Пляко Д.А. Базы данных - Методическое пособие
Подождите немного. Документ загружается.

Санкт-Петербургский государственный университет
-------------------------------------
БАЗЫ ДАННЫХ
Методическое пособие
Составитель Д.А.Пляко
Введение
Задачи, связанные с хранением и обработкой информации, совсем недавно были уде-
лом узких специалистов по информатике. В настоящее время с подобными задачами сталки-
вается каждый, кто в своей работе в той или иной мере использует компьютер. Существует
множество программных продуктов, предназначенных для решения проблем построения и
использования баз данных, которые ориентированы на малоподготовленных пользователей
персональных компьютеров. Однако, как показывает практика, более-менее полноценное ис-
пользование таких программных продуктов требует достаточно хорошего понимания основ-
ных понятий и концепций теории баз данных. Видимо, именно потому курс «Базы данных»
введен в учебный план ряда гуманитарных специальностей. Данное методическое пособие
построено на основе подобного курса, читаемого автором на восточном факультете Санкт-
Петербургского государственного университета.
§ 1. Основные понятия
Термин «база данных» в настоящее время применяется, когда речь идет о задаче хра-
нения и переработке информации с помощью компьютера. Однако, не всякую информацию,
хранимую в компьютере можно назвать базой данных (БД). Под этим термином обычно по-
нимают совокупность информации, организованную определенным образом и объединенную
в одно целое по некоторому признаку. Чтобы не углубляться пока в детали, связанные с пра-
вилами хранения информации в памяти компьютеров, поясним сформулированное опреде-
ление базы данных на «бытовом» примере.
Предположим, что некто хранит информацию о своих знакомых (например: фамилию,
имя, дату рождения и номер телефона) где придется: на обрывках бумаги, на полях книг, в
записной книжке на наугад открытой странице и т.п. Понятно, что пользоваться такой ин-
формацией весьма трудно (если вообще возможно). Альтернативой вышеописанной манере
«хранения» информации является способ, используемый при составлении телефонных спра-
вочников, где данные строго упорядочены, и потому можно быстро найти телефон нужного
абонента.
В компьютере тоже можно хранить информацию безо всякой системы (по тому же
принципу, как это делал вышеупомянутый «некто»), ее тогда тоже трудно будет использо-
вать и такая совокупность информации не может претендовать на то, чтобы называться ба-
зой данных. Именно это обстоятельство и оговаривается в определении БД, когда подчерки-
вается, что информация должна быть «организована определенным образом».
Конкретный способ организации базы данных определяется тем программным про-
дуктом, который специально создается для обработки информации, объединенной в БД.
Программные средства, предназначенные для указанной цели, называются «системами
управления базами данных» (СУБД). Все СУБД выполняют более или менее одинаковый
набор задач по обработке информации, хранящейся в базе данных. Среди них основными яв-
ляются: ввод данных, коррекция данных, удаление ненужной информации, поиск требуемой

2
информации и отображение ее на экране дисплея (либо вывод на печатающее устройство).
Различаются системы управления базами данных по разнообразным критериям (по быстро-
действию, по удобству работы с ними, по типу компьютеров, для которых эти СУБД разра-
ботаны и т.д.), но, прежде всего, СУБД классифицируются по способу организации инфор-
мации в базе данных. В теории баз данных известно несколько таких способов, однако к на-
стоящему времени особую популярность и распространение получил пожалуй самый про-
стой из них, при котором информация в базе данных организуется в виде таблиц. Такие таб-
лицы называются также «отношениями» (relation), а сами базы данных, организованные с
помощью отношений (и соответствующие СУБД) получили название «реляционных».
В дальнейшем мы будем рассматривать исключительно реляционные базы данных.
Прежде всего, изучим подробнее то, как информация размещается в таблицах (отношениях)
и какие типы данных можно хранить в таких таблицах .
