Hager G., Wellein G. Introduction to High Performance Computing for Scientists and Engineers
Подождите немного. Документ загружается.


Modern processors 5
Listing 1.1: Basic code fragment for the vector triad benchmark, including performance
measurement.
1 double precision, dimension(N) :: A,B,C,D
2 double precision :: S,E,MFLOPS
3
4 do i=1,N !initialize arrays
5 A(i) = 0.d0; B(i) = 1.d0
6 C(i) = 2.d0; D(i) = 3.d0
7 enddo
8
9 call get_walltime(S) ! get time stamp
10 do j=1,R
11 do i=1,N
12 A(i) = B(i) + C(i)
*
D(i) ! 3 loads, 1 store
13 enddo
14 if(A(2).lt.0) call dummy(A,B,C,D) ! prevent loop interchange
15 enddo
16 call get_walltime(E) ! get time stamp
17 MFLOPS = R
*
N
*
2.d0/((E-S)
*
1.d6) ! compute MFlop/sec rate
memory bandwidth. One of the prominent examples is the vector triad, introduced
by Schönauer [S5]. It comprises a nested loop, the inner level executing a multiply-
add operation on the elements of three vectors and storing the result in a fourth (see
lines 10–15 in Listing 1.1). The purpose of this benchmark is to measure the perfor-
mance of data transfers between memory and arithmetic units of a processor. On the
inner level, three load streams for arrays B, C and D and one store stream for A are
active. Depending on N, this loop might execute in a very small time, which would be
hard to measure. The outer loop thus repeats the triad R times so that execution time
becomes large enough to be accurately measurable. In practice one would choose R
according to N so that the overall execution time stays roughly constant for different
N.
The aim of the masked-out call to the dummy() subroutine is to prevent the
compiler from doing an obvious optimization: Without the call, the compiler might
discover that the inner loop does not depend at all on the outer loop index j and drop
the outer loop right away. The possible call to dummy() fools the compiler into
believing that the arrays may change between outer loop iterations. This effectively
prevents the optimization described, and the additional cost is negligible because the
condition is always false (which the compiler does not know).
The MFLOPS variable is computed to be the MFlops/sec rate for the whole loop
nest. Please note that the most sensible time measure in benchmarking is wallclock
time, also called elapsed time. Any other “time” that the system may provide, first
and foremost the much stressed CPU time, is prone to misinterpretation because there
might be contributions from I/O, context switches, other processes, etc., which CPU
time cannot encompass. This is even more true for parallel programs (see Chapter 5).
A useful C routine to get a wallclock time stamp like the one used in the triad bench-

6 Introduction to High Performance Computing for Scientists and Engineers
Listing 1.2: A C routine for measuring wallclock time, based on the gettimeofday()
POSIX function. Under the Windows OS, the GetSystemTimeAsFileTime() routine
can be used in a similar way.
1 #include <sys/time.h>
2
3 void get_walltime_(double
*
wcTime) {
4 struct timeval tp;
5 gettimeofday(&tp, NULL);
6
*
wcTime = (double)(tp.tv_sec + tp.tv_usec/1000000.0);
7 }
8
9 void get_walltime(double
*
wcTime) {
10 get_walltime_(wcTime);
11 }
mark above could look like in Listing 1.2. The reason for providing the function with
and without a trailing underscore is that Fortran compilers usually append an under-
score to subroutine names. With both versions available, linking the compiled C code
to a main program in Fortran or C will always work.
Figure 1.4 shows performance graphs for the vector triad obtained on different
generations of cache-based microprocessors and a vector system. For very small
loop lengths we see poor performance no matter which type of CPU or architec-
ture is used. On standard microprocessors, performance grows with N until some
maximum is reached, followed by several sudden breakdowns. Finally, performance
stays constant for very large loops. Those characteristics will be analyzed in detail in
Section 1.3.
