
=k
x
s
1
i
· . . . · x
s
n
n
(27)
После подстановки x
i
= x получаем производящую функцию:
(1 + x + x
2
+ x
3
+ . . . )
n
=
∞
X
k=0
CC
k
n
x
k
. (28)
Теперь заметим, что у нас слева стоит произведение формальных рядов. А их мы уже умеем сворачивать.
Получаем
(1 − x)
−n
=
∞
X
k=0
CC
k
n
x
k
. (29)
Теперь получим формулу бинома Ньютона для отрицательных степеней:
(1 − αx)
−n
=
∞
X
k=0
CC
k
n
α
k
x
k
. (30)
Отметим одно полезное свойство числа сочетаний:
CC
k
n
= C
n−1
n+k−1
=
(k + n − 1) · . . . · (k + 1)
(n − 1)!
, (31)
то есть это многочлен по переменной k степени n − 1.
Теперь рас смотрим ещё один содержат е льный пример, в котором используются производящие функции.
Рассмотрим сначала такую простенькую задачу. Найти число u
n
последовательностей длины n, в которых нет
двух нулей, стоящих подряд. Идея решения состоит в том, чтобы выразить u
n
через числа u
j
с меньшими
номерами (написать рекуррентное соотношение). Попробуем сделать это: ясно, что u
0
= 1 и u
1
= 2. Далее, если
у нас есть последовательность w длины n, то возможны два случая:
w = 1 ∗. . . ∗
|{z}
n−1
, w = 01 ∗. . . ∗
|{z}
n−2
. (32)
На месте звёздочек могут стоять любые допустимые пос ледовательности длин n − 1 и n − 2 соответс твенно.
Таким образом, u
n
= u
n−1
+ u
n−2
. Мы получили линейное рекуррентное соот ношение. Давайте выясним, какой
общий вид могут иметь решения линейных рекуррентных соотношений.
11

Теорема 1.19. Пусть K = C. Пусть u
0
, u
1
, u
2
, . . . — искомая последовательность. Пусть задано рекур-
рентное соотношение
u
n+r
= a
1
u
n+r−1
+ . . . + a
r
u
n
, a
r
6= 0 (33)
и заданы начальные условия u
0
, . . . , u
r−1
. Тогда общий член последовательности u
n
выражается в виде мно-
гочлена степени строго меньше r:
u
n
=
s
X
i=1
P
i
(n)α
n
i
. (34)
Расс мотрим производящую функцию этой последовательности:
U(x) =
∞
X
n=0
u
n
x
n
. (35)
Рассмотрим многочлен
G(x) := 1 − a
1
x − a
2
x
2
− . . . − a
r
x
r
. (36)
А теперь перемножим их:
C(x) := G(x) · U (x) =
∞
X
n=0
c
n
x
n
. (37)
Заметим, что
c
n+r
= u
n+r
− a
1
u
n+r−1
− . . . − a
r
u
n
(38)
при всех n > 0. Но в силу имеющегося рекуррентного соотно шения получаем, что все коэффициенты ряда,
начиная с r-го, равны нулю. Значит, C(x) — это просто многочлен степени не выше r − 1.
Рассмотрим многочлен
F (x) = x
r
− a
1
x
r−1
− . . . − a
r
= (x − α
1
)
q
1
· . . . · (x − α
s
)
q
s
,
X
q
i
= r. (39)
Легко видеть, что
G(x) = (1 − α
1
x)
q
1
· . . . · (1 − α
s
x)
q
s
. (40)
В самом деле, из определения G ясно, что G(x) = x
r
F
1
x
, но выписанное произведение (40) тоже , очевидно,
равно x
r
F
1
x
.
Далее, поскольку
U(x) =
C(x)
G(x)
=
r−1
X
i=0
c
i
x
i
(1 − α
1
x)
−q
1
· . . . · (1 − α
s
x)
−q
s
. (41)
А теперь применяем формулу для бинома с отрицательными степенями:
u
n
=
min(n,r−1)
X
i=0
c
i
X
m
1
,...,m
s
>0,
m
1
+...+m
s
=n−i
s
Y
j=1
α
m
j
j
CC
m
j
q
j
. (42)
С другой с тороны, вспомним теорему из анализа о ра з ложении рациональных дробей в сумму простейших:
deg C < deg G, поэтому
U(x) =
C(x)
G(x)
=
C(x)
(1 − α
1
x)
q
1
· . . . · (1 − α
s
x)
q
s
=
s
X
i=1
q
i
X
k=1
β
ik
(1 − α
i
x)
k
. (43)
Разлагаем в ряды наши «прогрессии» и приравниваем коэффициенты:
U(x) =
s
X
i=1
q
i
X
k=1
∞
X
n=0
β
ik
CC
n
k
α
n
i
x
n
=
s
X
i=1
∞
X
n=0
P
i
(n)α
n
i
x
n
. (44)
Здесь deg P
i
6 q
i
− 1 6 r − 1. Окончательно получаем
u
n
=
s
X
i=1
P
i
(n)α
n
i
, (45)
что и требовалось доказать.
