Растригин Л.А. Адаптация сложных систем
Подождите немного. Документ загружается.


где
(6.3.10)
Здесь U — двоичный вектор, характеризующий
распределение блоков
памяти по сети:
U = (u
11
, ..., u
n1
, ..., u
nm
);...... (6.3.11)
Q(U) — интенсивность обращения к банку данных всех ЭВМ сети;
первые ограничения (6.3.10) связаны с ограниченностью пропускной
способности каждой ЭВМ: при нарушении хотя бы одного из них
образуется бесконечная очередь заявок; вторые ограничения в (6.3.10)
совпадают с (6.3.2).
Полученная задача (6.3.9) является задачей стохастического
программирования с булевыми переменными (6.3.11) большой
размерности пт. Для ее решения прежде всего необходимо иметь
информацию о вероятной структуре (6.3.3) потоков решаемых задач,
интенсивности (6.3.7) этих потоков и интенсивности (6.3.8) решения
задач в сети. Но именно эту информацию труднее всего выявить.
Более того — и поток задач, и интенсивности обслуживания могут
изменяться во времени непредсказуемым образом [274].
Следовательно, задачу распределения памяти по сети следует
решать адаптивным способом. Воспользуемся для этого методами
эволюционной адаптации.
6.3.3. Адаптивное распределение памяти в сети ЭВМ
Естественной адаптивной мерой образования памяти ЭВМ в сети
является сохранение наиболее часто используемых блоков
информации. Сделать это можно следующим образом.
Пусть первоначальное распределение блоков по ЭВМ было
произвольным (например, случайным):
I
10
, ..., I
n0
, (6.3.12)
где I
i0
— начальное множество номеров блоков информации, рас-
положенное в памяти i-й ЭВМ. На это множество наложено
ограничение по объему (6.3.2) в виде
(6.3.13)
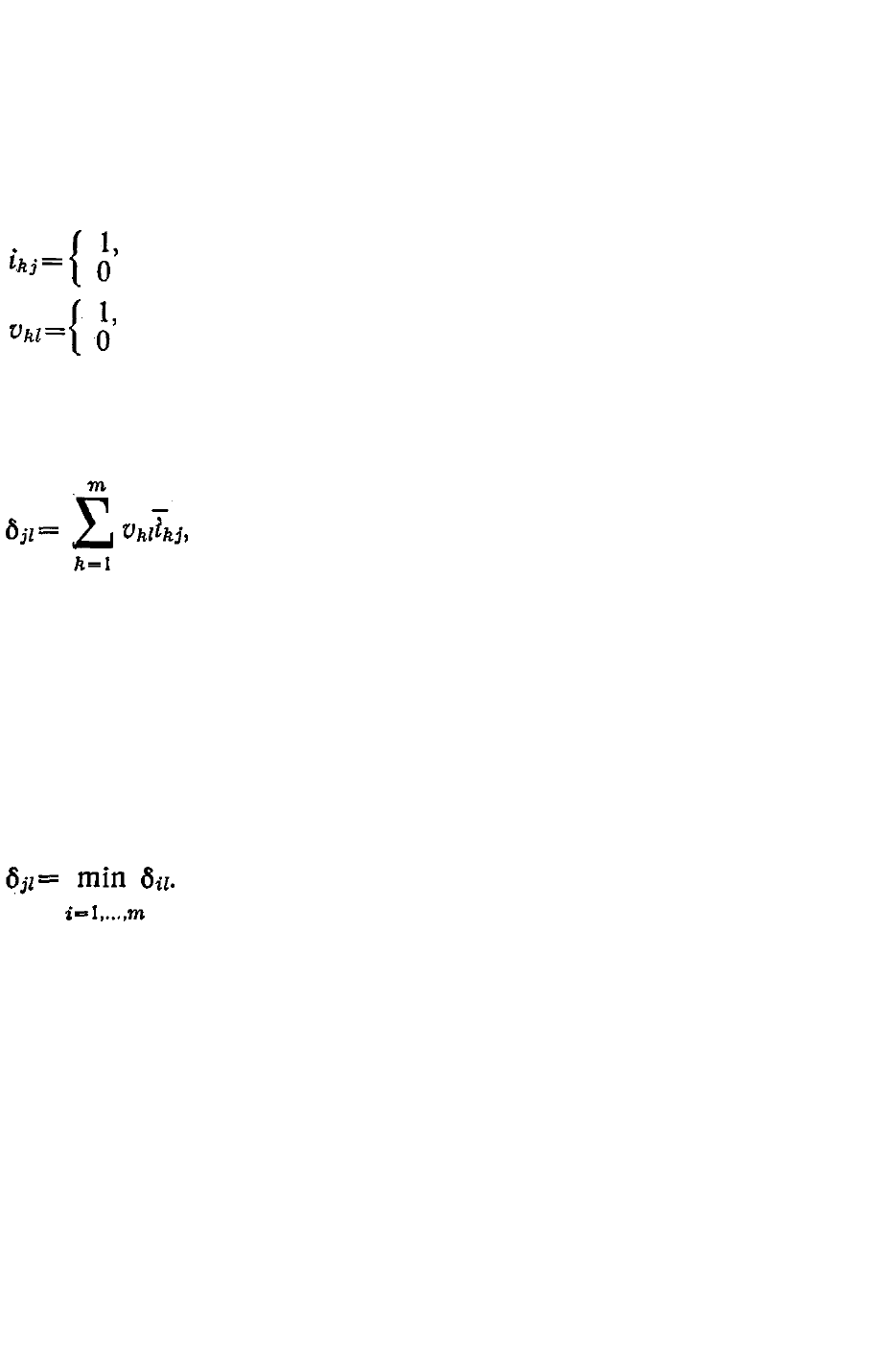
Заявка (задача) представляет собой множество V номеров блоков
информации, требуемых для ее обслуживания (решения). Представим
I и V в виде двоичных n-мерных векторов:
I
j
= (i
1j
, ..., i
mj
) (j = 1, ..., n); (6.3.14)
V
l
= (v
1l
, ..., v
ml
) (l = 1, ...).
