Ломакин Д.В., Туркин А.И. Прикладная теория информации и кодирования
Подождите немного. Документ загружается.


3. ДИСКРЕТНЫЕ ИСТОЧНИКИ СООБЩЕНИИ И ИХ
ОПИСАНИЕ
ЭРГОДИЧЕСКИЕ ИСТОЧНИКИ
Источник будем называть эргодическим, если его вероятностные
параметры можно оценить по одной достаточно длинной реализации, которую
он вырабатывает. При неограниченном возрастании длины реализации (я)
оценка параметра (результат измерения) совпадает с его истинным значением
с вероятностью, равной единице. Например, при бросании игральной кости
можно оценить вероятность выпадения какой-либо цифры через
относительную частоту ее появления в достаточно длинной серии испытаний.
Указанная серия испытаний представляет собой ту самую реализацию, по
которой осуществляется оценка вероятности (параметра). Реализации, по
которым можно оценить закон распределения, являются типичными. Поэтому
эргодическим источником можно назвать источник, который вырабатывает
типичные последовательности. Типичная последовательность несет сведения о
структуре источника, то есть является типичной для данного источника. Если
два источника различаются своей структурой (значением оцениваемого
параметра), то, наблюдая реализацию, можно определить, какому из них она
принадлежит. Источник, эргодический по одному параметру, может оказаться
не эргодическим по другому параметру.
ПРОИЗВОДИТЕЛЬНОСТЬ ДИСКРЕТНОГО
ИСТОЧНИКА СООБЩЕНИЙ
Кодовое слово, которое вырабатывает источник, будем записывать в виде
,
Xi1, xi2, …,xik , где xik –ik-я буква
(символ) алфавита с k порядковым номером в слове. Например, пусть k=5, a
is=3. Это значит, что пятой буквой в слоге является третья буква алфавита.
Обозначим через Xk , множество букв (алфавит),
из которых выбирается k-я
буква слова. В нашем случае все множества Xk(k=1,n) состоят из одних и тех
же тx букв. Когда не требуется указывать место буквы в слове, i-ю букву
алфавита будем обозначать через
XI
Количество информации, которое в среднем несет отдельное слово, раино
энтропии
5,0811,0
)|()(
1811,00
)|()()|(
0311,05,0811,0)|()(),(
,811,0)75,0log75,025,0log25,0()(
5,01*5,00*5,0)|()()|()()|(
1)5,0log5,05,0log5,0()|(log)|()|(log)|()|(
,00log01log1)|(log)|()|(log)|()|(
21
2211
2
2
2
2
2
1
2
1
2
1
2
1
2
1
1
1
1
1
>
>
<<
<<
>
YXHXH
XHXHXH
отсюда
YXHXHYXI
XH
XHpXHpYX
ppppXH
ppppXH
yy
yyyy
y
x
y
x
y
x
y
x
y
xxxx
=−≈−=
≈+−=
=+=+=
=+−=−−=
=−−=−−=
где суммирование ведется по всему множеству слов. Определим
производительность источника Hи как предел отношения
количества информации, которое в среднем несет отдельное слово, к числу
букв в слове п при неограниченном возрастании п:
Если буквы в слове статистически независимы (вероятность выбора
очередной буквы не зависит от состава предшествующих еп букв), то
∑
=
−=
++=
m
pPH
где
HHHH
x
i
iIK
K
NKn
xx
X
XXXXX
1
11
)(log)()(
),(...)(...)(),...,(
yyyyy
),...,(log),...,(),...,1(
x
i
x
i
x
i
x
i
X
nini
n
ppXH
∑
−=
H
)6(
),....(
1
lim
n
H
X
X
H
n
n
И
→
=

Источник со статистически независимыми буквами сообщений будет
стационарным, если вероятность выбора ;-й буквы алфавита не зависит от
того, какое место в слове она занимает (p(Xik)=p(Xi)).
В этом случае
H(X1, ..., Хп)=пН(х}
и производительность источника (бит/символ)
Часто производительность источника измеряется количеством информации
vН(х}, которое он вырабатывает за одну секунду (v—количество букв за одну
секунду). Максимальная производительность источника достигается, когда все
буквы алфавита появляются с равными вероятностями. В этом случае
Hи=logp(mx)
МАРКОВСКИЕ ИСТОЧНИКИ СООБЩЕНИИ
Рассмотренная модель дискретного источника сообщений имеет
сравнительно узкую область применения, поскольку реальные источники
вырабатывают слова при наличии статистической зависимости между
буквами. В реальных источниках вероятность выбора какой-либо очередной
буквы зависит от всех предшествующих букв. Многие реальные источники
достаточно хорошо описываются марковскими моделями источника
сообщений. Согласно указанной модели условная вероятность выбора
источником очередной Хгk буквы зависит только от v предшествующих.
