Самсонова В.П., Мешалкина Ю.Л., Дядькина С.Е. Компьютерный практикум по курсу: математическая статистика в почвоведении
Подождите немного. Документ загружается.


К 250-летию Московского государственного
университета
им.
М. В. Ломоносова
В.П. Самсонова, Ю.Л. Мешалкина, СЕ. Дядькина
Практикум на компьютере по курсу:
«МАТЕМАТИЧЕСКАЯ СТАТИСТИКА»
Издательско-торговая корпорация «Дашков и К »
Москва, 2005

УДК 631.421
ББК (29.172+403)я7
С178
Рецензенты:
Е.В.
Шеин
- доктор биологических наук
Ю.Н.
Благовещенский
- доктор физико-математических наук
Рекомендовано Учебно-методической комиссией ф-та почвоведения МГУ в
качестве учебного пособия для студентов, обучающихся по специальности
013000 и направлению 510700 «Почвоведение»
В.П. Самсонова,
Ю.Л.
Мешалкина, СЕ. Дядькина. Практикум на
ком-
пьютере по
курсу:
«МАТЕМАТИЧЕСКАЯ СТАТИСТИКА»
:
М.: Изда-
тельско-торговая корпорация «Дашков и К »,
2005.
- 36с.
ISBN
5-94798-697-3
В пособии представлены задачи, выполняемые студентами ф-та почвове-
дения МГУ на компьютере в ходе практикума по курсу «Математическая
статистика». Приведены ход решения задач и примеры оформления отчетов.
Задачи посвящены следующим темам: описательная статистика, проверка
нормальности распределений, сравнение средних, дисперсионный анализ,
регрессионный анализ, кластерный анализ, метод главных компонент и дис-
криминантный анализ.
Для студентов, аспирантов и научных работников, занимающихся во-
просами почвоведения, экологии и агрохимии.
ISBN
5-94798-697-3
©
Московский государственный
университет, 2005

Занятие 1
Знакомство с пакетом STATISTICA. Ввод данных. Импорт и
экспорт данных. Описательная статистика (анализ единичной
выборки). Анализ распределений. Гистограммы
I. Статистические расчеты
1) Получите у преподавателя свой вариант данных, внимательно ознакомь-
тесь с ним (описание данных см. стр.33).
2) Войти в систему, под именем кафедры. Имя и пароль спросите у препо-
давателя. Запомните их или запишите. Создайте свой каталог на диске Y
в каталоге своей кафедры (biol4, geogr4 и т.д.). Назовите каталог своей
фамилией латинскими буквами.
3) В своем каталоге создайте файл, с помощью программы EXCEL для за-
писи результатов анализа. Назовите его RES1 (вместо точек поставь-
те начальные буквы фамилии не более 4). Введите свои данные, как они
даны на странице 2 варианта. Сохраните файл, но не закрывайте его.
4) Откройте программу STATISTICA.
Запуск программы.
Нажмите кнопку ПУСК в левом нижнем углу экрана, укажите в меню
курсором мыши на команду ПРОГРАММЫ. В появившемся меню выбе-
рите STATISTICA. Выберите в меню Basic Statistics (Основные стати-
стики) и щелкните еще раз левой кнопкой мыши. В появившемся меню
Basic Statistics and Tables выберите клавишу Cancel.
5) Создайте файл для своих данных.
Создание файла.
В таблице появятся последние данные, с которыми работала программа,
или таблица будет пустой. Надпись на синем поле над таблицей Data:
NEW.STA 10v*10c указывает параметры файла, с которым происходит
работа: NEW - имя файла, .STA - расширение, с которым работает
STATISTICA , 10v - число переменных, Юс - число строк.
Создание нового файла эквивалентно сохранению уже существующего
файла под новым именем. Для этого подведите курсор мыши в строке
меню к пункту File (файл) и щелкните левой кнопкой мыши. В появив-
шемся меню выберите команду Save As (сохранить как). В появившемся
диалоговом окне выберите свою директорию на диске Y, введите имя
своего нового файла латинскими буквами. Имя файла не должно быть не
более 8 знаков, оно должно легко запоминаться и ассоциироваться с
данными. Лучше всего выберите свои инициалы или сокращение от фа-
милии. Запомните или запишите это имя! Нажмите кнопку Сохранить в
правом нижнем углу окна. На появившийся вопрос: "File exists and will be
overwritten. Do you want to create backup file?" - ответьте утвердительно
3

(YES).