где
если k-й блок имеется в памяти j-й ЭВМ; . в
противном случае;
если l-й заявке необходим k-й блок информации; в
противном случае.
На двоичных векторах (6.3.14) введем функцию,
определяющую число запрошенных l-й заявкой блоков информации,
не обеспеченных содержимым памяти j-й ЭВМ:
(6.3.15)
где верхней чертой обозначено логическое
отрицание. Каждая l-я заявка сопровождается
вектором
∆ = (δ
1l
, ..., δ
ml
) (6.3.16)
и направляется на обслуживание в ту (j-ю) ЭВМ, для которой 8ц
минимально, т. е. требует минимальных затрат обращения к банку
данных:
(6.3.17)
Если у j-й ЭВМ очередь превышает величину v
j
, то
заявка переправляется к другой машине, для которой δ
il
минимально
(исключая i=j). Там заявка принимается на обслуживание, если
очередь к ней не превышает v
i
. В противном случае заявка
направляется к другой ЭВМ и т. д.
Таким образом, в дисциплину обслуживания входит, вектор
предельных длин очередей
N = (v
1
, ..., v
m
), (6.3.18)
который также может адаптироваться (но уже параметрическим
образом).
Адаптация памяти каждой ЭВМ происходит после обслуживания
очередной заявки. Здесь задача состоит в том, чтобы определить новое
состояние памяти i-й ЭВМ I
i,N+1
по предыдущему
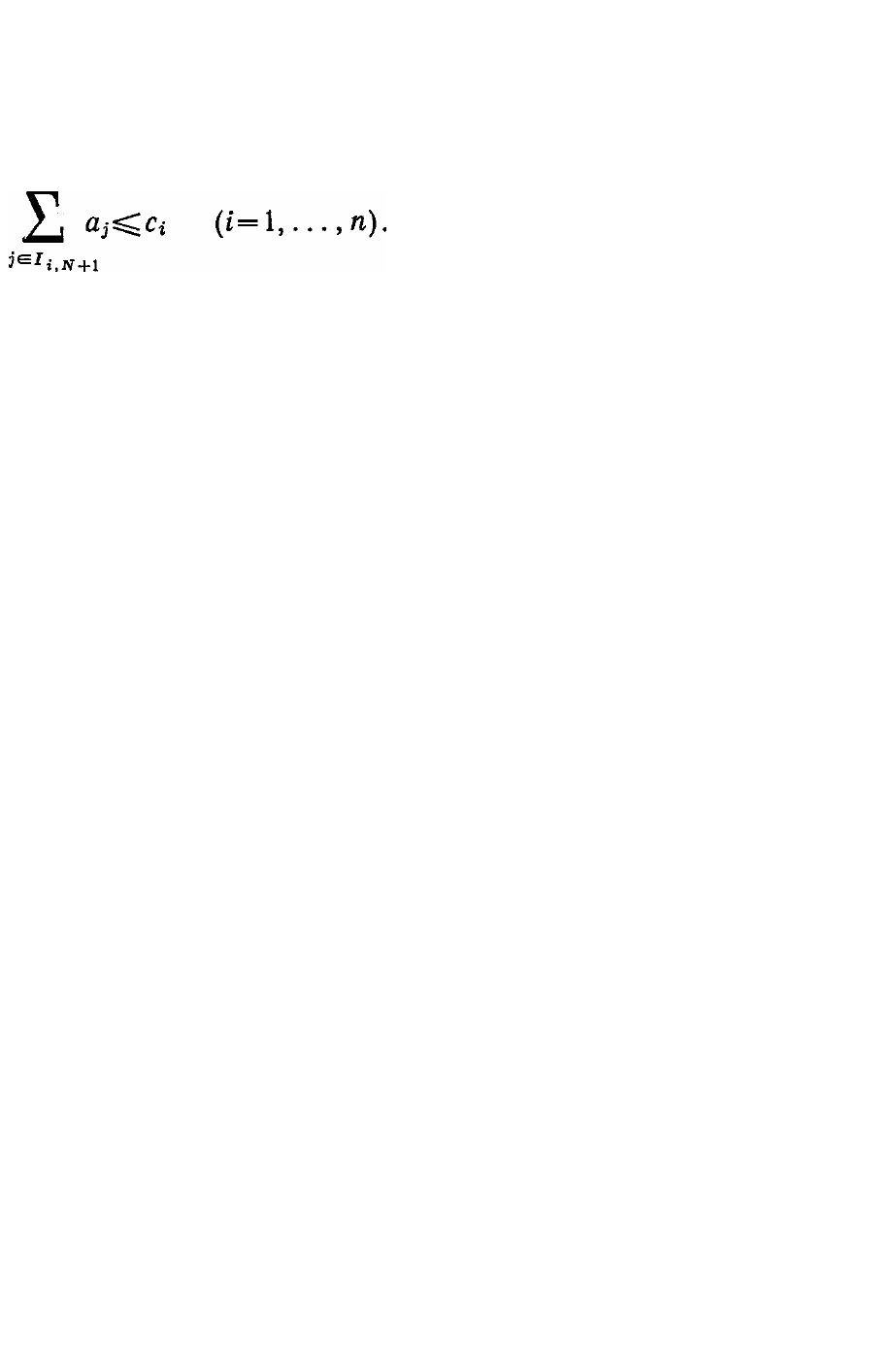
I
i,N
и множеству новых номеров Z
N+1
блоков, полученных в данный
момент из банка данных. Очевидно, что
I
i,N
∩ Z
N+1
= 0, (6.3.19)
т. е. эти множества не пересекаются. При этом I
i,N+1
должно
удовлетворять ограничению
(6.3.20)
Следовательно, работу алгоритма
адаптивного изменения памяти можно представить в виде
преобразования:
I
i,N+1
= φ(I
i,N
, Z
N+1
), (6.3.21)
где φ — алгоритм адаптации.