Математической моделью сообщений, вырабатываемых таким источником,
являются цепн Маркова v-го
порядка. В рамках указанной модели условная вероятность выбора ik-й
буквы
Если последнее равенство не зависит от времени, то есть справедливо при
любом значении k, источник называется однородным. Однородный
марковский источник называется стационарным, если безусловная вероятность
выбора очередной буквы не зависит от k {p{xi }==p{Xi)). В дальнейшем будем
иметь дело только со стационарными источниками. Вычислим
производительность источника для простой цепи Маркова (v=1). В этом
случае вероятность
∑
=
−==
m
pPHHи
x
i
iIK
xx
X
1
)(log)()(
P(xi1, …, xin)=p(xi1)p(xi2|xi1)… p(xin|xin-1)
Прологарифмировав последнее равенство, получим
Это равенство показывает, что индивидуальное количество информации,
которое несет слово, равно количеству информации, которое несет первая
буква, плюс количество информации, которое несет вторая буква при условии,
что первая буква уже принята, и т. д.
)|(log....)|(log)(log)...,(log
11111
x
x
x
x
x
x
x
iniiiiini
pppp
−
−−−=−
Усредняя равенство по всем словам, получим количество информации,
которое в среднем несет каждое слово:
H(X1,…Xn)=H(X1)+H(X2|X1)+…+H(Xn|Xk-1)
Поскольку источник стационарный, то энтропия не зависит от k и равна
H(X1,…Xn)=H(X)+(n-1)H(Xk|Xk-1)<=nH(X)
В случае марковской цепи v-го порядка Hи вычисляется аналогично и равна
Ни=Н(Xv+1|Xv, …, X1 )
Таким образом, производительность Марковского источника равна
неопределенности выбора очередной буквы при условии, что известны v
предшествующих.
Для производительности Марковского источника всегда справедливо
неравенство
H<=H(X)<=logmx.
Максимального значения, равного log mx, производительность источника
достигает, когда отсутствует статистическая зависимость между буквами в
слове и когда все буквы алфавита вырабатываются с равными вероятностями.
Очевидно, максимальная производительность источника полностью
определяется размером алфавита т.у.
),|(),...,,...,|(
111
x
x
x
x
x
x
x
x
vikkikivikvikikik
pp
−−−−−
=
Для того чтобы характеризовать, насколько полно использует источник
возможности алфавита, вводится параметр
)(
)(
max
max
X
X
r
H
H
H
и
−
=
называемый избыточностью.
Для передачи заданного количества информации, равного I, требуется
n=I/Hи букв, если производительность источника равна Ни; В случае, когда
производительность источника достигает своего максимального значения,
равного Нтax(X)= =logmx, для передачи того же количества информации /тре-
буется минимальное количество букв, равное no=I/Hmax

Отсюда_I=nHи=noHmax_или_
nX
n
H
H
Oи
=
)(
max
I
Учитывая последнее равенство, выражение для избыточности можно записать
в виде
Таким образом, нзбьпочность показывает, какая часть букв в слове не
загружена информацией.
Пример 1. Определить избыточность источника, если он вырабатывает
статистически независимую последовательность из единиц и нулей
соответственно с вероятностями, равными. p=0,,3 и q==0,7.
Решение. Поскольку символы в последовательности статистически
независимы, то производительность источника
Н=Н(Х) =-plogp-qlogq
≅
0,88 бит.
Максимально возможная производительность источника Hmax(X)==logmx=l,
поскольку т,у=2. При этом символы 1 и О должны вырабатываться с равными
вероятностями (p=q= =0.5). Отсюда
R=1-0,88/1=0,12
Пример 2. Определить избыточность стационарного марковского
источника, алфавит которого состоит из двух символов
лов: 0 и 1. Вырабатываемая источником последовательность представляет
собой простую цепь Маркова. Заданы следующие значения условных
вероятностей
p(xik+1|xik) (ik+1=1,2, ik=1,2)
nX
r
nn
H
H
O
и
−
=−=
)(
1
max
p(0|0)-0,3; р(1]0)=0,7; р(0[1)=0,1; р(1|1)=0,9.
Решение. Безусловную вероятность того, что (k+1)-M символом
последовательности будет нуль, по формуле полной вероятности можно
представить в виде
Pk+i(0)=pk(0)p(0|0)+[l-pt(0)]p(0|l).