12
1.3.2. Формальное дифференцирование
Чтобы не напрягать себя лишними проблемами, будем далее считать кольцо K ассоциативным коммутатив-
ным кольцом, потому что ничего другого нам, по сути, и не потребуется.
Определение. Пусть дан формальный ряд A(x). Его формальной производной назовём ряд
DA(x) :=
∞
X
n=0
(n + 1)a
n+1
x
n
. (46)
Очевидно, что производная — это линейная операция.
Несложно проверить, что имеет место формула Лейбница
D(A · B) = DA · B + A · D B. (47)
Кроме того, если ряды A и B обратимы, то имеет место формула (правило ло гарифмического дифференци-
рования)
D(A · B)
A · B
=
DA
A
+
DB
B
. (48)
Этот результат немедленно следует из формулы Лейбница.
Далее, эта формула без труда обобщается на произво льное количество слагаемых:
D(A
1
· . . . · A
n
)
A
1
· . . . · A
n
=
DA
1
A
1
+ . . . +
DA
n
A
n
. (49)
Из формулы Лейбница легко выводится ещё одно полезное св ойство:
D(A
n
) = nA
n−1
DA. (50)
1.3.3. Сходимость в пространстве формальных рядов
Верхние индексы будут обозначать не степень, а номер.
Определение. Рассмотрим последовате льность рядов
A
i
⊂ K
[x]
. Будем гов орить, что A
i
→ A, если
для всякого n найдётся δ(n) такое что при всех i > δ(n) имеем a
i
n
= a
n
. Иначе говоря, начиная с некоторого
номера, n-й коэффициент предела стабилизируется.
Определение. Будем гово рить, что формальный ряд, составленный из рядов, сходится, если сходится по-
следовате льность его частичных сумм.
Пример 3.2. Рассмотрим ряды A
i
(x) := a
i
x
i
. Тогда
P
A
i
(x) = A(x) =
∞
P
i=0
a
i
x
i
.
Определение. Через deg
∗
A будем обозначать номер минимального ненулевого коэффициента ряда A.
Утверждение 1.20 (Критерий сходимости). Ряд
∞
P
j=0
A
j
(x) сходится т огда и только тогда, когда
deg
∗
A
j
→ ∞, j → ∞. (51)
Очевидно.
Определение. Пусть ряды B
j
таковы, что B
j
(0) = 0. Будем говорить, что B(x) =
∞
Q
j=1
1 + B
j
(x)
, если
последовательность частных произведений
i
Y
j=1
1 + B
j
(x)
(52)
сходится к ряду B.
Утверждение 1.21. Бесконечное произведение
∞
Y
j=1
1 + B
j
(x)
(53)
сходится тогда и только тогда, когда deg
∗
B
j
→ ∞ при j → ∞.
Очевидно.
13

Эти свойства сходимости позволяют беспрепятственно перенести операцию дифференцирования на ряды и
произведения. Так, для сходящихся рядов имеет место свойство:
D
∞
X
j=1
A
j
=
∞
X
j=1
DA
j
, (54)
а для сходящихся про изведений — формула
D
∞
Q
j=1
1 + B
j
(x)
!
∞
Q
j=1
1 + B
j
(x)
=
∞
X
j=1
D
1 + B
j
(x)
1 + B
j
(x)
. (55)
1.3.4. Подсчёт количества неприводимых многочленов над F
p
Рассмотрим поле F
p
и кольцо многочленов F
p
[x].
Определение. Многочлен называется приведённым, если его старший коэффициент равен 1.
Заметим, что произведение приведённых многочленов является приведённым многочленом. Мы будем здесь
рассматривать только приведённые многочлены, поэтому слово «приведённый» часто будем опускать.