Если название таблицы данных (надпись на синем фоне не изме-
нилась) - повторите процедуру сохранения еще раз. (Выберите в строке
меню пункт File и т.д.). Выйдите из программы STATIST1CA. Для этого
выберете в строке меню пункт File, затем в появившемся подменю - Exit.
Ответьте на вопрос о прекращении работы утвердительно (Current analy-
sis in progress/ Do you want to close it? - Yes).
Открытие подготовленных данных.
После запуска программы STATISTICA появятся последние данные, с
которыми работала программа. Для открытия нужного файла выберите в
меню File, затем пункт Open Data. Далее стандартным образом указыва-
ется, откуда будут взяты данные.
6) Наполните созданный файл своими данными для занятий
1
и 2.
7) Постройте таблицу статистических характеристик для переменных. От-
кройте пункт панели Basic Statistics and Tables. Если он уже был от-
крыт, но неактивен, щелкнуть по нему два раза. При всяких сбоях и
трудностях для восстановления меню данных нажать кнопку Analysis из
строки меню и выбрать либо Startup Panel (возврат к головному меню),
либо Resume analysis (возврат к предшествующей панели).
8) Выберите пункт Descriptive Statistics (Описательные статистики).
Щелкните по нему два раза, откроется панель расчета описательных ста-
тистик и попутного графического анализа. Щелкнув по верхней левой
кнопке Variables вы получаете возможность выбрать переменные для
анализа
(Если переменные идут не подряд, их можно выделить, щелкая по ним
мышью при нажатой клавише Ctrl).
Выберите все переменные.
В области Statistics нажмите кнопку More Statistics и выберите все ста-
тистики (АН).
9) Нажав кнопку ОК закройте эту панель и выйдите в предыдущую. Нажав
ОК в правом верхнем углу вы запустите анализ.
10) Выделите результаты анализа, щелкнув по левому полю результирую-
щей таблицы. Нажмите кнопку File в строке меню, выберите в открыв-
шейся панели Сору, затем активизируйте Excel и скопируйте туда дан-
ные.
Переключитесь в программу STATISTICA. (Если Вы провели ана-
лиз только для одной переменной, то для выхода в предыдущую панель
нажмите кнопку Continue в левом верхнем углу таблицы и повторите
анализ для других выборок).
11) Сохраните результирующий файл в формате Excel. Отредактируйте таб-
лицу следующим образом: Выделите таблицу, скопируйте ее в верти-
кальный вариант (смотреть пример отчета): Сору - Специальная
вставка- отметить галочкой транспонировать -ОК. Поставьте русские
4

названия статистических характеристик.
Проверьте правильность набивки данных и, следовательно, полученных
результатов по значению суммы всех значений для каждой переменной.
При необходимости исправьте ошибки набивки.
II.
Техника Box-Whisker Plot («коробочка с усиками») для пилотного
(предварительного) анализа данных.
12) Выберите Box-Whisker Plot и постройте графики 1) Медиана-квартили-
лимиты (Median-Quart-Range) и 2) среднее- односигмовый предел- до-
верительные интервалы (Mean/SE/1.96*SE). Перенесите полученный
график в Excel. Для этого щелкните по кнопке File в строке меню, выбе-
рите Сору, затем активизируйте Excel и скопируйте туда данные.
III.
Построение гистограмм.
12) В пункте Descriptive Statistics (Описательные статистики) проанализи-
руйте распределения переменных (Область Distributions). Щелкните по
очереди по всем окошкам в этой области, в них появятся галочки. Это
обеспечит вам расчет разных статистических критериев и соответствую-
щих им уровней значимости (р). Щелкнув по кнопке Histograms, вы по-
лучите график гистограммы и значения разных критериев с соответст-
вующими им уровнями значимости.
13) Перенесите полученный график в Excel. Для этого щелкните по кнопке
File в строке меню, выберите Сору, затем активизируйте Excel и скопи-
руйте туда данные.
IV. Техника Normal probability plot. (Нормальная вероятностная бумага)
14) Ознакомьтесь с техникой Normal probability plot, нажав на кнопку с
соответствующим названием. Постройте графики. Перенесите получен-
ный график в Excel. Для этого щелкните по кнопке File в строке меню,
выберите Сору, затем активизируйте Excel и скопируйте туда данные.