В правую часть неравенства входит вероятность рь(0) того, что k-м символом
последовательности будет нуль. В силу стационарности источника
pk+1(O)=pk(0)=p(0). Подставив в равенство значения р(0|0) и р(0| 1), получим
р(0) =0,125, р(1)=1—р(0) =0,875. Производительность
источника
Hи=р(0)H/(Хk+1+|0)+p(1)H(Xk+1|1)=-0,125 (0,3 log 0,3+0,7 log
0,7) —0,875(0,1 log 0,1+ +0,9 log 0,9)= 0,51,
а избыточность источника //„
49,0
1
51,0
1
)(
1
max
=−=−=
X
r
H
H
и
де Hmax(Х)=1.
Когда отношение v/n стремится к нулю, при неограниченном возрастании п
марковский источник вырабатывает типичные последовательности,
количество которых Q≅2
(n-v)
Hи пли более приближенно Q≅2
nHи
4. КОДИРОВАНИЕ СООБЩЕНИЙ ПРИ ПЕРЕДАЧЕ ПО КАНАЛУ БЕЗ
ПОМЕХ
ВОЗМОЖНОСТЬ ОПТИМАЛЬНОГО (ЭФФЕКТИВНОГО)
КОДИРОВАНИЯ
Под кодированием будем понимать отображение состояний некоторой
системы (источника сообщений) с помощью состояний сложного сигнала,
который представляет собой последовательность из п элементарных сигналов.
Мно-
жество У состояний элементарного сигнала образует алфавит кола размера ту.
При m,v-=2 элементарный сигнал имеет два состояния, которые обозначим
через 1 и 0. Состояние сложного сигнала описывается последовательностью из
нулей г. единиц, которая называется кодовым словом. Если кодовые слова
имеют разную длину, то код называется неравномерным, а если одинаковую,
то код называется равномерным..
Пусть источник сообщений вырабатывает последовательность из k букв,
причем xi; буква в
этой последовательности
появляется п.; раз. Каждой букве Xi{i-=\, m.v) отпетствие кодовое слово с
длиной, равной /;
кодирование). Тогда длина соответствующей ности 'п кодовых слов будет
равна
Это равеиство-можио представить в виде
При неограниченном увеличении числа букв К в последовательности
относительная частота появления хi буквы с вероятностью. равной единице,
совпадает со значением вероятности рi; появления этой буквы. Поэтому с
вероятностью, равной единице, выполняется равенство
Где — по определению средняя длина кодового
∑
=
слова. Длина последовательности кодовых слов L является случайной
величиной, но значительные отклонения ее от среднего значения L=Kl
маловероятны при неограниченном возрастании К.
Таким образом, источник сообщений с вероятностью, равной единице,
вырабатывает типичные последовательности, длина которых мало отличается
от их среднего значения Кl.
Поскольку время передачи сообщений определяется длиной L, то имеется
возможность его сокращения за счет уменьшения средней длины кодового
слова Т (L
≅
KT}. Задача оптимального кодирования заключается в определении
однозначно декодируемых кодовых слов с такими длинами, при которых их
средняя длина минимальна.
ПРЕФИКСНЫЕ КОДЫ
При неравномерном коде в длинной последовательности кодовых слов не
всегда удается определить начало и конец переданной буквы.
Однако однозначное декодирование всегда имеет место в случае
применения кодов, обладающих свойством префикса (приставки). Код
обладает свойством префикса, если ни одно кодовое слово не является
началом (приставкой) какого-либо другого кодового слова.
Все множество кодовых слов, максимальная длина которых не
превосходит число, равное /, геометрически удобно изобразить в виде узлов
дерева (рис. 2). Дерево представляет собой множество точек (узлов),
соединенных отрезками, которые называются ребрами дерева. Из каждого
узла выходят ту ребер, каждое из которых изображает соответствующий
символ алфавита кода. Слова, состоящие всего из одной буквы, изображаются
узлами первого порядка. Их число равно т-у. Слова, состоящие из двух букв,
изображаются узлами второго порядка и т. д. Причем узлов (слов) К-го
порядка в /Лу раз больше, чем узлов (К—1)-го порядка, поскольку каждый
узел предыдущего порядка порождает т^-узлов следующего порядка.
Конкретный вид кодового слова определяется но изображающему его узлу как
последовательность ребер (букв), которые соединяют основание дерева с
указанным узлом. В случае префиксных кодов на пути, соединяющем
основание дерева с изображающим узлом, не может быть промежуточных
изображающих узлов.