Через R
k
будем обозначать множество всех приведённых многочленов степени k. Заметим, что c
k
:= |R
k
| =
p
k
, потому что старший коэффициент равен 1, а все остальные k коэффициентов произвольны. Рассмотрим
производящую функцию для последовательности {c
i
}:
C
R
(x) :=
∞
X
k=0
c
k
x
k
=
∞
X
k=0
p
k
x
k
=
1
1 − px
. (56)
Через I
m
будем обозначать количество неприводимых многочленов степени m. Вычислим нашу производя-
щую функцию другим способ ом. Покажем, что
C
R
(x) =
∞
Y
m=1
(1 + x
m
+ x
2m
+ x
3m
+ . . . )
I
m
. (57)
Почему так? Всякий многочлен P как-то разлагается в произведение неприводимых, взяты х в некоторых сте-
пенях. У нас есть большой выбор неприводимых многочленов: I
1
видов веса 1, I
2
видов веса 2 и так далее.
Вес многочлена — это прос то е г о степень, то есть тот вклад, который он вносит в степень многочлена P . Что
касается видов, то многочленов каждого вида у нас неограниченное количество (потому что, вообще го воря,
степени сомножителей ничем не ограничены, и потому в каждой скобке бесконечное количество слагаемых).
Множитель m-го веса k-го вида, взятый в с тепени s, соо тветствует одночлену x
ms
из скобки с номером k в m-м
множителе бесконечного произведения.
А теперь начинаем подсчёт. Сворачивая прогрессии и переходя к об ратным рядам, получаем
1 − px =
∞
Y
m=1
(1 − x
m
)
I
m
. (58)
Продифференцируем это тождество, применяя формулу (55):
−p
1 − px
=
∞
X
m=1
mI
m
−x
m−1
1 − x
m
. (59)
Умножим раве нство на x:
−px
1 − px
=
∞
X
m=1
mI
m
−x
m
1 − x
m
. (60)
Выделяя целую часть в дробях, получаем
1 −
1
1 − px
=
∞
X
m=1
mI
m
1 −
1
1 − x
m
. (61)
Раскатывая слагаемые в левой и право й части в прогрессии, полу чаем
∞
X
k=1
p
k
x
k
=
∞
X
m=1
mI
m
x
m
+ x
2m
+ x
3m
+ . . .
. (62)
14

Приравнивая коэффициенты при подобных членах, получаем
p
k
=
X
m|k
mI
m
. (63)
Выведем сначала несколько простых следствий.
1
◦
Без всяких формул ясно, что I
k
> 0.
2
◦
Ясно, что I
1
= p (это многочлены вида x + a, a = 0, . . . , p − 1).
3
◦
Из 2
◦
и (63) сразу следует, что при k > 2 имеем I
k
6
p
k
−p
k
<
p
k
k
.
4
◦
Заметим, что если k — простое число, то слагаемых в сумме всего два, поэтому I
k
=
p
k
−p
k
.
5
◦
Получим оценку снизу для чисел I
k
:
p
k
= kI
k
+
X
m|k
m<k
mI
m
!
< kI
k
+
k/2
X
m=0
p
m
< kI
k
+ p
k/2
+ 1. (64)
Здесь переход «!» следует из оценки, полученной в 3
◦
. Стало быть,
I
k
>
p
k
− p
k/2+1
k
. (65)
6
◦
Из неравенства, полученного в 5
◦
, следует, что I
k
> 0, т о есть су ществуют неприводимые многочлены
любой степени.
Замечание. В курсе алгебры обычно доказывается, что над конечными полями существу ют неприводимые
многочлены с коль угодно высокой степени. Мы получили некото рое усиление э того утв е рждения, правда, не
для всех конечных полей, а только для полей F
p
.
Мы ещё получим явную формулу для вычисления I
k
, но для этого нам потребуется одна формула , очень
полезная в борьбе с производящими функциями.
1.3.5. Формула обращения Мёбиуса
Пусть f, g : N → R.
Определение. Пусть n = p
m
1
1
· . . . · p
m
k
k
— разложение числа n на простые множители. Функция
µ(n) :=
1, n = 1,
(−1)
k
, m
1
= ··· = m
k
= 1,
0 иначе.
(66)
называет ся функцией Мебиуса.
Лемма 1.22.
X
d|n
µ(d) =
(
1, n = 1,
0 иначе.
