Koster A., Munoz X. Graphs and Algorithms in Communication Networks
Подождите немного. Документ загружается.

406 L. Carr-Motyckova et al.
TotSPI(G)=
∑
u,v∈V
∑
e∈SPuv
Cov(e)
In other words TotSPI(G) is a sum of interferences of shortest paths (in the num-
ber of hops) between all node pairs in a graph. The average interference for all short-
est paths is defined as TotSPI(G) divided by the number of node pairs connected in
G.
The maximum interference difference metric is defined as the largest difference
in interference between IoptPuv in the original graph and IoptPuv in the graph that
is the output of a topology control algorithm.
The Average Path Interference (API) algorithm [16] consists of two steps: First a
Gabriel subgraph of the original graph is computed. A Gabriel Graph is defined as
follows: there is an edge between u and v if there is no vertex w in the circle with
diameter chord (u,v). The next step is to remove links that lead to high interference.
The coverage of each link can be calculated locally. If a link can be replaced with
two links that together have smaller coverage, it is removed. The graph produced by
the algorithm is an energy spanner. For the proof we refer to [16]. The API algorithm
was compared to XTC and LISE algorithms by simulations. The API topology gives
results close to those of the XTC algorithm, and far better than LISE in the following
measures:
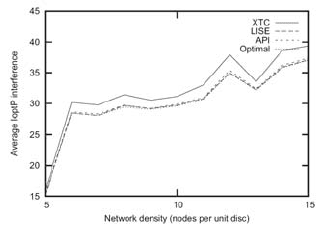
Using the average interference-optimal path metric, the API algorithm generally
gives the best results. Both the LISE and the API algorithms preserve almost all
interference-optimal paths (cf. Figure 16.1). When considering the average path in-
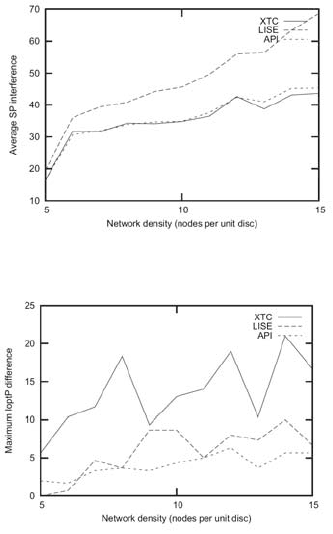
terference with respect to the shortest path, API and XTC give a lower interference
than LISE (cf. Figure 16.2). Using the maximum interference difference metric, the
API topology has lower interference than both LISE and, especially, XTC algo-
rithms (cf. Figure 16.3).
Fig. 16.1 The average interference-optimal path interference
16 Topology Control and Routing in Ad Hoc Networks 407
Fig. 16.2 The average shortest-path interference
Fig. 16.3 The biggest difference between interference in a interference-optimal path compared to
the interference-optimal path in the original topology
16.3 Energy Aware Scatternet Formation and Routing
In this section we consider energy-efficient routing in Bluetooth networks. These
networks must obey certain rules imposed on their topology. Whenever two Blue-
tooth devices communicate, one must assume the role of a master and the other the
role of a slave. Together they form a piconet. Each piconet consists of one master
and an unlimited number of slaves, but there can only be at most seven active slaves
simultaneously. If there are more than seven slaves in a piconet, some of them must
therefore be parked, i.e., inactive. A collection of piconets is called a scatternet.
In order to communicate between piconets, two nodes from neighboring piconets
must get connected. A node can switch between master and slave mode on the time
bases. In the same manner, a node can change a membership in different piconets at
different time slots.
Recently, there has been an increased interest in routing algorithms in ad hoc
networks that take the energy levels of the nodes into account. An example of
an energy-aware routing algorithm is the Capacity-competitive (CMAX) algorithm
[17], where each link in the network is assigned a weight. The weight of a link in-
creases with the energy consumed by the sending of a unit message over the link,
408 L. Carr-Motyckova et al.
and with the increase of energy utilization of the node when it transmits message
m over the link. The shortest path with respect to link weights is selected by the
CMAX algorithm. This algorithm requires that each node knows the energy utiliza-
tion of the other nodes in the network. In order to spread the power information
through the network, each node periodically broadcasts its power information to the
nearest nodes.
