Витяев Е.Е. Извлечение знаний из данных. Компьютерное познание. Модели когнитивных процессов (2006)
Подождите немного. Документ загружается.

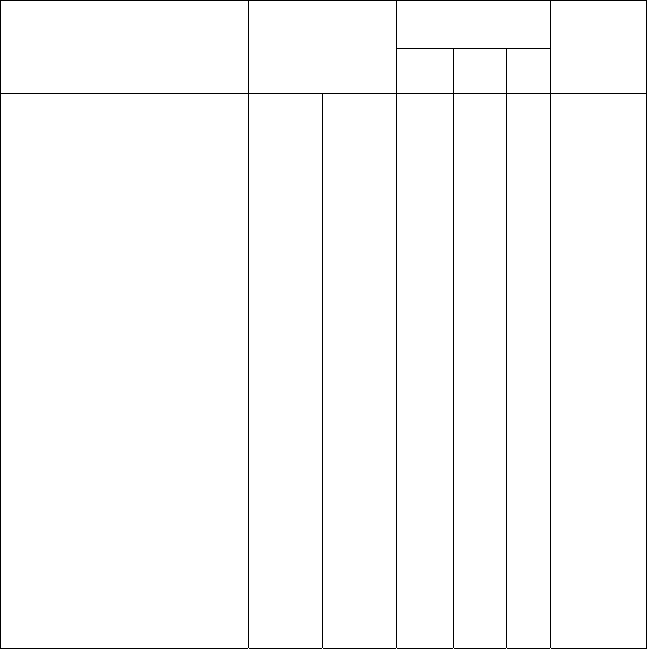
161
Эта таблица дает примеры обнаруженных правил вместе с их статистиче-
скими оценками.
Таблица 9
Примеры извлеченных диагностических правил
Значение F-
критерия
Диагностическое правило F-критерий
0.01 0.05 0.1
Точность
диагноза
на кон-
троле
IF NUMber of calcifications
per cm
2
is between 10 and 20
AND VOLume > 5 cm
3
THEN Malignant
NUM
VOL
0.0029
0.0040
+
+
+
+
+
+
93.3%
IF TOTal # of calcifications
>30 AND VOLume > 5 cm
3
AND DENSITY of calcifica-
tions is moderate
THEN Malignant
TOT
VOL
DEN
0.0229
0.0124
0.0325
-
-
-
+
+
+
+
+
+
100.0%
IF VARiation in shape of cal-
cifications is marked
AND NUMber of calcifica-
tions is between 10 and 20
AND IRRegularity in shape
of calcifications is moderate
THEN Malignant
VAR
NUM
IRR
0.0044
0.0039
0.0254
+
+
-
+
+
+
+
+
+
100.0%
IF variation in SIZE of calci-
fications is moderate AND
Variation in SHAPE of calci-
fications is mild
AND IRRegularity in shape
of calcifications is mild
THEN Benign
SIZE
SHAPE
IRR
0.0150
0.0114
0.0878
-
-
-
+
+
-
+
+
+
92.86%
Рис. 22 представляет результаты другого критерия выбора: уровень ус-
ловной вероятности. Мы рассмотрели три уровня 0.7, 0.85 и 0.95. Более
высокий уровень условной вероятности уменьшает количество правил и
диагностированных пациентов, но увеличивает точность диагноза. Их ре-
зультаты отмечены как MMDR1, MMDR2 и MMDR3. Нами было обнару-
жено 44 статистически значительных диагностических правила при
0.05 уровне F-критерия с условной вероятностью,
не меньшей, чем 0.75
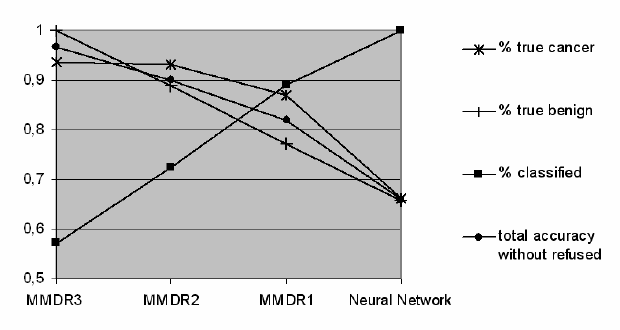
162
(MMDR1). Было обнаружено 30 правил с условной вероятностью, не
меньшей, чем 0.85 (MMDR2), и 18 правил с условной вероятностью, не
меньшей, чем 0.95 (MMDR3). Общая точность диагноза – 82 %. Ошибка
первого рода была 6.5 % (9 злокачественных случаев были диагностирова-
ны как доброкачественные); ошибка второго рода была 11.9 % (16 добро-
качественных случаев были диагностированы как злокачественные).