(67)
При n = 1 доказывать нечего. Пусть теперь n = p
m
1
1
· . . . · p
m
k
k
, а bn = p
1
· . . . · p
k
. Тогда
X
d|n
µ(d) =
X
d|bn
µ(d) +
X
d|n
d∤bn
µ(d). (68)
Вторая сумма равна нулю, потому что если d|n и d ∤ bn, то у d есть делители в степенях, больших 1. А первая
сумма соответствует неповторяющимся простым делителям. Количество слагаемых для s делителей, очевидно,
равно C
s
k
. Значит,
X
d|bn
µ(d) = 1 − C
1
k
+ C
2
k
− C
3
k
+ ··· = (1 − 1)
k
= 0. (69)
Итак, обе суммы в этом случае равны нулю, и лемма доказана.
Теорема 1.23 (Формула обращения Мёбиуса). Если для всех n выполнено равенство
f(n) =
X
d|n
g(d), (70)
15

то
g(n) =
X
d|n
µ(d)f
n
d
. (71)
Для всякого делителя d числа n имеем
f
n
d
=
X
b
d|
n
d
g(
b
d). (72)
Отсюда
X
d|n
µ(d)f
n
d
=
X
d|n
µ(d)
X
b
d|
n
d
g(
b
d) =
X
d,
b
d : d
b
d|n
µ(d)g(
b
d) =
X
b
d|n
X
d|
n
b
d
µ(d)g(
b
d) =
X
b
d|n
g(
b
d)
X
d|
n
b
d
µ(d) = g(n), (73)
потому что в силу леммы выживет только то слагаемое, для которого
n
b
d
= 1, то есть когда n =
b
d.
Следствие 1.3 (Формула для количества приведённых неприводимых многочле нов).
I
k
=
1
k
X
m|k
µ(m)p
k/m
. (74)
В предыдущем разделе мы уста новили формулу
p
k
=
X
m|k
mI
m
. (75)
Применим формулу обра щения к функциям f (k) = p
k
и g(k) = kI
k
. Получим
kI
k
=
X
m|k
µ(m)p
k/m
, (76)
и осталось только разделить это равенство на k.
1.3.6. Тождества Ньютона
Сейчас мы применим технику работы со степенными рядами над кольцом K[α
1
, . . . , α
n
], где K — поле. Этот
страшный объект обозначается, ясное дело, K[α
1
, . . . , α
n
]
[x]
.
Напомним, чт о многочлен f ∈ K[α
1
, . . . , α
n
] называется с имметрическим, если он инвариантен относительно
любых перестановок его переменных.
Определим степенные суммы: S
k
:= α
k
1
+ . . .+ α
k
n
. Напомним, что элементарные симметрические многочлены
от n переменных имеют вид
σ
1
= −(α
1
+ . . . + α
n
),
σ
2
= α
1
α
2
+ α
1
α
3
+ . . . ,
. . .
σ
k
= (−1)
k
X
i
1
,...,i
k
α
i
1
· . . . · α
i
k
,
. . .
σ
n
= (−1)
n
α
1
· . . . · α
n
.
(77)
Рассмотрим
S(x) =
∞
X
k=1
S
i
x
i
. (78)
Рассмотрим многочлен
σ(x) = (1 − α
1
x)(1 − α
2
x) · . . . · (1 − α
n
x) = 1 +
n
X
k=1
σ
k
x
k
. (79)
Применим формулу логарифмического дифференцирования:
Dσ(x)
σ(x)
=
n
X
k=1
D(1 − α
k
x)
1 − α
k
x
=
n
X
k=1
−α
k
1 − α
k
x
. (80)
16
Домножая на x это равенст во, получаем
xDσ(x)
σ(x)
=
n
X
k=1
1 −
1
1 − α
k
x
. (81)
Мы знаем, что
1
1 − α
p
x
= 1 + α
p
x + α
2
p
x
2
+ α
3
p
x
3
+ . . . , (82)
поэтому
1 −
1
1 − α
p
x
= − (α
p
x + α
2
p
x
2
+ α
3
p
x
3
+ . . . ), (83)
откуда
n
X
k=1
1 −
1
1 − α
k
x
= −
(α
1
+ . . . + α
n
)x + (α
2
1
+ . . . + α
2
n
)x
2
+ . . .
= −S(x). (84)
Комбинируя эту формулу с фо рмуло й (81), получаем, что
S(x)σ(x) + xDσ(x) = 0. (85)
Но продифференцировать многочлен σ(x) очень легко:
xDσ(x) =
n
X
k=1
kσ
k
x
k
, (86)
и окончательно получаем тождество
S(x)σ(x) =
n
X
k=1
kσ
k
x
k
. (87)
Приравнивая коэффициенты при степенях x, получаем формулы
0 = S
1
+ σ
1
,
0 = S
2
+ S
1
σ
1
+ 2σ
2
,
0 = S
3
+ S
2
σ
1
+ S
1
σ
2
+ 3σ
3
,
. . .