5
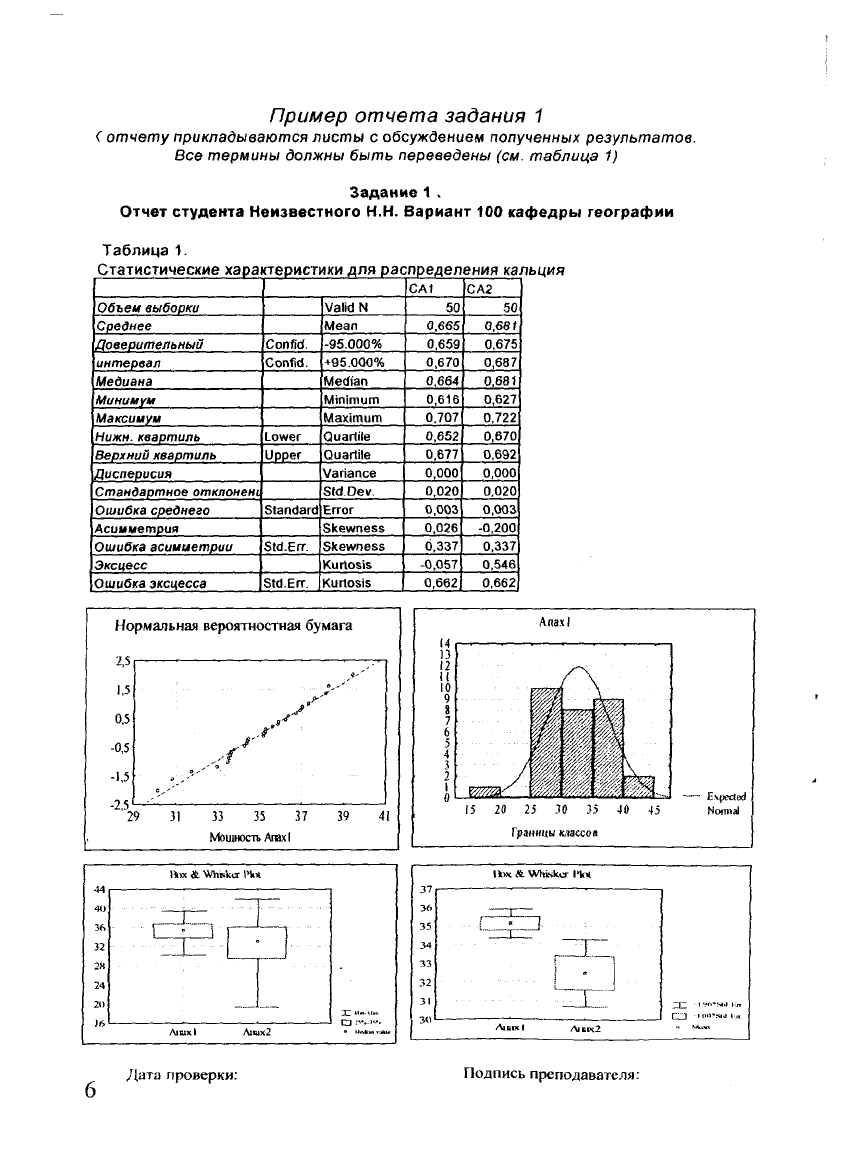
Пример отчета задания 1
< отчету прикладываются листы с обсуждением полученных результатов
Все термины должны быть переведены (см. таблица 1)
Задание 1 .
Отчет студента Неизвестного Н.Н. Вариант 100 кафедры географии
Таблица 1.
Статистические характеристики для распределения кальция
Объем выборки
Среднее
Доверительный
интервал
Медиана
Минимум
Максимум
Нижн. квартиль
Верхний квартиль
Дисперисия
Стандартное отклонен1
Ошибка среднего
Асимметрия
Ошибка асимиетрии
Эксцесс
Ошибка эксцесса
Confid.
Confid.
Lower
Upper
Standard
Sld.Err.
Std.Err.
Valid N
Mean
-95.000%
+95.000%
Median
Minimum
Maximum
Quarlile
Quartile
Variance
Std.Dev.
Error
Skewness
Skewness
Kurtosis
Kurtosis
CA1
50
0,665
0,659
0,670
0,664
0,616
0,707
0,652
0,677
0,000
0,020
0,003
0,026
0,337
-0,057
0,662
CA2
50
0,681
0,675
0,687
0,68)
0,627
0,722
0,670
0,692
0,000
0,020
0,003
-0,200
0,337
0,546
0,662
Нормальная вероятностная бумага
-2,5
29
.•*
•Г
33 35 37
Мощность Anaxl
15
20 Ъ 30 .Ъ 40
4 з
Границы классов
Expected
Norma]
44
40
36
32
2Х
24
20
16
Г»к & VWlBkcr 1>V»
, i_ .
