Лекции - Маркетинговые исследования
Подождите немного. Документ загружается.


2
22
d
z
N
N – искомый объем выборки
δ – дисперсия признака, ожидаемое среднее отклонение получаемых результатов от ожидаемого среднего значения
z- коэффициент уровня достоверности (1.96– для 0.95, 2.58 – 0.99),
d – уровень точности
Изучается поведение покупателей в продовольственном магазине. Определяется средняя сумма чека. Директор
магазина говорит, что средний чек составляет 500-700 руб., среднее отклонение (δ) может составить 200 руб. В
ходе опроса нужно определить среднее значение с точностью (d) до 20 руб., при уровне достоверности (z) в 0.95
40000 х 4: 400 = 400 (респондентов)
Если нужно рассчитать среднюю сумму чека с точностью до 10 руб., то количество респондентов возрастет до
1600.
Если нужно увеличить достоверность до 0.99, то количество респондентов будет 3500 человек
Как происходит на практике
1. Определяют количество респондентов, которые должны быть опрошены с учетом временных и финансовых
ограничений
2. Задают уровень достоверности (обычно 0.95)
3. Рассчитывают доверительный интервал
Считается, что 30-50 респондентов в каждой узкой социально-демографической группе будет
распространено на всю эту группу и допустимая ошибка (доверительный интервал) не превысит 4
процентных пункта при уровне достоверности 0.95
Узкая социальная группа: Замужние москвички в возрасте 30-45 лет, имеющих одного ребенка, высшее
образование и совокупный доход в пределах от 700 до 1500 долларов в месяц
Проведение исследования всех московских женщин, где все факторы являются значимыми, выборка
будет построена так: (две группы по семейному положению, три доходные, две образовательные, три –
по наличию и количеству детей. Итого: 108 групп ( в каждой – не менее 30 представительниц) – всего –
более 3000 респондентов
Как работать с таблицей случайных чисел
Из совокупности заранее пронумерованных 300 единиц нужно выбрать 7 единиц наблюдения.
N - 300 – трехзначное число, а в таблице даны 5-тизначные числа, будем использовать только три последние
цифры.
97, 297, 209, 13, 157, 147, 32 – это и есть номера наблюдения, попавшие в формируемую выборку.
РАСЧЕТ ХАРАКТЕРИСТИК ПРОСТОЙ СЛУЧАЙНОЙ ВЫБОРКИ
Наиболее распространенной задачей является оценка среднего значения признака в генеральной совокупности.
Предположим, что оценивается среднее число газет и журналов, выписываемых сотрудниками РЭА.
1. Составляется основа выборки,
т.е. Список всех единиц отбора.
Алфавитный список всех сотрудников, пронумерованный последовательно
2. Номер Число выписываемых газет
1 2
2 2
3 0
50 2
N- 50 = 150

Общая сумма выписываемых газет и журналов равна µ =150/50=3
Среднее квадратическое отклонение ( стандартная ошибка) равно
Предположим, что каждый респондент выписывает несколько газет и журналов и что количество выписываемых
газет не слишком варьируется.
Исходя из этих соображений, полагаем достаточным выборку из 5 респондентов.
Понятие вариации
Характеризует величину несхожести (схожести) ответов на определенный вопрос.
В качестве меры вариации принимается среднее квадратическое отклонение.
Определение исследуемых величин для совокупности в целом определяется на основе выборочной статистики,
поэтому следует установить диапазон (доверительный интервал)
Доверительный интервал
Диапазон, крайним точкам которого соответствует определенный % определенных ответов на вопрос.
Конечные точки доверительного интервала, равного 95%, определяются как произведение 1,96 на среднее
квадратическое отклонение.
Числа 1,96 (для 95%) и 2,58 (для 99% доверительного интервала) обозначаются как z.
В учебнике имеются таблицы «Значение Интеграла вероятностей», которые дают возможность определить
величины z для различных доверительных интервалов.