The max-min zP
min
algorithm [20] finds paths that avoid nodes with only a small
fraction of their battery power remaining. The goal is to find the path with the max-
imal minimal fraction of remaining power after the message is transmitted. How-
ever, the path must also not use more power than a constant factor of the smallest
possible power consumption P
min
. This results in finding a path that avoids using up
the power of individual nodes, while still maintaining an upper bound on the total
power consumption of the path.
Both of the above algorithms require that each node have full knowledge of the
topology of the network, an assumption that is not realistic in larger networks.
Another approach is to extend existing on-demand algorithms in order to com-
pute energy-efficient paths. On-demand routing algorithms create a route only after
a demand for the routing of a message. The authors in [25] enhance the Ad hoc On
Demand Distance Vector (AODV) routing protocol by adding energy information
in the route request messages. In this way, the destination node can decide on the
path with the lowest energy cost. The extended AODV algorithm only considers to-
tal energy cost and estimated bit error rates in order to select the path; it does not
consider the amount of energy that remains in the nodes.
Wang et al. [33] present a power-aware on-demand routing protocol that takes
the remaining energy of the nodes into account. The routing algorithm anticipates
energy requirements of a transmission and makes energy reservation for it. The
metric used for a path selection takes to account the shortest path and the maximum
lifetime of the network.
Routing in Bluetooth networks presents more challenges than routing in general
ad hoc networks. For every communication between two Bluetooth devices they
must form a master-slave relationship. A Bluetooth node can only take part in one
such relationship at a time. Therefore, creating a path between two Bluetooth nodes
is not a trivial problem, especially if there are several simultaneous communications
in the network that intersect each other. A proactive algorithm that creates a routing
path in scatternet formation before there is a demand for transmission is described
in [37]. A single node initiates the construction of a Bluetree. The root node assumes
the role of master and selects all its neighbors as slaves, and the slaves in turn assign
themselves as masters in new piconets and search for unassigned neighbors to be
their slaves. This procedure is repeated until the entire network is covered by the
Bluetree.
In [21] the authors use location information in order to produce a planar sub-
graph, which can improve the performance of routing algorithms. This optional step
is followed by assigning roles to the Bluetooth nodes.
Recently, there has been work that aims to extend the lifetime of scatternets by
considering the amount of power remaining for each node [36]: when a node wants
16 Topology Control and Routing in Ad Hoc Networks 409
to initiate a communication, it sends out a route request to the destination by flood-
ing the network. When the destination receives the request it responds with a route
reply. To form the temporary scatternet between the source and the destination, the
destination sets its role to master, and for the rest of the nodes in the path every
other node is a master while the other nodes are slaves in two different piconets.
No node needs to know about the topology of the entire network. This approach
has a relatively simple mechanism to avoid low-powered nodes: either a node has
enough energy to forward a message or it does not. When a node is reached by a
route request there is no way to know from which path the packet comes and what
the energy condition of the entire path is.
In the following paragraph we consider routing data between scatternets in a
Bluetooth network over a path that consumes less energy compared to other possi-
ble paths [15]. The two main differences between the algorithm presented in [15]
and Wang’s algorithm is that the latter does not take the total power cost of paths
into account, and the cost metric does not change over time to reflect the changing
amount of energy in the nodes. In [15] a creation of a routing path over a piconet
sequence is considered. The on-demand scatternet formation and routing algorithm
create a local, temporary scatternet that forms a path between the sending and re-
ceiving nodes for the duration of the data transfer. The scatternet is created just for
the purpose of a single transmission between the sender and the receiver, and the
existence of the scatternet (a sequence of piconets) is limited just to the time of data
transmission. It means that the topology (definition of piconets) is disregarded after
the transmission is completed.
