Kline R.B. Principles and Practice of Structural Equation Modeling
Подождите немного. Документ загружается.


84 CONCEPTS AND TOOLS
latent classes, such as a two-level mixture confirmatory factor analysis model or a two-
level regression mixture analysis. There is a free demonstration (student) version that
contains all the capabilities of the full version of Mplus except that is limited to eight
observed variables and two between variables in a two-level analysis.
9
Mx
Version 1.66b of Mx
10
(Matrix) (Neale, Boker, Xie, & Maes, 2003) is a matrix algebra
processor and a numerical optimizer that can analyze structural equation models and
other kinds of multivariate statistical models. It is freely available over the Internet and
runs under several different operating systems, including Microsoft Windows, Apple
Macintosh OSX, LINUX, and AIX. A new, open-source version of Mx, called OpenMx,
is being developed for the R programming environment. A GUI for Mx is available for
personal computers with Microsoft Windows. The installation of Mx with its GUI is
referred to as Mx Graph. There are two different ways to specify a model in Mx Graph.
The first is to write a script in the Mx programming language that describes the data
and model and then run it in batch mode. The syntax of Mx is based on the McArdle–
McDonald RAM matrix formulation, which represents structural equation models with
three different matrices: S (symmetric) for covariances, A (asymmetric) for effects of
one variable on another, and F (filter) for specifying the observed variables. See Loehlin
(2004, pp. 44–46) for examples.
The second way to specify a model in Mx Graph is to use its drawing editor. This
method does not require knowledge of the Mx programming language. After defining
an external data file, the user can click on a list of variables, and these variables are then
automatically displayed in the drawing editor. Model diagrams in Mx Graph use the
McArdle–McDonald RAM symbolism. Mx Graph automatically writes the Mx syntax for
the analysis that corresponds to the user’s model diagram and then executes it. Special
features of Mx Graph for SEM include the ability to calculate confidence intervals and
statistical power for individual parameter estimates and analyze special types of latent
variable models for genetics data. It also has nonparametric bootstrapping capabilities.
Examples of Mx scripts for continuous or categorical variables of the kind analyzed in
genetics research can be freely downloaded.
11
raMona
M. Browne’s RAMONA,
12
Reticular Action Model or Near Approximation, is the mod-
ule for SEM in SYSTAT 13 (Systat Software, Inc., 2009), a comprehensive program for
9
www.statmodel.com/demo.shtml
10
www.vcu.edu/mx/
11
www.vcu.edu/mx/examples.html
12
www.systat.com/

Computer Tools 85
general statistical analysis for Microsoft Windows. The user interacts with RAMONA
in the general SYSTAT environment by submitting a batch file with commands that
describe the model and data or by typing these commands at a prompt for interactive
sessions. An alternative method is to use a wizard with graphical dialogs for naming
observed and latent variables and specifying the type of data to be analyzed, but syntax
that specifies the model must be typed directly in a text window by the user. Syntax for
RAMONA is straightforward and involves only two parameter matrices, one for direct
effects and the other for covariances between independent variables. Special features of
RAMONA include the ability to correctly fit a model to a correlation matrix only. There
is also a “Restart” command that automatically takes parameter estimates from a prior
analysis as initial estimates in a new analysis. The RAMONA module cannot analyze a
structural equation model across multiple samples, and there is no direct way to analyze
means. There is a free student version of SYSTAT called MYSTAT, but it does not include
RAMONA. The full version of SYSTAT can be downloaded for a free 30-day trial.
13
sePath
J. Steiger’s SEPATH
14
(Structural Equation Modeling and Path Analysis) is the SEM mod-
ule in STATISTICA 9 Advanced (StatSoft Inc., 2009), an integrated program for general
statistical analyses, data mining, and quality control. Structural equation models are
specified in SEPATH with the PATH1 programming language that mimics the appear-
ance of a model diagram based on McArdle–McDonald RAM symbolism. There are
three ways to enter PATH1 code in SEPATH. First, users who already know the PATH1
language can enter syntax directly into a dialog box. The two other methods do not
require PATH1 knowledge. One is a graphical path construction tool in which the user
clicks with the mouse cursor on variable names or buttons that represent different types
of paths for direct effects or covariances. The other method is a graphical wizard for
specifying models with substantive latent variables, such as confirmatory factor analysis
models. Both methods automatically write PATH1 syntax in a separate window.
The special strengths of SEPATH include the capabilities to correctly analyze a cor-
relation matrix without standard deviations and generate simulated random samples in
Monte Carlo studies. This program offers many options to precisely control parameter
estimation, but their effective use requires technical knowledge of nonlinear optimiza-
tion procedures. There is also a power analysis module in STATISTICA 9 Advanced (also
by J. Steiger) that estimates the power of statistical tests of model fit in SEM (Chapter 8).
The full version of STATISTICA can be downloaded for a free 30-day trial.
15
13
www.systat.com/Downloads.aspx
14
www.statsoft.com/
15
www.statsoft.com/support/free-statistica-trial/