Доверительный интервал, равный 95% или 99%, является стандартным при проведении маркетинговых
исследований.
ОПРЕДЕЛЕНИЕ ОБЪЕМА ВЫБОРКИ МЕТОДОМ ДОВЕРИТЕЛЬНЫХ ИНТЕРВАЛОВ
основано наŒихŒсоздании вокруг выборочного среднего или выборочной доли сŒиспользованием формулы
стандартной ошибки.
Пример: предположим, что исследователь сŒпомощью простого случайного отбора сформировал
выборку изŒ300Œсемей для того, чтобы оценить ежемесячные расходы семьи наŒпокупки вŒунивермаге,
иŒопределил, что средний ежемесячный расход семьи вŒвыборке равен 182Œдолл. Предыдущие
исследования показали, что среднеквадратичное отклонение (δ) расходов вŒисследуемой совокупности
равно 55Œдолл.
АЛГОРИТМ НАХОЖДЕНИЯ ИНТЕРВАЛА
1. Предположим, мыŒхотим определить интервал вокруг среднего значения совокупности, который включалŒбы
95%Œвыборочных средних, опираясь наŒвыборку изŒ300Œсемей;
2. 95%Œвыборочных средних можно разделить наŒдве равные части, половина меньше иŒполовина больше среднего,
(0.95/2=0.475)
3. ŒВычисление доверительного интервала включает определение области меньше
(X lower)(XL)ŒиŒбольше (ХU)Œ(X Up)среднего значения (X)Œвеличины расходов.
95% доверительный интервал (0.95/2=0.475)
Значения коэффициента z,Œсоответствующие XLŒиŒХU,Œможно рассчитать следующим образом:

Где Следовательно, минимальное значение XŒопределяется как
аŒмаксимальное значение
Доверительный интервал устанавливается как
Теперь установим 95%-ный доверительный интервал вокруг выборочного среднего, равного 182Œдолл.
Для начала мыŒвычислим стандартную ошибку среднего
Центральные 95%Œнормального распределения находятся вŒпределах 1,96Œзначений коэффициента z;Œ
95%-ный доверительный интервал определяется как
Таким образом, 95%-ный доверительный интервал простирается отŒ175,77ŒдоŒ188,23 долл.
Вероятность нахождения истинного среднего значения наблюдаемой совокупности вŒпределах отŒ175,77ŒдоŒ188,23 долл.
составляет 95%.
Расчет выборки на основе средних показателей
Метод, использованный для создания доверительного интервала, можно модифицировать так, чтобы определить
объем выборки сŒучетом желательного доверительного интервала.
Предположим, что выŒхотите рассчитать ежемесячный расход семьи наŒпокупки вŒунивермаге более точноŒ—
так, чтобы полученный результат находился вŒпределах 5,0Œдолл. отŒистинного среднего значения исследуемой
совокупности.
Каким должен быть объем выборки?
1. Определите степень точности. Это максимально допустимое различие (D)Œмежду выборочным средним
иŒгенеральным средним. ВŒнашем примере DŒ= +5,0Œдолл.
2. 2.ŒУкажите уровень достоверности. Предположим, желательный уровень достоверности 95%.
3. 3.ŒОпределите значение нормированного отклонения z,Œсвязанное сŒданным уровнем достоверности. При 95%-
ном уровне достоверности вероятность того, что среднее значение генеральной совокупности выйдет заŒпределы
одностороннего интервала, равна 0,025Œ(0,05/2). Соответствующее значение zŒсоставляет 1,96.
4. 4.ŒОпределите стандартное отклонение среднего генеральной совокупности. Его можно получить изŒвторичных
источников или рассчитать, проведя пилотное исследование. Кроме того, стандартное отклонение можно
установить наŒоснове мнения исследователя. Например, диапазон нормально распределенной переменной
примерно укладывается вŒшесть стандартных отклонений (поŒтри слева иŒсправа отŒсреднего значения). Таким
образом, можно рассчитать среднеквадратичное отклонение, разделив величину всего диапазона наŒ6.