В качестве такого алгоритма могут быть использованы известные
алгоритмы замещения [3], предложенные для обмена между основной
и вспомогательной памятью ЭВМ:
1. Алгоритм случайного замещения формирует из двух мно
жеств I
i,N
и Z
N+1
одно случайное, удовлетворяющее условию
(6.3.20), таким образом, чтобы не осталось ни одного блока, ко
торый можно было бы разместить в памяти, не нарушив условия
(6.3.20).
2. Алгоритм «первый пришел — первый обслужен», в соответ
ствии с которым из памяти удаляются (замещаются) те блоки,
которые дольше находились в ней.
3. Алгоритм замещения наименее используемых блоков. В
этом случае из памяти удаляются блоки, которые дольше всех
не запрашивались при работе данной ЭВМ.
4. Многоуровневые алгоритмы замещения [3], которые сво
дятся к организации на каждом шаге приоритетных списков и
принятию решения на их базе. Эти алгоритмы обобщают преды
дущие.
Хотя перечисленные алгоритмы вполне работоспособны, они не
используют идей адаптации.
Предложим новый рандомизированный алгоритм φ. Пусть
каждому j-му блоку информации, находящемуся в памяти любой ЭВМ
сети, соответствует число h
j,N
, выражающее уровень приоритета этого
j-го блока в момент N (индекс i номера ЭВМ здесь можно снять, так
как алгоритм одинаков для всех ЭВМ сети).
Введем монотонно возрастающую функцию ψ(h), такую, что
0 ≤ ψ(h
j,N
) ≤ 1 (j = 1,..., т'), (6.3.22)
где т' — число блоков, претендующих на сохранение в памяти ЭВМ.
Значение этой функции можно рассматривать как вероятность
сохранения соответствующего блока в памяти.
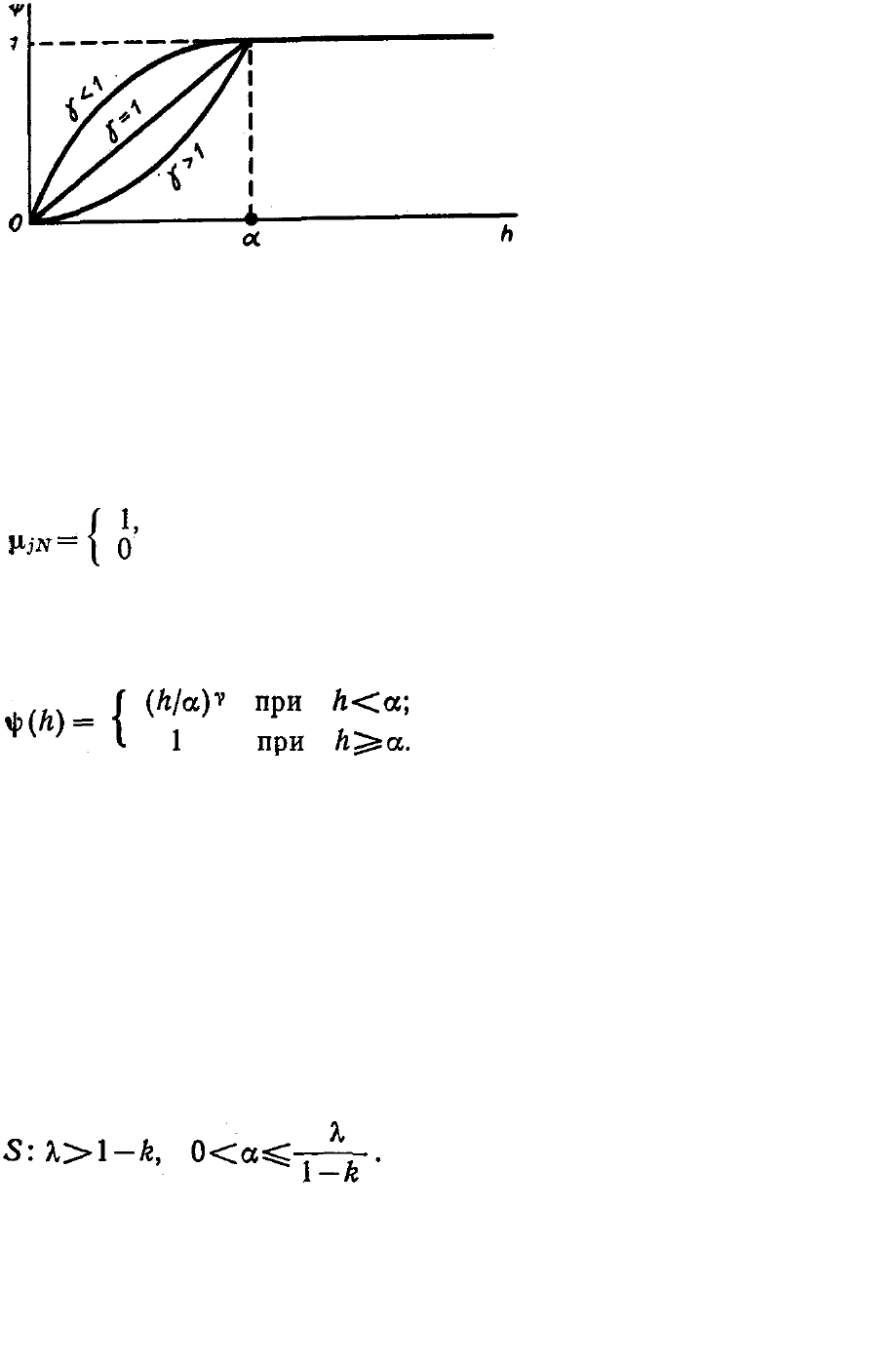
Рис. 6.3.1. График функции
ψ(h).