86 CONCEPTS AND TOOLS
other CoMPuter tools
Two other options for SEM are described next: R and MATLAB.
r
The R programming language and environment is an implementation of S, developed
at Bell Labs as a computing environment for statistics, data mining, and graphics. The
S-PLUS program by TIBCO Software, Inc., is a commercial version of S, but R is a free,
cooperatively developed, and open-source version that can be downloaded over the
Internet.
16
It runs on Unix, Microsoft Windows, and Apple Macintosh families of oper-
ating systems. A basic R installation has about the same statistical capabilities as some
commercial programs, such as SPSS, but there are now over 1,700 add-on modules, or
packages, that further extend R’s analytical repertoire. For example, the package sem
by J. Fox (2006) is designed specifically for structural equation modeling. Other pack-
ages for R support SEM analyses, including boot for bootstrapping and polychor for
calculating polyserial and polychoric correlations.
The user interacts with R in one of two different ways. One is through a command
prompt that accepts R programming language and numerical (data) input. Another is
batch mode in which commands are entered in an editor before the entire file is executed
(run). Researchers with no programming experience whatsoever may find the R user
interface austere, but others should be able to work in a command-driven environment
with little problem. The sem package uses the McArdle–McDonald RAM notational
system to specify structural equation models. The model-fitting capabilities of sem are
limited at present compared with those of commercial SEM tools. For example, sem
cannot simultaneously estimate a model across multiple groups, but its capabilities may
be extended in the future.
MatlaB
Version 7.10 of MATLAB
17
(Matrix Laboratory) (The MathWorks, Inc., 2010) is a com-
mercial computing environment and programming language for data analysis. It has
extensive capabilities for data manipulation and visualization, and there are many built-
in functionalities for linear algebra, curve fitting, and optimization and numerical inte-
gration, among others. There are also optional add-ons that support more specialized
kinds of analyses, including those for multivariate statistical techniques. Widely known
in engineering and the natural sciences, MATLAB is increasingly being used by behav-
ioral science researchers, too.
Similar to R, the main user interface for MATLAB is command-driven; that is, users
16
www.r-project.org/
17
www.mathworks.com/