Самые надежные 30 правил дали точность 90 %, 18 самых надежных
правил
, выполненных с точностью на 96.6 %, только с тремя ошибками
второго рода (3.4 %).
Нейронная сеть
Brainmaker дала 100 % точность на обучении, но на
скользящем контроле точность упала до 66 %. Главная причина этой низ-
кой точности в том, что нейронные сети (NN) не оценивают статистиче-
скую значимость своего распознавания (100 %) на обучении.
Слабые результаты (76 % на контрольных обучающихся данных) были
получены линейным дискриминантным анализом (программное обеспече-
ние SIGAMD). Решающие деревья (программное обеспечение SIPINA) дал
точность 76–82 % на обучении. Этот результат хуже, чем результат метода
MMDR с намного более трудным испытанием скользящим контролем.
Очень важно, что ошибка первого рода была в 3–8 случаях (MMDR), в 8-9
случаях (решающие деревья), в 19 случаях (линейный дискриминантный
анализ) и 26 случаев (NN). В этих экспериментах, методы основанные на
правилах (MMDR и решающие деревья) выиграли у других методов.
Заметим также, что только MMDR и решающие деревья дают диагно-
стические правила. Эти правила делают автоматизированный диагности-
ческий процесс решения видимым и прозрачным для радиолога. С этими
Рис. 22
163
методами радиолог может управлять и оценивать процесс принятия реше-
ний. Линейный дискриминантный анализ дает уравнение, которое отделя-
ет доброкачественные и злокачественные классы, например
0.0670x
1
-0.9653x
2
+…. Как можно было бы интерпретировать взвешенное
количество кальцинозов на cм
2
(0.0670x
1
) плюс взвешенный объем (cм
3
),
т.e.
0.9653x
2
? В этой арифметике нет никакого прямого медицинского
смысла.
§ 64. Правила, извлеченные из эксперта
Примеры извлеченных диагностических правил извлеченных из экс-
перта.
Экспертное правило (ER1):
ЕСЛИ КОЛИЧЕСТВО кальцинозов в cм2 (w1) большое
И ОБЩЕЕ КОЛИЧЕСТВО кальцинозов (w3) большое
И неисправность в ФОРМЕ индивидуальных кальцинозов
отмечена,
ТО подозрение на злокачественное развитие.
Экспертное правило (ER2):
ЕСЛИ КОЛИЧЕСТВО кальцинозов в cм
2
(w
1
) большое
И ОБЩЕЕ КОЛИЧЕСТВО кальцинозов большое (w
3
)
И изменение в РАЗМЕРЕ кальцинозов (y
3
) отмечено
И ИЗМЕНЕНИЕ в Плотности кальцинозов (y
4
) отмечено
И ПЛОТНОСТЬ кальциноза (y
5
) отмечена,
ТО подозрение на злокачественное развитие.
Экспертное правило (ER3):
ЕСЛИ (ФОРМА и плотность кальцинозов положительны для рака
И Сравнение с предыдущей экспертизой положительно для рака),
ИЛИ (количество и ОБЪЕМ, занятый кальцинозами
положительны для рака
И ФОРМА и плотность кальцинозов положительны для рака),
ИЛИ (количество и ОБЪЕМ, занятый кальцинозами
положительны для рака,
И сравнение с предыдущей экспертизой положительно для рака),
ИЛИ ПРОТОКОВАЯ ориентация положительна для рака,
ИЛИ РЕЗУЛЬТАТЫ ИССЛЕДОВАНИЯ положительны для рака,
ТО биопсия рекомендуется.
Далее мы представляем некоторые другие извлеченные правила кратко
и формально. «Мал» означает подозрительность на злокачественное разви-
тие.