Vector processors (dotted line in Figure 1.4) show very contrasting features. The
low-performance region extends much farther than on cache-based microprocessors,
Figure 1.4: Serial vector
triad performance ver-
sus loop length for sev-
eral generations of In-
tel processor architec-
tures (clock speed and
year of introduction is
indicated), and the NEC
SX-8 vector processor.
Note the entirely differ-
ent performance charac-
teristics of the latter.
10
1
10
2
10
3
10
4
10
5
10
6
10
7
N
0
1000
2000
3000
4000
MFlops/sec
Netburst 3.2 GHz (2004)
Core 2 3.0 GHz (2006)
Core i7 2.93 GHz (2009)
NEC SX-8 2.0 GHz
Modern processors 7
but there are no breakdowns at all. We conclude that vector systems are somewhat
complementary to standard CPUs in that they meet different domains of applicability
(see Section 1.6 for details on vector architectures). It may, however, be possible to
optimize real-world code in a way that circumvents low-performance regions. See
Chapters 2 and 3 for details.
Low-level benchmarks are powerful tools to get information about the basic ca-
pabilities of a processor. However, they often cannot accurately predict the behavior
of “real” application code. In order to decide whether some CPU or architecture is
well-suited for some application (e.g., in the run-up to a procurement or before writ-
ing a proposal for a computer time grant), the only safe way is to prepare application
benchmarks. This means that an application code is used with input parameters that
reflect as closely as possible the real requirements of production runs. The decision
for or against a certain architecture should always be heavily based on application
benchmarking. Standard benchmark collections like the SPEC suite [W118] can only
be rough guidelines.
1.2.2 Transistors galore: Moore’s Law
Computer technology had been used for scientific purposes and, more specifi-
cally, for numerically demanding calculations long before the dawn of the desktop
PC. For more than thirty years scientists could rely on the fact that no matter which
technology was implemented to build computer chips, their “complexity” or general
“capability” doubled about every 24 months. This trend is commonly ascribed to
Moore’s Law. Gordon Moore, co-founder of Intel Corp., postulated in 1965 that the
number of components (transistors) on a chip that are required to hit the “sweet spot”
of minimal manufacturing cost per component would continue to increase at the indi-
cated rate [R35]. This has held true since the early 1960s despite substantial changes
in manufacturing technologies that have happened over the decades. Amazingly, the
growth in complexity has always roughly translated to an equivalent growth in com-
pute performance, although the meaning of “performance” remains debatable as a
processor is not the only component in a computer (see below for more discussion
regarding this point).
Increasing chip transistor counts and clock speeds have enabled processor de-
signers to implement many advanced techniques that lead to improved application
performance. A multitude of concepts have been developed, including the following:
1. Pipelined functional units. Of all innovations that have entered computer de-
sign, pipelining is perhaps the most important one. By subdividing complex
operations (like, e.g., floating point addition and multiplication) into simple
components that can be executed using different functional units on the CPU,
it is possible to increase instruction throughput, i.e., the number of instructions
executed per clock cycle. This is the most elementary example of instruction-
level parallelism (ILP). Optimally pipelined execution leads to a throughput of
one instruction per cycle. At the time of writing, processor designs exist that
feature pipelines with more than 30 stages. See the next section on page 9 for
details.
8 Introduction to High Performance Computing for Scientists and Engineers
2. Superscalar architecture. Superscalarity provides “direct” instruction-level
parallelism by enabling an instruction throughput of more than one per cycle.
This requires multiple, possibly identical functional units, which can operate
currently (see Section 1.2.4 for details). Modern microprocessors are up to
six-way superscalar.
3. Data parallelism through SIMD instructions. SIMD (Single Instruction Multi-
ple Data) instructions issue identical operations on a whole array of integer or
FP operands, usually in special registers. They improve arithmetic peak per-
formance without the requirement for increased superscalarity. Examples are
Intel’s “SSE” and its successors, AMD’s “3dNow!,” the “AltiVec” extensions
in Power and PowerPC processors, and the “VIS” instruction set in Sun’s Ul-
traSPARC designs. See Section 1.2.5 for details.