Computer Tools 87
enter MATLAB statements at a command prompt. However, this interface is supported
by a GUI for the whole MATLAB environment. For example, users can drag a previous
command from a command history window to the command prompt and then execute
it. Many statistical and graphical functions are available by clicking with the mouse cur-
sor on program icons. The user can also program MATLAB to conduct a specific type
of analysis in batch mode processing. There are now some MATLAB routines for SEM.
For example, Steele (2009) describes MATLAB code for SEM analyses in functional
Magnetic Resonance Imaging (fMRI) studies; this code can be freely downloaded.
18
Goldstein, Bonnet, and Rocher (2007) describe a MATLAB routine for multilevel SEM
analyses of comparative data on educational performance across different counties. At
present, there are relatively few SEM-specific routines for MATLAB, but I expect this
situation will change. A student version of MATLAB available at a reduced cost, and the
full version can be downloaded for a free 15-day trial.
19
suMMarY
Many contemporary SEM computer tools are no more difficult to use than other com-
puter programs for general statistical analyses. Ideally, this situation should allow you to
be more concerned with the logic and rationale of the analysis than with the mechanics
of carrying it out. The capability to specify a structural equation model by drawing it on
the screen helps beginners to be productive right away. However, with experience you
may find that specifying models in syntax and working in batch mode are actually faster
and more efficient methods, and thus easier. Problems can be expected in the analysis of
complex models, and no amount of user friendliness in the interface of a computer tool
can negate this fact. When (not if) things in the analysis go wrong, you need, first, to
have a good conceptual understanding of the nature of the problem and, second, basic
computer skills in order to correct the problem. You should also not let ease of computer
tool use lead you to carry out unnecessary analyses or select analytical methods that you
do not really understand. The fundamental concepts and tools discussed in Part I of this
book set the stage for the overview of core SEM techniques in Part II.
reCoMMended readIngs
Nachtigall, Kroehne, Funke, and Steyer (2003) describe an “SEM first-aid kit,” or a discussion
of typical problems—including those that concern computer programs—that beginners often
encounter and possible solutions. Steiger (2001) reminds us that the availability of graphical
user interfaces in SEM computer tools should not be seen as a shortcut to understanding the
conceptual and statistical bases of the analysis.
18
www.dundee.ac.uk/medschool/staff/douglas_steele/structural_equation_modelling
19
www.mathworks.com/downloads/web_downloads/trials

88 CONCEPTS AND TOOLS
Nachtigall, C., Kroehne, U., Funke, F., & Steyer, R. (2003). (Why) Should we use SEM? Pros
and cons of structural equation modeling. Methods of Psychological Research Online,
8(2), 1–22. Retrieved March 24, 2009, from aodgps.de/fachgruppen/methoden/mpr-
online/issue20/art1/mpr127_11.pdf
Steiger, J. H. (2001). Driving fast in reverse: The relationship between software development,
theory, and education in structural equation modeling. Journal of the American Statistical
Association, 96, 331–338.

Part II
Core Techniques

91
5
Specification
The specification of path analysis (PA) models, confirmatory factor analysis (CFA) mea-
surement models, and structural regression (SR) models is the topic of this chapter. Out-
lined first are the basic steps of SEM and graphical symbols used in model diagrams.
Some straightforward rules are suggested for counting the number of observations
(which is not the sample size) in the analysis and the number of model parameters.
Both of these quantities are needed for checking model identification (next chapter).
Actual research examples dealt with in more detail in later chapters are also intro-
duced. The main goal of this presentation is to give you a better sense of the kinds of
hypotheses that can be tested with core structural equation models.
stePs oF seM
Six basic steps are followed in most analyses, and two additional optional steps, in a per-
fect world, would be carried out in every analysis. Review of these steps will help you to
understand (1) the relation of specification, the main topic of this chapter, to later steps
of SEM and (2) the utmost importance of specification.
Basic steps
The basic steps are listed next and then discussed afterward, and a flowchart of these
steps is presented in Figure 5.1. These steps are actually iterative because problems at a
later step may require a return to an earlier step. (Later chapters elaborate specific issues
at each step beyond specification for particular SEM techniques.)
1. Specify the model.
2. Evaluate model identification (if not identified, go back to step 1).
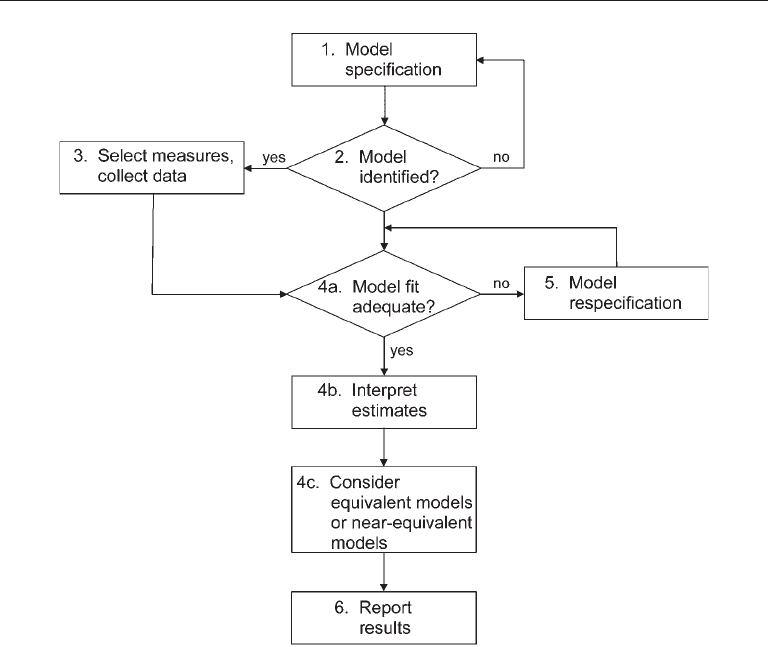
92 CORE TECHNIQuES
3. Select the measures (operationalize the constructs) and collect, prepare, and
screen the data.
4. Estimate the model:
a. Evaluate model fit (if poor, skip to step 5).
b. Interpret parameter estimates.
c. Consider equivalent or near-equivalent models (skip to step 6).
5. Respecify the model (return to step 4).
6. Report the results.
Specification
The representation of your hypotheses in the form of a structural equation model is
specification. Many researchers begin the process of specification by drawing a model
diagram using a set of more or less standard graphical symbols (defined later), but the
model can alternatively be described by a series of equations. These equations define
the model’s parameters, which correspond to presumed relations among observed or
FIgure 5.1. Flowchart of the basic steps of SEM.