ЕСЛИ w2*y1 ТО Мал.
164
ЕСЛИ w2*y2 ТО Мал.
ЕСЛИ w2*y*3*y4*y5 ТО Мал.
ЕСЛИ w1*w3*y2 ТО Мал.
ЕСЛИ w1*w3*x5 ТО Мал.
§ 65. Извлечение правил используя монотонные Булевы функции
Мы получили Булево выражение для формы и плотности кальциноза
x
2
= ψ(y
1
, y
2
, y
3
, y
4
, y
5
) из информации в столбцах 1 и 4, следуя следующим
шагам:
i)
найти все максимальные нижние единицы для всех цепей в виде
элементарных конъюнкций;
ii)
исключить избыточные термины (конъюнкции) из окончательной
формулы (см. выражение (29) ниже).
Таким образом, из столбцов 2, 4 мы получим
x
2
= ψ(y
1
, y
2
, y
3
, y
4
, y
5
)
= y
1
y
2
y
2
y
3
∨ y
2
y
4
∨ y
1
y
3
∨ y
1
y
4
∨ y
2
y
3
y
4
∨ y
2
y
3
y
5
∨ y
2
∨ y
1
∨ y
3
y
4
y
5
и затем упростим это до y
2
∨ y
1
∨ y
3
y
4
y
5
.
Как и выше, из столбцов 2 и 3 мы получим начальные компоненты це-
левых функций от переменных
x
1
, x
2
, x
3
, x
4
, x
5
для подпроблемы биопсии
следующим образом:
f
1
(x) = x
2
x
3
∨ x
2
x
4
∨ x
1
x
2
∨ x
1
x
4
∨ x
1
x
3
∨ x
3
x
4
∨ x
3
∨ x
2
x
5
∨ x
1
x
5
∨ x
5
,
и для подпроблемы рака как:
f
2
(x) = x
2
x
3
∨ x
1
x
2
x
4
∨ x
1
x
2
∨ x
1
x
3
x
4
∨ x
1
x
3
∨ x
3
x
4
∨ x
3
∨ x
2
x
5
∨ x
1
x
5
∨ x
4
x
5
.
Упрощение этой дизъюнктивой нормальной формы (ДНФ) выражения
позволило нам исключать некоторые избыточные конъюнкции. Например,
в
x
2
термин y
1
y
4
не является необходимым, потому что
y
1
покрывает их.
Таким образом, правая сторона выражений даёт минимальные дизъюнк-
тивные нормальные формы.
Используя эту методику мы извлекли 16 правил для диагностического
класса «подозрительный на злокачественное развитие» и 13 правил для
класса «биопсия» (формулы (32), (33)).
Все эти правила получены из формулы (33), представленной ниже.
Точно так же для второй подпроблемы (образец очень подозрительный
на
рак) мы нашли функцию
f
2
(x) = x
1
x
2
∨ x
3
∨ (x
2
∨ x
1
∨ x
4
)x
5
. (29)
Относительно второго уровня иерархии (имеющую 11 двойных при-
знаков) мы в интерактивном режиме построили следующие функции (ин-
терпретация признаков представлена ниже):
x
1
= ν(w
1
, w
2
, w
3
) = w
2
∨ w
1
w
3
; (30)
x
2
= ψ(y
1
, y
2
, y
3
, y
4
, y
5
) = y
1
∨ y
2
∨ y
3
y
4
y
5
. (31)
165
Объединяя функции, получим формулы всех 11 признаков биопсии
f
1
(x)=(y
2
∨ y
1
∨ y
3
y
4
y
5
)x
4
∨( w
2
∨ w
1
w
3
)(y
2
∨ y
1
∨ y
3
y
4
y
5
) ∨
(w
2
∨ w
1
w
3
)x
4
∨ x
3
∨ x
5
(32)
и для подозрительности на рак
f
2
(x) = x
1
x
2
∨x
3
∨(x
2
∨x
1
∨x
4
)x
5
= (33)
(w
2
∨w
1
w
3
)(y
1
∨y
2
∨y
3
y
4
y
5
)∨x
3
∨(y
1
∨y
2
∨y
3
y
4
y
5
)∨(w
2
∨w
1
w
3
∨x
4
)x
5
.