Итак, задача адаптации сводится к формированию такой функции
ψ и преобразованию значения весов h
j
. Естественно воспользоваться
следующей рекуррентной формулой:
h
j,N+1
= kh
j,N
+ λµ
j,N
, (6.3.23)
где 0<k< 1 и λ>0 — параметры;
если j-й блок использовался в момент N; в
противном случае.
Видно, что при постоянном использовании j-го
блока h
jN
→ λ / (1 — k), а при неиспользовании h
jN
→ 0.
Функцию ψ(h) (рис. 6.3.1) удобно представить в виде
(6.3.24)
Ее параметрами являются 0 < α < λ /
(1 — k) и γ>0. Завершает определение алгоритма φ задание начального
значения параметра h для веса новых блоков:
h
j0
= δ (j = 1, ..., m). (6.3.25)
Таким образом, алгоритм φ адаптации памяти ЭВМ в сети
рандомизирован и однозначно определяется набором из пяти не-
отрицательных параметров
С = (k, λ, α, δ), (6.3.26)
изменяемых в очевидных пределах
(6.3.27)
С помощью этих параметров
оптимизируется работа ЭВМ: минимизируется ее обращаемость к
банку данных в процессе решения задач.
Как видно, описанный алгоритм адаптивного распределения
памяти по сети ЭВМ имеет ярко выраженную иерархическую

структуру. На первом (нижнем) уровне иерархии производится
адаптивное образование памяти каждой ЭВМ и адаптация этого
процесса
(6.3.28)
по критерию Q(C, υ
i
) — обращаемости данной i-й
ЭВМ к банку данных. На втором уровне производится адаптация
параметров N (6.3.18) — порогов каждой ЭВМ, т. е. решается задача
(6.3.29)
где — выбранный критерий функционирования всей
сети, например среднее время решения одной задачи в сети и т. д., а
— множество допустимых порогов:
Таким образом, эффективность
алгоритма эволюционной адаптации памяти каждой ЭВМ сети и сети в
целом зависит от набора параметров (6.3.26) и (6.3.18), которые
следует адаптировать параметрическим образом.
Эксперименты по эволюционной адаптации такого рода показали
работоспособность и эффективность данного подхода даже без
параметрической адаптации [143, 144, 211, 282—284].
§ 6.4. Эволюционная адаптация
структуры решающих правил
Проблема принятия оптимального решения Y в ситуации X
сводится к синтезу решающего правила R, связывающего ситуацию и
решение:
Y = R (Х). (6.4.1)
Простейшей задачей принятия решений является задача о
распознавании (классификации) двух образов, в которой
, где 0 и 1 являются именами различаемых образов (классов).
Рассмотрим эту проблему с точки зрения эволюционной адаптации
[62].
Задача обучения распознаванию образов заключается в построении
оптимального решающего правила R* из некоторого априорно