=
i
i
l
x
l
p
m
i
i
1
∑
=
=
m
i
i
L
x
i
i
l
n
1
∑
⎟
⎠
⎞
⎜
⎝
⎛
=
=
m
i
L
x
i
I
i
l
K
n
1
L
∑
=
=
=
m
i
i
KL
x
i
i
lK
p
l
1
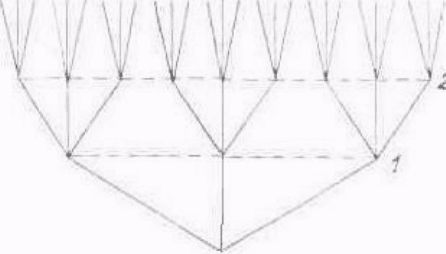
Рис. 2. Полное троичное ('n,v=3) кодовое дерево третьего порядка
(1=3): 1. 2, 3 — узлы первого, второго, третьего порядков
Поскольку с помощью дерева (pile. 2) можно изобразить все кодовые слова
с длиной, меньшей или равной I, то оно называется полным деревом порядка /
с алфавитом объема ту.
НЕРАВЕНСТВО КРАФТА
Теорема 1. Если целые числа l1, …, li,…,ln удовлетворяют неравенству
то существует код. обладающий свойством префикса с алфавитом объема
m-v, длины кодовых слов в котором равны этим числам. Обратно, длины
кодовых слов любого кода, обладающее:: свойством префикса,
удовлетворяют указанному неравенству.
Теорема нс утверждает, что любой код с длинами кодовых слов,
удовлетворяющими (7), является префиксным. Так, например, множество
двоичных кодовых слов 0,00,11 удовлетворяет (7), но lie обладает свойством
префикса. Теорема утверждает только существование префиксного кода, но не
указывает его конкретный вид. Кодовые слова 0,10,П удовлетворяют
неравенству (7) и обладают свойством префикса.
Доказательство. Пусть числа l1, …, li,…,ln удовлетворяют неравенству (7).
Покажем, как можно построить префиксный код с этими длинами кодовых
слов, и тем самым докажем существование префиксного кода. Не нарушая
общности доказательства, все числа можно перенумеровать в порядке
возрастания их значений.
Тогда будем иметь l1<= li…<=ln. Построение будем вести на полном
дереве порядка /,у.
Построение сводится к последовательному выбору узлов порядков l1, …,
li,…,ln, но так, чтобы очередной выбираемый узел не был порожден каким-
либо ранее выбранным узлом. Первый узел (кодовое слово) выбирается
произвольно из
^исла узлов порядка /i. Этот узел порождает ту
–l1
- ю часть узлов более
высокого порядка, которые уже не могут быть использованы. После выбора
следующего узла порядка ^
уже ту
–
l1+ ту
–l2
часть узлов не может быть использована
и т.д. После выбора (N-1)-го узла может быть использовала
,1
1
1
∑
−
=
−
−
N
i
y
m
l
i
часть узлов порядка lN
Поскольку для чисел 11, ..., 1N- справедливо неравенство
Крафта, которое можно записать в виде
,1
1
≤
∑
=
−
N
i
y
m
l
i
,1
1
≤+
−
=
−
∑
mm
ll
Nii
y
N
i
y
то величина 2 /Пу
;
строго меньше единицы. Следовательно,
i=i
существует часть узлов порядка 1^, из которых можно выбрать последний N-u
узел.
Отметим еще одно свойство кодовых слов. Если код однозначно
декодируется, то его кодовые слова удовлетворяют неравенству Крафта.
Доказательство можно найти, например, в работе [4].
Таким образом, префиксные коды составляют часть однозначно
декодируемых кодов, а последние составляют часть кодов, удовлетворяющих
неравенству Крафта.
ПРЕДЕЛЬНЫЕ ВОЗМОЖНОСТИ ОПТИМАЛЬНОГО
КОДИРОВАНИЯ
Определим границы для /, и I, пользуясь эвристическими соображениями,
основанными на количестве информации. Очевидно, код будет самым
экономным, если каждый символ кодового слова будет переносить
максимально возможное количество информации.
Поскольку собственное количество информации, содержащееся в
сообщении Xi
∈
X равно—logp-;, информационной емкости соответствующего
кодового слова будет достаточно, чтобы перенести указанное количество
информации, только
Р том случае, если его минимальная длина ^ будет нахо-
диться в пределах
где log my— максимальное количество информации, которое может перенести
отдельный символ кодового слова.
