Daniels M.J., Hogan J.W. Missing Data in Longitudinal Studies: Strategies for Bayesian Modeling and Sensitivity Analysis
Подождите немного. Документ загружается.


120 INFERENCE UNDER MAR
the posterior for the mean parameters in Bayesian inference replaces (β, α)
in (6.8) with (β, α)+logp(β, α). 2
We illustrate using a multivariate normal model.
Example 6.2. Information matrix based on observed data log likelihood un-
der ignorability with a multivariate normal model.
Assume Y
i
follows a multivariate normal distribution with mean X
i
β and
covariance matrix Σ(α). Let θ =(β, α)andassume that p(β, α)=p(β)p(α)
(a common assumption). For the case of complete data, it is easy to show
that the off-diagonal block of the information matrix, I
β,α
,isequalto zero
for all values of α,therebysatisfying condition (6.8). For Bayesian inference,
the posterior for β will be consistent even under mis-specification of Σ(α).
However, under ignorability, the submatrix of the information matrix, now
based on the observed data log likelihood
obs
(or observed dataposterior)
and given by
I
obs
β,α
(β, α)=− E
∂
2
obs
(β, α)
∂β∂α
T
,
is no longer equal to zero even at the true value for Σ(α)(Little and Rubin,
2002). Hence the weaker parameter orthogonality condition given in Definition
6.2 does not even hold. As a result, in order for the posterior distribution of the
mean parameters to be consistent, the dependence structure must be correctly
specified.
This lack of orthogonality can be seen in the setting of a bivariate normal
linear regression, by making a simple analogy to univariate simple linear re-
gression. This will also provide some additional intuition into how inferences
change under missingness.
Suppose E(Y )=µ, R
i
=1fori =1,...,n
1
(y
i2
observed), and R
i
=0for
i = n
1
+1,...,n(y
i2
missing). As in Chapter 5, we factor the joint distribution
of p(y
1
,y
2
)asp(y
1
)p(y
2
| y
1
). For complete data, the conditional distribution
of Y
2
given Y
1
(ignoring priors for the time being) as a function of µ
2
and
φ
21
= σ
12
/σ
11
is proportional to
exp
-
−
n
i=1
{y
i2
− µ
2
− φ
21
(y
i1
− µ
1
)}
2
/2σ
2|1
.
, (6.9)
where σ
2|1
= σ
22
− σ
21
σ
−1
11
σ
12
.Notethatφ
21
and µ
2
do not appear in p(y
1
).
Theorthogonality of µ
2
and φ
21
is apparent by recognizing (6.9) as the
same form as the log likelihood for a simple linear regression having a centered
covariate y
i1
− µ
1
with intercept µ
2
and slope φ
21
.Itcanbeshownfromthis
form that the element of the (expected) information matrix corresponding to
µ
2
and φ
21
is zero for all values of φ
21
.However, with missing data (under
DATA AUGMENTATION 121
MAR), the analogue of (6.9) is
exp
-
−
n
1
i=1
{y
i2
− µ
C
2
− φ
21
(y
i1
− µ
C
1
)}
2
/2σ
2|1
.
.
The sum is now only over the terms that correspond to R
i
=1.
Recall the mean of the completers at time j is µ
C
j
= E(Y
ij
| R =1).Again
using the analogy to simple linear regression, µ
C
2
and φ
21
are orthogonal,
but µ
2
and φ
21
arenot.This is clear from the following, which holds under
ignorability:
µ
2
= µ
C
2
π + µ
D
2
(1 − π)
= µ
C
2
− φ
21
(1 − π)(µ
C
1
− µ
D
1
),
where π = P (R
i
=1).Thus,µ
2
is a function of φ
21
.Withnomissing data,
π =1(soµ
2
= µ
C
2
). Under MCAR, (µ
C
1
− µ
D
1
)=0andthesecond term
involving φ
21
disappears. 2
Examples 6.1 and 6.2 demonstrate the importance of correctly specifying
Σ even when primary interest is in µ.Thus,ifwemodel the covariance matrix
parsimoniously, we must be sure to consider whether Σ depends on covariates.
Of course, such modeling decisionsareonlyverifiable from the data underthe
ignorability assumption.
Similar results hold for directly specified models for binary data. It can
be shown that the information matrix for the mean parameters β and the
dependence parameters α in an MTM(1) (Example 2.5) satisfies condition
(6.8) under no missing data or MCAR (Heagerty, 2002) , but not under MAR.