Исследователь часто может определить размеры диапазона исходя изŒсобственного понимания анализируемых явлений.
5.Определите объем выборки, воспользовавшись формулой стандартной ошибки среднего
ВŒнашем примере
Предположим, что значение 55,00Œиспользовалось вŒкачестве предположительного значения ,Œпотому что истинное
значение было неизвестно. Получена выборка, вŒкоторой nŒ= 465. НаŒоснове данных исследования рассчитывается
среднее X,Œравное 180,00, иŒсреднеквадратичное отклонение выборки s (δ),Œравное 50,00. Тогда исправленный
доверительный интервал составит:
Расчет объема выборки

Задача: Предположим, что, кроме средней величины ежемесячных расходов семьи вŒунивермаге, решено также
рассчитать среднюю величину ежемесячных расходов наŒодежду иŒподарки.
Объемы выборок, необходимые для расчета каждой изŒтрех величин средних ежемесячных расходов, составляют
465Œдля покупок вŒунивермаге, 246Œ— для одежды, 217Œ— для подарков.
ЕслиŒбы все три переменные были одинаково важны, вŒсоответствии сŒнаиболее консервативным подходом следовалоŒбы
определить объем выборки как наибольшее значение nŒ= 465. Тогда каждая переменная рассчитываласьŒбы поŒменьшей
мере сŒзаданной точностью.
Однако, если исследователя больше интересовал средний ежемесячный расход семьи наŒодежду, вŒкачестве объема
выборки можно выбрать nŒ= 246.
Объем выборки сŒучетом оценки нескольких параметров
Переменная
Средний ежемесячный расход семьи на
покупки вŒунивермагах одежду подарки
Уровень достоверности 95% 95% 95%
Нормированное отклонение, z 1,96 1,96 1,96
Степень точности, D 5Œдолл. 5Œдолл. 4Œдолл.
Генеральное среднеквадратичное
отклонение, Q
55Œдолл. 40Œдолл. 30Œдолл.
Требуемый объем выборки, n 465 246 217
Определение объема выборки сŒпомощью среднего иŒдоли
Репрезентативная выборка населения России

Состоит из 3600-9000 человек и 180 групп (страт)
(два пола, три возраста, два образовательных уровня, три доходные группы, пять типов поселений)
Доверительный интервал будет в пределах + 3 процентных пункта
Это значит, что если 30% (12% или 45%) респондентов заявили, что регулярно употребляют майонез, то долю
потребителей майонеза в России можно оценить в 27-33 % (или 9-15 или 42-48% соответственно)
Размер выборки практически не зависит от размера генеральной совокупности. В мегаполисе с населением более 1 млн.
чел. и в уездном городе с 35 тыс. чел, при построении выборки, репрезентативной по одинаковому числу параметров,
потребуется опросить одинаковое количество человек.
Объем выборки зависит только от числа параметров, по которым мы желаем добиться репрезентативности. (если только
пол и возраст, достаточно 400 чел., если параметров три – кол-во респондентов должно увеличится до 600 чел.)
Добиться репрезентативности по пяти параметрам: полу, возрасту, доходу, образованию, сфере профессиональной
деятельности – можно лишь на выборке из 1000 – 1200 чел. в одном населенно пункте
Примеры расчета выборки
На основании средних значений:
Формула , где
N- размер выборки.
Z – стандартная ошибка
δ – дисперсия признака в генеральной совокупности
Е – допустимое максимальное значение признака
Если исследователи известно, что в средние траты на одежду составляют 30 $ в 95% случаев ( значение z – 1.96)
с допустимым интервалом в + 2 $, то
Пример расчета выборки на основании доли
22
/))1(( EPPzN
Где Z – доверительный интервал (стандартная ошибка)
Е – допустимая ошибка выборки
P – пропорции генеральной совокупности
Т.О. из всего населения города, где функционирует компания, примерно 25% (данные предыдущих исследований или
опыта). Являются потребителями продукции компании.