§ 66. Сравнение экспертных и извлеченных из данных правил
Далее мы сравним некоторые правила, извлеченные из 156 случаев
системой
Discovery, и через интервью, взятого у радиолога.
На данных было обнаружено правило DR1:
ЕСЛИ количество кальцинозов в cм
2
(w
1
) между 10 и 20 И объем
(w
2
) > 5 cм
3
,
ТО злокачественный.
Самое близкое экспертное правило – ER1:
ЕСЛИ количество кальцинозов в cм
2
(w
1
) большое
И общее количество кальцинозов (w
3
) большое
И неисправность в ФОРМЕ индивидуальных кальцинозов (y
1
)
отмечена,
ТО злокачественный.
Среди экспертных правил нет правила DR1, но это правило статистиче-
ски значимо (0.01, F-критерий). Правило DR1 должно быть проверено ра-
диологом и включено в диагностическую базу знаний после его проверки.
Та же самая процедура проверки должна быть сделана для ER1. Это пра-
вило должно быть проанализировано на реальных случаях в данных. Этот
анализ
может привести к заключению, что база данных не достаточна, и
правило DR1 должно быть извлечено из расширенной базы данных. Кроме
того, радиолог может заключить, что набор признаков не достаточен, что-
бы включить правило DR1 в базу знаний. Такой анализ невозможен для
линейного дискриминантного анализа или нейронных сетей.
Мы проверили надежность экспертного радиолога на
30 реальных слу-
чаях. Он классифицировал эти случаи в три категории:
1) «высокая вероятность рака, биопсия необходима» (РБ).
2) «низкая вероятность рака, вероятно доброкачественная, но био-
псия через некторое время необходима» (или ДБ).
3) «доброкачественный, биопсия не необходима» (Д).
Эти случаи были взяты из отсканированных случаев для повторного
анализа увеличения кальцинозов. Для РБ
случаев и ДБ, сообщения о пато-
логичности биопсий подтверждали диагноз, в то время как два года потре-
бовалось для подтверждения доброкачественного статуса Д.
166
Диагноз эксперта был в полном согласии с его извлеченными диагно-
стическими правилами для 18 случаев и для 12 случаев эксперт запросил
больше информации, чем было дано в извлеченном правиле. Когда его
спросили, он ответил, что он имел случаи с той же самой комбинацией
11 признаков, но с другим диагнозом. Это предполагает, что нам
нужно
расширить набор признаков и набор правил, чтобы адекватно охватить бо-
лее сложные случаи. Восстановление монотонных Булевых функций по-
зволило нам идентифицировать эту потребность. Это – одно из полезных
использований этих функций.
Мы извлекли из базы данных следующее правило DR2:
ЕСЛИ изменения в размере кальцинозов умеренны
И изменения в форме кальцинозов умеренны
И нерегулярность в форме кальцинозов умеренна,
ТО доброкачественная.
Это правило подтверждено на 156 фактических случаях скользящим
контролем. Мы извлекли из этой базы данных все случаи, к которым это
правило применимо, т. е. случаи, где изменения в размере кальцинозов
умеренны, изменения в форме кальцинозов умеренны и нерегулярность в
форме кальцинозов умеренна. Для 92.86 % этих случаев правило точно.
Эксперт также имеет
правило с этой посылкой, но экспертное правило
включает два дополнительных признака: протоковая ориентация не при-
сутствует и нет сопутствующих результатов исследования (см. формулу
(32)). Это говорит о том, что база данных должна быть расширена, чтобы
определить, какое из правил является правильным.
Комментарии радиолога относительно правил, извлеченных из данных:
DB правило 1:
ЕСЛИ общее количество кальцинозов > 30
И объем > 5 cм
3
И плотность кальцинозов умеренна,
ТО
злокачественная.
F-критерий значим при уровне 0.05. Точность диагноза на контроле –
100 %. Комментарий радиолога
– это правило обещающее, но я считаю это
рискованным.
DB правило 2:
ЕСЛИ изменение в форме кальцинозов отмечено
И количество кальцинозов между 10 и 20
И неисправность в форме кальцинозов умеренна,
ТО – злокачественная.
F-критерий значим при уровне 0.05. Точность диагноза на контроле –
100 %. Комментарий радиолога
– я доверял бы этому правилу.