§ 2. Табличная структура реляционных баз данных
Таблица реляционной базы данных предназначена для хранения информации об объ-
ектах определенного вида. Такая таблица состоит из произвольного количества строк, при -
чем в каждой строке х ранится информация ровно об одном объекте. Строки такой таблицы
называются также записями. Особо подчеркнем, что все строки таблицы имеют одинаковую
структуру хранимой информации. Поясним сказанное на примере.
Предположим, что все тот же «некто» решил хранить информацию о своих знакомых
в виде таблицы реляционной БД. В этом случае, в каждой строке таблицы должна храниться
информация ровно об одном знакомом нашего «некто». Так как информация эта состоит из
отдельных «порций » (напомним: фамилия, имя, дата рождения, номер телефона), то строка
таблицы состоит из отдельных разделов, называемых полями. «Порции» информации назы-
ваются данными. Таким образом, каждому отдельному данному соответствует отдельное
поле. Если «некто» решил, что в первой строке данные должны следовать в том, порядке, как
указано выше в скобках, то в таком же порядке данные должны располагаться во всех ос-
тальных строках таблицы. Далее, «некто» может расположить в первом поле строки и фа-
милию, и имя, а может эти данные разместить в разных полях (в первом поле – фамилию, а
во втором поле – имя), но какое бы решение из этих двух альтернатив он ни выбрал, оно
должно быть одинаковым для всех записей.
Допустим, что «некто» выбрал вариант, при котором фамилия и имя занимают только
одно поле. Следующее решение, которое ему следует принять – это выбрать размер такого
поля (т.е., сколько символов требуется, чтобы записать такое «сдвоенное» данное). Наверно
уже понятно, что очередное требование реляционной БД состоит в том, что размер всех та-
ких полей должен быть одинаков во всех строках таблицы. Отсюда следует, что размер пер-
вого поля нужно подбирать таким, чтобы в этом поле можно было разместить самое длинное
данное (то есть, самое длинное сочетание фамилия+имя).
Требование одинаковости всех атрибутов, относится и ко всем остальным полям за-
писи. Поэтому таблицу реляционной БД можно представить схематически совершенно есте-
ственным образом («в виде таблицы»):
Таблица 1.
Иванов Сидор 13.01.1973 1234567
Сидоров Петр 23.02.1978 2345678
Петров Иван 08.03.1977 3456789
Римский-Корсаков Николай 24.04.1844
...
3
Легко заметить, что таблица реляционной БД состоит из столбцов, содержащих одно-
родную информацию об объектах. В нашем примере первый столбец содержит информацию
о фамилии и имени (всех знакомых нашего «некто»), второй – о дате рождения, наконец,
третий – сведения о телефонах. Следует отметить, что если количество строк в таблице мо-
жет быть в принципе произвольным и обычно изменяется (увеличивается и/или уменьшает-
ся) в процессе работы с базой данных, то количество столбцов (иными словами, количество
полей в строке) не может быть сколь угодно большим. Оно фиксируется в момент создания
таблицы и его изменение – процесс более «болезненный», чем изменение количества запи-
сей. Более подробно об этом мы поговорим позже.
Если требуется выбрать из таблицы какое-либо отдельное данное (например, телефон
Сидорова), то необходимо указать строку и столбец, на пересечении которых находится тре-
буемое данное. В таблицах реляционных БД для этой цели строки нумеруются, а каждому
столбцу дается имя. Дополним Таблицу 1 именами столбцов:
Таблица 1а.
Family Birthday Phone
Иванов Сидор 13.01.1973 1234567
Сидоров Петр 23.02.1978 2345678
Петров Иван 08.03.1977 3456789
Римский-Корсаков Николай 24.04.1844
...
Теперь если требуется телефон Сидорова, то его следует выбрать из поля Phone второй стро-
ки, а день рождения Римского-Корсакова можно узнать в поле Birthday четвертой строки и
т.д.