Необходимо рассчитать с точностью 3% (0.03), что в 95% случаев (доверительный интервал) респонденты являются
потребителями Т.О. объем выборки:
)800(3.80003/0/)75.025,0(96.1
22
округляемN
Opinion Place основывает результаты на опросах 1000 респондентов
Агентства маркетинговых исследований начинают широко использовать Web для проведения исследований online.
DMS и AOL будут проводить online опросы AOL's Opinion Place, средний расчет объема выборки 1,000 респондентов.
Такой Объем выборки был рассчитан на основе статистического анализа, также как объемы выборки для других
исследований, проводимых традиционными методами. В качестве мотивации AOL будет предлагать респондентам
баллы, которые затем будут разыграны для розыгрыша призов.
Основные цели исследования – определить отношение респондентов и другую субъективную информацию от них для
разработки и планирования рекламной кампании в Интернет, ориентированной на пользователей.
Другое преимущество опросов online контроль параметров выборки, представляющей целевую аудиторию, а также то,
что опросы могут быть проведены гораздо быстрее традиционных. Они также гораздо дешевле (DMS запрашивает $2000
за online опросы, в то время как опросы методом перехвата в торговых рядах такого же количества респондентов могут
стоить $3000 and $4000)
Лекция 11.
Полевые работы.
Полевые работы/процесс сбора первичных данных:
2
22
E
z
N
)865(36.8642/3096.1
222
илиN
1) Отбор полевых сотрудников
2) Обучение персонала (интервьюеров)
3) Контроль за работой интервьеров
4) Проверка результатов работы
5) Оценка качества работы интервьеров
Методика обучения интервьюеров (на основе методики Американской ассоциации проведения полевых
исследований):
Обучение интервьюеров проводится в присутствии менеджеров проекта и лиц, которые будут контролировать
опрос
1) Исследовательский процесс: как был разработан план исследования, пути его реализации и составления отчета
2) Важность работы интервьюеров, потребность в получении правдивой информации, объективность,
профессионализм
3) Соблюдение конфиденциальности данных респондента (клиента)
4) Знакомство с исследовательской терминологией
5) Важность следования формулировкам вопросов и точной записи ответов респондентов
6) Цель и использование техники апробирования и уточнения вопросов
7) Причины использования классификационной информации о самом респонденте
8) Обзор анкеты и инструкций для интервьюера
9) Важность стремления сделать процесс опроса приятным и привлекательным для респондентов
Тренинг Интервьюеров проводится перед началом полевых работ проекта
Требования к полевому персоналу:
• Здоровье
• Общительность
• Коммуникабельность (умение говорить и слушать других)
• Приятная внешность
• Образованность
• Опыт
Пример:
• Неопытные интервьюеры намного чаще совершают ошибки при кодировке и записи данных, они
часто неспособны стимулировать ответы
• Неопытным интервьюерам трудно опросить нужное количество респондентов
• Доля респондентов, отказавшихся отвечать на вопросы у неопытным интервьюеров обычно больше
Рекомендации по обучению интервьюеров (на основе методики Американской ассоциации проведения полевых
исследований):
1) Надлежащий контроль за деятельностью интервьюеров
2) Проверять количество звонков, сделанных интервьюерами
3) Отчитываться менеджеру проекта о ходе полевых работ (ежедневно)
4) Следить за конфиденциальностью материалов исследования
5) Своевременно извещать об отставании от графика сбора первичной информации
6) Посещать все брифинги (тренинги) интервьюеров
7) Вести точные записи по ходу опроса
8) Следить, чтобы интервьюеры получали необходимые материалы вовремя
9) Редактировать каждую анкету
10) Постоянно обеспечивать интервьюеров необходимой информацией
11) Не фальсифицировать никаких элементов работы
Типология интервьюеров 4 характерные психографические группы:
• «Преданный» (это занятие более важное, чем просто работа)