выбранного класса функций, определяющего структуру решающего
правила. Если структура выбрана удачно, то в результате обучения
возможно построить хорошее решающее правило. Однако обычно
имеющейся априорной информации
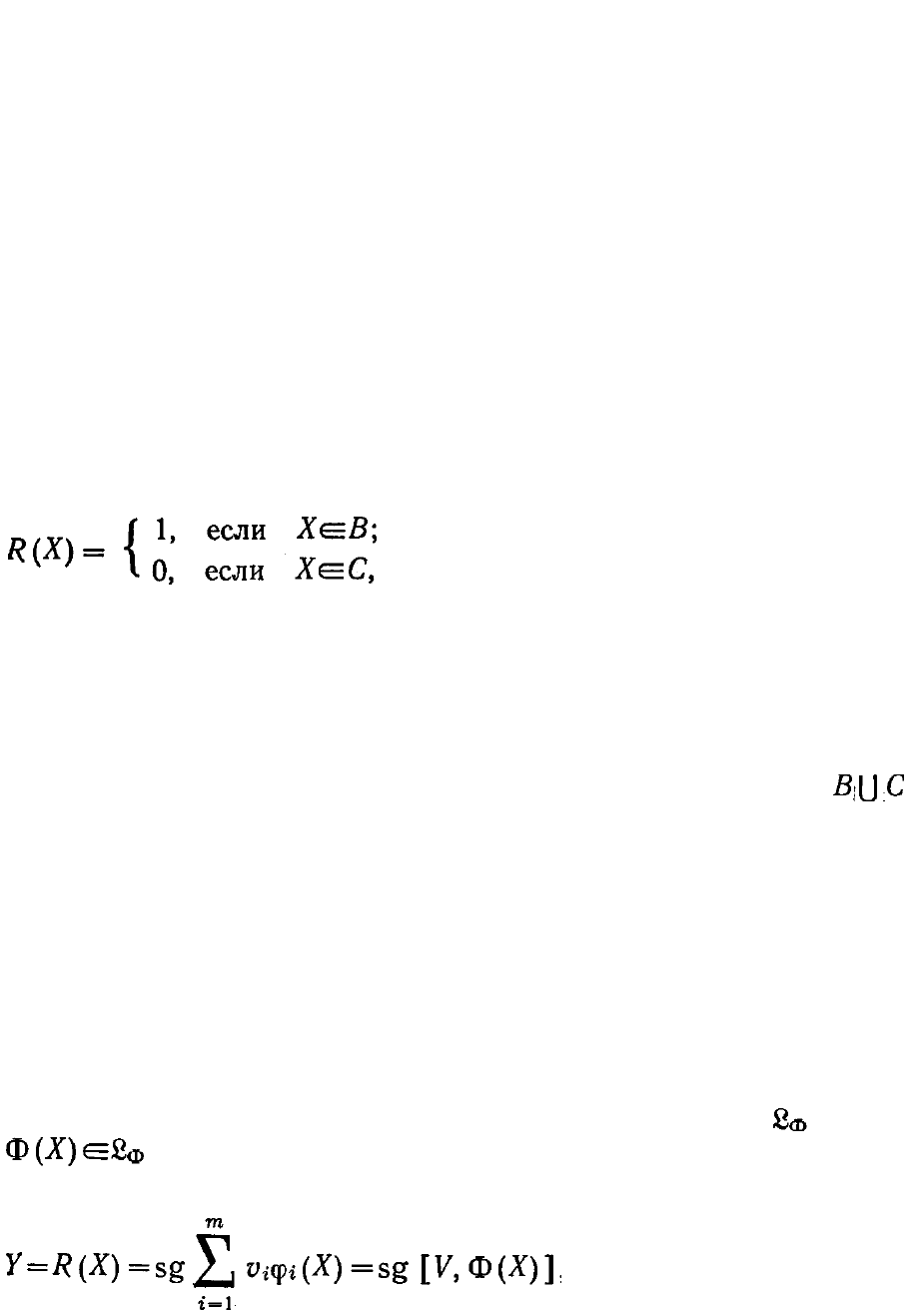
оказывается недостаточно для правильного выбора структуры ре-
шающего правила, поэтому построенное таким образом решающее
правило может значительно отличаться от требуемого, рационального
(не говоря уже об оптимальном).
В связи с этим возникает важная проблема адаптации структуры
решающего правила к конкретной задаче распознавания. Для ее
решения необходимо в процесс обучения ввести процедуру поиска
оптимальной структуры решающего правила, т. е. сочетать процесс
обучения решающего правила с оптимизацией его структуры.
6.4.1. Постановка задачи
Задача обучения классификации объектов, как известно, за-
ключается в построении в процессе обучения решающего правила
вида
(6.4.2)
где X — n-мерный вектор, описывающий
распознаваемый объект; В и С — множества, соответствующие двум
различаемым классам объектов (объекты класса В имеют имя «1», а
класса С — имя «0»).
Выражение (6.4.2) реализует в n-мерном пространстве признаков
{X} разделяющую поверхность для всех объектов множества .
Однако для определения решающего правила R(X) используется
только некоторое подмножество объектов из В и С, составляющее
конечную обучающую последовательность длины L<∞. Поэтому
задача обучения классификации обычно представляется как задача
аппроксимации заранее неизвестной разделяющей поверхности другой
поверхностью, достаточно близкой к первой, но построенной на базе
конечной обучающей последовательности.
Один из наиболее распространенных подходов к решению этой
задачи заключается в представлении искомой разделяющей функции в
виде разложения в ряд по некоторой системе функций Ф(Х),
выбираемой однократно из априорно заданного класса , т. е.
. Искомое решающее правило в этом случае
описывается выражением
(6.4.3)
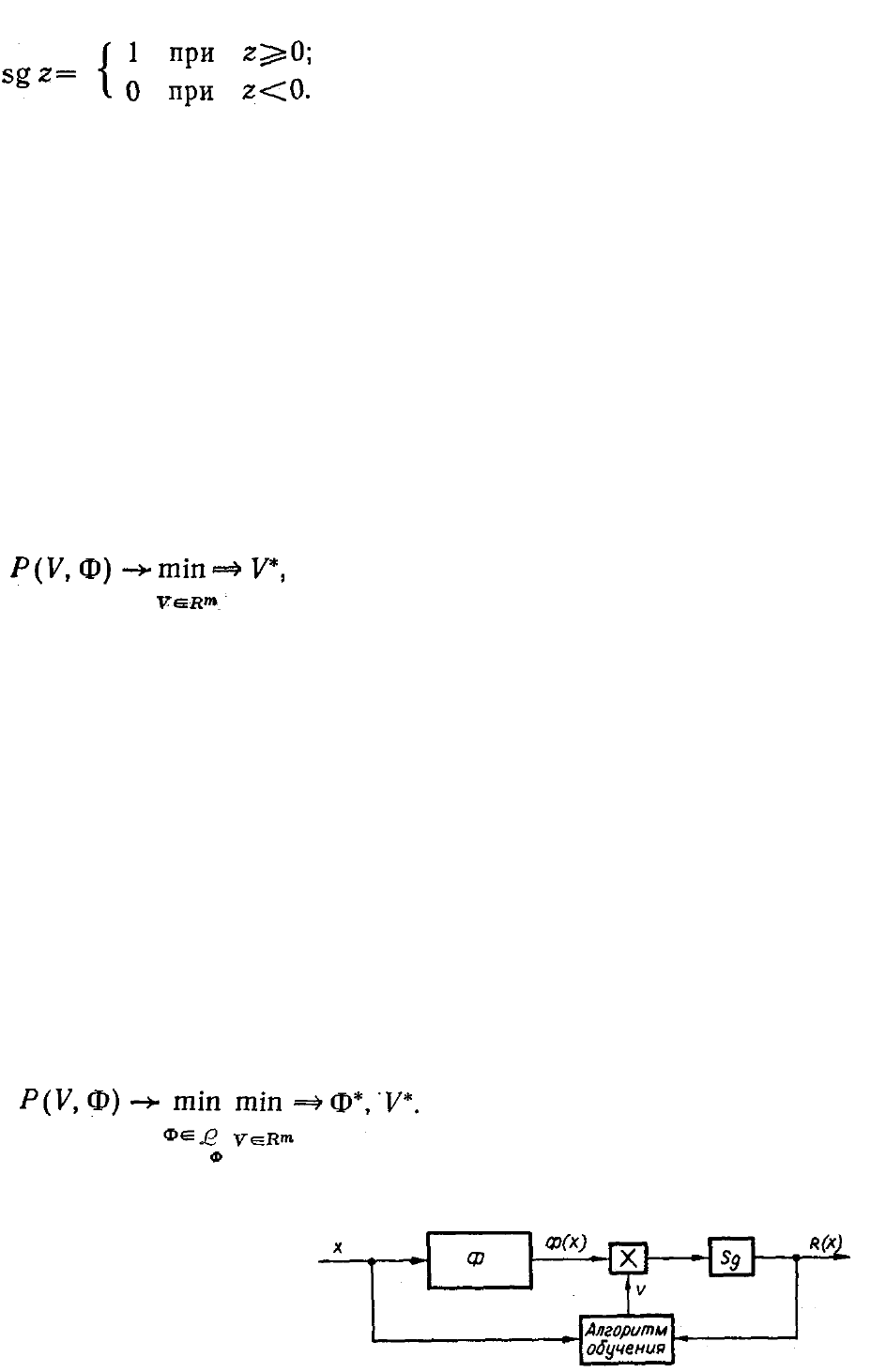
где
(6.4.4)
Система функций Ф(Х) = {φ
l
(X), ..., φ
m
(X)}
определяет структуру правила R(X), V = (v
1
, ..., v
m
) — вектор его весов,
а через [V, Ф(X)] обозначено скалярное произведение векторов V и
Ф(X).
Задача построения оптимального решающего правила R за-
ключается в определении параметров V таким образом, чтобы
обеспечить наилучшую аппроксимацию действительной разделяющей
поверхности, т. е. эффективно приблизить искомое правило (6.4.3) к
действительному (6.4.2).
Обозначим через P(V,Ф) эмпирический риск (число ошибок на