Важной х арактеристикой данных, хранимых в БД, является их тип. Вернемся к наше-
му примеру. Данные из первого столбца Таблицы 1 относятся к символьному типу. К тако-
му типу относится информация, которая записывается в виде последовательности произ-
вольных символов (букв, цифр, знаков препинания и т.д.). Поскольку любая информация
может быть представлена в виде последовательности символов, то символьный тип данных
является самым общим из всех типов данных. В принципе, в структуре полей БД можно бы-
ло бы обходиться только им одним, но такое решение сильно сузило бы возможности обра-
ботки данных. (Символьный тип данных часто называют также строковым, а сами данные –
строками, но мы не будем использовать эту терминологию, чтобы не путать строки-данные
со строками-записями таблицы).
Характеристикой символьного поля является его размер. Следует подчеркнуть, что
при определении размера необходимо учитывать все символы, участвующие в символьном
данном. Например, в четвертой записи Таблицы 1 размер символьного данного из первого
столбца равен 24, учитывая знак дефиса в фамилии, а также символ пробела, разделяющего
фамилию и имя.
Своеобразной платой за универсальность символьного типа данных является очень
небольшой набор операций, которые допускаются при обработке таких данных. Таких опе-
раций только две: символьные данные можно сравнивать (в лексикографическом смысле) и
несколько символьных полей можно объединить в одну последовательность символов путем
их слияния (эта операция называется операцией конкатенации).
Рассмотрим теперь третий столбец Таблицы 1. Данные этого столбца можно хранить
(как и вообще любые данные) в символьном виде, но можно отнести их к числовому типу
данных, поскольку номера телефонов обычно записываются в виде целых чисел. Какой бы
ни был выбран тип для данных третьего столбца, внешний вид таблицы никак не изменится.
Однако выбор числового типа, дает определенные выгоды: данные этого типа занимают
меньше места при хранении в компьютере и при обработке таких данных можно использо-
4
вать все стандартные арифметические операции (над номерами телефонов, конечно, никакие
арифметические операции обычно не используются, но в иных случаях подобное преимуще-
ство играет первостепенную роль).
Отметим, что если необходимо номер телефона хранить вместе с кодом города, кото-
рый принято записывать в скобках (например, (812) 1234567), то тогда данные третьего
столбца нельзя отнести к числовому типу данных, и следует использовать символьный тип.
Таким образом, числовой тип данных можно использовать только тогда, когда данные явля-
ются числами, записываемыми в одной из принятых форм (подробнее о формах представле-
ния числовых данных будет говориться ниже, при обсуждении конкретных СУБД).
Во втором столбце Таблицы 1 помещена информация, которая относится к типу «ка-
лендарная дата» (или просто «дата»). Все современные СУБД «поддерживают» в том или
ином виде этот тип данных (т.е. позволяют вводит данные такого типа в базу данных и осу-
ществлять над этими данными необходимые операции). Вновь следует отметить, что даты
можно хранить как символьный тип данных, но если хранить этот вид информации как спе-
циальный тип «календарная дата», то СУБД автоматически будет контролировать вводимую
информацию на корректность (например, СУБД не позволит ввести дату «31 июня» или «29
февраля» не високосного года и т.п.). Кроме того, все СУБД разрешают осуществлять над
календарными датами некоторые полезные операции, например, можно добавить к какой-
нибудь дате целое число, в результате чего получается новая дата, которая «позже» первона-
чальной на это число дней; из одной даты можно «вычесть» другую, в результате получи м
число дней, разделяющих эти две даты. Конкретные примеры операций над датами будут
приведены позже.
Системы управления базами данных, как правило, допу скают обработку еще некото-
рых других типов данных, но пока мы ограничимся рассмотрением вышеперечисленных
трех основных типов, как наиболее употребительных.
В заключение данного параграфа сформулируем основные сведения, относящиеся к
построению таблицы реляционной базы данных.
1. Таблица состоит из строк и столбцов, причем количество столбцов ограничено и
определяется при конструи ровании таблицы, а число строк – не ограничено (по
крайней мере теоретически) и обычно изменяется при работе с таблицей.