Усредняя неравенство по всему множеству Х сообщений, получим
неравенство, определяющее границыдля минимальной средней длины
кодового слова:
В данном случае довольно большой интервал изменения возможных
значений l. Однако при кодировании блоков (слов из п букв Хг) средняя
длина l приближается к значеию
ри неограниченном увеличении длины блока п,
что следует из неравенства
где lb— среднее количество символов кодового слова, приходящееся на один
блок, а lb / n на одну букву в блоке. п
Полученные неравенства справедливы для всех однозначно декодируемых
кодов.
СВЯЗИ ПРОПУСКНАЯ СПОСОБНОСТЬ
ДИСКРЕТНОГО КАНАЛА
1
log
log
log
log
+
−
≤≤
−
m
p
l
m
p
y
i
i
y
i
Для общего описания канала связи и построения теории информации
используется одна и та же модель. Канал называется дискретным
(непрерывным), если множества Х и Y дискретны (непрерывны), и
полунепрерывным, если одно из множеств дискретно, а другое непрерывно.
Ниже рассматриваются только дискретные каналы.
Канал полностью описывается условными вероятностями Р{Уik Xi,,-:,Xi.)
того, что k-м. принятым символом будет
jk.-й символ множества Y (jk=1,mу).
1
log
)(
log
)(
+≤≤
mm
yy
XH
l
XH
Указанную вероятность можно рассматривать jk как функцию и Х у , ..., Хг
, вид которой отражает состояние
канала, в частности, характер взаимодействия помехи и сигнала.
еcли
),1,,1(
)|(),...,|(
1
mim
j
x
y
xx
то соотвстсгвугощий канал называется каналом без памяти. Если вероятность
P(jk|. \Хгk ) не зависит от k (от времени), то соответствующий канал
называется стационарным. Ограничимся рассмотрением только стационарных
каналов без памяти.
y
xky
k
jk
jk
iki
jk
pp
==
=
m
y
XH
log
)(
n
XH
n
XH
m
l
m
y
m
y
1
log
)(
log
)(
+≤
,
),(
lim
YXI
R =
n
n ∞→

Определим скорость передачи информации как предел:
),( YXI
где - средняя взаимная информация между переданным
x∈ Х и принятым у
∈
У. В случае отсутствия помех H(X\Y)=0, следовательно,
R=Н(Х). Этот предел в случае канала без памяти равен взаимной информации:
),1_()|(__)(
mx
y
x
xi
i
i
ipиp =
∑
=
m
x
i
i
q
1
Скорость пеледачи информации 1^ полностью определяется
вероятностями
Поэтому изменять величину R мы мо/кем только за счет изменения вида
распределения'p(.v,), поскольку p(yj\Xi} — характеристика неуправляемого
канала. Определим пропускную способность кана-•;а С как максимальную по
p{xi) скорость передачи информации:
С= max R= max 1(Х, У).
В случае отсутствия помех
С= max H(X)=logmx.
ВЫЧИСЛЕНИЕ ПРОПУСКНОЙ СПОСОБНОСТИ
СИММЕТРИЧНЫХ КАНАЛОВ
Существует класс каналов, для которых пропускная способность С легко
вычисляется. Канал полиостью описывается так называемой стохастической
матрицей
P(y1|x1)……….p(ymy|x1)
…………………………..
P(y1|xmx)……….p(ymy|xmx)
которой сумма всех элементов, образующих строку, равна единице.
Канал называется симметричным по входу, если '-•троки матрицы
различаются только порядком расстановки некоторого множества чисел р\, ..,
рт .
Для симметричных по входу каналов частная условная энтропия
,.
∑∑
==
−=−=
m
p
m
pYH
yy
j
jj
i
j
j
i
j
i
pp
x
y
x
y
x
11
log)|(log)|()|(
3=1 J=1
Она нс зависит от номера передаваемой буквы и может быть вычислена по
любой строке матрицы. Поэтому условная энтропия
pp
xx
j
j
j
I
I
i
m
YH
m
pXYH
y
X
log)|()()|(
11
∑∑
==
−==
Канал называется симметричным по выходу, если столбцы матрицы
различаются только порядком расстановки некоторого множества чисел q1, ...,
qmx .
Если распределение источника равномерное (р.(х,)=1/mx), то распределение
р(у,) на выходе симметричного по выходу канала также будет
равномерным. При этом энтропии Н(Х) л Н (У) достигают своего
максимального значения. В этом легко убедиться, если доказать, что
вероятность p(xi) не зависит от .