4. Out-of-order execution. If arguments to instructions are not available in regis-
ters “on time,” e.g., because the memory subsystem is too slow to keep up with
processor speed, out-of-order execution can avoid idle times (also calledstalls)
by executing instructions that appear later in the instruction stream but have
their parameters available. This improves instruction throughput and makes it
easier for compilers to arrange machine code for optimal performance. Cur-
rent out-of-order designs can keep hundreds of instructions in flight at any
time, using a reorder buffer that stores instructions until they become eligible
for execution.
5. Larger caches. Small, fast, on-chip memories serve as temporary data storage
for holding copies of data that is to be used again “soon,” or that is close to
data that has recently been used. This is essential due to the increasing gap
between processor and memory speeds (see Section 1.3). Enlarging the cache
size does usually not hurt application performance, but there is some tradeoff
because a big cache tends to be slower than a small one.
6. Simplified instruction set. In the 1980s, a general move from the CISC to the
RISC paradigm took place. In a CISC (Complex Instruction Set Computer),
a processor executes very complex, powerful instructions, requiring a large
hardware effort for decoding but keeping programs small and compact. This
lightened the burden on programmers, and saved memory, which was a scarce
resource for a long time. A RISC (Reduced Instruction Set Computer) features
a very simple instruction set that can be executed veryrapidly (fewclock cycles
per instruction; in the extreme case each instruction takes only a single cycle).
With RISC, the clock rate of microprocessors could be increased in a way that
would never have been possible with CISC. Additionally, it frees up transistors
for other uses. Nowadays, most computer architectures significant for scientific
computing use RISC at the low level. Although x86-based processors execute
CISC machine code, they perform an internal on-the-fly translation into RISC
“
µ
-ops.”
In spite of all innovations, processor vendors have recently been facing high obsta-
cles in pushing the performancelimits of monolithic, single-core CPUs to new levels.

Modern processors 9
B(1)
C(1)
B(2)
C(2)
B(3)
C(3)
B(4)
C(4)
B(N)
C(N)
B(1)
C(1)
B(2)
C(2)
B(3)
C(3)
B(4)
C(4)
B(5)
C(5)
B(N)
C(N)
B(2)
C(2)
B(3)
C(3)
B(1)
C(1)
B(N)
C(N)
Multiply
mantissas
Add
exponents
Normalize
result
Insert
sign
Separate
mant./exp.
(N−4)
A
(N−3)
A A
(N−2)
A
(N−1)
A(1) A(N)
(N−3)
A
(N−2)
A A
(N−1)
A(N)
A(1) A(2)
C(N−1)
B(N−1)
B(N−2)
C(N−2)
B(N−1)
C(N−1)
...
...
...
...
...
1 2 3 4 5 N N+1 N+2 N+3 N+4...
Cycle
Wind−up
Wind−down
Figure 1.5: Timeline for a simplified floating-point multiplication pipeline that executes
A(:)=B(:)
*
C(:). One result is generated on each cycle after a four-cycle wind-up phase.
Moore’s Law promises a steady growth in transistor count, but more complexity does
not automatically translate into more efficiency: On the contrary, the more functional
units are crammed into a CPU, the higher the probability that the “average” code will
not be able to use them, because the number of independent instructions in a sequen-
tial instruction stream is limited. Moreover, a steady increase in clock frequencies is
required to keep the single-core performance on par with Moore’s Law. However, a
faster clock boosts power dissipation, making idling transistors even more useless.
In search for a way out of this power-performance dilemma there have been some
attempts to simplify processor designs by giving up some architectural complexity
in favor of more straightforward ideas. Using the additional transistors for larger
caches is one option, but again there is a limit beyond which a larger cache will not
pay off any more in terms of performance. Multicore processors, i.e., several CPU
cores on a single die or socket, are the solution chosen by all major manufacturers
today. Section 1.4 below will shed some light on this development.