2. Каждая строка содержит информацию ровно об одном объекте и состоит из от -
дельных разделов, называемых полями. «Порции» информации, хранящиеся в от-
дельном поле, называются данными. Полям строк дается имя, по которому мож-
но обращаться к содержащимся в полях данным.
3. Все строки таблицы имеют идентичную структуру, т.е. состоят из одинакового ко-
личества полей, размещаемых в одинаковом порядке.
4. Каждый столбец (образующийся из одноименных полей всех записей) содержит
данные одного определенного типа. Для каждого типа данных системой управле-
ния базой данных поддерживается определенный набор операций.
Приемы и правила работы с данными, организованными в виде реляционной таблицы,
рассмотрим на примере «электронной таблицы» Microsoft Excel.
§ 3. Работа с электронной таблицей Microsoft Excel
Программный продукт Excel, разработанный фирмой Microsoft, не является системой
управления базой данных в строгом смысле. Хотя информация в Excel хранится в табличном
виде, но способ хранения информации во многом отступает от тех правил, которые сформу-
лированы в конце предыдущего параграфа. По этой причине структуру хранения информа-
ции в Excel и сам программный продукт (что не вполне корректно) называют «электронной
5
таблицей». Тем не менее, знакомство с принципами работы с базами данных мы начнем на
примере Excel, поскольку простота и наглядность работы с электронной таблицей позволит
на первых порах обойти некоторые трудные для восприятия моменты. К тому же, если при
разработке структуры для хранения информации соблюдать вышеупомянутые правила, то
полученный фрагмент электронной таблицы в терминах Excel тоже называется базой данных
и для работы с такой БД в Excel имеется целый набор встроенных средств.
Поскольку нашей целью является рассмотрение именно этих средств, то прочие воз-
можности Excel будут изложены лишь в порядке краткого вступления.
3.1. Ввод данных
То, что увидит пользователь на экране дисплея после запуска Excel, представлено на
рис.1.
Рис.1
Основную часть экрана занимает таблица, строки которой пронумерованы, а столбцы
поименованы буквами латинского алфавита. Размер таблицы превышает размеры экрана и
потому на экране представлена только часть ее. С помощью горизонтальной и вертикальной
«прокрутки» пользователь может «перемещать» экран «над» таблицей и видеть любую ее
часть. Количество строк таблицы (теоретически) не ограничено, а количество столбцов равно
230. Первые 26 столбцов имеют однобуквенные имена, следующие 26 столбцов имеют имена
от AA до AZ, затем от BA до BZ и так далее вплоть до IV.
На пересечении строк и столбцов находятся ячейки, которые и служат для хранения
информации. Ячейки идентифицируются путем указания имени столбца и номера строки.
Такая идентификация называется адресом ячейки. Например, левая верх няя ячейка имеет
адрес A1. На рис.1 эта ячейка выделена черной рамкой. Пользователь может выделить лю-
6
бую другую ячейку либо с помощью мыши (щелкнув кнопку, когда указатель мыши уста-
новлен на нужную ячейку), либо путем перемещения черной рамки клавишами управления
курсором (клавишами со стрелками). Ввод информации всегда осуществляется именно в
выделенную ячейку.
Вводить данные можно разнообразными способами. Укажем два из них. Первый спо-
соб позволяет вводить информацию, очищая ячейку от данных, ранее в ней содержащихся.
Для этого, выделив нужную ячейку, наберите на клавиатуре требуемый текст и затем нажми-
те клавишу Enter. Набранные данные отобразятся в выделенной ячейке, а если в ней нахо-
дился ранее введенный текст, то он будет удален. Если введенные ранее данные необх одимо
только подкорректировать, то лучше использовать второй способ: выделив нужную ячейку,
следует нажать клавишу F2, подправить текст, а затем нажать клавишу Enter. В обоих слу ча-
ях завершая ввод информации, можно вместо клавиши Enter использовать какую-либо из
клавиш управления курсором (как бы «покидая» ячейку).