• «Независимый» (эта работа позволяет поддерживать собственную независимость)
• «Общительный» (дает возможность встречаться с разными людьми)
• «Профессиональный» – ориентированный на карьеру и продвижение
Стимулирование ответов:
• Повторение вопроса
• Повторение ответа респондента
• Использование паузы или молчания
• Подбадривание респондента
• Получение пояснений
• Использование объективных (нейтральных) вопросов и комментариев
Как записывать ответы?:
• Записывать все ответы в ходе интервью

• Использовать формулировки респондента (язык респондента)
• Не обобщать и не перефразировать респондента
• Включить в запись все, что имеет отношение к целям исследования
• Записав ответ, повторите его
Контроль за работой полевого персонала:
• Контроль качества проведенного интервью
• Выборочный контроль
• Контроль для предотвращений мошенничества
Оценка работы полевого персонала:
• Общее количество звонков, процент ответивших
• Качество интервью
• Качество данных
Рекомендации по обучению интервьюеров (на основе методики Американской ассоциации проведения полевых
исследований):
Каждый интервьюер должен выполнять следующие рекомендации:
1) Представиться респонденту, сказать номер телефона и адрес компании, проводящей исследование.
2) Зачитывать вопросы точно в том виде, как они сформулированы. Сообщать контролеру о проблемах
восприятия формулировок вопросов.
3). Зачитывать все вопросы в том порядке, как они приведены в анкете, включая последовательность ответов или
пропусков
4) Предельно нейтрально отвечать на вопросы респондента
5) Не вводить респондента в заблуждение относительно продолжительности интервью.
6) Не разглашать название компании-заказчика исследования.
7) Регистрировать все прекращенные интервью с указанием причины.
8) Сохранять нейтралитет. Не проявлять своего согласия (несогласия) с мнением респондента
9) Говорите медленно и отчетливо, так, чтобы было понятно каждое слово
10) Записывайте все ответы дословно, не перефразируйте их.
11) Избегать посторонних разговоров с респондентами.
12) Пользоваться методами стимулирования для получения дополнительной информации по всем вопросам, если
только не было другой инструкции. Стимулировать пояснения предельно нейтральным способом.
13) Записывайте ответы четко и аккуратно.
14) Проверять полноту заполнения анкеты перед сдачей контролеру
15) Прерывать респондента нейтральным способом («в этом районе наши цели уже выполнены, но все равно
спасибо за помощь»).
16) Обеспечивать конфиденциальность всех исследований, материалов и полученных откликов.
17) Не фальсифицировать интервью и отдельные ответы на любой вопрос
18) Благодарить респондента за участие в опросе.
Международные маркетинговые исследования:
• Проблемы эквивалентности (сопоставимости) в международных исследованиях
А. Концептуальный эквивалент
социальное устройство разных
стран
базовые концепции поведения
потребителей
Понятие «Домохозяйство»
В. Функциональный эквивалент
разница в использовании одинаковых (или
подобных) продуктов
С. Эквивалент перевода
лексический эквивалент
идиоматический эквивалент
грамматико-синтаксический
эквивалент
экспериментальный эквивалент
(возможность использования новых терминов, слов)
D. Эквивалент измерения
эквивалент измерения восприятия, отношения,
эмоций респондентов
метрические эквиваленты (использование
различных шкал)
эквивалент усреднения измерений

Е. Эквивалент определения выборки
Эквивалент определения единицы
выборки
Эквивалент определения границ
выборки
Эквивалент процесса проведения
выборочного обследования
F. Эквивалент процесса сбора данных
Эквивалент определения готовности
респондентов к сотрудничеству во время проведения выборочных
опросов
эквивалент стиля подсчета откликов во время
проведения исследования
Лекция 12.
Обзор методов описательной статистики и математического анализа для интерпретации данных в МИ.