1.2.3 Pipelining
Pipelining in microprocessors serves the same purpose as assembly lines in man-
ufacturing: Workers (functional units) do not have to know all details about the fi-
nal product but can be highly skilled and specialized for a single task. Each worker
executes the same chore over and over again on different objects, handing the half-
finished product to the next worker in line. If it takes m different steps to finish the
product, m products are continually worked on in different stages of completion. If
all tasks are carefully tuned to take the same amount of time (the “time step”), all
workers are continuously busy. At the end, one finished product per time step leaves
the assembly line.
Complex operations like loading and storing data or performing floating-point
arithmetic cannot be executed in a single cycle without excessive hardware require-

10 Introduction to High Performance Computing for Scientists and Engineers
ments. Luckily, the assembly line concept is applicable here. The most simple setup
is a “fetch–decode–execute” pipeline, in which each stage can operate indepen-
dently of the others. While an instruction is being executed, another one is being
decoded and a third one is being fetched from instruction (L1I) cache. These still
complex tasks are usually broken down even further. The benefit of elementary sub-
tasks is the potential for a higher clock rate as functional units can be kept simple.
As an example we consider floating-point multiplication, for which a possible di-
vision into five “simple” subtasks is depicted in Figure 1.5. For a vector product
A(:)=B(:)
*
C(:), execution begins with the first step, separation of mantissa and
exponent, on elements B(1) and C(1). The remaining four functional units are idle
at this point. The intermediate result is then handed to the second stage while the
first stage starts working on B(2) and C(2). In the second cycle, only three out of
five units are still idle. After the fourth cycle the pipeline has finished its so-called
wind-up phase. In other words, the multiply pipe has a latency (or depth) of five cy-
cles, because this is the time after which the first result is available. From then on,
all units are continuously busy, generating one result per cycle. Hence, we speak of a
throughput of one cycle. When the first pipeline stage has finished working on B(N)
and C(N), the wind-down phase starts. Four cycles later, the loop is finished and all
results have been produced.
In general, for a pipeline of depth m, executing N independent, subsequent op-
erations takes N + m−1 steps. We can thus calculate the expected speedup versus a
general-purpose unit that needs m cycles to generate a single result,
T
seq
T
pipe
=
mN
N + m−1
, (1.1)
which is proportional to m for large N. The throughput is
N
T
pipe
=
1
1+
m−1
N
, (1.2)
approaching 1 for large N (see Figure 1.6). It is evident that the deeper the pipeline
the larger the number of independent operations must be to achieve reasonable
throughput because of the overhead caused by the wind-up phase.
One can easily determine how large N must be in order to get at least p results
per cycle (0 < p ≤ 1):
p =
1
1+
m−1
N
c
=⇒ N
c
=
(m−1)p
1− p
. (1.3)
For p = 0.5 we arrive at N
c
= m −1. Taking into account that present-day micro-
processors feature overall pipeline lengths between 10 and 35 stages, we can im-
mediately identify a potential performance bottleneck in codes that use short, tight
loops. In superscalar or even vector processors the situation becomes even worse as
multiple identical pipelines operate in parallel, leaving shorter loop lengths for each
pipe.
Another problem connected to pipelining arises when very complex calculations

Modern processors 11
1 10 100 1000
N
0
0.2
0.4
0.6
0.8
1
N/T
pipe
m=5
m=10
m=30
m=100
Figure 1.6: Pipeline
throughput as a function
of the number of inde-
pendent operations. m is
the pipeline depth.
like FP divide or even transcendental functions must be executed. Those operations
tend to have very long latencies (several tens of cycles for square root or divide,
often more than 100 for trigonometric functions) and are only pipelined to a small
level or not at all, so that stalling the instruction stream becomes inevitable, leading
to so-called pipeline bubbles. Avoiding such functions is thus a primary goal of code
optimization. This and other topics related to efficient pipelining will be covered in
Chapter 2.
