Kline R.B. Principles and Practice of Structural Equation Modeling
Подождите немного. Документ загружается.


154
7
Estimation
This chapter is organized into three main parts. Described in the first is the workhorse
of SEM for the analysis, maximum likelihood (ML) estimation. It is the default method
in most SEM computer tools and the most widely used method for analyses with con-
tinuous outcomes. Possible things that can go wrong in the analysis are considered
and suggestions are offered about how to deal with these challenges. In the second
major part of this chapter, how to interpret model parameter estimates is demonstrated
through a detailed analysis of a recursive path model. Alternative estimation methods
for outcomes that are not continuous are considered in the third part. The concepts and
skills reviewed here will help to prepare you to learn about hypothesis testing in SEM,
the subject of the next chapter.
MaXIMuM lIkelIhood estIMatIon
The method of ML estimation method is the default in most SEM computer programs,
and most structural equation models described in the literature are analyzed with this
method. Indeed, use of an estimation method other than ML requires explicit justifica-
tion (Hoyle, 2000).
description
The term maximum likelihood describes the statistical principle that underlies the der-
ivation of parameter estimates; the estimates are the ones that maximize the likelihood
(the continuous generalization) that the data (the observed covariances) were drawn
from this population. It is a normal theory method because multivariate normality is
assumed for the population distributions of the endogenous variables. Only continuous
variables can have normal distributions; therefore, if the endogenous variables are not

Estimation 155
continuous or if their distributions are severely non-normal, then an alternative estima-
tion method is needed.
Most forms of ML estimation in SEM are simultaneous, which means that the esti-
mates of model parameters are calculated all at once. Thus, ML estimation is a full-
information method. When all statistical requirements are met and the model is cor-
rectly specified, ML estimates in large samples are asymptotically unbiased, efficient,
and consistent.
1
In this sense, ML estimation has an advantage under these ideal condi-
tions over partial-information methods that analyze only a single equation at a time.
An example of the latter is two-stage least squares (TSLS), which was used in the late
1970s to estimate nonrecursive path models before the advent of programs such as LIS-
REL. Nowadays, ML estimation is generally used to analyze nonrecursive models. How-
ever, the TSLS method is still relevant for SEM—see Topic Box 7.1. Implications of the
difference between full- versus partial-information methods when there is specification
error are considered later in this chapter.
The criterion minimized in ML estimation, or the fit function, is related to the
discrepancy between sample covariances and those predicted by the researcher’s model.
The mathematics of ML estimation are complex, and it is beyond the scope of this sec-
tion to describe them in detail—see Nunnally and Bernstein (1994, pp. 147–155), Ferron
and Hess (2007), or Mulaik (2009, chap. 7) for more information. There are points of
contact between ML estimation and more standard methods. For example, ordinary least
squares (OLS) and ML estimates of coefficients in multiple regression (MR) analyses are
basically identical. Estimates of error variances may differ slightly in small samples, but
the two methods yield similar results in large samples.
sample variances
One difference between ML estimation and more standard statistical techniques con-
cerns estimation of the population variance σ
2
. In standard techniques, σ
2
is estimated
in a single sample as s
2
= SS/df where the numerator is the total sum of squared devia-
tions from the mean and the denominator is the overall within-group degrees of free-
dom, or N – 1. In ML estimation, σ
2
is estimated as S
2
= SS/N. In small samples, S
2
is
a negatively biased estimator of σ
2
. In large samples, however, values of s
2
and S
2
are
similar, and they are asymptotic in very large samples.
The implementations of ML estimation in some SEM computer programs, such as
Amos and Mplus, calculate sample variances as S
2
, not s
2
. Thus, variances calculated
as s
2
using a computer program for general statistical analyses, such as SPSS, may not
exactly equal those calculated in an SEM computer program as S
2
for the same data.
Check the documentation of your SEM computer tool to avoid possible confusion about
this issue.
1
A consistent estimator is one where increasing the sample size increases the probability that the estimator
is close to the population parameter, and an efficient estimator has a low error variance among results from
random samples.