DB правило 3:
167
ЕСЛИ изменение в размере кальцинозов умеренно
И изменение в форме кальцинозов умеренно
И неисправность в форме кальцинозов умеренна,
ТО – доброкачественная.
F-критерий значим при уровне 0.05. Точность диагноза на контроле –
92.86%. Комментарий радиолога – я доверял бы этому правилу.
§ 67. Обсуждение и заключение
Исследование продемонстрировало, как можно извлечь из данных и
эксперта совместное множество знаний для медицинской диагностической
системы рака груди. Согласованная база знаий лишена противоречий меж-
ду правилами, полученными системой
Discovery, правилами, используе-
мыми опытным радиологом, и базой данных патологически подтвержден-
ных случаев.
Мы применили две комплиментарные интеллектуальные технологии
для извлечения правил и распознавания противоречий. Первая технология
основана на обнаружении статистически значимых логических диагности-
ческих правил. Вторая – на восстановлении монотонной Булевой функции
путем нахождения минимальной динамической последовательности во-
просов медику-эксперту.
Результаты этой взаимной проверки экспертных
правил и правил, выводимых из данных, демонстрируют реализуемость
подхода для создания совместных автоматизированных диагностических
систем.
168
ГЛАВА 7. ПРИЛОЖЕНИЯ РЕЛЯЦИОННОГО ПОДХОДА
В БИОИНФОРМАТИКЕ.
§ 68. Задача анализа регуляторных районов ДНК
Технологии извлечения знаний и Knowledge Discovery зарекомендовали
себя действенными рабочими инструментами решения различных ком-
плексных задач в биологии, включая исследование ДНК. Методики из-
влечения знаний, и других компьютерных подходов машинному обуче-
нию (
Machine Learning) были активно использованы в биоинформатике
[113; 130], для анализа баз данных. Системы извлечения знаний, основан-
ные на логике первого порядка, – особый класс технологий извлечения
знаний с большими выразительными возможностями для представления
комплексных паттернов.
Данная работа показывает реализацию логических технологий в обна-
ружении закономерностей в таблицах контекстных характеристик после-
довательностей ДНК, вовлеченных в
регуляцию транскрипции. Наша цель
– найти закономерности, которые устанавливают взаимосвязь между нук-
леотидными последовательностями и функциональным классом этих по-
следовательностей. Поиск закономерностей выполнен в программной сис-
темой
Gene Discovery, которая является адаптацией системы Discovery
применительно к задачам анализа генетических последовательностей.
Система Gene Discovery дает общий сценарий функциональной аннотации
произвольной нуклеотидной последовательности. Эта система берет моле-
кулярно-генетические данные из базы данных, используя SQL-запросы.
Последовательности не гомологичных генных промотеров, выделенных из
базы данных TRRD, были проанализированы с использованием этой сис-
темы. Были обнаружены закономерности, связывающие контекстные ха-
рактеристики
нуклеотидных последовательностей ДНК и их положение,
соответствующее началу транскрипции, с функциональным классом. Наш
подход, основанный на реляционном подходе к извлечению знаний, обна-
руживает олигонуклеотидные паттерны, описывающие некоторый функ-
циональный класс генов.
Как и с любой технологией, основанной на логических правилах, этот
метод позволяет получать удобные для восприятия человеком правила
прогноза, которые
легко интерпретируются в биологическом языке. Обна-
ружение закономерностей имеет две стороны: 1) обнаружение правил и 2)
обнаружение признаков промотерных районов и запись их как функцио-
нальную аннотацию генов. Биолог может оценить как правильность пред-
сказаний при аннотации, так и сами правила. Мы применили систему
Gene
Discovery [32–33; 35; 38; 114; 119; 121; 155–156] для функциональной ан-
169
нотации регуляторных районов. Система обнаруживает статистически
значимые правила в логике первого порядка для решения этой проблемы.
Анализ регуляционных районов генов очень важен для понимания мо-
лекулярных механизмов транскрипции. Регуляторные последовательности
составляют небольшую долю, грубо говоря 95 % генома млекопитающих,
которые не кодируют белки, но они определяют уровень, локализацию и
хронологию экспрессии генов [110].