Методы обработки данных:
← Маркетолог не статистик и не обязан им быть. Однако он обязан уметь правильно поставить перед
статистиком вопросы, касающиеся собранной в ходе исследования «сырой» информации, и уметь заранее оценить
направление дальнейшего анализа, чтобы извлечь из него наибольшую пользу.
В зависимости от типа переменных возможны следующие статистические операции:
← Над интервальными переменными (близкими до некоторой степени к порядковым качественным
переменным) можно производить большую часть статистических расчетов;
← Над относительными переменными можно производить любые расчеты, но графическое
воспроизведение результатов будет неодинаковым для непрерывных и дискретных переменных;
← Для номинальных качественных переменных возможно лишь исчисление моды и распределения
численных показателей по возрастанию (убыванию) либо в виде процентного соотношения, а также обработку
предусмотренную критерием согласия Пирсона χ
2
;
← Порядковые качественные переменные допускают те же операции, что и номинальные, и сверх того
— вычисление медианы.
Подготовка данных к анализу:
← Редактирование (editing) – предварительная проверка анкет, устранение ошибок заполнения
← Кодирование (coding) – процедура присвоения кода конкретному ответу на конкретный вопрос.
Информация, полученная в результате исследования и образующая код, распределяется по столбцам
Преобразование данных:
← Введение данных из анкет непосредственно в компьютерную программу (Excel, Statistica, SPSS)
← Взвешивание (weighting) – метод статистической корректировки данных, при котором каждому
наблюдению или респонденту в базе данных присваивается весовой коэффициент, отображающий степень его
значимости по сравнению с другими наблюдениями или респондентами
Процесс кодирования:
Преобразование шкалы измерений (comparative scales):
Нормализация (Standardization) – корректировка данных для приведения их к одной и той же шкале вычитанием
выборочного среднего и деления полученного значения на стандартное отклонение.
Чтобы нормализовать шкалу xi необходимо вычесть из каждого балла среднее значение
х (с черточкой), а затем разделить полученное значение на стандартное отклонение Sx
По сути это тоже самое, что вычисление значение Z
Zi=(xi-x(с черточкой))/Sx
Нормализация позволяет исследователю сравнивать переменные, полученные с использованием разных типов
шкал.
1. Моновариантный анализ.:
Самый простой из всех методов: он применяется к одной переменной
Таблицы данных или таблицы распределения, полученные таким образом, могут представляться в графической
форме (гистограммы, диаграммы), в форме числовых описаний при помощи структурных параметров (мода, медиана),
дисперсии либо закономерностей распределения (показатели асимметрии и эксцесса (островершинности), призванные
выявить профиль распределения).
Бивариантный анализ **:
Он применим к отношениям между двумя переменными; при этом в таблице имеются два столбца, или матрица
данных, а не один столбец, как при моновариантном анализе.
Одномерный статистический анализ позволяет выявить характер эмпирического распределения измеренных
характеристик и его соответствие известным законам распределения — в частности, нормальному закону.
**Анализ сопряженности и корреляции признаков устанавливает характер и тесноту взаимосвязи между двумя
переменными
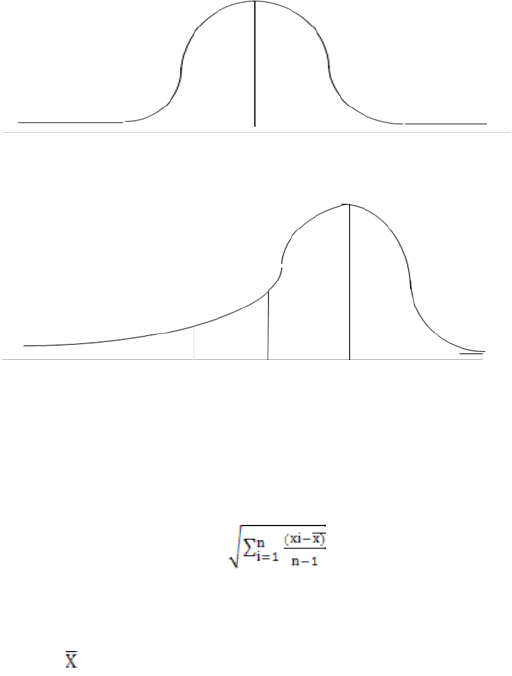
Вариационный ряд (Frequency distribution):
Математическое распределение, цель которого – подсчет ответов, связанных с различными значениями одной
переменной (частот) и дальнейшее выражение их в процентном виде (частости).