Specification 93
latent variables that the computer eventually estimates with sample data. Specification
is the most important step. This is because results from later steps assume that the model
is basically correct. I also suggest that you make a list of possible changes to the initial
model that would be justified according to theory or empirical results. This is because
it is often necessary to respecify models (step 5), and respecification should respect the
same principles as specification.
Identification
If life were fair, the researcher could proceed directly from specification to collection of
the data to estimation. Unfortunately, the analysis of a structural equation model is not
always so straightforward. The problem that potentially complicates the analysis is that
of identification. A model is identified if it is theoretically possible for the computer to
derive a unique estimate of every model parameter. Otherwise, the model is not identi-
fied. The word “theoretically” emphasizes identification as a property of the model and
not of the data. For example, if a model is not identified, then it remains so regardless
of the sample size (N = 100, 1,000, etc.). Therefore, models that are not identified should
be respecified (return to step 1); otherwise, attempts to analyze them may be fruitless.
Different types of structural equation models must meet the specific requirements for
identification that are described in Chapter 6.
Measure Selection and Data Collection
The various activities for this step—select good measures, collect the data, and screen
them—were discussed in Chapter 3.
Estimation
This step involves using an SEM computer tool to conduct the analysis. Several things
take place at this step: (1) Evaluate model fit, which means determine how well the
model explains the data. Perhaps more often than not, researchers’ initial models do
not fit the data very well. When (not if) this happens to you, skip the rest of this step
and go to the next, respecification, and then reanalyze the respecified model using the
same data. Assuming satisfactory model fit, then (2) interpret the parameter estimates.
In written summaries, too many researchers fail to interpret the parameter estimates
for specific effects. Perhaps concern for overall model fit is so great that relatively little
attention is paid to whether estimates of its parameters are meaningful (Kaplan, 2009).
Next, (3) consider equivalent or near-equivalent models. Recall that an equivalent model
explains the data just as well as the researcher’s preferred model but does so with a dif-
ferent configuration of hypothesized relations among the same variables (Chapter 1).
For a given model, there may be many—and in some cases infinitely many—equivalent
versions. Thus, the researcher needs to explain why his or her preferred model should
not be rejected in favor of statistically equivalent ones. Too many authors of SEM stud-