Вопреки важности этих некодирую-
щих последовательностей в генной регуляции, наша возможность иденти-
фицировать и предсказать функции для этой категории ДНК сильно огра-
ничена.
Контроль экспрессии генов у эукариот первично определяется относи-
тельно короткими последовательностями (сигналами / мотивами) в облас-
ти промотера гена. Эти последовательности варьируются в длине, пози-
ции, обилии, ориентации в
цепи ДНК. Промотеры эукариот характеризу-
ются отсутствием точной локализации контекстных сигналов и их слабо-
стью [105]. Разнообразие промотеров – основная сложность в разработке
программ распознавания.
Существование консенсуса для многих известных транскрипционных
факторов использовалась для построения базы данных, в которой могут
быть найдены интересующие потенциальные транскрипционные факторы
(transcription factor binding sites (TFBS)), скрепляющие участки в последо-
вательностях
ДНК [115–116; 161]. Тем не менее нужные участки данных
были получены, хотя идентификация таких участков до сих пор представ-
ляет собой большие трудности. Мы ссылаемся на некоторое количество
программ, прогнозирующих участки, как на первый шаг по извлечению
знаний в структуре промотера [139; 140; 160; 161]. Вопреки факту, что не-
которые транскрипционные факторы связываются с высокоспецифичными
последовательностями ДНК
, большинство имеют небольшое количество
неизменных коровых последовательностей (около 4–6 bp), окруженных
варьирующим количеством нуклеотидов.
Мы разрешаем эту проблему, используя несколько методов:
1) использованием специализированных баз данных, таких как TRRD и
её секций [115–116];
2) комбинированием различных статистических программ прогнозиро-
вания;
3) оцениванием статистически определенных олигонуклеотидов, как
потенциальных TFBS [160].
TFBS или потенциальные сайты служат входной таблицей характери-
стик с точки зрения методов извлечения знаний. Компьютерное обнаруже-
ние областей регуляции генов является значительным вкладом в дополне-
ние к новым
экспериментальным подходам.
170
Основой для использования программных систем является обучающая
выборка нуклеотидных последовательностей промотеров. Трудно описать
все эукариотичные последовательности промотера с помощью некоторого
паттерна из-за огромной изменчивости различных TFBS. Чтобы преодо-
леть эту трудность, множества промотеров генов, выполняющих схожую
функцию, были извлечены из базы данных TRRD. Однако даже такие
функциональные наборы не имеют единственной
олигонуклеотидной мо-
дели, описывающей все последовательности. Отличительная особенность
алгоритма – использование специфических паттернов свойств, которые
описывают подгруппу обучающего набора.
Наша задача состоит в том, чтобы развить новый подход прогнозиро-
вания промотеров относящийся к проблеме комбинаторного регулирования
транскрипции, основанный на отобранных паттернах транскрипционных
факторах.
Главная цель этого исследования состоит в том, чтобы осуществить
функциональную аннотацию генов, используя ряд интегрированных мето-
дов распознавания регуляторных элементов и сайтов связывания
транс-
крипционных факторов
.
Анализ последовательности имеет несколько стадий:
1) осуществление компьютерного обнаружения потенциальных сайтов
связывания транскрипционных факторов в интересующей последователь-
ности и маркировка их местоположения;
2) определение является данная область гена регуляторной или струк-
турной (например, промотер, 5'UTR, 3'UTR, кодирующая последователь-
ность, энхансеры) на основании спрогнозированных сайтов связывания
транскрипционных факторов;
3) сравнение спрогнозированных структурных или функциональных
областей
с подобными областями на других генах (используя информа-
цию, накопленную в имеющихся базах данных);
4) осуществление функциональной аннотации генной последователь-
ности.
Трудно описать все эукариотические последовательности промотера
обычной моделью из-за разнообразия факторов транскрипции, связываю-
щих участки. Чтобы уменьшать такое разнообразие, мы изучили корегули-
руемые последовательности. Однако даже эти функциональные множества
не могли дать олигонуклеотидную модель общую для всех последователь-
ностей. Система
Gene Discovery имеет гибкость, чтобы искать структурные
модели типичные для целого множества последовательностей и для под-
множества последовательностей. Олигонуклеотидные паттерны включают
различное количество олигонуклеотидов.