3.2. Типы данных, формулы, функции
Excel поддерживает все те основные типы данных, которые были изложены в преды-
дущем параграфе: символьный, числовой и тип «дата». Кроме того, Excel позволяет исполь-
зовать особый тип данных «формула», который применяется только в электронных табли-
цах. С помощью формулы пользователь может указать правило вычисления нужного значе-
ния. Excel произведет вычисления по этому правилу, а результат будет показан в той ячейке,
в которую был введен текст формулы.
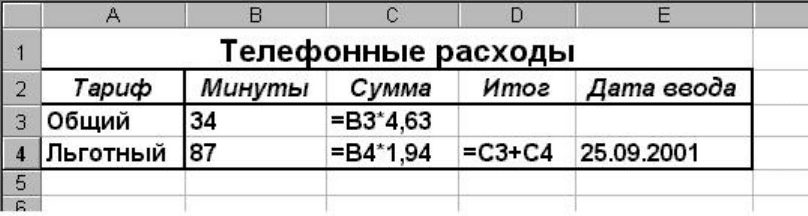
Рассмотрим пример. Допустим, что пользователь часто звонит в Москву и хочет с по-
мощью компьютера контролировать свои расходы на телефонные переговоры. Стоимость
одной минуты разговора с Москвой равна 4 руб. 63 коп., а по льготному тарифу – 1 руб. 94
коп. В ячейку В3 пользователь будет вводить длительность разговоров по обычному тарифу,
а в ячейку В4 – по льготному. В ячейках С3 и С4 нужно «сконструировать» формулы, по-
зволяющие рассчитать расходы на каждый из этих видов переговоров (перемножение ставки
тарифа на затраченное время). Наконец, в ячейке D4 пользователь желает видеть общую за-
траченну ю сумму.
На рис.2 показано, какой текст нужно ввести в указанные ячейки. Для примера приня-
то, что по обычному тарифу пользователь говорил 34 минуты, а по льготному тарифу – 87
минут. В таблицу добавлены поясняющие заголовки, а также (в ячейку Е4) – информация о
дате, когда пользователь вводил данные
Рис.2
Ячейка С3 содержит формулу, в состав которой входит адрес ячейки В3 (в таких слу-
чаях говорят, что формул а содержит «ссылку» на ячейку). При вычислении значения форму-
лы, Excel вместо адреса ячейки подставит то значение, которое в данный момент хранит
ячейка. Символ «*» в информатике означает операцию умножения. Формула в ячейке D4
представляет собой операцию суммирования значений, хранящихся в ячейках С3 и С4. Разу-
7
меется, что суммироваться будут не записанные в этих ячейках формулы, а те числа, кото-
рые получатся после вычислений по формулам.
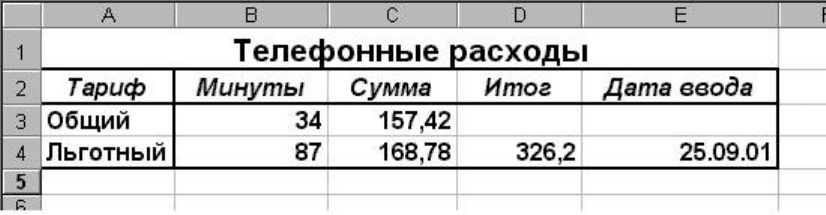
Поскольку пользователя интересует не столько вводимый текст формул, сколько ре-
зультат вычислений, то Excel покажет на экране не то, что изображено на рис.2, а то, что по-
казано на рис.3
Рис.3
Разработанную таблицу можно сохранить на внешнем носителе, и в дальнейшем, как
только пользователь проведет очередные разговоры с Москвой, ему достаточно обновить
числа в ячейках В3 и В4. Excel произведет вычисления, исходя из новых данных, и пользова-
тель увидит новый итог своих расходов.