There are also situations where misspecification of dependence with com-
plete data can lead to biased estimates of the mean parameters. For example,
in marginalized transition model of order p (where p ≥ 2), β and α are not
orthogonal (Heagerty, 2002). Hence, the dependence structure must be cor-
rectly specified. Similar specificationissues with complete data are also seen
in conditionally specified models for binary data.
Of course, it is not possible to verify whether the dependence structure is
correct when data are incomplete. As a practical matter, when ignorability
is being assumed, it is recommended that the dependence model be selected
based on the model that is most suitable for the observed data.
6.3 Posterior sampling using data augmentation
Data augmentation is an important tool for full data inference in the pres-
ence of missing data; it is related to theEMalgorithm (Dempster, Laird, and
Rubin, 1977) and its variations (van Dyk and Meng, 2001). As we illustrated
in Chapter 5 the general strategy is to specify a model and priors for the full
data and then to base posterior inference on the induced observed data pos-
122 INFERENCE UNDER MAR
terior, p(θ | y
obs
). However, the full-data posterior p(θ | y)isofteneasier to
sample than the observed-data posterior p(θ | y
obs
). Specifically, full condi-
tional distributions of the full-data posterior used in Gibbs sampling typically
have simpler forms than the full conditionals derived using the observed-data
posterior. This motivates augmenting the observed-data posterior with the
missing data y
mis
.Wepointout that if the model is specified directly for the
observed data, i.e, specify the observed data response model instead of the
full-data response model, and priors are put directly on the parameters of the
observed-data response model (see Example 5.7), then data augmentation is
not needed.
For data augmentation, at each iteration k of the sampling algorithm, we
sample (y
(k)
mis
, θ
(k)
)via
1. y
(k)
mis
∼ p(y
mis
| y
obs
, θ
(k−1)
)
2. θ
(k)
∼ p(θ | y
obs
, y
(k)
mis
).
Thus, we can sample θ using the tools we described in Chapter 3 for the full-
data posterior, as if we had complete data. Implicitly, via Monte Carlo integra-
tion within the MCMC algorithm, we obtain a sample from the observed-data
posterior p(θ | y
obs
)givenin (6.3).
Because data augmentation depends on sampling from p(y
mis
| y
obs
, θ), the
augmentation depends heavily on the within-subject dependence structure.
We illustrate by giving some examples of the data augmentation step for
several models from Chapter 2 under ignorable dropout.
Example 6.3. Data augmentation under ignorability with a multivariate nor-
mal model (continuation ofExample2.3).
Without loss of generality, define Y
obs,i
=(Y
i1
,...,Y
iJ
)
T
and Y
mis,i
=
(Y
i,J
+1
,...,Y
iJ
)
T
with corresponding partitions of X
i
and Σ given by
x
i
=
/
x
obs,i
x
mis,i
0
Σ =
/
Σ
obs
Σ
obs,mis
Σ
T
obs,mis
Σ
mis
0
.
Within the sampling algorithm, the distribution of p(y
mis,i
| y
obs,i
, θ)takes
the form
Y
mis,i
| Y
obs,i
, θ ∼ N(µ
, Σ
),
where
µ
= x
mis,i
β + B(Σ)(y
obs,i
− x
obs,i
β)
Σ
= Σ
mis
− Σ
T
obs,mis
Σ
−1
obs
Σ
obs,mis
,
and B(Σ)=Σ
T
obs,mis
Σ
−1
obs
.Thedependence of Y
mis,i
on Y
obs,i
is governed

DATA AUGMENTATION 123
by B(Σ), the matrix of autoregressive coefficients from regressing Y
mis,i
on
Y
obs,i
.Clearly, B(Σ)isafunction of the full-data covariance matrix Σ. 2
Example 6.4. Data augmentation under ignorability with random effects lo-
gistic regression (continuation ofExample2.2).