156 CORE TECHNIQuES
toPIC BoX 7.1
two-stage least squares estimation
The method of two-stage least squares (TSLS) estimation provides a way to get
around the requirement of ordinary least squares (OLS) estimation that the resid-
uals are uncorrelated with the predictors (Chapter 2). The TSLS technique is
still widely used today in many disciplines, such as economics. Many computer
programs for general statistical analyses, including SAS and SPSS, have TSLS
procedures. Some SEM computer tools, such as LISREL, use a special form of
TSLS for latent variable models (Bollen, 1996) to calculate initial estimates of
model parameters, or start values. In my experience, the TSLS-generated start
values in LISREL generally perform well even for nonrecursive models.
For nonrecursive path models, TSLS is nothing more than OLS but applied in
two stages. The aim of the first stage is to replace a problematic causal variable
with a newly created predictor. A “problematic” causal variable has a direct
effect on an outcome variable and also covaries with the disturbance of that
outcome variable (i.e., a predictor is correlated with the residuals). Variables
known as instruments or instrumental variables are used to create the
new predictors. An instrument has (1) a direct effect on the problematic causal
variable but (2) no direct effect on the outcome variable. That is, the instrument
is excluded from the equation of the criterion. Note that both conditions are
given by theory, not statistical analysis. An instrument can be either exogenous
or endogenous. Because exogenous variables are assumed to be uncorrelated
with all disturbances, exogenous variables are good candidates as instruments.
In a direct feedback loop, the same variable cannot serve as the instrument for
both variables in that loop. Also, one of the variables does not need an instru-
ment if the disturbances of variables in the loop are specified as uncorrelated
(Kenny, 2002).
The TSLS method works as follows. The problematic causal variable is
regressed on the instrument. The predicted criterion variable in this analysis will
be uncorrelated with the disturbance of the outcome variable. When similar
replacements are made for all problematic causal variables, we proceed to the
second stage of TSLS, which is just ordinary OLS estimation (multiple regression)
conducted for each endogenous variable but using the predictors created in the
first step whenever the original ones were replaced.
As an example, look back at Figure 6.2(b). This nonrecursive path model
specifies two direct causes if Y
1
, the variables X
1
and Y
2
. From the perspective
of OLS estimation, Y
2
is a problematic causal variable because it covaries with
the disturbance of Y
1
. This model-implied association is represented in Figure
6.2(b) by the path
D
2
D
1
→ Y
1

Estimation 157
Iterative estimation and start values
Computer implementations of ML estimation are typically iterative, which means that the
computer derives an initial solution and then attempts to improve these estimates through
subsequent cycles of calculations. “Improvement” means that the overall fit of the model
to the data gradually improves. For most just-identified models, the fit will eventually be
perfect. For overidentified models, the fit of the model to the data may be imperfect, but
iterative estimation will continue until the improvements in model fit fall below a pre-
defined minimum value. When this happens, the estimation process has converged.
Iterative estimation may converge to a solution more quickly if the procedure is
given reasonably accurate start values, or initial estimates of the parameters. If these
initial estimates are grossly inaccurate—for instance, the start value for a path coef-
ficient is positive when the actual direct effect is negative—then iterative estimation
may fail to converge, which means that a stable solution has not been reached. Iterative
estimation can also fail if the covariance matrix is ill scaled (Chapter 3).
Computer programs typically issue a warning if iterative estimation is unsuccess-
ful. When this occurs, whatever final set of estimates was derived by the computer war-
rants little confidence. Some SEM computer programs automatically generate their own
start values. It is important to understand, however, that computer-derived start values do
not always lead to converged solutions. Although, the computer’s “guesses” about initial
estimates are usually pretty good, sometimes it is necessary for you to provide better
ones in order for the solution to converge, especially for more complex models. The
guidelines for calculating start values for structural models presented in Appendix 7.A
may be helpful. Another tactic is to increase the program’s default limit on the number
of iterations to a higher value, such as from 30 to 100. Allowing the computer more
“tries” may lead to a converged solution.