Представим вероятность р(xi) в виде
∑
∑
=
=
=
=
=
m
p
тоpиp
m
ppp
x
x
i
i
x
i
i
j
x
i
i
i
j
i
j
q
m
y
x
y
m
x
x
y
x
y
1
1
1
)(
),|(__
1
)(
)|()()(
Сумма не зависит от номера столбца j и в общем случае не равна

единице. Поэтому вероятность р{у,} также не зависит от j и равна
При этом
H(X)=logmx, H(Y)=logmy.
Канал называется симметричным, если он симметричен по входу и выходу.
Для симметричного канала H(Y\X) не зависит от распределения источника
сообщений, поэтому пропускная способность
В качестве примера вычислим пропускную способность симметричного
канала, который описывается матрицей
где m=mx=my В этом случае
Рис. 3. Зависимость пропускной способности ДСК от вероятности ошибки ре
m
y
y
i
p
1
)( =
Вероятность 1-pe равна вероятности правильного приема
символа. Вероятность ошибки р,. равна вероятности приема у, с /^:' при
условии, что было передано x-i. Тогда
Р.
C=logm+(l—pe,)log(l—pe)+Pelog pe/(m-1)
Широкое распространение получил двоичный симметричный капал (ДСК)
(m=2), для которого пропускная способность (рис. 3)
C=l+(l-Pe)log(l-Pe)+PelogPe.
[]
pp
m
i
j
i
y
m
XYHYHXYHYHС
y
loglog)|()(max)|()(max
1
∑
=
+=−=−=
Максимальная скорость передачи информации, равная единице, получается
при ре=0 и при рe=1. В этом случае множества Х и Y находятся во взаимно
однозначном соответствии, и по принятому у, (j=1, 2) всегда можно
определить с вероятностью, равной единице, переданную букву. К сожалению,
это возможно только тогда, когда априори (до приема) известно значение
вероятности ре (нуль или единица).
⎟
⎟
⎟
⎟
⎟
⎟
⎟
⎠
⎞
⎜
⎜
⎜
⎜
⎜
⎜
⎜
⎝
⎛
−
−
−−
−
p
p
pp
p
e
e
ee
e
m
mm
1,....,
1
....................................
1
,....,
1
,1
5. КОДИРОВАНИЕ ИНФОРМАЦИИ ПРИ ПЕРЕДАЧЕ ПО КАНАЛУ С
ПОМЕХАМИ
ОСНОВНЫЕ ОПРЕДЕЛЕНИЯ
При передаче дискретных сообщений по каналу с помехами всегда
существует вероятность того, что принятые данные будут содержать ошибки.
Если частота ошибок в принимаемых данных превышает заданный
допустимый уровень, то можно использовать кодирование с исправлением
ошибок, которое позволяет уменьшить частоту ошибок до приемлемой.
Польза кодирования доказана в работах К. Шеннона, где установлено, что
если скорость создания сообщений источником не превосходит некоторой
величины, называемой пропускной способностью канала, то при подходящих
процедурах кодирования и декодирования можно вести передачу по каналу с
помехами со сколь угодно малой вероятностью ошибки. Фактические
ограничения на скорость передачи устанавливаются не пропускной
способностью канала, а вычислительной сложностью процедур кодирования п
декодирования. Ограничения на вычислительную сложность приводят к необ-
ходимости вести передачу со скоростями, намного меньшими пропускной
способности канала. Повышение эффективности передачи дискретных

сообщений по каналам с помехами достигается за счет применения
избыточного кодирования (кодирования с исправлением и обнаружением
ошибок).
Кодированные сообщения всегда содержат дополнительные или
избыточные символы. Эти символы используются для того, чтобы
подчеркнуть индивидуальность каждого передаваемого сообщения. Их всегда
выбирают так, чтобы сделать маловероятными потери сообщением его
индивидуальности из-за искажений достаточно большого числа символов.
Рассмотрим дискретный q-ичный канал, входной и выходной алфавиты
которого образуют конечное поле GF{q}. В случае q=2 имеем двоичный канал
с символами 0' и 1. Совокупность всех последовательностей элементов поля
GF(q} длины п образует векторное пространство V
n
.
q
Рассмотрим блоковую пепедачу павиовеооятиых Q-ИЧНЫХ сообщений
х={х,}
nr
, x
∈
GF(q), ∀i, где nR—длина передаваемого сообщения. Множество
векторов
xi
∈
V
n
.
q
образует ансамбль сообщений X^{x:x,
∈
EGF(ci), i=1 nR, x∈V
11
"}.
Введем в рассмотрение подмножество
Y
∈
V
n
.
q
, содержащее не менее q
nR
последовательностей у= {у:}", yi=GF{q), Vj.