Again, we define Y
mis,i
and Y
obs,i
as in Example 6.3. The distribution p(y
mis,i
|
y
obs,i
, b
i
, θ)isaproduct of independent Bernoullis with probabilities
P (Y
mis,ij
=1| y
obs,i
, b
i
, θ)=
exp(x
ij
β + w
ij
b
i
)
1+exp(x
ij
β + w
ij
b
i
)
,j≥ J
+1. (6.10)
The dependence of these imputed values on the random effects covariance
matrix Ω is evidenced by the presence of b
i
in (6.10). By integrating out b
i
(as in Example 2.2), we have
p(y
mis,i
| y
obs,i
, θ)=
p(y
mis,i
| y
obs,i
, b
i
, θ) p(b
i
| θ, y
obs,i
) db
i
=
p(y
mis,i
| b
i
, β) p(b
i
| β, Ω, y
obs,i
) db
i
. (6.11)
The integral (6.11) is not available in closed form; however, recalling that the
population-averaged distribution can be approximated by
P (Y
mis,ij
=1| y
obs,i
, θ) ≈
exp(x
ij
β
)
1+exp(x
ij
β
)
,
where β
≈ βK(Ω)andK(Ω)isaconstantthat depends on Ω,thedepen-
dence on the random effects covariance matrix is clear. 2
Data augmentation and multiple imputation
Certain types of multiple imputation (Rubin, 1987) can be viewed as ap-
proximations to data augmentation. Bayesianly proper multiple imputation
(Schafer, 1997) provides an approximation to the fully Bayesian data augmen-
tation procedure in (6.3), which is based on the full-data response model; for
nonignorable missingness (Chapter 8), it would be based on the entire full-
data model. This approximation is computed by sampling just a few values,
say M ,fromp(y
mis
| y
obs
)(asopposed to full Monte Carlo integration). The
M sets of y
mis
are then usedtocreateM full datasets that are analyzed using
full-data response log likelihoods, (θ | y)orfull-data response model poste-
riors p(θ | y). Inferences are then appropriately adjusted for the uncertainty
in themissing values (Schafer, 1997).
Bayesianly ‘improper’ multiple imputation would sample M values from
some distribution, say p
(y
mis
| y
obs
), where
p
(y
mis
| y
obs
) = p(y
mis
| y
obs
).
This might be implemented when the imputation model is specified and fit
124 INFERENCE UNDER MAR
separately from the full-data response model (Rubin, 1987) or when auxiliary
covariates V arebeing used under an MAR assumption.
6.4 Covariance structures for univariate longitudinal processes
In Examples 6.1 and 6.2, we showed the importance of covariance specifica-
tion in incomplete data. We now describe a number of specific approaches to
accomplish this. For multivariate normal models where the dimension of Y
i
is large relative to the sample size, it is common to assume a parsimonious
structure for Σ to avoid having to estimate a large numberofparameters.
We discuss two classes of models that are computationally convenient to do
this. For the first class, we directly specify the covariance structure. For the
second, we specify the covariance structure indirectly via random effects.
6.4.1 Serial correlation models
Anatural parameterization on whichtointroduce structure for Σ in multivari-
ate normal models is via the parameters in the modified Cholesky decomposi-
tion (Pourahmadi, 1999). The parameters of this decomposition correspond to
the means and variances of the conditional distributions p(y
j
| y
1
,...,y
j−1
):
j =1,...,J,
E(Y
j
| y
1
,...,y
j−1
)=µ
j
+
j−1
k=1
φ
jk
(y
k
− µ
k
), (6.12)
var(Y
j
| y
1
,...,y
j−1
)=σ
2
j
. (6.13)
The autoregressive coefficients in (6.12),
{φ
jk
: k =1,...,j− 1; j =2,...,J},
are called generalized autoregressive parameters (GARP) and characterize the
dependence structure. The variance parameters in (6.13),
{σ
2
j
: j =1,...,J} ,
are called the innovation variances (IV). A major advantage of these param-
eters is that the GARP are unconstrained regression coefficients and the logs
of the innovation variances are also unconstrained, unlike the variance and
covariances {σ
jk
} of Σ.
The GARP/IV parameters are also natural for characterizing missingness
due to dropout and for characterizing identifying restrictions given their con-
nections to the conditional distributions p(y
j
| y
1
,...,y
j−1
). This was briefly
discussed in Example 5.11 and will be discussed in detail in Section 8.4.2 in
Chapter 8.
Before discussing a particular class of models based on the GARP and IV

COVARIANCE STRUCTURES 125
parameters, we review some approaches to explore the feasibility of different
parsimonious structures based on these parameters.
Exploratory analysis of GARP/IV parameters
Exploratory model selection can be conducted by examining an unstructured
estimate of Σ and by examining regressograms (Pourahmadi, 1999), which
plot the GARP and IV parameters vs. both lag and time. We illustrate both
these approaches on the schizophrenia data (Section 1.2). To simplify this
demonstration, we ignore the fact that the lag between the last two measure-
ments was 2 weeks, not 1 week.
Table 6.1 Schizophrenia trial: GARP parameters from fitting a multivariate normal
model. The elements in the matrix are φ
j,j+k
.