В таблице на рис.3 имеются все основные типы данных, поддерживаемые Excel: в
ячейки В3 и В4 введены числовые данные; в ячейку Е4 – тип дата; в ячейках С3, С4 и D4 со-
держатся формулы, а во всех остальных ячейках – символьные данные. Excel различает тип
данных, вводимый в ту или иную ячейку по «внешнему виду» информации. Правила распо-
знавания типа данных следующие:
• тип «формула» должен быть отмечен знаком «=», предшествующим тексту формулы;
• данное относится к числовому типу, если введенный текст представляет собой запись
числа (в одной из принятых форм) и если этот текст не начинается знаком «апострофа»
(‘);
• данное относится к типу «дата», если введенный текст представляет собой запись кален-
дарной даты и текст этот не начинается знаком «апострофа» или символом «пробел»;
• во всех остальных случаях введенная информация относится к символьному типу дан-
ных.
Из всех этих правил существенным является первое, а все остальные настолько есте-
ственны, что пользователь вводит информацию, часто даже не задумываясь о требуемом ти-
пе данных. Такое «дружелюбие» со стороны Excel весьма полезно, но оно же иногда приво-
дит к необъяснимым на первый взгляд «ошибкам» в построенных таблицах.
Чаще всего такие «ошибки » возникают при работе с датами. Рассмотрим на эту тему
пример. Допустим, нам требуется определить текущий возраст (число полных лет) пациента,
зная его дату рождения. Мы уже знаем (см. в § 2 абзац, посвященный типу «дата») что мож-
но от одной даты вычесть другую, в результате чего получи м число дней, разделяющих эти
две даты. Поэтому определить возраст пациента можно следующей последовательностью
действий:
• от текущей даты вычесть дату рождения пациента;
• получившееся число дней, прожитых пациентом, разделить на среднее число дней в году
(365,25);
• у получившегося дробного числа отбросить дробную часть (сделать это можно с помо-
щью одной из функций Excel).
На рис.4 показаны формулы, решающие наш простой пример (в качестве дня рожде-
ния пациента взята дата 25 сентября 1978 года).

8
Рис.4
В ячейку А2 записана формула, представляющая из себя исполнение функции Excel
СЕГОДНЯ(), значением которой является текущая дата (по часам компьютера). В ячейку В2
вводится дата рождения пациента. Значением формулы в ячейке С2 является разность двух
предыдущих дат. Формула в ячейке D2 делит число дней , прожитых пациентом на среднее
число дней в году. Наконец формула в ячейке Е2 содержит исполнение еще одной функции
Excel, которая от результата, полученного в ячейке D2, отбрасывает дробную часть. На рис.5
показан результат вычисления по введенным формулам.
Рис.5
Разумеется, совсем другой результат мы ожидали. В ячейке С2, например, должно по-
лучиться целое число (число дней, разделяющее даты в ячейках А2 и В2). Почему же в ячей-
ке С2 высвечивается какая-то странная дата? Дело в том, что Excel х ранит «внутри себя» да-
ты как целое число, означающее число дней, прошедшее от начала 20-го века (т.е. с 1 января
1900 года). Такое внутримашинное представление дат дает возможность легко совершать
предусмотренные операции над датами. Но это приводит к тому, что обычные целые числа и
даты Excel различает только в зависимости от типа ячейки. Если ячейка хранит число 5 и
имеет числовой тип данных, мы увидим в этой ячейке число 5, а если поменять тип данных
для ячейки на «дату» (не меняя самого хранимого значения), то мы увидим все в той же
ячейке дату «5 января 1900 года».