0 = S
n
+ S
n−1
σ
1
+ S
n−2
σ
2
+ . . . + S
1
σ
n−1
+ nσ
n
,
. . .
0 = S
n+i
+ S
n+i−1
σ
1
+ . . . + S
i
σ
n
.
(88)
Эти соотношения называются формулами Ньютона.
Следствие 1.4. В случае, если char K = 0, многочлены σ
i
выражаются через степенные суммы.
Следствие 1.5. Всякий симметрический многочлен однозначно выражается через степенные суммы.
1.3.7. Что ещё можно делать со степенными рядами?
Так вот, степенные ряды так и тянет подставить один в другой. Разберёмся, когда это можно делать.
Пусть у нас есть ряд A(x), и мы хотим подставить в нег о ряд B(x). Ясно, что если B(0) 6= 0, то вс ё плохо:
нулевой коэффициент результирующего ряда является бесконечной суммой, чт о не есть хорошо. Поймём те перь,
почему в случае, когда B(0) = 0, всё будет хорошо.
Действительно, если B(0) = 0, то deg
∗
B(x)
n
> n → ∞ при n → ∞, поэтому со сходимостью ряда
A
B(x)
=
∞
X
n=0
a
n
B(x)
n
(89)
проблем не будет.
Пример 3.3. В качестве примера рассмотрим последова тельность Фибоначчи. . .
17

1.3.8. Принцип включений и исключений
Пусть имеются объекты x
1
, . . . , x
N
и свойства p
1
, . . . , p
n
. Через E(m) будем обозначать число объектов,
обладающих ровно m свойствами, а через w(p
1
, . . . , p
k
) — число объе ктов, об ладающих свойств ами p
1
, . . . , p
k
.
Положим
W (k) :=
X
(i
1
,...,i
k
)
w(p
i
1
, . . . , p
i
k
). (90)
Утверждение 1.24. Имеет место формула для числа объектов, не обладающих никаким свойством:
E(0) = N − W (1) + W (2) − W (3) + . . . + (−1)
n
W (n). (91)
Расс мотрим два случая. 1
◦
Пусть x
1
не обладает никаким свойством. Тогда в лев ую часть формулы он
добавит единицу. А спра ва будем считать, что его единица в ходит в число N. 2
◦
Пусть x
1
обладает свойствами
p
i
1
, . . . , p
i
k
. Тогда вклад в левую часть есть 0. А в правую — 1 − C
1
k
+ C
2
k
+ . . . + (−1)
k
C
k
k
= (1 − 1)
k
= 0.
2. Кодирование
2.1. Общая теория кодирования и сжатия информации
2.1.1. Схемы кодирования. Коды с однозначным декодированием
Пусть заданы два алфавита A = {a
1
, . . . , a
r
} и B = {b
1
, . . . , b
q
}.
Определение. Слово в каком-либо алфавите — это конечный упорядоченный набор символов этого алфа-
вита. Множество всех слов алфавита A мы будем обозначать A
∗
.
Определение. Схема кодирования — это любое отображение ϕ : A → B
∗
, ϕ : a
i
7→ B
i
. Образ символа при
таком отображении будем называть кодом этого символа.
Такое отображение очевидным образом распространяется на множество всех слов над алфавитом A:
a
i
1
. . . a
i
s
7→ B
i
1
. . . B
i
s
. (1)
Пример 1.1. A = {a
1
, a
2
, a
3
}, B = {0, 1}. Схему кодирования зададим следующим образом:
a
1
7→ 01, a
2
7→ 010, a
3
7→ 101. (2)
Исходному слов у a
1
a
1
a
1
будет соответствовать кодовое слово 0101 01.
Определение. Будем говорить, что некоторая схема кодирования допускает однозначное декодирование, ес-
ли кодовые слова (то есть результаты кодирования) различны для любых несовпадающих кодируемых наборов.
Нетрудно заметить, что схема кодирования в предыдущем примере не допускает однозначного декодирова-
ния, так как кодовое слово 010101 соответствует одновременно двум наборам — a
1
a
1
a
1
и a
2
a
3
.