In words, the disturbance of Y
2
, or D
2
, covaries with the disturbance of Y
1
, or
D
1
. Because D
2
is part of Y
2
, this means that Y
2
is correlated with D
1
. Note that
there is no such problem with X
1
, the other causal variable for Y
1
. The instrument
here is X
2
because it is excluded from the equation of Y
1
and has a direct effect
on Y
2
, the problematic causal variable (see Figure 6.2(b)). Therefore, we regress
Y
2
on X
2
in a standard regression analysis. The predicted criterion variable from
this first analysis,
ˆ
Y
2
, replaces Y
2
as a predictor of Y
1
in a second regression
analysis where X
1
is the other predictor. The regression coefficients from the sec-
ond regression analysis are taken as the estimates of the path coefficients for the
direct effects of X
1
and Y
2
on Y
1
. See James and Singh (1978) and Kenny (1979,
pp. 83–92) for more information about TSLS estimation for path models. Bollen
(1996) describes variants of TSLS estimation for latent variable models.

158 CORE TECHNIQuES
Inadmissible solutions and heywood Cases
Although usually not a problem when analyzing recursive path models, it can happen
in ML estimation and other iterative methods that a converged solution is inadmis-
sible. This is most evident by a parameter estimate with an illogical value, such as Hey-
wood cases (after H. B. Heywood; e.g., Heywood, 1931). These include negative variance
estimates (e.g., an unstandardized error variance is –12.58) or estimated correlations
between factors or between a factor and an indicator with absolute values > 1.0. Another
indication of a problem is when the standard error of a parameter estimate is so large
that no interpretation seems plausible (e.g., 999,999.99). Some causes of Heywood cases
(Chen, Bollen, Paxton, Curran, & Kirby, 2001) include:
1. Specification errors;
2. Nonidentification of the model;
3. The presence of outliers that can distort the solution;
4. A combination of small sample sizes (e.g., N < 100) and only two indicators per
factor;
5. Bad start values; or
6. Extremely low or high population correlations that result in empirical underi-
dentification.
An analogy may help to give a context for Heywood cases: ML estimation (and
related methods) is like a religious fanatic in that it so believes the model’s specifica-
tions that it will do anything, no matter how implausible, to force the model on the data.
Some SEM computer programs do not permit certain Heywood cases to appear in the
solution. For example, EQS does not allow the estimate of an error variance to be less
than zero; that is, it sets a lower bound of zero (an inequality constraint) that prevents
a negative variance estimate. However, solutions in which one or more estimates have
been constrained by the computer to prevent an illogical value should not be trusted.
Instead, you should try to determine the source of the problem instead of constraining
an error variance to be positive and then rerunning the analysis.
In your own analyses, always carefully inspect the whole solution, unstandardized
and standardized, for any sign that it is inadmissible. Computer programs for SEM gen-
erally issue warning messages about Heywood cases or other kinds of problems with
the estimates, but they are not foolproof. It can therefore happen that the solution is
inadmissible but no warning was given. It is you, not the computer, who provides the
ultimate quality control check for admissibility.
scale Freeness and scale Invariance
The ML method is generally both scale free and scale invariant. Scale free means that if
a variable’s scale is linearly transformed, a parameter estimated for the transformed vari-
able can be algebraically converted back to the original metric. Scale invariant means

Estimation 159
that the value of the ML fitting function in a particular sample remains the same regard-
less of the scale of the observed variables (Kaplan, 2009). However, ML estimation may
lose these properties if a correlation matrix is analyzed instead of a covariance matrix.
That is, standard ML estimation assumes unstandardized variables, and it generally cal-
culates standard errors for the unstandardized solution only. Thus the level of statistical
significance of an unstandardized parameter estimate may not apply to the correspond-
ing standardized estimate (Chapter 2).
assumptions and error Propagation
As just mentioned, default ML estimation assumes that the variables are unstandard-
ized. It also assumes there are no missing values when a raw data file is analyzed, but
there is a special form of ML estimation for incomplete data files (Chapter 3). The sta-
tistical assumptions of ML estimation include independence of the scores, multivariate
normality of the endogenous variables, and independence of the exogenous variables
and error terms. An additional assumption when a path model is analyzed is that the
exogenous variables are measured without error, but this requirement is not specific to
ML estimation.
Perhaps the most important assumption of all is that the model is correctly specified.