The routing algorithm starts by flooding the network with a request for a route
(route request procedure). Several alternative paths between the source and the des-
tination are found, while measuring the energy parameters for each path. The idea
is to choose a path that avoids nodes that have a small amount of energy left, while
still keeping the total energy cost of the path as low as possible. When evaluating
the quality of a path (with respect to the energy levels in the nodes), the following
definitions will be used:
• the potential remaining power of every link (i, j) in the path as
rp
ij
= p
i
−e(m)
ij
where p
i
is the power level at node i, and e(m)
ij
is the power needed to send the
message m directly from i to j.
• the amount of energy needed to send the message m over the path P: the metric
that represents the energy consumption of the path P is defined as
Pow(P)=
n
∑
i=1
e(m)
l
i
where n is a sequence number of the last node in the path and l
i
is the ith link in
the path.
410 L. Carr-Motyckova et al.
The minimum Min(P)=min
l∈P
rp
l
value for each path received during the route
request procedure S is computed as the minimum potential remaining power of all
links in path P. The threshold value rp
threshold
is defined as a median of Min(P) over
all received paths in S. The basic idea is to avoid nodes which would be drained of
power if they were to forward the data message. In order to achieve that, all paths
P ∈ S such that
Min(P) < rp
threshold
are canceled. Of the remaining paths in S, the path P with the lowest Pow(P) is
chosen.
In order to evaluate the algorithm, simulations were performed to compare it with
a routing algorithm that always selects the path that consumes the least amount of
energy. Each node started with the same amount of energy. At every time step, data
transmissions between randomly selected sender and receiver nodes were generated.
This was repeated until the first node in the network had depleted all its power. The
results from the simulations showed that the algorithm in [15] extends the lifetime of
the network compared to choosing energy-optimal paths without taking the power
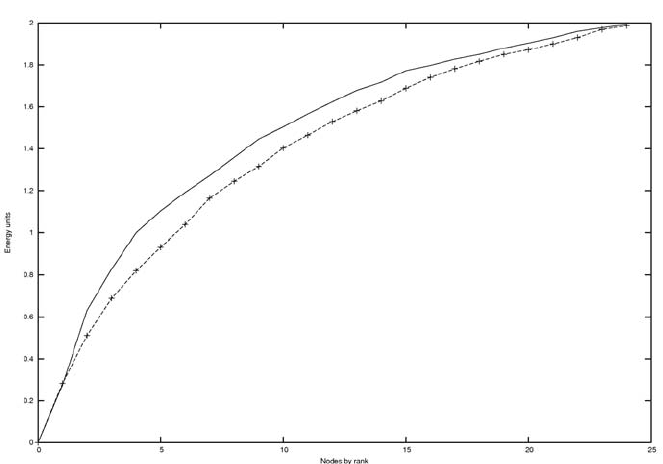
level of the nodes into account. Figure 16.4 show the average distribution of energy
in the network when the first node had depleted its power. The presented algorithm,
represented by the dashed line in the graph, had consumed more energy (at least
partly due to the fact that it had routed more messages), but the load had been spread
somewhat more evenly through the network.
Fig. 16.4 Remaining energy in nodes
16 Topology Control and Routing in Ad Hoc Networks 411
16.4 Bandwidth-Constrained Clustering
The purpose of clustering algorithms is to divide the original network graph into
non-overlapping subgraphs. The resulting structure is used for different control
functions, including routing. The control functions decrease interference and the
amount of global traffic, and therefore decrease energy consumption of the network.
In this paragraph we consider only clusters, where the slaves are direct neighbors
of its cluster head. Recent work in clustering for wireless networks began with the
work of Gerla and Tzu-Chieh Tsai [10]. In their algorithms, if a node hears from a
cluster head with a lower ID than itself, it resigns and uses that node as a cluster head
instead. Another version uses the degree of the nodes. The idea is that nodes with a
high degree are good candidates for cluster heads, since the resulting clusters will
be larger. However, even small changes in the network topology can result in large
changes in the degree of the nodes. This means that the cluster heads are not likely to
stay as cluster heads for a long time, and the clustering structure becomes unstable.