2.1.2. Неприводимые слова
Определение. Префиксной называют такую схему кодирования, в которой код ни одного из символов вход-
ного алфав ита не является началом для кода другого символа.
Замечание. Это условие является достаточным для однозначности декодирования, но не необходимым. В
качестве примера можно рассмотреть схему a 7→ 0, b 7→ 01 . Ясно, что это не префиксный код, но тем не менее
декодирование однозначно.
Определение. Слово, допускающее неоднозначное декодирование, наз ывают неприводимым , если при уда -
лении из него каких-либо символов полученное слово либо не является кодовым (то ест ь не допускает декоди-
рования вообще), либо допускает только однозначное декодирование.
Очевидно, что любой код, допуска ющий неоднозначное декодирование, содержит неприводимые слова.
Определение. Рассмотрим некоторое кодовое слово b
1
. . . b
m
, допускающее неоднозначное декодирование.
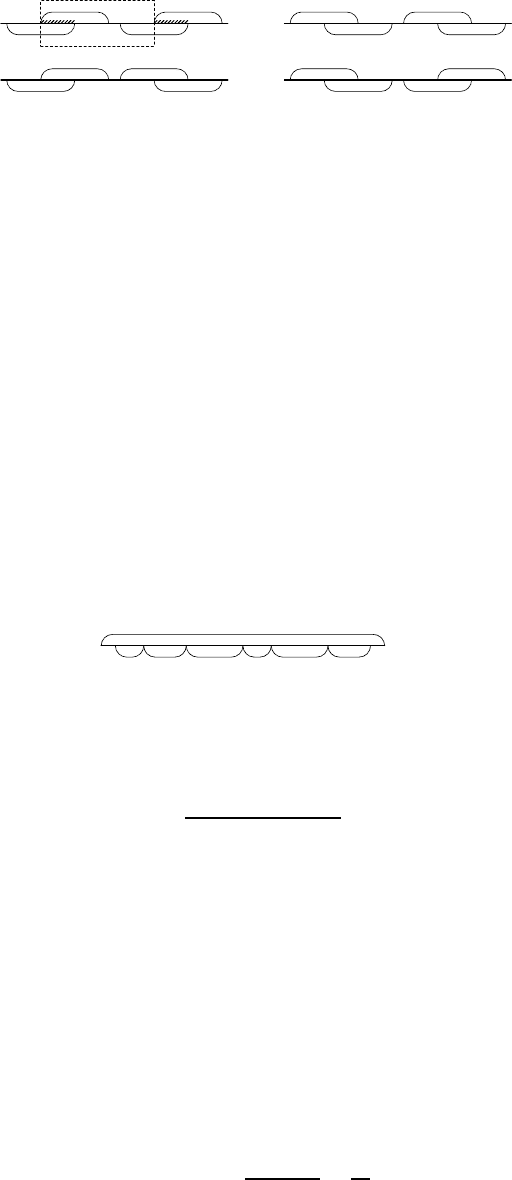
Схематически это можно изобразить следующим об разом:
a
i
1
a
i
2
a
i
3
a
i
4
a
i
5
a
i
6
a
i
7
a
j
1
a
j
2
a
j
3
a
j
4
a
j
5
a
j
6
a
j
7
a
j
8
a
j
9
Рис. 6. Примеры слов
18
Рассмотрим разбиение, полученное объединением верхнего и нижнего ра з биений, получим набор отрезков.
Если отрезок одного декодирования целиком содержится в некотором отрезке другого (как a
j
6
и a
j
8
на на-
шей схеме), его на з ы вают отрезком первого рода, иначе, то е сть если он является началом отрез ка при одном
декодировании и концом при другом (как пересечение отрезков a
i
4
и a
j
5
на рисунке) — отрезком второго рода.
Лемма 2.1 (О неприводимом слове). В неприводимом слове все отрезки второго рода различны.
Предположим противное: пусть нашлось два одинаковых отрезка второго рода. Имеются четыре воз-
можности их расположения:
а)
б)
в)
г)
Рис. 7. Возможные расположения верхних и нижних слов
Разберем случай а), а для остальных случаев рассуждения аналогичны. Совпадающие отрезки второго рода
выделены штриховкой. Удалим из слова все символы от начала первого отрезка до начала второго, и «склеим»
оставшиеся слова. Полученное таким образом сло во также будет допускать неоднозначное декодирование, а это
противоречит предположению о том, что исходное слово было неприводимым.