•J—.
|
~E^-
•
Aiux
1
AI&IX2
X M«-«.i
37
36
35
34
33
32
31
ЗО
\Ък & Whisker I'k*
Г -~J-
_j
n.
~
. ... 1 • ]
ТТ./
Л|Е1Х1 Л|Е1Х2
IZ1 >
Дата проверки:
6
Подпись преподавателя:

Занятие 2
Проверка гипотез о типе распределения. Сравнение средних.
1) В каталоге создайте файл Excel для записи результатов. Назовите его
RES2...
.(вместо точек поставьте начальные буквы фамилии- не более 4).
I. Проверка гипотез о типе распределения
2) Запустите программу STAT1STICA. В появившемся окне выберите раз-
дел Nonparametrics/Distrib. (Непараметрические методы/ распределе-
ния).
Если такого пункта нет, то в верхней строке меню выберите Analy-
sis,
затем пункт Other Statistics и выберите пункт Nonparamet-
rics/Distrib. и щелкните по кнопке Switch to (переключиться в ). Затем
нужно выбрать из двух альтернатив -Distribution Fitting . Затем выбрать
распределение (Normal). Щелкнув по кнопке Variables, выберите пере-
менную, для которой будет проводиться анализ, нажмите кнопку ОК. В
окошках следующей панели появятся значения статистических характе-
ристик (среднее, дисперсия), число классов, верхние и нижние пределы.
На этом этапе можно изменить параметры аппроксимирующего распре-
деления, число классов, пределы варьирования для переменной. Подбор
аппроксимирующего распределения можно сделать и для части массива
(кнопка Select Cases- отбор случаев). Выбор условий в области Kolmo-
gorov-Smirnov test (тест Колмагорова -Смирнова) позволяет либо от-
ключить его, либо выбрать непрерывную форму критерия, либо форму
для группированных (categorized) данных. Используйте параметры
предлагаемые по умолчанию.
3) Нажатие кнопки ОК приведет к вычислению таблицы частот и значений
критерия хи-квадрат и Колмогорова Смирнова и соответствующих им
уровней значимости (р). Скопируйте результаты в файл Excel, который
можно либо создать предварительно, либо активизировать Excel из про-
граммы STATIST1CA (Пуск-Программы- Excel-пиктограмма нового фай-
ла).
Щелкнув по кнопке STATISTICA внизу, вернитесь в программу. Для
активизации модуля щелкните по нему (слева) и выберите Восстано-
вить.
4) Познакомьтесь с графическими возможностями, нажав кнопку Graph.
5) Повторить вычисления для второй переменной.
6) Повторить вычисления, выбрав вместо нормального распределения лога-
рифмически нормальное. Запишите результаты в файл Excel .
П. Проверка гипотез о равенстве средних.
7) Войти в программу STATISTICA. В появившемся окне выберите раздел
Basic Statistics. Если такого пункта нет, то в верхней строке меню выбе-
рите Analysis, затем пункт Other Statistics и выберите пункт Basic
7

Statistics. Нажмите Switch To. В появившемся окне нажмите Open data и
выберите свои данные. Вообще при всяких сбоях и трудностях восста-
новления меню анализа нажать кнопку Analysis из строки меню и вы-
брать либо Startup Panel (возврат к головному меню), либо Resume
analysis (возврат к предшествующей панели).
8) В меню второго уровня выберите пункт t-test for independent variables
(в других версия программы STAT1STICA этот пункт может называться
t-test for independent Samples).
Теория
Верхняя строка определяет характер сравнений - для двух файлов в целом
(Each variable contains the data for one group) или сравнение будет прово-
диться для частей файла согласно кодовой переменной (one record per case
(use a grouping variable).
В качестве опций возможен расчет t-критерия как с объединением диспер-
сий,
так и с раздельным их расчетом (t-test with separate variance estimates).
Для выбора опций щелкните в окошках Options.
Запуск счета возможен либо нажатием кнопки
T-test,
либо ОК. В резуль-
тате появляется таблица со значениями t-критерия для выбранных пере-
менных.