On the other hand, using the Lowest-ID algorithm, the nodes with a low ID stay
as cluster heads most of the time. This results in an unfair distribution of load that
could lead to some nodes losing power prematurely. Amis and Prakash [1] present
additions to these clustering mechanisms that help avoid cluster head exhaustion by
providing virtual IDs to the nodes.
An algorithm that makes it possible to choose clusters with a radius r larger than
1(theslavesarer hops away from its head) is presented in [2]. This algorithm pro-
duces large clusters that are relatively stable compared to the previously mentioned
algorithms. This algorithm also uses the node’s ID values when forming the clusters.
First, the nodes set their winner value (possible leader ID) to be their ID number,
and broadcast it. If one node receives a larger winner value than its own, it switches
to the new winner value instead. This procedure is repeated r times. The result is
that the larger ID values spread through the network. The process is repeated, ex-
cept that lower winner values now overtake larger ones. The purpose is to achieve
a balance in the cluster sizes, instead of having the clusters with the largest IDs be
much larger than the others. If clusters of constant size is the primary objective,
this algorithm is the only one that guarantees the property. In [9], another algorithm
creates a cluster structure that is, with high probability, a constant approximation of
the optimal solution. In this case, an optimal cluster structure is the one that uses the
lowest number of clusters of radius r to cover the network at this time.
McDonald and Znati [23] present an algorithm that forms clusters of nodes that
have sufficient probability to stay connected during a specific time interval. The al-
gorithm requires that movements of nodes in an ad hoc network are predictable,
something which might not always be true. In [22], Lin and Gerla present an al-
gorithm that dynamically maintains clusters in a dynamic environment. A cluster-
based energy conservation algorithm including the cluster formation is described in
Xu et al. [35]. Ryu, Song, and Cho [30] suggest that by using a distributed heuris-
tic clustering scheme, the transmission power can be minimized. A similar problem
of power control supported by clustering is solved in Kawadia and Kumar [18]. A
412 L. Carr-Motyckova et al.
hierarchical clustering proposed by Bandyopadhyay and Coyle [3] is used to save
energy in wireless sensor networks.
Most existing clustering algorithms create new clustering structures from scratch
after a specified time interval in order to maintain cluster structure properties. In [14]
the maintenance function is interleaved with the traditional clustering function. The
algorithm consists of two parts, the clustering part, where a clustering structure is
created from scratch, and the maintenance part, where the existing clustering struc-
ture is modified where necessary.
The clustering part of the algorithm starts with a broadcast phase. Nodes broad-
cast their leader values (initialized to the node’s ID) to all the neighbors, and wait
for broadcasts from all of them. When a node receives a value that is higher than its
own, it sets its leader value to the received value. When all nodes have exchanged
their messages, one round of the broadcast phase is completed. There are r broad-
cast phases, where r, a parameter of the algorithm, is the maximum radius of the
clusters that are created. At the end of the last broadcast phase, the larger ID values
have spread through the network.
Once the clustering part is completed, the maintenance part of the algorithm is
performed. If the path to the cluster leader, which is checked by regular messages,
does not exist anymore, the node will try to find a new path to a cluster leader
through one of its reachable neighbors. Otherwise, it becomes an orphan node and
starts up the clustering part of the algorithm.
The algorithm by Johansson and Carr [14] has time complexity of O(r), where
no node is more than r hops away from the cluster head. Since r is likely to be a very
small constant, this is an acceptable complexity. The overall message complexity is
low, due to the nature of the algorithm and the maintenance part of the algorithm.
The number of messages depends largely on the radius of the clusters created.
While it might be advantageous to create clusters with radius larger than 1, it is
important to avoid unnecessary broadcasting. The algorithm only uses one broad-
cast phase. Clusters created by the algorithm have limited radius. The properties of
different clustering algorithms covered here are summarized in Table 16.1.
16.5 Localizing Using Arrival Times
In this section, the problem of localizing random sensor networks is considered.