Теперь мы можем понять, почему наши «правильные» формулы привели к странному
результату. Для ячеек А2 и В2 Excel установил тип «дата», по правилам распознавания типа
данных (и это нас вполне устраивает). Поскольку в ячейке С2 находится формула, операнда-
ми которой являются даты, то Excel и для этой ячейки установил тип «дата», что нас уже не
устраивает. Стало быть, для исправления «ошибки » надо поменять тип данных для ячеек С2,
D2 и Е2 на числовой. (Сделать это можно, например, следующим образом: выделив ячейку,
щелкнуть правой кнопкой мыши. В появившемся контекстном меню выбрать пункт «фор-
мат ячейки». Затем выбрать вкладку «Число» и в ней формат «Общий».) Установив нужный
тип данных в указанных ячейках, мы получим именно тот результат, который рассчитывали
увидеть. Он показан на рис.6.
Замечания
.
1. Может возникнуть недоумение: почему Excel «сам» не установил числовой тип
данных для ячейки С2? Видимо, разработчики Excel полагали, что разность дат
пользователь пожелает видеть как количество дней, месяцев и лет, разделяющих
две даты. Именно такой результат и получится (он показан в ячейке С2 на рис.5),

9
если трактовать полное количество дней, разделяющих две даты, как самостоя-
тельную дату.
2. Поскольку даты отсчитываются от 1 января 1900 года, то более ранние даты Excel
не поддерживает.
Рис.6
Если в последнем примере нас не интересуют промежуточные результаты (что обыч-
но и бывает), то в формулу ячейки Е2 (где подсчитывается окончательный результат) следу -
ет последовательно «вставить» формулы из «промежуточных» ячеек. Конечно, итоговая
формула будет иметь достаточно громоздкий вид, но зато в таблице не останется ничего
лишнего. В нашем примере поэтапное получение итоговой формулы будет выглядеть сле-
дующим образом:
1. Вместо ЦЕЛОЕ(D2) получаем ЦЕЛОЕ(С2/365,25);
2. Вместо ЦЕЛОЕ(С2/365,25) получаем ЦЕЛОЕ((А2-В2)/365,25);
3. Вместо ЦЕЛОЕ((А2-В2)/365,25) получаем ЦЕЛОЕ((СЕГОДНЯ()-В2)/365,25).
После подстановки окончательного текста формулы в ячейку Е2, можно очистить содержи-
мое ячеек А2, С2 и D2. В результате, в таблице будут заполнены только две ячейки: В2 (ис-
ходное данное) и Е2 (результат).
При решении рассмотренного примера нам пришлось воспользоваться некоторыми
функциями Excel. Функции Excel – это мощное средство, значительно облегчающее работу
пользователя при разработке формул. Если необходимо использовать какую-либо функцию в
формуле, то следует ввести имя функции (СЕГОДНЯ или ЦЕЛОЕ в нашем примере), а затем
в скобках – список параметров. Если функция параметров не имеет (как например,
СЕГОДНЯ), то скобки все равно нельзя опускать (наличие скобок позволяет Excel отличить
функцию от всех прочих компонент, используемых в формулах).
Количество функций, встроенных в Excel довольно значительно (свыше двух сотен).
Помнить их всех не обязательно, поскольку в Excel имеется система «подсказок», облег-
чающая ввод нужной функции в формулу. Вызов этой системы осуществляется нажатием
кнопки «f
x
» или кнопки с символом «=», находящейся над строкой с именами столбцов.
3.3. Диапазоны
В Excel имеется целый ряд функций, которые в качестве параметра имеют ссылку не
на отдельную ячейку (как, например, функция ЦЕЛОЕ на рис.4), а на группу ячеек. Для при-
мера рассмотрим одну из наиболее часто встречающихся функций, с помощью которой
можно суммировать числовые значения, хранящиеся в группе смежных ячеек. Введите ка-
кие-нибудь числа в ячейки А1, А2,…А5, В1,В2,…В5, С1,С2,…С5. Затем выделите ячейку
А6, нажмите кнопку с символом Σ
ΣΣ
Σ и потом клавишу Enter. Если все сделано правильно, то в
ячейку А6 Excel поместит текст «=СУММ(А1:А5)», представляющий собой обращение к
функции СУММ, которая в нашем случае осуществляет суммирование значений всех ячеек
от А1 до А5 включительно.