2.1.3. Проверка однозначности декодирования
Мы хотим получить алгоритм проверки однозначности декодирования. Именно, эта процедура будет выгля-
деть примерно так: проверяем однозначность декодиро вания кодов, полученных из слов алфавита A длины не
более N , где N зависит только от схемы кодирования, и если это так, то заключаем, что и вся схема однозначна.
Рассмотрим следующую схему кодирования: исходный алфавит A = {a
1
, . . . , a
r
}, конечный алфавит B, со-
стоящий из q символов, причем каждому символу a
i
∈ A ставится в соответст вие слово B
i
∈ B
∗
длины l
i
.
Обозначим l := l
1
+ . . . + l
r
.
Ясно, что нужно проверять только неприводимые слова. Сейчас мы покажем, что длина неприводимого
слова ограничена константой. Её-то и возьмём в качестве числа N .
Зафиксируе м некоторое слово и его код, и мы хотим выяснить, может ли этот код быть неприводимым
словом. Вначале убедимся, что оно допускает по крайней мере два декодирования. Потом выпишем оба деко-
дирования, как на рис. 6.
Под кодовым словом (или просто сло вом) будем понимать код симв ола. Посчитаем максимальное число
кодовых слов одного декодиров ания, которые одновременно попадают внутрь некоторого слов а другого деко-
дирования (см. рис. 8)
Рис. 8. Слов´а внутри другого сл´ова
. Обозначим эту величину через w.
Утверждение 2.2. Максимальная длина самого короткого слова в алфавите A, порождающего (при ука-
занной выше схеме кодирования) неприводимое слово над алфавитом B, не превосходит величины
N =
(1 + l − r)(w + 1)
2
. (3)
Рассмотрим первое длинное (не содержащееся ни в каком другом) слово. Все остальные длинные слова
начинаются с о трезков второго рода. Обозначим число длинных сло в через R, а число отрезков второго рода —
через k. Получим R = 1+k. Общее число слов, лежащих внутри других, не превосходит Rw, а число не лежащих
внутри (то есть длинных) — в точности равно R. Значит, всего не более Rw + R = R(w + 1) = (1 + k)(w + 1) слов.
Осталось оценить k. Заметим, что любой отрезок второго рода является началом некоторого длинног о слова.
Сколько может быть «начал»? Слово B
i
длины l
i
имеет l
i
−1 начало. Если рассматриваемое декодируемое слово
неприводимо, все отрезки второго рода должны быть различны, значит,
k 6
r
X
i=1
(l
i
− 1) = l − r, (4)
откуда получаем N 6 (1 + l − r)(w + 1). Здесь N = N
1
+ N
2
— число слов в обоих декодированиях. Осталось
заметить, что
min(N
1
, N
2
) 6
N
1
+ N
2
2
=
N
2
, (5)
и мы приходим к требуемой оценке.
19
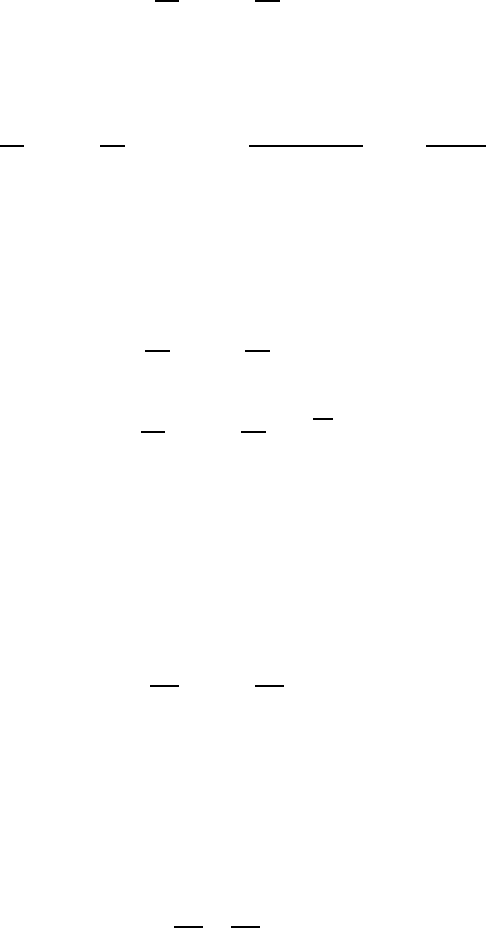
2.1.4. Неравенство Мак-Миллана
Напомним, что мы обозначаем через q количество букв в алфавите B.