9) Выберите переменные для сравнения (пункт Variables). Поставьте пере-
ключатель типа сравнения в положение Each variable contains the data
for one group. Отметьте опции сравнения как сравнение при раздельном
расчете дисперсий (t-test with separate variance estimates). Нажмите ОК.
Скопируйте получившиеся результаты в файл Excel. Повторите расчет,
отметив в опциях сравнение с одинаковыми дисперсиями, для этого сни-
мите значок. Отметьте для себя, чем отличаются эти две таблицы. Какая
из них короче и почему?
10) Скопируйте получившиеся результаты в файл Excel по образцу. Исполь-
зуйте возможность транспонирования при вставке данных : Сору
—
Спе-
циальная вставка- отметить галочкой транспонировать-ОК.
8
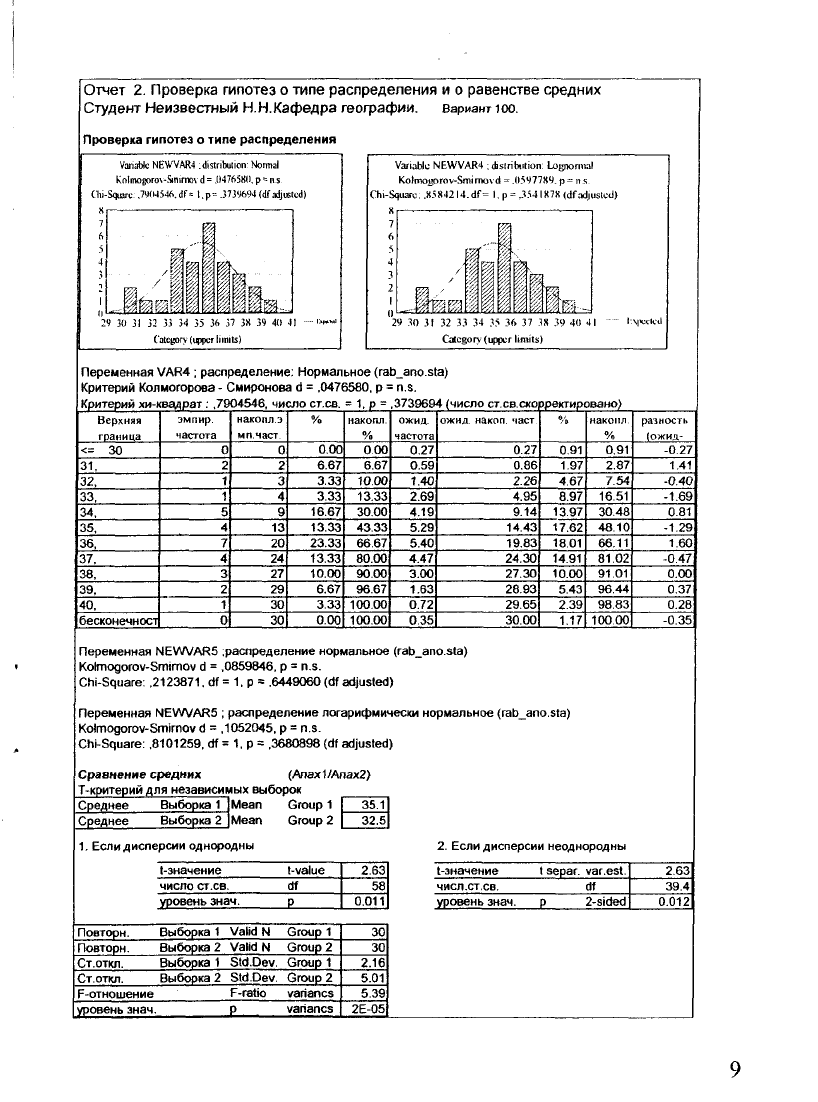
Отчет 2. Проверка гипотез о типе распределения и о равенстве средних
Студент Неизвестный
Н.Н.Кафедра
географии, вариант юо.
Проверка гипотез о типе распределения
Variable NEWVAR4 :distribution- Normal
KolmogorovSnirnov
d =
.0476580,
p
~ n s
Chi-Squarc.,7y04546.tJf=l.p-.373%94(dfadiiBtcd)
ItoJ
1
mu
32 53 34 35 36 37 3» 39 40 -II
C'ategor>(upper
limits)
Variable NEWVAR4
:
distribution Lxjjjnomial
KoluKujorov-Smimovd = .05977X9. p = n s
Chi-Square. .8584214.df= I. p= .3541878 (df adjusted)
29 30 31 32 33 34 35 36 37 38 39 40 41
Gregory (upper limits)
Переменная VAR4 ; распределение: Нормальное (rab_ano.sta)
Критерий Колмогорова - Смиронова d = ,0476580, р = n.s.