Параметром функции СУММ является диапазон ячеек, который задается именами
первой и конечной ячеек, разделенных знаком «двоеточие». Диапазон может охватывать не
только группу клеток «по вертикали», но и «по горизонтали»: если в ячейку D1 ввести текст
10
«=СУММ(А1:С1)», то в этой ячейке появится сумма значений, хранящихся в ячейках А1, В1
и С1.
Рассмотрим теперь самый общий случай диапазона. Введем в ячейку D6 формулу
«=СУММ(А1:С5)». В этой ячейке появится сумма всех чисел прямоугольного фрагмента
таблицы, где ячейки А1 и С5 являются конечными ячейками одной из диагонали этого пря-
моугольника. Этот же прямоугольный фрагмент можно задать иначе (используя другую диа-
гональ): С1: А5. (Можно к тому же переставить имена начальной и конечной ячеек местами:
А5:С1, правда Excel в этом случае поменяет адресацию диапазона на более удобный для не-
го вариант: А1:С5.)
Отметим, что как «вертикальный», так и «горизонтальный» диапазоны являются ча-
стными случаями более общего прямоугольного диапазона. Наконец, отдельную ячейку
можно также рассматривать как частный случай диапазона (т.е. вполне допустима формула
«=СУММ(А1)»).
3.4. Базы данных в Excel
Познакомившись с основными правилами построения в Excel электронных таблиц,
предназначенных для обычных вычислений, рассмотрим теперь, как можно организовать
данные в таком виде, который очень похож на таблицу реляционной базы данных. Предпо-
ложим, что требуется хранить следующую информацию о студентах (в скобках указаны
предлагаемые имена соответствующих полей):
• Фамилия, имя (Family)
• Дата рождения (BirthDay)
• Возраст (Age)
• На каком курсе учится (Year)
• Учится ли без троек (GoodLearned)
• Размер стипендии (Grant)
Мы уже рассматривали задачу определения текущего возраста по дате рождения, по-
этому для определения возраста будем использовать разработанную нами формулу (разуме-
ется, эта формула не является единственным и лучшим способом вычисления возраста; при-
ведена она была главным образом в учебных целях). Таким образом, поле «Age» будет «вы-
числяемым» полем.
Условимся, что в поле «GoodLearned» будем вводить знак «+», если студент учится
без троек и знак «-» в противном случае. В этом поле, таким образом, будут встречаться все-
го два различных значения. Такого типа поля принято относить к логическому типу данных.
В логических полях хранятся значения «истина» либо «ложь» (вместо «+» либо «-», как мы
условились). Однако Excel не поддерживает логический тип данных для ячеек, и по этой
причине нам пришлось поступить так, как оговорено выше.
Поле «Grant» как и поле «Age» сделаем вычисляемым. Предположим, что студентам
назначается стипендия в размере 850 руб. 60 коп., если студент учится без троек, и дается
стипендия в размере 350 руб. 20 коп. в противном случае. Построим формулу, с помощью
которой стипендия будет вычисляться по таким правилам. Пусть значение поля
«GoodLearned» хранится в ячейке Е3. Тогда текст требуемой формулы может быть таким:
«=ЕСЛИ (E3=”+”; 850,60; 350,20)». Приведенная формула содержит использование функции
ЕСЛИ, которая требует три параметра, отделяемых друг от друга знаком «точка с запятой».
Первым параметром является логическое условие (в нашем случае это условие состоит в
проверке того, что в ячейке Е3 х ранится знак «+»). Если условие выполнено (это означает,
что студент учится без троек), то значением функции является значение второго параметра
(т.е. величина 850,60); в противном случае значением функции является значение третьего
параметра (в нашем примере это величина 350,20).
Примерный вид таблицы приведен на рис.7.