This is critical because of error propagation. Full-information methods, including ML,
tend to propagate errors throughout the model. This means that a specification error in
one parameter can affect results for other parameters elsewhere in the model. Suppose
that the measurement error correlation for a factor with just two indicators is really sub-
stantial but cannot be estimated due to identification (e.g., Figure 6.5(d)). This specifica-
tion error may propagate to estimation of the factor loadings for this pair of indicators.
2
It is difficult to predict the direction or magnitude of this “contamination,” but the more
serious the specification error, the more serious may be the resulting bias in other parts
of the model.
When misspecification occurs, partial-information methods may outperform ML
estimation. This is because the partial-information methods may better isolate the
effects of errors to misspecified parts of the model instead of allowing them to spread
to other parts. Bollen, Kirby, Curran, Paxton, and Chen (2007) found in a Monte Carlo
simulation study that bias in ML and various TSLS estimators for latent variable models
was generally negligible in large samples when a three-factor measurement model was
correctly specified. However, when model specification was incorrect, there was greater
bias of the ML estimator compared with that of TSLS estimators even in large sample
sizes. Based on these results, Bollen et al. (2007) suggested that researchers consider a
TSLS estimator as a complement to or substitute for ML estimation when there is doubt
about specification.
3
2
B. Muthén, personal communication, November 25, 2003.
3
A drawback of partial-information methods is that there is no statistical test of overall model fit.

160 CORE TECHNIQuES
Interpretation of Parameter estimates
This section concerns path models. Later chapters deal with the interpretation of param-
eter estimates for models with substantive latent variables. The interpretation of ML
estimates for path models is straightforward:
1. Path coefficients are interpreted just as regression coefficients in MR. This is
true for both the unstandardized and the standardized solution.
2. Disturbance variances in the unstandardized solution are estimated in the met-
ric of the unexplained variance of the corresponding endogenous variable. Suppose that
the observed variance of endogenous variable Y is 25.00 and that the unstandardized
variance of its disturbance, D, is 15.00. We can conclude that 15.00/25.00, or .60 of the
variance in total variability in Y is unexplained. Accordingly, 1.00 – .60 = .40 is the pro-
portion of explained variance. This proportion also equals the squared multiple correla-
tion
2
smc
R
for Y.
3. In the standardized solution, the variances of all variables (including distur-
bances) equal 1.0. However, some SEM computer programs, such as LISREL and Mplus,
report standardized estimates for disturbances that are proportions of unexplained vari-
ance. These estimates equal 1 –
2
smc
R
for each endogenous variable.
detaIled eXaMPle
Considered next is estimation of the parameters for the recursive path model of causes
and effects of positive teacher–pupil interactions introduced in Chapter 5. In the next
chapter, you will learn how to evaluate the overall fit of this model (and others, too) to
the data. The discussion of parameter estimation now and of model fit later is inten-
tional. This is because too many researchers become so preoccupied with model fit that
they do not pay enough attention to the meaning of the parameter estimates. Also, there
is a “surprise” concerning the estimates for this example, one that could be missed by
focusing too much on model fit. To not keep you in suspense, the surprise concerns
suppression effects evident in the standardized solution. But you have to pay attention
to the details of the computer output in order to detect such effects.
Briefly reviewed next is the work of Sava (2002), who administered measures of
perceived school support, burnout, and extent of a coercive view of student discipline
to 109 high school teachers. A total of 946 students of these teachers completed ques-
tionnaires about the degree of positive teacher–pupil interactions. These students also
completed questionnaires about whether they viewed their school experience as positive
and about their general somatic status.
4
High scores on general somatic status indicate
fewer somatic complaints related to stress. Student responses were averaged in order to
4
The Sava (2002) data set is actually hierarchical where students are nested under teachers, but a multilevel
analysis was not conducted for this example.