Затем множество сообщений Х отображается на множество Y таким образом,
что каждому сообщению х
∈
Х ставится во взаимно однозначное соответствие
некоторая последовательность y
∈
Y. Множество У называют при этом
блоковым кодом, а правило отображения способом кодирования.
Операцию кодирования можно существенно упростить, если
рассматривать только линейные коды. Множество векторов У(n,R)∈
У" называют линейным кодом длины п и. скорости
R тогда и только тогда, когда оно является пР-мерным подпространством
пространства всех последовательностей длины п, заданных V
n
.
q
[5].
Чтобы кодирование в канале было эффективным, необходимо согласовать
свойства кода Y(n,R) с характером помех. Согласование будет тем более
полным, чем большая часть из числа всех обнаруживаемых или
корректируемых ошибок приходится на долю наиболее вероятных. Для
построения кода с обнаружением и исправлением независимых ошибок
удобным оказывается подход, при котором корректирующие свойства кода
описываются расстояниями между элементами множества Y{n, R) (кодовыми
словами).
Вес Хемминга у, обозначаемый W(y), определяется как число ненулевых
компонент вектора у. Так как расстояние Хемминга d между двумя
векторами y
\
и у
2
равно числу компонент, которыми они отличаются, то
расстояние между у' " у
2
равно W(y
1
—у
2
). Если векторы у' и у
2
оба являются
кодовыми векторами линейного кода Y(n,R), то разность y
1
—у
2
также должна
быть кодовым вектором, потому что множество всех кодовых векторов есть
линейное векторное пространство-
Следовательно, расстояние между двумя кодовыми векторами равно весу
некоторого третьего кодового вектора и минимальное расстояние для
линейного кода Y(n,R) равно минимальному весу его ненулевых векторов.
Для обнаружения произвольных искажений, которые измеряют в
передаваемых кодовых блоках не более t символов, необходимо и достаточно,
чтобы никакие t-кратные искажения не переводили одно кодовое слово в
другое. Это условие будет выполнено, если множество V (п, К)выбрано так,
что в нем нет двух кодовых слов, находящихся на расстоянии, меньшем t+l-
Если такой код использован для кодирования сообщений то прием
последовательности, которой нет в списке кодовых слов, является признаком
обнаружения ошибки.
Для того чтобы код исправлял все ошибки, кратность которых не
превосходит t, никакая пара кодовых слов под действием таких ошибок не
должна переходить в одну и ту же третью последовательность из , Другими
словами, все пары уi, yi
∈
Y(n,R) должны находиться друг от друга на рас-
стоянии, не меньшем 2t+1. Минимальное расстояние, взятое по всем парам
кодовых слов, называется минимальным ко-довым ра с стояние м. В общем
случае для исправления всех ошибок кратности не выше t и одновременного
обнаружения ошибок кратности не выше f, f
≥
f, необходимо и достаточно
выполнение условия do^t-^-f-т-},
т
'
:!
•
e
do—минимальное кодовое расстояние.
Здесь учитывается, что в коде, допускающем исправление вплоть до /-кратных
ошибок, происходит и обнаружение таких ошибок, поэтому, например, при
исправлении однократных и обнаружении двух- и трехкратных ошибок
должно быть rfo^5.
ПРОВЕРОЧНАЯ МАТРИЦА
Известно, что любое п R-мерное подпространство n-мерного линейного
пространства может быть задано с помощью системы n(1-R} линейно
независимых однородных уравнений, связывающих координаты векторов в
некотором базисе. Так как координатами векторов из V
n
.
q
в единичном базисе
являются символы у1, y2,..yn то система уравнений, определяющих линейный
код Y(n,R). имеет вид
(8)
,)1(,1,0
1
Rni
y
h
j
n
j
ij
−==
∑
=
где hij
∈
GF(q}, V i, /, y
∈
GF(q),
∀
j, m=n(1—R). Арифметические операции в (8)
выполняются над полем GF(q). Уравнение (8) можно переписать в матричной
форме
yH
T
=0 (9)
гд.е y={yj}
n
-, H==[h
ij
}, i=1m, J=1n: Н
T
T
T
—матрица, полудающаяся
транспонированием Н. Матрица Н, составленная яз коэффициентов уравнений

(8), называется проверочной или контрольной матрицей кода.
Таким образом, каждому линейному коду соответствует некоторая
проверочная матрица и, наоборот, каждой проверочной матрице соответствует
линейный код, для всех слов которого выполняется равенство (9). Поэтому
задачу построения линейного кода можно трактовать как задачу отыскания
матрицы Я размера {т*п} со свойствзмп, которые определяются теоремой [5].