Note that although a depth of five is not unrealistic for a floating-point multipli-
cation pipeline, executing a “real” code involves more operations like, e.g., loads,
stores, address calculations, instruction fetch and decode, etc., that must be over-
lapped with arithmetic. Each operand of an instruction must find its way from mem-
ory to a register, and each result must be written out, observing all possible inter-
dependencies. It is the job of the compiler to arrange instructions in such a way as
to make efficient use of all the different pipelines. This is most crucial for in-order
architectures, but also required on out-of-order processors due to the large latencies
for some operations.
As mentioned above, an instruction can only be executed if its operands are avail-
able. If operands are not delivered “on time” to execution units, all the complicated
pipelining mechanisms are of no use. As an example, consider a simple scaling loop:
1 do i=1,N
2 A(i) = s
*
A(i)
3 enddo
Seemingly simple in a high-level language, this loop transforms to quite a number of
assembly instructions for a RISC processor. In pseudocode, a naïve translation could
look like this:
1 loop: load A(i)
2 mult A(i) = A(i)
*
s
3 store A(i)
4 i = i + 1

12 Introduction to High Performance Computing for Scientists and Engineers
10
2
10
4
10
6
N
0
200
400
600
800
1000
MFlop/s
A(i) = s*A(i)
A(i) = s*A(i+1)
A(i) = s*A(i-1)
10
2
10
4
10
6
N
offset = 0
offset = +1
offset = -1
Figure 1.7: Influence of constant (left) and variable (right) offsets on the performance of a
scaling loop. (AMD Opteron 2.0GHz).
5 branch -> loop
Although the multiply operation can be pipelined, the pipeline will stall if the load
operation on A(i) does not provide the data on time. Similarly, the store operation
can only commence if the latency for mult has passed and a valid result is available.
Assuming a latency of four cycles for load, two cycles for mult and two cycles
for store, it is clear that above pseudocode formulation is extremely inefficient. It
is indeed required to interleave different loop iterations to bridge the latencies and
avoid stalls:
1 loop: load A(i+6)
2 mult A(i+2) = A(i+2)
*
s
3 store A(i)
4 i = i + 1
5 branch -> loop
Of course there is some wind-up and wind-down code involved that we do not show
here. We assume for simplicity that the CPU can issue all four instructions of an it-
eration in a single cycle and that the final branch and loop variable increment comes
at no cost. Interleaving of loop iterations in order to meet latency requirements is
called software pipelining. This optimization asks for intimate knowledge about pro-
cessor architecture and insight into application code on the side of compilers. Often,
heuristics are applied to arrive at “optimal” code.
It is, however, not always possible to optimally software pipeline a sequence of
instructions. In the presence of loop-carried dependencies, i.e., if a loop iteration
depends on the result of some other iteration, there are situations when neither the
compiler nor the processor hardware can prevent pipeline stalls. For instance, if the
simple scaling loop from the previous example is modified so that computing A(i)
requires A(i+offset), with offset being either a constant that is known at
compile time or a variable:

Modern processors 13
real dependency pseudodependency general version
do i=2,N
A(i)=s
*
A(i-1)
enddo
do i=1,N-1
A(i)=s
*
A(i+1)
enddo
start=max(1,1-offset)
end=min(N,N-offset)
do i=start,end
A(i)=s
*
A(i+offset)
enddo
As the loop is traversed from small to large indices, it makes a huge difference
whether the offset is negative or positive. In the latter case we speak of a pseudo-
dependency, because A(i+1) is always available when the pipeline needs it for
computing A(i), i.e., there is no stall. In case of a real dependency, however, the
pipelined computation of A(i) must stall until the result A(i-1) is completely
finished. This causes a massive drop in performance as can be seen on the left of
Figure 1.7. The graph shows the performance of above scaling loop in MFlops/sec
versus loop length. The drop is clearly visible only in cache because of the small
latencies and large bandwidths of on-chip caches. If the loop length is so large that
all data has to be fetched from memory, the impact of pipeline stalls is much less
significant, because those extra cycles easily overlap with the time the core has to
wait for off-chip data.