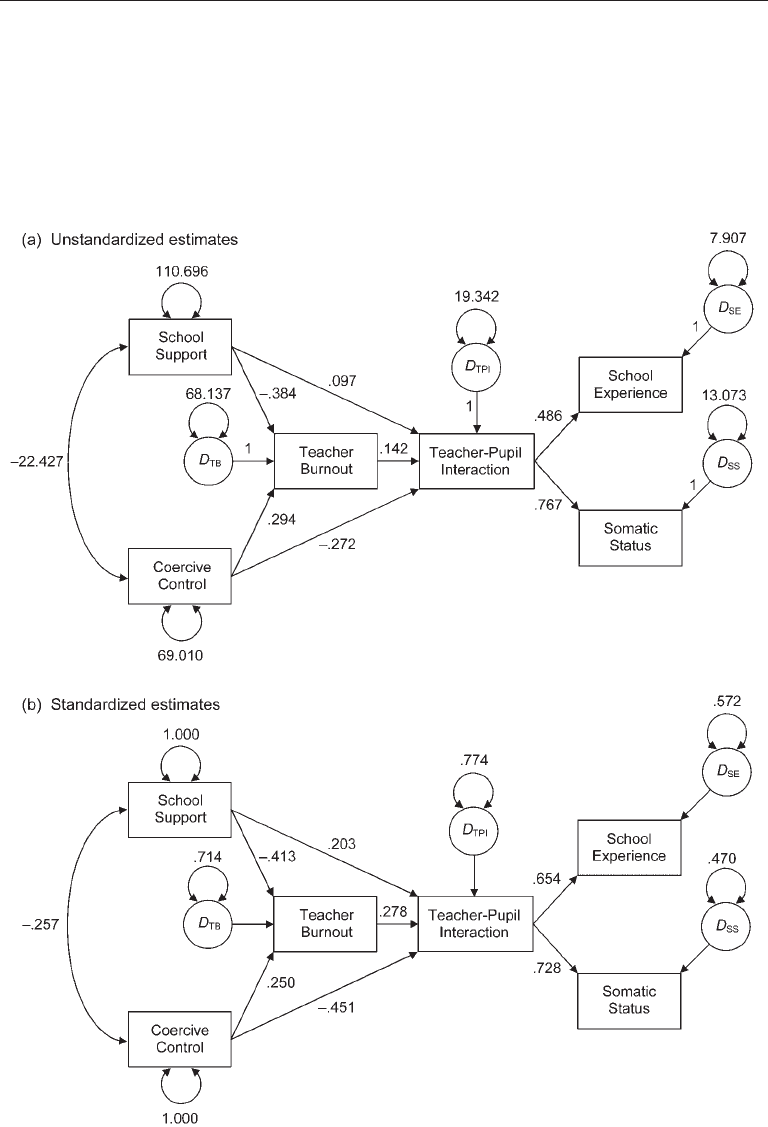
Estimation 161
generate summary scores for each teacher. Thus, the overall sample size for this analy-
sis is N = 109, which is small. The path model in Figure 7.1 represents the hypothesis
that teachers who suffer from burnout due to poor school support or a coercive view of
discipline will have less positive interactions with students, which in turn negatively
affects the school experience and somatic status of students. You should verify for this
FIgure 7.1. A recursive path model of causes and effects of teacher–pupil interactions.
Standardized estimates for the disturbances are proportions of unexplained variance.

162 CORE TECHNIQuES
model that df
M
= 7 (Chapter 5, Exercise 4). Because the structural model in Figure 7.1 is
recursive, it is identified (Rule 6.1).
Sava (2002) screened the data for skewness and kurtosis before applying trans-
formations to normalize scores on the teacher–pupil interactions variable. The origi-
nal covariance matrix analyzed by Sava (2002) was ill scaled because the ratio of the
largest variance over the smallest variance exceeded 100.0. To remedy this problem, I
multiplied scores on the variable with the lowest variance (school support) by the con-
stant 5.0, which increased its variance by a factor of 25.0. The sample correlations and
rescaled standard deviations for this analysis are presented in Table 7.1. Note that the
correlation between the variables teacher burnout and positive teacher–pupil interac-
tions is .0207. This near-zero association is related to suppression effects described later
in this chapter.