There are two approaches: the first one uses information about the reachable neigh-
bors and the second one uses the arrival times of messages within the network.
We shortly explain the first approach. If the sensors of a network are laid out on
the plane, then some of the nodes form the outer boundary of the network. There
may be more boundaries within the network, due to some holes. These boundary
nodes may be identified, because they have a lower degree than the inner nodes. In
a second step each node may compute the minimal number of hops to any border
node. The nodes where the distance to the border is maximal compared to the local
neighbors form the backbone of the structure of the network. Now disjoint groups

16 Topology Control and Routing in Ad Hoc Networks 413
Table 16.1 Summary of different clustering algorithms
Algorithm Properties Complexity Strengths Weaknesses
Lowest-ID
(LCA2) [10]
Cluster head
selection based on
node ID.
Cluster head is
directly linked to
any other node in
the cluster.
Constant time
complexity,
message
complexity
increase with
denseness of
graphs.
Fast and simple
algorithm.
Relatively stable
clusters.
Small clusters.
Some cluster
heads likely to
remain for long
time.
Highest-
connectivity
[10]
Cluster head
selection based on
highest degree,
otherwise same as
LCA2.
Same as LCA2. The nodes with
highest degree are
good candidates
for cluster heads.
Very unstable
clusters.
Max-min d-
cluster [2]
Cluster radius d,
where d is a
constant.
O(d) time and
storage
complexity.
Large and stable
clusters.
High number of
messages sent.
Discrete mobile
centers. [9]
One-radius
clusters are
produced. The
number of clusters
is a constant-factor
approximation of
the smallest
possible number.
O(sn) storage
complexity, where
s is usually small,
but can be up to n.
Time complexity
O(loglogn).
Close to optimal
clustering structure
with respect to
number of clusters.
No simulations to
show cluster
stability of the
algorithm.
Hierarchical
[31]
No fixed diameter
of each cluster.
Cluster size
< k,2k −1 >,
where k is a
constant.
Time complexity
O(E).
Guaranteed upper
and lower bound
on cluster size.
Slow algorithm.
Cluster radius can
be up to k.
Adaptive clus-
ters [23]
Created clusters
should be
connected in time t
with probability
α
.
Undefined.
α
and t can be
varied in order to
adapt to different
mobility rates.
Difficult to predict
future
connectivity.
Maintenance Added
maintenance
phase.
O(r) where r is
the radius of the
clusters.
Repairs lost
connections.
Small clusters.
of nodes may be formed using some of the backbone nodes. There are two reasons
to form these disjoint groups. The first is that each node has precisely one leader.
Secondly, it is now a more simple task to get the overall topology of the network.
The topology of the groups provides enough information to localize the nodes of the
network. This nice technique is presented in a series of papers [5–7, 19].
A second approach is presented in [26]. Random instances of sensor networks
are studied inside a square area. The power of transmission P
s
is fixed for each sen-
sor. A small percentage of the sensors called Anchors are assumed to be equipped
with GPS capabilities. Hence, those sensors have the knowledge of their actual po-
sition; all other ones are assigned a random estimation of their position. Moreover,
414 L. Carr-Motyckova et al.
sensors are equipped with Time of Arrival (ToA) capabilities, i.e., they are able to es-
timate their distances to the corresponding neighbors. The network is asynchronous.
Hence, sensors can be in one of two different operational states: sleep and wake.In
the sleep state a sensor can receive the position communications from other sensors,
and computes its new position accordingly. In the wake state a sensor communicates
the information concerning its estimated position to its neighborhood. Each sensor
is assumed to operate for a predetermined time interval.