обучающей последовательности) искомого решающего правила R
(6,4.3). Тогда задачу наилучшей аппроксимации можно рассматривать
как задачу минимизации эмпирического риска по параметрам V в
процессе обучения при неизменной, априорно выбранной структуре
Ф, т. е.
(6.4.5)
где R
m
— евклидово пространство размерности т, а V* — результат
решения задачи. Решение (6.4.5) и есть обучение.
Для решения этой задачи разработаны многочисленные алгоритмы
обучения. Общая блок-схема такого обучения приведена на рис. 6.4.1.
В зависимости от выбора системы функций Ф(Х) схема может
описывать метод потенциальных функций [13], классический
перцептрон [199] и др.
Однако во многих конкретных задачах имеющиеся априорные
соображения либо оказываются недостаточными для правильного
выбора системы функций Ф(X), либо отсутствуют. В таких случаях
естественно адаптировать структуру Ф решающего правила R в
процессе обучения. Тогда оптимальное решающее правило,
обеспечивающее наилучшую аппроксимацию, будет определяться из
условия минимума функционала эмпирического риска при вариации
структуры решающего правила:
(6.4.6)
Блок-схема этой процедуры приведена на рис. 6.4.2.
Рис. 6.4.1. Блок-схема
обучения решающего
правила при заданной
структуре.

Рис. 6.4.2. Блок-схема
обучения с адаптацией
структуры решающего
правила.
Для решения такой задачи удобно представить систему функции Ф
в виде
Ф = Ф' (X, S),
где Ф' — заданная система функций, a S — вектор, кодирующий
структуру этой системы. Тогда задачу адаптации структуры ре-
шающего правила можно сформулировать как задачу отыскания
оптимальной структуры S* в процессе обучения:
(6.4.7)
где Ω — множество допустимых структур. Ввиду обилия допустимых
структур S решение задачи адаптации целесообразно производить
методами случайного поиска. (Заметим, что возможна и
параметризация структуры перцептрона, которая была успешно
использована в работе [176], где для этого применялась процедура
многомерной линейной экстраполяции [186].)
6.4.2. Адаптация структуры перцептрона
Адаптация структуры решающего правила исследовалась в классе
перцептронных решающих правил, определяемых выражением (6.4.3),
в котором v
i
— вес i-гo А элемента, a φ
i
(X,S) — пороговая функция,
реализуемая i-м А-элементом перцептрона:
(6.4.8)
где x
j
— выходной сигнал j-го
элемента сетчатки (x
j
{0; 1}, j = = 1, ..., n); θ
j
— порог j-го A-
элемента; s
ji
— коэффициент связи между j-м элементом сетчатки и i-
м A-элементом (s
ji
{-1; 0; 1} в зависимости от наличия и знака связи,
i = 1, ..., m).