I used the ML method of LISREL 8.8 to fit the path model of Figure 7.1 to a covari-
ance matrix constructed from the data in Table 7.1. You can download from this book’s
website (see p. 3) the EQS, LISREL, and Mplus computer files for this analysis. The anal-
ysis in LISREL converged to an admissible solution. Reported in Table 7.2 are the esti-
mates of model parameters except for the variances and covariance of the two measured
exogenous variables, school support and coercive control (Figure 7.1). The estimates of
these parameters are just the sample values (Table 7.1).
direct effects
Let’s consider first the unstandardized direct effects in Table 7.2, which are also reported
in Figure 7.1(a). For example, the unstandardized direct effect of school support on
teacher burnout is –.384. This means that a 1-point increase on the school support
variable predicts a .384-point decrease on the burnout variable, controlling for coer-
cive control. The estimated standard error for this direct effect is .079 (Table 7.2), so
z = –.384/.079 = 4.86, which exceeds the critical value for two-tailed statistical signifi-
cance at the .01 level, or 2.58.
5
The unstandardized path coefficient for the direct effect
of coercive control on burnout is .294. Thus, a 1-point increase on coercive control
predicts a .294-point increase on burnout, controlling for school support. The estimated
standard error is .100, so z = .294/.100 = 2.94, which is also statistically significant at
the .01 level. Other unstandardized path coefficients in Table 7.2 and Figure 7.1(a) are
interpreted in similar ways.
Because these variables do not have the same scale, the unstandardized path coef-
ficients for school support and coercive control cannot be directly compared. However,
this is not a problem for the standardized path coefficients, which are reported in Table
7.2 and Figure 7.1(b). Note in the table that there are no standard errors for the standard-
ized estimates, which is typical in standard ML estimation. Consequently, no informa-
5
Note that test statistics for individual parameter estimates are referred to in LISREL as t statistics, but in
large samples they are actually z statistics.

Estimation 163
tion about statistical significance is associated with the standardized results in Table
7.2. The standardized coefficients for the direct effects of school support and coercive
control on teacher burnout are, respectively, –.413 and .250. That is, a level of school
support one full standard deviation above the mean predicts a burnout level just over
.40 standard deviations below the mean, holding coercive control constant. Likewise, a
level of coercive control one full standard deviation above the mean is associated with a
burnout level about .25 standard deviations above the mean, controlling for school sup-
port. The absolute size of the standardized direct effect of school support on burnout is
thus about 1½ times that of coercive control. Results for the other standardized direct
effects in the model are interpreted in similar ways.
Inspection of the standardized path coefficients for direct effects on teacher–pupil
interactions indicates suppression effects. For example, the standardized direct effect of
teacher burnout on teacher–pupil interactions is .278 (Table 7.2, Figure 7.1(b)), which
TABLE 7.1. Input Data (Correlations and Standard Deviations) for Analysis of a
Recursive Path Model of Causes and Effects of Positive Teacher–Pupil Interactions
Variable 1 2 3 4 5 6
1. Coercive Control 1.0000
2. Teacher Burnout .3557 1.0000
3. School Support −.2566 −.4774 1.0000
4. Teacher–Pupil Interactions −.4046 .0207 .1864 1.0000
5. School Experience −.1615 .0938 .0718 .6542 1.0000
6. Somatic Status −.3487 −.0133 .1570 .7277 .4964 1.0000
SD
8.3072 9.7697 10.5212 5.0000 3.7178 5.2714
Note. These data are from Sava (2002); N = 109. Means were not reported by Sava (2002).
TABLE 7.2. Maximum Likelihood Estimates for a Recursive Path Model of Causes
and Effects of Positive Teacher-Pupil Interactions
Parameter Unstandardized
SE
Standardized
Direct effects
Support → Burnout
−.384** .079 −.413
Support → Teacher–Pupil
.097* .046 .203
Coercive → Burnout
.294** .100 .250
Coercive → Teacher–Pupil
−.272** .055 −.451
Burnout → Teacher–Pupil
.142** .052 .278
Teacher-Pupil → Experience
.486** .055 .654
Teacher-Pupil → Somatic
.767** .070 .728
Disturbance variances
Teacher Burnout
68.137** 9.359 .714
Teacher–Pupil Interactions
19.342** 2.657 .774
School Experience
7.907** 1.086 .572
Somatic Status
13.073** 1.796 .470
Note. Standardized estimates for disturbance variances are proportions of unexplained variance.
*p < .05; **p < .01.