Теорема 2. Линейный код У (n,R) с проверочной .матрицей Н имеет
минимальное кодовое расстояние do тогда и только тогда, когда любые d
o
—
1 столбцов матрицы Н линейно независимы.
ПРОЦЕДУРА КОДИРОВАНИЯ. ПОРОЖДАЮЩАЯ МАТРИЦА
Рассмотрим процедуру кодирования для линейного кода. В этом коде. как
во всяком линейном пространстве размерности k=nR, существуют k линейно
независимых векторов,
линейными комбинациями которых представляется любое кодовое слово.
Пусть Y{n,R)—линейный код и y
l
={Y
1
j}
n
y
k
={Y
k
j}
n
—линейно независимые
векторы из Y{n,R). Для обозначения линейного кода У (n, R} часто
ИСПОЛЬЗУЮТ символ (n,k} [5].
Каждая последовательность элементов поля x
l
={x
1
j}
n
GF(q} определяет единственный вектор
из Y(n,R), и наоборот, каждому вектору y
∈
Y(n,R) соответствует
единственная последовательность х={х,}
k
элементов GF{q}, такая, что имеет
место соотношение (10). Отсюда следует, что при использовании линейного
кода Y(n,R} для передачи информации лишь k=nR символов из п могут быть
выбраны произвольно. Остальные m=n(1—R) символов являются их
линейными комбинациями.
Равенство (10) можно записать в виде
y-xG, (11)
где G—матрица, строками которой служат
векторы y
i
Матричное равенство (11) следует понимать как запись способа кодирования
сообщения x={xi}
nR
в кодовое
слово y={Уj}
n
, - G называется порождающей матрицей ли-иейното кода
Y(n,R).
СВЯЗЬ МЕЖДУ ПРОВЕРОЧНОЙ И ПОРОЖДАЮЩЕЙ
МАТРИЦАМИ
Разобьем проверочную матрицу на две подматрицы H={
H
1
|H
2
} так, чтобы
правая подматрица была квадратной (m*m)-матрицей. Аналогичным образом
представим порождающую матрицу G=[G1|Gs}, где левая подматрица G1 —
квадратная, размером k*k. Подматрица G2 является прямоугольной (m*k)-
матрицей, а H1,—прямоугольной (m*k)-матрицей. Из уравнений (10) и (11)
следует, что G H
т
=0. Тогда
{
}
{}
0
1
1
||
2
1
1
21
21
=+=
H
G
H
G
HH
GG
T
T
T
Матрица Н представлена в правой канонической форме, если H2 есть
единичная матрица /, и G представлена в левой канонической форме, если G1
есть единичная матрица /. Для канонических представлений проверочной и
порождающей матриц имеем H
1
T
+G
2
=0
. Это соотношение позволяет записать
правую каноническую формy проверочной матрицы Н в виде Н={—С
2
T
|1}и
левую каноническую форму порождающей матрицы G в виде G=[I|—Н
1
T
}.
В общем случае, зная одну из матриц, с помощью соотношения GH
T
=0
можно найти вторую.
y
x
i
nR
i
i
y
∑
=
=
1
10)
Любая порождающая матрица линейного кода может быть приведена к левой
(правой) канонической форме, если в такой матрице возможны разбиения на
подматрицы, причем левая (правая) квадратная подматрица имеет определи-
тель, нс равный нулю. Действительно, пусть
G=={G
1
|G
2
} г. Gj есть квадратная
подматрица с det G
1
≠O.
Очевидно, G', равная F G, где F—квадратная матрица с det F^O, будет
снова порождающей матрицей того же кода. Тогда G'={FG1| F G2} и имеет
левую каноническую форму, если F G
1
=I.
В линейном коде с порождающей матрицей в левой канонической форме
первые k символов кодовых слов совпадают с сообщением (X1, X2, …,XK).
Остальные m символов являются линейными комбинациями первых. Поэтому
первые символы называют информационными, а последние контрольными.
Линейный код, задаваемый порождающей матрицей в канонической форме,
называется также систематическим..
ПРИМЕРЫ ПРОСТЫХ ЛИНЕЙНЫХ КОДОВ
.,1 nRi =
В настоящее время в теории и технике передачи дискретной информации
находят широкое применение относительно простые линейные коды. На
основе этих кодов можно построить более сложные корректирующие коды,
как линейные, так и нелинейные "(например, итеративные коды, каскадные.
рекуррентные), которые обладают большей эффективностью, чем
производные коды.