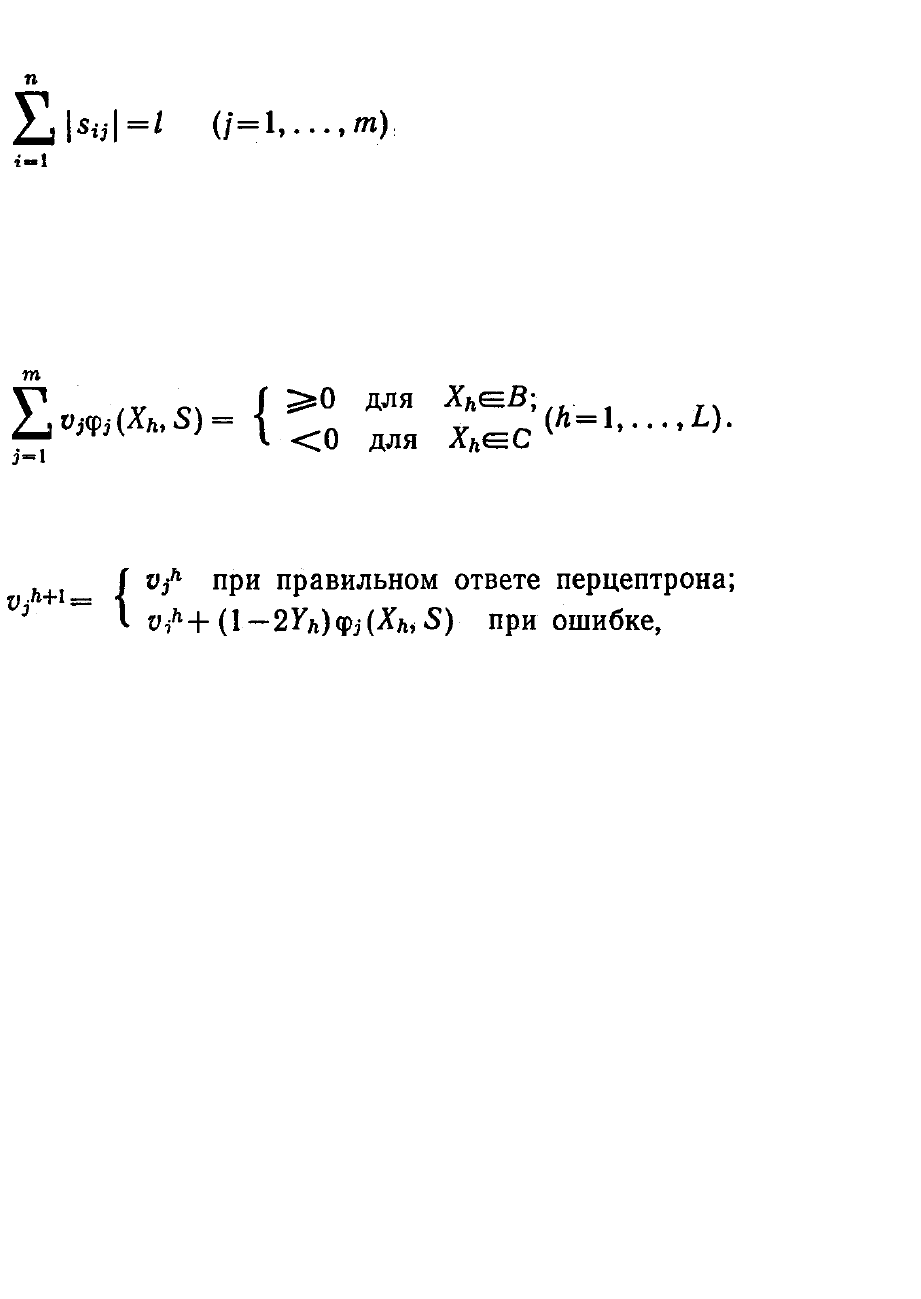
Матрица S = || s
ij
||
n x n
, составленная из коэффициентов связи с
учетом ограничения
(6.4.9)
где l — число входов каждого элемента, полностью определяет
структуру решающего правила. В обычном перцептроне эта матрица
определялась однократно и случайно, причем процедура обучения
(6.4.5) сводилась к формированию вектора V весов A-элементов таким
образом, чтобы на заданной обучающей последовательности L
удовлетворялись соотношения
(6.4.10)
Для обучения
использовалась α-система подкрепления с коррекцией ошибок [199]. В
случае, если величина подкрепления принимается равной ± 1, этот
алгоритм может быть записан в следующем виде:
(6.4.11)
где h — номер предъявляемого объекта (или такт обучения), а Y
h
—
выход перцептрона, определяемый соотношением (6.4.3) для X
h
.
Реализуемое перцептроном решающее правило, таким образом,
может быть представлено в виде Y = R (X, V, S), где матрица S
определяет структуру, а вектор V — параметры.
В работе [199] показано, что для случая непересекающихся
классов объектов элементарный перцептрон с исходной матрицей S и
бесконечным числом A-элементов всегда позволяет построить точную
разделяющую поверхность. Однако при ограниченном числе A-
элементов (что всегда бывает в реальных системах) построенное из
условия (6.4.5) решающее правило может значительно отличаться от
оптимального, т. е. соотношение (6.4.10) может не выполняться для
непересекающихся классов. Это, например, будет иметь место тогда,
когда непересекающиеся в исходном n-мерном пространстве
рецепторов {X} перцептрона классы оказываются пересекающимися в
m-мерном пространстве A-элементов (т. е. когда объектам разных
классов соответствует одинаковый бинарный код, образованный
выходами A-элементов) .