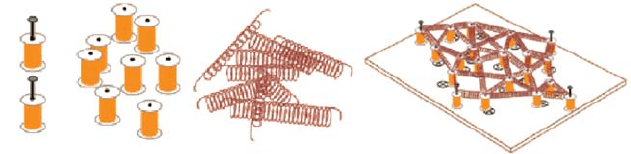
anchors masses springs the composed system
Fig. 16.5 Mass-spring system. Circles on the board of the composed system represent the real
position of the corresponding masses
The modeling can be seen like a mass-spring system; see Figure 16.5. Sensors
are masses. Masses representing anchors are well positioned in the area, while all
others have a random estimation of their actual position. When a sensor performs a
transmission, receivers can derive the distance at which the sender should be. This is
accomplished by connecting senders and receivers by means of springs. The resting
length of the spring is the length estimated by the ToA equipment, while the length
assigned is equivalent to the distance of the estimated positions of the masses. Due
to this, masses are subject to a set of forces generated by the springs. These forces
tend to move the whole system to a final configuration of equilibrium. This is ac-
complished by means of successive transmissions from each sensor of its estimated
position until the desired equilibrium is reached. That is, forces acting on the masses
are smaller than a fixed threshold. As in a real mass-spring system, the algorithm
makes use of two main parameters, i.e., the damper and the elastic constants of the
springs. The former reflects the stability of springs with respect to oscillations. The
latter reflects the ability of springs to recover and return to their original shape after
being stressed or deformed. Those two parameters must be well tuned in order to
obtain good performances of the convergence process to the equilibrium.
The Localization Algorithm exploits a framework that computes the dynamics of
mass-spring systems. The algorithm, from now on called Basic Localization algo-
rithm (BL), is composed of two phases: an Initialization phase and an Propagation
phase.
In particular, in the Initialization phase a random distribution of sensors and an-
chors is simulated. Each sensor s
i
computes the set N
s
i
of sensors within its trans-
mission range. Then, for each s
j
∈ N
s
i
, a spring with endpoints s
i
and s
j
is created.
16 Topology Control and Routing in Ad Hoc Networks 415
Initially, every anchor a
i
communicates its position to each sensor s
j
∈ N
a
i
in
order to give a first rough estimation of the sensors’ positions. Then, each informed
sensor communicates its estimated position to its neighbors that have not estimated
their position yet. The Initialization phase ends when all sensors have an estimation
of their positions. The obtained configuration will be referred as the Initial Config-
uration.
The Propagation phase computes the dynamics of the mass-spring system. Each
mass s
i
is subject to an internal force F
s
i
that is the result of the forces generated
by each spring connected to s
i
. At each time step, each mass s
i
modifies its position
according to the internal force F
s
i
. At the end of the Propagation phase, the final con-
figuration of the mass-spring system approximates the Target Configuration, where
the F
s
i
acting on each mass s
i
is close to zero. The Propagation phase ends when
the force acting on each mass is less than a given threshold F
toll
.
The BL algorithm can be modified in order to minimize the number of sensor
transmissions needed to compute the Target Configuration. The gain with respect to
the time required by BL to converge is even more considerable when a ±1% error
of the sensors’ ToA equipment is considered.
The following sensor localization strategies were proposed in order to improve
the BL algorithm:
• AAD, Ad Hoc Anchor Deployment strategy: a limited number
λ
of anchors are
deployed on the border of the square area.
• DES, Dynamic Elastic constant Strengthening strategy: springs connecting at
least one anchor have the elastic constants increased by a factor
γ
> 1. Therefore,
anchors have more influence in the localization problem computation.
• VA , Virtual Anchors strategy: if a sensor does not change its position for a given
successive number of steps T, its status is moved to anchor.
• CA, Computed Anchors strategy: if a sensor has some fixed number K of anchors
in its neighborhood, it computes its position from the positions of those anchors
and becomes an anchor itself.
In [26], comparisons among strategies and combinations of such strategies have
been evaluated for hundreds of instances under different assumptions with respect
to the density of the network and the percentage of anchors.
16.6 Conclusions
In this chapter we have discussed selected algorithmic topics in the area of mobile
ad hoc networking. In total, four topics were discussed.
In contrast to most of the related work, we studied in Section 16.2 at the interfer-
ence of entire paths instead of interference of individual edges or nodes. Three new
interference metrics that aim to reflect the interference of the entire network have
been presented. A new topology control algorithm that produces an energy-spanning
graph is also presented.