Week (j)
Lag (k)1 2 3 4 5
1.81.89.85 .68 .80
2–.07.03.30 .14
3.17–.10 .06
4–.02.03
5–.04
Table 6.1 showstheestimated GARP parameters from fitting a multivari-
ate normal model to the schizophrenia data. The lag-1 parameters (first row)
are the largest and appear to characterize most of the dependence. We can also
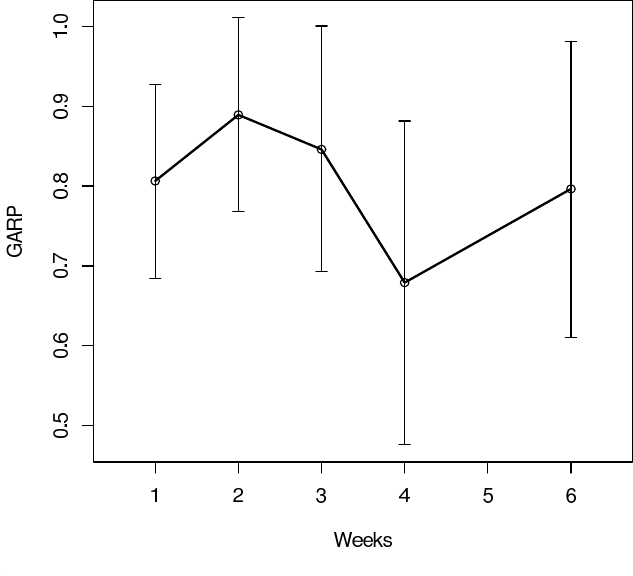
view the GARP graphically using regressograms. Figure 6.1 shows a regresso-
gram of the lag-1 GARP as a function of week (corresponding to the first row
of Table 6.1); there is little structure to exploit here other than potentially
assuming the lag-1 GARP are constant over week φ
j,j+1
= φ
1
.
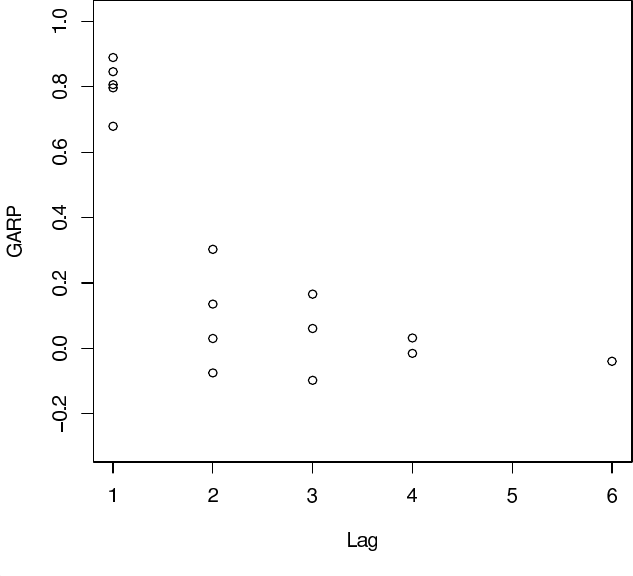
Figure 6.2 is another regressogram showing the GARP as a function of lag
(for example, the first column in the figure has a dot for each of the five lag-1
GARP given inTable6.1). The GARP for lags greater than 2 seem small,
suggesting these parameters can be fixed at zero. An alternative approach,
as suggested in Pourahmadi (1999) would be to model the GARP using a
polynomial in lag. Based on Figure 6.2, a quadratic might be adequate for
this data and would reduce the number of GARP parameters from fifteen to
three. Note that this model implicitly assumes that for a given lag, the GARP
are constant.
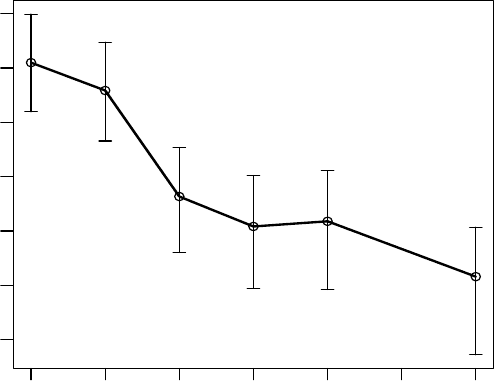
Figure 6.3 shows the log of the IV as a function of weeks. Clearly, the
126 INFERENCE UNDER MAR
Figure 6.1 Schizophrenia trial: posterior means of lag-1 GARP with 95% credible
intervals as a function of weeks.
innovation variances are decreasing over time andasimplelinear trend in
weeks would likely be adequate to model the IV, reducing the number of IV
parameters from six to two.