Критерий хи-квадрат : ,7904546, число ст.са. = 1, р = 3739694 (число ст ев скорректировано)
Верхняя
граница
эмпир.
частота
накопл.э
мп.част
%
накопл
%
ожид.
частота
ожид. накоп. част накопл
%
разность
(ожид
30
0.00 0.27 0.91
-0.27
6.67
6.67 2.87
1.41
32,
3.33 10.00
7.54
-0.40
-1.69
0.81
-1.29
1.60
-0.47
0.00
0.37
0.28
-0.35
33,
34,
16.67 30.00 4.19
13 97
30.48
35,
13 13.33 43.33 5.29 14.43 17.62
23.33
66.67 5.40 19.83 1801 66.11
13.33
80.00 4.47 24.30 81.02
27 10.00 90.00 3.00 27.30 10.00 91.01
6.67 96.67 28.93 96.44
3.33
100.00 0.72 29 65 98.83
бесконечност 30
0.00
100.00
035
30.00 100 00
Переменная NEWVAR5 распределение нормальное (rab_ano.sta)
Kolmogorov-Smirnov d = ,0859846, р = n.s.
Chi-Square.
,2123871,
df = 1, p « ,6449060 (df adjusted)
Переменная NEWVAR5 ; распределение логарифмически нормальное (rab_ano.sta)
Kolmogorov-Smirnov d = ,1052045, p = n.s.
Chi-Square: ,8101259, df = 1,p = ,3680898 (df adjusted)
Сравнение средних (Апах1/Апах2)
Т-критерий для независимых выборок
Среднее Выборка 1
Среднее Выборка 2
Mean
Mean
Group 1
Group 2 32.5
1.
Если дисперсии однородны
2.
Если дисперсии неоднородны
t-значение
число ст.св.
уровень знач.
t-value
df
Р
2.63
58
0.011
t-значение
числ.ст.св.
уровень знач.
t
separ.
var.est.
df
p
2-sided
2.63
39.4
0.012
Повтори.
Выборка 1 Valid N Group 1
Повтори.
Выборка 2 Valid N Group 2
Ст.откл.
Ст.откл.
Выборка 1 Std.Dev. Group 1
F-отношение
уровен!
Выборка 2 Std.Dev. Group 2
F-ratio
variance
30
30
2.16
5.01
5.39
2E-05

Вопросы к семинарскому занятию 1
К отчету должны быть приложены подробные письменные ответы. Они
должны быть основаны на результатах, полученных по своим данным и по
данным студентов той же кафедры.
Влияние особенностей выборок на статистические характеристики и
результаты проверки гипотез о типе распределения. Сравнение средних.
1.
Что характеризуют данные? Как они получены?
2.
Насколько близки различные характеристики центра распределений для
показателей. О чем может свидетельствовать их совпадение? О чем мо-
жет свидетельствовать их значительное расхождение?
3.
Какие из показателей имеют распределения, близкие к нормальному? (по
данным всей группы)
4.
Сравните представление Median-Quart-Range (Медиана- Квартили- Раз-
мах) и Mean/SE/1,96*SE (Среднее- Стандартное отклонение - 1,96 * на
Стандартное отклонение.). Какую информацию можно получить, ис-
пользуя каждое из этих представлений?
5.
В каких случаях может использоваться техника "Нормальная вероятно-
стная бумага" (Normal probability plot)?
6. Чем отличаются выводы, сделанные относительно характера распределе-
ния на основании статистических критериев и на основании техники
"Нормальная вероятностная бумага" (Normal probability plot)?
7.
Как влияет выбор критерия на результат принятия или отвержения гипо-
тезы о типе распределения?
8. Как влияет выбор уровня значимости на результат принятия или отвер-
жения гипотезы о типе распределения?
9. Можно ли считать дисперсии свойств однородными?
10.
Как влияет признание дисперсий неоднородными на конечные выводы
проверки гипотезы о равенстве средних?
11.
Как влияет уровень значимости на результаты проверки гипотезы о ра-
венстве средних?
12.
Чему равно число степеней свободы для критерия сравнения средних при
равенстве дисперсий? В случае неравенства дисперсий?
13.
Как влияет отличие распределений свойств от нормального на результа-
ты сравнения средних?
10