Although one might expect that it should make no difference whether the offset
is known at compile time, the right graph in Figure 1.7 shows that there is a dramatic
performance penalty for a variable offset. The compiler can obviously not optimally
software pipeline or otherwise optimize the loop in this case. This is actually a com-
mon phenomenon, not exclusively related to software pipelining; hiding information
from the compiler can have a substantial performance impact (in this particular case,
the compiler refrains from SIMD vectorization; see Section 1.2.4 and also Prob-
lems 1.2 and 2.2).
There are issues with software pipelining linked to the use of caches. See Sec-
tion 1.3.3 below for details.
1.2.4 Superscalarity
If a processor is designed to be capable of executing more than one instruction
or, more generally, producing more than one “result” per cycle, this goal is reflected
in many of its design details:
• Multiple instructions can be fetched and decoded concurrently (3–6 nowa-
days).
• Address and other integer calculations are performed in multiple integer (add,
mult, shift, mask) units (2–6). This is closely related to the previous point,
because feeding those units requires code execution.
• Multiple floating-point pipelines can run in parallel. Often there are one or two
combined multiply-add pipes that perform a=b+c
*
d with a throughput of one
each.
• Caches are fast enough to sustain more than one load or store operation per
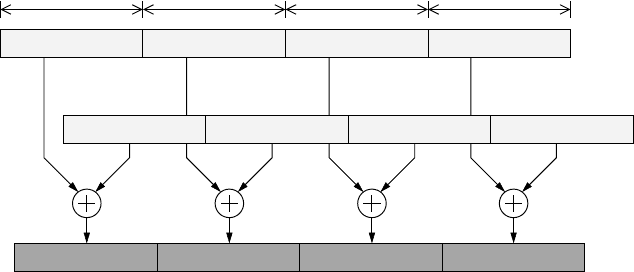
14 Introduction to High Performance Computing for Scientists and Engineers
32 32 32 32
x x x x
4 3 2 1
y y y y
4 3 2 1
r r r r
4 3 2 1
Figure 1.8: Example for SIMD: Single precision FP addition of two SIMD registers (x,y),
each having a length of 128 bits. Four SP flops are executed in a single instruction.
cycle, and the number of available execution units for loads and stores reflects
that (2–4).
Superscalarity is a special form of parallel execution, and a variant of instruction-
level parallelism (ILP). Out-of-order execution and compiler optimization must work
together in order to fully exploit superscalarity. However, even on the most advanced
architectures it is extremely hard for compiler-generatedcode to achieve a throughput
of more than 2–3 instructions per cycle. This is why applications with very high
demands for performance sometimes still resort to the use of assembly language.
1.2.5 SIMD
The SIMD concept became widely known with the first vector supercomputers
in the 1970s (see Section 1.6), and was the fundamental design principle for the
massively parallel Connection Machines in the 1980s and early 1990s [R36].
Many recent cache-based processors have instruction set extensions for both in-
teger and floating-point SIMD operations [V107], which are reminiscent of those
historical roots but operate on a much smaller scale. They allow the concurrent ex-
ecution of arithmetic operations on a “wide” register that can hold, e.g., two DP or
four SP floating-point words. Figure 1.8 shows an example, where two 128-bit reg-
isters hold four single-precision floating-point values each. A single instruction can
initiate four additions at once. Note that SIMD does not specify anything about the
possible concurrency of those operations; the four additions could be truly parallel,
if sufficient arithmetic units are available, or just be fed to a single pipeline. While
the latter strategy uses SIMD as a device to reduce superscalarity (and thus complex-
ity) without sacrificing peak arithmetic performance, the former option boosts peak
performance. In both cases the memory subsystem (or at least the cache) must be
able to sustain sufficient bandwidth to keep all units busy. See Section 2.3.3 for the
programming and optimization implications of SIMD instruction sets.