Утверждение 2.3 (Неравенство Мак-Миллана). Если кодирование допускает только однозначное де-
кодирование, то
1
q
l
1
+ . . . +
1
q
l
r
6 1. (6)
Обозначим l := max
i
l
i
. Пусть Q(n, t) — число кодовых слов длины t, которые являются образами слов
длины n (вполне возможно, что какие-то Q(n, t) равны нулю). Рассмотрим
1
q
l
1
+ . . . +
1
q
l
r
n
=
X
(i
1
,...,i
n
)
1
q
l
i
1
· . . . · q
l
i
n
!
=
ln
X
t=1
Q(n, t)
q
t
. (7)
Переход, отмеченный «!» следует в точности из того, что схема однозначно декодируется, и потому имеется
инъективное соответствие
(i
1
, . . . , i
n
) 7→ a
i
1
. . . a
i
n
7→ B
i
1
. . . B
i
n
. (8)
Всего имеется q
t
слов длины t, поэтому во всяком случае Q(n, t) 6 q
t
, следовательно
1
q
l
1
+ . . . +
1
q
l
r
n
6 ln, (9)
откуда
1
q
l
1
+ . . . +
1
q
l
r
6
n
√
ln. (10)
Переходя к пределу при n → ∞, получаем неравенство (6).
Теорема 2.4. Для любой схемы кодирования B, имеющей однозначное декодирование, найдется префиксная
схема
b
B, имеющая тот же набор длин слов, что и схема B.
Упорядочим по возрастанию длины l
i
кодовых слов из B, то есть будем считать, что l
1
6 . . . 6 l
r
. Пусть
набор {λ
i
} — это отсортированный по возрастанию набор {l
i
}, из которого выкинуты дубликаты (и таким
образом, λ
1
< . . . < λ
t
), а ν
i
— количество дубликатов длины λ
i
.
В этих обозначениях (собирая одинаковые слагаемые) нераве нство Мак-Миллана переписыв ается следующим
образом:
ν
1
q
λ
1
+ . . . +
ν
r
q
λ
r
6 1. (11)
Будем ст роить новую схему
b
B последовательно. Для начала включим в неё ν
1
различных слов длины λ
1
.
Это не противоречит её префиксности. В силу условия оптимальности, в ней должно быть ещё ν
2
слов длины
λ
2
. Чтобы префиксность не нарушилась, мы можем брать не любые слова длины λ
2
, коих всего имеется q
λ
2
штук, а только те, которые не начина ются с уже выбранных. Таких имеется ν
1
·q
λ
2
−λ
1
штук, потому что каждое
из первых ν
1
кодовых слов можно расширить до слова длины λ
2
именно q
λ
2
−λ
1
способа ми. Таким образо м,
остаётся не более q
λ
2
− ν
1
· q
λ
2
−λ
1
кодовых слов. Но их хватит, потому что их нужно ν
2
штук, то есть должно
быть выполнено неравенство ν
2
6 q
λ
2
− ν
1
· q
λ
2
−λ
1
. А его можно переписать по-другому:
ν
1
q
λ
1
+
ν
2
q
λ
2
6 1. (12)
А это уже прямое следствие неравенства (11). Значит, нужное количество слов длины λ
2
тоже найдётся. Далее,
при выборе слов длины λ
3
нам запреще но ν
1
· q
λ
3
−λ
1
+ ν
2
· q
λ
3
−λ
2
слов, но, опять-таки в силу неравенства (11)
мы их найдём, и так далее.
В итоге мы получи префиксный код
b
B, у которого набор длин кодовых слов тот же.
Следствие 2.1. При рассмотрении любой схемы кодирования всегда можно считать, что она префиксная.
2.1.5. Оптимальные коды. Код Хаффмана
Как и рань ше, рассматриваем следующую схему кодирования: исходный алфавит A = {a
1
, . . . , a
r
}, конечный
алфавит B, состоящий из q символов, причем каждому символу a
i
ставится в соответствие слово B
i
длины l
i
.
Теперь наша цель — построить в некотором смысле оптимальный код. Пусть мы кодируем некоторый текст
(последоват е льность символов исходного алфавита). Ясно, что если какие-то символы очень часто встречаются
в э том тексте, то будет хорошо, если кодовые слова, им соо тветст вующие, будут иметь маленькую длину, и
наоборот. Будем считать, что нам известны вероятности p
i
появления в тексте кодируемых символов a
i
.
20