Structured GARP/IV models for Σ
Structured GARP/IV models (Pourahmadi and Daniels, 2002) specify linear
and log-linear models for the GARP and IV parameters, respectively, via
φ
jk
= v
jk
γ,k=1,...,j− 1; j =2,...,J
log(σ
2
j
)= d
j
λ,j=1,...,J. (6.14)
The design vector v
jk
can be specified as a smooth function in lag (j − k)(cf.
Figure 6.2) and/or a smooth function in j forafixedlagj − k (cf. Figure 6.1).
The design vector d
j
can be specified as a smooth function of j (cf. Figure
6.3). These smooth functions are typically chosen as low-order polynomials
COVARIANCE STRUCTURES 127
Figure 6.2 Schizophrenia trial: posterior means of GARP as a function of lag.
(or splines). Special cases of these models include setting φ
jk
= φ
|j−k|
for all
j and k, i.e., constant within lag (stationary) GARP. A first-order structure
would set φ
|j−k|
=0for|j − k| > 1.
Based on our exploratory analysis of the schizophrenia data, we might
specify a first order lag structure for the GARP. As such, the design vector
for the GARP would be
v
jk
=
1 |j − k| =1
0otherwise
with γ representing the lag-1 regression coefficient. We might specify a linear
model for the log IV, setting d
j
=(1,j)
T
.
Apracticaladvantage of structured GARP/IV models is that they allow
simple computations since the GARP regression parameters γ have full con-
ditional distributions that are normal when the prior on γ is normal (see
Pourahmadi and Daniels, 2002). In general, fitting these models in WinBUGS
128 INFERENCE UNDER MAR
0123456
3.8 4.0 4.2 4.4 4.6 4.8 5.0
Weeks
Log(IV)
Figure 6.3 Schizophrenia trial: posterior means of log of the IV as a function of
weeks.
can be difficult (slow mixing) because WinBUGS does not recognize that
the full conditional distributions of the mean regression coefficients and the
GARP regression parameters are both multivariate normal (see Pourahmadi
and Daniels, 2002). However, for some simple cases, these can be fit efficiently
in WinBUGS. In Chapter 7, we explore models based on these parameters
further (including the computations) for the Growth Hormone trial (Section
1.3).
6.4.2 Covariance matrices induced by random effects
Random effects are another way to parsimoniously model the dependence
structure. Whereas the GARP/IV modelsparameterize the covariance matrix
directly, random effects models induce structure on the covariance matrix
indirectly.
COVARIANCE STRUCTURES 129
Recall the normal random effects model (Example 2.1),
Y
i
| x
i
, b
i
∼ N(µ
b
i
, Σ
b
)
b
i
| Ω ∼ N (0, Ω),
with
µ
b
i
= x
i
β + w
i
b
i
.
Here, we set Σ
b
= σ
2
I.Themarginalcovariance structure for Y
i
,afterinte-
grating out the random effects, is
Σ = σ
2
I + w
i
Ωw
T
i
with j, k element
σ
jk
= σ
2
I(j = k)+w
ij
Ωw
T
ik
,
where w
ij
is the jth row of w
i
and dim(Ω)=q.Thevector of covariance
parameters has dimension q(q +1)/2+1 whereasthevector of parameters of
an unstructured Σ has dimension J(J +1)/2. Typically, q J.
For the schizophrenia clinical trial analysis in Chapter 7, we specify w
ij
usinganorthogonal quadratic polynomial (q =3).Assuch,wereduce the
number of covariance parameters from 21 to 7.
The random effects structure is an alternative to the GARP/IV struc-
ture and can also be used to introduce structured dependence in general-
ized linear mixed models (cf. Example 2.2). It is possible to combine struc-
tured GARP/IV models with random effects by decomposing Σ as Σ = Σ
b
+
w
i
Ωw
T
i
and modeling Σ
b
using a parsimonious GARP/IV model (Pourah-
madi and Daniels, 2002).
6.4.3 Covariance functions for misaligned data
As discussed in Example 2.4, a structured covariance is typically required
to estimate the covariance function for misaligned temporal data. We review
some examples next.
For temp orally misaligned longitudinal data, the covariance structure is
typically summarized via a covariance function,
cov(Y
ij
,Y
ik
|x
i
; φ)=C(t
ij
,t
ik
; x
i
, φ).
To draw inference about this function, simplifying assumptions (about the
process) or structure (on the function itself) are necessary because it is often
the casethatno(orfew)replications are available for observations at certain
times or pairs of times. In the remaining development, we drop the dependence
on x in the covariance function for clarity.
Acommon assumption is (weak) stationarity, where the covariance func-
tion C(t
ij
,t
ik
; φ)isonlyafunction of the difference between times, i.e.,