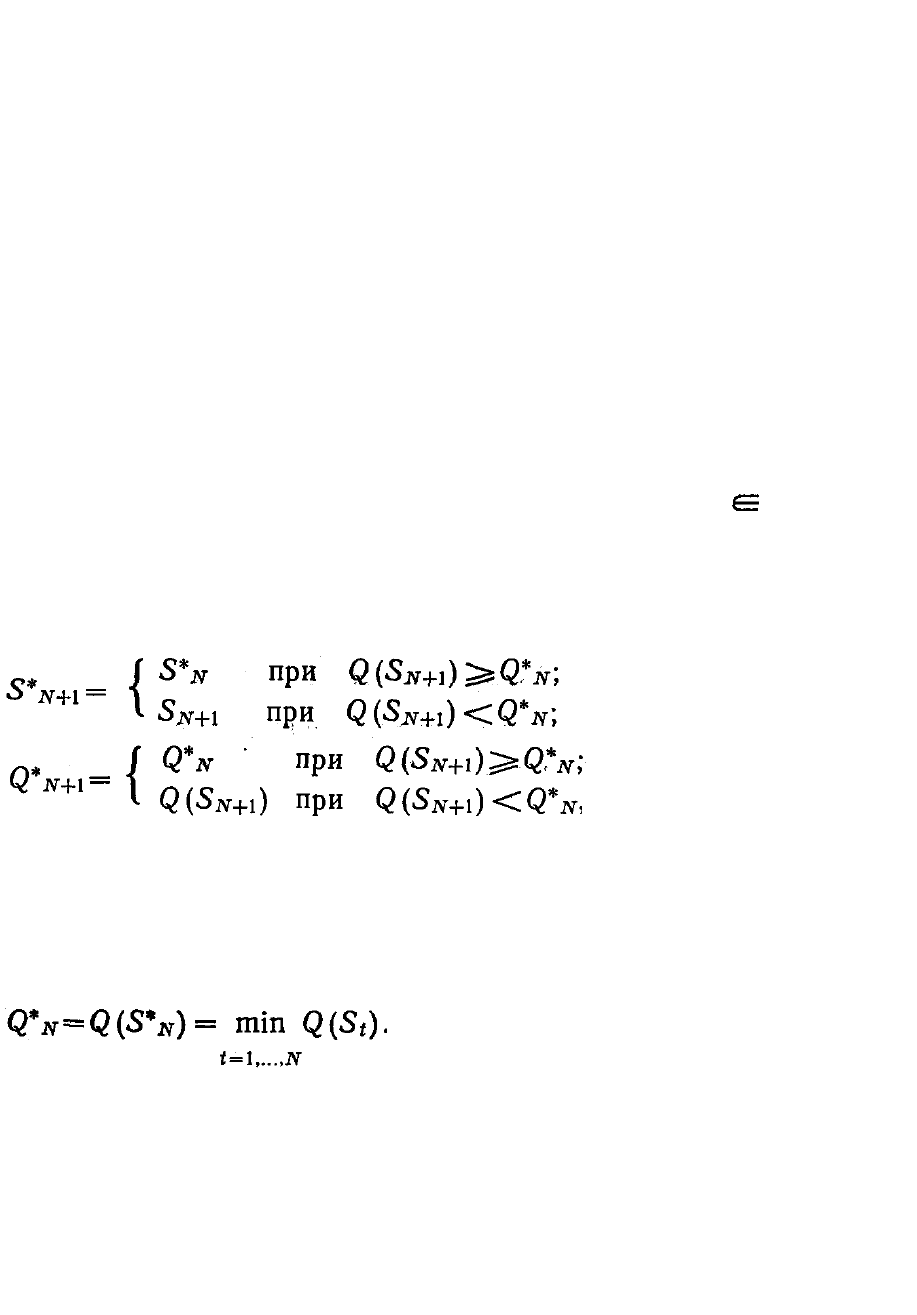
В таких случаях в процессе обучения необходима адаптация
структуры связей между сетчаткой и A-элементами к конкретной
задаче, т. е. к заданной обучающей последовательности объектов. Для
этого в перцептрон должен быть дополнительно введен процесс
адаптации — поиск оптимальной матрицы S, минимизирующей
эмпирический риск (6.4.6), причем ввиду многомерности структуры
связей А-элементов с сетчаткой для ее оптимизации наиболее
целесообразно использовать методы случайного поиска (см. главу 3).
Здесь можно применить следующие алгоритмы случайного поиска.
1. Алгоритм случайного поиска структуры связей всех А-
элементов с сетчаткой. Этот алгоритм представляет собой слу-
чайный перебор матриц S:
S
N
= Ξ, (6.4.12)
где S
N
— матрица S на N-м шаге случайного поиска; Ξ — случайная
матрица п×т, элементы которой случайны и равны s
ij
{-1; 0; 1} с
учетом ограничения (6.4.9).
Целенаправленность перебора (6.4.11) достигается благодаря
специальной организации памяти в процессе поиска. Рекуррентные
выражения для содержимого памяти имеют вид
(6.4.13)
где Q(S
N
) — значение
минимизируемого
показателя качества — числа неправильных реакций перцептрона на
обучающую последовательность для матрицы связей S
N
; Q*
N
—
наименьшее хранимое в памяти значение показателя качества за N
шагов поиска; S*
N
— оптимальная матрица за N шагов поиска, обес-
печивающая наименьшее значение критерия:
(6.4.14)
2. Алгоритм случайного поиска оптимальной матрицы S с
отбором А-элементов. Здесь показатель качества вычисляется
отдельно для каждого A-элемента и поиск строится на тех элементах,
которые дают значения показателя качества, большие заданного
порога q.
Представив матрицу S в виде S = || s
1
, ..., s
m
||, где s
j
— вектор-
столбец этой матрицы, соответствующий соединениям входов