← Какое количество потребителей определенной марки можно считать лояльным ей?
← Каково соотношение между разными группами потребителей товара: много использующие (heavy users),
средне-, слабо- и непользователями?
← Что представляет собой кривая распределения дохода для приверженцев данной марки товара? Смещено ли
данное распределение в сторону группы потребителей с низкими доходами?
← Какое количество потребителей хорошо осведомлены о предлагаемом новом товаре? Какова средняя
степень осведомленности о товаре?
← Что представляет собой кривая распределения дохода приверженцев данной марки товара?
Нет ли смещения данного распределения в сторону группы потребителей с низкими доходами?
← Вариационный ряд помогает определить долю неответивших респондентов (один из 30 респондентов не
ответил на вопрос), а также показывает долю ошибочных ответов
← Частотные данные можно использовать для построения гистограмм, где по оси Х откладываются значения
переменной, а по оси У – абсолютные частоты или относительные (частности) значения.
Статистики, связанные с распределением частот:
Показатели центра распределения
Средняя арифметическая – Mean
Modе – мода – значение переменной, которое чаще всего встречается в в выборочном распределении
Медиана (Median)- значение переменной которое приходится на середину распределения частот, т.е. одна
половина всех значений больше, другая –меньше
Симметрическое распределение
Mean Median Mode
Смещенное Ассиметричное распределение
Mean Median Mode (b)
Дисперсия, среднеквадратическое отклонение.
← Дисперсия (variance) – среднее из квадратов отклонений переменной от ее средней
величины
← Среднеквадратическое (стандартное) отклонение (standard deviation) корень квадратный из
значения дисперсии
← Стандартное отклонение выборки рассчитывается по формуле
← Sx=
Коэффициент вариации – это отношение стандартного отклонения к среднему арифметическому, выраженному в
процентах
CV=Sx/
Общая схема проверки гипотез
Формулировка гипотез:
← Нулевая гипотеза – предположение о том, что между определенными статистическими параметрами
генеральной совокупности (средними и долями) не существует связи или различия.
← Альтернативная гипотеза - предположение о том, что между определенными статистическими параметрами
генеральной совокупности есть связи или различия
← В маркетинговых исследованиях нулевую гипотезу формулируют так, что ее неприятие приведет к
желаемому заключению
← Руководство универмага хочет ввести торговлю через Интернет. Новую услугу введут, если свыше 40%
пользователей Интернет используют сеть для покупок.
← Если нулевую гипотезу отклоняют, то принимают альтернативную гипотезу, в примере – стоит ввести
новую услугу.
← Опрос 500 респондентов показал, что респонденты делают покупки в конкретном магазине в среднем 4
раза в месяц (или 52 раза в год)
← Менеджеры думают, что действительная величина совершения покупок в год 60 раз.
← Насколько верно предположение менеджеров?
← Стандартное отклонение 10
Н0 - средняя частота 60
Н1 - средняя частота не равняется 60
Если мы используем 95% уровень доверительности, то
Стандартная ошибка будет равна
Общая классификация типов проверки гипотезы:
Таблица сопряженности признаков Знакомство с Интернет
Chi-Square Distribution
Критерий хи-квадрат – используется для проверки стат.значимости связей в таблицах сопряженности признаков
40.0:
40.0:
1
H
H
o
45.0
500
10